Este documento es la tercera parte de una serie en la que se trata la recuperación ante desastres (DR) en Google Cloud. En esta parte, se analizan las situaciones para crear copias de seguridad y recuperar datos.
La serie consta de estas partes:
- Guía de planificación para la recuperación ante desastres
- Componentes básicos de la recuperación ante desastres
- Situaciones de recuperación ante desastres para datos (este documento)
- Situaciones de recuperación ante desastres para aplicaciones
- Arquitectura de recuperación ante desastres para cargas de trabajo con restricciones de localidad
- Casos de uso de recuperación ante desastres: aplicaciones de análisis de datos con restricciones de localidad
- Arquitectura de recuperación ante desastres para interrupciones de infraestructura de nube
Introducción
En tus planes de recuperación ante desastres se debe especificar cómo puedes evitar la pérdida de datos durante un desastre. Aquí, el término datos incluye dos situaciones. La creación de copias de seguridad y la recuperación de bases de datos, los datos de registro y otros tipos de datos se adecúan a una de las siguientes situaciones:
- Copias de seguridad de datos. La copia de seguridad de datos implica copiar una cantidad específica de datos de un lugar a otro. Las copias de seguridad se realizan como parte de un plan de recuperación para recuperarse de una corrupción de datos a fin de que puedas restablecer un estado óptimo conocido directamente en el entorno de producción. También se realizan para restablecer datos en el entorno de DR si el entorno de producción no funciona. Por lo general, las copias de seguridad de datos tienen un valor de RTO de pequeño a mediano y un RPO pequeño.
- Copias de seguridad de bases de datos. Las copias de seguridad de bases de datos son un poco más complejas porque, por lo general, implican la recuperación hasta el momento. Por lo tanto, debes considerar cómo crear una copia de seguridad de las copias de seguridad de la base de datos y cómo restablecerlas, y asegurarte de que el sistema de recuperación de la base de datos duplique la configuración de producción (misma versión y configuración duplicada del disco). También debes considerar cómo crear copias de seguridad de los registros de transacciones. Durante la recuperación, después de restablecer la funcionalidad de la base de datos, debes aplicar la última copia de seguridad de la base de datos y, luego, los registros de transacciones restablecidos de los que se creó una copia de seguridad después de la última copia de seguridad. Debido a los factores que complican los sistemas de bases de datos (por ejemplo, tener que hacer coincidir las versiones entre los sistemas de producción y recuperación), adoptar un enfoque de alta disponibilidad primero para minimizar el tiempo de recuperación de una situación que podría causar la falta de disponibilidad del servidor de la base de datos te permite lograr valores de RTO y RPO más pequeños.
Cuando ejecutas cargas de trabajo de producción en Google Cloud, puedes usar un sistema distribuido a nivel global para que, si ocurre algún error en una región, la aplicación continúe prestando servicio, incluso si se reduce su disponibilidad. En definitiva, la aplicación invoca su plan de recuperación ante desastres.
En el resto de este documento, se analizan ejemplos de cómo diseñar algunas situaciones para datos y bases de datos que pueden ayudarte a alcanzar tus objetivos de RTO y RPO.
El entorno de producción es local
En esta situación, el entorno de producción es local y el plan de recuperación ante desastres implica el uso de Google Cloud como el sitio de recuperación.
Copia de seguridad y recuperación de datos
Puedes usar varias estrategias para implementar un proceso en el que se creen copias de seguridad de datos con regularidad de forma local en Google Cloud. En esta sección, se analizan dos de las soluciones más comunes.
Solución 1: crea una copia de seguridad en Cloud Storage con una tarea programada
Este patrón usa los siguientes componentes básicos de DR:
- Cloud Storage
Una opción para crear una copia de seguridad de los datos es generar una tarea programada que ejecute una secuencia de comandos o una aplicación que transfiera los datos a Cloud Storage. Puedes automatizar un proceso de copia de seguridad en Cloud Storage con el comando gcloud storage de Google Cloud CLI o con una de las bibliotecas cliente de Cloud Storage.
Por ejemplo, el siguiente comando de gcloud storage copia todos los archivos de un directorio de origen a un bucket específico.
gcloud storage cp -r SOURCE_DIRECTORY gs://BUCKET_NAME
Reemplaza SOURCE_DIRECTORY por la ruta de acceso a tu directorio del código fuente y BUCKET_NAME por el nombre que elijas para el bucket.
