Este documento é a terceira parte de uma série que aborda a recuperação de desastres (RD) no Google Cloud. Esta parte aborda cenários de cópia de segurança e recuperação de dados.
A série é composta por estas partes:
- Guia de planeamento de recuperação de desastres
- Bases de recuperação de desastres
- Cenários de recuperação de desastres para dados (este documento)
- Cenários de recuperação de desastres para aplicações
- Arquitetar a recuperação de desastres para cargas de trabalho restritas por localidade
- Exemplos de utilização de recuperação de desastres: aplicações de estatísticas de dados restritas à localidade
- Criar arquiteturas de recuperação de desastres para interrupções da infraestrutura na nuvem
Introdução
Os seus planos de recuperação de desastres têm de especificar como pode evitar a perda de dados durante um desastre. O termo dados aqui abrange dois cenários. Fazer uma cópia de segurança e, em seguida, recuperar a base de dados, os dados de registo e outros tipos de dados enquadra-se num dos seguintes cenários:
- Cópias de segurança de dados. A cópia de segurança de dados envolve apenas a cópia de uma quantidade discreta de dados de um local para outro. As cópias de segurança são feitas como parte de um plano de recuperação para recuperar de uma corrupção de dados, de modo que possa restaurar para um estado bom conhecido diretamente no ambiente de produção, ou para que possa restaurar dados no seu ambiente de recuperação em caso de desastre se o seu ambiente de produção estiver inativo. Normalmente, as cópias de segurança de dados têm um RTO pequeno a médio e um RPO pequeno.
- Cópias de segurança da base de dados. As cópias de segurança da base de dados são ligeiramente mais complexas, porque normalmente envolvem a recuperação até ao momento específico. Por conseguinte, além de considerar como fazer uma cópia de segurança e restaurar as cópias de segurança da base de dados e garantir que o sistema de base de dados de recuperação reflete a configuração de produção (mesma versão, configuração de disco refletida), também tem de considerar como fazer uma cópia de segurança dos registos de transações. Durante a recuperação, depois de restaurar a funcionalidade da base de dados, tem de aplicar a cópia de segurança mais recente da base de dados e, em seguida, os registos de transações recuperados dos quais foi feita uma cópia de segurança após a última cópia de segurança. Devido aos fatores complexos inerentes aos sistemas de base de dados (por exemplo, ter de fazer corresponder as versões entre os sistemas de produção e de recuperação), a adoção de uma abordagem de prioridade à alta disponibilidade para minimizar o tempo de recuperação de uma situação que possa causar a indisponibilidade do servidor de base de dados permite-lhe alcançar valores de RTO e RPO mais pequenos.
Quando executa cargas de trabalho de produção no Google Cloud, pode usar um sistema distribuído globalmente para que, se algo correr mal numa região, a aplicação continue a fornecer serviço, mesmo que esteja menos disponível. Essencialmente, essa aplicação invoca o respetivo plano de recuperação de desastres.
O resto deste documento aborda exemplos de como criar alguns cenários para dados e bases de dados que podem ajudar a atingir os seus objetivos de RTO e RPO.
O ambiente de produção está nas instalações
Neste cenário, o seu ambiente de produção está no local e o seu plano de recuperação de desastres envolve a utilização do Google Cloud como o site de recuperação.
Cópias de segurança e recuperação de dados
Pode usar várias estratégias para implementar um processo de cópia de segurança regular dos dados locais para o Google Cloud. Esta secção analisa duas das soluções mais comuns.
Solução 1: faça uma cópia de segurança no Cloud Storage através de uma tarefa agendada
Este padrão usa as seguintes bases de dados de registos detalhados:
- Cloud Storage
Uma opção para fazer uma cópia de segurança dos dados é criar uma tarefa agendada que execute um script ou uma aplicação para transferir os dados para o Cloud Storage. Pode automatizar um processo de cópia de segurança para o Cloud Storage através do comando gcloud storage da CLI Google Cloud ou de uma das bibliotecas de cliente do Cloud Storage.
Por exemplo, o comando gcloud storage seguinte copia todos os ficheiros de um diretório de origem para um contentor especificado.
gcloud storage cp -r SOURCE_DIRECTORY gs://BUCKET_NAME
Substitua SOURCE_DIRECTORY pelo caminho para o diretório de origem
e BUCKET_NAME por um nome à sua escolha para o contentor.
