Este documento es la primera parte de una serie en la que se aborda la recuperación tras fallos en Google Cloud. En esta parte se ofrece una descripción general del proceso de planificación de recuperación tras fallos: lo que debes saber para diseñar e implementar un plan de recuperación tras fallos. En las siguientes partes se analizan casos prácticos específicos de recuperación ante desastres con ejemplos de implementaciones en Google Cloud.
La serie consta de las siguientes partes:
- Guía de planificación para la recuperación tras fallos (este documento)
- Componentes básicos de recuperación tras fallos
- Situaciones de recuperación tras fallos con los datos
- Situaciones de recuperación tras fallos de aplicaciones
- Diseñar la recuperación tras fallos para cargas de trabajo con restricciones de localidad
- Casos prácticos de recuperación ante desastres: aplicaciones de analíticas de datos restringidas por localidad
- Diseñar la recuperación tras fallos para las interrupciones de la infraestructura de la nube
Los eventos que interrumpen el servicio pueden ocurrir en cualquier momento. Tu red podría sufrir una interrupción, la última versión de tu aplicación podría introducir un error crítico o podrías tener que hacer frente a un desastre natural. Cuando las cosas no van bien, es importante tener un plan de recuperación tras fallos sólido, específico y bien probado.
Con un plan de recuperación tras fallos bien diseñado y probado, puedes asegurarte de que, si se produce una catástrofe, el impacto en los resultados de tu empresa sea mínimo. Sean cuales sean tus necesidades de recuperación tras fallos, Google Cloud ofrece una selección de productos y funciones robusta, flexible y rentable que puedes usar para crear o mejorar la solución que más te convenga.
Conceptos básicos de la planificación de DR
La recuperación tras desastres es un subconjunto de la planificación de la continuidad de la actividad empresarial. La planificación de la recuperación tras fallos empieza con un análisis del impacto empresarial que define dos métricas clave:
- Un objetivo de tiempo de recuperación (RTO), que es el tiempo máximo aceptable que tu aplicación puede estar sin conexión. Este valor suele definirse como parte de un acuerdo de nivel de servicio (ANS) más amplio.
- Un objetivo de punto de recuperación (RPO), que es el tiempo máximo aceptable durante el cual se pueden perder datos de tu aplicación debido a un incidente grave. Esta métrica varía en función de las formas en que se usan los datos. Por ejemplo, los datos de usuario que se modifican con frecuencia podrían tener un RPO de solo unos minutos. Por el contrario, los datos menos críticos y que se modifican con poca frecuencia podrían tener un RPO de varias horas. Esta métrica solo describe el tiempo que se ha perdido, no la cantidad ni la calidad de los datos.
Por lo general, cuanto menores sean los valores de RTO y RPO (es decir, cuanto más rápido deba recuperarse tu aplicación de una interrupción), más costará ejecutarla. En el siguiente gráfico se muestra la relación entre el coste y el RTO/RPO.
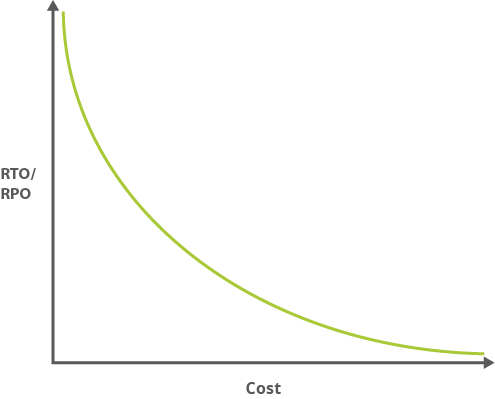
Dado que los valores de RTO y RPO más pequeños suelen implicar una mayor complejidad, la carga administrativa asociada sigue una curva similar. Una aplicación de alta disponibilidad puede requerir que gestiones la distribución entre dos centros de datos separados físicamente, que gestiones la replicación, etc.
Los valores de RTO y RPO suelen agregarse en otra métrica: el objetivo de nivel de servicio (SLO), que es un elemento clave medible de un SLA. A menudo, los SLA y los SLO se confunden. Un ANS es el acuerdo completo que especifica qué servicio se va a proporcionar, cómo se va a ofrecer asistencia, los plazos, las ubicaciones, los costes, el rendimiento, las sanciones y las responsabilidades de las partes implicadas. Los SLOs son características específicas y medibles del SLA, como la disponibilidad, el rendimiento, la frecuencia, el tiempo de respuesta o la calidad. Un SLA puede contener muchos SLOs. Los TPOs y los TPs son medibles y deben considerarse SLOS.
