Este documento apresenta conceitos, princípios, terminologia e arquitetura da migração de bases de dados com tempo de inatividade quase nulo para arquitetos da nuvem que estão a migrar bases de dados para o Google Cloud a partir de ambientes nas instalações ou de outras nuvens.
Este documento é a parte 1 de 2. Parte 2 aborda a configuração e a execução do processo de migração, incluindo cenários de falha.
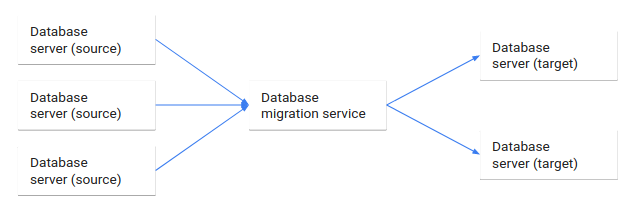
A migração de bases de dados é o processo de migração de dados de uma ou mais bases de dados de origem para uma ou mais bases de dados de destino através de um serviço de migração de bases de dados. Quando uma migração está concluída, o conjunto de dados nas bases de dados de origem reside totalmente, embora possa ser reestruturado, nas bases de dados de destino. Os clientes que acederam às bases de dados de origem são, em seguida, transferidos para as bases de dados de destino, e as bases de dados de origem são desativadas.
O diagrama seguinte ilustra este processo de migração da base de dados.
Este documento descreve a migração de bases de dados do ponto de vista da arquitetura:
- Os serviços e as tecnologias envolvidas na migração de bases de dados.
- As diferenças entre a migração de bases de dados homogénea e heterogénea.
- As concessões e a seleção de uma tolerância de tempo de inatividade da migração.
- Uma arquitetura de configuração que suporta uma alternativa se ocorrerem erros imprevistos durante uma migração.
Este documento não descreve como configurar uma tecnologia de migração de base de dados específica. Em vez disso, apresenta a migração de bases de dados em termos fundamentais, conceptuais e de princípios.
Arquitetura
O diagrama seguinte mostra uma arquitetura de migração de base de dados genérica.
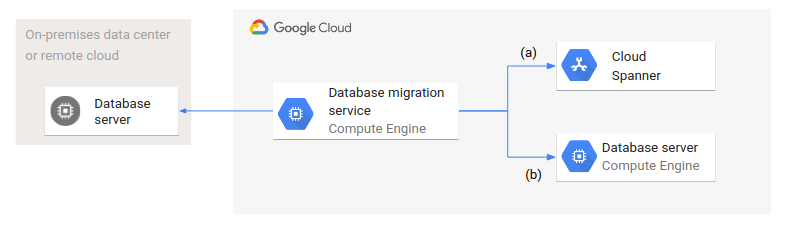
Um serviço de migração de base de dados é executado no Google Cloud e acede às bases de dados de origem e de destino. São representadas duas variantes: (a) mostra a migração de uma base de dados de origem num centro de dados no local ou numa nuvem remota para uma base de dados gerida, como o Spanner; (b) mostra uma migração para uma base de dados no Compute Engine.
Embora as bases de dados de destino sejam de tipo diferente (geridas e não geridas) e configuração, a arquitetura e a configuração da migração da base de dados são as mesmas para ambos os casos.
Terminologia
Os termos de migração de dados mais importantes para estes documentos são definidos da seguinte forma:
base de dados de origem: uma base de dados que contém dados a migrar para uma ou mais bases de dados de destino.
Base de dados de destino: uma base de dados que recebe dados migrados de uma ou mais bases de dados de origem.
Migração de base de dados: uma migração de dados de bases de dados de origem para bases de dados de destino com o objetivo de desativar os sistemas de base de dados de origem após a conclusão da migração. É migrado o conjunto de dados completo ou um subconjunto.
Migração homogénea: uma migração de bases de dados de origem para bases de dados de destino em que as bases de dados de origem e de destino são do mesmo sistema de gestão de bases de dados do mesmo fornecedor.
