本文介绍了用于导出 Cloud Monitoring 指标以供长期分析的解决方案。Cloud Monitoring 可为Google Cloud 和 Amazon Web Services (AWS) 提供监控解决方案。Cloud Monitoring 会将指标保留六周,因为 Monitoring 指标的价值通常具有时限性。因此,历史指标的价值会随着时间的推移而逐渐降低。六周的时限过后,对于无法通过短期分析判断的趋势,您仍可通过聚合指标来进行长期分析。
本解决方案旨在让您了解可供导出的指标详细信息,并提供一个无服务器参考实现供您将指标导出到 BigQuery。
DevOps 现状报告确定了可提高软件交付方面表现的功能。此解决方案将帮助您使用以下功能:
关于导出指标的使用场景
Cloud Monitoring 会从 Google Cloud、AWS 和应用插桩收集指标和元数据。Monitoring 指标可让您通过 API、信息中心和 Metrics Explorer 深入了解云应用的性能、正常运行时间和整体运行状况。通过这些工具,您可以查看过去 6 周的指标值以进行分析。如果您需要对指标进行长期分析,可使用 Cloud Monitoring API 导出指标以实现长期存储。
Cloud Monitoring 会保留最近 6 周的指标。它经常用于运维目的,例如监控虚拟机基础架构(CPU、内存、网络指标)和应用性能指标(请求或响应延迟时间)。如果这些指标超过预设的阈值,系统会通过提醒功能触发运维流程。
捕获的指标可能也会有助于进行长期分析。例如,您可能需要将来自网购星期一或其他高流量事件的应用性能指标与来自上一年度的指标进行比较,以为下一次高流量事件做好规划。另一个用例是查看 Google Cloud 一季度或一年内的服务用量,以对费用做出更准确的预测。您可能还需要查看数月或数年间的应用性能指标。
这些用例都需要长期保留指标以用于分析。将这些指标导出到 BigQuery 即可实现解决这些用例所需的分析功能。
使用要求
如需对 Monitoring 指标数据执行长期分析,请谨记以下三项基本要求:
- 从 Cloud Monitoring 导出数据。您需要将 Cloud Monitoring 指标数据导出为聚合指标值。之所以需要聚合指标,是因为存储原始
timeseries数据点虽然在技术上可行,但并不会带来更多价值。大多数长期分析都是在较长的时间范围内通过聚合信息进行的。聚合粒度取决于您的使用场景,但我们建议至少以一小时为时间段进行聚合。 - 提取数据进行分析。您需要将导出的 Cloud Monitoring 指标导入分析引擎以进行分析。
- 根据数据编写查询并构建信息中心。您需要使用信息中心和标准 SQL 来查询、分析及直观呈现数据。
实用步骤
- 构建要导出的指标列表。
- 从 Monitoring API 读取指标。
- 将从 Monitoring API 导出的 JSON 输出中的指标映射为 BigQuery 表格式。
- 将指标写入 BigQuery 中。
- 创建程序化时间表以定期导出指标。
架构
此架构的设计利用代管式服务来简化运维和管理工作、降低成本,并提供按需扩缩的能力。
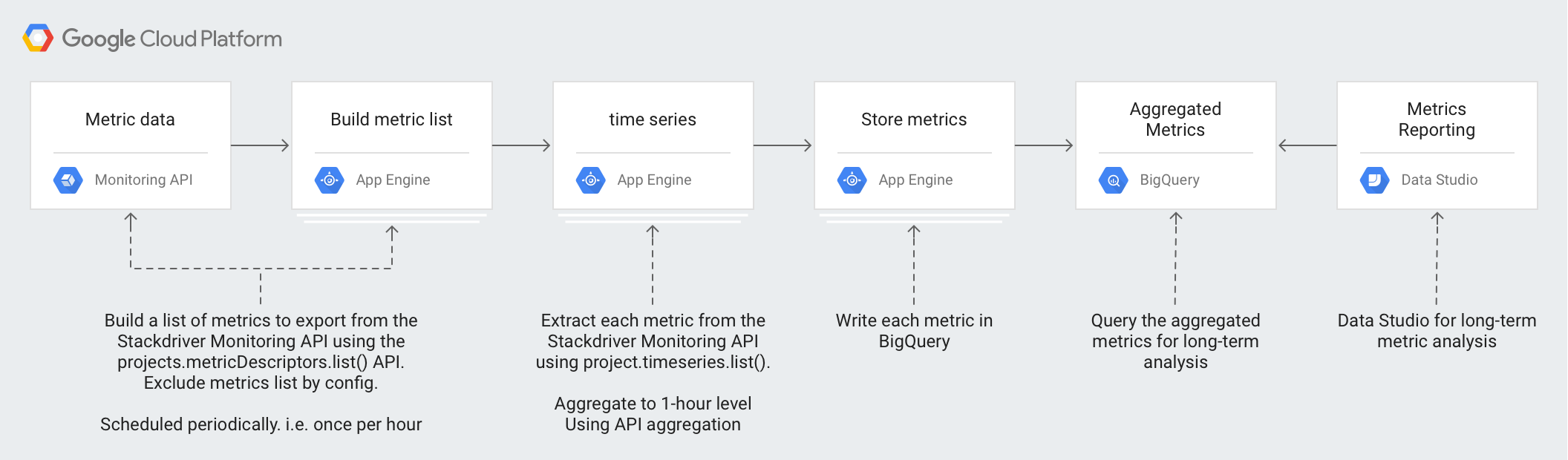
该架构中使用了以下技术:
- App Engine - 一种可伸缩的平台即服务 (PaaS) 解决方案,用于调用 Monitoring API 并向 BigQuery 写入数据。
- BigQuery - 一个全代管式分析引擎,用于提取和分析
timeseries数据。 - Pub/Sub - 一种全代管式实时消息传递服务,用于提供可扩缩的异步处理。
- Cloud Storage - 一种适用于开发者和企业的统一对象存储服务,用于存储有关导出状态的元数据。
- Cloud Scheduler - 一种 cron 式调度器,用于执行导出过程。
了解 Cloud Monitoring 指标详细信息