Puedes consultar más información sobre los SLOs y los SLAs en el libro Site Reliability Engineering de Google.
También puedes estar planificando una arquitectura de alta disponibilidad. La alta disponibilidad no se solapa por completo con la recuperación ante desastres, pero a menudo es necesario tenerla en cuenta cuando se piensa en los valores de RTO y RPO. La alta disponibilidad ayuda a garantizar un nivel de rendimiento operativo acordado, normalmente tiempo de actividad, durante un periodo superior al habitual. Cuando ejecutas cargas de trabajo de producción enGoogle Cloud, puedes usar un sistema distribuido globalmente para que, si algo va mal en una región, la aplicación siga ofreciendo servicio aunque no esté disponible en todas partes. En esencia, esa aplicación invoca su plan de recuperación tras fallos.
¿Por qué? Google Cloud
Google Cloud puede reducir en gran medida los costes asociados tanto al RTO como al RPO en comparación con el cumplimiento de los requisitos de RTO y RPO on-premise. Por ejemplo, la planificación de la recuperación ante desastres requiere que tengas en cuenta una serie de requisitos, entre los que se incluyen los siguientes:
- Capacidad: conseguir suficientes recursos para escalar según sea necesario.
- Seguridad: proporciona seguridad física para proteger los recursos.
- Infraestructura de red: incluye componentes de software como firewalls y balanceadores de carga.
- Asistencia: poner a disposición técnicos cualificados para realizar tareas de mantenimiento y solucionar problemas.
- Ancho de banda: planificar un ancho de banda adecuado para la carga máxima.
- Instalaciones: asegurar la infraestructura física, incluido el equipo y la energía.
Al proporcionar una solución muy gestionada en una plataforma de producción de primer nivel,Google Cloud te ayuda a evitar la mayoría o todos estos factores, lo que reduce muchos costes empresariales. Además, Google Cloudse centra en la simplicidad administrativa, lo que significa que también se reducen los costes de gestión de una aplicación compleja.
Google Cloud ofrece varias funciones relevantes para la planificación de la recuperación ante desastres, entre las que se incluyen las siguientes:
- Una red mundial. En Google contamos con una de las redes informáticas más grandes y avanzadas del mundo. La red troncal de Google utiliza redes definidas por software avanzadas y servicios de almacenamiento en caché perimetral para ofrecer un rendimiento rápido, uniforme y escalable.
- Redundancia. Los múltiples puntos de presencia (PoPs) de todo el mundo ofrecen una gran redundancia. Tus datos se replican automáticamente en dispositivos de almacenamiento de varias ubicaciones.
- Escalabilidad. Google Cloud está diseñado para escalarse como otros productos de Google (por ejemplo, la Búsqueda y Gmail), incluso cuando experimentes un enorme pico de tráfico. Los servicios gestionados, como Cloud Run, Compute Engine y Firestore, te ofrecen un escalado automático que permite que tu aplicación crezca y se reduzca según sea necesario.
- Seguridad. El modelo de seguridad de Google se basa en décadas de experiencia protegiendo a los clientes en aplicaciones de Google como Gmail y Google Workspace. Además, los equipos de Site Reliability Engineering de Google ayudan a garantizar una alta disponibilidad y a evitar el uso inadecuado de los recursos de la plataforma.
- Cumplimiento. Google se somete periódicamente a auditorías externas independientes para verificar que Google Cloud cumple las normativas y las prácticas recomendadas de seguridad, privacidad y cumplimiento. Google Cloud Cumple certificaciones como ISO 27001, SOC 2/3 y PCI DSS 3.0.
Patrones de recuperación ante desastres
Los patrones de respuesta ante la demanda se consideran fríos, cálidos o calientes. Estos patrones indican la facilidad con la que el sistema puede recuperarse cuando algo va mal. Una analogía sería lo que harías si estuvieras conduciendo y se te pinchara un neumático.
La forma de afrontar un pinchazo depende de lo preparado que estés:
- Fría: no tienes rueda de repuesto, así que debes llamar a alguien para que te traiga una rueda nueva y la cambie. El viaje se detendrá hasta que llegue la asistencia para hacer la reparación.
