이 문서에서는 Google Cloud 의 리소스에서 로그 및 이벤트를 Splunk로 스트리밍하는 프로덕션에 즉시 사용 가능하고 확장성과 내결함성이 있는 로그 내보내기 메커니즘을 만드는 데 도움이 되는 참조 아키텍처를 설명합니다. Splunk는 통합 보안 및 관측 가능성 플랫폼을 제공하는 인기 분석 도구입니다. 실제로 로깅 데이터를 Splunk Enterprise 또는 Splunk Cloud Platform으로 내보낼 수 있습니다. 관리자는 IT 운영 또는 보안 사용 사례에도 이 아키텍처를 사용할 수 있습니다.
이 참조 아키텍처는 다음 다이어그램과 유사한 리소스 계층 구조를 가정합니다. 조직, 폴더, 프로젝트 수준의 모든 Google Cloud 리소스 로그가 집계된 싱크로 수집됩니다. 그런 다음 집계된 싱크는 이러한 로그를 로그 내보내기 파이프라인으로 전송하고, 이 파이프라인에서 로그를 처리하여 Splunk로 내보냅니다.

아키텍처
다음 다이어그램은 이 솔루션을 배포할 때 사용하는 참조 아키텍처를 보여줍니다. 이 다이어그램은 로그 데이터가Google Cloud 에서 Splunk로 전송되는 방식을 보여줍니다.

이 아키텍처에는 다음 구성요소가 포함됩니다.
- Cloud Logging: 프로세스를 시작하기 위해 Cloud Logging은 로그를 조직 수준의 집계된 로그 싱크로 수집하고 해당 로그를 Pub/Sub으로 전송합니다.
- Pub/Sub: 그러면 Pub/Sub 서비스에서 로그에 대한 단일 주제 및 구독을 만들어 기본 Dataflow 파이프라인으로 전달합니다.
- Dataflow: 이 참조 아키텍처에는 두 가지 Dataflow 파이프라인이 있습니다.
- 기본 Dataflow 파이프라인: 이 프로세스의 핵심인 기본 Dataflow 파이프라인은 Pub/Sub 구독에서 로그를 가져와 Splunk에 전달하는 Pub/Sub to Splunk 스트리밍 파이프라인입니다.
- 보조 Dataflow 파이프라인: 기본 Dataflow 파이프라인과 동시에 사용되는 보조 Dataflow 파이프라인은 전송이 실패할 경우 메시지를 재생하는 Pub/Sub to Pub/Sub 스트리밍 파이프라인입니다.
- Splunk: 프로세스가 끝나면 Splunk Enterprise 또는 Splunk Cloud Platform이 HTTP Event Collector(HEC) 역할을 하며 추가 분석을 위해 로그를 수신합니다. Splunk는 온프레미스에 배포하거나 Google Cloud 에 SaaS로 배포하거나 하이브리드 방식을 통해 배포할 수 있습니다.
사용 사례
이 참조 아키텍처는 클라우드 푸시 기반 접근 방식을 사용합니다. 이 푸시 기반 방법에서는 Pub/Sub to Splunk Dataflow 템플릿을 사용하여 로그를 Splunk HTTP Event Collector(HEC)로 스트리밍합니다. 이 참조 아키텍처에서는 Dataflow 파이프라인 용량 계획 및 일시적인 서버 또는 네트워크 문제가 발생했을 때 잠재적인 전송 실패를 처리하는 방법도 설명합니다.
이 참조 아키텍처는 Google Cloud 로그에 중점을 두지만 동일한 아키텍처를 사용하여 실시간 애셋 변경사항, 보안 발견사항과 같은 다른 Google Cloud 데이터를 내보낼 수도 있습니다. Cloud Logging의 로그를 통합하여 Splunk와 같은 기존 파트너 서비스를 계속 통합 로그 분석 솔루션으로 사용할 수 있습니다.
Google Cloud 데이터를 Splunk로 스트리밍하는 푸시 기반 방법에는 다음과 같은 이점이 있습니다.
- 관리형 서비스: 관리형 서비스인 Dataflow는 로그 내보내기와 같은 데이터 처리 태스크를 위해 Google Cloud 에서 필요한 리소스를 유지보수합니다.
- 분산 워크로드: 이 메서드를 사용하면 병렬 처리를 위해 여러 작업자에 워크로드를 분산할 수 있으므로 단일 장애점이 없습니다.