如需了解如何以最佳方式从 Cloud Monitoring 导出指标,您有必要了解它如何存储指标。
指标类型
Cloud Monitoring 中主要有四种类型的指标可供您导出。
- Google Cloud 指标列表:来自 Google Cloud 服务(例如 Compute Engine 和 BigQuery)的指标。
- 代理指标列表:来自运行 Cloud Monitoring 代理的虚拟机实例的指标。
- AWS 指标列表:来自 AWS 服务(如 Amazon Redshift 和 Amazon CloudFront)的指标。
- 来自外部来源的指标:来自第三方应用的指标和用户定义的指标,包括自定义指标。
这些指标类型都有一个指标描述符,其中包含指标类型以及其他指标元数据。以下示例指标演示了如何通过 Monitoring API projects.metricDescriptors.list 方法列出指标描述符。
{
"metricDescriptors": [
{
"name": "projects/sage-facet-201016/metricDescriptors/pubsub.googleapis.com/subscription/push_request_count",
"labels": [
{
"key": "response_class",
"description": "A classification group for the response code. It can be one of ['ack', 'deadline_exceeded', 'internal', 'invalid', 'remote_server_4xx', 'remote_server_5xx', 'unreachable']."
},
{
"key": "response_code",
"description": "Operation response code string, derived as a string representation of a status code (e.g., 'success', 'not_found', 'unavailable')."
},
{
"key": "delivery_type",
"description": "Push delivery mechanism."
}
],
"metricKind": "DELTA",
"valueType": "INT64",
"unit": "1",
"description": "Cumulative count of push attempts, grouped by result. Unlike pulls, the push server implementation does not batch user messages. So each request only contains one user message. The push server retries on errors, so a given user message can appear multiple times.",
"displayName": "Push requests",
"type": "pubsub.googleapis.com/subscription/push_request_count",
"metadata": {
"launchStage": "GA",
"samplePeriod": "60s",
"ingestDelay": "120s"
}
}
]
}
请务必注意指标描述符中 type、valueType 和 metricKind 字段的值。这些字段用于标识指标,并会影响指标描述符适用的聚合。
指标种类
每个指标都具有指标种类和值类型两个特性。如需了解详情,请参阅值类型和指标种类。指标种类和关联的值类型非常重要,因为它们的组合会影响指标的聚合方式。