O nome tem de cumprir os requisitos do nome do contentor.
Os passos seguintes descrevem como implementar um processo de cópia de segurança e recuperação
usando o comando gcloud storage.
- Instale o
gcloud CLIna máquina no local que usa para carregar os seus ficheiros de dados. - Crie um contentor como destino da sua cópia de segurança de dados.
- Crie uma conta de serviço.
- Crie uma política de IAM para restringir quem pode aceder ao contentor e aos respetivos objetos. Inclua a conta de serviço criada especificamente para este fim. Para ver detalhes sobre as autorizações
de acesso ao Cloud Storage, consulte o artigo Autorizações de IAM para
gcloud storage. - Use a representação da conta de serviço para conceder ao seu utilizador local Google Cloud(ou conta de serviço) a capacidade de representar a conta de serviço que criou anteriormente. Em alternativa, pode criar um novo utilizador especificamente para este fim.
- Teste se consegue carregar e transferir ficheiros no contentor de destino.
- Configure um horário para o script que usa para carregar as suas cópias de segurança através de ferramentas como o Linux
crontabe o Agendador de tarefas do Windows. - Configure um processo de recuperação que use o comando
gcloud storagepara recuperar os seus dados para o ambiente de recuperação de DR no Google Cloud.
Também pode usar o comando gcloud storage rsync para fazer sincronizações incrementais em tempo real entre os seus dados e um contentor do Cloud Storage.
Por exemplo, o seguinte comando gcloud storage rsync faz com que o conteúdo num contentor do Cloud Storage seja igual ao conteúdo no diretório de origem, copiando todos os ficheiros ou objetos em falta ou aqueles cujos dados foram alterados. Se o volume de dados que foi alterado entre sessões de cópia de segurança sucessivas for pequeno em relação ao volume total dos dados de origem, a utilização de gcloud storage rsync pode ser mais eficiente do que a utilização do comando gcloud storage cp. Ao usar o gcloud storage rsync, pode implementar um agendamento de cópias de segurança mais frequente e alcançar um RPO mais baixo.
gcloud storage rsync -r SOURCE_DIRECTORY gs:// BUCKET_NAME
Para mais informações, consulte o comando
gcloud storage para transferências mais pequenas de dados no local.
Solução 2: faça uma cópia de segurança no Cloud Storage através do Serviço de transferência para dados nas instalações
Este padrão usa as seguintes bases de dados de registos detalhados:
- Cloud Storage
- Serviço de transferência para dados nas instalações
A transferência de grandes quantidades de dados numa rede requer frequentemente um planeamento cuidadoso e estratégias de execução robustas. É uma tarefa não trivial desenvolver scripts personalizados que sejam escaláveis, fiáveis e fáceis de manter. Os scripts personalizados podem, muitas vezes, originar valores de RPO mais baixos e até aumentar os riscos de perda de dados.
Para orientações sobre a movimentação de grandes volumes de dados de localizações no local para o Cloud Storage, consulte o artigo Mova ou faça uma cópia de segurança de dados do armazenamento no local.
Solução 3: faça uma cópia de segurança no Cloud Storage através de uma solução de gateway de parceiros
Este padrão usa as seguintes bases de dados de registos detalhados:
- Cloud Interconnect
- Armazenamento hierárquico do Cloud Storage
As aplicações no local são frequentemente integradas com soluções de terceiros que podem ser usadas como parte da sua estratégia de cópia de segurança e recuperação de dados. As soluções usam frequentemente um padrão de armazenamento hierárquico em que tem as cópias de segurança mais recentes num armazenamento mais rápido e migra lentamente as cópias de segurança mais antigas para um armazenamento mais barato (mais lento). Quando usa Google Cloud como destino, tem várias opções de classe de armazenamento disponíveis para usar como o equivalente do nível mais lento.
Uma forma de implementar este padrão é usar um gateway de parceiros entre o seu armazenamento local e Google Cloud para facilitar esta transferência de dados para o Cloud Storage. O diagrama seguinte ilustra esta disposição, com uma solução de parceiro que gere a transferência do dispositivo NAS ou SAN no local.