El nombre debe cumplir con los requisitos de nombres de buckets.
En los siguientes pasos, se describe cómo implementar un proceso de copia de seguridad y recuperación con el comando gcloud storage.
- Instala
gcloud CLIen la máquina local que usas para subir tus archivos de datos. - Crea un bucket como destino de la copia de seguridad de los datos.
- Crea una cuenta de servicio.
- Crea una política de IAM para restringir quién puede acceder al bucket y sus objetos. Incluye la cuenta de servicio creada específicamente para este propósito. Si quieres obtener detalles sobre los permisos de acceso a Cloud Storage, consulta Permisos de IAM para
gcloud storage. - Usa la suplantación de identidad de la cuenta de servicio para proporcionar acceso a tu usuario local Google Cloud(o cuenta de servicio) para suplantar la identidad de la cuenta de servicio que acabas de crear. Como alternativa, puedes crear un usuario nuevo específicamente para este propósito.
- Comprueba que puedes subir y descargar archivos en el bucket de destino.
- Configura un programa para la secuencia de comandos que usas para subir tus copias de seguridad con herramientas como
crontabde Linux y el Programador de tareas de Windows. - Configura un proceso de recuperación que use el comando
gcloud storagepara recuperar tus datos en el entorno de recuperación de DR en Google Cloud.
También puedes usar el comando gcloud storage rsync para realizar sincronizaciones incrementales en tiempo real entre tus datos y un bucket de Cloud Storage.
Por ejemplo, el siguiente comando gcloud storage rsync hace que el contenido de un bucket de Cloud Storage sea el mismo que el del directorio del código fuente copiando los archivos u objetos faltantes, o aquellos cuyos datos cambiaron. Si el volumen de datos que cambió entre las sesiones sucesivas de copia de seguridad es pequeño en relación con el volumen completo de los datos de origen, usar gcloud storage rsync puede ser más eficaz que usar el comando gcloud storage cp. Si usas gcloud storage rsync, puedes implementar un programa de copia de seguridad más frecuente y lograr un RPO más bajo.
gcloud storage rsync -r SOURCE_DIRECTORY gs:// BUCKET_NAME
Para obtener más información, consulta el comando gcloud storage para transferencias de datos locales más pequeñas.
Solución 2: Crea una copia de seguridad en Cloud Storage mediante el servicio de transferencia de los datos locales
Este patrón usa los siguientes componentes básicos de DR:
- Cloud Storage
- Servicio de transferencia de los datos locales
La transferencia de grandes cantidades de datos en una red a menudo requiere una planificación cuidadosa y estrategias de ejecución sólidas. Desarrollar secuencias de comandos personalizadas que sean escalables, confiables y fáciles de mantener no es una tarea trivial. A menudo, las secuencias de comandos personalizadas pueden reducir los valores de RPO e incluso aumentar los riesgos de pérdida de datos.
Para obtener orientación sobre cómo mover grandes volúmenes de datos desde ubicaciones locales a Cloud Storage, consulta Traslada los datos al almacenamiento local o crea una copia de seguridad de ellos.
Solución 3: Crea una copia de seguridad en Cloud Storage mediante una solución de puerta de enlace de socios
Este patrón usa los siguientes componentes básicos de DR:
- Cloud Interconnect
- Almacenamiento en niveles de Cloud Storage
Las aplicaciones locales suelen integrarse a soluciones de terceros que pueden usarse como parte de la estrategia de copia de seguridad y recuperación de datos. En general, para las soluciones se usa un patrón de almacenamiento en niveles en el que se colocan las copias de seguridad más recientes en un almacenamiento más rápido y se migran con lentitud las copias de seguridad más antiguas a un almacenamiento más económico (más lento). Cuando usas Google Cloud como destino, tienes varias opciones de clase de almacenamiento disponibles para usar como equivalentes del nivel más lento.
Una forma de implementar este patrón es usar una puerta de enlace de socios entre tu almacenamiento local y Google Cloud para facilitar esta transferencia de datos a Cloud Storage. En el siguiente diagrama, se ilustra esta disposición, con una solución de socios que administra la transferencia desde el dispositivo NAS local o SAN.