在上述示例中,对于 pubsub.googleapis.com/subscription/push_request_count metric 指标类型,指标种类为 DELTA,值类型为 INT64。

在 Cloud Monitoring 中,指标种类和值类型存储在 metricsDescriptors 中,您可通过 Monitoring API 获取它们。
Timeseries
timeseries 是一段时间内针对每个指标类型存储的常规测量结果,其中包括指标类型、元数据、标签以及各测量数据点。系统会定期收集由 Monitoring 自动收集的指标(例如Google Cloud 和 AWS 指标)。例如,appengine.googleapis.com/http/server/response_latencies 指标会每 60 秒收集一次。
根据数据的报告频率以及与指标类型关联的任何标签,针对给定 timeseries 收集的一组数据点可能会不断增加。如果您导出原始 timeseries 数据点,那么需要导出的数据量可能非常大。要减少返回的 timeseries 数据点,您可以按给定的校准时间段对指标进行聚合。例如,对于每分钟返回一个数据点的给定指标 timeseries,通过使用聚合,您可以每小时返回一个数据点。这不但会减少导出数据点的数量,而且还会减轻分析引擎所需执行的分析处理量。在本文中,所选的每种指标类型都会返回 timeseries。
指标聚合
您可以使用聚合将来自多个 timeseries 的数据合并成一个 timeseries。Monitoring API 拥有强大的校准和聚合函数,因此,您只需将校准和聚合参数传递给 API 调用,而无需自行执行聚合。如需详细了解 Monitoring API 聚合的工作原理,请参阅过滤和聚合以及这篇博文。
您可以将 metric type 映射到 aggregation type,以确保校准指标并根据具体分析需求减少 timeseries 的数量。有很多校准器和缩减器可用于聚合 timeseries。校准器和缩减器都有一组指标,可供您用来根据指标种类和值类型进行校准或缩减。例如,如果您以 1 小时为时间段进行聚合,那么聚合结果就是每小时为 timeseries 返回 1 个数据点。
微调聚合的另一种方法是使用 Group By 函数,该函数可让您将聚合值分组为多个聚合 timeseries 列表。例如,您可以选择基于 App Engine 模块对 App Engine 指标进行分组。如果按 App Engine 模块进行分组,并结合使用校准器和缩减器以一小时为时间段进行聚合,那么聚合结果就是每小时为每个 App Engine 模块生成一个数据点。
如需进行详细的长期分析,您就需要保留足够多的数据,但记录各数据点会导致成本增加。在这种情况下,您可以借助指标聚合来平衡这两个方面。
参考实现细节
参考实现包含的组件与架构设计图中所示的组件相同。下文介绍了每个步骤所涉及的一些实用的相关实现细节。
构建指标列表
Cloud Monitoring 定义了一千多种指标类型,可帮助您监控 Google Cloud、AWS 和第三方软件。Monitoring API 提供了 projects.metricDescriptors.list 方法,该方法会返回 Google Cloud项目可用的指标列表。此外,Monitoring API 还提供了过滤机制,可让您对需要导出以进行长期性存储和分析的指标进行过滤。
GitHub 中的参考实现使用 Python App Engine 应用来获取一系列指标,然后分别将每条消息写入一个 Pub/Sub 主题。导出过程由 Cloud Scheduler 启动,它会生成用于运行应用的 Pub/Sub 通知。
您可以通过多种方式来调用 Monitoring API;在本例中,Cloud Monitoring 和 Pub/Sub API 是使用 Python 版 Google API 客户端库调用的,因为该客户端库可以灵活访问 Google API。