- 보안: Google Cloud 는 데이터를 Splunk HEC에 푸시하므로 서비스 계정 키를 만들고 관리하는 것과 관련된 유지보수 및 보안 부담이 없습니다.
- 자동 확장: Dataflow 서비스가 수신 로그 볼륨 및 백로그의 변형에 따라 작업자 수를 자동으로 확장합니다.
- 내결함성 일시적인 서버 또는 네트워크 문제가 발생하는 경우 푸시 기반 방법에서 Splunk HEC로 데이터를 다시 전송하려고 자동으로 시도합니다. 이 방법은 또한 데이터 손실을 방지하기 위해 전달할 수 없는 로그 메시지에 대해 처리되지 않은 주제(데드 레터 주제라고도 함)를 지원합니다.
- 단순성: Splunk에서 하나 이상의 헤비 포워더를 실행하는 데 드는 관리 오버헤드와 비용을 피할 수 있습니다.
이 참조 아키텍처는 제약, 금융 서비스 등의 규제 업종을 포함한 다양한 업종 카테고리의 비즈니스에 적용됩니다. 다음과 같은 이유로 Google Cloud 데이터를 Splunk로 내보낼 수 있습니다.
- 비즈니스 분석
- IT 운영
- 애플리케이션 성능 모니터링
- 보안 운영
- 규정 준수
설계 대안
Splunk로 로그를 내보내기 위한 또 다른 방법은Google Cloud에서 로그를 가져오는 것입니다. 이 가져오기 기반 메서드에서는 Google Cloud API를 사용하여 Google Cloud용 Splunk 부가기능을 통해 데이터를 가져옵니다. 다음과 같은 상황에서는 가져오기 기반 메서드를 사용할 수 있습니다.
- Splunk 배포가 Splunk HEC 엔드포인트를 제공하지 않습니다.
- 로그 볼륨이 낮습니다.
- Cloud Monitoring 측정항목, Cloud Storage 객체, Cloud Resource Manager API 메타데이터, Cloud Billing 데이터 또는 소량의 로그를 내보내고 분석하려고 합니다.
- 이미 Splunk에서 하나 이상의 헤비 포워더를 관리하고 있습니다.
- 호스팅된 Splunk Cloud용 입력 데이터 관리자를 사용합니다.
또한 가져오기 기반 방법을 사용할 때 발생하는 추가 고려사항에 유의하세요.
- 단일 작업자가 데이터 수집 워크로드를 처리하며 자동 확장 기능을 제공하지 않습니다.
- Splunk에서 헤비 전달자를 사용하여 데이터를 가져오면 단일 장애점이 발생할 수 있습니다.
- 가져오기 기반 메서드를 사용하려면 Google Cloud용 Splunk 부가기능을 구성하는 데 사용하는 서비스 계정 키를 만들고 관리해야 합니다.
Splunk 부가기능을 사용하기 전에 먼저 로그 싱크를 사용하여 로그 항목을 Pub/Sub으로 라우팅해야 합니다. Pub/Sub 주제를 대상으로 하는 로그 싱크를 만들려면 싱크 만들기를 참조하세요.
Pub/Sub 주제 대상을 통해 싱크의 작성자 ID에 Pub/Sub 게시자 역할(roles/pubsub.publisher)을 부여해야 합니다. 싱크 대상 권한을 구성하는 방법은 대상 권한 설정을 참조하세요.
Splunk 부가기능을 사용 설정하려면 다음 단계를 따르세요.
- Splunk에서 Splunk 안내에 따라 Google Cloud용 Splunk 부가기능을 설치합니다.
- 로그가 라우팅되는 Pub/Sub 주제에 대한 Pub/Sub 풀(pull) 구독을 만듭니다(아직 없는 경우).
- 서비스 계정을 만듭니다.
- 방금 만든 서비스 계정의 서비스 계정 키를 만듭니다.
- 계정이 Pub/Sub 구독으로부터 메시지를 수신할 수 있도록 서비스 계정에 Pub/Sub 뷰어(
roles/pubsub.viewer) 및 Pub/Sub 구독자(roles/pubsub.subscriber) 역할을 부여합니다. Splunk에서 Splunk 안내에 따라 Google Cloud용 Splunk 부가기능에서 새 Pub/Sub 입력을 구성합니다.
로그 내보내기의 Pub/Sub 메시지가 Splunk에 표시됩니다.
