Este documento é a primeira parte de uma série que aborda a recuperação de desastres (RD) no Google Cloud. Esta parte oferece uma vista geral do processo de planeamento de DR: o que precisa de saber para conceber e implementar um plano de DR. As partes subsequentes abordam exemplos de utilização específicos da DR com exemplos de implementações no Google Cloud.
A série é composta pelas seguintes partes:
- Guia de planeamento de recuperação de desastres (este documento)
- Bases de recuperação de desastres
- Cenários de recuperação de desastres para dados
- Cenários de recuperação de desastres para aplicações
- Arquitetar a recuperação de desastres para cargas de trabalho restritas por localidade
- Exemplos de utilização de recuperação de desastres: aplicações de estatísticas de dados restritas à localidade
- Criar arquiteturas de recuperação de desastres para interrupções da infraestrutura na nuvem
Os eventos que interrompem o serviço podem ocorrer em qualquer altura. A sua rede pode ter uma interrupção, o envio da aplicação mais recente pode introduzir um erro crítico ou pode ter de lidar com um desastre natural. Quando as coisas correm mal, é importante ter um plano de recuperação de desastres robusto, segmentado e bem testado.
Com um plano de recuperação de desastres bem concebido e testado, pode garantir que, se ocorrer uma catástrofe, o impacto no resultado final da sua empresa será mínimo. Independentemente das suas necessidades de resposta direta, Google Cloud tem uma seleção robusta, flexível e rentável de produtos e funcionalidades que pode usar para criar ou aumentar a solução certa para si.
Noções básicas do planeamento de recuperação de desastres
A RD é um subconjunto do planeamento de continuidade do negócio. O planeamento de DR começa com uma análise do impacto empresarial que define duas métricas principais:
- Um objetivo de tempo de recuperação (OTR), que é o período máximo aceitável durante o qual a sua aplicação pode estar offline. Normalmente, este valor é definido como parte de um contrato de nível de serviço (SLA) mais abrangente.
- Um objetivo de ponto de recuperação (OPR), que é o período máximo aceitável durante o qual os dados podem ser perdidos da sua aplicação devido a um incidente grave. Esta métrica varia com base nas formas como os dados são usados. Por exemplo, os dados do utilizador que são modificados com frequência podem ter um RPO de apenas alguns minutos. Por outro lado, os dados menos críticos e modificados com pouca frequência podem ter um RPO de várias horas. (Esta métrica descreve apenas o período; não aborda a quantidade nem a qualidade dos dados perdidos.)
Normalmente, quanto menores forem os valores de RTO e RPO (ou seja, quanto mais rapidamente a sua aplicação tiver de recuperar de uma interrupção), maior será o custo de execução da aplicação. O gráfico seguinte mostra a relação entre o custo e o OTR/OPR.
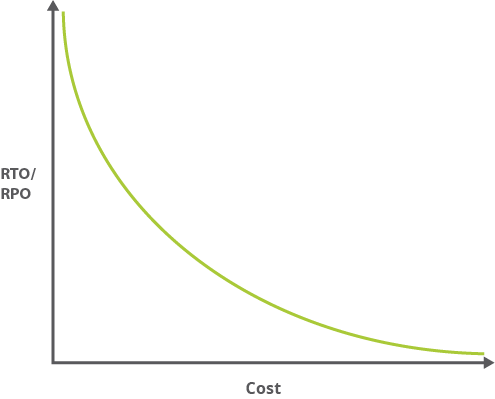
Uma vez que os valores de OTR e OPR mais pequenos significam frequentemente uma maior complexidade, os custos administrativos associados seguem uma curva semelhante. Uma aplicação de alta disponibilidade pode exigir que faça a gestão da distribuição entre dois centros de dados separados fisicamente, a gestão da replicação e muito mais.
Normalmente, os valores de RTO e RPO são agregados noutra métrica: o objetivo ao nível do serviço (SLO), que é um elemento mensurável fundamental de um SLA. Muitas vezes, os SLAs e os SLOs são confundidos. Um SLA é o contrato completo que especifica o serviço a ser prestado, como é suportado, os horários, as localizações, os custos, o desempenho, as penalizações e as responsabilidades das partes envolvidas. Os SLOs são caraterísticas específicas e mensuráveis do SLA, como disponibilidade, débito, frequência, tempo de resposta ou qualidade. Um SLA pode conter vários SLOs. Os RTOs e os RPOs são mensuráveis e devem ser considerados SLOs.
