En este documento se describe una arquitectura de referencia que te ayuda a crear un mecanismo de exportación de registros listo para producción, escalable, tolerante a fallos y que transmite registros y eventos de tus recursos en Google Cloud a Splunk. Splunk es una herramienta de analíticas popular que ofrece una plataforma unificada de seguridad y observabilidad. De hecho, puedes exportar los datos de registro a Splunk Enterprise o a Splunk Cloud Platform. Si eres administrador, también puedes usar esta arquitectura para casos prácticos de operaciones de TI o de seguridad.
Esta arquitectura de referencia presupone una jerarquía de recursos similar a la del siguiente diagrama. Todos los registros de recursos de los niveles de organización, carpeta y proyecto se recogen en un receptor agregado. Google Cloud A continuación, el sumidero agregado envía estos registros a una canalización de exportación de registros, que procesa los registros y los exporta a Splunk.

Arquitectura
En el siguiente diagrama se muestra la arquitectura de referencia que se usa al implementar esta solución. En este diagrama se muestra cómo fluyen los datos de registro deGoogle Cloud a Splunk.

Esta arquitectura incluye los siguientes componentes:
- Cloud Logging: para iniciar el proceso, Cloud Logging recoge los registros en un receptor de registros agregados a nivel de organización y los envía a Pub/Sub.
- Pub/Sub: el servicio Pub/Sub crea un único tema y una única suscripción para los registros y reenvía los registros al flujo de procesamiento de Dataflow principal.
- Dataflow: esta arquitectura de referencia incluye dos flujos de procesamiento de Dataflow:
- Flujo de procesamiento de Dataflow principal: en el centro del proceso, el flujo de procesamiento de Dataflow principal es un flujo de procesamiento de streaming de Pub/Sub a Splunk que extrae registros de la suscripción de Pub/Sub y los envía a Splunk.
- Flujo de procesamiento de Dataflow secundario: paralelo al flujo de procesamiento de Dataflow principal, el flujo de procesamiento de Dataflow secundario es un flujo de procesamiento de streaming de Pub/Sub a Pub/Sub que vuelve a reproducir los mensajes si se produce un error en la entrega.
- Splunk: al final del proceso, Splunk Enterprise o Splunk Cloud Platform actúan como un recopilador de eventos HTTP (HEC) y reciben los registros para analizarlos más a fondo. Puedes implementar Splunk de forma local, en Google Cloud como SaaS o mediante un enfoque híbrido.
Caso práctico
Esta arquitectura de referencia usa un enfoque basado en la nube y en las notificaciones push. En este método basado en push, se usa la plantilla de Dataflow de Pub/Sub a Splunk para transmitir registros a un recopilador de eventos HTTP (HEC) de Splunk. La arquitectura de referencia también aborda la planificación de la capacidad de la canalización de Dataflow y cómo gestionar posibles fallos de entrega cuando hay problemas transitorios en el servidor o en la red.
Aunque esta arquitectura de referencia se centra en los Google Cloud registros, la misma arquitectura se puede usar para exportar otros Google Cloud datos, como los cambios en los recursos y los resultados de seguridad en tiempo real. Al integrar los registros de Cloud Logging, puedes seguir usando servicios de partners como Splunk como solución unificada de analíticas de registros.
El método basado en push para transmitir Google Cloud datos a Splunk tiene las siguientes ventajas:
- Servicio gestionado. Como servicio gestionado, Dataflow mantiene los recursos necesarios en Google Cloud para tareas de procesamiento de datos, como la exportación de registros.
- Carga de trabajo distribuida. Este método te permite distribuir cargas de trabajo entre varios trabajadores para que se procesen en paralelo, de modo que no haya un único punto de fallo.
- Seguridad. Como Google Cloud envía tus datos a Splunk HEC, no tienes que preocuparte del mantenimiento ni de la seguridad que conlleva crear y gestionar claves de cuentas de servicio.
- Autoescalado. El servicio Dataflow autoescala el número de trabajadores en función de las variaciones en el volumen de registros entrantes y el trabajo pendiente.