获取 timeseries
您可以提取指标的 timeseries,然后将每个 timeseries 写入 Pub/Sub。借助 Monitoring API,您可以使用 project.timeseries.list 方法来按给定的校准时间段对指标值进行聚合。聚合数据有助于减少处理负载、所需存储空间、查询时间以及分析费用。数据聚合是高效执行长期指标分析的最佳做法。
GitHub 中的参考实现使用 Python App Engine 应用来订阅主题,在该主题中,需要导出的每个指标均作为一条单独消息进行发送。对于收到的每条消息,Pub/Sub 会将其推送到 App Engine 应用。该应用会根据输入配置获取给定聚合指标的 timeseries。在本例中,Cloud Monitoring 和 Pub/Sub API 是使用 Google API 客户端库调用的。
每个指标至少可以返回一个 timeseries.。系统会通过单独的 Pub/Sub 消息发送每个指标,以将其插入 BigQuery 中。参考实现中内置了 type-to-aligner 和 type-to-reducer 指标的映射。下表根据校准器和缩减器支持的指标种类和值类型捕获参考实现中使用的映射。
| 值类型 | GAUGE |
校准器 | 缩减器 | DELTA |
校准器 | 缩减器 | CUMULATIVE2 |
校准器 | 缩减器 |
|---|---|---|---|---|---|---|---|---|---|
BOOL |
有 |
ALIGN_FRACTION_TRUE
|
无 | 无 | 不适用 | 不适用 | 无 | 不适用 | 不适用 |
INT64 |
有 |
ALIGN_SUM
|
无 | 有 |
ALIGN_SUM
|
无 | 有 | 无 | 无 |
DOUBLE |
有 |
ALIGN_SUM
|
无 | 有 |
ALIGN_SUM
|
无 | 有 | 无 | 无 |
STRING |
有 | 已排除 | 已排除 | 无 | 不适用 | 不适用 | 无 | 不适用 | 不适用 |
DISTRIBUTION |
有 |
ALIGN_SUM
|
无 | 有 |
ALIGN_SUM
|
无 | 有 | 无 | 无 |
MONEY |
无 | 不适用 | 不适用 | 无 | 不适用 | 不适用 | 无 | 不适用 | 不适用 |
请务必考虑 valueType 与校准器和缩减器之间的映射,因为对于每个校准器和缩减器,只有特定的 valueTypes 和 metricKinds 才可以进行聚合。
例如,请考虑 pubsub.googleapis.com/subscription/push_request_count metric 类型。根据 DELTA 指标种类和 INT64 值类型,您可以按以下方式对该指标进行聚合:
- 校准时间段 - 3600 秒(即 1 小时)
Aligner = ALIGN_SUM- 按该校准时间段生成的数据点是该时间段内所有数据点的总和。Reducer = REDUCE_SUM- 通过计算每个校准时间段的timeseries的总和进行缩减。
除了校准时间段、校准器和缩减器值以外,project.timeseries.list 方法还需要其他几项输入:
filter- 选择要返回的指标。startTime- 选择返回timeseries的开始时间点。endTime- 选择返回timeseries的最后时间点。groupBy- 输入对timeseries响应进行分组所依据的字段。alignmentPeriod- 输入指标的校准时间段。perSeriesAligner- 根据alignmentPeriod定义的均衡时间间隔来校准数据点。crossSeriesReducer- 按时间间隔,将多个具有不同标签值的数据点合并为一个数据点。
向 API 发送的 GET 请求包括前述列表中的所有参数。