Pode ler mais acerca dos SLOs e SLAs no livro Google Site Reliability Engineering.
Também pode estar a planear uma arquitetura de alta disponibilidade (HA). A HA não se sobrepõe totalmente à DR, mas é frequentemente necessário ter em conta a HA quando pensa nos valores de RTO e RPO. A DA ajuda a garantir um nível acordado de desempenho operacional, normalmente, tempo de atividade, durante um período superior ao normal. Quando executa cargas de trabalho de produção no Google Cloud, pode usar um sistema distribuído globalmente para que, se algo correr mal numa região, a aplicação continue a fornecer serviço, mesmo que esteja menos disponível. Essencialmente, essa aplicação invoca o respetivo plano de recuperação de desastres.
Porquê Google Cloud?
Google Cloud Pode reduzir significativamente os custos associados ao RTO e ao RPO em comparação com o cumprimento dos requisitos de RTO e RPO no local. Por exemplo, o planeamento de DR requer que tenha em conta vários requisitos, incluindo o seguinte:
- Capacidade: garantir recursos suficientes para dimensionar conforme necessário.
- Segurança: fornecer segurança física para proteger os recursos.
- Infraestrutura de rede: incluindo componentes de software, como firewalls e balanceadores de carga.
- Apoio técnico: disponibilizar técnicos qualificados para realizar a manutenção e resolver problemas.
- Largura de banda: planeamento da largura de banda adequada para a carga máxima.
- Instalações: garantir a infraestrutura física, incluindo equipamento e energia.
Ao oferecer uma solução altamente gerida numa plataforma de produção de nível mundial, Google Cloud ajuda a contornar a maioria ou todos estes fatores complicados, removendo muitos custos empresariais no processo. Além disso,o foco da Google Cloudna simplicidade administrativa significa que os custos de gestão de uma aplicação complexa também são reduzidos.
OGoogle Cloud oferece várias funcionalidades relevantes para o planeamento de recuperação de desastres, incluindo o seguinte:
- Uma rede global. A Google tem uma das maiores e mais avançadas redes de computadores do mundo. A rede principal da Google usa redes definidas por software e serviços de cache na extremidade avançados para oferecer um desempenho rápido, consistente e escalável.
- Redundância. Vários pontos de presença (PoPs) em todo o mundo significam uma forte redundância. Os seus dados são espelhados automaticamente em dispositivos de armazenamento em várias localizações.
- Escalabilidade. Google Cloud foi concebido para ser escalável como outros produtos Google (por exemplo, a Pesquisa e o Gmail), mesmo quando regista um aumento significativo no tráfego. Os serviços geridos, como o Cloud Run, o Compute Engine e o Firestore, oferecem-lhe uma escalabilidade automática que permite que a sua aplicação cresça e diminua conforme necessário.
- Segurança. O modelo de segurança da Google baseia-se em décadas de experiência em ajudar a manter os clientes em segurança nas aplicações Google, como o Gmail e o Google Workspace. Além disso, as equipas de engenharia de fiabilidade do site na Google ajudam a garantir uma elevada disponibilidade e a evitar o abuso de recursos da plataforma.
- Conformidade. A Google é submetida regularmente a auditorias independentes de terceiros para verificar se está em conformidade com os regulamentos e as práticas recomendadas de segurança, privacidade e conformidade.A Google está em conformidade com certificações como a ISO 27001, a SOC 2/3 e a PCI DSS 3.0. Google Cloud Google Cloud
Padrões de RD
Os padrões de DR são considerados frios, mornos ou quentes. Estes padrões indicam a facilidade com que o sistema consegue recuperar quando algo corre mal. Uma analogia pode ser o que faria se estivesse a conduzir e tivesse um furo num pneu do carro.