Em caso de falha, os dados cuja cópia de segurança está a ser feita têm de ser recuperados para o seu ambiente de recuperação de desastres. O ambiente de recuperação de desastres é usado para publicar tráfego de produção até poder reverter para o seu ambiente de produção. A forma como o consegue depende da sua aplicação, da solução de parceiros e da respetiva arquitetura. (Alguns cenários completos são abordados no documento de aplicação de DR.)
Também pode usar bases de dados Google Cloud geridas como destinos de recuperação de desastres. Por exemplo, o Cloud SQL para SQL Server suporta importações de registos de transações. Pode exportar registos de transações da sua instância do SQL Server no local, carregá-los para o Cloud Storage e importá-los para o Cloud SQL para SQL Server.
Para mais orientações sobre formas de transferir dados de local para Google Cloud, consulte o artigo Transferir grandes conjuntos de dados para o Google Cloud.
Para mais informações sobre soluções de parceiros, consulte a página de parceiros no Google Cloud Website.
Cópia de segurança e recuperação de bases de dados
Pode usar várias estratégias para implementar um processo de recuperação de um sistema de base de dados no local para a Google Cloud. Esta secção analisa duas das soluções mais comuns.
Está fora do âmbito deste documento discutir detalhadamente os vários mecanismos de cópia de segurança e recuperação incorporados incluídos nas bases de dados de terceiros. Esta secção fornece orientações gerais, que são implementadas nas soluções abordadas aqui.
Solução 1: cópia de segurança e recuperação através de um servidor de recuperação no Google Cloud
- Crie uma cópia de segurança da base de dados através dos mecanismos de cópia de segurança incorporados do seu sistema de gestão de bases de dados.
- Associe a sua rede no local e a sua rede Google Cloud .
- Crie um contentor do Cloud Storage como destino da cópia de segurança dos seus dados.
- Copie os ficheiros de cópia de segurança para o Cloud Storage através da
gcloud storageCLI gcloud ou de uma solução de gateway de parceiros (consulte os passos abordados anteriormente na secção de cópia de segurança e recuperação de dados). Para ver detalhes, consulte o artigo Migre para Google Cloud: transfira os seus grandes conjuntos de dados. - Copie os registos de transações para o seu site de recuperação em Google Cloud. Ter uma cópia de segurança dos registos de transações ajuda a manter os valores de RPO baixos.
Depois de configurar esta topologia de cópia de segurança, tem de garantir que consegue fazer a recuperação para o sistema que está em Google Cloud. Normalmente, este passo envolve não só restaurar o ficheiro de cópia de segurança na base de dados de destino, mas também repetir os registos de transações para alcançar o menor valor de RTO. Uma sequência de recuperação típica tem o seguinte aspeto:
- Crie uma imagem personalizada do servidor de base de dados no Google Cloud. O servidor de base de dados deve ter a mesma configuração na imagem que o seu servidor de base de dados no local.
- Implemente um processo para copiar os ficheiros de cópia de segurança no local e os ficheiros de registo de transações para o Cloud Storage. Consulte a solução 1 para ver um exemplo de implementação.
- Inicie uma instância de tamanho mínimo a partir da imagem personalizada e anexe todos os discos persistentes necessários.
- Defina a flag de eliminação automática como falsa para os discos persistentes.
- Aplique o ficheiro de cópia de segurança mais recente que foi copiado anteriormente para o Cloud Storage, seguindo as instruções do sistema de base de dados para recuperar ficheiros de cópia de segurança.
- Aplique o conjunto mais recente de ficheiros de registo de transações que foram copiados para o armazenamento na nuvem.
- Substitua a instância mínima por uma instância maior capaz de aceitar tráfego de produção.
- Mude os clientes para apontarem para a base de dados recuperada em Google Cloud.
Quando o ambiente de produção estiver em execução e for capaz de suportar cargas de trabalho de produção, tem de reverter os passos que seguiu para fazer a comutação por falha para oGoogle Cloud ambiente de recuperação. Uma sequência típica para regressar ao ambiente de produção tem o seguinte aspeto:
- Faça uma cópia de segurança da base de dados em execução no Google Cloud.
- Copie o ficheiro de cópia de segurança para o ambiente de produção.
- Aplique o ficheiro de cópia de segurança ao seu sistema de base de dados de produção.