- Tolerancia a fallos. Si hay problemas transitorios con el servidor o la red, el método basado en push intenta automáticamente volver a enviar los datos al HEC de Splunk. También admite temas sin procesar (también conocidos como temas de mensajes fallidos) para cualquier mensaje de registro que no se pueda entregar, de modo que se evite la pérdida de datos.
- Simplicidad. De esta forma, se evitan los gastos de gestión y el coste de ejecutar uno o varios heavy forwarders en Splunk.
Esta arquitectura de referencia se aplica a empresas de muchos sectores, incluidos los regulados, como el farmacéutico y el de servicios financieros. Si decides exportar tus Google Cloud datos a Splunk, puede que lo hagas por los siguientes motivos:
- Analíticas empresariales
- Operaciones de TI
- Monitorización del rendimiento de las aplicaciones
- Operaciones de seguridad
- Cumplimiento
Alternativas de diseño
Otro método para exportar registros a Splunk es extraerlos deGoogle Cloud. En este método basado en extracción, se usan APIs de Google Cloud para obtener los datos a través del complemento de Splunk para Google Cloud. Puedes usar el método basado en extracción en las siguientes situaciones:
- Tu implementación de Splunk no ofrece un endpoint HEC de Splunk.
- El volumen de los registros es bajo.
- Quieres exportar y analizar métricas de Cloud Monitoring, objetos de Cloud Storage, metadatos de la API de Cloud Resource Manager, datos de Cloud Billing o registros de poco volumen.
- Ya gestionas uno o varios heavy forwarders en Splunk.
- Usa el Gestor de datos de entradas alojado para Splunk Cloud.
Además, ten en cuenta las consideraciones adicionales que surgen al usar este método basado en la extracción:
- Un solo trabajador gestiona la carga de trabajo de ingesta de datos, que no ofrece funciones de autoescalado.
- En Splunk, el uso de un heavy forwarder para extraer datos puede provocar un único punto de fallo.
- El método basado en extracción requiere que crees y gestiones las claves de la cuenta de servicio que usas para configurar el complemento de Splunk para Google Cloud.
Antes de usar el complemento de Splunk, las entradas de registro deben enrutarse primero a Pub/Sub mediante un receptor de registro. Para crear un receptor de registro con un tema de Pub/Sub como destino, consulta Crear un receptor.
Asegúrate de conceder el rol de editor de Pub/Sub (roles/pubsub.publisher) a la identidad de escritura del receptor en ese destino del tema de Pub/Sub. Para obtener más información sobre cómo configurar los permisos de destino del receptor, consulta Definir permisos de destino.
Para habilitar el complemento de Splunk, sigue estos pasos:
- En Splunk, sigue las instrucciones de Splunk para instalar el complemento de Splunk para Google Cloud.
- Crea una suscripción de extracción de Pub/Sub para el tema de Pub/Sub al que se dirigen los registros, si aún no tienes una.
- Crear cuentas de servicio
- Crea una clave de cuenta de servicio para la cuenta de servicio que acabas de crear.
- Concede los roles Lector de Pub/Sub (
roles/pubsub.viewer) y Suscriptor de Pub/Sub (roles/pubsub.subscriber) a la cuenta de servicio para que pueda recibir mensajes de la suscripción de Pub/Sub. En Splunk, sigue las instrucciones para configurar una nueva entrada de Pub/Sub en el complemento de Splunk para Google Cloud.
Los mensajes de Pub/Sub de la exportación de registros aparecen en Splunk.
Para comprobar que el complemento funciona, sigue estos pasos:
- En Cloud Monitoring, abre Explorador de métricas.
- En el menú Recursos, selecciona
pubsub_subscription. - En las categorías de Métricas, seleccione
pubsub/subscription/pull_message_operation_count. - Monitoriza el número de operaciones de extracción de mensajes durante uno o dos minutos.