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=START_TIME_VALUE&
interval.endTime=END_TIME_VALUE&
aggregation.alignmentPeriod=ALIGNMENT_VALUE&
aggregation.perSeriesAligner=ALIGNER_VALUE&
aggregation.crossSeriesReducer=REDUCER_VALUE&
filter=FILTER_VALUE&
aggregation.groupByFields=GROUP_BY_VALUE
以下 HTTP GET 示例演示了如何使用输入参数来调用 projects.timeseries.list API 方法:
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z&
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
aggregation.crossSeriesReducer=REDUCE_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+&
aggregation.groupByFields=metric.labels.key
上述 Monitoring API 调用包含一个 crossSeriesReducer=REDUCE_SUM,这意味着指标将合并并缩减为一个总和,如以下示例所示。
{
"timeSeries": [
{
"metric": {
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"resource": {
"type": "pubsub_subscription",
"labels": {
"project_id": "sage-facet-201016"
}
},
"metricKind": "DELTA",
"valueType": "INT64",
"points": [
{
"interval": {
"startTime": "2019-02-08T14:00:00.311635Z",
"endTime": "2019-02-08T15:00:00.311635Z"
},
"value": {
"int64Value": "788"
}
}
]
}
]
}
这种聚合级别会将数据聚合为单个数据点,从而生成一个可反映整体 Google Cloud 项目情况的理想指标。但是,它无法让您深入了解对该指标有影响的资源。在上述示例中,您无法分辨哪个 Pub/Sub 订阅对请求计数的影响最大。
如果要查看生成 timeseries 的各个组件的详细信息,您可以移除 crossSeriesReducer 参数。没有 crossSeriesReducer 参数,Monitoring API 就不会合并各种 timeseries 来创建单个值。
以下 HTTP GET 示例演示了如何使用输入参数来调用 projects.timeseries.list API 方法。本例未使用 crossSeriesReducer 参数。
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+
在以下 JSON 响应中,由于 timeseries 已进行分组,因此 metric.labels.keys 在两个结果中保持不变。系统会为每个 resource.labels.subscription_ids 值返回单独的数据点。请查看以下 JSON 中的 metric_export_init_pub 和 metrics_list 值。建议按此级别进行聚合,因为这可让您在 BigQuery 查询中使用作为资源标签包含在内的Google Cloud 产品。
{
"timeSeries": [