A forma como lida com um pneu furado depende da sua preparação:
- Frio: não tem pneu sobresselente, por isso, tem de ligar a alguém para que lhe traga um pneu novo e o substitua. A viagem para até chegar ajuda para fazer a reparação.
- Quente: tem um pneu sobresselente e um kit de substituição, pelo que pode voltar à estrada com o que tem no carro. No entanto, tem de parar a sua viagem para reparar o problema.
- Quente: tem pneus run-flat. Pode ter de abrandar um pouco, mas não há um impacto imediato na sua viagem. Os pneus estão em bom estado e pode continuar a conduzir (embora tenha de resolver o problema).
Criar um plano de recuperação de desastres detalhado
Esta secção fornece recomendações sobre como criar o seu plano de recuperação de desastres.
Crie o design de acordo com os seus objetivos de recuperação
Quando cria o seu plano de RD, tem de combinar as técnicas de recuperação de dados e aplicações e analisar o panorama geral. A forma habitual de o fazer é analisar os valores de RTO e RPO e que padrão de DR pode adotar para cumprir esses valores. Por exemplo, no caso de dados históricos orientados para a conformidade, provavelmente não precisa de acesso rápido aos dados, pelo que um valor de RTO elevado e um padrão de DR frio são adequados. No entanto, se o seu serviço online sofrer uma interrupção, é importante poder recuperar os dados e a parte da aplicação visível para o utilizador o mais rapidamente possível. Nesse caso, um padrão quente seria mais adequado. O seu sistema de notificação por email, que normalmente não é crítico para a empresa, é provavelmente um candidato a um padrão de aquecimento.
Para orientações sobre a utilização do Google Cloud para resolver cenários de recuperação de desastres comuns, reveja os cenários de recuperação de aplicações. Estes cenários oferecem estratégias de recuperação de desastres direcionadas para uma variedade de exemplos de utilização e oferecem exemplos de implementações emGoogle Cloud para cada um.
Crie a pensar na recuperação ponto a ponto
Não basta ter um plano para fazer cópias de segurança ou arquivar os seus dados. Certifique-se de que o seu plano de recuperação de desastres aborda o processo de recuperação completo, desde a cópia de segurança ao restauro e à limpeza. Abordamos este assunto nos documentos relacionados sobre os dados de DR e a recuperação.
Especifique as suas tarefas
Quando chegar a altura de executar o seu plano de recuperação de desastres, não vai querer ter dúvidas sobre o significado de cada passo. Faça com que cada tarefa no seu plano de recuperação de desastres consista num ou mais comandos ou ações concretos e inequívocos. Por exemplo, "Executar o script de restauro" é demasiado
geral. Por outro lado, "Abrir um shell e executar /home/example/restore.sh" é preciso e concreto.
Implementar medidas de controlo
Adicione controlos para evitar a ocorrência de desastres e detetar problemas antes que ocorram. Por exemplo, adicione um monitor que envia um alerta quando um fluxo destrutivo de dados, como um pipeline de eliminação, apresenta picos inesperados ou outra atividade invulgar. Este monitor também pode terminar os processos da pipeline se for atingido um determinado limite de eliminação, o que evita uma situação catastrófica.
A preparar o software
Parte do seu planeamento de DR é certificar-se de que o software no qual confia está pronto para um evento de recuperação.
Confirme se consegue instalar o software
Certifique-se de que o software da sua aplicação pode ser instalado a partir da origem ou de uma imagem pré-configurada. Certifique-se de que tem as licenças adequadas para qualquer software que vai implementar em Google Cloud. Consulte o fornecedor do software para obter orientações.
Certifique-se de que os recursos do Compute Engine necessários estão disponíveis no ambiente de recuperação. Isto pode exigir a pré-atribuição de instâncias ou a reserva das mesmas.
Crie uma implementação contínua para recuperação
O conjunto de ferramentas de implementação contínua (IC) é um componente integral quando está a implementar as suas aplicações. Como parte do seu plano de recuperação, tem de considerar onde vai implementar artefactos no seu ambiente recuperado. Planeie onde quer alojar o seu ambiente e artefactos de CD. Estes têm de estar disponíveis e operacionais em caso de desastre.