부가기능이 작동하는지 확인하려면 다음 단계를 따르세요.
- Cloud Monitoring에서 측정항목 탐색기를 엽니다.
- 리소스 메뉴에서
pubsub_subscription을 선택합니다. - 측정항목 카테고리에서
pubsub/subscription/pull_message_operation_count를 선택합니다. - 1~2분 동안 메시지 가져오기 작업 수를 모니터링합니다.
설계 고려사항
다음 가이드라인은 보안, 개인정보 보호, 규정 준수, 운영 효율성, 안정성, 내결함성, 성능 및 비용 최적화에 대한 조직의 요구사항을 충족하는 아키텍처를 개발하는 데 도움이 될 수 있습니다.
보안, 개인 정보 보호, 규정 준수
다음 섹션에서는 이 참조 아키텍처의 보안 고려사항을 설명합니다.
- 비공개 IP 주소를 사용하여 Dataflow 파이프라인을 지원하는 VM 보호
- 비공개 Google 액세스 사용 설정
- Splunk HEC 인그레스 트래픽을 Cloud NAT에서 사용하는 알려진 IP 주소로 제한
- Secret Manager에 Splunk HEC 토큰 저장
- 최소 권한 권장사항을 따르도록 커스텀 Dataflow 작업자 서비스 계정 만들기
- 비공개 CA를 사용하는 경우 내부 루트 CA 인증서에 SSL 검증 구성
비공개 IP 주소를 사용하여 Dataflow 파이프라인을 지원하는 VM 보호
Dataflow 파이프라인에 사용되는 작업자 VM에 대한 액세스를 제한해야 합니다. 액세스를 제한하려면 이러한 VM을 비공개 IP 주소로 배포합니다. 하지만 이러한 VM은 HTTPS를 사용하여 내보낸 로그를 Splunk로 스트리밍하고 인터넷에 액세스할 수도 있어야 합니다. 이 HTTPS 액세스 권한을 제공하려면 Cloud NAT IP 주소를 이를 필요로 하는 VM에 자동으로 할당하는 Cloud NAT 게이트웨이가 필요합니다. VM이 포함된 서브넷을 Cloud NAT 게이트웨이에 매핑해야 합니다.
비공개 Google 액세스 사용 설정
Cloud NAT 게이트웨이를 만들면 비공개 Google 액세스가 자동으로 사용 설정됩니다. 하지만 비공개 IP 주소가 있는 Dataflow 작업자가 Google Cloud API 및 서비스가 사용하는 외부 IP 주소에 액세스할 수 있도록 하려면 서브넷에 비공개 Google 액세스를 수동으로 사용 설정해야 합니다.
Splunk HEC 인그레스 트래픽을 Cloud NAT에서 사용하는 알려진 IP 주소로 제한
Splunk HEC로 들어오는 트래픽을 알려진 IP 주소의 하위 집합으로 제한하려면 고정 IP 주소를 예약하여 Cloud NAT 게이트웨이에 수동으로 할당할 수 있습니다. 그런 다음 Splunk 배포에 따라 이러한 고정 IP 주소를 사용하여 Splunk HEC 인그레스 방화벽 규칙을 구성할 수 있습니다. Cloud NAT에 대한 자세한 내용은 Cloud NAT를 사용하여 네트워크 주소 변환 설정 및 관리를 참조하세요.
Secret Manager에 Splunk HEC 토큰 저장
Dataflow 파이프라인을 배포할 때 다음 방법 중 하나로 토큰 값을 전달할 수 있습니다.
- 일반 텍스트
- Cloud Key Management Service 키로 암호화된 암호문
- Secret Manager에서 암호화하고 관리하는 보안 비밀 버전
이 참조 아키텍처에서는 Secret Manager 옵션을 사용합니다. 이 옵션이 Splunk HEC 토큰을 보호하는 방법 중 가장 간단하고 효율적이기 때문입니다. 또한 이 옵션은 Dataflow 콘솔 또는 작업 세부정보에서 Splunk HEC 토큰이 유출되는 것을 방지합니다.
Secret Manager의 보안 비밀에는 보안 비밀 버전 모음이 포함됩니다. 각 보안 비밀 버전은 Splunk HEC 토큰과 같은 실제 보안 비밀 데이터를 저장합니다. 나중에 보안 강화를 위해 Splunk HEC 토큰을 순환하도록 선택한 경우 새 토큰을 이 보안 비밀에 새 보안 비밀 버전으로 추가할 수 있습니다. 보안 비밀 순환에 대한 일반적인 내용은 순환 일정 정보를 참조하세요.