En el caso de una falla, los datos de los que se está creando una copia de seguridad en ese momento deberán recuperarse en el entorno de DR. El entorno de DR se usa para entregar el tráfico de producción hasta que puedas volver al entorno de producción. La forma de lograrlo depende de la aplicación y de la solución del socio y su arquitectura. Algunas situaciones de extremo a extremo se analizan en el documento sobre DR en aplicaciones.
También puedes usar bases de datos Google Cloud administradas como destinos de DR. Por ejemplo, Cloud SQL para SQL Server admite la importación de registros de transacciones. Puedes exportar los registros de transacciones de tu instancia local de SQL Server, subirlos a Cloud Storage y, luego, importarlos a Cloud SQL para SQL Server.
Para obtener más información sobre cómo transferir datos de las instalaciones aGoogle Cloud, consulta Transfiere conjuntos de macrodatos a Google Cloud.
Para obtener más información sobre las soluciones de socios, consulta la página Socios en el sitio web de Google Cloud .
Copia de seguridad y recuperación de la base de datos
Puedes usar varias estrategias para implementar un proceso de recuperación de un sistema de base de datos local en Google Cloud. En esta sección, se analizan dos de las soluciones más comunes.
En este documento, no se analizan en detalle los diversos mecanismos integrados de copia de seguridad y recuperación que se incluyen en las bases de datos de terceros. En esta sección, se proporciona orientación general, que se implementa en las soluciones que se analizan aquí.
Solución 1: Copia de seguridad y recuperación con un servidor de recuperación en Google Cloud
- Crea una copia de seguridad de la base de datos mediante los mecanismos de copia de seguridad integrados del sistema de administración de bases de datos.
- Conecta tu red local y tu red de Google Cloud .
- Crea un bucket de Cloud Storage como destino para la copia de seguridad de tus datos.
- Copia los archivos de copia de seguridad en Cloud Storage con gcloud CLI
gcloud storageo una solución de puerta de enlace de socios (consulta los pasos que se explicaron antes en la sección de copia de seguridad y recuperación de datos). Para obtener más información, consulta Migra a Google Cloud: Transfiere tus conjuntos de datos grandes. - Copia los registros de transacciones en el sitio de recuperación en Google Cloud. Tener una copia de seguridad de los registros de transacciones ayuda a mantener los valores de RPO pequeños.
Después de configurar esta topología de copia de seguridad, debes asegurarte de poder recuperar el sistema que esté en Google Cloud. Por lo general, este paso implica restablecer el archivo de copia de seguridad en la base de datos de destino y, también, volver a reproducir los registros de transacciones para obtener el valor de RTO más pequeño. Una secuencia de recuperación típica incluye los siguientes pasos:
- Crea una imagen personalizada de tu servidor de base de datos en Google Cloud. El servidor de la base de datos debe tener la misma configuración en la imagen que el servidor de base de datos local.
- Implementa un proceso para copiar los archivos de copia de seguridad locales y los archivos de registro de transacciones en Cloud Storage. Consulta la Solución 1 para ver una implementación de ejemplo.
- Inicia una instancia de tamaño mínimo desde la imagen personalizada y conecta los discos persistentes que sean necesarios.
- Establece la marca de borrado automático en falso para los discos persistentes.
- Aplica el último archivo de copia de seguridad que se copió antes en Cloud Storage. Para ello, sigue las instrucciones del sistema de base de datos a fin de recuperar archivos de copia de seguridad.
- Aplica el último conjunto de archivos de registro de transacciones que se copió en Cloud Storage.
- Reemplaza la instancia mínima por una instancia más grande que pueda aceptar tráfico de producción.
- Cambia los clientes para que se orienten a la base de datos recuperada en Google Cloud.
Cuando tu entorno de producción se encuentra en ejecución y puede admitir cargas de trabajo de producción, debes revertir los pasos que seguiste para conmutar por error al entorno de recuperación deGoogle Cloud . En una secuencia típica para volver al entorno de producción, se siguen estos pasos:
- Toma una copia de seguridad de la base de datos que se ejecuta en Google Cloud.
- Copia el archivo de copia de seguridad en el entorno de producción.
- Aplica el archivo de copia de seguridad al sistema de base de datos de producción.
