Questo documento è la seconda parte di una serie che descrive il disaster recovery (RE) in Google Cloud. Questa parte descrive servizi e prodotti che puoi utilizzare come componenti di base per il tuo piano di RE, sia Google Cloud prodotti sia prodotti che funzionano su più piattaforme.
La serie è composta dalle seguenti parti:
- Guida alla pianificazione del ripristino di emergenza
- Componenti di base per il ripristino di emergenza (questo articolo)
- Scenari di ripristino di emergenza dei dati
- Scenari di ripristino di emergenza per le applicazioni
- Progettazione ripristino di emergenza per i workload con limitazioni a livello di località
- Casi d'uso di ripristino di emergenza: applicazioni di analisi dei dati con limitazioni di località
- Progettazione ripristino di emergenza per interruzioni dell'infrastruttura cloud
Google Cloud offre una vasta gamma di prodotti che puoi utilizzare come parte della tua architettura di ripristino di emergenza. Questa sezione descrive le funzionalità relative RE dei prodotti più comunemente utilizzati come Google Cloud componenti di base per il ripristino di emergenza.
Molti di questi servizi dispongono di funzionalità di alta disponibilità. L'alta affidabilità non si sovrappone completamente al RE, ma molti dei suoi obiettivi si applicano anche alla progettazione di un piano di RE. Ad esempio, sfruttando le funzionalità di alta affidabilità, puoi progettare architetture che ottimizzano l'uptime e che possono mitigare gli effetti di errori su piccola scala, come l'errore di una singola VM. Per saperne di più sulla relazione tra RE e HA, consulta la Guida alla pianificazione del disaster recovery.
Le sezioni seguenti descrivono questi elementi costitutivi del Google Cloud recupero di emergenza e come ti aiutano a implementare i tuoi obiettivi di RE.
Computing e archiviazione
La tabella seguente fornisce un riepilogo delle funzionalità dei servizi di calcolo e archiviazione che fungono da componenti di base per RE: Google Cloud
| Prodotto | Funzionalità |
|---|---|
| Compute Engine |
|
| Cloud Storage |
|
| Google Kubernetes Engine (GKE) |
|
Per saperne di più su come le funzionalità e la progettazione di questi e altri Google Cloud prodotti potrebbero influenzare la tua strategia di RE, consulta Architettura ripristino di emergenza per interruzioni dell'infrastruttura cloud: riferimento al prodotto.
Compute Engine
Compute Engine fornisce istanze di macchine virtuali (VM) ed è il cavallo di battaglia di Google Cloud. Oltre a configurare, avviare e monitorare le istanze Compute Engine, in genere utilizzi una serie di funzionalità correlate per implementare un piano di ripristino di emergenza.
Per gli scenari di ripristino di emergenza, puoi impedire l'eliminazione accidentale delle VM impostando il flag di protezione dall'eliminazione. Ciò è particolarmente utile quando ospiti servizi stateful come i database.
Per informazioni su come soddisfare valori RTO e RPO bassi, consulta Progettazione di sistemi resilienti.
Modelli di istanza
Puoi utilizzare i modelli di istanza Compute Engine per salvare i dettagli di configurazione della VM e poi creare istanze Compute Engine dai modelli di istanza esistenti. Puoi utilizzare il modello per avviare tutte le istanze che ti servono, configurate esattamente come vuoi quando devi configurare l'ambiente di destinazioneRER. I modelli di istanza vengono replicati a livello globale, quindi puoi ricreare l'istanza ovunque in Google Cloud con la stessa configurazione.
Per maggiori informazioni, consulta le seguenti risorse:
Per informazioni dettagliate sull'utilizzo delle immagini Compute Engine, consulta la sezione Bilanciamento della configurazione dell'immagine e della velocità di deployment più avanti in questo documento.
Gruppi di istanze gestite
I gruppi di istanze gestite funzionano con Cloud Load Balancing (descritto più avanti in questo documento) per distribuire il traffico a gruppi di istanze configurate in modo identico che vengono copiate tra le zone. I gruppi di istanze gestite consentono funzionalità come la scalabilità automatica e la riparazione automatica, in cui il gruppo di istanze gestite può eliminare e ricreare automaticamente le istanze.
