Este artículo forma parte de una serie en la que se explica la recuperación tras fallos en Google Cloud. En esta parte se describe el proceso para diseñar cargas de trabajo con Google Cloud y componentes que sean resistentes a las interrupciones de la infraestructura de la nube.
La serie consta de las siguientes partes:
- Guía de planificación para la recuperación tras fallos
- Componentes básicos de recuperación tras fallos
- Situaciones de recuperación tras fallos con los datos
- Situaciones de recuperación tras fallos de aplicaciones
- Diseñar la recuperación tras fallos para cargas de trabajo con restricciones de localidad
- Casos prácticos de recuperación ante desastres: aplicaciones de analíticas de datos restringidas por localidad
- Diseñar la recuperación tras fallos para interrupciones de la infraestructura en la nube (este documento)
Introducción
A medida que las empresas migran cargas de trabajo a la nube pública, deben adaptar sus conocimientos sobre la creación de sistemas on-premise resilientes a la infraestructura hiperescalable de proveedores de la nube como Google Cloud. En este artículo se relacionan conceptos estándar del sector sobre la recuperación tras desastres, como el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO), con la infraestructura de Google Cloud.
Las directrices de este documento siguen uno de los principios clave de Google para lograr una disponibilidad del servicio extremadamente alta: planificar los fallos. Aunque Google Cloud proporciona un servicio extremadamente fiable, se producirán desastres (desastres naturales, cortes de fibra y fallos complejos e impredecibles de la infraestructura) que provocarán interrupciones. La planificación de las interrupciones permite a los clientes crear aplicaciones que funcionen de forma predecible durante estos eventos inevitables mediante el uso de productos con mecanismos de recuperación tras fallos "integrados".Google Cloud Google Cloud
La recuperación tras fallos es un tema amplio que abarca mucho más que los fallos de infraestructura, como los errores de software o la corrupción de datos, por lo que debes tener un plan integral de principio a fin. Sin embargo, este artículo se centra en una parte de un plan de recuperación tras fallos general: cómo diseñar aplicaciones que sean resistentes a las interrupciones de la infraestructura de la nube. En concreto, en este artículo se explica lo siguiente:
- La Google Cloud infraestructura, cómo se manifiestan los desastres comoGoogle Cloud interrupciones y cómo se Google Cloud ha diseñado para minimizar la frecuencia y el alcance de las interrupciones.
- Una guía de planificación de la arquitectura que proporciona un marco para categorizar y diseñar aplicaciones en función de los resultados de fiabilidad deseados.
- Una lista detallada de productos Google Cloud seleccionados que ofrecen funciones de recuperación ante desastres integradas que puede usar en su aplicación.
Para obtener más información sobre la planificación general de la recuperación tras fallos y el uso de Google Cloud como componente de tu estrategia de recuperación tras fallos local, consulta la guía de planificación de la recuperación tras fallos. Además, aunque la alta disponibilidad es un concepto estrechamente relacionado con la recuperación tras desastres, no se trata en este artículo. Para obtener más información sobre cómo diseñar una arquitectura de alta disponibilidad, consulta el framework Well-Architected.
Nota sobre la terminología: en este artículo se habla de disponibilidad cuando se hace referencia a la capacidad de acceder a un producto y usarlo de forma significativa a lo largo del tiempo, mientras que fiabilidad hace referencia a un conjunto de atributos que incluyen la disponibilidad, pero también aspectos como la durabilidad y la corrección.
Cómo Google Cloud se ha diseñado para ofrecer resiliencia
Centros de datos de Google
Los centros de datos tradicionales se basan en maximizar la disponibilidad de los componentes individuales. En la nube, la escala permite a operadores como Google distribuir servicios en muchos componentes mediante tecnologías de virtualización y, por lo tanto, superar la fiabilidad de los componentes tradicionales. Esto significa que puedes cambiar tu mentalidad sobre la arquitectura de fiabilidad y dejar de preocuparte por los innumerables detalles que antes te preocupaban en las instalaciones locales. En lugar de preocuparte por los distintos modos de fallo de los componentes (como la refrigeración y el suministro de energía), puedes planificar los Google Cloud productos y sus métricas de fiabilidad. Estas métricas reflejan el riesgo de interrupción agregado de toda la infraestructura subyacente. De esta forma, puedes centrarte mucho más en el diseño, el despliegue y las operaciones de las aplicaciones en lugar de en la gestión de la infraestructura.
Google diseña su infraestructura para cumplir objetivos de disponibilidad ambiciosos basados en nuestra amplia experiencia en la creación y gestión de centros de datos modernos. Google es una empresa líder a nivel mundial en el diseño de centros de datos. Desde la energía hasta la refrigeración y las redes, cada tecnología de los centros de datos tiene sus propias redundancias y medidas de mitigación, incluidos los planes de FMEA. Los centros de datos de Google se construyen de forma que se equilibren los diferentes riesgos y se ofrezca a los clientes un nivel de disponibilidad esperado constante para los productos de Google Cloud . Google utiliza su experiencia para modelizar la disponibilidad de la arquitectura general del sistema físico y lógico con el fin de asegurarse de que el diseño del centro de datos cumpla las expectativas. Los ingenieros de Google hacen todo lo posible para que se cumplan esas expectativas. La disponibilidad medida real suele superar nuestros objetivos de diseño con un margen considerable.
Al destilar todos estos riesgos y mitigaciones de los centros de datos en productos orientados a los usuarios, Google Cloud te libera de esas responsabilidades de diseño y operativas. En su lugar, puedes centrarte en la fiabilidad de lasGoogle Cloud regiones y zonas.
Regiones y zonas
Las regiones son áreas geográficas independientes que están formadas por zonas. Las zonas y las regiones son abstracciones lógicas de los recursos físicos subyacentes. Para obtener más información sobre las consideraciones específicas de cada región, consulta el artículo Geografía y regiones.
Los productos deGoogle Cloud se dividen en recursos de zona, recursos regionales o recursos multirregionales.
Los recursos de zona se alojan en una sola zona. Una interrupción del servicio en esa zona puede afectar a todos los recursos de la zona. Por ejemplo, una instancia de Compute Engine se ejecuta en una zona específica. Si se produce un fallo de hardware que interrumpe el servicio en esa zona, la instancia de Compute Engine no estará disponible mientras dure la interrupción.
Los recursos regionales se despliegan de forma redundante en varias zonas de una región. De esta manera, tienen una mayor fiabilidad que los recursos de zona.
Los recursos multirregionales se distribuyen dentro de las regiones y en distintas regiones. En general, los recursos multirregionales tienen una fiabilidad mayor que los recursos regionales. Sin embargo, en este nivel, los productos deben optimizar la disponibilidad, el rendimiento y la eficiencia de los recursos. Por lo tanto, es importante que conozcas las ventajas y desventajas de cada producto multirregional que decidas usar. Las medidas que se toman para conseguir ese equilibrio se documentan por separado para cada producto más adelante en este documento.
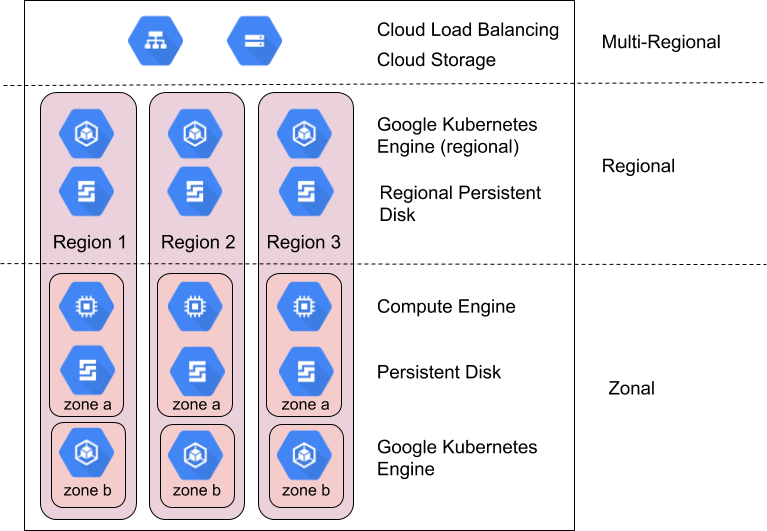
Cómo aprovechar las zonas y las regiones para lograr la fiabilidad
Los ingenieros de fiabilidad de sitios de Google gestionan y escalan productos para usuarios globales de alta fiabilidad, como Gmail y la Búsqueda, mediante diversas técnicas y tecnologías que aprovechan sin problemas la infraestructura informática de todo el mundo. Esto incluye desviar el tráfico de las ubicaciones no disponibles mediante el balanceo de carga global, ejecutar varias réplicas en muchas ubicaciones de todo el mundo y replicar datos en varias ubicaciones. Estas mismas funciones están disponibles para los clientes a través de productos como Cloud Load Balancing, Google Kubernetes Engine (GKE) y Spanner. Google Cloud
Google Cloud suele diseñar sus productos para que ofrezcan los siguientes niveles de disponibilidad en las zonas y regiones:
| Recurso | Ejemplos | Objetivo de diseño de disponibilidad | Tiempo de inactividad implícito |
|---|---|---|---|
| Por zonas | Compute Engine, Persistent Disk | 99,9 % | 8,75 horas al año |
| Regional | Cloud Storage regional, Persistent Disk replicado y GKE regional | 99,99 % | 52 minutos al año |
Compara los Google Cloud objetivos de diseño de disponibilidad Google Cloud con el tiempo de inactividad aceptable para identificar los recursos adecuados. Mientras que los diseños tradicionales se centran en mejorar la disponibilidad a nivel de componente para mejorar la disponibilidad de la aplicación resultante, los modelos de nube se centran en la composición de los componentes para lograr este objetivo. Muchos productos deGoogle Cloud usan esta técnica. Por ejemplo, Spanner ofrece una base de datos multirregional que se compone de varias regiones para ofrecer una disponibilidad del 99,999 %.
La composición es importante porque, sin ella, la disponibilidad de tu aplicación no puede superar la de los Google Cloud productos que usas. De hecho, a menos que tu aplicación nunca falle, tendrá una disponibilidad inferior a la de los productosGoogle Cloud subyacentes. En el resto de esta sección se muestra cómo puede usar una composición de productos zonales y regionales para conseguir una disponibilidad de la aplicación mayor que la que proporcionaría una sola zona o región. En la siguiente sección se ofrece una guía práctica para aplicar estos principios a tus aplicaciones.
Planificar los ámbitos de las interrupciones de zonas
Los fallos de infraestructura suelen provocar interrupciones del servicio en una sola zona. Dentro de una región, las zonas se diseñan para minimizar el riesgo de fallos correlacionados con otras zonas, y una interrupción del servicio en una zona no suele afectar al servicio de otra zona de la misma región. Si una interrupción se limita a una zona, no significa necesariamente que toda la zona no esté disponible, sino que solo define el límite del incidente. Es posible que una interrupción de una zona no tenga ningún efecto tangible en tus recursos de esa zona.
Aunque es menos habitual, también es importante tener en cuenta que, en algún momento, varias zonas seguirán experimentando una interrupción correlacionada en una misma región. Cuando se produce una interrupción en dos o más zonas, se aplica la estrategia de ámbito de interrupción regional que se indica a continuación.
Los recursos regionales se han diseñado para resistir a las interrupciones de las zonas, ya que ofrecen servicio desde una composición de varias zonas. Si se interrumpe una de las zonas que respaldan un recurso regional, el recurso se pone automáticamente a disposición desde otra zona. Consulta detenidamente la descripción de las funciones del producto en el apéndice para obtener más información.
Google Cloud solo ofrece algunos recursos de zona, como las máquinas virtuales (VMs) de Compute Engine y Persistent Disk. Si tienes previsto usar recursos zonales, tendrás que llevar a cabo tu propia composición de recursos diseñando, creando y probando la conmutación por error y la recuperación entre recursos zonales ubicados en varias zonas. Algunas estrategias son las siguientes:
- Dirigir rápidamente el tráfico a máquinas virtuales de otra zona mediante Cloud Load Balancing cuando una comprobación de estado determina que una zona tiene problemas.
- Usa plantillas de instancias de Compute Engine o grupos de instancias gestionados para ejecutar y escalar instancias de VM idénticas en varias zonas.
- Usa un disco persistente regional para replicar datos de forma síncrona en otra zona de una región. Consulta más información sobre las opciones de alta disponibilidad con discos persistentes regionales.
Planificar los ámbitos de las interrupciones regionales
Una interrupción regional es una interrupción del servicio que afecta a más de una zona de una región. Se trata de interrupciones a mayor escala y menos frecuentes, que pueden deberse a desastres naturales o a fallos de infraestructuras a gran escala.
En el caso de un producto regional diseñado para ofrecer una disponibilidad del 99,99 %, una interrupción puede traducirse en casi una hora de inactividad al año para un producto concreto. Por lo tanto, es posible que tus aplicaciones críticas necesiten un plan de recuperación tras desastres multirregional si no puedes permitirte que se produzca una interrupción de este tipo.
Los recursos multirregionales se han diseñado para resistir a las interrupciones de servicio de las regiones, ya que ofrecen servicio desde varias regiones. Como se ha descrito anteriormente, los productos multirregionales ofrecen un equilibrio entre latencia, coherencia y coste. La compensación más habitual se da entre la replicación de datos síncrona y asíncrona. La replicación asíncrona ofrece una latencia más baja, pero conlleva el riesgo de perder datos durante una interrupción. Por lo tanto, es importante consultar la descripción de las funciones del producto en el apéndice para obtener más información.
Si quieres usar recursos regionales y mantener la resiliencia ante interrupciones regionales, debes realizar tu propia composición de recursos diseñando, creando y probando su conmutación por error y recuperación entre recursos regionales ubicados en varias regiones. Además de las estrategias zonales que se han descrito anteriormente y que también puedes aplicar en varias regiones, ten en cuenta lo siguiente:
- Los recursos regionales deben replicar los datos en una región secundaria, en una opción de almacenamiento multirregional, como Cloud Storage, o en una opción de nube híbrida, como GKE y Google Distributed Cloud.
- Una vez que hayas implementado una mitigación de interrupciones regionales, pruébala periódicamente. Hay pocas cosas peores que pensar que eres resistente a una interrupción de una sola región y descubrir que no es así cuando ocurre de verdad.
Google Cloud enfoque de resiliencia y disponibilidad
Google Cloud supera con frecuencia los objetivos de diseño de disponibilidad, pero no debes dar por hecho que este buen rendimiento anterior es la disponibilidad mínima que puedes diseñar. En su lugar, debes seleccionar Google Cloud dependencias cuyos objetivos de diseño superen la fiabilidad prevista de tu aplicación, de modo que el tiempo de inactividad de tu aplicación más el tiempo de inactividad de la dependencia Google Cloud proporcione el resultado que buscas.
Un sistema bien diseñado puede responder a la pregunta: "¿Qué ocurre cuando una zona o región sufre una interrupción de 1, 5, 10 o 30 minutos?". Esto debe tenerse en cuenta en muchos niveles, como los siguientes:
- ¿Qué experimentarán mis clientes durante una interrupción?
- ¿Cómo puedo saber si se ha producido una interrupción del servicio?
- ¿Qué ocurre con mi aplicación durante una interrupción?
- ¿Qué ocurre con mis datos durante una interrupción?
- ¿Qué ocurre con mis otras aplicaciones debido a una interrupción (por dependencias cruzadas)?
- ¿Qué debo hacer para recuperarme después de que se haya resuelto una interrupción? ¿Quién lo hace?
- ¿A quién debo avisar de una interrupción y en qué plazo?
Guía paso a paso para diseñar la recuperación tras desastres de aplicaciones en Google Cloud
En las secciones anteriores se ha explicado cómo crea Google la infraestructura de nube y algunas estrategias para hacer frente a las interrupciones zonales y regionales.
En esta sección se explica cómo desarrollar un marco para aplicar el principio de composición a tus aplicaciones en función de los resultados de fiabilidad que quieras obtener.
Las aplicaciones del cliente en Google Cloud que tengan como objetivo la recuperación tras desastres, como los objetivos de tiempo de recuperación (RTO) y de punto de recuperación (RPO), deben diseñarse de forma que las operaciones críticas para la empresa, sujetas a los RTO y RPO, solo dependan de los componentes del plano de datos que se encarguen del procesamiento continuo de las operaciones del servicio. En otras palabras, estas operaciones críticas para el negocio del cliente no deben depender de las operaciones del plano de gestión, que gestionan el estado de la configuración y envían la configuración al plano de control y al plano de datos.
Por ejemplo, Google Cloud los clientes que quieran conseguir un tiempo de recuperación ante desastres para operaciones críticas no deben depender de una API de creación de VMs ni de la actualización de un permiso de gestión de identidades y accesos.
Paso 1: Recopila los requisitos actuales
El primer paso es definir los requisitos de disponibilidad de tus aplicaciones. La mayoría de las empresas ya tienen un nivel de directrices de diseño en este ámbito, que pueden haber desarrollado internamente o derivarse de normativas u otros requisitos legales. Estas directrices de diseño se codifican normalmente en dos métricas clave: el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO). En términos empresariales, el RTO se traduce como "¿Cuánto tiempo después de un desastre puedo volver a estar operativo?". El RPO se traduce como "¿Cuántos datos puedo permitirme perder en caso de desastre?".

Tradicionalmente, las empresas han definido los requisitos de RTO y RPO para una amplia gama de desastres, desde fallos de componentes hasta terremotos. Esto tenía sentido en el mundo on-premise, donde los planificadores tenían que asignar los requisitos de RTO y RPO a toda la pila de software y hardware. En la nube, ya no es necesario que definas tus requisitos con tanto detalle, ya que el proveedor se encarga de ello. En su lugar, puedes definir tus requisitos de RTO y RPO en términos del ámbito de pérdida (zonas o regiones completas) sin especificar los motivos subyacentes. Google Cloud De esta forma, solo tendrás que tener en cuenta tres escenarios: un fallo en una zona, un fallo en una región o un fallo en varias regiones (algo muy poco probable).
Como no todas las aplicaciones tienen la misma importancia, la mayoría de los clientes clasifican sus aplicaciones en niveles de importancia para los que se puede aplicar un requisito de RTO o RPO específico. Si se tienen en cuenta conjuntamente, el RTO y el RPO, así como la criticidad de la aplicación, se optimiza el proceso de diseño de una aplicación determinada, ya que se responde a las siguientes preguntas:
- ¿La aplicación debe ejecutarse en varias zonas de la misma región o en varias zonas de varias regiones?
- ¿De qué Google Cloud productos puede depender la aplicación?
Este es un ejemplo del resultado del ejercicio de recogida de requisitos:
RTO y RPO por criticidad de la aplicación de la empresa de ejemplo:
| Criticidad de la aplicación | % de las aplicaciones | Aplicaciones de ejemplo | Interrupción de zona | Interrupción del servicio regional |
|---|---|---|---|---|
| Nivel 1
(más importante) |
5 % | Normalmente, se trata de aplicaciones globales o externas orientadas a los clientes, como las de pagos en tiempo real y las escaparates de comercio electrónico. | RTO Cero
RPO Zero |
RTO Cero
RPO Zero |
| Nivel 2 | 35 % | Normalmente, se trata de aplicaciones regionales o internas importantes, como CRM o ERP. | RTO 15 min
RPO 15 min |
RTO 1 h
RPO 1 h |
| Nivel 3
(menos importante) |
60 % | Normalmente, se trata de aplicaciones de equipos o departamentos, como las de gestión interna, reserva de vacaciones, viajes internos, contabilidad y recursos humanos. | RTO 1 h
RPO 1 h |
RTO 12 horas
RPO 12hrs |
Paso 2: Asignación de funciones a los productos disponibles
El segundo paso es conocer las funciones de resiliencia de los productos de Google Cloud que usarán tus aplicaciones. La mayoría de las empresas revisan la información del producto pertinente y, a continuación, añaden directrices sobre cómo modificar sus arquitecturas para cubrir las posibles carencias entre las funciones del producto y sus requisitos de resiliencia. En esta sección se tratan algunas áreas habituales y recomendaciones sobre las limitaciones de datos y aplicaciones en este espacio.
Como se ha mencionado anteriormente, los productos de Google con recuperación ante desastres se adaptan a dos tipos de interrupciones: regionales y de zona. Las interrupciones parciales se deben planificar de la misma forma que las interrupciones completas en lo que respecta a la recuperación ante desastres. Esto proporciona una matriz inicial de alto nivel de los productos que son adecuados para cada situación de forma predeterminada:
Google Cloud Funciones generales de los productos
(consulta el apéndice para ver las funciones específicas de cada producto)
| Todos los productos de Google Cloud | Productos regionales Google Cloud con replicación automática en zonas | Productos multirregionales o globales Google Cloud con replicación automática entre regiones | |
|---|---|---|---|
| Fallo de un componente en una zona | Cubierto* | Con cobertura | Con cobertura |
| Interrupción de zona | No cubierto | Con cobertura | Con cobertura |
| Interrupción del servicio regional | No cubierto | No cubierto | Con cobertura |
* Todos Google Cloud los productos son resistentes a los fallos de los componentes, excepto en los casos específicos que se indican en la documentación del producto. Normalmente, se trata de situaciones en las que el producto ofrece acceso directo o asignación estática a un hardware especializado, como la memoria o las unidades de estado sólido (SSD).
Cómo limitan las RPOs las opciones de productos
En la mayoría de las implementaciones en la nube, la integridad de los datos es el aspecto más importante que se debe tener en cuenta en un servicio. Al menos algunas aplicaciones tienen un requisito de RPO de cero, lo que significa que no debería haber pérdida de datos en caso de interrupción. Para ello, normalmente es necesario que los datos se repliquen de forma síncrona en otra zona o región. La replicación síncrona tiene ventajas e inconvenientes en cuanto a costes y latencia, por lo que, aunque muchos Google Cloud productos ofrecen replicación síncrona entre zonas, solo unos pocos la ofrecen entre regiones. Esta compensación entre coste y complejidad significa que no es raro que los diferentes tipos de datos de una aplicación tengan valores de RPO distintos.
En el caso de los datos con un RPO superior a cero, las aplicaciones pueden aprovechar la replicación asíncrona. La replicación asíncrona es aceptable cuando los datos perdidos se pueden volver a crear fácilmente o se pueden recuperar de una fuente de datos fiable si es necesario. También puede ser una opción razonable cuando se acepta una pequeña pérdida de datos a cambio de la duración prevista de las interrupciones zonales y regionales. También es importante tener en cuenta que, durante una interrupción transitoria, los datos escritos en la ubicación afectada, pero que aún no se han replicado en otra ubicación, suelen estar disponibles una vez que se resuelve la interrupción. Esto significa que el riesgo de perder datos permanentemente es menor que el riesgo de perder el acceso a los datos durante una interrupción.
Acciones clave: determina si necesitas un RPO cero y, si es así, si puedes hacerlo con un subconjunto de tus datos. Esto aumenta considerablemente la gama de servicios habilitados para la recuperación ante desastres que tienes a tu disposición. En Google Cloud, conseguir un RPO cero significa usar principalmente productos regionales para tu aplicación, que de forma predeterminada son resistentes a las interrupciones a nivel de zona, pero no a nivel de región.