Migração heterogénea: uma migração de bases de dados de origem para bases de dados de destino em que as bases de dados de origem e de destino são de diferentes sistemas de gestão de bases de dados de diferentes fornecedores.
Sistema de migração de bases de dados: um sistema ou um serviço de software que se liga a bases de dados de origem e bases de dados de destino e executa migrações de dados das bases de dados de origem para as bases de dados de destino.
Processo de migração de dados: um processo configurado ou implementado executado pelo sistema de migração de dados para transferir dados das bases de dados de origem para as de destino, possivelmente transformando os dados durante a transferência.
Replicação de bases de dados: uma transferência contínua de dados de bases de dados de origem para bases de dados de destino sem o objetivo de desativar as bases de dados de origem. A replicação da base de dados (por vezes, denominada streaming de base de dados) é um processo contínuo.
Classificação das migrações de bases de dados
Existem diferentes tipos de migrações de bases de dados que pertencem a diferentes classes. Esta secção descreve os critérios que definem essas classes.
Replicação versus migração
Numa migração de base de dados, move dados de bases de dados de origem para bases de dados de destino. Depois de os dados serem totalmente migrados, elimina as bases de dados de origem e redireciona o acesso do cliente para as bases de dados de destino. Por vezes, mantém as bases de dados de origem como uma medida alternativa se encontrar problemas imprevistos com as bases de dados de destino. No entanto, depois de as bases de dados de destino estarem a funcionar de forma fiável, acaba por eliminar as bases de dados de origem.
Com a replicação da base de dados, por outro lado, transfere continuamente dados das bases de dados de origem para as bases de dados de destino sem eliminar as bases de dados de origem. Por vezes, a replicação da base de dados é denominada streaming da base de dados. Embora exista uma hora de início definida, normalmente, não existe uma hora de conclusão definida. A replicação pode ser interrompida ou tornar-se uma migração.
Este documento aborda apenas a migração de bases de dados.
Migração parcial versus completa
A migração de base de dados é entendida como uma transferência completa e consistente de dados. Define o conjunto de dados inicial a transferir como uma base de dados completa ou uma base de dados parcial (um subconjunto dos dados numa base de dados), além de todas as alterações confirmadas no sistema de base de dados de origem posteriormente.
Migração heterogénea versus migração homogénea
Uma migração de base de dados homogénea é uma migração entre as bases de dados de origem e de destino da mesma tecnologia de base de dados, por exemplo, a migração de uma base de dados MySQL para uma base de dados MySQL ou de uma base de dados Oracle® para uma base de dados Oracle. As migrações homogéneas também incluem migrações entre um sistema de base de dados alojado por si, como o PostgreSQL, para uma versão gerida do mesmo, como o Cloud SQL para PostgreSQL ou o AlloyDB para PostgreSQL.
Numa migração de base de dados homogénea, é provável que os esquemas das bases de dados de origem e de destino sejam idênticos. Se os esquemas forem diferentes, os dados das bases de dados de origem têm de ser transformados durante a migração.
A migração de base de dados heterogénea é uma migração entre bases de dados de origem e de destino de diferentes tecnologias de bases de dados, por exemplo, de uma base de dados Oracle para o Spanner. A migração de base de dados heterogénea pode ocorrer entre os mesmos modelos de dados (por exemplo, de relacional para relacional) ou entre diferentes modelos de dados (por exemplo, de relacional para chave-valor).
A migração entre diferentes tecnologias de bases de dados não envolve necessariamente diferentes modelos de dados. Por exemplo, o Oracle, o MySQL, o PostgreSQL e o Spanner suportam o modelo de dados relacionais. No entanto, as bases de dados multimodelos, como o Oracle, o MySQL ou o PostgreSQL, suportam diferentes modelos de dados. Os dados armazenados como documentos JSON numa base de dados multimodelos podem ser migrados para o MongoDB com pouca ou nenhuma transformação necessária, uma vez que o modelo de dados é o mesmo na base de dados de origem e de destino.