Prenotazioni
Compute Engine consente la prenotazione di istanze VM in una zona specifica, utilizzando tipi di macchine personalizzati o predefiniti, con o senza GPU aggiuntive o SSD locali. Per garantire la capacità per i tuoi workload mission critical perRER, devi creare prenotazioni nelle zone di destinazioneRER. Senza prenotazioni, è possibile che tu non ottenga la capacità on demand necessaria per soddisfare il tuo obiettivo del tempo di ripristino. Le prenotazioni possono essere utili in scenariREa freddi, tiepidi o caldi. Ti consentono di mantenere le risorse di ripristino disponibili per il failover per soddisfare esigenze di RTO inferiori, senza doverle configurare e implementare completamente in anticipo.
Dischi permanenti e snapshot
I dischi permanenti sono dispositivi di archiviazione di rete durevoli a cui possono accedere le tue istanze. Sono indipendenti dalle istanze, quindi puoi scollegare e spostare i dischi permanenti per conservare i dati anche dopo aver eliminato le istanze.
Puoi eseguire backup o snapshot incrementali delle VM di Compute Engine che puoi copiare tra le regioni e utilizzare per ricreare dischi permanenti in caso di emergenza. Inoltre, puoi creare snapshot dei dischi permanenti per difenderti dalla perdita di dati in seguito a errori commessi dall'utente. Gli snapshot sono incrementali e la loro creazione richiede solo pochi minuti, anche se i dischi snapshot sono collegati a istanze in esecuzione.
I dischi permanenti hanno una ridondanza integrata per proteggere i dati da guasti dell'apparecchiatura e per garantire la disponibilità dei dati tramite eventi di manutenzione del data center. I dischi permanenti sono a livello di zona o di regione. I dischi permanenti a livello di regione replicano le scritture in due zone di una regione. In caso di interruzione a livello di zona, un'istanza VM di backup può forzare l'associazione di un disco permanente regionale nella zona secondaria. Per saperne di più, vedi Opzioni di alta affidabilità utilizzando i dischi permanenti regionali.
Manutenzione trasparente
Google esegue regolarmente la manutenzione della propria infrastruttura applicando patch ai sistemi con il software più recente, eseguendo test di routine e manutenzione preventiva e lavorando per garantire che l'infrastruttura di Google sia la più veloce ed efficiente possibile.
Per impostazione predefinita, tutte le istanze Compute Engine sono configurate in modo che questi eventi di manutenzione siano trasparenti per le applicazioni e i workload. Per saperne di più, consulta Manutenzione trasparente.
Quando si verifica un evento di manutenzione, Compute Engine utilizza la migrazione live per eseguire automaticamente la migrazione delle istanze in esecuzione a un altro host nella stessa zona. La migrazione live consente a Google di eseguire la manutenzione, essenziale per mantenere un'infrastruttura protetta e affidabile, senza interrompere nessuna delle tue VM.
Strumento di importazione del disco virtuale
Lo strumento di importazione dei dischi virtuali ti consente di importare formati di file tra cui VMDK, VHD e RAW per creare nuove macchine virtuali Compute Engine. Utilizzando questo strumento, puoi creare macchine virtuali Compute Engine con la stessa configurazione delle tue macchine virtuali on-premise. Questo è un buon approccio quando non riesci a configurare le immagini Compute Engine dai binari di origine del software già installato nelle immagini.
Backup automatici
Puoi automatizzare i backup delle tue istanze Compute Engine utilizzando i tag. Ad esempio, puoi creare un modello di piano di backup utilizzando il servizio di Backup e DR e applicarlo automaticamente alle tue istanze Compute Engine.
Per saperne di più, consulta Automatizzare la protezione delle nuove istanze Compute Engine.
Cloud Storage
Cloud Storage è uno spazio di archiviazione di oggetti ideale per archiviare i file di backup. Fornisce diverse classi di archiviazione adatte a casi d'uso specifici, come illustrato nel seguente diagramma.

Negli scenari di ripristino di emergenza, Nearline Storage, Coldline Storage e Archive Storage sono di particolare interesse. Queste classi di archiviazione riducono i costi di archiviazione rispetto all'archiviazione Standard. Tuttavia, sono previsti costi aggiuntivi associati al recupero dei dati o dei metadati archiviati in queste classi, oltre a durate minime di archiviazione per le quali vengono addebitati dei costi. Nearline è progettato per scenari di backup in cui l'accesso avviene al massimo una volta al mese, il che è ideale per consentirti di eseguire test di stress RE regolari mantenendo i costi bassi.