- Cálido: tienes una rueda de repuesto y un kit de sustitución, por lo que puedes volver a la carretera con lo que tienes en el coche. Sin embargo, debes detener el viaje para solucionar el problema.
- Hot: You have run-flat tires. Puede que tengas que reducir un poco la velocidad, pero no afectará a tu viaje de inmediato. Los neumáticos están en buen estado, por lo que puedes seguir conduciendo (aunque debes solucionar el problema tarde o temprano).
Crear un plan de recuperación ante desastres detallado
En esta sección se ofrecen recomendaciones sobre cómo crear un plan de recuperación ante desastres.
Diseña tu estrategia en función de tus objetivos de recuperación
Al diseñar tu plan de recuperación tras desastres, debes combinar tus técnicas de recuperación de aplicaciones y datos, y tener una visión más general. La forma habitual de hacerlo es consultar los valores de RTO y RPO, y el patrón de recuperación ante desastres que puedes adoptar para cumplir esos valores. Por ejemplo, en el caso de los datos históricos orientados al cumplimiento, probablemente no necesite un acceso rápido a los datos, por lo que es adecuado un valor de RTO grande y un patrón de recuperación ante desastres en frío. Sin embargo, si tu servicio online sufre una interrupción, querrás poder recuperar tanto los datos como la parte de la aplicación que ven los usuarios lo antes posible. En ese caso, sería más adecuado usar un patrón de calor. Tu sistema de notificaciones por correo electrónico, que normalmente no es fundamental para la empresa, probablemente sea un buen candidato para un patrón de uso moderado.
Para obtener información sobre cómo usar Google Cloud para abordar situaciones de recuperación ante desastres habituales, consulta los escenarios de recuperación de aplicaciones. En estos casos se proporcionan estrategias de recuperación ante desastres específicas para distintos casos prácticos y se ofrecen ejemplos de implementaciones enGoogle Cloud para cada uno.
Diseñar una recuperación integral
No basta con tener un plan para hacer copias de seguridad o archivar tus datos. Asegúrate de que tu plan de recuperación ante desastres abarca todo el proceso de recuperación, desde la copia de seguridad hasta la restauración y la limpieza. Hablamos de ello en los documentos relacionados sobre los datos y la recuperación ante desastres.
Especifica tus tareas
Cuando llegue el momento de ejecutar tu plan de recuperación ante desastres, no querrás tener que adivinar qué significa cada paso. Cada tarea de tu plan de recuperación ante desastres debe constar de uno o varios comandos o acciones concretos e inequívocos. Por ejemplo, "Ejecuta la secuencia de comandos de restauración" es demasiado general. Por el contrario, "Abre una shell y ejecuta /home/example/restore.sh" es precisa y concreta.
Implementar medidas de control
Añade controles para evitar que se produzcan desastres y para detectar problemas antes de que ocurran. Por ejemplo, añade un monitor que envíe una alerta cuando un flujo destructivo de datos, como una canalización de eliminación, muestre picos inesperados u otra actividad inusual. Este monitor también podría finalizar los procesos de la canalización si se alcanza un determinado umbral de eliminación, lo que evitaría una situación catastrófica.
Preparar el software
Una parte de tu planificación de recuperación ante desastres es asegurarte de que el software que utilizas esté preparado para un evento de recuperación.
Verificar que puedes instalar el software
Asegúrate de que el software de tu aplicación se pueda instalar desde la fuente o desde una imagen preconfigurada. Asegúrate de que tienes la licencia adecuada para el software que vas a implementar en Google Cloud. Para obtener más información, ponte en contacto con el proveedor del software.
Asegúrate de que los recursos de Compute Engine necesarios estén disponibles en el entorno de recuperación. Para ello, puede que tengas que preasignar instancias o reservarlas.
Diseñar el despliegue continuo para la recuperación
Tu conjunto de herramientas de implementación continua es un componente fundamental cuando implementas tus aplicaciones. Como parte de tu plan de recuperación, debes tener en cuenta dónde vas a implementar los artefactos en tu entorno recuperado. Planifica dónde quieres alojar tu entorno y tus artefactos de CD, ya que deben estar disponibles y operativos en caso de desastre.