Cómo limitan las restricciones de RTO las opciones de productos
Una de las principales ventajas del cloud computing es la capacidad de implementar infraestructura bajo demanda. Sin embargo, no es lo mismo que la implementación instantánea. El valor de RTO de tu aplicación debe tener en cuenta el RTO combinado de los Google Cloud productos que utiliza tu aplicación y las acciones que deben llevar a cabo tus ingenieros o ingenieros de fiabilidad de sitios para reiniciar tus máquinas virtuales o componentes de la aplicación. Un tiempo de recuperación tras un desastre medido en minutos significa diseñar una aplicación que se recupere automáticamente de un desastre sin intervención humana o con pasos mínimos, como pulsar un botón para activar la conmutación por error. Históricamente, el coste y la complejidad de este tipo de sistemas han sido muy elevados, pero los Google Cloud productos, como los balanceadores de carga y los grupos de instancias, hacen que este diseño sea mucho más asequible y sencillo. Por lo tanto, deberías plantearte la conmutación por error y la recuperación automáticas para la mayoría de las aplicaciones. Ten en cuenta que diseñar un sistema para este tipo de conmutación por error activa entre regiones es complicado y caro. Solo una pequeña parte de los servicios críticos justifica esta función.
La mayoría de las aplicaciones tendrán un RTO de entre una hora y un día, lo que permite una conmutación por error en caliente en caso de desastre, con algunos componentes de la aplicación en modo de espera (como las bases de datos) y otros escalados en caso de desastre real (como los servidores web). En estas aplicaciones, te recomendamos que automatices los eventos de escalado horizontal. Los servicios con un RTO de más de un día tienen la criticidad más baja y, a menudo, se pueden recuperar a partir de una copia de seguridad o recrear desde cero.
Acciones clave: determina si necesitas un tiempo de recuperación ante desastres (RTO) de (casi) cero para la conmutación por error regional y, si es así, si puedes hacerlo en un subconjunto de tus servicios. Esto cambia el coste de ejecutar y mantener tu servicio.
Paso 3: Desarrolla tus propias arquitecturas de referencia y guías
El último paso recomendado es crear tus propios patrones de arquitectura específicos de la empresa para ayudar a tus equipos a estandarizar su enfoque de recuperación ante desastres. La mayoría de los clientes Google Cloud elaboran una guía para sus equipos de desarrollo que se ajusta a sus expectativas de resiliencia empresarial en las dos categorías principales de escenarios de interrupción de Google Cloud. De esta forma, los equipos pueden categorizar fácilmente qué productos con recuperación ante desastres son adecuados para cada nivel de criticidad.
Crear directrices de productos
Si volvemos a la tabla de RTO y RPO del ejemplo anterior, tienes una guía hipotética que indica qué productos se permitirían de forma predeterminada en cada nivel de criticidad. Ten en cuenta que, aunque se hayan identificado determinados productos como no aptos de forma predeterminada, siempre puedes añadir tus propios mecanismos de replicación y conmutación por error para habilitar la sincronización entre zonas o regiones. Sin embargo, este ejercicio va más allá del alcance de este artículo. Las tablas también incluyen enlaces a más información sobre cada producto para ayudarte a entender sus funciones en relación con la gestión de las interrupciones de zonas o regiones.
Patrones de arquitectura de ejemplo de la empresa Example Organization Co: interrupción de la zona Resiliencia
| Google Cloud Producto | ¿El producto cumple los requisitos de interrupción zonal de Example Organization (con la configuración de producto adecuada)? | ||
|---|---|---|---|
| Nivel 1 | Nivel 2 | Nivel 3 | |
| Compute Engine | No | No | No |
| Dataflow | No | No | No |
| BigQuery | No | No | Sí |
| GKE | Sí | Sí | Sí |
| Cloud Storage | Sí | Sí | Sí |
| Cloud SQL | No | Sí | Sí |
| Spanner | Sí | Sí | Sí |
| Cloud Load Balancing | Sí | Sí | Sí |
Esta tabla es solo un ejemplo basado en los niveles hipotéticos que se muestran arriba.
Patrones de arquitectura de ejemplo para la empresa de ejemplo Co: resiliencia ante interrupciones en una región
| Google Cloud Producto | ¿El producto cumple los requisitos de interrupción de la región de Ejemplo Organización (con la configuración de producto adecuada)? | ||
|---|---|---|---|
| Nivel 1 | Nivel 2 | Nivel 3 | |
| Compute Engine | Sí | Sí | Sí |
| Dataflow | No | No | No |
| BigQuery | No | No | Sí |
| GKE | Sí | Sí | Sí |
| Cloud Storage | No | No | No |
| Cloud SQL | No | Sí | Sí |
| Spanner | Sí | Sí | Sí |
| Cloud Load Balancing | Sí | Sí | Sí |
Esta tabla es solo un ejemplo basado en los niveles hipotéticos que se muestran arriba.
Para mostrar cómo se usarían estos productos, en las siguientes secciones se describen algunas arquitecturas de referencia para cada uno de los niveles de criticidad de las aplicaciones hipotéticas. Se trata de descripciones de alto nivel que ilustran las decisiones arquitectónicas clave y no representan un diseño de solución completo.
Ejemplo de arquitectura de nivel 3
| Criticidad de la aplicación | Interrupción de zona | Interrupción del servicio regional |
|---|---|---|
| Nivel 3 (menos importante) |
RTO de 12 horas RPO de 24 horas |
RTO de 28 días RPO de 24 horas |
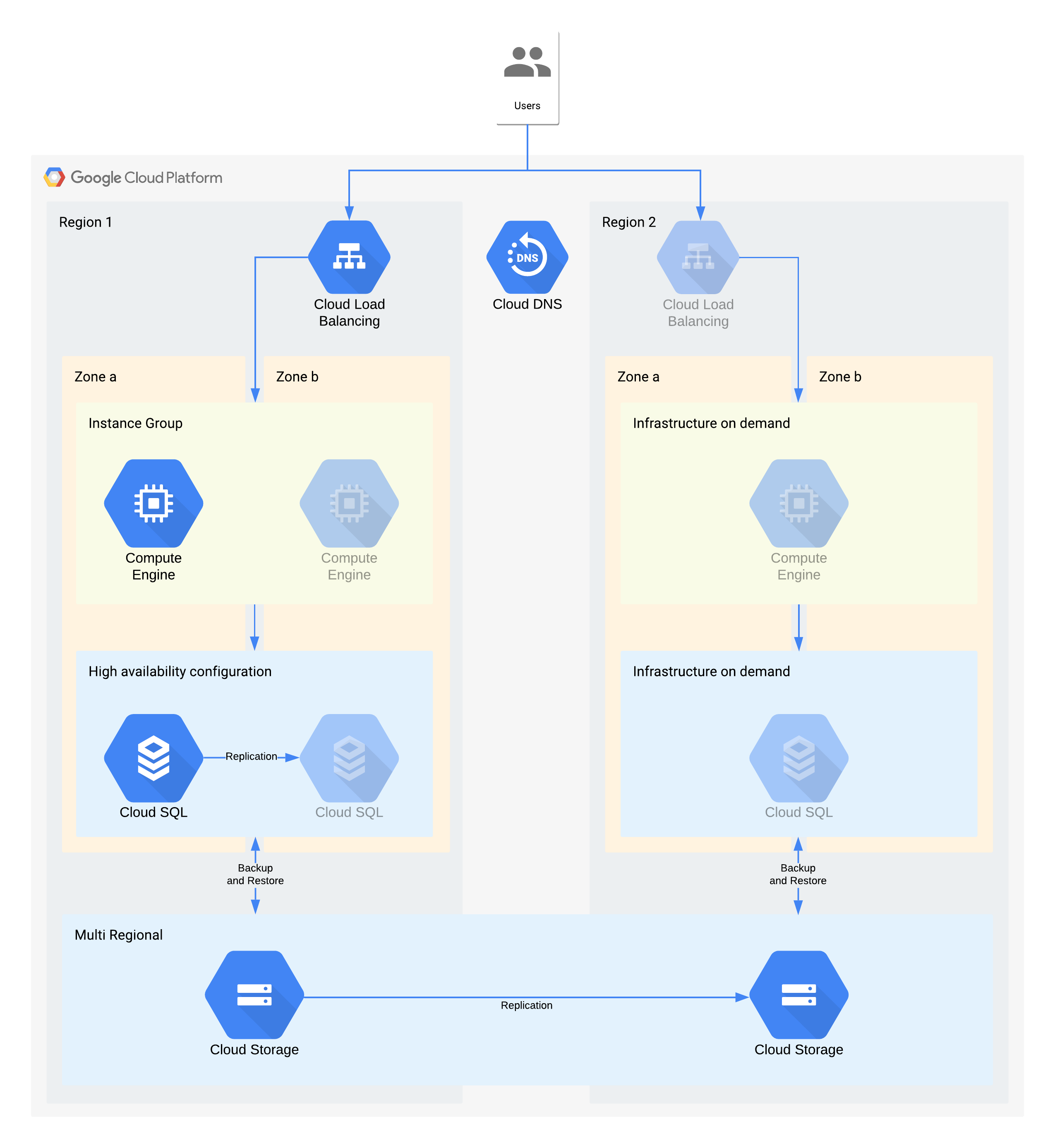
Los iconos atenuados indican que la infraestructura se debe habilitar para la recuperación.
Esta arquitectura describe una aplicación cliente/servidor tradicional: los usuarios internos se conectan a una aplicación que se ejecuta en una instancia de proceso, que está respaldada por una base de datos para el almacenamiento persistente.
Es importante tener en cuenta que esta arquitectura admite valores de RTO y RPO mejores de los necesarios. Sin embargo, también debe plantearse eliminar los pasos manuales adicionales cuando puedan resultar costosos o poco fiables. Por ejemplo, recuperar una base de datos a partir de una copia de seguridad nocturna podría admitir un RPO de 24 horas, pero normalmente se necesitaría a un experto, como un administrador de bases de datos, que podría no estar disponible, sobre todo si se vieran afectados varios servicios al mismo tiempo. Con la infraestructura bajo demanda de Google Cloud, puedes crear esta función sin tener que hacer un gran sacrificio económico. Por eso, esta arquitectura usa la alta disponibilidad de Cloud SQL en lugar de una copia de seguridad o restauración manual en caso de interrupciones zonales.
Decisiones de arquitectura clave en caso de interrupción de la zona: RTO de 12 horas y RPO de 24 horas:
- Se usa un balanceador de carga interno para proporcionar un punto de acceso escalable a los usuarios, lo que permite la conmutación por error automática a otra zona. Aunque el RTO es de 12 horas, los cambios manuales en las direcciones IP o incluso las actualizaciones de DNS pueden tardar más de lo previsto.
- Un grupo de instancias gestionado regional se configura con varias zonas, pero con recursos mínimos. De esta forma, se optimiza el coste, pero se permite que las máquinas virtuales se escalen rápidamente en la zona de copia de seguridad.
- Una configuración de alta disponibilidad de Cloud SQL permite la conmutación por error automática a otra zona. Las bases de datos son mucho más difíciles de recrear y restaurar que las máquinas virtuales de Compute Engine.
Decisiones de arquitectura clave en caso de interrupción del servicio en una región: tiempo de inactividad máximo de 28 días y tiempo de recuperación de datos de 24 horas:
- Un balanceador de carga se crearía en la región 2 solo en caso de interrupción regional. Cloud DNS se usa para proporcionar una función de conmutación por error regional manual y coordinada, ya que la infraestructura de la región 2 solo estará disponible en caso de que se produzca una interrupción en la región.
- Un nuevo grupo de instancias gestionado se crearía solo en caso de que se produjera una interrupción en una región. De esta forma, se optimiza el coste y es poco probable que se invoque, dada la corta duración de la mayoría de las interrupciones regionales. Ten en cuenta que, por motivos de simplicidad, en el diagrama no se muestra la herramienta asociada necesaria para volver a desplegar ni la copia de las imágenes de Compute Engine.
- Se volvería a crear una instancia de Cloud SQL y se restaurarían los datos a partir de una copia de seguridad. De nuevo, el riesgo de que se produzca una interrupción prolongada en una región es extremadamente bajo, por lo que se trata de otra compensación para optimizar los costes.
- Para almacenar estas copias de seguridad, se usa Cloud Storage multirregional. De esta forma, se proporciona una resiliencia automática de la zona y la región dentro del RTO y el RPO.
Ejemplo de arquitectura de nivel 2
| Criticidad de la aplicación | Interrupción de zona | Interrupción del servicio regional |
|---|---|---|
| Nivel 2 | RTO de 4 horas RPO cero |
RTO de 24 horas RPO de 4 horas |
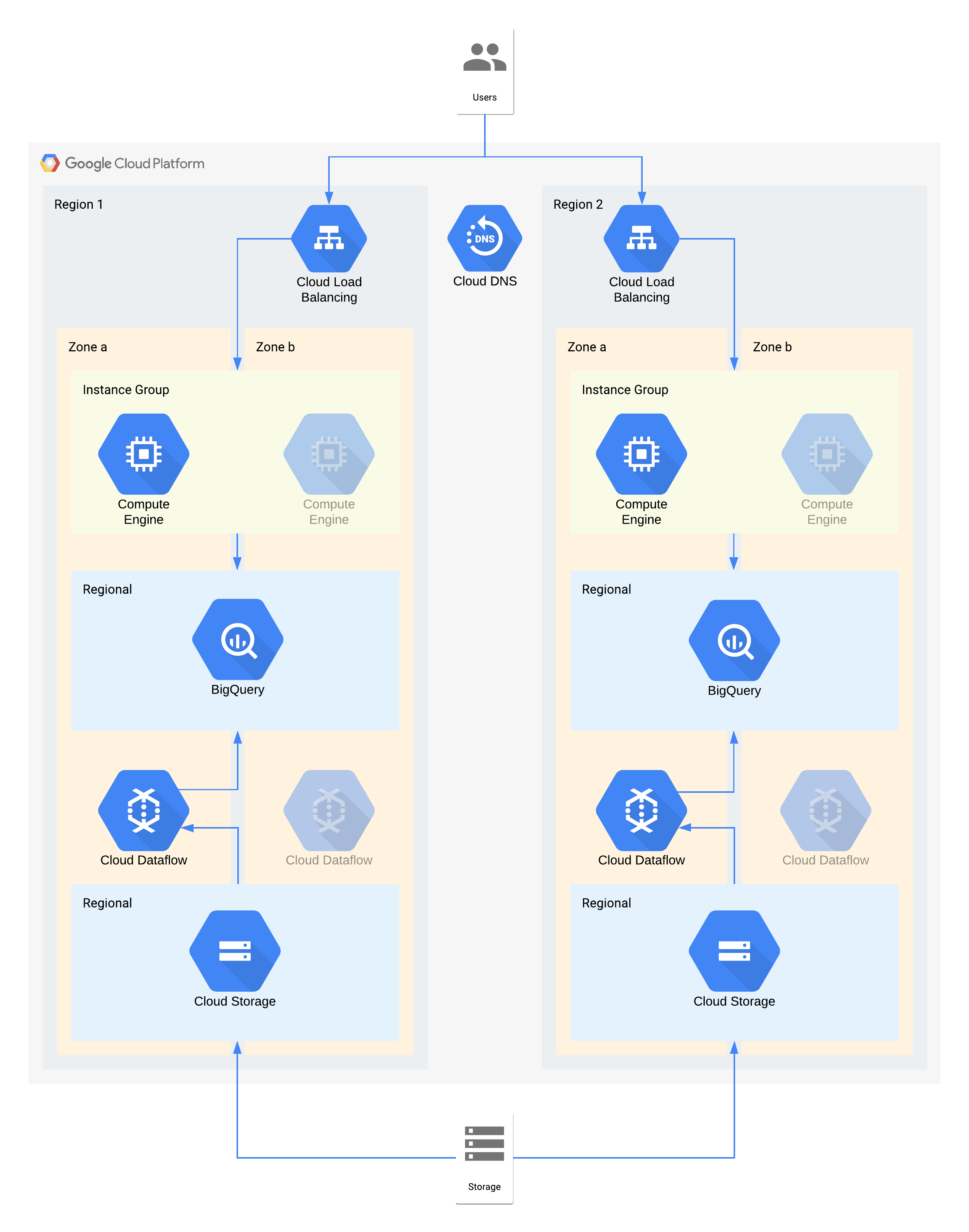
En esta arquitectura se describe un almacén de datos con usuarios internos que se conectan a una capa de visualización de instancias de computación y una capa de ingestión y transformación de datos que rellena el almacén de datos backend.
Algunos componentes individuales de esta arquitectura no admiten directamente el RPO requerido para su nivel. Sin embargo, debido a la forma en que se usan conjuntamente, el servicio en general cumple el RPO. En este caso, como Dataflow es un producto zonal, sigue las recomendaciones para diseñar una alta disponibilidad para evitar la pérdida de datos durante una interrupción. Sin embargo, la capa de Cloud Storage es la fuente principal de estos datos y admite un RPO de cero. De esta forma, puedes volver a ingerir los datos perdidos en BigQuery usando la zona b en caso de que se produzca una interrupción en la zona a.
Decisiones de arquitectura clave para una interrupción de zona: RTO de 4 horas y RPO de cero:
- Un balanceador de carga se usa para proporcionar un punto de acceso escalable a los usuarios, lo que permite la conmutación por error automática a otra zona. Aunque el RTO sea de 4 horas, los cambios manuales en las direcciones IP o incluso las actualizaciones de DNS pueden tardar más de lo previsto.
- Un grupo de instancias gestionado regional para la capa de cálculo de visualización de datos se configura con varias zonas, pero con recursos mínimos. De esta forma, se optimiza el coste, pero se permite que las máquinas virtuales se escalen horizontalmente rápidamente.
- El Cloud Storage regional se usa como capa de almacenamiento provisional para la ingestión inicial de datos, lo que proporciona resiliencia automática de las zonas.
- Dataflow se usa para extraer datos de Cloud Storage y transformarlos antes de cargarlos en BigQuery. En caso de que se produzca una interrupción en una zona, se trata de un proceso sin estado que se puede reiniciar en otra zona.
- BigQuery proporciona el backend del almacén de datos para el frontend de visualización de datos. En caso de interrupción de una zona, los datos perdidos se volverían a ingerir desde Cloud Storage.
Decisiones de arquitectura clave para las interrupciones de la región: RTO de 24 horas y RPO de 4 horas:
- Se usa un balanceador de carga en cada región para proporcionar un punto de acceso escalable a los usuarios. Cloud DNS se usa para proporcionar una función de conmutación por error regional orquestada pero manual, ya que la infraestructura de la región 2 solo estaría disponible en caso de que se produjera una interrupción en la región.
- Un grupo de instancias gestionado regional para la capa de cálculo de visualización de datos se configura con varias zonas, pero con recursos mínimos. No se puede acceder a él hasta que se vuelva a configurar el balanceador de carga, pero no requiere ninguna intervención manual.
- Cloud Storage regional se usa como capa de almacenamiento provisional para la ingestión inicial de datos. Se carga al mismo tiempo en ambas regiones para cumplir los requisitos de RPO.
- Dataflow se usa para extraer datos de Cloud Storage y transformarlos antes de cargarlos en BigQuery. En caso de que se produzca una interrupción en una región, BigQuery se rellenaría con los datos más recientes de Cloud Storage.
- BigQuery proporciona el backend del almacén de datos. En condiciones normales, se actualizaría de forma intermitente. En caso de interrupción de una región, los datos más recientes se volverían a ingerir a través de Dataflow desde Cloud Storage.
Ejemplo de arquitectura de nivel 1
| Criticidad de la aplicación | Interrupción de zona | Interrupción del servicio regional |
|---|---|---|
| Nivel 1 (más importante) |
RTO cero RPO cero |
RTO de 4 horas RPO de 1 hora |
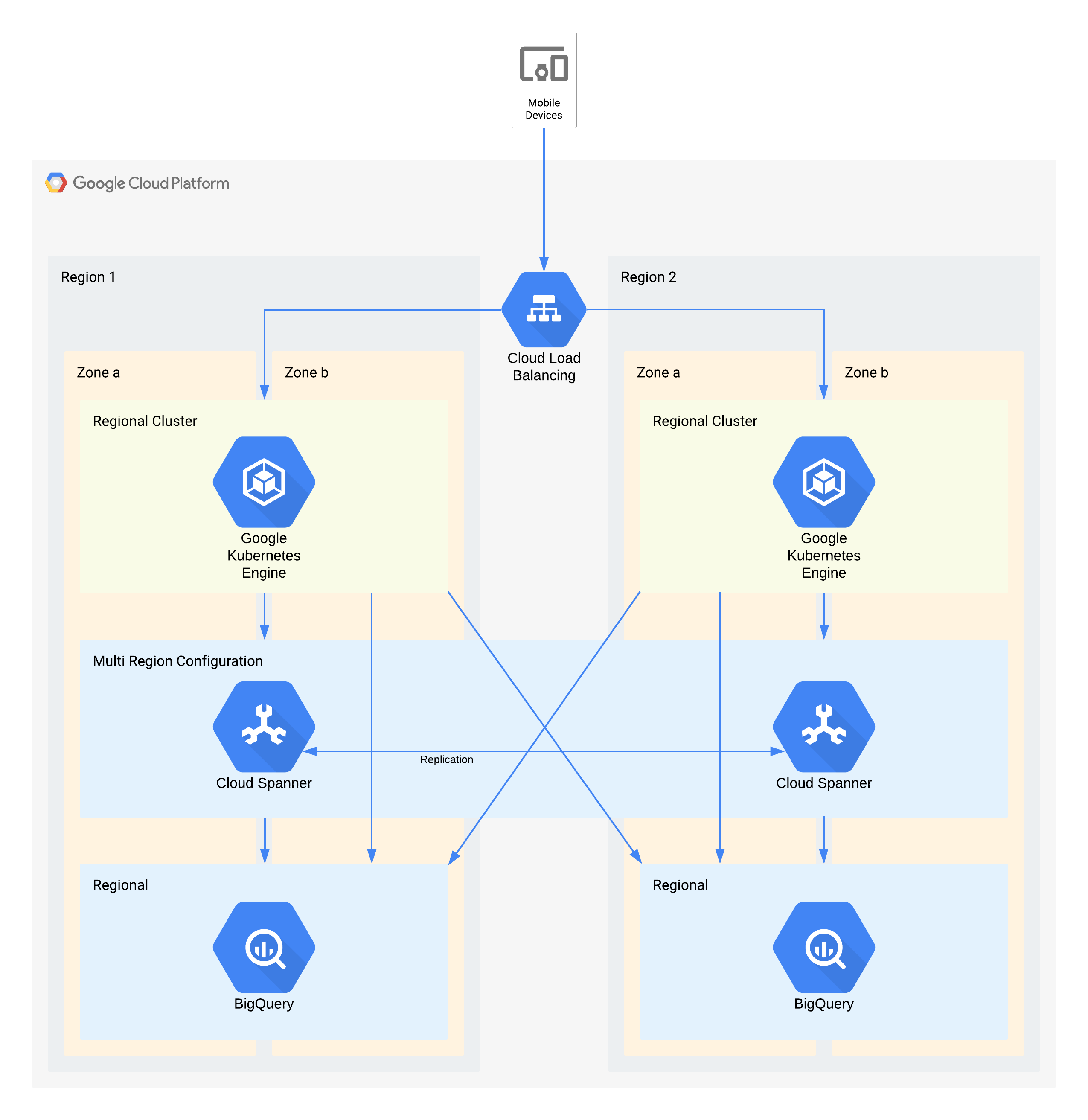
En esta arquitectura se describe una infraestructura de backend de una aplicación móvil con usuarios externos que se conectan a un conjunto de microservicios que se ejecutan en GKE. Spanner proporciona la capa de almacenamiento de datos backend para los datos en tiempo real, y los datos históricos se transmiten a un lago de datos de BigQuery en cada región.