Le classi Nearline, Coldline e Archive sono ottimizzate per l'accesso poco frequente e il modello di determinazione del prezzo è progettato tenendo conto di questo aspetto. Pertanto, ti vengono addebitati i costi per le durate minime di archiviazione e sono previsti costi aggiuntivi per il recupero dei dati o dei metadati in queste classi prima della durata minima di archiviazione per la classe.
Per proteggere i tuoi dati in un bucket Cloud Storage da eliminazioni accidentali o dannose, puoi utilizzare la funzionalità Eliminazione temporanea per conservare gli oggetti eliminati e sovrascritti per un periodo di tempo specificato e la funzionalità Blocchi degli oggetti per impedire l'eliminazione o gli aggiornamenti degli oggetti.
Storage Transfer Service consente di importare dati da Amazon S3, Azure Blob Storage o origini dati on-premise in Cloud Storage. Negli scenari di ripristino di emergenza, puoi utilizzare Storage Transfer Service per:
- Eseguire il backup dei dati di altri fornitori di spazio di archiviazione in un bucket Cloud Storage.
- Sposta i dati da un bucket in una regione doppia o multiregione a un bucket in una regione per ridurre i costi di archiviazione dei backup.
Filestore
Le istanze Filestore sono file server NFS completamente gestiti da utilizzare con applicazioni in esecuzione su istanze Compute Engine o cluster GKE.
I livelli Filestore Basic e di zona sono risorse a livello di zona e non supportano la replica tra le zone, mentre le istanze del livello Filestore Enterprise sono risorse a livello di regione. Per aumentare la resilienza dell'ambiente Filestore, ti consigliamo di utilizzare istanze di livello Enterprise.
Google Kubernetes Engine
GKE è un ambiente gestito e pronto per la produzione per il deployment di applicazioni containerizzate. GKE ti consente di orchestrare sistemi HA e include le seguenti funzionalità:
- Riparazione automatica dei nodi. Se un nodo non supera controlli di integrità consecutivi per un periodo di tempo prolungato (circa 10 minuti), GKE avvia un processo di riparazione per quel nodo.
- Probe di attività e idoneità. Puoi specificare un probe di attività, che comunica periodicamente a GKE che il pod è in esecuzione. Se il pod non supera il test, può essere riavviato.
- Cluster in più zone e in una regione. Puoi distribuire le risorse Kubernetes in più zone all'interno di una regione.
- Multi-cluster Gateway ti consente di configurare risorse di bilanciamento del carico condivise in più cluster GKE in diverse regioni.
- Backup per GKE consente di eseguire il backup e il ripristino dei carichi di lavoro nei cluster GKE.
Networking e trasferimento dei dati
La tabella seguente fornisce un riepilogo delle funzionalità dei servizi di networking e trasferimento dei dati che fungono da componenti di base per RE: Google Cloud
| Prodotto | Funzionalità |
|---|---|
| Cloud Load Balancing |
|
| Cloud Service Mesh |
|
| Cloud DNS |
|
| Cloud Interconnect |
|
Cloud Load Balancing
Cloud Load Balancing fornisce l'alta disponibilità per i prodotti di calcolo Google Cloud distribuendo il traffico utente su più istanze delle applicazioni. Puoi configurare Cloud Load Balancing con controlli di integrità che determinano se le istanze sono disponibili per eseguire il lavoro in modo che il traffico non venga instradato alle istanze non funzionanti.
Cloud Load Balancing fornisce un singolo indirizzo IP anycast per il frontend delle tue applicazioni. Le tue applicazioni possono avere istanze in esecuzione in regioni diverse (ad esempio in Europa e negli Stati Uniti) e gli utenti finali vengono indirizzati al set di istanze più vicino. Oltre a fornire il bilanciamento del carico per i servizi esposti a internet, puoi configurare il bilanciamento del carico interno per i tuoi servizi dietro un indirizzo IP privato di bilanciamento del carico. Questo indirizzo IP è accessibile solo alle istanze VM interne al tuo Virtual Private Cloud (VPC).
Per saperne di più, consulta la panoramica di Cloud Load Balancing.