- Impedir que os clientes se liguem ao sistema de base de dados emGoogle Cloud; por exemplo, parando o serviço do sistema de base de dados. A partir deste ponto, a sua aplicação fica indisponível até terminar de restaurar o ambiente de produção.
- Copie todos os ficheiros de registo de transações para o ambiente de produção e aplique-os.
- Redirecionar as ligações de clientes para o ambiente de produção.
Solução 2: replicação para um servidor de reserva no Google Cloud
Uma forma de alcançar valores de RTO e RPO muito pequenos é replicar (e não apenas fazer uma cópia de segurança) os dados e, em alguns casos, o estado da base de dados em tempo real para uma réplica do servidor da base de dados.
- Ligue a sua rede no local e a rede Google Cloud .
- Crie uma imagem personalizada do servidor de base de dados no Google Cloud. O servidor de base de dados deve ter a mesma configuração na imagem que a configuração do seu servidor de base de dados no local.
- Inicie uma instância a partir da imagem personalizada e anexe todos os discos persistentes necessários.
- Defina a flag de eliminação automática como falsa para os discos persistentes.
- Configure a replicação entre o servidor de base de dados no local e o servidor de base de dados de destino seguindo as instruções específicas do software de base de dados. Google Cloud
- Os clientes estão configurados no funcionamento normal para apontar para o servidor de base de dados no local.
Depois de configurar esta topologia de replicação, mude os clientes para apontarem para o servidor de espera em execução na sua Google Cloud rede.
Quando o ambiente de produção estiver novamente em funcionamento e for capaz de suportar cargas de trabalho de produção, tem de sincronizar novamente o servidor da base de dados de produção com o servidor da base de dados e, em seguida, mudar os clientes para apontarem novamente para o ambiente de produçãoGoogle Cloud
O ambiente de produção é Google Cloud
Neste cenário, o ambiente de produção e o ambiente de recuperação de desastres são executados no Google Cloud.
Cópias de segurança e recuperação de dados
Um padrão comum para cópias de segurança de dados é usar um padrão de armazenamento hierárquico. Quando a carga de trabalho de produção está ativada Google Cloud, o sistema de armazenamento hierárquico tem o seguinte aspeto. Migrar dados para um nível com custos de armazenamento mais baixos, porque o requisito de acesso aos dados de cópia de segurança é menos provável.
Este padrão usa as seguintes bases de dados de registos detalhados:
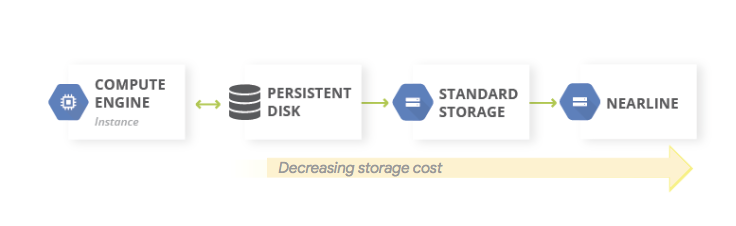
Uma vez que as classes Nearline, Coldline e Archive Storage destinam-se ao armazenamento de dados acedidos com pouca frequência, existem custos adicionais associados à obtenção de dados ou metadados armazenados nestas classes, bem como durações mínimas de armazenamento que lhe são cobradas.
Cópia de segurança e recuperação de bases de dados
Quando usa uma base de dados autogerida (por exemplo, instalou o MySQL, o PostgreSQL ou o SQL Server numa instância do Compute Engine), aplicam-se as mesmas preocupações operacionais que na gestão de bases de dados de produção no local, mas já não precisa de gerir a infraestrutura subjacente.
O serviço de cópia de segurança e RD é uma solução centralizada nativa da nuvem para fazer cópias de segurança e recuperar cargas de trabalho na nuvem e híbridas. Oferece uma recuperação de dados rápida e facilita a retoma rápida das operações empresariais essenciais.
Para mais informações sobre a utilização da cópia de segurança e da RD para cenários de base de dados autogeridos no Google Cloud, consulte o seguinte:
Em alternativa, pode configurar configurações de HA através das funcionalidades de base de DR adequadas para manter o RTO pequeno. Pode conceber a configuração da base de dados para tornar factível a recuperação para um estado o mais próximo possível do estado anterior à catástrofe; isto ajuda a manter os valores de RPO pequenos.O Google Cloud oferece uma grande variedade de opções para este cenário.