- Evita que los clientes se conecten al sistema de base de datos enGoogle Cloud; por ejemplo, deteniendo el servicio del sistema de base de datos. Desde este punto, la aplicación no estará disponible hasta que termines de restablecer el entorno de producción.
- Copia los archivos de registro de transacciones en el entorno de producción y aplícalos.
- Redirecciona las conexiones del cliente al entorno de producción.
Solución 2: Replicación a un servidor en espera en Google Cloud
Una forma de lograr valores de RTO y RPO muy pequeños es replicar los datos (no solo crear una copia de seguridad de ellos) y, en algunos casos, el estado de la base de datos en tiempo real a una réplica del servidor de la base de datos.
- Conecta tu red local y tu red de Google Cloud .
- Crea una imagen personalizada de tu servidor de base de datos en Google Cloud. El servidor de la base de datos debe tener la misma configuración en la imagen que el servidor de la base de datos local.
- Inicia una instancia desde la imagen personalizada y conecta los discos persistentes que sean necesarios.
- Establece la marca de borrado automático en falso para los discos persistentes.
- Configura la replicación entre el servidor de la base de datos local y el servidor de la base de datos de destino en Google Cloud siguiendo las instrucciones específicas del software de la base de datos.
- Los clientes se configuran en funcionamiento normal para que se orienten al servidor de la base de datos local.
Después de configurar esta topología de replicación, cambia los clientes para que se orienten al servidor en espera que se ejecuta en tu red de Google Cloud .
Cuando se crea una copia de seguridad del entorno de producción, y este puede admitir cargas de trabajo de producción, debes volver a sincronizar el servidor de la base de datos de producción con el servidor de la base de datos deGoogle Cloud y, luego, cambiar los clientes para que se orienten al entorno de producción.
El entorno de producción es Google Cloud
En esta situación, el entorno de producción y el de recuperación ante desastres se ejecutan en Google Cloud.
Copia de seguridad y recuperación de datos
Un patrón común para las copias de seguridad de datos es usar un patrón de almacenamiento en niveles. Cuando tu carga de trabajo de producción está en Google Cloud, el sistema de almacenamiento en niveles se parece al siguiente diagrama. Debes migrar los datos a un nivel que tiene costos de almacenamiento menores, porque es menos probable que necesites acceder a los datos de los que creaste una copia de seguridad.
Este patrón usa los siguientes componentes básicos de DR:
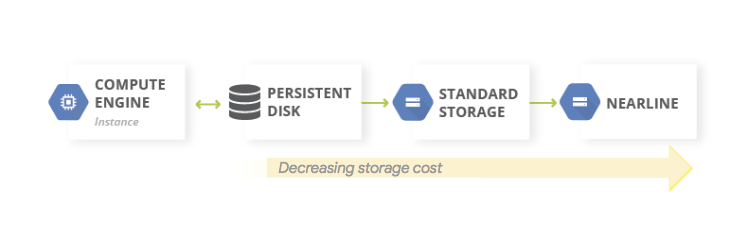
Debido a que las clases de almacenamiento Nearline, Coldline y Archive están destinadas a almacenar datos a los que se accede con poca frecuencia, hay costos adicionales asociados a la recuperación de datos o metadatos almacenados en estas clases, al igual que períodos mínimos de almacenamiento por los que se te cobra.
Copia de seguridad y recuperación de la base de datos
Cuando usas una base de datos autoadministrada (por ejemplo, si instalaste MySQL, PostgreSQL o SQL Server en una instancia de Compute Engine), los mismos problemas operativos se aplican a la administración de bases de datos de producción locales, pero ya no deberás administrar la infraestructura subyacente.
El servicio Backup and DR es una solución centralizada nativa de la nube para crear copias de seguridad y recuperar cargas de trabajo híbridas y en la nube. Ofrece una recuperación de datos rápida y facilita la reanudación veloz de las operaciones comerciales esenciales.
Para obtener más información sobre el uso de Backup and DR en situaciones de bases de datos autoadministradas en Google Cloud, consulta lo siguiente:
Como alternativa, puedes establecer las opciones de configuración de alta disponibilidad con las funciones de los componentes básicos de DR adecuadas para mantener el RTO pequeño. Puedes diseñar la configuración de tu base de datos para que sea factible recuperarla a un estado lo más cercano posible al estado anterior al desastre; esto ayuda a mantener los valores de RPO pequeños. Google Cloud proporciona una amplia variedad de opciones para esta situación.