Cloud Service Mesh
Cloud Service Mesh è un mesh di servizi gestito da Google disponibile su Google Cloud. Cloud Service Mesh fornisce una telemetria approfondita per aiutarti a raccogliere informazioni dettagliate sulle tue applicazioni. Supporta i servizi eseguiti su una gamma di infrastrutture di computing.
Cloud Service Mesh supporta anche funzionalità avanzate di gestione e routing del traffico, come l'interruzione del circuito e l'inserimento di errori. Con l'interruzione del circuito, puoi applicare limiti alle richieste a un servizio specifico. Quando vengono raggiunti i limiti di interruzione del circuito, le richieste non possono raggiungere il servizio, il che impedisce un ulteriore degrado del servizio. Con l'inserimento di errori, Cloud Service Mesh può introdurre ritardi o interrompere una frazione di richieste a un servizio. Fault injection ti consente di testare la capacità del tuo servizio di sopravvivere a ritardi o interruzioni delle richieste.
Per saperne di più, consulta la panoramica di Cloud Service Mesh.
Cloud DNS
Cloud DNS offre un modo programmatico per gestire le voci DNS nell'ambito di una procedura di ripristino automatizzata. Cloud DNS utilizza la rete globale Google di server dei nomi Anycast per la gestione delle zone DNS da località ridondanti in tutto il mondo, offrendo disponibilità elevata e minore latenza agli utenti.
Se hai scelto di gestire le voci DNS on-premise, puoi abilitare le VM in Google Cloud per risolvere questi indirizzi tramite il forwarding di Cloud DNS.
Cloud DNS supporta policy per configurare la modalità di risposta alle richieste DNS. Ad esempio, puoi configurare i criteri di routing DNS per indirizzare il traffico in base a criteri specifici, ad esempio attivare il failover a una configurazione di backup per garantire l'alta disponibilità o per instradare le richieste DNS in base alla loro posizione geografica.
Cloud Interconnect
Cloud Interconnect offre modi per spostare le informazioni da altre fonti a Google Cloud. Parleremo di questo prodotto più avanti nella sezione Trasferimento dei dati da e verso Google Cloud.
Gestione e monitoraggio
La tabella seguente fornisce un riepilogo delle funzionalità dei servizi di gestione e monitoraggio di Google Cloud che fungono da elementi costitutivi per RE:
| Prodotto | Funzionalità |
|---|---|
| Dashboard di stato di Cloud |
|
| Google Cloud Observability |
|
| Google Cloud Managed Service per Prometheus |
|
Dashboard di stato di Cloud
La dashboard dello stato di Cloud mostra la disponibilità attuale dei servizi. Google Cloud Puoi visualizzare lo stato nella pagina e puoi iscriverti a un feed RSS che viene aggiornato ogni volta che ci sono novità su un servizio.
Cloud Monitoring
Cloud Monitoring raccoglie metriche, eventi e metadati da Google Cloud, AWS, probe di uptime in hosting, strumentazione delle applicazioni e una serie di altri componenti di applicazioni. Puoi configurare gli avvisi per inviare notifiche a strumenti di terze parti come Slack o PagerDuty per fornire aggiornamenti tempestivi agli amministratori.
Cloud Monitoring ti consente di creare controlli di uptime per endpoint disponibili pubblicamente e per endpoint all'interno dei tuoi VPC. Ad esempio, puoi monitorare URL, istanze Compute Engine, revisioni Cloud Run e risorse di terze parti, come le istanze Amazon Elastic Compute Cloud (EC2).
Google Cloud Managed Service per Prometheus
Google Cloud Managed Service per Prometheus è una soluzione multi-cloud e multiprogetto gestita da Google per le metriche Prometheus. Ti consente di monitorare e creare avvisi sui tuoi carichi di lavoro a livello globale utilizzando Prometheus, senza dover gestire e utilizzare manualmente Prometheus su larga scala.
Per ulteriori informazioni, vedi Google Cloud Managed Service per Prometheus.
Componenti di base per il ripristino di emergenza multipiattaforma
Quando esegui workload su più piattaforme, un modo per ridurre i costi operativi generali è selezionare strumenti che funzionino con tutte le piattaforme che utilizzi. Questa sezione illustra alcuni strumenti e servizi indipendenti dalla piattaforma e che pertanto supportano scenari di RE multipiattaforma.