최소 권한 권장사항을 따르도록 커스텀 Dataflow 작업자 서비스 계정 만들기
Dataflow 파이프라인의 작업자는 Dataflow 작업자 서비스 계정을 사용하여 리소스에 액세스하고 작업을 실행합니다. 기본적으로 작업자는 프로젝트의 Compute Engine 기본 서비스 계정을 작업자 서비스 계정으로 사용합니다. 이 계정은 프로젝트의 모든 리소스에 대한 광범위한 권한을 부여합니다. 하지만 프로덕션에서 Dataflow 작업을 실행하려면 최소한의 역할 및 권한 집합이 있는 커스텀 서비스 계정을 만드는 것이 좋습니다. 그런 다음 이 커스텀 서비스 계정을 Dataflow 파이프라인 작업자에게 할당할 수 있습니다.
다음 다이어그램은 Dataflow 작업자가 Dataflow 작업을 성공적으로 실행하려면 서비스 계정에 할당해야 하는 역할입니다.
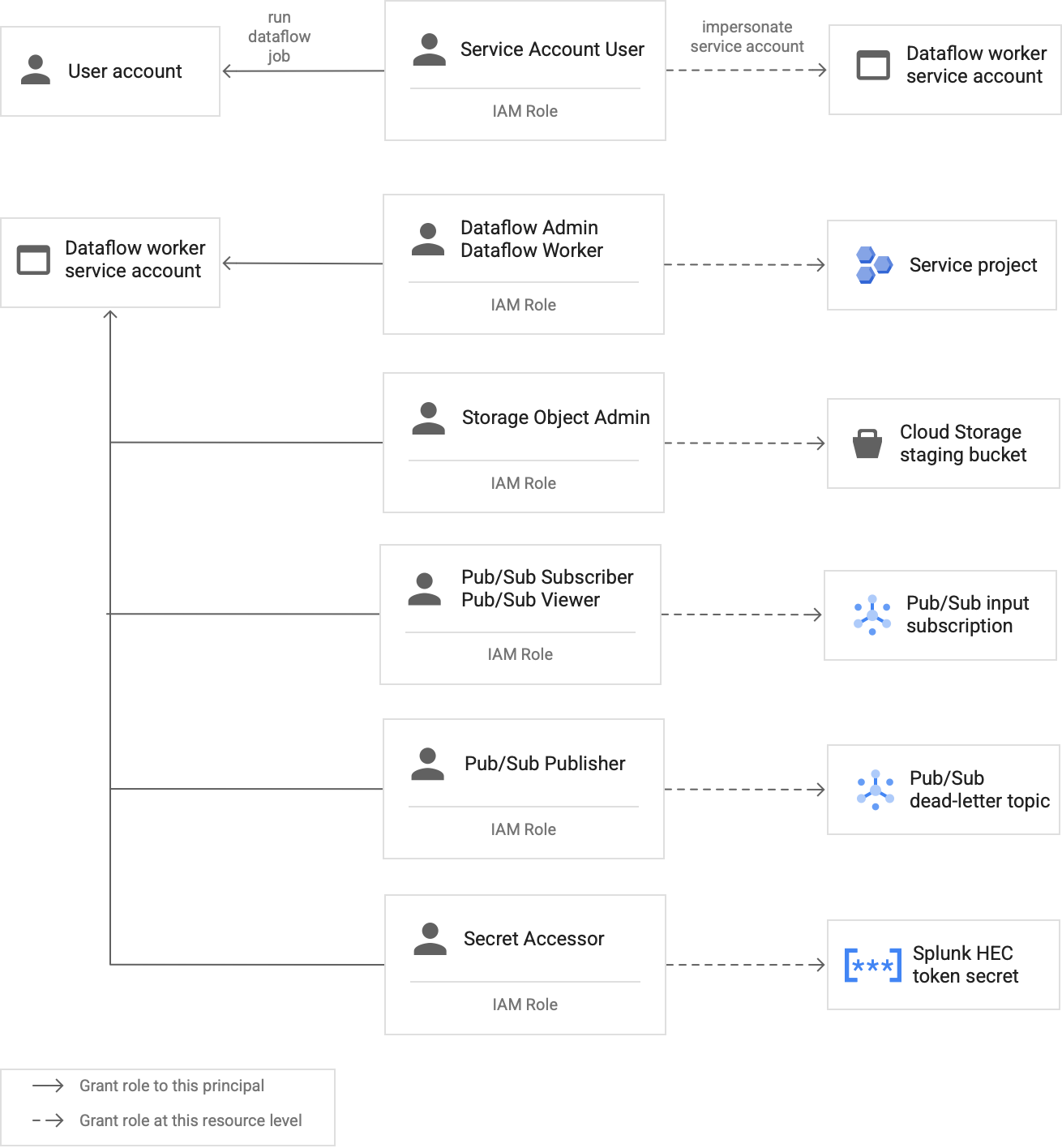
다이어그램에 표시된 대로 Dataflow 작업자의 서비스 계정에 다음 역할을 할당해야 합니다.