Nesta secção, são abordadas duas abordagens comuns para conceber a arquitetura de recuperação da base de dados para bases de dados autogeridas no Google Cloud .
Recuperar um servidor de base de dados sem sincronizar o estado
Um padrão comum é ativar a recuperação de um servidor de base de dados que não exija que o estado do sistema seja sincronizado com uma réplica em espera atualizada.
Este padrão usa as seguintes bases de dados de registos detalhados:
- Compute Engine
- Grupos de instâncias geridas
- Cloud Load Balancing (balanceamento de carga interno)
O diagrama seguinte ilustra uma arquitetura de exemplo que aborda o cenário. Ao implementar esta arquitetura, tem um plano de DR que reage automaticamente a uma falha sem exigir uma recuperação manual.

Os passos seguintes descrevem como configurar este cenário:
- Crie uma rede de VPC.
Crie uma imagem personalizada configurada com o servidor da base de dados fazendo o seguinte:
- Configure o servidor para que os ficheiros de base de dados e os ficheiros de registo sejam escritos num disco persistente padrão anexado.
- Crie um instantâneo a partir do disco persistente anexado.
- Configure um script de arranque para criar um disco persistente a partir da cópia instantânea e para montar o disco.
- Crie uma imagem personalizada do disco de arranque.
Crie um modelo de instância que use a imagem.
Usando o modelo de instância, configure um grupo de instâncias geridas com um tamanho de destino de 1.
Configure a verificação de funcionamento através de métricas do Cloud Monitoring.
Configure o equilíbrio de carga interno através do grupo de instâncias geridas.
Configure uma tarefa agendada para criar capturas de ecrã regulares do disco persistente.
Caso seja necessária uma instância de base de dados de substituição, esta configuração faz automaticamente o seguinte:
- Apresenta outro servidor de base de dados da versão correta na mesma zona.
- Anexa um disco persistente que tem os ficheiros de registo de transações e de cópia de segurança mais recentes à instância do servidor de base de dados recém-criada.
- Minimiza a necessidade de reconfigurar os clientes que comunicam com o servidor da base de dados em resposta a um evento.
- Garante que os Google Cloud controlos de segurança (políticas de IAM, definições de firewall) que se aplicam ao servidor da base de dados de produção se aplicam ao servidor da base de dados recuperado.
Uma vez que a instância de substituição é criada a partir de um modelo de instância, os controlos aplicados à instância original aplicam-se à instância de substituição.
Este cenário tira partido de algumas das funcionalidades de HA disponíveis no Google Cloud. Não tem de iniciar nenhum passo de comutação por falha, porque estes ocorrem automaticamente em caso de desastre. O balanceador de carga interno garante que, mesmo quando é necessária uma instância de substituição, é usado o mesmo endereço IP para o servidor de base de dados. O modelo de instância e a imagem personalizada garantem que a instância de substituição é configurada de forma idêntica à instância que está a substituir. Ao tirar instantâneos regulares dos discos persistentes, garante que, quando os discos são recriados a partir dos instantâneos e anexados à instância de substituição, a instância de substituição está a usar dados recuperados de acordo com um valor de RPO ditado pela frequência dos instantâneos. Nesta arquitetura, os ficheiros de registo de transações mais recentes que foram escritos no disco persistente também são restaurados automaticamente.
O grupo de instâncias geridas oferece HA em profundidade. Fornece mecanismos para reagir a falhas ao nível da aplicação ou da instância, e não tem de intervir manualmente se ocorrer algum desses cenários. A definição de um tamanho-alvo de um garante que tem sempre uma instância ativa que é executada no grupo de instâncias gerido e que serve tráfego.
Os discos persistentes padrão são zonais. Por isso, se ocorrer uma falha zonal, são necessários instantâneos para recriar os discos. As capturas de ecrã também estão disponíveis em várias regiões, o que lhe permite restaurar um disco não só na mesma região, mas também numa região diferente.
Uma variação desta configuração é usar discos persistentes regionais em vez de discos persistentes padrão. Neste caso, não precisa de restaurar a imagem instantânea como parte do passo de recuperação.
A variação que escolher é determinada pelo seu orçamento e pelos valores de RTO e RPO.