Factores del diseño
Las siguientes directrices pueden ayudarte a desarrollar una arquitectura que cumpla los requisitos de tu organización en cuanto a seguridad, privacidad, cumplimiento, eficiencia operativa, fiabilidad, tolerancia a fallos, rendimiento y optimización de costes.
Seguridad, privacidad y cumplimiento
En las siguientes secciones se describen las consideraciones de seguridad de esta arquitectura de referencia:
- Usar direcciones IP privadas para proteger las VMs que admiten la canalización de Dataflow
- Habilita el Acceso privado de Google
- Restringir el tráfico de entrada de Splunk HEC a las direcciones IP conocidas que utiliza Cloud NAT
- Almacenar el token HEC de Splunk en Secret Manager
- Crear una cuenta de servicio de trabajador de Dataflow personalizada para seguir las prácticas recomendadas de mínimos accesos
- Configurar la validación SSL para un certificado de AC raíz interno si usas una AC privada
Usar direcciones IP privadas para proteger las VMs que admiten la canalización de Dataflow
Debes restringir el acceso a las VMs de trabajador que se utilizan en la pipeline de Dataflow. Para restringir el acceso, implementa estas VMs con direcciones IP privadas. Sin embargo, estas VMs también deben poder usar HTTPS para transmitir los registros exportados a Splunk y acceder a Internet. Para proporcionar este acceso HTTPS, necesitas una pasarela Cloud NAT que asigne automáticamente direcciones IP de Cloud NAT a las VMs que las necesiten. Asegúrate de mapear la subred que contiene las VMs a la pasarela Cloud NAT.
Habilitar Acceso privado de Google
Cuando creas una pasarela Cloud NAT, el acceso privado a Google se habilita automáticamente. Sin embargo, para permitir que los trabajadores de Dataflow con direcciones IP privadas accedan a las direcciones IP externas que usan las APIs y los servicios de Google Cloud, también debes habilitar manualmente el acceso privado de Google en la subred.
Restringir el tráfico de entrada de Splunk HEC a direcciones IP conocidas que utiliza Cloud NAT
Si quieres restringir el tráfico a Splunk HEC a un subconjunto de direcciones IP conocidas, puedes reservar direcciones IP estáticas y asignarlas manualmente a la puerta de enlace Cloud NAT. En función de tu implementación de Splunk, puedes configurar las reglas de firewall de entrada de HEC de Splunk con estas direcciones IP estáticas. Para obtener más información sobre Cloud NAT, consulta el artículo Configurar y gestionar la traducción de direcciones de red con Cloud NAT.
Almacenar el token HEC de Splunk en Secret Manager
Cuando implementes la canalización de Dataflow, puedes transferir el valor del token de una de las siguientes formas:
- Texto sin formato
- Texto cifrado con una clave de Cloud Key Management Service
- Versión del secreto cifrada y gestionada por Secret Manager
En esta arquitectura de referencia, se usa la opción Secret Manager porque es la forma más sencilla y eficiente de proteger el token HEC de Splunk. Esta opción también evita que se filtre el token HEC de Splunk desde la consola de Dataflow o los detalles del trabajo.
Un secreto de Secret Manager contiene una colección de versiones de secreto. Cada versión de secreto almacena los datos del secreto, como el token HEC de Splunk. Si más adelante decide rotar su token HEC de Splunk como medida de seguridad adicional, puede añadir el nuevo token como una nueva versión secreta a este secreto. Para obtener información general sobre la rotación de secretos, consulta Acerca de las programaciones de rotación.
Crear una cuenta de servicio de trabajador de Dataflow personalizada para seguir las prácticas recomendadas de mínimos accesos
Los trabajadores de la canalización de Dataflow usan la cuenta de servicio de trabajador de Dataflow para acceder a los recursos y ejecutar operaciones. De forma predeterminada, los trabajadores usan la cuenta de servicio predeterminada de Compute Engine de tu proyecto como cuenta de servicio de trabajador, lo que les concede permisos amplios para todos los recursos de tu proyecto. Sin embargo, para ejecutar tareas de Dataflow en producción, te recomendamos que crees una cuenta de servicio personalizada con un conjunto mínimo de roles y permisos. Después, puedes asignar esta cuenta de servicio personalizada a los trabajadores de tu canalización de Dataflow.