- Dataflow 관리자
- Dataflow 작업자
- 스토리지 객체 관리자
- Pub/Sub 구독자
- Pub/Sub 뷰어
- Pub/Sub 게시자
- 보안 비밀 접근자
비공개 CA를 사용하는 경우 내부 루트 CA 인증서에 SSL 검증 구성
기본적으로 Dataflow 파이프라인은 Dataflow 작업자의 기본 트러스트 저장소를 사용하여 Splunk HEC 엔드포인트의 SSL 인증서를 검증합니다. 비공개 인증 기관(CA)을 사용하여 Splunk HEC 엔드포인트에서 사용하는 SSL 인증서에 서명하는 경우 내부 루트 CA 인증서를 트러스트 저장소로 가져올 수 있습니다. 그런 다음 Dataflow 작업자가 가져온 인증서를 SSL 인증서 검증에 사용할 수 있습니다.
자체 서명된 인증서 또는 비공개 서명된 인증서가 있는 Splunk 배포에 자체 내부 루트 CA 인증서를 사용하고 가져올 수 있습니다. 내부 개발 및 테스트 목적에 한해 SSL 검증을 완전히 중지할 수도 있습니다. 이 내부 루트 CA 방법은 인터넷 연결이 아닌 내부 Splunk 배포에 가장 적합합니다.
자세한 내용은 Pub/Sub to Splunk Dataflow 템플릿 매개변수
rootCaCertificatePath 및 disableCertificateValidation을 참조하세요.
운영 효율성
다음 섹션에서는 이 참조 아키텍처의 운영 효율성 고려사항을 설명합니다.
UDF를 사용하여 진행 중인 로그 또는 이벤트 변환
Pub/Sub to Splunk Dataflow 템플릿은 커스텀 이벤트 변환을 위한 사용자 정의 함수(UDF)를 지원합니다. 사용 사례로는 추가 필드를 사용한 레코드 보강, 일부 민감한 필드 수정, 원치 않는 레코드 필터링 등이 있습니다. UDF를 사용하면 템플릿 코드 자체를 다시 컴파일하거나 유지하지 않고도 Dataflow 파이프라인의 출력 형식을 변경할 수 있습니다. 이 참조 아키텍처에서는 UDF를 사용하여 파이프라인이 Splunk에 전송할 수 없는 메시지를 처리합니다.
처리되지 않은 메시지 재생
파이프라인이 전송 오류를 수신하고 메시지를 다시 전송하려고 시도하지 않을 때가 간혹 있습니다. 이 경우 다음 다이어그램과 같이 Dataflow에서 처리되지 않은 메시지를 처리되지 않은 주제로 전송합니다. 전송 실패의 근본 원인을 해결한 후 처리되지 않은 메시지를 재생할 수 있습니다.
다음 단계는 이전 다이어그램에 표시된 프로세스를 간략히 보여줍니다.
- 사용자 조사를 위해 Pub/Sub에서 Splunk로의 기본 전송 파이프라인에서 전달할 수 없는 메시지를 처리되지 않은 주제로 자동으로 전달합니다.
운영자 또는 사이트 안정성 엔지니어(SRE)가 처리되지 않은 구독에서 실패한 메시지를 조사합니다. 운영자가 전송 실패의 근본 원인을 해결합니다. 예를 들어 HEC 토큰 구성 오류를 수정하면 메시지가 전송될 수 있습니다.