Implementação de controlos de segurança e conformidade
Quando cria um plano de recuperação de desastres, a segurança é importante. Os mesmos controlos que tem no ambiente de produção têm de se aplicar ao ambiente recuperado. Os regulamentos de conformidade também se aplicam ao seu ambiente recuperado.
Configurar a segurança da mesma forma para os ambientes de produção e recuperação de desastres
Certifique-se de que os controlos de rede oferecem a mesma separação e bloqueio que o ambiente de produção de origem usa. Saiba como configurar a VPC partilhada e as firewalls para lhe permitir estabelecer um controlo de rede e segurança centralizado da sua implementação, configurar sub-redes e controlar o tráfego de entrada e saída. Compreenda como usar contas de serviço para implementar o menor privilégio possível para aplicações que acedem às APIs. Google Cloud Certifique-se de que usa contas de serviço como parte das regras de firewall.
Certifique-se de que concede aos utilizadores o mesmo acesso ao ambiente de recuperação de desastres que têm no ambiente de produção de origem. A seguinte lista descreve formas de sincronizar autorizações entre ambientes:
Se o seu ambiente de produção for Google Cloud, a replicação das políticas de IAM no ambiente de DR é simples. Pode usar ferramentas de infraestrutura como código (IaC) como o Terraform para implementar as suas políticas de IAM na produção. Em seguida, usa as mesmas ferramentas para associar as políticas aos recursos correspondentes no ambiente de recuperação de desastres como parte do processo de configuração do ambiente de recuperação de desastres.
Se o seu ambiente de produção for no local, mapeie as funções funcionais, como as funções de administrador de rede e auditor, para políticas do IAM que tenham as funções do IAM adequadas. A documentação do IAM tem algumas configurações de funções funcionais de exemplo. Por exemplo, consulte a documentação para criar funções funcionais de rede e registo de auditoria.
Tem de configurar políticas de IAM para conceder as autorizações adequadas aos produtos. Por exemplo, pode querer restringir o acesso a contentores específicos do Cloud Storage.
Se o seu ambiente de produção for outro fornecedor de nuvem, mapeie as autorizações nas políticas de IAM do outro fornecedor para as políticas de Google Cloud IAM Google Cloud .
Valide a segurança da sua DR
Depois de configurar as autorizações para o ambiente de recuperação de desastres, certifique-se de que testa tudo. Crie um ambiente de teste. Verifique se as autorizações que concede aos utilizadores correspondem às que os utilizadores têm no local.
Certifique-se de que os utilizadores podem aceder ao ambiente de recuperação de desastres
Não espere que ocorra um desastre para verificar se os seus utilizadores conseguem aceder ao ambiente de recuperação de desastres. Certifique-se de que concedeu os direitos de acesso adequados aos utilizadores, programadores, operadores, cientistas de dados, administradores de segurança, administradores de rede e quaisquer outras funções na sua organização. Se estiver a usar um sistema de identidade alternativo, certifique-se de que as contas foram sincronizadas com a sua conta do Cloud ID. Uma vez que o ambiente de recuperação de desastres vai ser o seu ambiente de produção durante algum tempo, peça aos utilizadores que precisam de acesso ao ambiente de recuperação de desastres para iniciarem sessão e resolvam quaisquer problemas de autenticação. Incorpore utilizadores que estão a iniciar sessão no ambiente de recuperação de desastres (DR) como parte dos testes de DR normais que implementa.
Para gerir centralmente quem tem acesso administrativo às máquinas virtuais (VMs) que são iniciadas, ative a funcionalidade Início de sessão do SO nos projetos que constituem o seu ambiente de recuperação de desastres. Google Cloud
Prepare os utilizadores
Os utilizadores têm de compreender como realizar as ações que estão habituados a realizar no ambiente de produção, como iniciar sessão e aceder às VMs. Google Cloud Usando o ambiente de teste, ensine os seus utilizadores a realizar estas tarefas de formas que salvaguardem a segurança do seu sistema.
Certifique-se de que o ambiente de recuperação de desastres cumpre os requisitos de conformidade
Verifique se o acesso ao seu ambiente de recuperação de desastres está restrito apenas a quem precisa de acesso. Certifique-se de que os dados de IIP são ocultados e encriptados. Se realizar testes de penetração regulares no seu ambiente de produção, deve incluir o ambiente de recuperação de desastres (RD) no âmbito desses testes e realizar testes regulares através da configuração de um ambiente de RD.