En el siguiente diagrama se enumeran los roles necesarios que debes asignar a una cuenta de servicio para que los trabajadores de Dataflow puedan ejecutar una tarea de Dataflow correctamente.
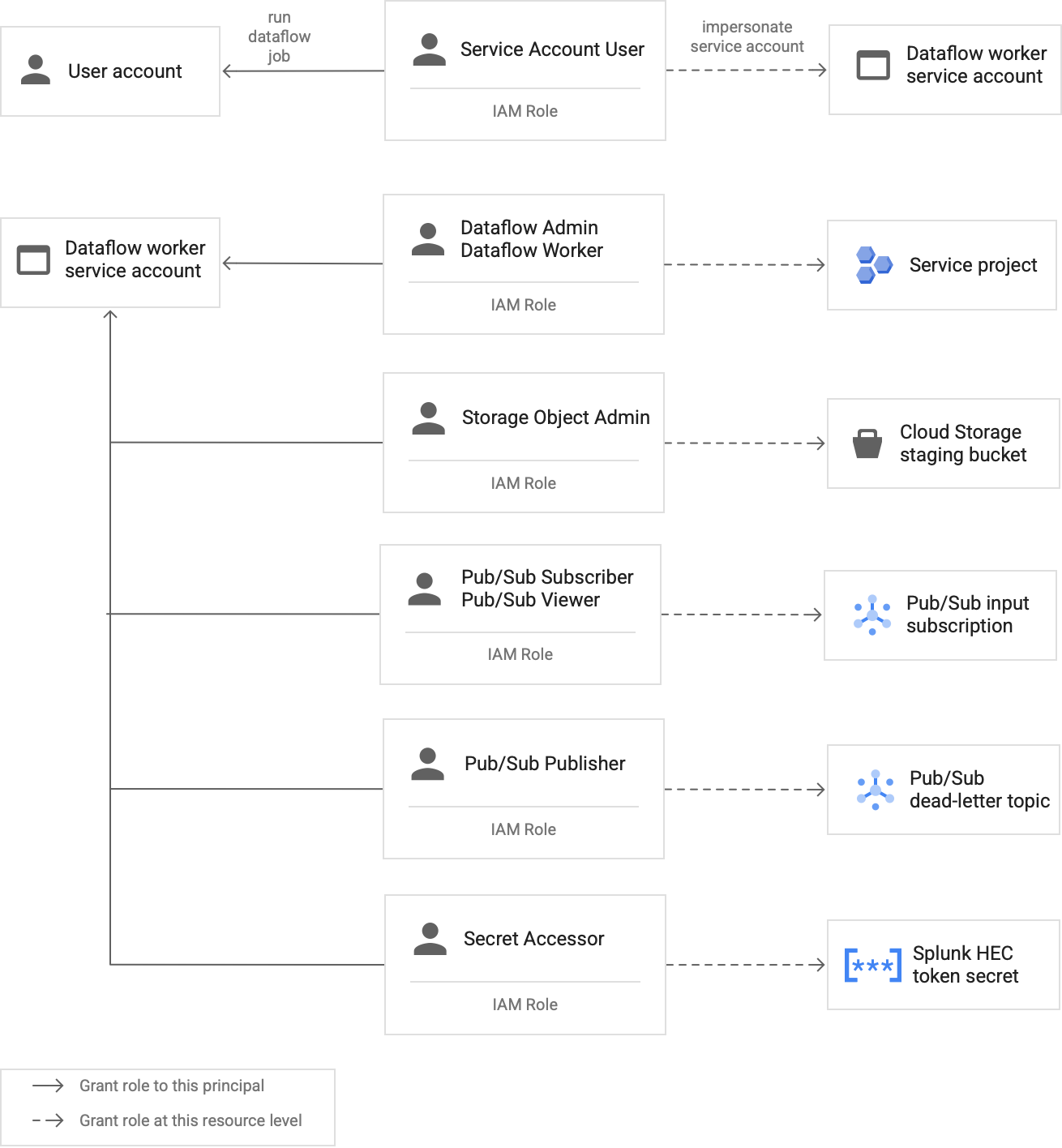
Como se muestra en el diagrama, debes asignar los siguientes roles a la cuenta de servicio de tu trabajador de Dataflow:
- Administrador de Dataflow
- Trabajador de Dataflow
- Administrador de objetos de Storage
- Suscriptor de Pub/Sub
- Lector de Pub/Sub
- Publicador de Pub/Sub
- Secret Accessor
Configurar la validación SSL con un certificado de AC raíz interno si usas una AC privada
De forma predeterminada, la canalización de Dataflow usa el almacén de confianza predeterminado del trabajador de Dataflow para validar el certificado SSL de tu endpoint de HEC de Splunk. Si usas una autoridad de certificación (CA) privada para firmar un certificado SSL que utiliza el endpoint HEC de Splunk, puedes importar tu certificado de CA raíz interno en el almacén de confianza. Los trabajadores de Dataflow pueden usar el certificado importado para validar el certificado SSL.