운영자가 재생 실패 메시지 파이프라인을 트리거합니다. 이 Pub/Sub to Pub/Sub 파이프라인(앞의 다이어그램에서 점선으로 표시된 섹션)은 실패한 메시지를 처리되지 않은 구독에서 원래 로그 싱크 주제로 다시 이동하는 임시 파이프라인입니다.
기본 전송 파이프라인이 이전에 실패한 메시지를 다시 처리합니다. 이 단계를 수행하려면 파이프라인이 UDF를 사용하여 실패한 메시지 페이로드를 올바르게 감지하고 디코딩해야 합니다. 다음 코드는 추적 목적의 전송 시도 집계를 포함하여 이 조건부 디코딩 로직을 구현하는 함수의 예시입니다.
// If the message has already been converted to a Splunk HEC object // with a stringified obj.event JSON payload, then it's a replay of // a previously failed delivery. // Unnest and parse the obj.event. Drop the previously injected // obj.attributes such as errorMessage and timestamp if (obj.event) { try { event = JSON.parse(obj.event); redelivery = true; } catch(e) { event = obj; } } else { event = obj; } // Keep a tally of delivery attempts event.delivery_attempt = event.delivery_attempt || 1; if (redelivery) { event.delivery_attempt += 1; }
안정성 및 내결함성
표 1에는 안정성과 내결함성과 관련된 몇 가지 Splunk 전송 오류가 나와 있습니다. 또한 이 표에는 처리되지 않은 주제에 메시지를 전달하기 전에 파이프라인이 각 메시지와 함께 기록하는 해당 errorMessage 속성이 나열되어 있습니다.
표 1: Splunk 전송 오류 유형
| 전송 오류 유형 | 파이프라인에서 자동 재시도 여부 | 예시 errorMessage 속성 |
|---|---|---|
일시적인 네트워크 오류 |
예 |
또는
|
Splunk 서버 5xx 오류 |
예 |
|
Splunk 서버 4xx 오류 |
아니요 |
|
Splunk 서버 중단 |
아니요 |
|
Splunk SSL 인증서가 잘못됨 |
아니요 |
|
사용자 정의 함수(UDF)의 자바스크립트 구문 오류 |
아니요 |
|
경우에 따라 파이프라인은 지수 백오프를 적용하고 메시지를 다시 전송하려고 자동으로 시도합니다. 예를 들어 Splunk 서버에서 5xx 오류 코드를 생성하면 파이프라인에서 메시지를 다시 전송해야 합니다. 이러한 오류 코드는 Splunk HEC 엔드포인트가 과부하될 때 발생합니다.
또는 HEC 엔드포인트에 메시지가 제출되지 못하도록 하는 지속적인 문제가 있을 수 있습니다. 이러한 지속적인 문제의 경우 파이프라인은 메시지를 다시 전송하려고 시도하지 않습니다. 다음은 지속적인 문제의 예시입니다.
- UDF 함수의 구문 오류
- Splunk 서버가
4xx'금지됨' 서버 응답을 생성하도록 하는 잘못된 HEC 토큰
성능 및 비용 최적화
성능 및 비용 최적화와 관련하여 Dataflow 파이프라인의 최대 크기와 처리량을 결정해야 합니다. 파이프라인이 업스트림 Pub/Sub 구독의 최대 일일 로그 볼륨(GB/일) 및 로그 메시지 속도(초당 이벤트 또는 EPS)를 처리할 수 있도록 올바른 크기 및 처리량 값을 계산해야 합니다.
시스템에 다음 문제 중 하나가 발생하지 않도록 크기 및 처리량 값을 선택해야 합니다.
- 메시지 백로그 또는 메시지 제한으로 인한 지연
- 파이프라인 초과 프로비저닝으로 인한 추가 비용
크기와 처리량을 계산한 후 그 결과를 사용하면 성능과 비용 간의 균형을 이루는 최적의 파이프라인을 구성할 수 있습니다. 파이프라인 용량을 구성하려면 다음 설정을 사용합니다.
- 머신 유형 및 머신 수 플래그는 Dataflow 작업을 배포하는 gcloud 명령어의 일부입니다. 이러한 플래그를 사용하면 사용할 VM의 유형과 수를 정의할 수 있습니다.
- 동시 로드 및 일괄 개수 매개변수는 Pub/Sub to Splunk Dataflow 템플릿의 일부입니다. 이러한 매개변수는 Splunk HEC 엔드포인트가 과부하되지 않도록 EPS를 높이는 데 중요합니다.