Embora a distinção entre a migração homogénea e heterogénea se baseie nas tecnologias de base de dados, uma categorização alternativa baseia-se nos modelos de base de dados envolvidos. Por exemplo, uma migração de uma base de dados Oracle para o Spanner é homogénea quando ambos usam o modelo de dados relacional. Uma migração é heterogénea se, por exemplo, os dados armazenados como objetos JSON no Oracle forem migrados para um modelo relacional no Spanner.
A categorização das migrações por modelo de dados expressa com maior precisão a complexidade e o esforço necessários para migrar os dados do que basear a categorização no sistema de base de dados envolvido. No entanto, uma vez que a categorização usada habitualmente na indústria se baseia nos sistemas de base de dados envolvidos, as secções restantes baseiam-se nessa distinção.
Tempo de inatividade da migração: zero, mínimo ou significativo
Depois de migrar com êxito um conjunto de dados da base de dados de origem para a base de dados de destino, transfere o acesso do cliente para a base de dados de destino e elimina a base de dados de origem.
A mudança de clientes das bases de dados de origem para as bases de dados de destino envolve vários processos:
- Para continuar o processamento, os clientes têm de fechar as associações existentes às bases de dados de origem e criar novas associações às bases de dados de destino. Idealmente, o encerramento das ligações é elegante, o que significa que não reverte desnecessariamente as transações em curso.
- Depois de fechar as ligações nas bases de dados de origem, tem de migrar as alterações restantes das bases de dados de origem para as bases de dados de destino (denominado drenagem) para garantir que todas as alterações são captadas.
- Pode ter de testar as bases de dados de destino para garantir que estas bases de dados estão funcionais e que os clientes estão funcionais e operam dentro dos respetivos objetivos de nível de serviço (SLOs) definidos.
Numa migração, é impossível alcançar um tempo de inatividade verdadeiramente nulo para os clientes; há alturas em que os clientes não conseguem processar pedidos. No entanto, pode minimizar a duração durante a qual os clientes não conseguem processar pedidos de várias formas (tempo de inatividade quase nulo):
- Pode iniciar os clientes de teste no modo só de leitura em relação às bases de dados de destino muito antes de mudar os clientes. Com esta abordagem, os testes são feitos em simultâneo com a migração.
- Pode configurar a quantidade de dados que estão a ser migrados (ou seja, em trânsito entre as bases de dados de origem e de destino) para ser o mais pequena possível quando o período de mudança se aproxima. Este passo reduz o tempo de esgotamento porque existem menos diferenças entre as bases de dados de origem e as bases de dados de destino.
- Se for possível iniciar novos clientes que operam nas bases de dados de destino em simultâneo com os clientes existentes que operam nas bases de dados de origem, pode reduzir o tempo de mudança, uma vez que os novos clientes estão prontos para execução assim que todos os dados forem transferidos.
Embora seja irrealista alcançar um tempo de inatividade zero durante uma mudança, pode minimizar o tempo de inatividade iniciando as atividades em simultâneo com a migração de dados em curso, sempre que possível.
Em alguns cenários de migração de bases de dados, um tempo de inatividade significativo é aceitável. Normalmente, esta tolerância é o resultado de requisitos empresariais. Nesses casos, pode simplificar a sua abordagem. Por exemplo, com uma migração de base de dados homogénea, pode não precisar de modificar os dados. A exportação e a importação, ou a cópia de segurança e o restauro, são abordagens perfeitas. Com as migrações heterogéneas, o sistema de migração de bases de dados não tem de lidar com atualizações dos sistemas de bases de dados de origem durante a migração.
No entanto, tem de estabelecer que o tempo de inatividade aceitável é suficientemente longo para que a migração da base de dados e os testes de seguimento ocorram. Se esta indisponibilidade não puder ser claramente estabelecida ou for inaceitavelmente longa, tem de planear uma migração que envolva uma indisponibilidade mínima.