De nuevo, algunos componentes individuales de esta arquitectura no admiten directamente el RPO necesario para su nivel, pero, debido a la forma en que se usan conjuntamente, el servicio en general sí lo hace. En este caso, BigQuery se usa para consultas analíticas. Cada región se alimenta simultáneamente desde Spanner.
Decisiones de arquitectura clave para las interrupciones de zonas: RTO y RPO cero:
- Un balanceador de carga se usa para proporcionar un punto de acceso escalable a los usuarios, lo que permite la conmutación por error automática a otra zona.
- Se usa un clúster de GKE regional para la capa de aplicación, que se configura con varias zonas. De esta forma, se consigue un RTO de cero en cada región.
- Spanner multirregional se usa como capa de persistencia de datos, lo que proporciona resiliencia automática de los datos de zona y coherencia de las transacciones.
- BigQuery proporciona la función de analíticas de la aplicación. Cada región recibe datos de Spanner de forma independiente y la aplicación accede a ellos de forma independiente.
Decisiones de arquitectura clave para las interrupciones de la región: RTO de 4 horas y RPO de 1 hora:
- Un balanceador de carga se usa para proporcionar un punto de acceso escalable a los usuarios, lo que permite la conmutación por error automática a otra región.
- Se usa un clúster de GKE regional para la capa de aplicación, que se configura con varias zonas. Si se produce una interrupción en una región, el clúster de la región alternativa se escalará automáticamente para asumir la carga de procesamiento adicional.
- Spanner multirregional se usa como capa de persistencia de datos, lo que proporciona resiliencia de datos regional y coherencia de las transacciones automáticas. Este es el componente clave para conseguir un RPO de 1 hora entre regiones.
- BigQuery proporciona la función de analíticas de la aplicación. Cada región recibe datos de Spanner de forma independiente y la aplicación accede a ellos de forma independiente. Esta arquitectura compensa el componente de BigQuery, lo que le permite cumplir los requisitos generales de la aplicación.
Apéndice: Referencia de producto
En esta sección se describe la arquitectura y las funciones de recuperación ante desastres de los productos de Google Cloud que se usan con más frecuencia en las aplicaciones de los clientes y que se pueden aprovechar fácilmente para cumplir los requisitos de recuperación ante desastres.
Temas habituales
Muchos Google Cloud productos ofrecen configuraciones regionales o multirregionales. Los productos regionales son resistentes a las interrupciones de zonas, y los productos multirregionales y globales son resistentes a las interrupciones de regiones. Por lo general, esto significa que, durante una interrupción, tu aplicación apenas se verá afectada. Google consigue estos resultados mediante algunos enfoques arquitectónicos habituales, que reflejan las directrices de arquitectura anteriores.
Implementación redundante: los back-ends de las aplicaciones y el almacenamiento de datos se implementan en varias zonas de una región y en varias regiones de una ubicación multirregional. Para obtener más información sobre las consideraciones específicas de cada región, consulta el artículo sobre geografía y regiones.
Replicación de datos: los productos usan la replicación síncrona o asíncrona en las ubicaciones redundantes.
La replicación síncrona significa que, cuando tu aplicación hace una llamada a la API para crear o modificar datos almacenados por el producto, recibe una respuesta correcta solo cuando el producto ha escrito los datos en varias ubicaciones. La replicación síncrona asegura que no pierdas el acceso a ninguno de tus datos durante una interrupción de la infraestructura, ya que todos tus datos están disponibles en una de las ubicaciones de backend disponibles. Google Cloud
Aunque esta técnica ofrece la máxima protección de datos, puede tener inconvenientes en cuanto a latencia y rendimiento. Los productos multirregión que usan la replicación síncrona experimentan este equilibrio de forma más significativa, normalmente con una latencia añadida del orden de decenas o centenas de milisegundos.
La replicación asíncrona significa que, cuando tu aplicación hace una llamada a la API para crear o modificar datos almacenados por el producto, recibe una respuesta correcta una vez que el producto ha escrito los datos en una sola ubicación. Después de enviar su solicitud de escritura, el producto replica sus datos en ubicaciones adicionales.
Esta técnica proporciona una latencia más baja y un mayor rendimiento en la API que la replicación síncrona, pero a costa de la protección de datos. Si la ubicación en la que has escrito datos sufre una interrupción antes de que se complete la réplica, perderás el acceso a esos datos hasta que se resuelva la interrupción de la ubicación.
Gestión de interrupciones con el balanceo de carga: Google Cloud usa el balanceo de carga de software para dirigir las solicitudes a los backends de aplicación adecuados. En comparación con otros enfoques, como el balanceo de carga de DNS, este enfoque reduce el tiempo de respuesta del sistema ante una interrupción. Cuando se produce una Google Cloud interrupción en una ubicación, el balanceador de carga detecta rápidamente que el backend implementado en esa ubicación ha pasado a estar en mal estado y dirige todas las solicitudes a un backend de una ubicación alternativa. De esta forma, el producto puede seguir respondiendo a las solicitudes de tu aplicación durante una interrupción de la ubicación. Cuando se resuelve la interrupción de la ubicación, el balanceador de carga detecta la disponibilidad de los back-ends de producto en esa ubicación y reanuda el envío de tráfico a ella.
Administrador de contextos de acceso
El Administrador de contextos de acceso permite a las empresas configurar niveles de acceso que se asignan a una política definida sobre atributos de solicitud. Las políticas se replican a nivel regional.
En caso de interrupción de una zona, las solicitudes a zonas no disponibles se atienden automáticamente y de forma transparente desde otras zonas disponibles de la región.
En caso de interrupción regional, los cálculos de las políticas de la región afectada no estarán disponibles hasta que la región vuelva a estarlo.
Transparencia de acceso
Transparencia de acceso permite a los administradores de la organización Google Cloud definir un control de acceso pormenorizado y basado en atributos para proyectos y recursos en Google Cloud. En ocasiones, Google debe acceder a los datos de los clientes con fines administrativos. Cuando accedemos a los datos de los clientes, Transparencia de acceso proporciona registros de acceso a los clientes afectados. Google CloudEstos registros de Transparencia de acceso ayudan a garantizar el compromiso de Google con la seguridad de los datos y la transparencia en el tratamiento de los datos.
Transparencia de acceso es resistente a las interrupciones zonales y regionales. Si se produce una interrupción zonal o regional, Transparencia de acceso sigue procesando los registros de acceso administrativo en otra zona u otra región.
AlloyDB for PostgreSQL
AlloyDB para PostgreSQL es un servicio de bases de datos totalmente gestionado y compatible con PostgreSQL. AlloyDB para PostgreSQL ofrece alta disponibilidad en una región a través de los nodos redundantes de su instancia principal, que se encuentran en dos zonas diferentes de la región. La instancia principal mantiene la disponibilidad regional activando una conmutación por error automática a la zona de espera si la zona activa tiene algún problema. El almacenamiento regional garantiza la durabilidad de los datos en caso de que se pierdan en una sola zona.
Como método adicional de recuperación ante desastres, AlloyDB para PostgreSQL usa la replicación entre regiones para proporcionar funciones de recuperación ante desastres replicando de forma asíncrona los datos de tu clúster principal en clústeres secundarios ubicados en Google Cloud regiones independientes.
Interrupción zonal: durante el funcionamiento normal, solo está activo uno de los dos nodos de una instancia principal de alta disponibilidad, que es el que gestiona todas las escrituras de datos. Este nodo activo almacena los datos en la capa de almacenamiento regional independiente del clúster.
AlloyDB para PostgreSQL detecta automáticamente los fallos a nivel de zona y activa una conmutación por error para restaurar la disponibilidad de la base de datos. Durante la conmutación por error, AlloyDB para PostgreSQL inicia la base de datos en el nodo de espera, que ya se ha aprovisionado en otra zona. Las nuevas conexiones de bases de datos se dirigen automáticamente a esta zona.
Desde el punto de vista de una aplicación cliente, una interrupción zonal se parece a una interrupción temporal de la conectividad de red. Una vez que se haya completado la conmutación por error, un cliente podrá volver a conectarse a la instancia en la misma dirección y con las mismas credenciales, sin perder datos.
Interrupción regional: la replicación entre regiones usa la replicación asíncrona, lo que permite que la instancia principal confirme las transacciones antes de que se confirmen en las réplicas. La diferencia de tiempo entre el momento en que se confirma una transacción en la instancia principal y el momento en que se confirma en la réplica se conoce como latencia de replicación. La diferencia de tiempo entre el momento en que el principal genera el registro de escritura anticipada (WAL) y el momento en que el WAL llega a la réplica se conoce como latencia de vaciado. La latencia de replicación y la latencia de vaciado dependen de la configuración de la instancia de base de datos y de la carga de trabajo generada por el usuario.
En caso de que se produzca una interrupción regional, puedes convertir los clústeres secundarios de otra región en clústeres principales independientes con capacidad de escritura. Este clúster promocionado ya no replica los datos del clúster principal original al que estaba asociado. Debido al retraso de vaciado, puede que se pierdan algunos datos, ya que puede haber transacciones en el clúster principal original que no se hayan propagado al clúster secundario.
El RPO de la replicación entre regiones se ve afectado tanto por el uso de la CPU del clúster principal como por la distancia física entre la región del clúster principal y la del clúster secundario. Para optimizar el RPO, te recomendamos que pruebes tu carga de trabajo con una configuración que incluya una réplica para establecer un límite seguro de transacciones por segundo (TPS), que es el TPS sostenido más alto que no acumula latencia de vaciado. Si tu carga de trabajo supera el límite de TPS seguro, se acumula el flag de vaciado, lo que puede afectar al RPO. Para limitar la latencia de la red, elige pares de regiones del mismo continente.
Para obtener más información sobre la monitorización de la latencia de red y otras métricas de AlloyDB para PostgreSQL, consulta Monitorizar instancias.
Anti Money Laundering AI
Anti Money Laundering AI (AML AI) proporciona una API para ayudar a las instituciones financieras de todo el mundo a detectar el blanqueo de dinero de forma más eficaz y eficiente. La IA contra el blanqueo de capitales es una oferta regional, lo que significa que los clientes pueden elegir la región, pero no las zonas que la componen. Los datos y el tráfico se balancean de carga automáticamente entre las zonas de una región. Las operaciones (por ejemplo, crear una canalización o ejecutar una predicción) se escalan automáticamente en segundo plano y se balancean entre zonas según sea necesario.
Interrupción zonal: AML AI almacena los datos de sus recursos de forma regional, replicados de forma síncrona. Cuando una operación de larga duración se completa correctamente, se puede confiar en los recursos independientemente de los errores zonales. El procesamiento también se replica en las zonas, pero esta replicación tiene como objetivo el balanceo de carga y no la alta disponibilidad, por lo que un fallo de zona durante una operación puede provocar un fallo de la operación. Si esto ocurre, puedes solucionar el problema volviendo a intentar la operación. Durante una interrupción zonal, los tiempos de procesamiento pueden verse afectados.
Interrupción regional: los clientes eligen la región de Google Cloud en la que quieren crear sus recursos de IA de lucha contra el blanqueo de capitales. Los datos nunca se replican entre regiones. La IA de AML nunca dirige el tráfico de los clientes a otra región. En caso de que se produzca un fallo regional, la IA de AML volverá a estar disponible en cuanto se resuelva la interrupción.
Claves de API
Las claves de API proporcionan una gestión escalable de los recursos de claves de API para un proyecto. Las claves de API son un servicio global, lo que significa que las claves se pueden ver y acceder desde cualquier ubicación de Google Cloud . Sus datos y metadatos se almacenan de forma redundante en varias zonas y regiones.
Las claves de API son resistentes a las interrupciones zonales y regionales. En caso de interrupción zonal o regional, las claves de API siguen atendiendo solicitudes desde otra zona de la misma región o de otra.
Para obtener más información sobre las claves de API, consulta el artículo Descripción general de la API Keys.
Apigee
Apigee proporciona una plataforma segura, escalable y fiable para desarrollar y gestionar APIs. Apigee ofrece despliegues de una o varias regiones.
Interrupción por zonas: los datos de tiempo de ejecución de los clientes se replican en varias zonas de disponibilidad. Por lo tanto, una interrupción en una sola zona no afecta a Apigee.
Interrupción regional: en el caso de las instancias de Apigee de una sola región, si una región deja de funcionar, las instancias de Apigee no estarán disponibles en esa región y no se podrán restaurar en otras regiones. En el caso de las instancias de Apigee multirregionales, los datos se replican de forma asíncrona en todas las regiones. Por lo tanto, si falla una región, el tráfico no se reduce por completo. Sin embargo, es posible que no puedas acceder a los datos no confirmados de la región en la que se ha producido el error. Puedes desviar el tráfico de las regiones que no estén en buen estado. Para conseguir una conmutación por error automática del tráfico, puedes configurar el enrutamiento de red mediante grupos de instancias gestionados (MIGs).
AutoML Translation
AutoML Translation es un servicio de traducción automática que te permite importar tus propios datos (pares de oraciones) para entrenar modelos personalizados que se adapten a las necesidades específicas de tu dominio.
Interrupción zonal: AutoML Translation tiene servidores de computación activos en varias zonas y regiones. También admite la replicación síncrona de datos entre zonas de una misma región. Estas funciones ayudan a AutoML Translation a lograr una conmutación por error instantánea sin pérdida de datos en caso de fallos zonales y sin necesidad de que los clientes hagan nada.
Interrupción regional: en caso de fallo regional, AutoML Translation no estará disponible.
AutoML Vision
AutoML Vision forma parte de Vertex AI. Ofrece un marco unificado para crear conjuntos de datos, importar datos, entrenar modelos y usar modelos para predicciones online y por lotes.
AutoML Vision es una oferta regional. Los clientes pueden elegir la región desde la que quieren iniciar un trabajo, pero no pueden elegir las zonas específicas de esa región. El servicio balancea la carga de trabajo automáticamente entre las diferentes zonas de la región.
Interrupción zonal: AutoML Vision almacena los metadatos de los trabajos a nivel regional y escribe de forma síncrona en las zonas de la región. Las tareas se inician en una zona específica, seleccionada por Cloud Load Balancing.
Tareas de entrenamiento de AutoML Vision: si se produce una interrupción zonal, se producirá un error en todas las tareas en curso y el estado de la tarea se actualizará a "Error". Si un trabajo falla, vuelve a intentarlo inmediatamente. El nuevo trabajo se dirige a una zona disponible.
Tareas de predicción por lotes de AutoML Vision: la predicción por lotes se basa en Predicción por lotes de Vertex AI. Cuando se produce una interrupción zonal, el servicio vuelve a intentar ejecutar el trabajo automáticamente dirigiéndolo a las zonas disponibles. Si se produce un error en varios reintentos, el estado del trabajo se actualiza a "failed" (error). Las solicitudes posteriores de los usuarios para ejecutar el trabajo se enrutan a una zona disponible.
Interrupción regional: los clientes eligen la Google Cloud región en la que quieren ejecutar sus tareas. Los datos nunca se replican entre regiones. En caso de fallo regional, el servicio AutoML Vision no estará disponible en esa región. Volverá a estar disponible cuando se solucione la interrupción. Para ejecutar sus trabajos, recomendamos a los clientes que usen varias regiones. Si se produce una interrupción regional, dirige las tareas a otra región disponible.
Lotes
Batch es un servicio totalmente gestionado para poner en cola, programar y ejecutar tareas por lotes en Google Cloud. Los ajustes de los lotes se definen a nivel de región. Los clientes deben elegir una región para enviar sus trabajos por lotes, no una zona de una región. Cuando se envía un trabajo, Batch escribe de forma síncrona los datos del cliente en varias zonas. Sin embargo, los clientes pueden especificar las zonas en las que las VMs de Batch ejecutan los trabajos.
Fallo de zona: cuando falla una zona, también fallan las tareas que se ejecutan en esa zona. Si las tareas tienen ajustes de reintento, Batch automáticamente transfiere esas tareas a otras zonas activas de la misma región. La conmutación por error automática está sujeta a la disponibilidad de recursos en las zonas activas de la misma región. Los trabajos que requieren recursos zonales (como máquinas virtuales, GPUs o discos persistentes zonales) que solo están disponibles en la zona con errores se ponen en cola hasta que se recupera la zona con errores o hasta que se alcanza el tiempo de espera de la cola de los trabajos. Cuando sea posible, recomendamos que los clientes dejen que Batch elija los recursos zonales para ejecutar sus trabajos. De esta forma, te aseguras de que los trabajos sean resistentes a las interrupciones zonales.
Fallo regional: en caso de que se produzca un fallo regional, el plano de control del servicio no estará disponible en la región. El servicio no replica datos ni redirige solicitudes entre regiones. Recomendamos a los clientes que usen varias regiones para ejecutar sus tareas y que redirijan las tareas a otra región si una de ellas falla.
Protección de datos y contra amenazas de Chrome Enterprise Premium
La protección de datos y contra amenazas de Chrome Enterprise Premium forma parte de la solución Chrome Enterprise Premium. Amplía Chrome con una variedad de funciones de seguridad, como la protección contra malware y phishing, la prevención de la pérdida de datos (DLP), las reglas de filtrado de URLs y los informes de seguridad.
Los administradores de Chrome Enterprise Premium pueden habilitar el almacenamiento de contenido principal de clientes que infrinja las políticas de DLP o de malware en eventos de registro de reglas de Google Workspace o en Cloud Storage para futuras investigaciones. Los eventos de registro de reglas de Google Workspace se basan en una base de datos de Spanner multirregional. Chrome Enterprise Premium puede tardar varias horas en detectar infracciones de las políticas. Durante este tiempo, los datos sin procesar están sujetos a pérdidas de datos debido a una interrupción zonal o regional. Una vez que se detecta una infracción, el contenido que infringe tus políticas se escribe en los eventos del registro de reglas de Google Workspace o en Cloud Storage.
Interrupción del servicio por zonas y regiones: como la protección contra amenazas y de datos de Chrome Enterprise Premium es multizonal y multirregional, puede resistir una pérdida completa e imprevista de una zona o una región sin que se vea afectada la disponibilidad. Para ofrecer este nivel de fiabilidad, redirige el tráfico a su servicio en otras zonas o regiones activas. Sin embargo, como la protección contra amenazas y de datos de Chrome Enterprise Premium puede tardar varias horas en detectar infracciones de DLP y malware, los datos sin procesar de una zona o región concretas pueden perderse si se produce una interrupción en esa zona o región.
BigQuery
BigQuery es un almacén de datos en la nube de alta escalabilidad, rentable y sin servidor, diseñado para agilizar tu negocio. BigQuery admite los siguientes tipos de ubicaciones para los conjuntos de datos de los usuarios:
- Una región: una ubicación geográfica específica, como Iowa (
us-central1) o Montreal (northamerica-northeast1). - Una multirregión: una zona geográfica grande que contiene dos o más lugares geográficos, como Estados Unidos (
US) o Europa (EU).
En ambos casos, los datos se almacenan de forma redundante en dos zonas de una misma región de la ubicación seleccionada. Los datos escritos en BigQuery se escriben de forma síncrona en las zonas primaria y secundaria. Esta opción protege frente a la falta de disponibilidad de una sola zona dentro de la región, pero no frente a una interrupción regional.
Autorización binaria
Autorización binaria es un producto de seguridad de la cadena de suministro de software para GKE y Cloud Run.
Todas las políticas de Autorización binaria se replican en varias zonas de cada región. La replicación ayuda a las operaciones de lectura de la política de Binary Authorization a recuperarse de los fallos de otras regiones. La replicación también hace que las operaciones de lectura sean tolerantes a los fallos de zona en cada región.
Las operaciones de aplicación de la autorización binaria son resistentes a las interrupciones zonales, pero no a las regionales. Las operaciones de aplicación se ejecutan en la misma región que el clúster de GKE o el trabajo de Cloud Run que realiza la solicitud. Por lo tanto, en caso de interrupción regional, no se ejecuta nada para hacer solicitudes de aplicación de la autorización binaria.
Certificate Manager
Certificate Manager te permite obtener y gestionar certificados de Seguridad en la capa de transporte (TLS) para usarlos con diferentes tipos de Cloud Load Balancing.
En caso de que se produzca una interrupción por zonas, Certificate Manager regional y global son resistentes a los fallos por zonas, ya que los trabajos y las bases de datos son redundantes en varias zonas de una región. En caso de interrupción regional, Certificate Manager global es resistente a los fallos regionales porque los trabajos y las bases de datos son redundantes en varias regiones. Certificate Manager regional es un producto regional, por lo que no puede resistir un fallo regional.
Sistema de Detección de Intrusos de Cloud
Cloud Intrusion Detection System (Cloud IDS) es un servicio zonal que proporciona endpoints de IDS de ámbito zonal, que procesan el tráfico de las máquinas virtuales de una zona específica y, por lo tanto, no tolera las interrupciones zonales ni regionales.
Interrupción zonal: Cloud IDS está vinculado a instancias de VM. Si un cliente tiene previsto mitigar las interrupciones zonales desplegando VMs en varias zonas (manualmente o mediante grupos de instancias gestionados regionales), también tendrá que desplegar endpoints de Cloud IDS en esas zonas.
Interrupción regional: Cloud IDS es un producto regional. No proporciona ninguna función entre regiones. Si se produce un fallo regional, se inhabilitará toda la funcionalidad de Cloud IDS en todas las zonas de esa región.
Google Security Operations SIEM
Google Security Operations SIEM (que forma parte de Google Security Operations) es un servicio totalmente gestionado que ayuda a los equipos de seguridad a detectar, investigar y responder a las amenazas.
Google Security Operations SIEM ofrece soluciones regionales y multirregionales.
En las ofertas regionales, los datos y el tráfico se equilibran de carga automáticamente entre las zonas de la región elegida, y los datos se almacenan de forma redundante en las zonas de disponibilidad de la región.
Las multirregiones tienen redundancia geográfica. Esta redundancia proporciona un conjunto de protecciones más amplio que el almacenamiento regional. También ayuda a garantizar que el servicio siga funcionando aunque se pierda una región completa.
La mayoría de las rutas de ingestión de datos replican los datos de los clientes de forma síncrona en varias ubicaciones. Cuando los datos se replican de forma asíncrona, hay un periodo (un objetivo de punto de recuperación o RPO) durante el cual los datos aún no se han replicado en varias ubicaciones. Este es el caso cuando se ingieren datos con feeds en implementaciones multirregionales. Después del RPO, los datos están disponibles en varias ubicaciones.
Interrupción zonal:
Despliegues regionales: las solicitudes se atienden desde cualquier zona de la región. Los datos se replican de forma síncrona en varias zonas. En caso de que se produzca una interrupción en toda la zona, las zonas restantes seguirán sirviendo tráfico y procesando los datos. El aprovisionamiento redundante y el escalado automático de la solución SIEM de Google Security Operations ayudan a garantizar que el servicio siga funcionando en las zonas restantes durante estos cambios de carga.