Puedes usar e importar tu propio certificado de CA raíz interno para las implementaciones de Splunk con certificados autofirmados o firmados de forma privada. También puedes inhabilitar la validación SSL por completo solo para fines de desarrollo y pruebas internos. Este método de CA raíz interna es el más adecuado para las implementaciones internas de Splunk que no están orientadas a Internet.
Para obtener más información, consulta los parámetros de la plantilla de Dataflow de Pub/Sub a Splunk
rootCaCertificatePath y disableCertificateValidation.
Eficiencia operativa
En las siguientes secciones se describen las consideraciones sobre la eficiencia operativa de esta arquitectura de referencia:
- Usar UDF para transformar registros o eventos en tiempo real
- Volver a reproducir mensajes no procesados
Usar una FDU para transformar registros o eventos en tiempo real
La plantilla de Dataflow de Pub/Sub a Splunk admite funciones definidas por el usuario (UDF) para la transformación de eventos personalizados. Entre los casos prácticos, se incluyen enriquecer registros con campos adicionales, ocultar algunos campos sensibles o filtrar registros no deseados. Las funciones definidas por el usuario te permiten cambiar el formato de salida de la canalización de Dataflow sin tener que volver a compilar ni mantener el código de la plantilla. Esta arquitectura de referencia usa una función definida por el usuario para gestionar los mensajes que la canalización no puede enviar a Splunk.
Volver a reproducir mensajes no procesados
A veces, la canalización recibe errores de entrega y no intenta entregar el mensaje de nuevo. En este caso, Dataflow envía estos mensajes sin procesar a un tema sin procesar, como se muestra en el siguiente diagrama. Una vez que hayas solucionado la causa principal del fallo en la entrega, podrás volver a enviar los mensajes no procesados.
En los siguientes pasos se describe el proceso que se muestra en el diagrama anterior:
- El flujo de procesamiento principal de Pub/Sub a Splunk reenvía automáticamente los mensajes que no se pueden entregar al tema sin procesar para que los usuarios puedan investigar.
El operador o el ingeniero de fiabilidad del sitio (SRE) investiga los mensajes fallidos en la suscripción no procesada. El operador soluciona el problema y corrige la causa raíz del fallo en la entrega. Por ejemplo, si corriges un error de configuración de un token de HEC, es posible que los mensajes se puedan enviar.
El operador activa el flujo de procesamiento de mensajes de error de reproducción. Esta canalización de Pub/Sub a Pub/Sub (destacada en la sección punteada del diagrama anterior) es una canalización temporal que mueve los mensajes fallidos de la suscripción no procesada al tema del sumidero de registro original.