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "1"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metric_export_init_pub"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
},
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "803"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metrics_list"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
}
]
}
在 projects.timeseries.list API 调用的 JSON 输出中,每个指标都作为一条单独消息直接写入 Pub/Sub。可能出现扇出情况,即一个输入指标生成一个或多个 timeseries。Pub/Sub 可以在不发生超时的情况下消减潜在的大型扇出。
作为输入提供的校准时间段意味着该时间范围内的值将被聚合为单个值,如前述示例响应中所示。此外,校准时间段还决定了导出作业的运行频率。例如,如果校准时间段设置为 3600 秒(即 1 小时),那么导出作业会每小时运行一次来定期导出 timeseries。
存储指标
GitHub 中的参考实现使用 Python App Engine 应用来读取每个 timeseries,然后将记录插入 BigQuery 表格中。对于收到的每条消息,Pub/Sub 会将其推送到 App Engine 应用。Pub/Sub 消息包含以 JSON 格式从 Monitoring API 导出的指标数据,并且需要映射到 BigQuery 表格的结构。在本例中,BigQuery API 是使用 Google API 客户端库调用的。
BigQuery 架构的设计与从 Monitor API 导出的 JSON 数据密切相关。在构建 BigQuery 表架构时,需要考虑的一个因素是数据规模,因为数据会不断增加。
在 BigQuery 中,我们建议您根据日期字段对表进行分区,因为这样可以通过选择日期范围来提高查询效率,而无需执行全表扫描。如果您打算定期运行导出作业,可以安全地使用基于提取日期的默认分区。
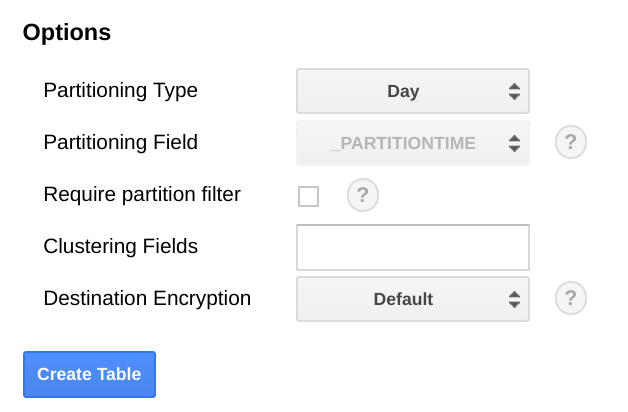
如果您计划批量上传指标或不定期运行导出作业,分区点可使用 end_time,,但这需要更改 BigQuery 架构。您可以将 end_time 移至架构中的顶级字段,以便使用它来进行分区,也可以向架构添加新的字段。之所以需要移动 end_time 字段,是因为该字段包含在 BigQuery 记录中,而分区必须在顶级字段上进行。如需了解详情,请参阅 BigQuery 分区文档。
BigQuery 还可以为数据集、表和表分区设置过期时间。
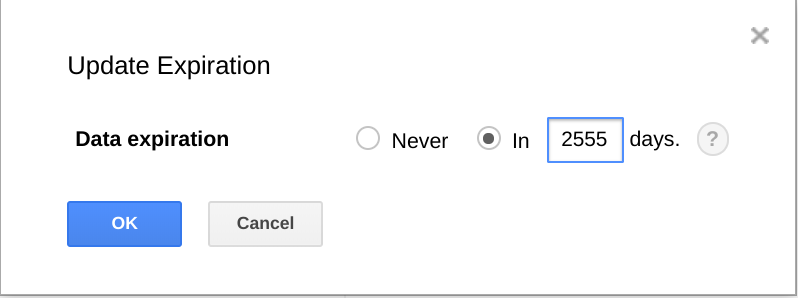
如需清除不再需要的旧数据,此功能会很实用。例如,如果您的分析涵盖的时间段为三年,您可以添加政策以删除 3 年前的数据。
安排导出作业
Cloud Scheduler 是一项全代管式的 Cron 作业调度服务。通过 Cloud Scheduler,您可以使用标准 Cron 时间安排格式来触发 App Engine 应用,使用 Pub/Sub 发送消息,或将消息发送到任意 HTTP 端点。
在 GitHub 的参考实现中,Cloud Scheduler 每小时发送一条 Pub/Sub 消息并在其中附上与 App Engine 配置匹配的令牌,以触发 list-metrics App Engine 应用。应用配置中的默认聚合时间段为 3600 秒(即 1 小时),该设置决定了应用的触发频率。建议至少以一小时为时间段进行聚合,因为这样既可以减少数据量,又可以保留高保真数据。如果使用其他校准时间段,请更改导出频率以与校准时间段保持一致。参考实现将最后的 end_time 值存储在 Cloud Storage 中,并将该值用作后续的 start_time(除非将 start_time 作为参数传递)。