Cardinalidade da migração de base de dados
Em muitas situações, a migração da base de dados ocorre entre uma única base de dados de origem e uma única base de dados de destino. Nessas situações, a cardinalidade é de 1:1 (mapeamento direto). Ou seja, uma base de dados de origem é migrada sem alterações para uma base de dados de destino.
No entanto, um mapeamento direto não é a única possibilidade. Outras cardinalidades incluem o seguinte:
- Consolidação (n:1). Numa consolidação, migra dados de várias bases de dados de origem para um número menor de bases de dados de destino (ou até mesmo um destino). Pode usar esta abordagem para simplificar a gestão da base de dados ou usar uma base de dados de destino que possa ser dimensionada.
- Distribuição (1:n). Numa distribuição, migra dados de uma base de dados de origem para várias bases de dados de destino. Por exemplo, pode usar esta abordagem quando precisar de migrar uma grande base de dados centralizada que contenha dados regionais para várias bases de dados de destino regionais.
- Redistribuição (n:m). Numa redistribuição, migra dados de várias bases de dados de origem para várias bases de dados de destino. Pode usar esta abordagem quando tiver bases de dados de origem divididas em partições com partições de tamanhos muito diferentes. A redistribuição distribui uniformemente os dados divididos em partições por várias bases de dados de destino que representam as partições.
A migração de base de dados oferece uma oportunidade de reformular e implementar a arquitetura da sua base de dados, além de simplesmente migrar dados.
Consistência da migração
A expetativa é que uma migração de base de dados seja consistente. No contexto da migração, consistente significa o seguinte:
- Concluído. Todos os dados especificados para migração são efetivamente migrados. Os dados especificados podem ser todos os dados numa base de dados de origem ou um subconjunto dos dados.
- Duplicar gratuitamente. Cada fragmento de dados é migrado uma vez e apenas uma vez. Não são introduzidos dados duplicados na base de dados de destino.
- Encomendado. As alterações de dados na base de dados de origem são aplicadas à base de dados de destino pela mesma ordem em que ocorreram na base de dados de origem. Este aspeto é essencial para garantir a consistência dos dados.
Uma forma alternativa de descrever a consistência da migração é que, após a conclusão de uma migração, o estado dos dados entre as bases de dados de origem e de destino é equivalente. Por exemplo, numa migração homogénea que envolva o mapeamento direto de uma base de dados relacional, têm de existir as mesmas tabelas e linhas nas bases de dados de origem e de destino.
Esta forma alternativa de descrever a consistência da migração é importante porque nem todas as migrações de dados se baseiam na aplicação sequencial de transações na base de dados de origem à base de dados de destino. Por exemplo, pode fazer uma cópia de segurança da base de dados de origem e usá-la para restaurar o conteúdo da base de dados de origem na base de dados de destino (quando for possível uma indisponibilidade significativa).
Migração ativo-passivo versus ativo-ativo
Uma distinção importante é se as bases de dados de origem e de destino estão ambas abertas à modificação do processamento de consultas. Numa migração de base de dados ativa-passiva, as bases de dados de origem podem ser modificadas durante a migração, enquanto as bases de dados de destino permitem apenas acesso de leitura.
Uma migração ativo-ativo suporta clientes que escrevem nas bases de dados de origem e de destino durante a migração. Neste tipo de migração, podem ocorrer conflitos. Por exemplo, se o mesmo item de dados na base de dados de origem e de destino for modificado de forma a entrar em conflito semanticamente, pode ter de executar regras de resolução de conflitos para resolver o conflito.
Numa migração ativo-ativo, tem de conseguir resolver todos os conflitos de dados através de regras de resolução de conflitos. Se não conseguir, pode ocorrer uma inconsistência nos dados.
Arquitetura de migração de base de dados
Uma arquitetura de migração de base de dados descreve os vários componentes necessários para executar uma migração de base de dados. Esta secção apresenta uma arquitetura de implementação genérica e trata o sistema de migração da base de dados como um componente separado. Também aborda as funcionalidades de um sistema de gestão de bases de dados que suportam a migração de dados, bem como as propriedades não funcionais que são importantes para muitos exemplos de utilização.