다음 섹션에서는 이러한 설정에 대해 설명합니다. 해당하는 경우 각 섹션에서는 수식과 각 수식을 사용하는 계산 예시도 제공합니다. 이 예시 계산 및 결과 값에서는 다음과 같은 특성을 가진 조직을 가정합니다.
- 매일 1TB의 로그를 생성합니다.
- 평균 메시지 크기는 1KB입니다.
- 지속 최대 메시지 속도는 평균 속도의 2배입니다.
Dataflow 환경은 고유하므로 단계를 진행할 때 예시 값을 조직의 값으로 대체하세요.
머신 유형
권장사항: --worker-machine-type 플래그를 n2-standard-4로 설정하여 최고의 성능 대비 비용 비율을 제공하는 머신 크기를 선택합니다.
n2-standard-4 머신 유형은 12,000개의 EPS를 처리할 수 있으므로 이 머신 유형을 모든 Dataflow 작업자의 기준으로 사용하는 것이 좋습니다.
이 참조 아키텍처의 경우 --worker-machine-type 플래그를 n2-standard-4 값으로 설정합니다.
머신 수
권장사항: --max-workers 플래그를 설정하여 예상되는 최대 EPS를 처리하는 데 필요한 최대 작업자 수를 제어합니다.
Dataflow 자동 확장을 사용하면 서비스에서 리소스 사용량 및 부하에 변경사항이 있을 때 스트리밍 파이프라인을 실행하는 데 사용되는 작업자 수를 적응적으로 변경할 수 있습니다. 자동 확장 시 초과 프로비저닝을 방지하려면 항상 Dataflow 작업자로 사용되는 최대 가상 머신 수를 정의하는 것이 좋습니다. Dataflow 파이프라인을 배포할 때 --max-workers 플래그를 사용하여 최대 가상 머신 수를 정의합니다.
Dataflow는 다음과 같이 스토리지 구성요소를 정적으로 프로비저닝합니다.
자동 확장 파이프라인은 데이터 영구 디스크를 잠재적인 스트리밍 작업자마다 하나씩 배포합니다. 기본 영구 디스크 크기는 400GB이며
--max-workers플래그를 사용하여 최대 작업자 수를 설정합니다. 이 디스크는 시작 시점을 포함하여 언제든지 실행 중인 작업자에 마운트됩니다.각 작업자 인스턴스는 영구 디스크 15개로 제한되므로 시작하는 작업자의 최소 개수는
⌈--max-workers/15⌉입니다. 따라서 기본값이--max-workers=20이면 파이프라인 사용량 및 비용은 다음과 같습니다.- 스토리지: 정적, 영구 디스크 20개
- 컴퓨팅: 동적, 작업자 인스턴스 최소 2개(⌈20/15⌉ = 2), 최대 20개
이 값은 8TB 영구 디스크와 같습니다. 디스크가 완전히 사용되지 않는 경우, 특히 대부분의 시간에 작업자 1~2개만 실행한다면 이 크기의 영구 디스크에서는 불필요한 비용이 발생할 수 있습니다.
파이프라인에 필요한 최대 작업자 수를 확인하려면 다음 수식을 순서대로 사용하세요.
다음 수식을 사용하여 초당 평균 이벤트 수(EPS)를 구합니다.
\( {AverageEventsPerSecond}\simeq\frac{TotalDailyLogsInTB}{AverageMessageSizeInKB}\times\frac{10^9}{24\times3600} \)계산 예시: 평균 메시지 크기가 1KB인 일일 로그 1TB를 예로 들면 이 수식으로 평균 EPS 값 11.5k EPS가 산출됩니다.
다음 수식을 사용하여 지속적인 최대 EPS를 구합니다. 여기서 승수 N은 로깅의 급격히 증가하는 특성을 나타냅니다.
\( {PeakEventsPerSecond = N \times\ AverageEventsPerSecond} \)계산 예시: N=2이고 이전 단계에서 계산한 평균 EPS 값 11.5k를 사용할 경우 이 수식으로 지속적 최대 EPS 값 23k EPS가 산출됩니다.
다음 수식을 사용하여 필요한 최대 vCPU 수를 구합니다.
\( {maxCPUs = ⌈PeakEventsPerSecond / 3k ⌉} \)계산 예시: 이전 단계에서 계산한 지속적 최대 EPS 값 23k를 사용할 경우 이 수식으로 ⌈23 / 3⌉ = 8개의 최대 vCPU 코어 수가 산출됩니다.