En esta sección, se analizan dos enfoques comunes de diseño de la arquitectura de recuperación de bases de datos para bases de datos autoadministradas en Google Cloud .
Recupera un servidor de base de datos sin sincronizar de estado
Un patrón común es habilitar la recuperación de un servidor de la base de datos que no requiera que el estado del sistema esté sincronizado con una réplica de espera actualizada.
Este patrón usa los siguientes componentes básicos de DR:
- Compute Engine
- Grupos de instancias administrados
- Cloud Load Balancing (balanceo de cargas interno)
En el siguiente diagrama, se ilustra una arquitectura de ejemplo para abordar la situación. Si implementas esta arquitectura, tienes un plan de DR que reacciona de manera automática ante una falla sin requerir una recuperación manual.

En los siguientes pasos, se describe cómo configurar esta situación:
- Crea una red de VPC.
Para crear una imagen personalizada que se configure con el servidor de la base de datos, sigue estos pasos:
- Configura el servidor para que los archivos de la base de datos y los archivos de registro se escriban en un disco persistente estándar conectado.
- Crea una instantánea desde el disco persistente adjunto.
- Configura una secuencia de comandos de inicio para crear un disco persistente a partir de la instantánea y activar el disco.
- Crea una imagen personalizada del disco de arranque.
Crea una plantilla de instancias que use la imagen.
Con la plantilla de instancias, configura un grupo de instancias administrado con un tamaño de destino de 1.
Configura la verificación de estado con las métricas de Cloud Monitoring.
Configura el balanceo de cargas interno con el grupo de instancias administrado.
Configura una tarea programada para crear instantáneas normales del disco persistente.
En el caso de que se necesite una instancia de base de datos de reemplazo, esta configuración hará lo siguiente de manera automática:
- Abre otro servidor de la base de datos de la versión correcta en la misma zona.
- Conectará un disco persistente que tenga los últimos archivos de registro de transacciones y la copia de seguridad a la instancia del servidor de la base de datos recién creada.
- Minimizará la necesidad de volver a configurar los clientes que se comunican con el servidor de la base de datos en respuesta a un evento.
- Garantiza que los Google Cloud controles de seguridad (políticas de IAM y configuración de firewall) que se aplican al servidor de la base de datos de producción se apliquen al servidor de la base de datos recuperado.
Debido a que la instancia de reemplazo se crea a partir de una plantilla de instancias, los controles que se aplicaron a la original también se aplican a la instancia de reemplazo.
En esta situación, se aprovechan algunas de las características de la alta disponibilidad enGoogle Cloud. No es necesario que inicies ningún paso de la conmutación por error, ya que comenzarán de manera automática si ocurre un desastre. El balanceador de cargas interno garantiza que, incluso cuando se necesite una instancia de reemplazo, se use la misma dirección IP para el servidor de la base de datos. La plantilla de instancias y la imagen personalizada garantizan que la instancia de reemplazo esté configurada de manera idéntica a la instancia que reemplaza. Si tomas instantáneas con regularidad de los discos persistentes, te aseguras de que cuando los discos se vuelvan a crear a partir de las instantáneas y se conecten a la instancia de reemplazo, esta usará datos recuperados de acuerdo con un valor de RPO determinado por la frecuencia de las instantáneas. En esta arquitectura, los últimos archivos de registro de transacciones que se escribieron en el disco persistente también se restablecen de manera automática.
El grupo de instancias administrado proporciona alta disponibilidad en profundidad. Proporciona mecanismos para reaccionar ante fallas a nivel de la aplicación o instancia. Por lo tanto, no necesitas intervenir de manera manual si ocurre alguna de esas situaciones. La configuración de un tamaño de destino de uno garantiza que solo tengas una instancia activa que se ejecute en el grupo de instancias administrado y entregue tráfico.
Como los discos persistentes estándar son zonales, si hay una falla zonal, se requieren instantáneas para volver a crear los discos. Las instantáneas también están disponibles en todas las regiones, lo que te permite restablecer un disco no solo dentro de la misma región, sino también en una región diferente.
Una variación de esta configuración es usar discos persistentes regionales en lugar de discos persistentes estándar. En este caso, no necesitas restablecer la instantánea como parte del paso de recuperación.
