Cliente
Spanner admite consultas SQL. Aquí tienes una consulta de ejemplo:
SELECT s.SingerId, s.FirstName, s.LastName, s.SingerInfo
FROM Singers AS s
WHERE s.FirstName = @firstName;
La construcción @firstName es una referencia a un parámetro de consulta. Puedes usar un parámetro de consulta en cualquier lugar donde se pueda usar un valor literal. Se recomienda usar parámetros en las APIs programáticas. El uso de parámetros de consulta ayuda a evitar ataques de inyección de SQL y es más probable que las consultas resultantes se beneficien de varias cachés del lado del servidor. Consulta la sección Almacenamiento en caché más abajo.
Los parámetros de consulta deben estar vinculados a un valor cuando se ejecute la consulta. Por ejemplo:
Statement statement =
Statement.newBuilder("SELECT s.SingerId...").bind("firstName").to("Jimi").build();
try (ResultSet resultSet = dbClient.singleUse().executeQuery(statement)) {
while (resultSet.next()) {
...
}
}
Cuando Spanner recibe una llamada a la API, analiza la consulta y los parámetros enlazados para determinar qué nodo de servidor de Spanner debe procesar la consulta. El servidor devuelve un flujo de filas de resultados que consumen las llamadas a ResultSet.next().
Ejecución de consultas
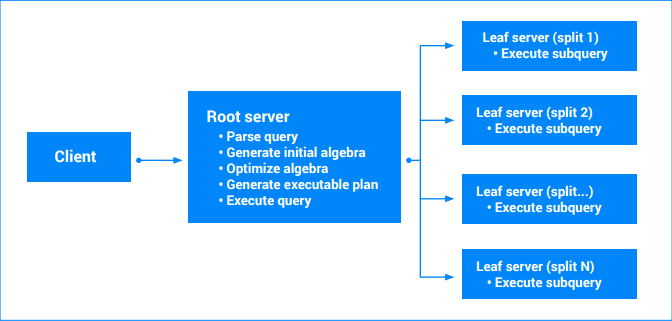
La ejecución de la consulta comienza cuando llega una solicitud de ejecución de consulta a algún servidor de Spanner. El servidor sigue estos pasos:
- Validar la solicitud
- Analizar el texto de la consulta
- Generar un álgebra de consultas inicial
- Generar un álgebra de consultas optimizado
- Generar un plan de consultas ejecutable
- Ejecuta el plan (comprueba los permisos, lee los datos, codifica los resultados, etc.).
Análisis
El analizador de SQL analiza el texto de la consulta y lo convierte en un árbol de sintaxis abstracta. Extrae la estructura básica de la consulta (SELECT …
FROM … WHERE …) y realiza comprobaciones sintácticas.
Álgebra
El sistema de tipos de Spanner puede representar escalares, arrays, estructuras, etc. El álgebra de consultas define operadores para análisis de tablas, filtrado, ordenación o agrupación, todo tipo de combinaciones, agregación y mucho más. El álgebra de consulta inicial se crea a partir de la salida del analizador. Las referencias de nombres de campos del árbol de análisis se resuelven mediante el esquema de la base de datos. Este código también comprueba si hay errores semánticos (por ejemplo, un número incorrecto de parámetros, incompatibilidades de tipos, etc.).
En el siguiente paso ("optimización de consultas"), se toma el álgebra inicial y se genera un álgebra más óptimo. Puede que sea más sencillo, eficiente o adecuado para las funciones del motor de ejecución. Por ejemplo, el álgebra inicial puede especificar solo una "unión", mientras que el álgebra optimizado especifica una "unión hash".
Ejecución
El plan de consulta ejecutable final se crea a partir del álgebra reescrita. Básicamente, el plan ejecutable es un grafo acíclico dirigido de "iteradores". Cada iterador expone una secuencia de valores. Los iteradores pueden consumir entradas para producir salidas (por ejemplo, el iterador de ordenación). Las consultas que implican una sola división pueden ejecutarse en un solo servidor (el que contiene los datos). El servidor analizará intervalos de varias tablas, ejecutará combinaciones, realizará agregaciones y todas las demás operaciones definidas por el álgebra de consultas.
Las consultas que impliquen varias divisiones se desglosarán en varias partes. Parte de la consulta se seguirá ejecutando en el servidor principal (raíz). Otras subconsultas parciales se transfieren a los nodos hoja (aquellos que son propietarios de las divisiones que se están leyendo). Esta transferencia se puede aplicar de forma recursiva a consultas complejas, lo que da como resultado un árbol de ejecuciones de servidor. Todos los servidores se ponen de acuerdo en una marca de tiempo para que los resultados de las consultas sean una instantánea coherente de los datos. Cada servidor hoja envía una secuencia de resultados parciales. En el caso de las consultas que implican agregación, podrían ser resultados agregados parcialmente. El servidor raíz de la consulta procesa los resultados de los servidores hoja y ejecuta el resto del plan de consulta. Para obtener más información, consulta Planes de ejecución de consultas.
Cuando una consulta implica varias divisiones, Spanner puede ejecutarla en paralelo en todas las divisiones. El grado de paralelismo depende del intervalo de datos que analiza la consulta, del plan de ejecución de la consulta y de la distribución de los datos en las divisiones. Spanner define automáticamente el grado máximo de paralelismo de una consulta en función del tamaño de su instancia y de la configuración de la instancia (regional o multirregional) para conseguir un rendimiento óptimo de la consulta y evitar sobrecargar la CPU.
Almacenamiento en caché
Muchos de los artefactos del procesamiento de consultas se almacenan automáticamente en caché y se reutilizan en consultas posteriores. Esto incluye álgebras de consultas, planes de consultas ejecutables, etc. El almacenamiento en caché se basa en el texto de la consulta, los nombres y los tipos de los parámetros enlazados, entre otros. Por eso, es mejor usar parámetros enlazados (como @firstName en el ejemplo anterior) que valores literales en el texto de la consulta. El primero se puede almacenar en caché una vez y reutilizarlo independientemente del valor enlazado real. Consulta más información en el artículo Optimizar el rendimiento de las consultas de Spanner.
Gestión de errores
El flujo de filas de resultados del método executeQuery se puede interrumpir por varios motivos: errores de red transitorios, transferencia de una división de un servidor a otro (por ejemplo, equilibrio de carga), reinicios del servidor (por ejemplo, actualización a una nueva versión), etc. Para ayudar a recuperarse de estos errores, Spanner envía "tokens de reanudación" opacos junto con lotes de datos de resultados parciales. Estos tokens de reanudación se pueden usar al reintentar la consulta para continuar donde se interrumpió. Si usas las bibliotecas de cliente de Spanner, esto se hace automáticamente, por lo que los usuarios de la biblioteca de cliente no tienen que preocuparse por este tipo de error transitorio.