以下 Cloud Scheduler 屏幕截图演示了如何使用 Google Cloud 控制台将 Cloud Scheduler 配置为每小时调用一次 list-metrics App Engine 应用。
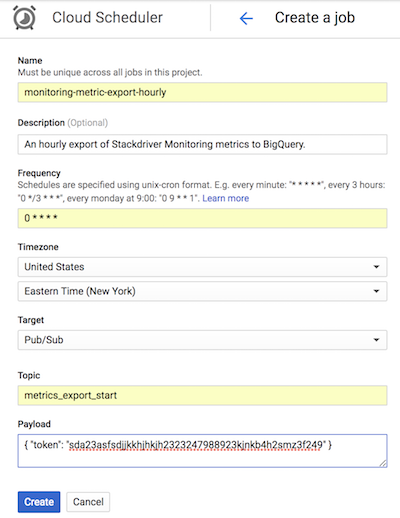
频率字段使用 Cron 格式语法指示 Cloud Scheduler 执行该应用的频率。目标字段指定生成的 Pub/Sub 消息,载荷字段包含 Pub/Sub 消息中所含的数据。
使用导出的指标
将数据导出到 BigQuery 中后,您现在可以使用标准 SQL 来查询该数据或构建信息中心,以直观呈现您的指标在一段时间内的趋势。
示例查询:App Engine 延迟时间
以下查询查找 App Engine 应用的平均延迟时间指标值的最小值、最大值和平均值。metric.type 用于标识 App Engine 指标,而标签用于根据 project_id 标签值标识 App Engine 应用。使用 point.value.distribution_value.mean 的原因是,此指标是 Monitoring API 中的 DISTRIBUTION 值,该值已映射到 BigQuery 中的 distribution_value 字段对象。end_time 字段用于回溯过去 30 天的值。
SELECT
metric.type AS metric_type,
EXTRACT(DATE FROM point.INTERVAL.start_time) AS extract_date,
MAX(point.value.distribution_value.mean) AS max_mean,
MIN(point.value.distribution_value.mean) AS min_mean,
AVG(point.value.distribution_value.mean) AS avg_mean
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'appengine.googleapis.com/http/server/response_latencies'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
GROUP BY
metric_type,
extract_date
ORDER BY
extract_date
示例查询:BigQuery 查询计数
以下查询返回项目每天的 BigQuery 查询数。使用 int64_value 字段的原因是,此指标是 Monitoring API 中的 INT64 值,该值已映射到 BigQuery 中的 int64_value 字段。metric.type 用于标识 BigQuery 指标,而标签根据 project_id 标签值标识项目。end_time 字段用于回溯过去 30 天的值。
SELECT
EXTRACT(DATE FROM point.interval.end_time) AS extract_date,
sum(point.value.int64_value) as query_cnt
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
and metric.type = 'bigquery.googleapis.com/query/count'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