El enfoque que elijas depende de tu presupuesto y los valores de RTO y RPO.
Recupérate de la corrupción parcial en bases de datos muy grandes
La replicación asíncrona de Persistent Disk ofrece replicación de almacenamiento en bloque con un RPO y un RTO bajos para la DR activa-pasiva entre regiones. Esta opción de almacenamiento te permite administrar la replicación de las cargas de trabajo de Compute Engine a nivel de la infraestructura, en lugar de a nivel de la carga de trabajo.
Si usas una base de datos que puede almacenar petabytes de datos, es posible que experimentes una interrupción que afecte a algunos de los datos, pero no a todos. En ese caso, se recomienda que minimices la cantidad de datos que deberás restablecer; no es necesario (o no es conveniente) recuperar la base de datos completa solo para restablecer algunos de los datos.
Puedes adoptar las siguientes estrategias de mitigación:
- Almacena los datos en tablas diferentes para períodos específicos. Este método garantiza que solo necesites restablecer un subconjunto de datos a una tabla nueva, en lugar de un conjunto de datos completo.
Almacena los datos originales en Cloud Storage. Este enfoque te permite crear una tabla nueva y volver a cargar los datos no dañados. Desde allí, puedes configurar las aplicaciones para que se orienten a la tabla nueva.
Además, si el RTO lo permite, puedes evitar el acceso a la tabla que tiene los datos dañados si dejas las aplicaciones sin conexión hasta que los datos no dañados se restablezcan a una tabla nueva.
Servicios de bases de datos administradas en Google Cloud
En esta sección, se describen algunos métodos que puedes usar a fin de implementar mecanismos adecuados de copia de seguridad y recuperación para los servicios de base de datos administradas enGoogle Cloud.
Las bases de datos administradas están diseñadas para el escalamiento, por lo que los mecanismos de copia de seguridad y restablecimiento tradicionales que se ven en los RDMBS tradicionales no suelen estar disponibles. Al igual que con las bases de datos autoadministradas, si usas una base de datos que puede almacenar petabytes de datos, se recomienda que minimices la cantidad de datos que debes restablecer en una situación de DR. Hay una serie de estrategias para cada base de datos administrada que te permiten lograr este objetivo.
Bigtable proporciona replicación de Bigtable. Una base de datos replicada de Bigtable puede proporcionar mayor disponibilidad que un solo clúster, capacidad de procesamiento de lectura adicional y mayor durabilidad y resiliencia ante fallas zonales o regionales.
Las copias de seguridad de Bigtable son un servicio completamente administrado que te permite guardar una copia del esquema y los datos de una tabla y, luego, restablecer la copia de seguridad en una nueva tabla más adelante.
También puedes exportar tablas desde Bigtable como una serie de archivos de secuencia de Hadoop. Luego, puedes almacenar estos archivos en Cloud Storage o usarlos para importar los datos en otra instancia de Bigtable. Puedes replicar tu conjunto de datos de Bigtable de manera asíncrona entre zonas dentro de una Google Cloud región.
BigQuery. Si deseas archivar datos, puedes aprovechar el almacenamiento a largo plazo de BigQuery. Si una tabla no se edita durante 90 días consecutivos, el precio de almacenamiento disminuye un 50 % de forma automática. El rendimiento, la durabilidad, la disponibilidad y otras funciones no disminuyen cuando una tabla se considera como almacenamiento a largo plazo. Sin embargo, si la tabla se edita, vuelve a los precios de almacenamiento normales y, la cuenta regresiva de 90 días vuelve a comenzar.
BigQuery se replica en dos zonas en una sola región, pero esto no ayudará con la corrupción de las tablas. Por lo tanto, debes tener un plan para poder recuperarte de esa situación. Por ejemplo, puedes hacer lo siguiente:
- Si el daño se detecta en un plazo de 7 días, consulta la tabla en un momento del pasado para recuperarla antes del daño mediante decoradores de instantáneas.
- Exporta los datos desde BigQuery y crea una tabla nueva que contenga los datos exportados, pero excluya los datos dañados.
- Almacena los datos en tablas diferentes para períodos específicos. Este método garantiza que solo necesites restablecer un subconjunto de datos a una tabla nueva, en lugar de un conjunto de datos completo.