Recuperação de corrupção parcial em bases de dados muito grandes
A replicação assíncrona do Persistent Disk oferece replicação de armazenamento de blocos com um RPO baixo e um RTO baixo para DR ativo-passivo entre regiões. Esta opção de armazenamento permite-lhe gerir a replicação para cargas de trabalho do Compute Engine ao nível da infraestrutura, em vez de ao nível da carga de trabalho.
Se estiver a usar uma base de dados capaz de armazenar petabytes de dados, pode ocorrer uma indisponibilidade que afete alguns dos dados, mas não todos. Nesse caso, quer minimizar a quantidade de dados que precisa de restaurar. Não precisa (nem quer) de recuperar toda a base de dados apenas para restaurar alguns dos dados.
Existem várias estratégias de mitigação que pode adotar:
- Armazene os seus dados em tabelas diferentes para períodos específicos. Este método garante que só precisa de restaurar um subconjunto de dados para uma nova tabela, em vez de um conjunto de dados completo.
Armazenar os dados originais no Cloud Storage. Esta abordagem permite-lhe criar uma nova tabela e recarregar os dados não danificados. A partir daí, pode ajustar as suas aplicações para apontarem para a nova tabela.
Além disso, se o seu RTO o permitir, pode impedir o acesso à tabela que tem os dados danificados deixando as suas aplicações offline até que os dados não danificados sejam restaurados para uma nova tabela.
Serviços de base de dados geridos no Google Cloud
Esta secção aborda alguns métodos que pode usar para implementar mecanismos de cópia de segurança e recuperação adequados para os serviços de base de dados geridos noGoogle Cloud.
As bases de dados geridas foram concebidas para serem escaláveis, pelo que os mecanismos tradicionais de cópia de segurança e restauro que vê com os RDBMSs tradicionais não estão normalmente disponíveis. Tal como no caso das bases de dados autogeridas, se estiver a usar uma base de dados capaz de armazenar petabytes de dados, é recomendável minimizar a quantidade de dados que tem de restaurar num cenário de recuperação de desastres. Existem várias estratégias para cada base de dados gerida que ajudam a alcançar este objetivo.
O Bigtable oferece a replicação do Bigtable. Uma base de dados do Bigtable replicada pode oferecer uma maior disponibilidade do que um único cluster, um débito de leitura adicional e uma maior durabilidade e resiliência em caso de falhas zonais ou regionais.
As cópias de segurança do Bigtable são um serviço totalmente gerido que lhe permite guardar uma cópia do esquema e dos dados de uma tabela e, em seguida, restaurar a partir da cópia de segurança para uma nova tabela mais tarde.
Também pode exportar tabelas do Bigtable como uma série de ficheiros de sequência do Hadoop. Em seguida, pode armazenar estes ficheiros no Cloud Storage ou usá-los para importar os dados novamente para outra instância do Bigtable. Pode replicar o seu conjunto de dados do Bigtable de forma assíncrona entre zonas numa Google Cloud região.
BigQuery. Se quiser arquivar dados, pode tirar partido do armazenamento a longo prazo do BigQuery. Se uma tabela não for editada durante 90 dias consecutivos, o preço do armazenamento dessa tabela diminui automaticamente 50%. Não existe degradação do desempenho, da durabilidade, da disponibilidade nem de qualquer outra funcionalidade quando uma tabela é considerada armazenamento a longo prazo. No entanto, se a tabela for editada, volta ao preço de armazenamento normal e a contagem decrescente de 90 dias recomeça.
O BigQuery é replicado em duas zonas numa única região, mas isto não ajuda com a corrupção nas suas tabelas. Por conseguinte, tem de ter um plano para poder recuperar desse cenário. Por exemplo, pode fazer o seguinte:
- Se a corrupção for detetada no prazo de 7 dias, consulte a tabela até um ponto no tempo no passado para recuperar a tabela antes da corrupção através de decoradores de instantâneos.
- Exporte os dados do BigQuery e crie uma nova tabela que contenha os dados exportados, mas exclua os dados danificados.
- Armazene os seus dados em tabelas diferentes para períodos específicos. Este método garante que só tem de restaurar um subconjunto de dados para uma nova tabela, em vez de um conjunto de dados completo.