Despliegues multirregionales: las interrupciones de servicio de una zona son equivalentes a las de una región.
Interrupción regional:
Implementaciones regionales: Google Security Operations SIEM almacena todos los datos de los clientes en una sola región y el tráfico nunca se enruta entre regiones. En caso de interrupción regional, Google Security Operations SIEM no estará disponible en la región hasta que se resuelva la interrupción.
Despliegues multirregionales (sin feeds): las solicitudes se sirven desde cualquier región del despliegue multirregional. Los datos se replican de forma síncrona en varias regiones. En caso de que se produzca una interrupción en toda una región, las regiones restantes seguirán enviando tráfico y procesando los datos. El aprovisionamiento redundante y el escalado automático del SIEM de Google Security Operations ayudan a garantizar que el servicio siga funcionando en las regiones restantes durante estos cambios de carga.
Despliegues multirregionales (con feeds): las solicitudes se sirven desde cualquier región del despliegue multirregional. Los datos se replican de forma asíncrona en varias regiones con el RPO proporcionado. En caso de que se produzca una interrupción en toda una región, solo estarán disponibles en las regiones restantes los datos almacenados después del RPO. Es posible que los datos del periodo de RPO no se repliquen.
Inventario de Recursos de Cloud
Inventario de recursos de Cloud es un servicio global de alto rendimiento y resistente que mantiene un repositorio de metadatos de recursos y políticas. Google Cloud Inventario de Recursos de Cloud proporciona herramientas de búsqueda y análisis que te ayudan a hacer un seguimiento de los recursos implementados en organizaciones, carpetas y proyectos.
En caso de interrupción de una zona, Cloud Asset Inventory sigue atendiendo solicitudes desde otra zona de la misma región o de otra.
En caso de interrupción regional, el Inventario de Recursos de Cloud seguirá atendiendo solicitudes de otras regiones.
Bigtable
Bigtable es un servicio de base de datos NoSQL de alto rendimiento y totalmente gestionado para grandes cargas de trabajo analíticas y operativas.
Descripción general de la replicación de Bigtable
Bigtable ofrece una función de replicación flexible y totalmente configurable que puedes usar para aumentar la disponibilidad y la durabilidad de tus datos copiándolos en clústeres de varias regiones o de varias zonas de la misma región. Bigtable también puede proporcionar conmutación por error automática para tus solicitudes cuando usas la replicación.
Cuando se usan configuraciones multizonales o multirregionales con enrutamiento de varios clústeres, en caso de interrupción zonal o regional, Bigtable redirige automáticamente el tráfico y sirve las solicitudes desde el clúster disponible más cercano. Como la replicación de Bigtable es asíncrona y eventualmente coherente, es posible que los cambios muy recientes en los datos de la ubicación de la interrupción no estén disponibles si aún no se han replicado en otras ubicaciones.
Consideraciones sobre el rendimiento.
Cuando la demanda de recursos de CPU supera la capacidad disponible del nodo, Bigtable siempre prioriza el servicio de las solicitudes entrantes por encima del tráfico de replicación.
Para obtener más información sobre cómo usar la replicación de Bigtable con tu carga de trabajo, consulta la descripción general de la replicación de Cloud Bigtable y los ejemplos de configuraciones de replicación.
Los nodos de Bigtable se usan tanto para atender las solicitudes entrantes como para replicar datos de otros clústeres. Además de mantener un número suficiente de nodos por clúster, también debe asegurarse de que sus aplicaciones usen un diseño de esquema adecuado para evitar puntos de acceso, que pueden provocar un uso excesivo o desequilibrado de la CPU y un aumento de la latencia de replicación.
Para obtener más información sobre cómo diseñar el esquema de tu aplicación para maximizar el rendimiento y la eficiencia de Bigtable, consulta las prácticas recomendadas para el diseño de esquemas.
Supervisión
Bigtable ofrece varias formas de monitorizar visualmente la latencia de replicación de tus instancias y clústeres mediante los gráficos de replicación disponibles en la Google Cloud console.
También puedes monitorizar de forma programática las métricas de replicación de Bigtable mediante la API Cloud Monitoring.
Servicio de Autoridades de Certificación
Servicio de Autoridades de Certificación permite a los clientes simplificar, automatizar y personalizar el despliegue, la gestión y la seguridad de las autoridades de certificación privadas, así como emitir certificados de forma resiliente a gran escala.
Interrupción zonal: el servicio de CA es resistente a los fallos zonales porque su plano de control es redundante en varias zonas de una región. Si se produce una interrupción zonal, el servicio de CA sigue atendiendo las solicitudes de otra zona de la misma región sin interrupciones. Como los datos se replican de forma síncrona, no se pierden ni se dañan.
Interrupción regional: el servicio de AC es un producto regional, por lo que no puede resistir un fallo regional. Si necesitas resiliencia ante fallos regionales, crea CAs emisoras en dos regiones diferentes. Crea la AC emisora principal en la región en la que necesites certificados. Crea una AC de respaldo en otra región. Usa la alternativa cuando la región de la AC subordinada principal tenga una interrupción. Si es necesario, ambas autoridades de certificación pueden encadenarse a la misma autoridad de certificación raíz.
Facturación de Google Cloud
La API Cloud Billing permite a los desarrolladores gestionar la facturación de susGoogle Cloud proyectos de forma programática. La API Cloud Billing se ha diseñado como un sistema global con actualizaciones escritas de forma síncrona en varias zonas y regiones.
Fallo zonal o regional: la API Cloud Billing se transferirá automáticamente a otra zona u otra región. Es posible que las solicitudes individuales fallen, pero una política de reintentos debería permitir que las solicitudes posteriores se completen correctamente.
Cloud Build
Cloud Build es un servicio que ejecuta las compilaciones en Google Cloud.
Cloud Build se compone de instancias aisladas por regiones que replican datos de forma síncrona en las zonas de la región. Te recomendamos que uses regiones específicas en lugar de la región global y que te asegures de que los recursos que usa tu compilación (como los contenedores de registro y los repositorios de Artifact Registry) estén alineados con la región en la que se ejecuta tu compilación. Google Cloud
En caso de interrupción zonal, las operaciones del plano de control no se ven afectadas. Sin embargo, las compilaciones que se estén ejecutando en la zona con errores se retrasarán o se perderán definitivamente. Las compilaciones que se activen se distribuirán automáticamente a las zonas que sigan funcionando.
En caso de fallo regional, el plano de control no estará disponible y las compilaciones en curso se retrasarán o se perderán de forma permanente. Los activadores, los grupos de trabajadores y los datos de compilación nunca se replican entre regiones. Te recomendamos que prepares activadores y grupos de trabajadores en varias regiones para facilitar la mitigación de una interrupción.
Cloud CDN
Cloud CDN distribuye y almacena en caché el contenido en muchas ubicaciones de la red de Google para reducir la latencia de servicio de los clientes. El contenido almacenado en caché se sirve de la mejor forma posible. Cuando la caché de Cloud CDN no puede servir una solicitud, esta se reenvía a los servidores de origen, como las VMs de backend o los segmentos de Cloud Storage, donde se almacena el contenido original.
Cuando falla una zona o una región, las cachés de las ubicaciones afectadas no están disponibles. Las solicitudes entrantes se enrutan a las ubicaciones de edge y las cachés de Google disponibles. Si estas cachés alternativas no pueden atender la solicitud, la reenviarán a un servidor de origen disponible. Si el servidor puede atender la solicitud con datos actualizados, no se perderá contenido. Si aumenta la frecuencia de los errores de caché, los servidores de origen experimentarán volúmenes de tráfico superiores a los habituales a medida que se llenen las cachés. Las solicitudes posteriores se atenderán desde las cachés que no se vean afectadas por la interrupción de la zona o la región.
Para obtener más información sobre Cloud CDN y el comportamiento de la caché, consulta la documentación de Cloud CDN.
Cloud Composer
Cloud Composer es un servicio gestionado de orquestación de flujos de trabajo que te permite crear, programar, monitorizar y gestionar flujos de trabajo que abarcan nubes y centros de datos on-premise. Los entornos de Cloud Composer se basan en el proyecto de código abierto Apache Airflow.
La disponibilidad de la API de Cloud Composer no se ve afectada por la falta de disponibilidad de las zonas. Durante una interrupción zonal, conservas el acceso a la API Cloud Composer, incluida la capacidad de crear nuevos entornos de Cloud Composer.
Un entorno de Cloud Composer tiene un clúster de GKE como parte de su arquitectura. Durante una interrupción zonal, los flujos de trabajo del clúster pueden verse afectados:
- En Cloud Composer 1, el clúster del entorno es un recurso zonal, por lo que una interrupción zonal puede hacer que el clúster no esté disponible. Los flujos de trabajo que se estén ejecutando en el momento de la interrupción podrían detenerse antes de completarse.
- En Cloud Composer 2, el clúster del entorno es un recurso regional. Sin embargo, los flujos de trabajo que se ejecuten en nodos de las zonas afectadas por una interrupción zonal podrían detenerse antes de completarse.
En ambas versiones de Cloud Composer, una interrupción zonal puede provocar que los flujos de trabajo ejecutados parcialmente dejen de ejecutarse, incluidas las acciones externas que hayas configurado para que el flujo de trabajo lleve a cabo. En función del flujo de trabajo, esto puede provocar incoherencias externas. Por ejemplo, si el flujo de trabajo se detiene en mitad de una ejecución de varios pasos para modificar almacenes de datos externos. Por lo tanto, debes tener en cuenta el proceso de recuperación al diseñar tu flujo de trabajo de Airflow, incluido cómo detectar estados de flujo de trabajo parcialmente no ejecutados y reparar los cambios de datos parciales.
En Cloud Composer 1, durante una interrupción de la zona, puedes iniciar un nuevo entorno de Cloud Composer en otra zona. Como Airflow mantiene el estado de tus flujos de trabajo en su base de datos de metadatos, transferir esta información a un nuevo entorno de Cloud Composer puede requerir pasos y preparaciones adicionales.
En Cloud Composer 2, puedes hacer frente a las interrupciones zonales configurando con antelación la recuperación ante desastres con instantáneas del entorno. Durante una interrupción de una zona, puedes cambiar a otro entorno transfiriendo el estado de tus flujos de trabajo con una instantánea del entorno. Solo Cloud Composer 2 admite la recuperación ante desastres con capturas de entornos.
Cloud Data Fusion
Cloud Data Fusion es un servicio de integración de datos empresariales totalmente gestionado que ayuda a los usuarios a crear y gestionar flujos de procesamiento de datos rápidamente. Ofrece tres ediciones.
Las interrupciones zonales afectan a las instancias de la edición Developer.
Las interrupciones regionales afectan a las instancias de las ediciones Basic y Enterprise.
Para controlar el acceso a los recursos, puedes diseñar y ejecutar las canalizaciones en entornos independientes. Esta separación te permite diseñar una canalización una vez y, después, ejecutarla en varios entornos. Puedes recuperar las pipelines en ambos entornos. Para obtener más información, consulta Crear copias de seguridad y restaurar datos de instancias.
Los siguientes consejos se aplican a las interrupciones regionales y zonales.
Interrupciones en el entorno de diseño de la canalización
En el entorno de diseño, guarda los borradores de las canalizaciones por si se produce una interrupción. En función de los requisitos específicos de RTO y RPO, puedes usar los borradores guardados para restaurar la canalización en otra instancia de Cloud Data Fusion durante una interrupción.
Interrupciones en el entorno de ejecución de la canalización
En el entorno de ejecución, puedes iniciar el flujo de procesamiento de forma interna con activadores o programaciones de Cloud Data Fusion, o de forma externa con herramientas de orquestación, como Cloud Composer. Para poder recuperar las configuraciones de tiempo de ejecución de las canalizaciones, haz una copia de seguridad de las canalizaciones y las configuraciones, como los complementos y las programaciones. En caso de interrupción, puedes usar la copia de seguridad para replicar una instancia en una región o zona que no se vea afectada.
Otra forma de prepararse para las interrupciones es tener varias instancias en las regiones con la misma configuración y el mismo conjunto de pasos. Si usas la orquestación externa, las canalizaciones en ejecución se pueden equilibrar de carga automáticamente entre instancias. Presta especial atención para asegurarte de que no haya recursos (como fuentes de datos o herramientas de orquestación) vinculados a una sola región y utilizados por todas las instancias, ya que esto podría convertirse en un punto central de fallo en caso de interrupción. Por ejemplo, puedes tener varias instancias en diferentes regiones y usar Cloud Load Balancing y Cloud DNS para dirigir las solicitudes de ejecución de la canalización a una instancia que no se vea afectada por una interrupción (consulta las arquitecturas de nivel 1 y nivel 3).
Interrupciones de otros Google Cloud servicios de datos de la canalización
Tu instancia puede usar otros Google Cloud servicios como fuentes de datos o entornos de ejecución de la canalización, como Dataproc, Cloud Storage o BigQuery. Esos servicios pueden estar en regiones diferentes. Cuando se requiere la ejecución entre regiones, un fallo en cualquiera de las regiones provoca una interrupción. En este caso, debes seguir los pasos estándar de recuperación ante desastres, teniendo en cuenta que la configuración entre regiones con servicios críticos en diferentes regiones es menos resistente.
Cloud Deploy
Cloud Deploy proporciona entrega continua de cargas de trabajo en servicios de tiempo de ejecución, como GKE y Cloud Run. El servicio se compone de instancias regionales que replican los datos de forma síncrona en las zonas de la región.
Interrupción zonal: las operaciones del plano de control no se ven afectadas. Sin embargo, las compilaciones de Cloud Build (por ejemplo, las operaciones de renderización o de implementación) que se estén ejecutando cuando falle una zona se retrasarán o se perderán definitivamente. Durante una interrupción, el recurso de Cloud Deploy que ha activado la compilación (una versión o un lanzamiento) muestra un estado de fallo que indica que la operación subyacente ha fallado. Puedes volver a crear el recurso para iniciar una nueva compilación en las zonas que sigan funcionando. Por ejemplo, puedes crear un nuevo lanzamiento desplegando de nuevo la versión en un objetivo.
Interrupción regional: las operaciones del plano de control no están disponibles, al igual que los datos de Cloud Deploy, hasta que se restaure la región. Para que te resulte más fácil restaurar el servicio en caso de que se produzca una interrupción regional, te recomendamos que almacenes tu canal de distribución y tus definiciones de destino en el control de versiones. Puedes usar estos archivos de configuración para volver a crear tus pipelines de Cloud Deploy en una región que funcione. Durante una interrupción, se pierden los datos sobre las versiones. Crea una nueva versión para seguir implementando software en tus destinos.
Cloud DNS
Cloud DNS es un servicio de sistema de nombres de dominio (DNS) global, resiliente y de alto rendimiento que publica tus nombres de dominio en el DNS global de forma económica.
En caso de interrupción zonal, Cloud DNS sigue respondiendo a las solicitudes desde otra zona de la misma región o de otra región sin interrupción. Las actualizaciones de los registros de Cloud DNS se replican de forma síncrona en las zonas de la región en la que se reciben. Por lo tanto, no se pierden datos.
En caso de interrupción regional, Cloud DNS sigue atendiendo solicitudes de otras regiones. Es posible que las actualizaciones más recientes de los registros de Cloud DNS no estén disponibles porque primero se procesan en una sola región antes de replicarse de forma asíncrona en otras regiones.
API de Cloud Healthcare
La API Cloud Healthcare, un servicio para almacenar y gestionar datos sanitarios, se ha diseñado para ofrecer una alta disponibilidad y protección frente a fallos zonales y regionales, en función de la configuración elegida.
Configuración regional: en su configuración predeterminada, la API Cloud Healthcare ofrece protección contra fallos zonales. El servicio se implementa en tres zonas de una región, y los datos también se triplican en diferentes zonas de la región. En caso de que se produzca un fallo en una zona que afecte a la capa de servicio o a la capa de datos, las zonas restantes tomarán el control sin interrupción. Con la configuración regional, si se produce una interrupción en toda una región en la que se encuentra el servicio, este no estará disponible hasta que la región vuelva a estar online. En el caso de que se produzca una destrucción física de toda una región, se perderán los datos almacenados en ella.
Configuración multirregional: en su configuración multirregional, la API Cloud Healthcare se despliega en tres zonas pertenecientes a tres regiones diferentes. Los datos también se replican en tres regiones. De esta forma, se evita la pérdida del servicio en caso de que se produzca una interrupción en toda una región, ya que las regiones restantes se harían cargo automáticamente. Los datos estructurados, como los FHIR, se replican de forma síncrona en varias regiones, por lo que están protegidos frente a la pérdida de datos en caso de que se produzca una interrupción en toda una región. Los datos almacenados en los contenedores de Cloud Storage, como los objetos DICOM y Dictation o los objetos HL7v2/FHIR de gran tamaño, se replican de forma asíncrona en varias regiones.
Cloud Identity
Los servicios de Cloud Identity se distribuyen en varias regiones y usan el balanceo de carga dinámico. Cloud Identity no permite que los usuarios seleccionen un ámbito de recursos. Si se produce una interrupción en una zona o región concreta, el tráfico se distribuye automáticamente a otras zonas o regiones.
Los datos persistentes se replican en varias regiones con replicación síncrona en la mayoría de los casos. Por motivos de rendimiento, algunos sistemas, como las cachés o los cambios que afectan a un gran número de entidades, se replican de forma asíncrona en las regiones. Si la región principal en la que se almacenan los datos más recientes sufre una interrupción, Cloud Identity servirá datos obsoletos de otra ubicación hasta que la región principal vuelva a estar disponible.
Cloud Interconnect
Cloud Interconnect ofrece a los clientes acceso RFC 1918 a redes Google Cloud desde sus centros de datos on-premise a través de cables físicos conectados al peering de Google.
Cloud Interconnect ofrece a los clientes un acuerdo de nivel de servicio del 99,9% si aprovisionan conexiones a dos dominios de disponibilidad de Edge (EADs) en un área metropolitana. Se ofrece un SLA del 99,99% si el cliente aprovisiona conexiones en dos EADs de dos áreas metropolitanas a dos regiones con enrutamiento global. Consulta la descripción general de la topología para aplicaciones que no son clave y la descripción general de la topología para aplicaciones de nivel de producción para obtener más información.
Cloud Interconnect no depende de la zona de computación y proporciona alta disponibilidad en forma de EADs. Si se produce un fallo en un EAD, la sesión de BGP con ese EAD se interrumpe y el tráfico se transfiere al otro EAD.
En caso de que se produzca un fallo regional, las sesiones de BGP de esa región se interrumpirán y el tráfico se conmutará por error a los recursos de la región que funcione. Esto se aplica cuando la opción de enrutamiento global está habilitada.
Cloud Key Management Service
Cloud Key Management Service (Cloud KMS) ofrece una gestión de recursos de claves criptográficas escalable y muy duradera. Cloud KMS almacena todos sus datos y metadatos en bases de datos de Spanner, que proporcionan una alta durabilidad y disponibilidad de los datos con replicación síncrona.
Los recursos de Cloud KMS se pueden crear en una sola región, en varias regiones o de forma global.
En caso de interrupción de una zona, Cloud KMS sigue atendiendo las solicitudes de otra zona de la misma región o de otra región sin interrupción. Como los datos se replican de forma síncrona, no se pierden ni se dañan. Cuando se resuelva la interrupción de la zona, se restaurará la redundancia completa.
En caso de interrupción regional, los recursos regionales de esa región no estarán disponibles hasta que la región vuelva a estarlo. Ten en cuenta que, incluso dentro de una región, se mantienen al menos 3 réplicas en zonas independientes. Si se requiere una mayor disponibilidad, los recursos deben almacenarse en una configuración multirregional o global. Las configuraciones multirregionales y globales están diseñadas para mantener la disponibilidad durante una interrupción regional almacenando y sirviendo datos con redundancia geográfica en más de una región.
Cloud External Key Manager (Cloud EKM)
Cloud External Key Manager está integrado con Cloud Key Management Service para que puedas controlar y acceder a claves externas a través de partners externos admitidos. Puedes usar estas claves externas para cifrar datos en reposo y usarlos en otros Google Cloud servicios que admitan la integración de claves de cifrado gestionadas por el cliente (CMEK).
Interrupción de una zona: Cloud External Key Manager es resistente a las interrupciones de zonas debido a la redundancia que proporcionan varias zonas de una región. Si se produce una interrupción zonal, el tráfico se redirige a otras zonas de la región. Mientras se redirige el tráfico, es posible que observes un aumento de los errores, pero el servicio seguirá estando disponible.
Interrupción regional: Cloud External Key Manager no está disponible durante una interrupción regional en la región afectada. No hay ningún mecanismo de conmutación por error que redirija las solicitudes entre regiones. Recomendamos que los clientes usen varias regiones para ejecutar sus tareas.
Cloud External Key Manager no almacena ningún dato de cliente de forma persistente. Por lo tanto, no se pierden datos durante una interrupción regional en el sistema Cloud External Key Manager. Sin embargo, Cloud External Key Manager depende de la disponibilidad de otros servicios, como Cloud Key Management Service y proveedores externos. Si esos sistemas fallan durante una interrupción regional, podrías perder datos. El RPO y el RTO de estos sistemas no están incluidos en los compromisos de Cloud EKM.
Cloud Load Balancing
Cloud Load Balancing es un servicio gestionado, definido mediante software y totalmente distribuido. Con Cloud Load Balancing, una sola dirección IP anycast puede servir como frontend para los backends de regiones de todo el mundo. No se basa en hardware, por lo que no tienes que gestionar una infraestructura física de balanceo de carga. Los balanceadores de carga son un componente fundamental de la mayoría de las aplicaciones de alta disponibilidad.
Cloud Load Balancing ofrece balanceadores de carga regionales y globales. También ofrece balanceo de carga interregional, incluida la conmutación automática por error en varias regiones, que traslada el tráfico a los backends de conmutación por error si los backends principales están en mal estado.
Los balanceadores de carga globales son resistentes a las interrupciones zonales y regionales. Los balanceadores de carga regionales son resistentes a las interrupciones zonales, pero se ven afectados por las interrupciones en su región. Sin embargo, en ambos casos, es importante tener en cuenta que la resiliencia de tu aplicación en general no solo depende del tipo de balanceador de carga que implementes, sino también de la redundancia de tus backends.
Para obtener más información sobre Cloud Load Balancing y sus funciones, consulta el artículo Información general sobre Cloud Load Balancing.
Cloud Logging
Cloud Logging consta de dos partes principales: el enrutador de registros y el almacenamiento de Cloud Logging.
El enrutador de registros gestiona los eventos de registro de streaming y dirige los registros al almacenamiento de Cloud Storage, Pub/Sub, BigQuery o Cloud Logging.
El almacenamiento de Cloud Logging es un servicio para almacenar, consultar y gestionar el cumplimiento de los registros. Es compatible con muchos usuarios y flujos de trabajo, como el desarrollo, el cumplimiento, la solución de problemas y las alertas proactivas.
Enrutador de registros y registros entrantes: durante una interrupción zonal, la API de Cloud Logging enruta los registros a otras zonas de la región. Normalmente, los registros que el enrutador de registros envía a Cloud Logging, BigQuery o Pub/Sub se escriben en su destino final lo antes posible, mientras que los registros que se envían a Cloud Storage se almacenan en búfer y se escriben en lotes cada hora.