Implementar controles de seguridad y cumplimiento
Cuando diseñes un plan de recuperación tras desastres, la seguridad será un factor importante. Los mismos controles que tenga en su entorno de producción deben aplicarse a su entorno recuperado. Las normativas de cumplimiento también se aplicarán a tu entorno recuperado.
Configurar la seguridad de la misma forma en los entornos de recuperación ante desastres y de producción
Asegúrate de que los controles de tu red proporcionen la misma separación y bloqueo que el entorno de producción de origen. Consulta cómo configurar VPC compartida y cortafuegos para establecer una red y un control de seguridad centralizados de tu implementación, configurar subredes y controlar el tráfico entrante y saliente. Descubre cómo usar cuentas de servicio para implementar el principio de mínimos privilegios en aplicaciones que acceden a APIs de Google Cloud . Asegúrate de usar cuentas de servicio como parte de las reglas de cortafuegos.
Asegúrate de conceder a los usuarios el mismo acceso al entorno de recuperación ante desastres que tienen en el entorno de producción de origen. En la siguiente lista se describen las formas de sincronizar los permisos entre entornos:
Si tu entorno de producción es Google Cloud, replicar las políticas de gestión de identidades y accesos en el entorno de recuperación ante desastres es sencillo. Puedes usar herramientas de infraestructura como código (IaC), como Terraform, para desplegar tus políticas de IAM en producción. A continuación, usa las mismas herramientas para vincular las políticas a los recursos correspondientes del entorno de recuperación ante desastres como parte del proceso de configuración de tu entorno de recuperación ante desastres.
Si tu entorno de producción es local, asigna los roles funcionales, como los de administrador de red y auditor, a políticas de gestión de identidades y accesos que tengan los roles de gestión de identidades y accesos adecuados. En la documentación de gestión de identidades y accesos se incluyen algunos ejemplos de configuraciones de roles funcionales. Por ejemplo, consulta la documentación sobre cómo crear roles funcionales de redes y de registro de auditoría.
Debe configurar políticas de gestión de identidades y accesos para conceder los permisos adecuados a los productos. Por ejemplo, puede que quieras restringir el acceso a determinados segmentos de Cloud Storage.
Si tu entorno de producción es otro proveedor de la nube, asigna los permisos de las políticas de gestión de identidades y accesos del otro proveedor a las políticas de gestión de identidades y accesos. Google Cloud
Verificar la seguridad de la recuperación ante desastres
Una vez que hayas configurado los permisos del entorno de recuperación ante desastres, asegúrate de probarlo todo. Crea un entorno de prueba. Verifica que los permisos que concedes a los usuarios coincidan con los que tienen en las instalaciones.
Asegurarse de que los usuarios puedan acceder al entorno de recuperación ante desastres
No esperes a que se produzca un desastre para comprobar que tus usuarios pueden acceder al entorno de recuperación ante desastres. Asegúrate de haber concedido los derechos de acceso adecuados a los usuarios, desarrolladores, operadores, científicos de datos, administradores de seguridad y de red, y a cualquier otro rol de tu organización. Si utilizas un sistema de identidad alternativo, asegúrate de que las cuentas se hayan sincronizado con tu cuenta de Cloud Identity. Como el entorno de recuperación ante desastres será tu entorno de producción durante un tiempo, pide a los usuarios que necesiten acceder a él que inicien sesión y resuelve cualquier problema de autenticación. Incluye a los usuarios que inician sesión en el entorno de recuperación ante desastres en las pruebas periódicas de recuperación ante desastres que implementes.
Para gestionar de forma centralizada quién tiene acceso de administrador a las máquinas virtuales (VMs) que se inician, habilita la función Inicio de sesión con SO en los proyectos que constituyen tu entorno de recuperación ante desastres. Google Cloud
Formar a los usuarios
Los usuarios deben saber cómo llevar a cabo las acciones en Google Cloud que suelen realizar en el entorno de producción, como iniciar sesión y acceder a máquinas virtuales. En el entorno de pruebas, enseña a tus usuarios a realizar estas tareas de forma que se proteja la seguridad de tu sistema.
Asegurarse de que el entorno de recuperación ante desastres cumple los requisitos
Verifica que solo tengan acceso a tu entorno de recuperación ante desastres las personas que lo necesiten. Asegúrate de que los datos de IPI se hayan anonimizado y cifrado. Si realizas pruebas de penetración periódicas en tu entorno de producción, debes incluir tu entorno de recuperación ante desastres en el ámbito de esas pruebas y llevar a cabo pruebas periódicas configurando un entorno de recuperación ante desastres.