group by extract_date
order by extract_date
示例查询:Compute Engine 实例
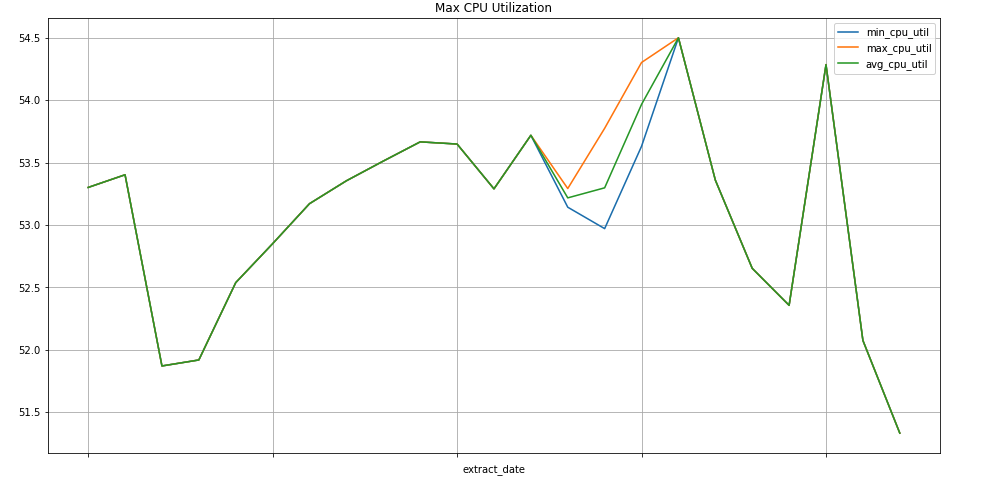
以下查询查找项目 Compute Engine 实例的 CPU 用量指标值的每周最小值、最大值和平均值。metric.type 用于标识 Compute Engine 指标,而标签根据 project_id 标签值标识实例。end_time 字段用于回溯过去 30 天的值。
SELECT
EXTRACT(WEEK FROM point.interval.end_time) AS extract_date,
min(point.value.double_value) as min_cpu_util,
max(point.value.double_value) as max_cpu_util,
avg(point.value.double_value) as avg_cpu_util
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'compute.googleapis.com/instance/cpu/utilization'
group by extract_date
order by extract_date
直观呈现数据
BigQuery 已与众多数据可视化工具相集成。
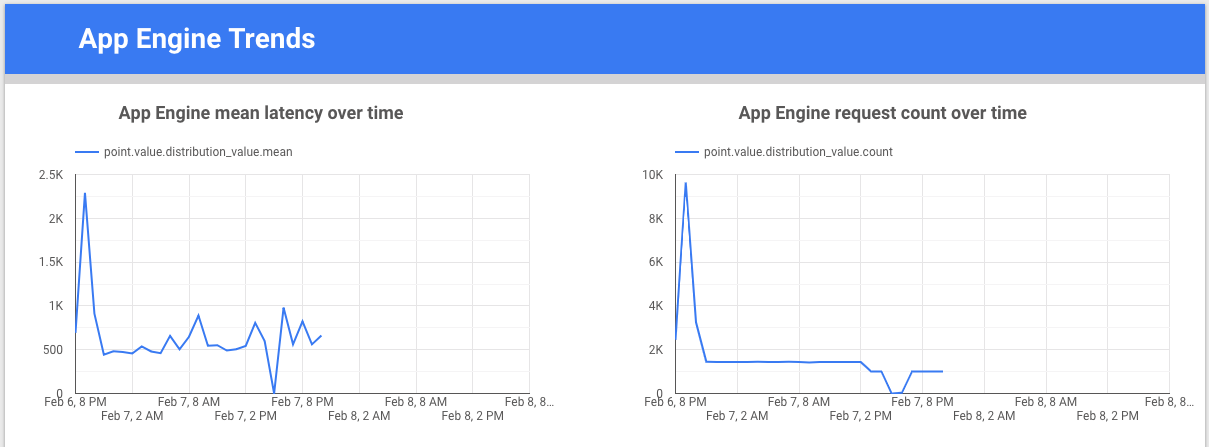
Looker 数据洞察 是一款由 Google 构建的免费工具,可让您构建数据图表和信息中心来直观呈现指标数据,然后分享给您的团队。以下示例演示了一段时间内 appengine.googleapis.com/http/server/response_latencies 指标的延迟时间和计数趋势线图。
Colaboratory 是一款适用于机器学习教育和研究领域的调查工具。它属于托管式 Jupyter 笔记本环境,您无需设置即可使用和访问 BigQuery 中的数据。借助 Colab 笔记本、Python 命令和 SQL 查询,您可以开发详细的分析和可视化效果。
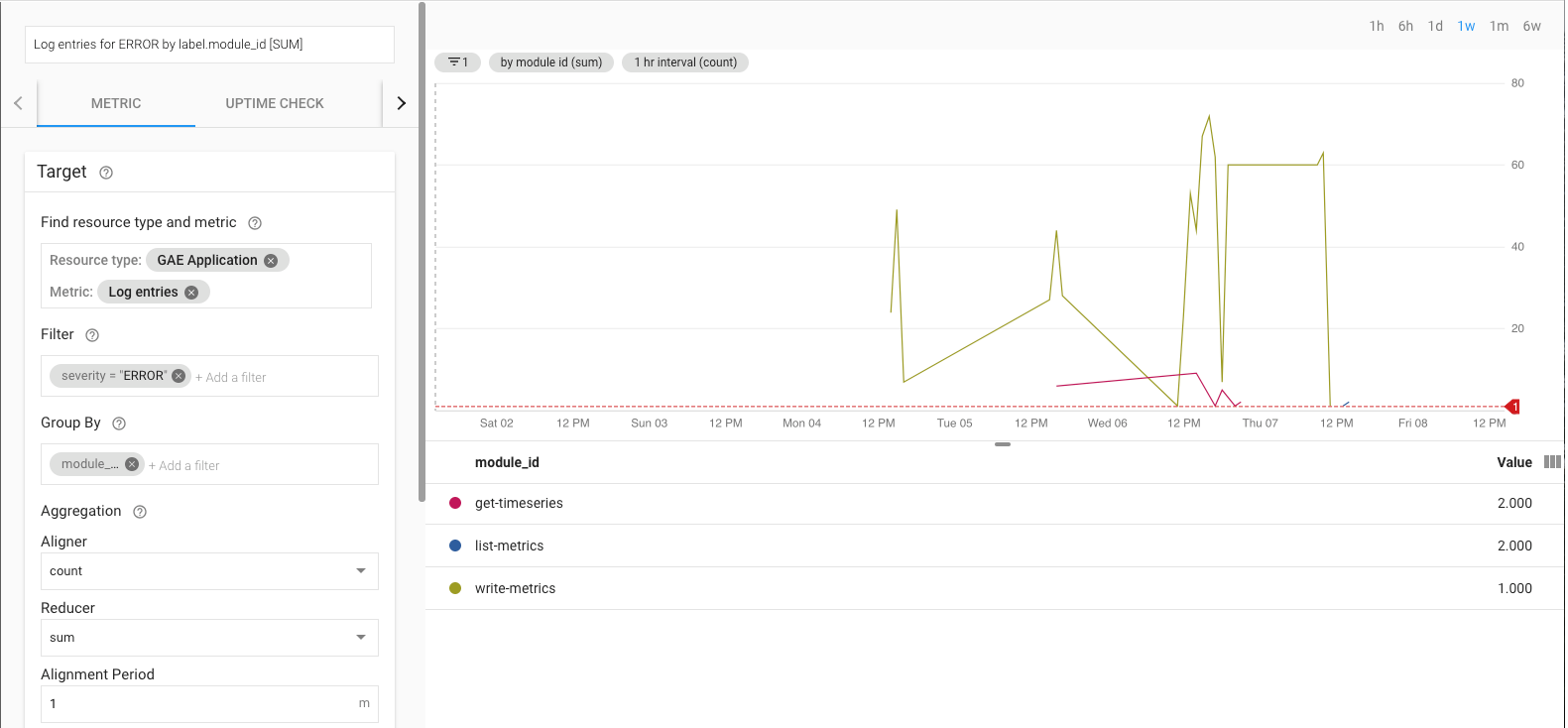
监控导出参考实现
导出作业运行时,您需要对其进行监控。可通过设置服务等级目标 (SLO) 来确定要监控的指标。SLO 是某一服务等级的一个或多个目标值,服务等级可通过指标来衡量。站点可靠性工程一书介绍了 SLO 的四个主要方面:可用性、吞吐量、错误率和延迟时间。对于数据导出,吞吐量和错误率是两个主要考虑因素,您可以通过以下指标来监控它们:
- 吞吐量 -
appengine.googleapis.com/http/server/response_count - 错误率 -
logging.googleapis.com/log_entry_count
例如,如需监控错误率,您可以使用 log_entry_count 指标并针对严重性为 ERROR 的 App Engine 应用(list-metrics、get-timeseries、write-metrics)进行过滤。然后,您可以使用 Cloud Monitoring 中的提醒政策来接收有关导出应用中所遇到错误的提醒。
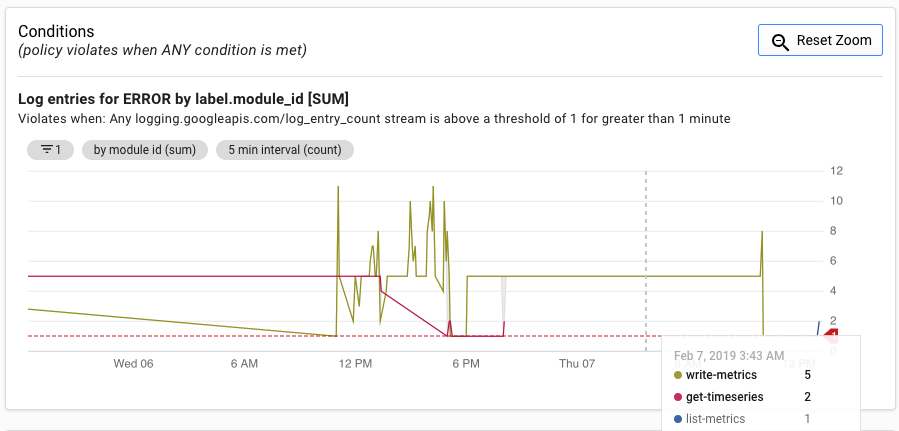
Alerting 界面显示 log_entry_count 指标与生成提醒的阈值的对照图。
后续步骤
- 查看 GitHub 上的参考实现。
- 阅读 Cloud Monitoring 文档。
- 浏览 Cloud Monitoring v3 API 文档。
- 如需查看更多参考架构、图表和最佳实践,请浏览云架构中心。
- 阅读我们关于 DevOps 的资源。
详细了解与本解决方案相关的 DevOps 功能:
进行 DevOps 快速检查,了解您与业界其他公司相比所处的位置。