Entradas de registro: en caso de interrupción del servicio en una zona o región, las entradas de registro que se hayan almacenado en la zona o región afectada y no se hayan escrito en el destino de exportación dejarán de estar accesibles. Las métricas basadas en registros también se calculan en el enrutador de registros y están sujetas a las mismas restricciones. Una vez que se hayan entregado en la ubicación de exportación de registros seleccionada, los registros se replicarán según el servicio de destino. Los registros que se exportan al almacenamiento de Cloud Logging se replican de forma síncrona en dos zonas de una región. Para obtener información sobre el comportamiento de la replicación de otros tipos de destino, consulta la sección correspondiente de este artículo. Ten en cuenta que los registros exportados a Cloud Storage se agrupan en lotes y se escriben cada hora. Por lo tanto, recomendamos usar el almacenamiento de Cloud Logging, BigQuery o Pub/Sub para minimizar la cantidad de datos afectados por una interrupción.
Metadatos de registro: los metadatos, como la configuración de los receptores y las exclusiones, se almacenan de forma global, pero se almacenan en caché a nivel regional, por lo que, en caso de interrupción, las instancias regionales de Log Router seguirían funcionando. Los fallos de una sola región no tienen ningún impacto fuera de ella.
Cloud Monitoring
Cloud Monitoring consta de varias funciones interconectadas, como paneles de control (tanto integrados como definidos por el usuario), alertas y monitorización del tiempo de actividad.
Toda la configuración de Cloud Monitoring, incluidos los paneles de control, las comprobaciones de disponibilidad y las políticas de alertas, se define de forma global. Todos los cambios que se realicen en ellos se replicarán de forma síncrona en varias regiones. Por lo tanto, durante las interrupciones zonales y regionales, los cambios de configuración que se realicen correctamente serán duraderos. Además, aunque se pueden producir errores de lectura y escritura transitorios cuando una zona o una región falla inicialmente, Cloud Monitoring redirige las solicitudes a las zonas y regiones disponibles. En este caso, puedes volver a intentar los cambios de configuración con un tiempo de espera exponencial.
Cuando se escriben métricas de un recurso específico, Cloud Monitoring primero identifica la región en la que reside el recurso. A continuación, escribe tres réplicas independientes de los datos de métricas en la región. La escritura de métricas regional general se devuelve como correcta en cuanto se completa una de las tres escrituras. No se garantiza que las tres réplicas se encuentren en zonas diferentes de la región.
Zonal: durante una interrupción zonal, las lecturas y escrituras de métricas no están disponibles para los recursos de la zona afectada. En la práctica, Cloud Monitoring actúa como si la zona afectada no existiera.
Regional: durante una interrupción regional, las lecturas y escrituras de métricas no están disponibles para los recursos de la región afectada. En la práctica, Cloud Monitoring actúa como si la región afectada no existiera.
Cloud NAT
Cloud NAT (traducción de direcciones de red) es un servicio gestionado distribuido y definido por software que permite que determinados recursos sin direcciones IP externas creen conexiones salientes a Internet. No se basa en VMs ni dispositivos proxy. En su lugar, Cloud NAT configura el software Andromeda que impulsa tu red de nube privada virtual para que proporcione traducción de dirección de red de origen (NAT de origen o SNAT) a las VMs sin direcciones IP externas. Cloud NAT también proporciona traducción de direcciones de red de destino (NAT de destino o DNAT) para los paquetes de respuesta de entrada establecidos.
Para obtener más información sobre la funcionalidad de Cloud NAT, consulta la documentación.
Interrupción de una zona: Cloud NAT es resistente a los fallos de las zonas porque el plano de control y el plano de datos de red son redundantes en varias zonas de una región.
Interrupción regional: Cloud NAT es un producto regional, por lo que no puede resistir un fallo regional.
Cloud Router
Cloud Router es un servicio totalmente distribuido y gestionado Google Cloud que usa el protocolo de puerta de enlace de frontera (BGP) para anunciar intervalos de direcciones IP. Programa rutas dinámicas basadas en los anuncios de BGP que recibe de un peer. En lugar de un dispositivo o un aparato físico, cada Cloud Router consta de tareas de software que actúan como altavoces y respondedores BGP.
En caso de interrupción de una zona, Cloud Router con una configuración de alta disponibilidad (HA) es resistente a los fallos de zonas. En ese caso, es posible que una interfaz pierda la conectividad, pero el tráfico se redirige a la otra interfaz mediante el enrutamiento dinámico con BGP.
En caso de interrupción regional, Cloud Router es un producto regional, por lo que no puede resistir un fallo regional. Si los clientes han habilitado el modo de enrutamiento global, el enrutamiento entre la región con errores y otras regiones podría verse afectado.
Cloud Run
Cloud Run es un entorno de computación sin reconocimiento del estado en el que los clientes pueden ejecutar su código en contenedores en la infraestructura de Google. Cloud Run es una oferta regional, lo que significa que los clientes pueden elegir la región, pero no las zonas que la componen. Los datos y el tráfico se balancean de carga automáticamente entre las zonas de una región. Las instancias de contenedor se escalan automáticamente para adaptarse al tráfico entrante y se balancean entre zonas según sea necesario. Cada zona mantiene un programador que proporciona este escalado automático por zona. También tiene en cuenta la carga que reciben otras zonas y proporcionará capacidad adicional en la zona para hacer frente a posibles fallos zonales.
Si usas GPUs de Cloud Run, puedes desactivar la redundancia zonal del servicio y, en su lugar, usar la fiabilidad con el mejor esfuerzo posible en caso de interrupción zonal, a un coste menor. Para obtener más información, consulta las opciones de redundancia zonal de GPU.
Interrupción zonal: Cloud Run almacena metadatos, así como el contenedor desplegado. Estos datos se almacenan a nivel regional y se escriben de forma síncrona. La API Admin de Cloud Run solo devuelve la llamada a la API una vez que los datos se han confirmado en un quórum de una región. Como los datos se almacenan por regiones, las operaciones del plano de datos tampoco se ven afectadas por los errores zonales. El tráfico se dirigirá a otras zonas en caso de que se produzca un fallo en una zona.
Interrupción regional: los clientes eligen la Google Cloud región en la que quieren crear su servicio de Cloud Run. Los datos nunca se replican entre regiones. Cloud Run nunca dirigirá el tráfico de los clientes a otra región. En caso de que se produzca un fallo regional, Cloud Run volverá a estar disponible en cuanto se resuelva la interrupción. Recomendamos a los clientes que realicen implementaciones en varias regiones y que usen Cloud Load Balancing para conseguir una mayor disponibilidad si lo desean.
Cloud Shell
Cloud Shell proporciona a los usuarios acceso a instancias de Compute Engine de un solo usuario que están preconfiguradas para la incorporación, la formación, el desarrollo y las tareas de los operadores. Google Cloud
Cloud Shell no es adecuado para ejecutar cargas de trabajo de aplicaciones, sino que está diseñado para el desarrollo interactivo y los casos prácticos educativos. Tiene límites de cuota de tiempo de ejecución por usuario, se cierra automáticamente tras un breve periodo de inactividad y solo el usuario asignado puede acceder a la instancia.
Las instancias de Compute Engine que respaldan el servicio son recursos zonales, por lo que, si se produce una interrupción en una zona, el Cloud Shell de un usuario no estará disponible.
Cloud Source Repositories
Cloud Source Repositories permite a los usuarios crear y gestionar repositorios de código fuente privados. Este producto se ha diseñado con un modelo global, por lo que no es necesario configurarlo para que tenga resiliencia regional o de zona.
En su lugar, las operaciones git push en Cloud Source Repositories replican de forma síncrona la actualización del repositorio de origen en varias zonas de varias regiones. Esto significa que el servicio es resistente a las interrupciones en cualquier región.
Si se produce una interrupción en una zona o región concretas, el tráfico se distribuye automáticamente a otras zonas o regiones.
La función para replicar automáticamente repositorios de GitHub o Bitbucket puede verse afectada por problemas en esos productos. Por ejemplo, la creación de réplicas se ve afectada si GitHub o Bitbucket no pueden alertar a Cloud Source Repositories de las nuevas confirmaciones o si Cloud Source Repositories no puede recuperar contenido del repositorio actualizado.
Spanner
Spanner es una base de datos escalable, de alta disponibilidad, multiversión, replicada de forma síncrona y de coherencia inmediata con semánticas relacionales.
Las instancias regionales de Spanner replican los datos de forma síncrona en tres zonas de una misma región. Una escritura en una instancia regional de Spanner se envía de forma síncrona a las tres réplicas y se confirma al cliente después de que al menos dos réplicas (el quórum mayoritario de 2 de 3) hayan confirmado la escritura. De esta forma, Spanner es resistente a los fallos de zona, ya que proporciona acceso a todos los datos. Además, las escrituras más recientes se han conservado y se puede seguir alcanzando un quórum mayoritario para las escrituras con dos réplicas.
Las instancias multirregionales de Spanner incluyen un quórum de escritura que replica los datos de forma síncrona en cinco zonas ubicadas en tres regiones (dos réplicas de lectura y escritura en la región líder predeterminada y en otra región, y una réplica en la región testigo). Una escritura en una instancia multirregional de Spanner se confirma después de que al menos 3 réplicas (el quórum mayoritario de 3 de 5) hayan confirmado la escritura. En caso de que se produzca un fallo en una zona o una región, Spanner tiene acceso a todos los datos (incluidas las últimas escrituras) y atiende las solicitudes de lectura y escritura, ya que los datos se conservan en al menos 3 zonas de 2 regiones en el momento en que se confirma la escritura al cliente.
Consulta la documentación de instancias de Spanner para obtener más información sobre estas configuraciones y la documentación de replicación para obtener más información sobre cómo funciona la replicación de Spanner.
Cloud SQL
Cloud SQL es un servicio de bases de datos relacionales totalmente gestionado para MySQL, PostgreSQL y SQL Server. Cloud SQL usa máquinas virtuales de Compute Engine gestionadas para ejecutar el software de la base de datos. Ofrece una configuración de alta disponibilidad para la redundancia regional, lo que protege la base de datos frente a interrupciones de la zona. Las réplicas entre regiones se pueden aprovisionar para proteger la base de datos frente a una interrupción en una región. Como el producto también ofrece una opción zonal, que no es resistente a una interrupción de la zona o de la región, debes seleccionar con cuidado la configuración de alta disponibilidad, las réplicas entre regiones o ambas.
Interrupción zonal: la opción alta disponibilidad crea una instancia de VM principal y otra de reserva en dos zonas independientes de una misma región. Durante el funcionamiento normal, la instancia de VM principal atiende todas las solicitudes y escribe los archivos de la base de datos en un disco persistente regional, que se replica de forma síncrona en las zonas principal y de espera. Si una interrupción de la zona afecta a la instancia principal, Cloud SQL inicia una conmutación por error durante la cual el disco persistente se adjunta a la VM de espera y se redirige el tráfico.
Durante este proceso, la base de datos debe inicializarse, lo que incluye el procesamiento de las transacciones escritas en el registro de transacciones, pero no aplicadas a la base de datos. El número y el tipo de transacciones no procesadas pueden aumentar el tiempo de espera. Un gran número de escrituras recientes puede provocar una acumulación de transacciones sin procesar. El tiempo de RTO se ve afectado principalmente por (a) una alta actividad de escritura reciente y (b) cambios recientes en los esquemas de la base de datos.
Por último, cuando se haya resuelto la interrupción zonal, puedes activar manualmente una operación de conmutación por recuperación para reanudar el servicio en la zona principal.
Para obtener más información sobre la opción de alta disponibilidad, consulta la documentación sobre alta disponibilidad de Cloud SQL.
Interrupción regional: la opción réplica entre regiones protege tu base de datos de las interrupciones regionales creando réplicas de lectura de tu instancia principal en otras regiones. La replicación entre regiones usa la replicación asíncrona, lo que permite que la instancia principal confirme las transacciones antes de que se confirmen en las réplicas. La diferencia de tiempo entre el momento en que se confirma una transacción en la instancia principal y el momento en que se confirma en la réplica se conoce como "latencia de replicación" (que se puede monitorizar). Esta métrica refleja tanto las transacciones que no se han enviado desde la réplica principal a las réplicas como las transacciones que se han recibido, pero que no han sido procesadas por la réplica. Las transacciones que no se envíen a la réplica no estarán disponibles durante una interrupción regional. Las transacciones recibidas, pero no procesadas por la réplica, afectan al tiempo de recuperación, tal como se describe a continuación.
Cloud SQL recomienda probar tu carga de trabajo con una configuración que incluya una réplica para establecer un límite de "transacciones por segundo (TPS) seguras", que es el TPS sostenido más alto que no acumula latencia de replicación. Si tu carga de trabajo supera el límite de TPS seguro, se acumulará un retraso en la replicación, lo que afectará negativamente a los valores de RPO y RTO. Como norma general, evita usar configuraciones de instancias pequeñas (menos de 2 núcleos de vCPU, menos de 100 GB de discos o PD-HDD), ya que son susceptibles de sufrir retrasos en la replicación.
En caso de interrupción regional, debe decidir si quiere promover manualmente una réplica de lectura. Se trata de una operación manual porque la promoción puede provocar una situación de cerebro dividido en la que la réplica promocionada acepta nuevas transacciones a pesar de haber quedado por detrás de la instancia principal en el momento de la promoción. Esto puede causar problemas cuando se resuelva la interrupción regional y tengas que conciliar las transacciones que nunca se propagaron de las instancias principales a las réplicas. Si esto supone un problema para tus necesidades, puedes plantearte usar un producto de base de datos con replicación síncrona entre regiones, como Spanner.
Una vez que el usuario activa el proceso de promoción, se siguen pasos similares a los de la activación de una instancia de reserva en la configuración de alta disponibilidad. En ese proceso, la réplica de lectura debe procesar el registro de transacciones, lo que determina el tiempo total de recuperación. Como no hay ningún balanceador de carga integrado en la promoción de réplicas, redirige manualmente las aplicaciones a la principal promocionada.
Para obtener más información sobre la opción de réplica entre regiones, consulta la documentación sobre la réplica entre regiones de Cloud SQL.
Para obtener más información sobre la recuperación tras desastres de Cloud SQL, consulta lo siguiente:
- Recuperación tras fallos de la base de datos de Cloud SQL para MySQL
- Recuperación tras fallos de la base de datos de Cloud SQL para PostgreSQL
- Recuperación tras fallos de la base de datos de Cloud SQL para SQL Server
Cloud Storage
Cloud Storage ofrece un servicio de almacenamiento de objetos unificado y escalable a nivel mundial y de alta durabilidad. Los segmentos de Cloud Storage se pueden crear en uno de los tres tipos de ubicación: en una sola región, en dos regiones o en una multirregión de un continente. Con los contenedores regionales, los objetos se almacenan de forma redundante en las zonas de disponibilidad de una sola región. Por otro lado, los segmentos birregionales y multirregionales tienen redundancia geográfica. Esto significa que, después de que los datos recién escritos se repliquen en al menos una región remota, los objetos se almacenan de forma redundante en varias regiones. Este enfoque ofrece a los datos de los segmentos birregionales y multirregionales un conjunto de protecciones más amplio que el que se puede conseguir con el almacenamiento regional.
Los segmentos regionales están diseñados para ser resistentes en caso de interrupción del servicio en una sola zona de disponibilidad. Si se produce una interrupción en una zona, los objetos de la zona no disponible se sirven automáticamente y de forma transparente desde otra parte de la región. Los datos y los metadatos se almacenan de forma redundante en distintas zonas, empezando por la escritura inicial. No se pierde ninguna escritura si una zona deja de estar disponible. En caso de interrupción regional, los segmentos regionales de esa región no estarán disponibles hasta que la región vuelva a estarlo.
Si necesitas una mayor disponibilidad, puedes almacenar datos en una configuración de dos regiones o multirregional. Los segmentos de dos regiones y multirregionales son segmentos únicos (no tienen ubicaciones principales y secundarias independientes), pero almacenan datos y metadatos de forma redundante en varias regiones. En caso de interrupción regional, el servicio no se interrumpe. Puedes considerar que los segmentos birregionales y multirregionales están activos, ya que puedes leer y escribir cargas de trabajo en más de una región simultáneamente mientras el segmento mantiene una coherencia sólida. Esto puede ser especialmente atractivo para los clientes que quieran dividir su carga de trabajo entre las dos regiones como parte de una arquitectura de recuperación tras desastres.
Las regiones duales y multirregionales tienen una coherencia sólida porque los metadatos siempre se escriben de forma síncrona en todas las regiones. Este enfoque permite que el servicio determine siempre cuál es la versión más reciente de un objeto y desde dónde se puede servir, incluidas las regiones remotas.
Los datos se replican de forma asíncrona. Esto significa que hay un periodo de RPO en el que los objetos recién escritos empiezan protegidos como objetos regionales, con redundancia en las zonas de disponibilidad de una sola región. A continuación, el servicio replica los objetos en una o varias regiones remotas dentro de ese periodo de RPO para que sean georredundantes. Una vez completada la replicación, los datos se pueden servir de forma automática y transparente desde otra región en caso de que se produzca una interrupción regional. La replicación turbo es una función premium disponible en los segmentos de dos regiones para obtener una ventana de RPO más pequeña, que tiene como objetivo que el 100% de los objetos recién escritos se repliquen y se hagan georredundantes en un plazo de 15 minutos.
El RPO es un factor importante, ya que, durante una interrupción regional, es posible que los datos escritos recientemente en la región afectada dentro del periodo del RPO aún no se hayan replicado en otras regiones. Por lo tanto, es posible que no se pueda acceder a esos datos durante la interrupción y que se pierdan en caso de destrucción física de los datos en la región afectada.
Cloud Translation
Cloud Translation tiene servidores de computación activos en varias zonas y regiones. También admite la replicación síncrona de datos entre zonas de una misma región. Estas funciones permiten que la traducción consiga una conmutación por error instantánea sin que se pierdan datos en caso de fallos zonales y sin que los clientes tengan que hacer nada. En caso de que se produzca un fallo regional, Cloud Translation no estará disponible.
Compute Engine
Compute Engine es una de las opciones de infraestructura como servicio de Google Cloud. Utiliza la infraestructura mundial de Google para ofrecer máquinas virtuales (y servicios relacionados) a los clientes.
Las instancias de Compute Engine son recursos zonales, por lo que, en caso de interrupción de una zona, las instancias no estarán disponibles de forma predeterminada. Compute Engine ofrece grupos de instancias gestionadas (MIGs) que pueden escalar automáticamente máquinas virtuales adicionales a partir de plantillas de instancia preconfiguradas, tanto en una sola zona como en varias zonas de una región. Los MIGs son ideales para aplicaciones que requieren resistencia a la pérdida de zonas y no tienen estado, pero requieren configuración y planificación de recursos. Se pueden usar varios MIGs regionales para conseguir que las aplicaciones sin estado resistan a las interrupciones de la región.
Las aplicaciones que tienen cargas de trabajo con estado pueden seguir usando grupos de instancias gestionados con estado, pero se debe tener más cuidado al planificar la capacidad, ya que no se escalan horizontalmente. En ambos casos, es importante configurar y probar correctamente las plantillas de instancias de Compute Engine y los MIGs con antelación para asegurarse de que las funciones de conmutación por error a otras zonas funcionan. Consulta la sección Desarrollar tus propias arquitecturas y guías de referencia de arriba para obtener más información.
Único cliente
El alquiler exclusivo te permite tener acceso exclusivo a un nodo de único cliente, que es un servidor físico de Compute Engine dedicado a alojar únicamente las máquinas virtuales de tu proyecto.
Los nodos de único propietario, al igual que las instancias de Compute Engine, son recursos zonales. En el improbable caso de que se produzca una interrupción zonal, no estarán disponibles. Para mitigar los fallos zonales, puedes crear un nodo de único cliente en otra zona. Dado que algunas cargas de trabajo pueden beneficiarse de los nodos de un solo inquilino por motivos de licencias o de contabilidad de gastos de capital, debes planificar una estrategia de conmutación por error con antelación.
Si vuelves a crear estos recursos en otra ubicación, es posible que tengas que pagar costes de licencia adicionales o que incumplas los requisitos de contabilidad de CAPEX. Para obtener información general, consulta el artículo Desarrollar arquitecturas y guías de referencia propias.
Los nodos de único propietario son recursos zonales y no pueden resistir fallos regionales. Para escalar en varias zonas, usa MIGs regionales.
Redes de Compute Engine
Para obtener información sobre las configuraciones de alta disponibilidad de las conexiones Interconnect, consulta los siguientes documentos:
- Disponibilidad del 99,99% en la interconexión dedicada
- Disponibilidad del 99,99% en Partner Interconnect
Puedes aprovisionar direcciones IP externas en modo global o regional, lo que afecta a su disponibilidad en caso de fallo regional.
Resiliencia de Cloud Load Balancing
Los balanceadores de carga son un componente fundamental de la mayoría de las aplicaciones de alta disponibilidad. Es importante tener en cuenta que la resiliencia de tu aplicación en general no depende solo del ámbito del balanceador de carga que elijas (global o regional), sino también de la redundancia de tus servicios de backend.
En la siguiente tabla se resume la resiliencia de los balanceadores de carga en función de su distribución o ámbito.
| Ámbito del balanceador de carga | Arquitectura | Resistencia a las interrupciones de zona | Resistencia a las interrupciones regionales |
|---|---|---|---|
| Global | Cada balanceador de carga se distribuye en todas las regiones | ||
| Interregional | Cada balanceador de carga se distribuye en varias regiones | ||
| Regional | Cada balanceador de carga se distribuye en varias zonas de la región. | Una interrupción en una región determinada afecta a los balanceadores de carga regionales de esa región. |
Para obtener más información sobre cómo elegir un balanceador de carga, consulta la documentación de Cloud Load Balancing.
Pruebas de conectividad
Pruebas de conectividad es una herramienta de diagnóstico que te permite comprobar la conectividad entre los endpoints de las redes. Analiza su configuración y, en algunos casos, realiza un análisis del plano de datos en tiempo real entre los endpoints. Un endpoint es un origen o un destino del tráfico de red, como una máquina virtual, un clúster de Google Kubernetes Engine (GKE), una regla de reenvío del balanceador de carga o una dirección IP. Pruebas de conectividad es una herramienta de diagnóstico que no tiene componentes de plano de datos. No procesa ni genera tráfico de usuarios.
Interrupción zonal: los recursos de Connectivity Tests son globales. Puedes gestionarlos y verlos en caso de interrupción zonal. Los recursos de pruebas de conectividad son los resultados de las pruebas de configuración. Estos resultados pueden incluir los datos de configuración de los recursos zonales (por ejemplo, las instancias de máquina virtual) de una zona afectada. Si hay una interrupción, los resultados del análisis no serán precisos porque se basarán en datos obsoletos de antes de la interrupción. No te fíes de él.
Interrupción regional: en caso de interrupción regional, puede seguir gestionando y viendo los recursos de pruebas de conectividad. Los recursos de pruebas de conectividad pueden incluir datos de configuración de recursos regionales, como subredes, en una región afectada. Si hay una interrupción, los resultados del análisis no serán precisos porque se basarán en datos obsoletos de antes de la interrupción. No te fíes de él.
Container Registry
Container Registry proporciona una implementación de Docker Registry alojada y escalable que almacena de forma segura y privada imágenes de contenedores Docker. Container Registry implementa la API HTTP Docker Registry.