La canalización de entrega principal vuelve a procesar los mensajes que no se han podido enviar anteriormente. Este paso requiere que la canalización use una UDF para detectar y decodificar correctamente las cargas útiles de los mensajes fallidos. El siguiente código es un ejemplo de función que implementa esta lógica de decodificación condicional, incluido un recuento de los intentos de entrega con fines de seguimiento:
// If the message has already been converted to a Splunk HEC object // with a stringified obj.event JSON payload, then it's a replay of // a previously failed delivery. // Unnest and parse the obj.event. Drop the previously injected // obj.attributes such as errorMessage and timestamp if (obj.event) { try { event = JSON.parse(obj.event); redelivery = true; } catch(e) { event = obj; } } else { event = obj; } // Keep a tally of delivery attempts event.delivery_attempt = event.delivery_attempt || 1; if (redelivery) { event.delivery_attempt += 1; }
Fiabilidad y tolerancia a fallos
En cuanto a la fiabilidad y la tolerancia a fallos, en la siguiente tabla (Tabla 1) se enumeran algunos posibles errores de entrega de Splunk. La tabla también muestra los atributos errorMessage correspondientes que la canalización registra con cada mensaje antes de reenviarlos al tema sin procesar.
Tabla 1: Tipos de errores de entrega de Splunk
| Tipo de error de entrega | ¿El flujo de trabajo vuelve a intentarlo automáticamente? | Ejemplo de atributo errorMessage |
|---|---|---|
Error de red transitorio |
Sí |
o
|
Error 5xx del servidor de Splunk |
Sí |
|
Error 4xx del servidor de Splunk |
No |
|
El servidor de Splunk está inactivo |
No |
|
Certificado SSL de Splunk no válido |
No |
|
Error de sintaxis de JavaScript en la función definida por el usuario (UDF) |
No |
|
En algunos casos, la canalización aplica un tiempo de espera exponencial e intenta entregar el mensaje de nuevo automáticamente. Por ejemplo, cuando el servidor de Splunk genera un código de error 5xx, la canalización debe volver a enviar el mensaje. Estos códigos de error se producen cuando el endpoint HEC de Splunk está sobrecargado.
También puede haber un problema persistente que impida que se envíe un mensaje al endpoint de HEC. En estos casos, la canalización no intenta entregar el mensaje de nuevo. Estos son algunos ejemplos de problemas persistentes:
- Un error de sintaxis en la función UDF
- Un token HEC no válido que provoca que el servidor Splunk genere una respuesta de servidor
4xx"Forbidden" (Prohibido).
Optimización de costes y rendimiento
En cuanto a la optimización del rendimiento y los costes, debes determinar el tamaño y el rendimiento máximos de tu flujo de procesamiento de Dataflow. Debe calcular los valores de tamaño y de rendimiento correctos para que su canalización pueda gestionar el volumen máximo de registros diarios (GB/día) y la tasa de mensajes de registro (eventos por segundo o EPS) de la suscripción de Pub/Sub upstream.
Debe seleccionar los valores de tamaño y de rendimiento para que el sistema no incurra en ninguno de los siguientes problemas:
- Retrasos causados por la acumulación o la limitación de mensajes.
- Costes adicionales por aprovisionar en exceso una canalización.
Una vez que hayas calculado el tamaño y el rendimiento, puedes usar los resultados para configurar una canalización óptima que equilibre el rendimiento y el coste. Para configurar la capacidad de la canalización, utiliza los siguientes ajustes:
- Las marcas Tipo de máquina y Número de máquinas forman parte del comando gcloud que implementa el trabajo de Dataflow. Estas marcas te permiten definir el tipo y el número de VMs que quieres usar.
- Los parámetros Paralelismo y Número de lotes forman parte de la plantilla de Dataflow de Pub/Sub a Splunk. Estos parámetros son importantes para aumentar el EPS y, al mismo tiempo, evitar que el endpoint HEC de Splunk se vea sobrecargado.
En las siguientes secciones se explica el significado de estos ajustes. Cuando corresponda, en estas secciones también se proporcionan fórmulas y ejemplos de cálculos que utilizan cada fórmula. En estos ejemplos de cálculos y valores resultantes se presupone una organización con las siguientes características:
- Genera 1 TB de registros al día.