- Crea copias de tu conjunto de datos en períodos específicos. Puedes usar estas copias si se produce un evento de corrupción de datos más allá de lo que puede capturar una consulta de un momento determinado (por ejemplo, hace más de 7 días). También puedes copiar un conjunto de datos de una región en otra para garantizar la disponibilidad de los datos en caso de que ocurran fallas en la región.
- Almacena los datos originales en Cloud Storage, lo que te permite crear una tabla nueva y volver a cargar los datos no dañados. Desde allí, puedes configurar las aplicaciones para que se orienten a la tabla nueva.
Firestore. El servicio de importación y exportación administrado te permite importar y exportar entidades de Firestore con un bucket de Cloud Storage. Luego, puedes implementar un proceso que se puede usar para recuperarte de una eliminación de datos accidental.
Cloud SQL. Si usas Cloud SQL, la base de datosGoogle Cloud MySQL completamente administrada, debes habilitar las copias de seguridad automáticas y el registro binario para tus instancias de Cloud SQL. Este enfoque te permite realizar una recuperación de un momento determinado, en la que se restablece la base de datos a partir de una copia de seguridad y se la recupera en una instancia de Cloud SQL nueva. Para obtener más información, consulta Acerca de las copias de seguridad de Cloud SQL y Acerca de la recuperación ante desastres (DR) en Cloud SQL.
También puedes configurar Cloud SQL en una configuración de HA y réplicas entre regiones para maximizar el tiempo de actividad en caso de una falla zonal o regional.
Si habilitaste el mantenimiento planificado con un tiempo de inactividad casi nulo para Cloud SQL, puedes evaluar el impacto de los eventos de mantenimiento en tus instancias simulando eventos de mantenimiento planificado con un tiempo de inactividad casi nulo en Cloud SQL para MySQL y en Cloud SQL para PostgreSQL.
En la edición Cloud SQL Enterprise Plus, puedes usar la recuperación ante desastres (DR) avanzada para simplificar los procesos de recuperación y resguardo sin pérdida de datos después de realizar una conmutación por error interregional.
Spanner. Puedes usar plantillas de Dataflow para realizar una exportación completa de tu base de datos a un conjunto de archivos Avro en un bucket de Cloud Storage y usar otra plantilla para volver a importar los archivos exportados a una base de datos de Spanner nueva.
En cuanto a las copias de seguridad más controladas, el conector de Dataflow te permite escribir un código para leer y escribir datos en Spanner en una canalización de Dataflow. Por ejemplo, puedes usar el conector para copiar datos fuera de Spanner y en Cloud Storage como destino de la copia de seguridad. La velocidad a la que se pueden realizar operaciones de lectura de los datos desde Spanner (o volver a realizar operaciones de escritura) depende de la cantidad de nodos configurados. Esto tiene un impacto directo en los valores de RTO.
La función de marca de tiempo de confirmación de Spanner puede ser útil para las copias de seguridad incrementales, ya que te permite seleccionar solo las filas que se agregaron o modificaron desde la última copia de seguridad completa.
Para las copias de seguridad administradas, Copia de seguridad y restablecimiento de Spanner te permite crear copias de seguridad coherentes que se pueden retener por hasta 1 año. El valor de RTO es menor en comparación con la exportación, ya que la operación de restablecimiento activa directamente la copia de seguridad sin copiar los datos.
A fin de obtener valores de RTO pequeños, podrías configurar una instancia de Spanner en espera semiactiva con la cantidad mínima de nodos necesarios para cumplir con tus requisitos de capacidad de procesamiento de lectura y escritura y de almacenamiento.
La recuperación de un momento determinado (PITR) de Spanner te permite recuperar datos de un momento específico en el pasado. Por ejemplo, si un operador escribe datos de forma inadvertida o el lanzamiento de una aplicación daña la base de datos, con la PITR, puedes recuperar los datos de un momento en el pasado, hasta un máximo de 7 días.
Cloud Composer. Puedes usar Cloud Composer (una versión administrada de Apache Airflow) para programar copias de seguridad regulares de varias bases de datos deGoogle Cloud . Puedes crear un grafo acíclico dirigido (DAG) que se ejecute en una programación (por ejemplo, a diario) a fin de copiar los datos en otro proyecto, conjunto de datos o tabla (según la solución usada), o para exportar los datos a Cloud Storage.