Container Registry es un servicio global que almacena de forma síncrona metadatos de imágenes de forma redundante en varias zonas y regiones de forma predeterminada. Las imágenes de contenedor se almacenan en segmentos multirregionales de Cloud Storage. Con esta estrategia de almacenamiento, Container Registry ofrece resistencia a las interrupciones zonales en todos los casos y resistencia a las interrupciones regionales para cualquier dato que Cloud Storage haya replicado de forma asíncrona en varias regiones.
Database Migration Service
Database Migration Service es un servicio de Google Cloud totalmente gestionado para migrar bases de datos de otros proveedores de servicios en la nube o de centros de datos on-premise a Google Cloud.
Database Migration Service se ha diseñado como un plano de control regional. El plano de control no depende de una zona concreta de una región. Durante una interrupción zonal, conservas el acceso a las APIs del servicio de migración de bases de datos, incluida la posibilidad de crear y gestionar tareas de migración. Durante una interrupción regional, perderás el acceso a los recursos de Database Migration Service que pertenezcan a esa región hasta que se resuelva la interrupción.
Database Migration Service depende de la disponibilidad de las bases de datos de origen y de destino que se utilicen en el proceso de migración. Si una base de datos de origen o de destino del servicio de migración de bases de datos no está disponible, las migraciones dejan de avanzar, pero no se pierden datos principales ni datos de tareas de los clientes. Las tareas de migración se reanudan cuando las bases de datos de origen y destino vuelven a estar disponibles.
Por ejemplo, puedes configurar una base de datos de Cloud SQL de destino con la alta disponibilidad habilitada para obtener una base de datos de destino que sea resistente a las interrupciones zonales.
Las migraciones de Database Migration Service se realizan en dos fases:
- Volcado completo: realiza una copia completa de los datos del origen al destino según la especificación de la tarea de migración.
- Captura de datos de cambios (CDC): replica los cambios incrementales del origen al destino.
Interrupción zonal: si se produce un fallo zonal durante cualquiera de estas fases, podrás seguir accediendo a los recursos y gestionándolos en Database Migration Service. La migración de datos se ve afectada de la siguiente manera:
- Volcado completo: la migración de datos falla. Debes reiniciar la tarea de migración una vez que la base de datos de destino haya completado la operación de conmutación por error.
- CDC: la migración de datos está en pausa. La tarea de migración se reanuda automáticamente cuando la base de datos de destino completa la operación de conmutación por error.
Interrupción regional: Database Migration Service no admite recursos entre regiones, por lo que no es resistente a los fallos regionales.
Dataflow
Dataflow es el servicio de procesamiento de datos sin servidor y totalmente gestionado de Google Cloudpara las canalizaciones de streaming y por lotes. De forma predeterminada, un endpoint regional configura el pool de trabajadores de Dataflow para que use todas las zonas disponibles de la región. La selección de zona se calcula para cada trabajador en el momento en que se crea, lo que optimiza la adquisición de recursos y el uso de reservas sin usar. En la configuración predeterminada de las tareas de Dataflow, el servicio Dataflow almacena los datos intermedios y el estado de la tarea se almacena en el backend. Si una zona falla, las tareas de Dataflow pueden seguir ejecutándose, ya que los trabajadores se vuelven a crear en otras zonas.
Se aplican las siguientes limitaciones:
- La colocación regional solo se admite en las tareas que usan Streaming Engine o Dataflow Shuffle. Los trabajos que no usan Streaming Engine o Dataflow Shuffle no pueden usar la colocación regional.
- La colocación regional solo se aplica a las máquinas virtuales. No se aplica a los recursos relacionados con Streaming Engine y Dataflow Shuffle.
- Las VMs no se replican en varias zonas. Si una máquina virtual deja de estar disponible, sus elementos de trabajo se consideran perdidos y otra máquina virtual los vuelve a procesar.
- Si se agotan las existencias en una región, el servicio Dataflow no podrá crear más VMs.
Diseñar flujos de procesamiento de Dataflow para conseguir una alta disponibilidad
Puedes ejecutar varias canalizaciones de streaming en paralelo para procesar datos de alta disponibilidad. Por ejemplo, puedes ejecutar dos tareas de streaming paralelas en regiones diferentes. Ejecutar flujos de trabajo paralelos proporciona redundancia geográfica y tolerancia a fallos para el procesamiento de datos. Si tienes en cuenta la disponibilidad geográfica de las fuentes y los receptores de datos, puedes operar las canalizaciones completas en una configuración multirregional de alta disponibilidad. Para obtener más información, consulta Alta disponibilidad y redundancia geográfica en "Diseñar flujos de trabajo de flujos de procesamiento de Dataflow".
En caso de interrupción del servicio en una zona o región, puedes evitar la pérdida de datos reutilizando la misma suscripción al tema de Pub/Sub. Para garantizar que no se pierdan registros durante la operación de barajado, Dataflow usa copias de seguridad de la fase anterior, lo que significa que el trabajador que envía los registros vuelve a intentar las llamadas RPC hasta que recibe una confirmación positiva de que el registro se ha recibido y de que los efectos secundarios del procesamiento del registro se han confirmado en el almacenamiento persistente de la fase posterior. Dataflow también sigue reintentando las llamadas RPC si el trabajador que envía los registros deja de estar disponible. Al reintentar las RPCs, se asegura de que cada registro se entregue exactamente una vez. Para obtener más información sobre la garantía de procesamiento "una sola vez" de Dataflow, consulta el artículo Procesamiento "una sola vez" en Dataflow.
Si la canalización usa la agrupación o las ventanas de tiempo, puedes usar la función de búsqueda de Pub/Sub o la función de repetición de Kafka después de una interrupción zonal o regional para volver a procesar los elementos de datos y obtener los mismos resultados de cálculo. Si la lógica empresarial que usa la canalización no depende de los datos anteriores a la interrupción, la pérdida de datos de las salidas de la canalización se puede minimizar hasta 0 elementos. Si la lógica empresarial de la canalización depende de datos que se procesaron antes de la interrupción (por ejemplo, si se usan ventanas de tiempo deslizantes largas o si una ventana de tiempo global almacena contadores que aumentan constantemente), usa snapshots de Dataflow para guardar el estado de la canalización de streaming e iniciar una nueva versión del trabajo sin perder el estado.
Dataproc
Dataproc ofrece funciones de procesamiento de datos en streaming y por lotes. Dataproc se ha diseñado como un plano de control regional que permite a los usuarios gestionar clústeres de Dataproc. El plano de control no depende de una zona concreta de una región determinada. Por lo tanto, durante una interrupción zonal, conservas el acceso a las APIs de Dataproc, incluida la posibilidad de crear clústeres.
Puedes crear clústeres de Dataproc en los siguientes entornos:
Clústeres de Dataproc en Compute Engine
Como un clúster de Dataproc en Compute Engine es un recurso de zona, una interrupción de la zona hace que el clúster no esté disponible o lo destruye. Dataproc no crea automáticamente una instantánea del estado del clúster, por lo que una interrupción de la zona podría provocar la pérdida de los datos que se estén procesando. Dataproc no conserva los datos de usuario en el servicio. Los usuarios pueden configurar sus canalizaciones para escribir resultados en muchos almacenes de datos. Debes tener en cuenta la arquitectura del almacén de datos y elegir un producto que ofrezca la resistencia ante desastres necesaria.
Si una zona sufre una interrupción, puedes recrear una instancia del clúster en otra zona. Para ello, selecciona una zona diferente o usa la función de colocación automática de Dataproc para elegir automáticamente una zona disponible. Una vez que el clúster esté disponible, se podrá reanudar el tratamiento de datos. También puedes ejecutar un clúster con el modo de alta disponibilidad habilitado, lo que reduce la probabilidad de que un fallo parcial de una zona afecte a un nodo maestro y, por lo tanto, a todo el clúster.
Clústeres de Dataproc en GKE
Los clústeres de Dataproc en GKE pueden ser zonales o regionales.
Para obtener más información sobre la arquitectura y las funciones de recuperación ante desastres de los clústeres de GKE zonales y regionales, consulta la sección Google Kubernetes Engine más adelante en este documento.
Datastream
Datastream es un servicio de replicación y captura de datos de cambios (CDC) sin servidor que te permite sincronizar datos de forma fiable y con una latencia mínima. Datastream replica datos de bases de datos operativas en BigQuery y Cloud Storage. Además, ofrece una integración optimizada con las plantillas de Dataflow para crear flujos de trabajo personalizados que permitan cargar datos en una amplia gama de destinos, como Cloud SQL y Spanner.
Interrupción zonal: Datastream es un servicio multizonal. Puede resistir una interrupción zonal completa e imprevista sin perder datos ni disponibilidad. Si se produce un fallo de zona, podrás seguir accediendo a tus recursos y gestionándolos en Datastream.
Interrupción regional: en caso de interrupción regional, Datastream vuelve a estar disponible en cuanto se resuelve la interrupción.
Document AI
Document AI es una plataforma de comprensión de documentos que toma datos no estructurados de documentos y los transforma en datos estructurados, lo que facilita su comprensión, análisis y consumo. Document AI es una oferta regional. Los clientes pueden elegir la región, pero no las zonas de esa región. Los datos y el tráfico se balancean de carga automáticamente entre las zonas de una región. Los servidores se escalan automáticamente para adaptarse al tráfico entrante y se balancean entre zonas según sea necesario. Cada zona mantiene un programador que proporciona este escalado automático por zona. El programador también tiene en cuenta la carga que reciben otras zonas y proporciona capacidad adicional en la zona para hacer frente a cualquier fallo zonal.
Interrupción zonal: Document AI almacena documentos de usuario y datos de versión del procesador. Estos datos se almacenan a nivel regional y se escriben de forma síncrona. Como los datos se almacenan por regiones, las operaciones del plano de datos no se ven afectadas por los fallos zonales. El tráfico se dirige automáticamente a otras zonas en caso de fallo zonal, con un retraso basado en el tiempo que tardan en recuperarse los servicios dependientes, como Vertex AI.
Interrupción regional: los datos nunca se replican en varias regiones. Durante una interrupción regional, Document AI no realizará una conmutación por error. Los clientes eligen la región de Google Cloud en la que quieren usar Document AI. Sin embargo, ese tráfico de clientes nunca se dirige a otra región.
Verificación de puntos finales
La verificación de endpoints permite a los administradores y a los profesionales de operaciones de seguridad crear un inventario de los dispositivos que acceden a los datos de una organización. Verificación de endpoints también proporciona confianza crítica en los dispositivos y control de acceso basado en la seguridad como parte de la solución Chrome Enterprise Premium.
Usa la verificación de puntos de conexión cuando quieras obtener una vista general de la estrategia de seguridad de los portátiles y los ordenadores de escritorio de tu organización. Si se combina con las soluciones de Chrome Enterprise Premium, permite implementar obligatoriamente el control de acceso granular en tus Google Cloud recursos.
Verificación de endpoints está disponible para Google Cloud, Cloud Identity, Google Workspace Business y Google Workspace Enterprise.
Eventarc
Eventarc proporciona eventos enviados de forma asíncrona desde proveedores de Google (propios), aplicaciones de usuario (de terceros) y software como servicio (de terceros) mediante servicios con bajo acoplamiento que reaccionan a los cambios de estado. Permite a los clientes configurar sus destinos (por ejemplo, una instancia de Cloud Run o una función de Cloud Run de segunda generación) para que se activen cuando se produzca un evento en un servicio de proveedor de eventos o en el código del cliente.
Interrupción zonal: Eventarc almacena metadatos relacionados con los activadores. Estos datos se almacenan a nivel regional y se escriben de forma síncrona. La API Eventarc, que crea y gestiona activadores y canales, solo devuelve la llamada a la API cuando los datos se han confirmado en un quórum de una región. Como los datos se almacenan por regiones, las operaciones del plano de datos no se ven afectadas por los fallos de las zonas. En caso de que se produzca un fallo en una zona, el tráfico se dirigirá automáticamente a otras zonas. Los servicios de Eventarc para recibir y enviar eventos de terceros y de segundos se replican en todas las zonas. Estos servicios se distribuyen por regiones. Las solicitudes a zonas no disponibles se atienden automáticamente desde las zonas disponibles de la región.
Interrupción regional: los clientes eligen la Google Cloud región en la que quieren crear sus activadores de Eventarc. Los datos nunca se replican entre regiones. Eventarc nunca dirige el tráfico de los clientes a otra región. En caso de fallo regional, Eventarc vuelve a estar disponible en cuanto se resuelve la interrupción. Para conseguir una mayor disponibilidad, se recomienda a los clientes que implementen activadores en varias regiones, si lo desean.
Ten en cuenta lo siguiente:
- Los servicios de Eventarc para recibir y enviar eventos propios se proporcionan en la medida de lo posible y no están cubiertos por el RTO ni el RPO.
- La entrega de eventos de Eventarc para los servicios de Google Kubernetes Engine se proporciona de la mejor forma posible y no está cubierta por el tiempo de recuperación objetivo (RTO) ni por el punto de recuperación objetivo (RPO).
Filestore
Los niveles Basic y Zonal son recursos de zona. No toleran los errores de la zona o la región implementadas.
Las instancias de Filestore de nivel regional son recursos regionales. Filestore adopta la estricta política de coherencia que requiere NFS. Cuando un cliente escribe datos, Filestore no devuelve una confirmación hasta que el cambio se conserva y se replica en dos zonas para que las lecturas posteriores devuelvan los datos correctos.
En caso de que falle una zona, una instancia de nivel regional sigue sirviendo datos desde otras zonas y, mientras tanto, acepta nuevas escrituras. Es posible que las operaciones de lectura y escritura tengan un rendimiento inferior. Es posible que la operación de escritura no se replique. El cifrado no se verá comprometido porque la clave se proporcionará desde otras zonas.
Recomendamos que los clientes creen copias de seguridad externas por si se producen más interrupciones en otras zonas de la misma región. La copia de seguridad se puede usar para restaurar la instancia en otras regiones.
Firestore
Firestore es una base de datos flexible y escalable para el desarrollo móvil, web y de servidores de Firebase y Google Cloud. Firestore ofrece replicación de datos multirregional automática, garantías de coherencia inmediata, operaciones por lotes atómicas y transacciones ACID.
Firestore ofrece a los clientes ubicaciones de una sola región y multirregionales. El tráfico se balancea de carga automáticamente entre las zonas de una región.
Las instancias regionales de Firestore replican los datos de forma síncrona en al menos tres zonas. En caso de fallo de una zona, las dos (o más) réplicas restantes pueden seguir confirmando las escrituras y los datos confirmados se conservan. El tráfico se dirige automáticamente a otras zonas. Una ubicación regional ofrece costes más bajos, menor latencia de escritura y colocación conjunta con otros recursos. Google Cloud
Las instancias multirregionales de Firestore replican los datos de forma síncrona en cinco zonas de tres regiones (dos regiones de servicio y una región testigo) y son resistentes a los fallos zonales y regionales. En caso de fallo por zonas o regional, los datos confirmados se conservan. El tráfico se dirige automáticamente a las zonas o regiones de servicio, y las confirmaciones se siguen sirviendo en al menos tres zonas de las dos regiones restantes. Las multirregiones maximizan la disponibilidad y la durabilidad de las bases de datos.
Firewall Insights
Firewall Insights te ayuda a comprender y optimizar tus reglas de cortafuegos. Proporciona información valiosa, recomendaciones y métricas sobre cómo se usan tus reglas de cortafuegos. Firewall Insights también usa el aprendizaje automático para predecir el uso futuro de las reglas de cortafuegos. Firewall Insights te permite tomar mejores decisiones durante la optimización de las reglas de cortafuegos. Por ejemplo, Firewall Insights identifica las reglas que clasifica como demasiado permisivas. Puedes usar esta información para reforzar la configuración de tu cortafuegos.
Interrupción zonal: como los datos de Estadísticas de firewall se replican en varias zonas, no se ven afectados por una interrupción zonal y el tráfico de los clientes se dirige automáticamente a otras zonas.
Interrupción regional: como los datos de Estadísticas de firewall se replican en varias regiones, no se ven afectados por una interrupción regional y el tráfico de los clientes se dirige automáticamente a otras regiones.
Fleet
Las flotas permiten a los clientes gestionar varios clústeres de Kubernetes como un grupo y a los administradores de plataformas usar servicios multiclúster. Por ejemplo, las flotas permiten a los administradores aplicar políticas uniformes en todos los clústeres o configurar Ingress de varios clústeres.
Cuando registras un clúster de GKE en una flota, de forma predeterminada, el clúster tiene una pertenencia regional en la misma región. Cuando registras un clúster que no esGoogle Cloud en una flota, puedes elegir cualquier región o la ubicación global. Lo más recomendable es elegir una región que esté cerca de la ubicación física del clúster. De esta forma, se consigue una latencia óptima al usar Connect Gateway para acceder al clúster.
En caso de interrupción zonal, las funciones de la flota no se verán afectadas a menos que el clúster subyacente sea zonal y deje de estar disponible.
En caso de interrupción regional, las funciones de la flota fallan de forma estática en los clústeres miembros de la región. Para mitigar una interrupción del servicio regional, es necesario implementar la solución en varias regiones, tal como se sugiere en el artículo Diseñar la recuperación tras desastres para las interrupciones de la infraestructura en la nube.
Google Cloud Armor
Cloud Armor te ayuda a proteger tus implementaciones y aplicaciones frente a varios tipos de amenazas, incluidos los ataques DDoS volumétricos y los ataques a aplicaciones, como los de cross-site scripting y de inyección de SQL. Cloud Armor filtra el tráfico no deseado en los balanceadores de carga de Google Cloud e impide que entre en tu VPC y consuma recursos. Algunas de estas protecciones son automáticas. En algunos casos, debes configurar políticas de seguridad y asociarlas a servicios de backend o regiones. Las políticas de seguridad de Cloud Armor de ámbito global se aplican a los balanceadores de carga globales. Las políticas de seguridad de ámbito regional se aplican a los balanceadores de carga regionales.
Interrupción zonal: en caso de interrupción zonal, los balanceadores de carga de Google Cloud redirigen el tráfico a otras zonas en las que haya instancias de backend en buen estado disponibles. La protección de Cloud Armor está disponible inmediatamente después de la conmutación por error del tráfico, ya que tus políticas de seguridad de Cloud Armor se replican de forma síncrona en todas las zonas de una región.
Interrupción regional: en caso de interrupciones regionales, los balanceadores de carga globales de Google Cloud redirigen el tráfico a otras regiones en las que haya instancias de backend en buen estado. La protección de Cloud Armor está disponible inmediatamente después de la conmutación por error del tráfico, ya que tus políticas de seguridad globales de Cloud Armor se replican de forma síncrona en todas las regiones. Para tener resiliencia ante fallos regionales, debe configurar políticas de seguridad regionales de Cloud Armor en todas sus regiones.
Google Kubernetes Engine
Google Kubernetes Engine (GKE) ofrece un servicio de Kubernetes gestionado que simplifica el despliegue de aplicaciones en contenedores en Google Cloud. Puedes elegir entre topologías de clúster regionales o zonales.
- Al crear un clúster zonal, GKE aprovisiona una máquina del plano de control en la zona elegida, así como máquinas de trabajador (nodos) en la misma zona.
- En el caso de los clústeres regionales, GKE aprovisiona tres máquinas del plano de control en tres zonas diferentes de la región elegida. De forma predeterminada, los nodos también se distribuyen en tres zonas, aunque puedes crear un clúster regional con nodos aprovisionados en una sola zona.
- Los clústeres multizona son similares a los clústeres zonales, ya que incluyen una máquina principal, pero además ofrecen la posibilidad de abarcar nodos en varias zonas.
Interrupción zonal: para evitar interrupciones zonales, usa clústeres regionales. El plano de control y los nodos se distribuyen en tres zonas diferentes de una región. Una interrupción de una zona no afecta al plano de control ni a los nodos de trabajador implementados en las otras dos zonas.
Interrupción regional: para mitigar una interrupción regional, es necesario realizar una implementación en varias regiones. Aunque actualmente no se ofrece como una función integrada, la topología multirregión es un enfoque que adoptan varios clientes de GKE y que se puede implementar manualmente. Puedes crear varios clústeres regionales para replicar tus cargas de trabajo en varias regiones y controlar el tráfico a estos clústeres mediante la entrada multi-clúster.
VPN de alta disponibilidad
La VPN de alta disponibilidad es una oferta de Cloud VPN resistente que cifra de forma segura el tráfico desde tu nube privada on-premise, otra nube privada virtual u otra red de proveedor de servicios en la nube hasta tu nube privada virtual (VPC) de Google Cloud.
Las pasarelas de VPN de alta disponibilidad tienen dos interfaces, cada una con una dirección IP de grupos de direcciones IP independientes, divididas tanto lógica como físicamente en diferentes puntos de presencia y clústeres, para asegurar una redundancia óptima.
Interrupción zonal: en caso de interrupción zonal, es posible que una interfaz pierda la conectividad, pero el tráfico se redirige a la otra interfaz mediante el enrutamiento dinámico con el protocolo de pasarela fronteriza (BGP).
Interrupción regional: en caso de interrupción regional, es posible que ambas interfaces pierdan la conectividad durante un breve periodo.
Gestión de Identidades y Accesos
Gestión de Identidades y Accesos (IAM) es responsable de todas las decisiones de autorización
para las acciones en los recursos de la nube. Gestión de identidades y accesos confirma que una política concede permiso para cada acción (en el plano de datos) y procesa las actualizaciones de esas políticas mediante una llamada SetPolicy (en el plano de control).
Todas las políticas de gestión de identidades y accesos se replican en varias zonas de cada región, lo que ayuda a que las operaciones del plano de datos de gestión de identidades y accesos se recuperen de los fallos de otras regiones y toleren los fallos de las zonas de cada región. La resiliencia del plano de datos de IAM frente a fallos de zonas y regiones permite arquitecturas multirregionales y multizona para lograr una alta disponibilidad.
Las operaciones del plano de control de IAM pueden depender de la replicación entre regiones. Cuando las llamadas SetPolicy se completan correctamente, los datos se han escrito en varias regiones, pero la propagación a otras regiones es coherente con el tiempo.
El plano de control de IAM es resistente a los fallos de una sola región.
Identity-Aware Proxy
Identity-Aware Proxy proporciona acceso a aplicaciones alojadas en Google Cloud, en otras nubes y on-premise. IAP se distribuye por regiones y las solicitudes a zonas no disponibles se atienden automáticamente desde otras zonas disponibles de la región.
Las interrupciones regionales en las compras en aplicaciones afectan al acceso a las aplicaciones alojadas en la región afectada. Te recomendamos que implementes tu aplicación en varias regiones y que uses Cloud Load Balancing para conseguir una mayor disponibilidad y resiliencia frente a las interrupciones regionales.
Identity Platform
Identity Platform permite a los clientes añadir a sus aplicaciones la gestión de identidades y accesos propia de Google, que es personalizable. Identity Platform es una oferta global. Los clientes no pueden elegir las regiones ni las zonas en las que se almacenan sus datos.
Interrupción zonal: durante una interrupción zonal, Identity Platform transfiere las solicitudes a la celda más cercana. Todos los datos se guardan a escala global, por lo que no se pierden.