- Tiene un tamaño medio de mensaje de 1 KB.
- Tiene una tasa máxima de mensajes sostenida que es el doble de la tasa media.
Como tu entorno de Dataflow es único, sustituye los valores de ejemplo por los de tu organización a medida que sigas los pasos.
Tipo de máquina
Práctica recomendada: define la marca --worker-machine-type como n2-standard-4 para seleccionar un tamaño de máquina que ofrezca la mejor relación entre rendimiento y coste.
Como el tipo de máquina n2-standard-4 puede gestionar 12.000 EPS, te recomendamos que lo utilices como base para todos tus trabajadores de Dataflow.
En esta arquitectura de referencia, asigna el valor n2-standard-4 a la marca --worker-machine-type.
Número de máquinas
Práctica recomendada: define la marca --max-workers para controlar el número máximo de trabajadores necesarios para gestionar el EPS máximo previsto.
El autoescalado de Dataflow permite que el servicio cambie de forma adaptativa el número de trabajadores que se usan para ejecutar tu canalización de streaming cuando hay cambios en el uso de recursos y la carga. Para evitar el aprovisionamiento excesivo al usar el autoescalado, te recomendamos que definas siempre el número máximo de máquinas virtuales que se utilizan como trabajadores de Dataflow. Puedes definir el número máximo de máquinas virtuales con la marca --max-workers al desplegar la canalización de Dataflow.
Dataflow aprovisiona estáticamente el componente de almacenamiento de la siguiente manera:
Un flujo de procesamiento con autoescalado implementa un disco persistente de datos por cada trabajador de streaming potencial. El tamaño predeterminado del disco persistente es de 400 GB y el número máximo de trabajadores se define con la marca
--max-workers. Los discos se montan en los trabajadores en ejecución en cualquier momento, incluido el inicio.Como cada instancia de trabajador está limitada a 15 discos persistentes, el número mínimo de trabajadores iniciales es
⌈--max-workers/15⌉. Por lo tanto, si el valor predeterminado es--max-workers=20, el uso de la canalización (y el coste) será el siguiente:- Almacenamiento: estático con 20 discos persistentes.
- Computación: dinámica con un mínimo de 2 instancias de trabajador (⌈20/15⌉ = 2) y un máximo de 20.
Este valor equivale a 8 TB de un disco persistente. Este tamaño de disco persistente puede generar costes innecesarios si los discos no se utilizan por completo, sobre todo si solo se ejecutan uno o dos trabajadores la mayor parte del tiempo.
Para determinar el número máximo de trabajadores que necesitas para tu canalización, usa las siguientes fórmulas en secuencia:
Determina el promedio de eventos por segundo (EPS) mediante la siguiente fórmula:
\( {AverageEventsPerSecond}\simeq\frac{TotalDailyLogsInTB}{AverageMessageSizeInKB}\times\frac{10^9}{24\times3600} \)Cálculo de ejemplo: con los valores de ejemplo de 1 TB de registros al día con un tamaño medio de mensaje de 1 KB, esta fórmula genera un valor medio de EPS de 11,5 K EPS.
Para determinar el EPS máximo sostenido, usa la siguiente fórmula, donde el multiplicador N representa la naturaleza de ráfaga del registro:
\( {PeakEventsPerSecond = N \times\ AverageEventsPerSecond} \)Cálculo de ejemplo: si el valor de N es 2 y el valor medio de EPS es de 11,5 k, como hemos calculado en el paso anterior, esta fórmula genera un valor de EPS máximo sostenido de 23 k.
Determina el número máximo de vCPUs necesarias con la siguiente fórmula:
\( {maxCPUs = ⌈PeakEventsPerSecond / 3k ⌉} \)Cálculo de ejemplo: con el valor de EPS máximo sostenido de 23.000 que has calculado en el paso anterior, esta fórmula genera un máximo de ⌈23 / 3⌉ = 8 núcleos de vCPU.