Certifique-se de que, enquanto o ambiente de recuperação de desastres está em serviço, todos os registos que recolhe são preenchidos novamente no arquivo de registos do seu ambiente de produção. Da mesma forma, certifique-se de que, como parte do seu ambiente de DR, pode exportar registos de auditoria recolhidos através do Cloud Logging para o seu arquivo principal de destino de registos. Use as funcionalidades do sink de exportação. Para registos de aplicações, crie uma imagem espelhada do seu ambiente de registo e monitorização no local. Se o seu ambiente de produção for outro fornecedor de nuvem, mapeie o registo e a monitorização desse fornecedor para os serviços Google Cloud equivalentes. Ter um processo implementado para formatar a entrada no seu ambiente de produção.
Trate os dados recuperados como dados de produção
Certifique-se de que os controlos de segurança que aplica aos dados de produção também se aplicam aos dados recuperados: devem aplicar-se as mesmas autorizações, encriptação e requisitos de auditoria.
Saber onde se encontram as suas cópias de segurança e quem tem autorização para restaurar dados. Certifique-se de que o processo de recuperação é auditável. Após uma recuperação de desastres, certifique-se de que consegue mostrar quem teve acesso aos dados da cópia de segurança e quem realizou a recuperação.
Certificar-se de que o seu plano de recuperação de desastres funciona
Certifique-se de que, se ocorrer um desastre, o seu plano de recuperação de desastres funciona conforme previsto.
Mantenha mais do que um caminho de recuperação de dados
Em caso de desastre, o seu método de ligação ao Google Cloud pode ficar indisponível. Implemente um meio de acesso alternativo a Google Cloud para ajudar a garantir que pode transferir dados para Google Cloud. Teste regularmente se o caminho da cópia de segurança está operacional.
Teste o seu plano regularmente
Depois de criar um plano de recuperação de desastres, teste-o regularmente, tome nota de quaisquer problemas que surjam e ajuste o plano em conformidade. Com o Google Cloud, pode testar cenários de recuperação a um custo mínimo. Recomendamos que implemente o seguinte para ajudar nos seus testes:
- Automatize o aprovisionamento de infraestrutura. Pode usar ferramentas de IaC, como o Terraform, para automatizar o aprovisionamento da sua infraestrutura. Google CloudSe estiver a executar o seu ambiente de produção no local, certifique-se de que tem um processo de monitorização que pode iniciar o processo de DR quando deteta uma falha e pode acionar as ações de recuperação adequadas.
- Monitorize os seus ambientes com a observabilidade do Google Cloud. Google Cloud Tem excelentes ferramentas de registo e monitorização às quais pode aceder através de chamadas API, o que lhe permite automatizar a implementação de cenários de recuperação reagindo às métricas. Quando estiver a criar testes, certifique-se de que tem uma monitorização e alertas adequados que podem acionar ações de recuperação adequadas.
Realize os testes indicados anteriormente:
- Teste se as autorizações e o acesso do utilizador funcionam no ambiente de recuperação de desastres (RD) da mesma forma que no ambiente de produção.
- Realize testes de intrusão no seu ambiente de recuperação de desastres.
- Realize um teste em que o seu caminho de acesso habitual a Google Cloud não funciona.
O que se segue?
- Leia mais sobre Google Cloud geografia e regiões.
- Leia outros documentos desta série de DR:
- Bases de recuperação de desastres
- Cenários de recuperação de desastres para dados
- Cenários de recuperação de desastres para aplicações
- Arquitetar a recuperação de desastres para cargas de trabalho restritas por localidade
- Exemplos de utilização de recuperação de desastres: aplicações de estatísticas de dados restritas à localidade
- Criar arquiteturas de recuperação de desastres para interrupções da infraestrutura na nuvem
- Para ver mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Centro de arquitetura na nuvem.
Colaboradores
Autores:
- Grace Mollison | Solutions Lead
- Marco Ferrari | Arquiteto de soluções na nuvem