Interrupción regional: durante una interrupción regional, las solicitudes de Identity Platform a la región no disponible fallan temporalmente mientras Identity Platform elimina el tráfico de la región afectada. Cuando ya no haya tráfico a la región afectada, un servicio de balanceo de carga de servidor global dirigirá las solicitudes a la región disponible más cercana. Todos los datos se guardan a nivel mundial, por lo que no se pierden.
Servicio de Knative
Knative Serving es un servicio global que permite a los clientes ejecutar cargas de trabajo sin servidor en clústeres de clientes. Su objetivo es asegurarse de que las cargas de trabajo de Knative Serving se implementen correctamente en los clústeres de los clientes y de que el estado de instalación de Knative Serving se refleje en el recurso de función de la API Fleet de GKE. Este servicio solo participa cuando se instalan o actualizan recursos de Knative Serving en clústeres de clientes. No participa en la ejecución de cargas de trabajo de clústeres. Los clústeres de clientes que pertenecen a proyectos en los que se ha habilitado Knative Serving se distribuyen entre réplicas de varias regiones y zonas. Cada clúster está monitorizado por una réplica.
Interrupción zonal y regional: los clústeres que monitorizan las réplicas alojadas en una ubicación que está sufriendo una interrupción se redistribuyen automáticamente entre las réplicas en buen estado de otras zonas y regiones. Mientras se lleva a cabo esta reasignación, puede que haya un breve periodo en el que Knative Serving no monitorice algunos clústeres. Si durante ese tiempo el usuario decide habilitar las funciones de Knative Serving en el clúster, la instalación de los recursos de Knative Serving en el clúster comenzará después de que el clúster se vuelva a conectar con una réplica de servicio de Knative Serving en buen estado.
Looker (servicio principal de Google Cloud)
Looker (en la infraestructura de Google Cloud) es una plataforma de inteligencia empresarial que ofrece un aprovisionamiento, una configuración y una gestión simplificados y optimizados de una instancia de Looker desde la Google Cloud consola. Looker (principal de Google Cloud) permite a los usuarios explorar datos, crear paneles de control, configurar alertas y compartir informes. Además, Looker (Google Cloud core) ofrece un IDE para modeladores de datos y funciones de API y de inserción enriquecida para desarrolladores.
Looker (Google Cloud core) se compone de instancias aisladas por regiones que replican datos de forma síncrona en las zonas de la región. Asegúrate de que los recursos que usa tu instancia, como las fuentes de datos a las que se conecta Looker (Google Cloud core), estén en la misma región en la que se ejecuta tu instancia.
Interrupción zonal: las instancias de Looker (principal de Google Cloud) almacenan metadatos y sus propios contenedores desplegados. Los datos se escriben de forma síncrona en las instancias replicadas. En caso de interrupción zonal, las instancias de Looker (servicio principal de Google Cloud) siguen funcionando desde otras zonas disponibles de la misma región. Las transacciones o las llamadas a la API se devuelven después de que los datos se hayan confirmado en un quórum de una región. Si la replicación falla, la transacción no se confirma y se notifica al usuario. Si falla más de una zona, las transacciones también fallarán y se notificará al usuario. Looker (en la infraestructura de Google Cloud) detiene las programaciones o consultas que se estén ejecutando. Tendrás que volver a programarlas o ponerlas en cola después de solucionar el problema.
Interrupción regional: las instancias de Looker (en la infraestructura de Google Cloud) de la región afectada no están disponibles. Looker (Google Cloud core) detiene las programaciones o las consultas que se estén ejecutando. Una vez que hayas resuelto el problema, tendrás que volver a programar o poner en cola las consultas. Puedes crear manualmente nuevas instancias en otra región. También puedes recuperar tus instancias siguiendo el proceso definido en Importar o exportar datos de una instancia de Looker (Google Cloud Core). Te recomendamos que configures un proceso de exportación de datos periódico para copiar los recursos con antelación, por si se produce una interrupción regional (aunque es poco probable).
Looker Studio
Looker Studio es un producto de visualización de datos y de inteligencia empresarial. Permite a los clientes conectarse a los datos almacenados en otros sistemas, crear informes y paneles de control con esos datos, y compartir los informes y los paneles de control en toda su organización. Looker Studio es un servicio global y no permite que los usuarios seleccionen un ámbito de recursos.
En caso de interrupción zonal, Looker Studio sigue atendiendo las solicitudes de otra zona de la misma región o de otra región sin interrupción. Los recursos de usuario se replican de forma síncrona en todas las regiones. Por lo tanto, no se pierden datos.
En caso de interrupción regional, Looker Studio seguirá atendiendo las solicitudes de otra región sin interrupción. Los recursos de los usuarios se replican de forma síncrona en todas las regiones. Por lo tanto, no se pierden datos.
Memorystore para Memcached
Memorystore para Memcached es la oferta de Memcached gestionada de Google Cloud. Memorystore para Memcached permite a los clientes crear clústeres de Memcached que se pueden usar como bases de datos de valor-clave de alto rendimiento para aplicaciones.
Los clústeres de Memcached son regionales y sus nodos se distribuyen en todas las zonas especificadas por el cliente. Sin embargo, Memcached no replica ningún dato entre nodos. Por lo tanto, un fallo zonal puede provocar la pérdida de datos, lo que también se conoce como vaciado parcial de la caché. Las instancias de Memcached seguirán funcionando, pero tendrán menos nodos. El servicio no iniciará ningún nodo nuevo durante un fallo zonal. Los nodos de Memcached de las zonas no afectadas seguirán sirviendo tráfico, aunque el fallo zonal provocará una tasa de aciertos de caché más baja hasta que se recupere la zona.
En caso de fallo regional, los nodos de Memcached no sirven tráfico. En ese caso, se pierden los datos, lo que provoca una limpieza de caché completa. Para mitigar una interrupción regional, puedes implementar una arquitectura que despliegue la aplicación y Memorystore para Memcached en varias regiones.
Memorystore para Redis
Memorystore para Redis es un servicio de Redis totalmente gestionado para Google Cloud que puede reducir la carga de gestionar implementaciones complejas de Redis. Actualmente, ofrece dos niveles: el nivel básico y el nivel estándar. En el nivel Básico, si se produce una interrupción del servicio en una zona o una región, se perderán los datos, lo que también se conoce como limpieza de caché completa. En el nivel Estándar, si hay una interrupción del servicio que afecte a una región, se perderán los datos. Una interrupción del servicio zonal puede provocar una pérdida parcial de datos en una instancia de nivel Estándar debido a su replicación asíncrona.
Interrupción zonal: las instancias del nivel Estándar replican de forma asíncrona las operaciones del conjunto de datos del nodo principal al nodo de réplica. Si se produce una interrupción en la zona del nodo principal, el nodo de réplica se convertirá en el nodo principal. Durante la promoción, se produce una conmutación por error y el cliente de Redis tiene que volver a conectarse a la instancia. Después de volver a conectarte, las operaciones se reanudarán. Para obtener más información sobre la alta disponibilidad de las instancias de Memorystore para Redis en el nivel estándar, consulta el artículo Alta disponibilidad de Memorystore para Redis.
Si habilitas las réplicas de lectura en tu instancia de nivel Estándar y solo tienes una réplica, el endpoint de lectura no estará disponible durante una interrupción zonal. Para obtener más información sobre la recuperación ante desastres de las réplicas de lectura, consulta Modos de fallo de las réplicas de lectura.
Interrupción regional: Memorystore para Redis es un producto regional, por lo que una sola instancia no puede resistir un fallo regional. Puedes programar tareas periódicas para exportar una instancia de Redis a un segmento de Cloud Storage de otra región. Cuando se produce una interrupción regional, puede restaurar la instancia de Redis en otra región a partir del conjunto de datos que haya exportado.
Descubrimiento de servicios en varios clústeres y entrada de varios clústeres
Los servicios multiclúster de GKE (MCS) constan de varios componentes. Entre los componentes se incluyen el centro de Google Kubernetes Engine (que orquesta varios clústeres de Google Kubernetes Engine mediante membresías), los propios clústeres y los controladores del centro de GKE (Multi Cluster Ingress y Multi-Cluster Service Discovery). Los controladores del centro orquestan la configuración del balanceador de carga de Compute Engine mediante back-ends en varios clústeres.
En caso de interrupción zonal, el descubrimiento de servicios en varios clústeres sigue atendiendo solicitudes de otra zona o región. En caso de interrupción regional, el descubrimiento de servicios en varios clústeres no realiza una conmutación por error.
En el caso de una interrupción zonal de Ingress con varios clústeres, si el clúster de configuración es zonal y está dentro del ámbito del fallo, el usuario debe realizar la conmutación por error manualmente. El plano de datos es estático en caso de fallo y seguirá sirviendo tráfico hasta que el usuario haya cambiado a la réplica. Para evitar la necesidad de realizar una conmutación por error manual, usa un clúster regional para el clúster de configuración.
En caso de interrupción regional, Ingress de varios clústeres no realiza la conmutación por error. Los usuarios deben tener un plan de recuperación ante desastres para conmutar por error manualmente el clúster de configuración. Para obtener más información, consulta Configurar Ingress de varios clústeres y Configurar servicios de varios clústeres.
Para obtener más información sobre GKE, consulta la sección "Google Kubernetes Engine" del artículo Arquitectura de recuperación ante desastres para interrupciones de la infraestructura en la nube.
Network Analyzer
Network Analyzer monitoriza automáticamente las configuraciones de tu red de VPC y detecta las configuraciones que son erróneas o no óptimas. Proporciona información valiosa sobre la topología de la red, las reglas de cortafuegos, las rutas, las dependencias de configuración y la conectividad a servicios y aplicaciones. Identifica los errores de red, proporciona información sobre la causa principal y sugiere posibles soluciones.
Analizador de red se ejecuta continuamente y activa análisis relevantes en función de las actualizaciones de configuración casi en tiempo real de tu red. Si Analizador de red detecta un fallo en la red, intenta relacionarlo con los cambios de configuración recientes para identificar las causas principales. Siempre que sea posible, proporciona recomendaciones con detalles sobre cómo solucionar los problemas.
Network Analyzer es una herramienta de diagnóstico sin componentes de plano de datos. No procesa ni genera tráfico de usuarios.
Interrupción de la zona: el servicio Network Analyzer se replica a nivel mundial, por lo que su disponibilidad no se ve afectada por una interrupción de la zona.
Si las estadísticas de Network Analyzer contienen configuraciones de una zona que sufre una interrupción, esto afecta a la calidad de los datos. Las métricas de la red que hacen referencia a las configuraciones de esa zona dejan de estar actualizadas. No confíe en las estadísticas que proporciona Network Analyzer durante las interrupciones.
Interrupción regional: el servicio Network Analyzer se replica a nivel mundial, por lo que su disponibilidad no se ve afectada por una interrupción regional.
Si las estadísticas de Analizador de red contienen configuraciones de una región que sufre una interrupción, esto afecta a la calidad de los datos. Las métricas de la red que hacen referencia a las configuraciones de esa región se quedarán obsoletas. No confíe en las estadísticas que proporciona Network Analyzer durante las interrupciones.
Topología de las redes
Topología de las redes es una herramienta de visualización que muestra la topología de tu infraestructura de red. La vista Infraestructura muestra las redes de nube privada virtual (VPC), la conectividad híbrida hacia y desde tus redes on-premise, la conectividad a los servicios gestionados por Google y las métricas asociadas.
Interrupción zonal: en caso de interrupción zonal, los datos de esa zona no aparecerán en Topología de red. Los datos de otras zonas no se verán afectados.
Interrupción regional: en caso de que se produzca una interrupción regional, los datos de esa región no aparecerán en Topología de red. Los datos de otras regiones no se verán afectados.
Panel de rendimiento
El panel de rendimiento te permite ver el rendimiento de toda la Google Cloud red, así como el rendimiento de los recursos de tu proyecto.
Con estas funciones de monitorización del rendimiento, puedes distinguir entre un problema de tu aplicación y un problema de la Google Cloud red subyacente. También puedes investigar problemas históricos de rendimiento de la red. El panel de rendimiento también exporta datos a Cloud Monitoring. Puedes usar Monitoring para consultar los datos y acceder a información adicional.
Interrupción zonal:
En caso de interrupción zonal, los datos de latencia y pérdida de paquetes del tráfico de la zona afectada no aparecerán en el panel de rendimiento. Los datos de latencia y pérdida de paquetes del tráfico de otras zonas no se ven afectados. Cuando finalice la interrupción, se reanudarán los datos de latencia y pérdida de paquetes.
Interrupción regional:
En caso de interrupción regional, los datos de latencia y pérdida de paquetes del tráfico de la región afectada no aparecerán en el panel de rendimiento. Los datos de latencia y pérdida de paquetes del tráfico de otras regiones no se verán afectados. Cuando finalice la interrupción, se reanudarán los datos de latencia y pérdida de paquetes.
Network Connectivity Center
Network Connectivity Center es un producto de gestión de la conectividad de red que emplea una arquitectura de eje y radio. Con esta arquitectura, un recurso de gestión central actúa como centro y cada recurso de conectividad actúa como radio. Actualmente, las ramas híbridas admiten VPN de alta disponibilidad, Interconexión Dedicada y de Partner, y dispositivos router SD-WAN de los principales proveedores externos. Con las radios híbridas de Network Connectivity Center, las empresas pueden conectar cargas de trabajo y servicios a centros de datos locales, otras nubes y sus sucursales a través de la cobertura global de la red. Google Cloud Google Cloud
Interrupción zonal: un spoke híbrido de Network Connectivity Center con una configuración de alta disponibilidad es resistente a los fallos zonales porque el plano de control y el plano de datos de red son redundantes en varias zonas de una región.
Interrupción regional: un radio híbrido de Network Connectivity Center es un recurso regional, por lo que no puede resistir un fallo regional.
Niveles de servicio de red
Los niveles de servicio de red te permiten optimizar la conectividad entre los sistemas de Internet y tus Google Cloud instancias. Ofrece dos niveles de servicio distintos: Premium y Standard. Con el nivel Premium, una dirección IP de nivel Premium de Anycast anunciada a nivel mundial puede servir como frontend para backends regionales o globales. Con el nivel estándar, una dirección IP de nivel estándar anunciada regionalmente puede servir como frontend para backends regionales. La resiliencia general de una aplicación se ve influida tanto por el nivel de servicio de la red como por la redundancia de los back-ends con los que se asocia.
Interrupción de una zona: tanto el nivel Premium como el Estándar ofrecen resistencia ante las interrupciones de una zona cuando se asocian a back-ends con redundancia regional. Cuando se produce una interrupción zonal, el comportamiento de conmutación por error en los casos que usan back-ends con redundancia regional se determina por los propios back-ends asociados. Cuando se asocie a back-ends zonales, el servicio volverá a estar disponible en cuanto se resuelva la interrupción.
Interrupción regional: el nivel Premium ofrece resistencia frente a las interrupciones regionales cuando se asocia a backends redundantes a nivel mundial. En el nivel Estándar, se producirá un error en todo el tráfico a la región afectada. El tráfico al resto de las regiones no se verá afectado. Cuando se produce una interrupción regional, el comportamiento de conmutación por error en los casos que usan el nivel Premium con back-ends redundantes a nivel global se determina por los propios back-ends asociados. Si utilizas el nivel Premium con back-ends regionales o el nivel Standard, el servicio volverá a estar disponible en cuanto se resuelva la interrupción.
Servicio de política de organización
El servicio de políticas de organización proporciona un control centralizado y programático sobre los Google Cloud recursos de tu organización. Como administrador de la política de organización, puedes configurar restricciones en toda tu jerarquía de recursos.
Interrupción zonal: todas las políticas de organización creadas por el servicio de políticas de organización se replican de forma asíncrona en varias zonas de cada región. Los datos de la política de la organización y las operaciones del plano de control toleran los fallos de zona en cada región.
Interrupción regional: todas las políticas de organización creadas por el servicio de políticas de organización se replican de forma asíncrona en varias regiones. Las operaciones del plano de control de la política de la organización se escriben en varias regiones y la propagación a otras regiones se realiza de forma coherente en cuestión de minutos. El plano de control de la política de organización es resistente a los fallos de una sola región. Las operaciones del plano de datos de la política de la organización pueden recuperarse de los fallos en otras regiones. Además, la resiliencia del plano de datos de la política de la organización frente a los fallos de zonas y regiones permite arquitecturas multirregionales y multizona para lograr una alta disponibilidad.
Replicación de paquetes
Replicación de paquetes clona el tráfico de las instancias especificadas en tu red de nube privada virtual (VPC) y reenvía los datos clonados a las instancias que hay detrás de un balanceador de carga interno regional para su análisis. La replicación de paquetes captura todo el tráfico y los datos de los paquetes, incluidas las cargas útiles y los encabezados.
Para obtener más información sobre la función de réplica de paquetes, consulta la página de descripción general de la réplica de paquetes.
Interrupción zonal: configura el balanceador de carga interno para que haya instancias en varias zonas. Si se produce una interrupción zonal, la replicación de paquetes desvía los paquetes clonados a una zona en buen estado.
Interrupción regional: Packet Mirroring es un producto regional. Si hay una interrupción regional, los paquetes de la región afectada no se clonarán.
Persistent Disk
Los discos persistentes están disponibles en configuraciones zonales y regionales.
Los discos persistentes de zona se alojan en una sola zona. Si la zona del disco no está disponible, el disco persistente tampoco lo estará hasta que se resuelva la interrupción de la zona.
Los discos persistentes regionales proporcionan la replicación síncrona de datos entre dos zonas de una región. En caso de interrupción en la zona de tu máquina virtual, puedes forzar la conexión de un disco persistente regional a una instancia de máquina virtual en la zona secundaria del disco. Para llevar a cabo esta tarea, debes iniciar otra instancia de VM en esa zona o mantener una instancia de VM de reserva activa en esa zona.
Para replicar datos de forma asíncrona en un Persistent Disk entre regiones, puedes usar la replicación asíncrona de Persistent Disk (replicación asíncrona de PD), que ofrece replicación de almacenamiento en bloques con RTO y RPO bajos para la recuperación tras fallos activa-pasiva entre regiones. En el improbable caso de que se produzca una interrupción regional, la replicación asíncrona de PD te permite conmutar por error tus datos a una región secundaria y reiniciar tu carga de trabajo en esa región.
Personalized Service Health
Personalized Service Health comunica las interrupciones de los servicios que sean relevantes para tus Google Cloud proyectos. Proporciona varios canales y procesos para ver o integrar eventos disruptivos (incidentes, mantenimiento programado) en tu proceso de respuesta ante incidentes, entre los que se incluyen los siguientes:
- Un panel de control en la consola de Google Cloud
- Una API de servicio
- Alertas configurables
- Registros generados y enviados a Cloud Logging
Interrupción zonal: los datos se sirven desde una base de datos global sin dependencia de ubicaciones específicas. Si se produce una interrupción zonal, el estado del servicio puede atender solicitudes y redirigir automáticamente el tráfico a las zonas de la misma región que sigan funcionando. Service Health puede devolver llamadas a la API correctamente si puede obtener datos de eventos de la base de datos de Service Health.
Interrupción regional: los datos se sirven desde una base de datos global sin depender de ubicaciones específicas. Si hay una interrupción regional, el estado del servicio podrá seguir atendiendo solicitudes, pero es posible que su capacidad se vea reducida. Los fallos regionales en las ubicaciones de Logging pueden afectar a los usuarios de Service Health que consumen registros o notificaciones de alertas en la nube.
Private Service Connect
Private Service Connect es una función de Google Cloud redes que permite a los consumidores acceder a servicios gestionados de forma privada desde su red de VPC. Del mismo modo, permite a los productores de servicios gestionados alojar estos servicios en sus propias redes de VPC independientes y ofrecer una conexión privada a sus consumidores.
Endpoints de Private Service Connect para servicios publicados
Un punto final de Private Service Connect se conecta a los servicios de la red de VPC de los productores de servicios mediante una regla de reenvío de Private Service Connect. El productor de servicios proporciona un servicio mediante conectividad privada a un consumidor de servicios exponiendo un único archivo adjunto de servicio. De esta forma, el consumidor del servicio podrá asignar una dirección IP virtual de su VPC a dicho servicio.
Interrupción zonal: el tráfico de Private Service Connect que procede del tráfico de la VM generado por los puntos finales de cliente de la VPC del consumidor puede seguir accediendo a los servicios gestionados expuestos en la red de VPC interna del productor de servicios. Este acceso es posible porque el tráfico de Private Service Connect se transfiere a backends de servicio más sanos en otra zona.
Interrupción regional: Private Service Connect es un producto regional. No es resistente a las interrupciones regionales. Los servicios gestionados multirregionales pueden lograr una alta disponibilidad durante las interrupciones regionales configurando endpoints de Private Service Connect en varias regiones.
Puntos finales de Private Service Connect para APIs de Google
Un punto final de Private Service Connect se conecta a las APIs de Google mediante una regla de reenvío de Private Service Connect. Esta regla de reenvío permite a los clientes usar nombres de endpoint personalizados con sus direcciones IP internas.
Interrupción zonal: el tráfico de Private Service Connect desde los puntos finales de cliente de la VPC del consumidor aún puede acceder a las APIs de Google, ya que la conexión entre la VM y el punto final se conmutará automáticamente a otra zona funcional de la misma región. Las solicitudes que ya estén en curso cuando empiece una interrupción dependerán del tiempo de espera TCP del cliente y del comportamiento de reintento para recuperarse.
Para obtener más información, consulta la sección sobre recuperación de Compute Engine.
Interrupción regional: Private Service Connect es un producto regional. No es resistente a las interrupciones regionales. Los servicios gestionados multirregionales pueden lograr una alta disponibilidad durante las interrupciones regionales configurando endpoints de Private Service Connect en varias regiones.
Para obtener más información sobre Private Service Connect, consulta la sección "Endpoints" (Puntos finales) del artículo Tipos de Private Service Connect.
Pub/Sub
Pub/Sub es un servicio de mensajería para la integración de aplicaciones y las analíticas de streaming. Los temas de Pub/Sub son globales, lo que significa que se pueden ver y acceder desde cualquier Google Cloud ubicación. Sin embargo, cada mensaje se almacena en una sola región, la más cercana al editor y permitida por la política de ubicación de recursos. Google Cloud Por lo tanto, un tema puede tener mensajes almacenados en diferentes regiones de Google Cloud. La política de almacenamiento de mensajes de Pub/Sub puede restringir las regiones en las que se almacenan los mensajes.
Interrupción zonal: cuando se publica un mensaje de Pub/Sub, se escribe de forma síncrona en el almacenamiento de al menos dos zonas de la región. Por lo tanto, si una zona deja de estar disponible, no habrá ningún impacto visible para los clientes.
Interrupción regional: durante una interrupción regional, no se puede acceder a los mensajes almacenados en la región afectada. Los editores y suscriptores que se conecten a la región afectada, ya sea a través de un endpoint regional o del endpoint global, no podrán hacerlo. Los editores y suscriptores que se conecten a otras regiones podrán seguir conectándose, y los mensajes disponibles en otras regiones se enviarán a los suscriptores más cercanos de la red que tengan capacidad.
Si tu aplicación depende del orden de los mensajes, consulta las recomendaciones detalladas del equipo de Pub/Sub. Las garantías de orden de los mensajes se proporcionan por región y pueden interrumpirse si usas un endpoint global.
reCAPTCHA
reCAPTCHA es un servicio global que detecta la actividad fraudulenta, el spam y el uso inadecuado. No requiere ni permite la configuración de la resiliencia regional o zonal. Las actualizaciones de los metadatos de configuración se replican de forma asíncrona en cada región en la que se ejecuta reCAPTCHA.
