Cliente
O Spanner suporta consultas SQL. Segue-se um exemplo de consulta:
SELECT s.SingerId, s.FirstName, s.LastName, s.SingerInfo
FROM Singers AS s
WHERE s.FirstName = @firstName;
A construção @firstName é uma referência a um parâmetro de consulta. Pode usar um parâmetro de consulta em qualquer lugar onde possa usar um valor literal. Recomendamos vivamente a utilização de parâmetros em APIs programáticas. A utilização de parâmetros de consulta ajuda a evitar ataques de injeção SQL e é mais provável que as consultas resultantes beneficiem de várias caches do lado do servidor. Consulte a secção Colocação em cache abaixo.
Os parâmetros de consulta têm de estar associados a um valor quando a consulta é executada. Por exemplo:
Statement statement =
Statement.newBuilder("SELECT s.SingerId...").bind("firstName").to("Jimi").build();
try (ResultSet resultSet = dbClient.singleUse().executeQuery(statement)) {
while (resultSet.next()) {
...
}
}
Assim que o Spanner recebe uma chamada API, analisa a consulta e os parâmetros associados para determinar que nó do servidor do Spanner deve processar a consulta. O servidor envia de volta um fluxo de linhas de resultados que são consumidas pelas chamadas a ResultSet.next().
Execução de consultas
A execução da consulta começa com a chegada de um pedido "execute query" a um servidor do Spanner. O servidor executa os seguintes passos:
- Valide o pedido
- Analise o texto da consulta
- Gere uma álgebra de consulta inicial
- Gere uma álgebra de consultas otimizada
- Gere um plano de consulta executável
- Executar o plano (verificar autorizações, ler dados, codificar resultados, etc.)
Análise
O analisador SQL analisa o texto da consulta e converte-o numa árvore de sintaxe
abstrata. Extrai a estrutura básica da consulta (SELECT …
FROM … WHERE …) e faz verificações sintáticas.
Álgebra
O sistema de tipos do Spanner pode representar escalares, matrizes, estruturas, etc. A álgebra de consultas define operadores para análises de tabelas, filtragem, ordenação/agrupamento, todos os tipos de junções, agregação e muito mais. A álgebra de consulta inicial é criada a partir do resultado do analisador. As referências de nomes de campos na árvore de análise são resolvidas através do esquema da base de dados. Este código também verifica a existência de erros semânticos (por exemplo, número incorreto de parâmetros, incompatibilidades de tipos, etc.).
O passo seguinte ("otimização de consultas") usa a álgebra inicial e gera uma álgebra mais otimizada. Isto pode ser mais simples, mais eficiente ou apenas mais adequado às capacidades do motor de execução. Por exemplo, a álgebra inicial pode especificar apenas uma "junção", enquanto a álgebra otimizada especifica uma "junção hash".
Execução
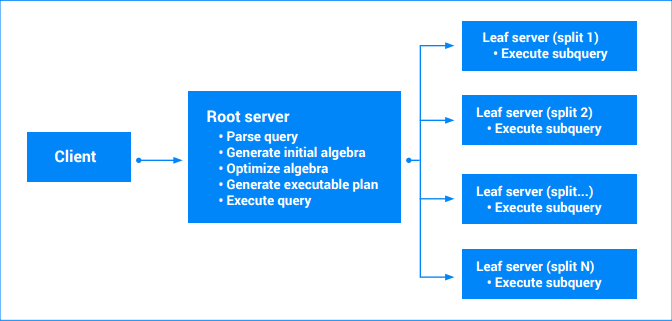
O plano de consulta executável final é criado a partir da álgebra reescrita. Basicamente, o plano executável é um gráfico acíclico dirigido de "iteradores". Cada iterador expõe uma sequência de valores. Os iteradores podem consumir entradas para produzir saídas (por exemplo, o iterador de ordenação). As consultas que envolvem uma única divisão podem ser executadas por um único servidor (o que contém os dados). O servidor vai analisar intervalos de várias tabelas, executar junções, realizar a agregação e todas as outras operações definidas pela álgebra de consultas.
As consultas que envolvem várias divisões são divididas em várias partes. Alguma parte da consulta vai continuar a ser executada no servidor principal (raiz). Outras subconsultas parciais são transferidas para os nós folha (aqueles que detêm as divisões que estão a ser lidas). Esta transferência pode ser aplicada recursivamente para consultas complexas, o que resulta numa árvore de execuções do servidor. Todos os servidores concordam com uma data/hora para que os resultados da consulta sejam um resumo consistente dos dados. Cada servidor folha envia de volta uma stream de resultados parciais. Para consultas que envolvem agregação, estes podem ser resultados parcialmente agregados. O servidor raiz da consulta processa os resultados dos servidores finais e executa o resto do plano de consulta. Para mais informações, consulte o artigo Planos de execução de consultas.
Quando uma consulta envolve várias divisões, o Spanner pode executar a consulta em paralelo nas divisões. O grau de paralelismo depende do intervalo de dados que a consulta analisa, do plano de execução da consulta e da distribuição de dados em divisões. O Spanner define automaticamente o grau máximo de paralelismo para uma consulta com base no tamanho da respetiva instância e na configuração da instância (regional ou multirregional) para alcançar o desempenho ideal da consulta e evitar sobrecarregar a CPU.
A colocar em cache
Muitos dos artefactos do processamento de consultas são automaticamente colocados em cache e reutilizados para consultas subsequentes. Isto inclui álgebras de consultas, planos de consultas executáveis, etc. O armazenamento em cache baseia-se no texto da consulta, nos nomes e nos tipos de parâmetros associados, entre outros. É por este motivo que a utilização de parâmetros associados (como @firstName no exemplo acima) é melhor do que a utilização de valores literais no texto da consulta. O primeiro pode ser colocado em cache uma vez e reutilizado independentemente do valor real associado. Consulte o artigo
Otimizar o desempenho das consultas do Spanner para ver mais detalhes.
Processamento de erros
A stream de linhas de resultados do método executeQuery pode ser interrompida por qualquer número de motivos: erros de rede transitórios, transferência de uma divisão de um servidor para outro (por exemplo, equilíbrio de carga), reinícios do servidor (por exemplo, atualização para uma nova versão), etc. Para ajudar a recuperar destes erros, o Spanner envia "tokens de retoma" opacos juntamente com lotes de dados de resultados parciais. Estes tokens de retoma podem ser usados ao tentar novamente a consulta para continuar
onde a consulta interrompida parou. Se estiver a usar as bibliotecas cliente do Spanner, isto é feito automaticamente. Por isso, os utilizadores da biblioteca cliente
não têm de se preocupar com este tipo de falha transitória.