- Fazer cópias do seu conjunto de dados em períodos específicos. Pode usar estas cópias se tiver ocorrido um evento de corrupção de dados para além do que uma consulta num determinado momento pode captar (por exemplo, há mais de 7 dias). Também pode copiar um conjunto de dados de uma região para outra para garantir a disponibilidade dos dados em caso de falhas na região.
- Armazenar os dados originais no Cloud Storage, o que lhe permite criar uma nova tabela e recarregar os dados não danificados. A partir daí, pode ajustar as suas aplicações para apontarem para a nova tabela.
Firestore. O serviço de exportação e importação gerido permite-lhe importar e exportar entidades do Firestore através de um contentor do Cloud Storage. Em seguida, pode implementar um processo que pode ser usado para recuperar de uma eliminação acidental de dados.
Cloud SQL. Se usar o Cloud SQL, a base de dados MySQL totalmente gerida, deve ativar as cópias de segurança automáticas e o registo binário para as suas instâncias do Cloud SQL.Google Cloud Esta abordagem permite-lhe fazer uma recuperação num determinado momento, que restaura a base de dados a partir de uma cópia de segurança e a recupera para uma nova instância do Cloud SQL. Para mais informações, consulte os artigos Acerca das cópias de segurança do Cloud SQL e Acerca da recuperação de desastres (RD) no Cloud SQL
Também pode configurar o Cloud SQL numa configuração de HA e réplicas entre regiões para maximizar o tempo de atividade em caso de falha zonal ou regional.
Se ativou a manutenção planeada com tempo de inatividade quase nulo para o Cloud SQL, pode avaliar o impacto dos eventos de manutenção nas suas instâncias simulando eventos de manutenção planeada com tempo de inatividade quase nulo no Cloud SQL para MySQL e no Cloud SQL para PostgreSQL.
Para a edição Cloud SQL Enterprise Plus, pode usar a recuperação após desastre (RAD) avançada para simplificar os processos de recuperação e replicação alternativa sem perda de dados depois de realizar uma replicação alternativa entre regiões.
Spanner. Pode usar modelos do Dataflow para fazer uma exportação completa da sua base de dados para um conjunto de ficheiros Avro num contentor do Cloud Storage e usar outro modelo para reimportar os ficheiros exportados para uma nova base de dados do Spanner.
Para cópias de segurança mais controladas, o conetor Dataflow permite-lhe escrever código para ler e escrever dados no Spanner num pipeline do Dataflow. Por exemplo, pode usar o conetor para copiar dados do Spanner para o Cloud Storage como destino da cópia de segurança. A velocidade a que os dados podem ser lidos do Spanner (ou escritos novamente nele) depende do número de nós configurados. Isto tem um impacto direto nos seus valores de RTO.
A funcionalidade de data/hora de confirmação do Spanner pode ser útil para cópias de segurança incrementais, pois permite selecionar apenas as linhas que foram adicionadas ou modificadas desde a última cópia de segurança completa.
Para cópias de segurança geridas, o Spanner Backup and Restore permite-lhe criar cópias de segurança consistentes que podem ser retidas durante um período máximo de 1 ano. O valor do RTO é inferior em comparação com a exportação porque a operação de restauro monta diretamente a cópia de segurança sem copiar os dados.
Para valores de RTO pequenos, pode configurar uma instância do Spanner em espera ativa com o número mínimo de nós necessários para cumprir os requisitos de armazenamento e débito de leitura e gravação.
A recuperação pontual (PITR) do Spanner permite-lhe recuperar dados de um ponto específico no tempo. Por exemplo, se um operador escrever dados inadvertidamente ou a implementação de uma aplicação corromper a base de dados, com a PITR, pode recuperar os dados de um momento no passado, até um máximo de 7 dias.
Cloud Composer. Pode usar o Cloud Composer (uma versão gerida do Apache Airflow) para agendar cópias de segurança regulares de váriasGoogle Cloud bases de dados. Pode criar um gráfico acíclico dirigido (DAG) para ser executado de acordo com um horário (por exemplo, diariamente) para copiar os dados para outro projeto, conjunto de dados ou tabela (consoante a solução usada) ou para exportar os dados para o Cloud Storage.
A exportação ou a cópia de dados pode ser feita através dos vários operadores da Cloud Platform.