Para determinar el número máximo de trabajadores de Dataflow, usa la siguiente fórmula:
\( maxNumWorkers = ⌈maxCPUs / 4 ⌉ \)Cálculo de ejemplo: si se usa el valor máximo de vCPUs de 8 que se ha calculado en el paso anterior, esta fórmula [8/4] genera un número máximo de 2 para un tipo de máquina
n2-standard-4.
En este ejemplo, asignarías el valor 2 a la marca --max-workers
en función del conjunto de cálculos de ejemplo anterior. Sin embargo, recuerda que debes usar tus propios valores y cálculos únicos cuando implementes esta arquitectura de referencia en tu entorno.
Paralelismo
Práctica recomendada: define el parámetro parallelism en la plantilla de Dataflow de Pub/Sub a Splunk como el doble del número de vCPUs que utiliza el número máximo de trabajadores de Dataflow.
El parámetro parallelism ayuda a maximizar el número de conexiones paralelas de Splunk HEC, lo que a su vez maximiza la tasa de EPS de tu canalización.
El valor predeterminado parallelism de 1 inhabilita el paralelismo y limita la velocidad de salida. Debes anular este ajuste predeterminado para tener en cuenta entre 2 y 4 conexiones paralelas por vCPU, con el número máximo de trabajadores implementados. Por lo general, para calcular el valor de anulación de este ajuste, se multiplica el número máximo de trabajadores de Dataflow por el número de vCPUs por trabajador y, a continuación, se duplica este valor.
Para determinar el número total de conexiones paralelas al HEC de Splunk en todos los trabajadores de Dataflow, usa la siguiente fórmula:
Cálculo de ejemplo: si se utiliza el número máximo de vCPUs del ejemplo anterior (8), esta fórmula genera el número de conexiones paralelas, que es 8 × 2 = 16.
En este ejemplo, asignarías al parámetro parallelism el valor 16
según el cálculo del ejemplo anterior. Sin embargo, recuerda que debes usar tus propios valores y cálculos únicos cuando implementes esta arquitectura de referencia en tu entorno.
Recuento de lotes
Práctica recomendada: Para permitir que Splunk HEC procese los eventos en lotes en lugar de uno a la vez, asigne al parámetro batchCount un valor de entre 10 y 50 eventos por solicitud de registros.
Configurar el recuento de lotes ayuda a aumentar el EPS y a reducir la carga en el endpoint HEC de Splunk. Este ajuste combina varios eventos en un solo lote para que el procesamiento sea más eficiente. Te recomendamos que asignes al parámetro batchCount
un valor de entre 10 y 50 eventos por solicitud de registros, siempre que aceptes el retraso máximo de almacenamiento en búfer de dos segundos.
Como el tamaño medio de los mensajes de registro es de 1 KB en este ejemplo, le recomendamos que cree lotes de al menos 10 eventos por solicitud. En este ejemplo, asignarías el valor 10 al parámetro batchCount. Sin embargo, recuerda que debes usar tus propios valores y cálculos únicos cuando implementes esta arquitectura de referencia en tu entorno.
Para obtener más información sobre estas recomendaciones de optimización del rendimiento y los costes, consulta el artículo Planificar una canalización de Dataflow.
Siguientes pasos
- Para ver una lista completa de los parámetros de la plantilla de Dataflow de Pub/Sub a Splunk, consulta la documentación de Dataflow de Pub/Sub a Splunk.
- Para ver las plantillas de Terraform correspondientes que te ayudarán a implementar esta arquitectura de referencia, consulta el repositorio de GitHub
terraform-splunk-log-export. Incluye un panel de control de Cloud Monitoring prediseñado para monitorizar tu canalización de Splunk Dataflow. - Para obtener más información sobre las métricas personalizadas de Splunk Dataflow y el registro que te ayudarán a monitorizar y solucionar problemas en tus pipelines de streaming de Splunk Dataflow, consulta esta entrada del blog: Nuevas funciones de observabilidad para tus pipelines de streaming de Splunk Dataflow.
- Para ver más arquitecturas de referencia, diagramas y prácticas recomendadas, consulta el centro de arquitectura de Cloud.