Puedes exportar o copiar datos mediante los distintos operadores de Cloud Platform.
Por ejemplo, puedes crear un DAG para que realice cualquiera de las siguientes acciones:
- Exportar una tabla de BigQuery a Cloud Storage mediante BigQueryToCloudStorageOperator
- Exportar Firestore en modo Datastore (Datastore) a Cloud Storage con DatastoreExportOperator
- Exportar tablas de MySQL a Cloud Storage mediante MySqlToGoogleCloudStorageOperator
- Exportar tablas de Postgres a Cloud Storage mediante PostgresToGoogleCloudStorageOperator
El entorno de producción es otra nube
En esta situación, el entorno de producción usa otro proveedor de servicios en la nube, y el plan de recuperación ante desastres implica el uso de Google Cloud como el sitio de recuperación.
Copia de seguridad y recuperación de datos
La transferencia de datos entre almacenamientos de objetos es un caso de uso común para las situaciones de DR. El Servicio de transferencia de almacenamiento es compatible con Amazon S3 y es el método recomendado para transferir objetos de Amazon S3 a Cloud Storage.
Puedes configurar un trabajo de transferencia para programar la sincronización periódica de la fuente de datos al receptor de datos, con filtros avanzados en función de las fechas de creación de los archivos, los filtros de nombres de los archivos y las horas del día en las que prefieres transferir datos. Para lograr el RPO que deseas, debes tener en cuenta los siguientes factores:
Frecuencia de cambio: Es la cantidad de datos que se generan o actualizan durante un período determinado. Cuanto más alta sea la frecuencia de cambio, se necesitarán más recursos para transferir los cambios al destino en cada período de transferencia incremental.
Rendimiento de la transferencia: Es el tiempo que lleva transferir archivos. Para las transferencias de archivos grandes, esto se suele determinar mediante el ancho de banda disponible entre la fuente y el destino. Sin embargo, si un trabajo de transferencia consta de una gran cantidad de archivos pequeños, las QPS pueden convertirse en un factor limitante. Si ese es el caso, puedes programar varios trabajos simultáneos para escalar el rendimiento siempre que haya suficiente ancho de banda disponible. Te recomendamos que midas el rendimiento de la transferencia mediante el uso de un subconjunto representativo de tus datos reales.
Frecuencia: Es el intervalo entre los trabajos de copia de seguridad. La actualidad de los datos en el destino es tan reciente como la última vez que se programó un trabajo de transferencia. Por lo tanto, es importante que los intervalos entre los trabajos de transferencia sucesivos no superen el objetivo de RPO. Por ejemplo, si el objetivo de RPO es de 1 día, el trabajo de transferencia debe programarse al menos una vez al día.
Supervisión y alertas: El Servicio de transferencia de almacenamiento proporciona notificaciones de Pub/Sub en una amplia variedad de eventos. Te recomendamos que te suscribas a estas notificaciones para controlar las fallas o los cambios inesperados en los tiempos de finalización de un trabajo.
Copia de seguridad y recuperación de la base de datos
En este documento, no se analizan en detalle los diversos mecanismos de copia de seguridad y recuperación integrados que se incluyen en las bases de datos de terceros o las técnicas de copia de seguridad y recuperación usadas en otros proveedores de servicios en la nube. Si usas bases de datos no administradas en los servicios de procesamiento, puedes aprovechar las instalaciones de alta disponibilidad que tu proveedor de servicios en la nube de producción tiene disponibles. Puedes ampliarlas para incorporar una implementación de alta disponibilidad en Google Cloud. También puedes usar Cloud Storage como el destino final para el almacenamiento en frío de los archivos de copia de seguridad de la base de datos.
Próximos pasos
- Obtén más información sobre Google Cloud geografía y regiones.
Lee otros documentos de esta serie sobre la DR:
- Guía de planificación para la recuperación ante desastres
- Componentes básicos para la recuperación ante desastres
- Situaciones de recuperación ante desastres para aplicaciones
- Arquitectura de recuperación ante desastres para cargas de trabajo con restricciones de localidad
- Casos de uso de recuperación ante desastres: aplicaciones de análisis de datos con restricciones de localidad
- Arquitectura de recuperación ante desastres para interrupciones de infraestructura de nube
- Arquitecturas para la alta disponibilidad de los clústeres de MySQL en Compute Engine
Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.