Por exemplo, pode criar um DAG para fazer qualquer uma das seguintes ações:
- Exporte uma tabela do BigQuery para o Cloud Storage através do BigQueryToCloudStorageOperator.
- Exporte o Firestore no modo Datastore (Datastore) para o Cloud Storage através do DatastoreExportOperator.
- Exporte tabelas do MySQL para o Cloud Storage através do MySqlToGoogleCloudStorageOperator.
- Exporte tabelas do Postgres para o Cloud Storage através do PostgresToGoogleCloudStorageOperator.
O ambiente de produção é outra nuvem
Neste cenário, o seu ambiente de produção usa outro fornecedor de nuvem e o seu plano de recuperação de desastres envolve a utilização do Google Cloud como o site de recuperação.
Cópias de segurança e recuperação de dados
A transferência de dados entre armazenamentos de objetos é um exemplo de utilização comum para cenários de recuperação de desastres. O serviço de transferência de armazenamento é compatível com o Amazon S3 e é a forma recomendada de transferir objetos do Amazon S3 para o Cloud Storage.
Pode configurar uma tarefa de transferência para agendar a sincronização periódica da origem de dados para o destino de dados, com filtros avançados baseados nas datas de criação dos ficheiros, nos filtros de nomes de ficheiros e nas horas do dia em que prefere transferir dados. Para alcançar o RPO pretendido, tem de ter em conta os seguintes fatores:
Taxa de alteração. A quantidade de dados que está a ser gerada ou atualizada durante um determinado período. Quanto maior for a taxa de alteração, mais recursos são necessários para transferir as alterações para o destino em cada período de transferência incremental.
Transfira o desempenho. O tempo necessário para transferir ficheiros. Para transferências de ficheiros grandes, isto é normalmente determinado pela largura de banda disponível entre a origem e o destino. No entanto, se uma tarefa de transferência consistir num grande número de ficheiros pequenos, o CPS pode tornar-se um fator limitativo. Se for esse o caso, pode agendar várias tarefas em simultâneo para dimensionar o desempenho, desde que esteja disponível largura de banda suficiente. Recomendamos que meça o desempenho da transferência com um subconjunto representativo dos seus dados reais.
Frequência. O intervalo entre trabalhos de cópia de segurança. A atualidade dos dados no destino é tão recente quanto a última vez que foi agendada uma tarefa de transferência. Por conseguinte, é importante que os intervalos entre tarefas de transferência sucessivas não sejam superiores ao objetivo de RPO. Por exemplo, se o objetivo de RPO for de 1 dia, a tarefa de transferência tem de ser agendada, pelo menos, uma vez por dia.
Monitorização e alertas. O Storage Transfer Service fornece notificações do Pub/Sub sobre uma variedade de eventos. Recomendamos que subscreva estas notificações para resolver falhas inesperadas ou alterações nos tempos de conclusão das tarefas.
Cópia de segurança e recuperação de bases de dados
Está fora do âmbito deste documento discutir detalhadamente os vários mecanismos de cópia de segurança e recuperação incorporados incluídos nas bases de dados de terceiros ou as técnicas de cópia de segurança e recuperação usadas noutros fornecedores de nuvem. Se estiver a operar bases de dados não geridas nos serviços de computação, pode tirar partido das instalações de HA que o seu fornecedor de nuvem de produção tem disponíveis. Pode expandir estas opções para incorporar uma implementação de HA para Google Cloud, ou usar o Cloud Storage como o destino final do armazenamento a frio dos seus ficheiros de cópia de segurança da base de dados.
O que se segue?
- Leia mais sobre Google Cloud geografia e regiões.
Leia outros documentos desta série de DR:
- Guia de planeamento de recuperação de desastres
- Bases de recuperação de desastres
- Cenários de recuperação de desastres para aplicações
- Arquitetar a recuperação de desastres para cargas de trabalho restritas por localidade
- Exemplos de utilização de recuperação de desastres: aplicações de estatísticas de dados restritas à localidade
- Criar arquiteturas de recuperação de desastres para interrupções da infraestrutura na nuvem
- Arquiteturas para a elevada disponibilidade de clusters MySQL no Compute Engine
Explore arquiteturas de referência, diagramas e práticas recomendadas sobre o Google Cloud. Consulte o nosso Centro de arquitetura na nuvem.