Infrastructure as Code (IaC)
Definendo l'infrastruttura utilizzando il codice, anziché interfacce grafiche o script, puoi adottare strumenti di modelli dichiarativi e automatizzare il provisioning e la configurazione dell'infrastruttura su piattaforme. Ad esempio, puoi utilizzare Terraform e Infrastructure Manager per attivare la configurazione dichiarativa dell'infrastruttura.
Strumenti di gestione della configurazione
Per un'infrastruttura di RE di grandi dimensioni o complessa, consigliamo strumenti di gestione software indipendenti dalla piattaforma, come Chef e Ansible. Questi strumenti garantiscono che le configurazioni riproducibili possano essere applicate indipendentemente da dove si trova il tuo carico di lavoro di calcolo.
Strumenti per l'orchestratore
I container possono essere considerati anche un elemento di base RE. I container sono un modo per pacchettizzare i servizi e introdurre coerenza tra le piattaforme.
Se lavori con i container, in genere utilizzi un orchestratore. Kubernetes non solo gestisce i container all'interno di Google Cloud (utilizzando GKE), ma fornisce un modo per orchestrare i carichi di lavoro basati su container su più piattaforme. Google Cloud, AWS e Microsoft Azure forniscono versioni gestite di Kubernetes.
Per distribuire il traffico ai cluster Kubernetes in esecuzione su piattaforme cloud diverse, puoi utilizzare un servizio DNS che supporti i record ponderati e incorpori il controllo di integrità.
Devi anche assicurarti di poter eseguire il pull dell'immagine nell'ambiente di destinazione. Ciò significa che devi essere in grado di accedere al registro delle immagini in caso di emergenza. Una buona opzione indipendente dalla piattaforma è Artifact Registry.
Trasferimento di dati
Il trasferimento dei dati è un componente fondamentale degli scenari di RE cross-platform. Assicurati di progettare, implementare e testare gli scenari di RE cross-platform utilizzando mockup realistici di ciò che richiede lo scenario di trasferimento dei dati di RE. Nella sezione successiva vengono descritti gli scenari di trasferimento dei dati.
Servizio di backup e RE
Il servizio di Backup e DR è una soluzione di backup e RE per i workload cloud. Ti aiuta a recuperare i dati e riprendere le operazioni aziendali critiche e supporta diversi Google Cloud prodotti e database di terze parti e sistemi di archiviazione dei dati.
Per ulteriori informazioni, vedi la panoramica del servizio di Backup e DR.
Pattern per il RE
Questa sezione illustra alcuni dei pattern più comuni per le architetture di RE basati sui blocchi di base descritti in precedenza.
Trasferimento dei dati da e verso Google Cloud
Un aspetto importante del tuo piano di RE è la velocità con cui i dati possono essere trasferiti da e verso Google Cloud. Ciò è fondamentale se il tuo piano di RE si basa sullo spostamento dei dati da on-premise a Google Cloud o da un altro cloud provider a Google Cloud. Questa sezione illustra i servizi di networking e Google Cloud che possono garantire una buona velocità effettiva.
Quando utilizzi Google Cloud come sito di ripristino per i workload on-premise o in un altro ambiente cloud, considera i seguenti elementi chiave:
- Come ti connetti a Google Cloud?
- Qual è la larghezza di banda tra te e il fornitore di interconnessione?
- Qual è la larghezza di banda fornita direttamente dal provider a Google Cloud?
- Quali altri dati verranno trasferiti utilizzando questo link?
Per saperne di più sul trasferimento dei dati a Google Cloud, consulta Eseguire la migrazione a Google Cloud: trasferire i set di dati di grandi dimensioni.
Bilanciamento della configurazione delle immagini e della velocità di deployment
Quando configuri un'immagine macchina per il deployment di nuove istanze, considera l'effetto che la configurazione avrà sulla velocità di deployment. Esiste un compromesso tra la quantità di preconfigurazione dell'immagine, i costi di manutenzione dell'immagine e la velocità di deployment. Ad esempio, se un'immagine della macchina è configurata in modo minimale, le istanze che la utilizzano richiedono più tempo per l'avvio, perché devono scaricare e installare le dipendenze. D'altra parte, se l'immagine macchina è altamente configurata, le istanze che la utilizzano vengono avviate più rapidamente, ma devi aggiornarla più spesso. Il tempo impiegato per avviare un'istanza completamente operativa sarà direttamente correlato al tuo RTO.