다음 수식을 사용하여 최대 Dataflow 작업자 수를 구합니다.
\( maxNumWorkers = ⌈maxCPUs / 4 ⌉ \)계산 예시: 이전 단계에서 계산한 최대 vCPU 값인 8을 사용할 경우 수식 [8/4]로
n2-standard-4머신 유형의 최대 개수 2개가 산출됩니다.
이 예시에서는 이전의 계산 예시를 토대로 --max-workers 플래그의 값을 2로 설정합니다. 그러나 사용자 환경에 이 참조 아키텍처를 배포할 때는 고유한 값과 계산을 사용해야 합니다.
동시 로드
권장사항: Pub/Sub to Splunk Dataflow 템플릿의 parallelism 매개변수를 최대 Dataflow 작업자 수에서 사용되는 vCPU 수의 두 배로 설정합니다.
parallelism 매개변수를 사용하면 동시 Splunk HEC 연결 수를 극대화하여 파이프라인의 EPS 속도를 극대화할 수 있습니다.
기본 1 값 parallelism은 동시 로드를 중지하고 출력 속도를 제한합니다. 배포된 최대 작업자 수를 포함하여 vCPU당 2~4개의 동시 연결을 고려하려면 이 기본 설정을 재정의해야 합니다. 일반적으로 이 설정의 재정의 값은 최대 Dataflow 작업자 수에 작업자당 vCPU 수를 곱하고 이 값을 2배로 계산하여 구합니다.
모든 Dataflow 작업자에서의 Splunk HEC에 대한 총 동시 연결 수를 구하려면 다음 수식을 사용합니다.
계산 예시: 이전에 머신 수에 대해 계산된 최대 vCPU 수 8개를 사용할 경우 이 수식으로 8 x 2 = 16개의 동시 연결 수가 산출됩니다.
이 예시에서는 이전의 계산 예시를 토대로 parallelism 매개변수의 값을 16으로 설정합니다. 그러나 사용자 환경에 이 참조 아키텍처를 배포할 때는 고유한 값과 계산을 사용해야 합니다.
일괄 개수
권장사항: Splunk HEC가 한 번에 하나씩이 아니라 일괄적으로 이벤트를 처리하도록 하려면 batchCount 매개변수를 로그에 대한 요청당 10~50개 사이의 값으로 설정합니다.
일괄 개수를 구성하면 EPS를 높이고 Splunk HEC 엔드포인트의 부하를 줄이는 데 도움이 됩니다. 이 설정에서는 보다 효율적인 처리를 위해 여러 이벤트를 단일 배치로 결합합니다. 최대 버퍼링 지연 시간으로 2초가 허용되는 경우 일반적으로 로그에 대한 이벤트당 요청 10~50개 사이의 값으로 batchCount 매개변수를 설정합니다.
이 예시에서는 평균 로그 메시지 크기가 1KB이므로 요청당 10개 이상의 이벤트를 일괄 처리하는 것이 좋습니다. 이 예시에서는 batchCount 매개변수의 값을 10으로 설정합니다. 그러나 사용자 환경에 이 참조 아키텍처를 배포할 때는 고유한 값과 계산을 사용해야 합니다.
이러한 성능 및 비용 최적화 추천에 대한 자세한 내용은 Dataflow 파이프라인 계획을 참조하세요.
다음 단계
- Pub/Sub to Splunk Dataflow 템플릿 매개변수의 전체 목록은 Pub/Sub to Splunk Dataflow 문서를 참조하세요.
- 이 참조 아키텍처를 배포하는 데 도움이 되는 해당 Terraform 템플릿은
terraform-splunk-log-exportGitHub 저장소를 참조하세요. 여기에는 Splunk Dataflow 파이프라인 모니터링을 위해 사전 빌드된 Cloud Monitoring 대시보드가 포함되어 있습니다. - Splunk Dataflow 파이프라인을 모니터링하고 문제를 해결하는 데 도움이 되는 Splunk Dataflow 커스텀 측정항목과 로깅에 대한 자세한 내용은 Splunk Dataflow 스트리밍 파이프라인을 위한 새로운 모니터링 가능성 기능 블로그를 참조하세요.
- 그 밖의 참조 아키텍처, 다이어그램, 튜토리얼, 권장사항을 알아보려면 Cloud 아키텍처 센터를 확인하세요.