En caso de interrupción zonal, reCAPTCHA sigue atendiendo solicitudes desde otra zona de la misma región o de otra región sin interrupción.
En caso de interrupción regional, reCAPTCHA sigue atendiendo solicitudes de otra región sin interrupciones.
Secret Manager
Secret Manager es un producto de gestión de secretos y credenciales paraGoogle Cloud. Con Secret Manager, puedes auditar y restringir fácilmente el acceso a los secretos, cifrar los secretos en reposo y asegurarte de que la información sensible esté protegida en Google Cloud.
Los recursos de Secret Manager se suelen crear con la política de replicación automática (recomendada), lo que hace que se repliquen en todo el mundo. Si tu organización tiene políticas que no permiten la réplica global de datos de secretos, los recursos de Secret Manager se pueden crear con políticas de réplica gestionadas por el usuario, en las que se eligen una o varias regiones para que se replique un secreto.
Interrupción zonal: en caso de interrupción zonal, Secret Manager sigue atendiendo solicitudes de otra zona de la misma región o de otra diferente sin interrupción. En cada región, Secret Manager siempre mantiene al menos 2 réplicas en zonas independientes (en la mayoría de las regiones, 3 réplicas). Cuando se soluciona la interrupción de la zona, se restaura la redundancia completa.
Interrupción regional: en caso de interrupción regional, Secret Manager sigue atendiendo las solicitudes de otra región sin interrupción, siempre que los datos se hayan replicado en más de una región (ya sea mediante la replicación automática o mediante la replicación gestionada por el usuario en más de una región). Cuando se resuelva la interrupción del servicio en la región, se restaurará la redundancia completa.
Security Command Center
Security Command Center es la plataforma de gestión de riesgos global y en tiempo real de Google Cloud. Consta de dos componentes principales: detectores y resultados.
Los detectores se ven afectados por las interrupciones regionales y zonales, pero de formas diferentes. Durante una interrupción regional, los detectores no pueden generar nuevos resultados para los recursos regionales porque los recursos que se supone que deben analizar no están disponibles.
Durante un corte de luz zonal, los detectores pueden tardar entre varios minutos y horas en volver a funcionar con normalidad. Security Command Center no perderá los datos de los resultados. Tampoco generará datos de nuevas detecciones para los recursos no disponibles. En el peor de los casos, los agentes de Container Threat Detection pueden quedarse sin espacio de búfer al conectarse a una celda en buen estado, lo que podría provocar que se perdieran detecciones.
Las detecciones son resistentes a las interrupciones regionales y zonales porque se replican de forma síncrona en todas las regiones.
Protección de Datos Sensibles (incluida la API DLP)
Protección de Datos Sensibles ofrece servicios de clasificación, creación de perfiles, desidentificación y tokenización de datos sensibles, así como de análisis de riesgos para la privacidad. Funciona de forma síncrona con los datos que se envían en los cuerpos de las solicitudes o de forma asíncrona con los datos que ya están presentes en los sistemas de almacenamiento en la nube. Se puede invocar Protección de Datos Sensibles a través de los endpoints globales o específicos de una región.
Endpoint global: el servicio se ha diseñado para que sea resistente a los fallos regionales y de zona. Si el servicio está sobrecargado cuando se produce un fallo, es posible que se pierdan los datos enviados al método hybridInspect del servicio.
Para crear una arquitectura resistente a los fallos, incluye lógica para examinar el resultado más reciente de la función hybridInspect. En caso de interrupción, es posible que se pierdan los datos que se hayan enviado al método, pero no más de los últimos 10 minutos antes del evento de fallo. Si hay resultados más recientes que 10 minutos antes de que empezara la interrupción, significa que no se han perdido los datos que han dado lugar a esos resultados. En ese caso, no es necesario reproducir los datos que se hayan enviado antes de la marca de tiempo del hallazgo, aunque estén dentro del intervalo de 10 minutos.
Punto de conexión regional: los puntos de conexión regionales no son resistentes a los fallos regionales. Si necesitas resiliencia frente a un fallo regional, considera la posibilidad de conmutar por error a otras regiones. Las características de los fallos zonales son las mismas que las anteriores.
Uso de Servicio
La API Service Usage es un servicio de infraestructura de Google Cloud que te permite listar y gestionar APIs y servicios en tus proyectos de Google Cloud . Puedes enumerar y gestionar APIs y servicios proporcionados por Google, Google Cloudy productores externos. La API Usage Service es un servicio global y resistente a las interrupciones zonales y regionales. En caso de interrupción zonal o regional, la API Service Usage sigue atendiendo solicitudes de otra zona de diferentes regiones.
Para obtener más información sobre Uso de Servicio, consulta la documentación de Uso de Servicio.
Speech‑to‑Text
Speech-to-Text te permite convertir audio de voz en texto mediante técnicas de aprendizaje automático, como los modelos de redes neuronales. El audio se envía en tiempo real desde el micrófono de una aplicación o se procesa como un lote de archivos de audio.
Interrupción zonal:
API Speech-to-Text v1: durante una interrupción zonal, la versión 1 de la API Speech-to-Text sigue atendiendo solicitudes de otra zona de la misma región sin interrupción. Sin embargo, se perderán los trabajos que se estén ejecutando en la zona que falla. Los usuarios deben volver a intentar las tareas fallidas, que se dirigirán automáticamente a una zona disponible.
API Speech-to-Text v2: durante una interrupción zonal, la versión 2 de la API Speech-to-Text sigue atendiendo solicitudes desde otra zona de la misma región. Sin embargo, se perderán los trabajos que se estén ejecutando en la zona que falla. Los usuarios deben volver a intentar las tareas fallidas, que se dirigirán automáticamente a una zona disponible. La API Speech-to-Text solo devuelve la llamada a la API una vez que los datos se han confirmado en un quórum de una región. En algunas regiones, los aceleradores de IA (TPUs) solo están disponibles en una zona. En ese caso, si se produce una interrupción en esa zona, el reconocimiento de voz no funcionará, pero no se perderán datos.
Interrupción regional:
API Speech-to-Text v1: la versión 1 de la API Speech-to-Text no se ve afectada por los fallos regionales porque es un servicio multirregional global. El servicio sigue respondiendo a las solicitudes de otra región sin interrupciones. Sin embargo, los trabajos que se estén ejecutando en la región con errores se perderán. Los usuarios deben volver a intentar esos trabajos fallidos, que se dirigirán automáticamente a una región disponible.
API Speech-to-Text v2:
Versión 2 de la API Speech-to-Text multirregional: el servicio sigue atendiendo solicitudes de otra zona de la misma región sin interrupciones.
Versión 2 de la API Speech-to-Text de una sola región: el servicio limita la ejecución del trabajo a la región solicitada. La versión 2 de la API Speech-to-Text no dirige el tráfico a otra región y los datos no se replican en otra región. Durante un fallo regional, la versión 2 de la API Speech-to-Text no está disponible en esa región. Sin embargo, vuelve a estar disponible cuando se soluciona la interrupción.
Servicio de transferencia de Storage
El Servicio de transferencia de Storage gestiona las transferencias de datos de varias fuentes en la nube a Cloud Storage, así como a sistemas de archivos, desde ellos y entre ellos.
La API del Servicio de transferencia de Storage es un recurso global.
El Servicio de transferencia de Storage depende de la disponibilidad del origen y del destino de una transferencia. Si una fuente o un destino de transferencia no está disponible, las transferencias dejan de avanzar. Sin embargo, no se perderán datos principales de clientes ni datos de trabajos. Las transferencias se reanudarán cuando el origen y el destino vuelvan a estar disponibles.
Puedes usar el Servicio de transferencia de Storage con o sin un agente, de la siguiente manera:
Las transferencias sin agente usan trabajadores regionales para coordinar las tareas de transferencia.
Las transferencias basadas en agentes usan agentes de software que se instalan en tu infraestructura. Las transferencias basadas en agentes dependen de la disponibilidad de los agentes de transferencia y de la capacidad de los agentes para conectarse al sistema de archivos. Cuando decidas dónde instalar los agentes de transferencia, ten en cuenta la disponibilidad del sistema de archivos. Por ejemplo, si ejecutas agentes de transferencia en varias máquinas virtuales de Compute Engine para transferir datos a una instancia de Filestore de nivel Enterprise (un recurso regional), deberías plantearte ubicar las máquinas virtuales en zonas diferentes de la región de la instancia de Filestore.
Si los agentes dejan de estar disponibles o se interrumpe su conexión con el sistema de archivos, las transferencias dejarán de avanzar, pero no se perderán datos. Si se terminan todos los procesos del agente, la tarea de transferencia se pausará hasta que se añadan nuevos agentes al grupo de agentes de la transferencia.
Durante una interrupción, el Servicio de transferencia de Storage se comporta de la siguiente manera:
Interrupción zonal: durante una interrupción zonal, las APIs del Servicio de transferencia de Storage siguen estando disponibles y puedes seguir creando tareas de transferencia. Los datos se siguen transfiriendo.
Interrupción regional: durante una interrupción regional, las APIs del Servicio de transferencia de Storage siguen estando disponibles y puedes seguir creando tareas de transferencia. Si los trabajadores de tu transferencia se encuentran en la región afectada, la transferencia de datos se detendrá hasta que la región vuelva a estar disponible y la transferencia se reanude automáticamente.
Vertex ML Metadata
Vertex ML Metadata te permite registrar los metadatos y los artefactos producidos por tu sistema de aprendizaje automático, así como consultar esos metadatos para analizar, depurar y auditar el rendimiento de tu sistema de aprendizaje automático o los artefactos que produce.
Interrupción por zonas: en la configuración predeterminada, Vertex ML Metadata ofrece protección frente a fallos por zonas. El servicio se implementa en varias zonas de cada región y los datos se replican de forma síncrona en diferentes zonas de cada región. En caso de que se produzca un fallo en una zona, las zonas restantes se harán cargo con una interrupción mínima.
Interrupción regional: Vertex ML Metadata es un servicio regionalizado. En caso de interrupción regional, Vertex ML Metadata no se conmutará por error a otra región.
Predicción por lotes de Vertex AI
La predicción por lotes permite a los usuarios ejecutar predicciones por lotes en modelos de IA o aprendizaje automático en la infraestructura de Google. La predicción por lotes es una oferta regional. Los clientes pueden elegir la región en la que ejecutan los trabajos, pero no las zonas específicas de esa región. El servicio de predicción por lotes balancea la carga del trabajo automáticamente entre las diferentes zonas de la región elegida.
Interrupción de una zona: la predicción por lotes almacena metadatos de las tareas de predicción por lotes en una región. Los datos se escriben de forma síncrona en varias zonas de esa región. En caso de interrupción zonal, la predicción por lotes pierde parcialmente los trabajadores que realizan tareas, pero los vuelve a añadir automáticamente en otras zonas disponibles. Si fallan varios reintentos de predicción por lotes, la interfaz de usuario mostrará el estado del trabajo como failed (fallido) en la interfaz y en las solicitudes de llamadas a la API. Las solicitudes posteriores de los usuarios para ejecutar el trabajo se enrutan a las zonas disponibles.
Interrupción regional: los clientes eligen la Google Cloud región en la que quieren ejecutar sus trabajos de predicción por lotes. Los datos nunca se replican entre regiones. La predicción por lotes limita la ejecución de la tarea a la región solicitada y nunca dirige las solicitudes de predicción a otra región. Cuando se produce un fallo regional, la predicción por lotes no está disponible en esa región. Vuelve a estar disponible cuando se soluciona la interrupción. Recomendamos que los clientes usen varias regiones para ejecutar sus tareas. En caso de interrupción regional, dirige los trabajos a otra región disponible.
Registro de modelos de Vertex AI
Vertex AI Model Registry permite a los usuarios optimizar la gestión, la gobernanza y el despliegue de modelos de aprendizaje automático en un repositorio central. El registro de modelos de Vertex AI es una oferta regional con alta disponibilidad y protección frente a interrupciones zonales.
Interrupción zonal: el registro de modelos de Vertex AI ofrece protección contra interrupciones zonales. El servicio se implementa en tres zonas de cada región y los datos se replican de forma síncrona en diferentes zonas de la región. Si una zona falla, las zonas restantes tomarán el control sin que se pierdan datos y con una interrupción mínima del servicio.
Interrupción regional: el registro de modelos de Vertex AI es un servicio regionalizado. Si falla una región, Model Registry no realizará una conmutación por error.
Predicción online de Vertex AI
La predicción online permite a los usuarios desplegar modelos de IA o aprendizaje automático en Google Cloud. La predicción online es una oferta regional. Los clientes pueden elegir la región en la que implementan sus modelos, pero no las zonas específicas de esa región. El servicio de predicción balanceará automáticamente la carga de trabajo entre las diferentes zonas de la región seleccionada.
Interrupción zonal: la predicción online no almacena contenido de los clientes. Una interrupción zonal provoca un error en la ejecución de la solicitud de predicción actual. La predicción online puede volver a intentar automáticamente la solicitud de predicción o no, en función del tipo de punto final que se utilice. En concreto, un punto final público volverá a intentarlo automáticamente, mientras que un punto final privado no lo hará. Para gestionar los errores y mejorar la resiliencia, incorpora una lógica de reintentos con un tiempo de espera exponencial en tu código.
Interrupción regional: los clientes eligen la Google Cloud región en la que quieren ejecutar sus modelos de IA o aprendizaje automático y sus servicios de predicción online. Los datos nunca se replican entre regiones. La predicción online limita la ejecución del modelo de IA o aprendizaje automático a la región solicitada y nunca dirige las solicitudes de predicción a otra región. Cuando se produce un fallo regional, el servicio de predicción online no está disponible en esa región. Vuelve a estar disponible cuando se soluciona la interrupción. Recomendamos que los clientes usen varias regiones para ejecutar sus modelos de IA o aprendizaje automático. En caso de que se produzca una interrupción regional, dirige el tráfico a otra región disponible.
Vertex AI Pipelines
Vertex AI Pipelines es un servicio de Vertex AI que te permite automatizar, monitorizar y controlar tus flujos de trabajo de aprendizaje automático (ML) sin servidor. Vertex AI Pipelines se ha diseñado para ofrecer una alta disponibilidad y protección frente a fallos de zonas.
Interrupción zonal: en la configuración predeterminada, Vertex AI Pipelines ofrece protección frente a fallos zonales. El servicio se implementa en varias zonas de cada región y los datos se replican de forma síncrona en diferentes zonas de la región. En caso de que se produzca un fallo en una zona, las zonas restantes se harán cargo con una interrupción mínima.
Interrupción regional: Vertex AI Pipelines es un servicio regionalizado. En caso de interrupción regional, Vertex AI Pipelines no se conmutará por error a otra región. Si se produce una interrupción regional, te recomendamos que ejecutes tus tareas de la canalización en una región de copia de seguridad.
Vertex AI Search
Vertex AI Search es una solución de búsqueda personalizable con funciones de IA generativa y cumplimiento nativo para empresas. Vertex AI Search se implementa y replica automáticamente en varias regiones de Google Cloud. Puedes configurar dónde se almacenan los datos eligiendo una multirregión admitida, como global, EE. UU. o la UE.
Interrupción zonal y regional: es posible que no se puedan recuperar los datos UserEvents subidos a Vertex AI Search debido a un retraso en la replicación asíncrona. Otros datos y servicios proporcionados por Vertex AI Search siguen estando disponibles gracias a la conmutación por error automática y a la replicación de datos síncrona.
Vertex AI Training
Vertex AI Training ofrece a los usuarios la posibilidad de ejecutar trabajos de entrenamiento personalizados en la infraestructura de Google. Vertex AI Training es una oferta regional, lo que significa que los clientes pueden elegir la región en la que ejecutar sus trabajos de entrenamiento. Sin embargo, los clientes no pueden elegir las zonas específicas de esa región. El servicio de entrenamiento puede balancear la carga de la ejecución del trabajo automáticamente entre las diferentes zonas de la región.
Interrupción zonal: Vertex AI Training almacena metadatos de la tarea de entrenamiento personalizada. Estos datos se almacenan a nivel regional y se escriben de forma síncrona. La llamada a la API Vertex AI Training solo se devuelve una vez que estos metadatos se han confirmado en un quórum dentro de una región. El trabajo de entrenamiento puede ejecutarse en una zona específica. Una interrupción del servicio en una zona provoca un error en la ejecución de la tarea actual. Si es así, el servicio vuelve a intentar realizar el trabajo automáticamente dirigiéndolo a otra zona. Si se produce un error en varios reintentos, el estado del trabajo se actualiza a "failed" (error). Las solicitudes posteriores de los usuarios para ejecutar el trabajo se enrutan a una zona disponible.
Interrupción regional: los clientes eligen la Google Cloud región en la que quieren ejecutar sus tareas de entrenamiento. Los datos nunca se replican entre regiones. Vertex AI Training limita la ejecución de la tarea a la región solicitada y nunca la dirige a otra región. En caso de fallo regional, el servicio Vertex AI Training no estará disponible en esa región y volverá a estarlo cuando se resuelva la interrupción. Recomendamos a los clientes que usen varias regiones para ejecutar sus tareas y, en caso de que se produzca una interrupción regional, que dirijan las tareas a otra región que esté disponible.
Nube privada virtual (VPC)
Las VPCs son un servicio global que proporciona conectividad de red a los recursos (por ejemplo, las VMs). Sin embargo, los errores son zonales. En caso de que se produzca un fallo en una zona, los recursos de esa zona no estarán disponibles. Del mismo modo, si falla una región, solo se verá afectado el tráfico hacia y desde la región que ha fallado. La conectividad de las regiones en buen estado no se ve afectada.
Interrupción zonal: si una red de VPC abarca varias zonas y una de ellas falla, la red de VPC seguirá funcionando correctamente en las zonas que no hayan fallado. El tráfico de red entre los recursos de las zonas en buen estado seguirá funcionando con normalidad durante el fallo. Un fallo zonal solo afecta al tráfico de red hacia y desde los recursos de la zona afectada. Para mitigar el impacto de los fallos de zona, le recomendamos que no cree todos los recursos en una sola zona. En su lugar, cuando crees recursos, distribúyelos entre las zonas.
Interrupción regional: si una red de VPC abarca varias regiones y una de ellas falla, la red de VPC seguirá funcionando correctamente en las regiones que no hayan fallado. El tráfico de red entre los recursos de las regiones en buen estado seguirá funcionando con normalidad durante el fallo. Un fallo regional solo afecta al tráfico de red hacia y desde los recursos de la región afectada. Para mitigar el impacto de los fallos regionales, te recomendamos que distribuyas los recursos en varias regiones.
Controles de Servicio de VPC
Controles de Servicio de VPC es un servicio regional. Con Controles de Servicio de VPC, los equipos de seguridad de las empresas pueden definir controles de perímetro detallados y reforzar su estrategia de seguridad en numerosos Google Cloud servicios y proyectos. Las políticas de clientes se replican a nivel regional.
Interrupción de la zona: Controles de Servicio de VPC sigue atendiendo solicitudes de otra zona de la misma región sin interrupciones.
Interrupción regional: las APIs configuradas para aplicar la política de Controles de Servicio de VPC en la región afectada no estarán disponibles hasta que la región vuelva a estarlo. Recomendamos a los clientes que desplieguen servicios con Controles de Servicio de VPC en varias regiones si quieren aumentar la disponibilidad.
Flujos de trabajo
Workflows es un producto de orquestación que permite a los clientes: Google Cloud
- Desplegar y ejecutar flujos de trabajo que conecten otros servicios mediante HTTP.
- Automatizar procesos, como esperar respuestas HTTP con reintentos automáticos durante un año como máximo.
- Implementar procesos en tiempo real con ejecuciones de baja latencia basadas en eventos.
Un cliente de Workflows puede desplegar flujos de trabajo que describan la lógica empresarial que quiera llevar a cabo y, a continuación, ejecutar los flujos de trabajo directamente con la API o con activadores basados en eventos (actualmente, solo se pueden usar Pub/Sub o Eventarc). El flujo de trabajo que se está ejecutando puede manipular variables, hacer llamadas HTTP y almacenar los resultados, o definir retrollamadas y esperar a que otro servicio lo reanude.
Interrupción zonal: el código fuente de los flujos de trabajo no se ve afectado por las interrupciones zonales. Workflows almacena el código fuente de los flujos de trabajo, así como los valores de las variables y las respuestas HTTP recibidas por los flujos de trabajo que se están ejecutando. El código fuente se almacena de forma regional y se escribe de forma síncrona: la API del plano de control solo devuelve un valor cuando estos metadatos se han confirmado en un quórum dentro de una región. Las variables y los resultados HTTP también se almacenan a nivel regional y se escriben de forma síncrona, al menos cada cinco segundos.
Si falla una zona, los flujos de trabajo se reanudan automáticamente en función de los últimos datos almacenados. Sin embargo, las solicitudes HTTP que aún no hayan recibido respuestas no se volverán a intentar automáticamente. Usa políticas de reintento para las solicitudes que se puedan reintentar de forma segura, tal como se describe en nuestra documentación.
Interrupción regional: Workflows es un servicio regionalizado. En caso de interrupción regional, Workflows no se conmutará por error. Recomendamos a los clientes que implementen Workflows en varias regiones si quieren tener una mayor disponibilidad.
Cloud Service Mesh
Cloud Service Mesh te permite configurar una malla de servicios gestionada que abarca varios clústeres de GKE. Esta documentación solo se refiere a Cloud Service Mesh gestionado. La variante en el clúster es autohospedada y se deben seguir las directrices de la plataforma habituales.
Interrupción de una zona: la configuración de la malla, como se almacena en el clúster de GKE, es resistente a las interrupciones de una zona siempre que el clúster sea regional. Los datos que usa el producto para llevar un registro interno se almacenan a nivel regional o global, y no se ven afectados si una sola zona deja de funcionar. El plano de control se ejecuta en la misma región que el clúster de GKE al que da servicio (en el caso de los clústeres zonales, es la región que los contiene) y no se ve afectado por las interrupciones en una sola zona.
Interrupción regional: Cloud Service Mesh proporciona servicios a clústeres de GKE, que pueden ser regionales o zonales. En caso de interrupción regional, Cloud Service Mesh no realizará una conmutación por error. Tampoco GKE. Recomendamos a los clientes que implementen mallas compuestas por clústeres de GKE que abarquen diferentes regiones.
Directorio de servicios
El Directorio de servicios es una plataforma para descubrir, publicar y conectar servicios. Proporciona información en tiempo real sobre todos tus servicios en un solo lugar. El directorio de servicios te permite gestionar el inventario de servicios a gran escala, tanto si tienes pocos endpoints de servicio como si tienes miles.
Los recursos de la guía de servicios se crean por regiones, según el parámetro de ubicación especificado por el usuario.
Interrupción zonal: durante una interrupción zonal, Service Directory sigue respondiendo a las solicitudes de otra zona de la misma región o de otra región sin interrupción. En cada región, Directorio de servicios siempre mantiene varias réplicas. Una vez que se haya resuelto la interrupción zonal, se restaurará la redundancia completa.
Interrupción regional: Directorio de servicios no es resistente a las interrupciones regionales.