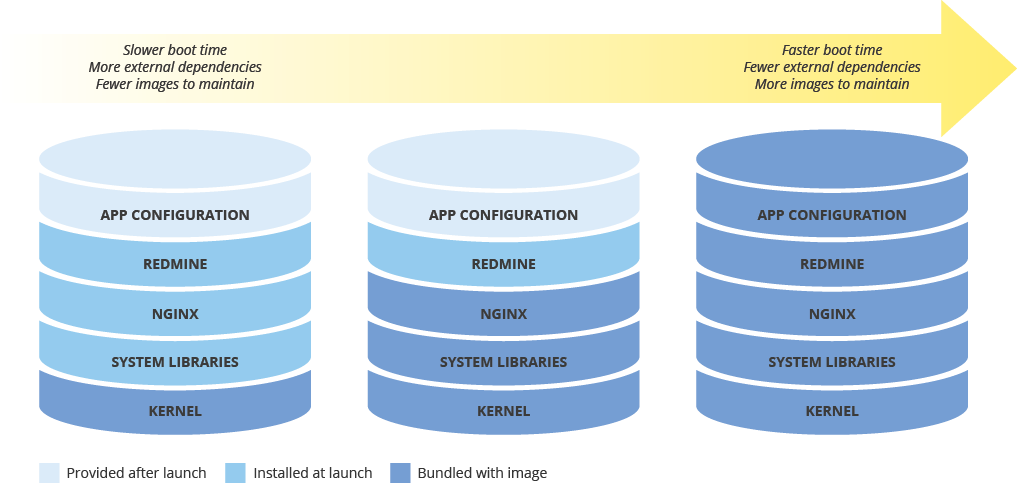
Mantenere la coerenza delle immagini macchina in ambienti ibridi
Se implementi una soluzione ibrida (on-premise-to-cloud o cloud-to-cloud), devi trovare un modo per mantenere la coerenza delle immagini negli ambienti di produzione.
Se è necessaria un'immagine completamente configurata, valuta la possibilità di utilizzare Packer, che può creare immagini della macchina identiche per più piattaforme. Puoi utilizzare gli stessi script con file di configurazione specifici della piattaforma. Nel caso di Packer, puoi inserire il file di configurazione nel controllo delle versioni per tenere traccia della versione di cui è stato eseguito il deployment in produzione.
In alternativa, puoi utilizzare strumenti di gestione della configurazione come Chef, Puppet, Ansible o Saltstack per configurare le istanze con una granularità più fine, creando immagini di base, immagini con configurazione minima o immagini completamente configurate in base alle esigenze.
Puoi anche convertire e importare manualmente le immagini esistenti, come le AMI Amazon, le immagini VirtualBox e le immagini disco RAW, in Compute Engine.
Implementazione dell'archiviazione a livelli
Il pattern di archiviazione a livelli viene in genere utilizzato per i backup in cui il backup più recente si trova su uno spazio di archiviazione più veloce e i backup meno recenti vengono migrati lentamente a uno spazio di archiviazione più economico (ma lento). Se applichi questo pattern, esegui la migrazione dei backup tra bucket di classi di archiviazione diverse, in genere da Standard a classi di archiviazione a costi inferiori, come Nearline e Coldline.
Per implementare questo pattern, puoi utilizzare la gestione del ciclo di vita degli oggetti. Ad esempio, puoi modificare automaticamente la classe di archiviazione degli oggetti più vecchi di un determinato periodo di tempo in Coldline.
Passaggi successivi
- Scopri di più su aree geografiche e regioni.Google Cloud
Leggi altri articoli di questa serie RE:
- Guida alla pianificazione del ripristino di emergenza
- Scenari di ripristino di emergenza dei dati
- Scenari di ripristino di emergenza per le applicazioni
- Progettazione ripristino di emergenza per i workload con limitazioni a livello di località
- Casi d'uso di ripristino di emergenza: applicazioni di analisi dei dati con limitazioni di località
- Progettazione ripristino di emergenza per interruzioni dell'infrastruttura cloud
Per ulteriori architetture di riferimento, diagrammi e best practice, esplora il Cloud Architecture Center.
Collaboratori
Autori:
- Grace Mollison | Solutions Lead
- Marco Ferrari | Cloud Solutions Architect