Mientras tu entorno de recuperación ante desastres esté en servicio, asegúrate de que todos los registros que recojas se vuelvan a rellenar en el archivo de registro de tu entorno de producción. Del mismo modo, asegúrate de que, como parte de tu entorno de recuperación ante desastres, puedas exportar los registros de auditoría que se recojan a través de Cloud Logging a tu archivo de receptor de registro principal. Usa las instalaciones del receptor de exportación. En el caso de los registros de aplicaciones, crea una réplica de tu entorno de almacenamiento de registros y monitorización local. Si tu entorno de producción es otro proveedor de servicios en la nube, asigna los servicios de registro y monitorización de ese proveedor a los servicios equivalentes de Google Cloud . Tener un proceso para dar formato a las entradas en tu entorno de producción.
Tratar los datos recuperados como datos de producción
Asegúrese de que los controles de seguridad que aplique a sus datos de producción también se apliquen a los datos recuperados: deben aplicarse los mismos permisos, cifrado y requisitos de auditoría.
Saber dónde se encuentran tus copias de seguridad y quién tiene autorización para restaurar datos. Asegúrate de que tu proceso de recuperación se pueda auditar. Después de una recuperación ante desastres, asegúrate de que puedes mostrar quién ha tenido acceso a los datos de la copia de seguridad y quién ha realizado la recuperación.
Asegurarse de que el plan de recuperación ante desastres funciona
Asegúrate de que, si se produce un desastre, tu plan de recuperación ante desastres funcione correctamente.
Mantener más de una ruta de recuperación de datos
En caso de desastre, es posible que el método de conexión a Google Cloud deje de estar disponible. Implementa un medio de acceso alternativo a Google Cloud para asegurarte de que puedes transferir datos a Google Cloud. Prueba periódicamente que la ruta de copia de seguridad funcione.
Prueba tu plan con regularidad
Después de crear un plan de recuperación ante desastres, pruébalo con regularidad, anota los problemas que surjan y ajusta el plan en consecuencia. Con Google Cloud, puedes probar escenarios de recuperación con un coste mínimo. Te recomendamos que implementes lo siguiente para facilitar las pruebas:
- Automatizar el aprovisionamiento de la infraestructura. Puedes usar herramientas de IaC como Terraform para automatizar el aprovisionamiento de tu Google Cloud infraestructura. Si tu entorno de producción se ejecuta de forma local, asegúrate de que tienes un proceso de monitorización que pueda iniciar el proceso de recuperación ante desastres cuando detecte un fallo y que pueda activar las acciones de recuperación adecuadas.
- Monitoriza tus entornos con Google Cloud Observability. Google Cloud tiene excelentes herramientas de registro y monitorización a las que puedes acceder mediante llamadas a la API, lo que te permite automatizar la implementación de escenarios de recuperación reaccionando a las métricas. Cuando diseñes pruebas, asegúrate de que tienes configurados sistemas de monitorización y alertas adecuados que puedan activar las acciones de recuperación pertinentes.
Realiza las pruebas que se han indicado anteriormente:
- Comprueba que los permisos y el acceso de los usuarios funcionan en el entorno de recuperación ante desastres igual que en el entorno de producción.
- Realiza pruebas de penetración en tu entorno de recuperación ante desastres.
- Realiza una prueba en la que no funcione tu ruta de acceso habitual a Google Cloud.
Siguientes pasos
- Consulta información sobre Google Cloud geografía y regiones.
- Consulta otros documentos de esta serie de recuperación ante desastres:
- Componentes básicos de recuperación tras fallos
- Situaciones de recuperación tras fallos con los datos
- Situaciones de recuperación tras fallos de aplicaciones
- Diseñar la recuperación tras fallos para cargas de trabajo con restricciones de localidad
- Casos prácticos de recuperación ante desastres: aplicaciones de analíticas de datos restringidas por localidad
- Diseñar la recuperación tras fallos para las interrupciones de la infraestructura de la nube
- Para ver más arquitecturas de referencia, diagramas y prácticas recomendadas, consulta el centro de arquitectura de Cloud.
Colaboradores
Autores:
- Grace Mollison | Responsable de soluciones
- Marco Ferrari | Arquitecto de soluciones en la nube