Arquitetura de implementação
Uma migração de base de dados pode ocorrer entre bases de dados de origem e de destino localizadas em qualquer ambiente, como no local ou em nuvens diferentes. Cada base de dados de origem e de destino pode estar num ambiente diferente. Não é necessário que todas estejam localizadas no mesmo ambiente.
O diagrama seguinte mostra um exemplo de uma arquitetura de implementação que envolve vários ambientes.
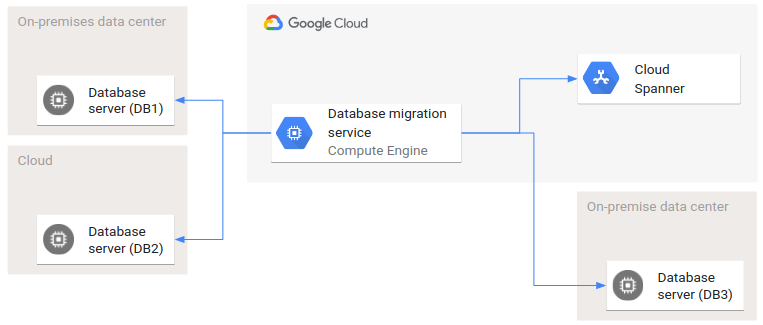
DB1 e DB2 são duas bases de dados de origem e DB3 e Spanner são as bases de dados de destino. Nesta migração de base de dados, estão envolvidas duas nuvens e dois centros de dados no local. As setas representam as relações de invocação: o serviço de migração de bases de dados invoca interfaces de todas as bases de dados de origem e de destino.
Um caso especial não abordado aqui é a migração de dados de uma base de dados para a mesma base de dados. Este caso especial usa o sistema de migração da base de dados apenas para a transformação de dados e não para a migração de dados entre diferentes sistemas em diferentes ambientes.
Fundamentalmente, existem três abordagens à migração de bases de dados, que esta secção aborda:
- Usar um sistema de migração de base de dados
- Usando a funcionalidade de replicação do sistema de gestão de bases de dados
- Usar a funcionalidade de migração de base de dados personalizada
Sistema de migração de base de dados
O sistema de migração de bases de dados está no centro da migração de bases de dados. O sistema executa a extração de dados real das bases de dados de origem, transporta os dados para as bases de dados de destino e, opcionalmente, modifica os dados durante o trânsito. Esta secção aborda as funcionalidades básicas do sistema de migração de bases de dados em geral. Seguem-se exemplos de sistemas de migração de bases de dados: Database Migration Service, Striim, Debezium, tcVision e Cloud Data Fusion.
Processo de migração de dados
O elemento técnico fundamental de um sistema de migração de base de dados é o processo de migração de dados. O processo de migração de dados é especificado por um programador e define as bases de dados de origem das quais os dados são extraídos, as bases de dados de destino para as quais os dados são migrados e qualquer lógica de modificação de dados aplicada aos dados durante a migração.
Pode especificar um ou mais processos de migração de dados e executá-los sequencialmente ou em simultâneo, consoante as necessidades da migração. Por exemplo, se migrar bases de dados independentes, os processos de migração de dados correspondentes podem ser executados em paralelo.
Extração e inserção de dados
Pode detetar alterações (inserções, atualizações, eliminações) num sistema de base de dados de duas formas: captura de dados de alterações (CDC) suportada pela base de dados com base num registo de transações e consultas diferenciais dos próprios dados através da interface de consulta de um sistema de gestão de bases de dados.
CDC com base num registo de transações
A CDC suportada por bases de dados baseia-se em funcionalidades de gestão de bases de dados que são separadas da interface de consulta. Uma abordagem baseia-se nos registos de transações (por exemplo, o registo binário no MySQL). Um registo de transações contém as alterações feitas aos dados pela ordem correta. O registo de transações é lido continuamente e, por isso, todas as alterações podem ser observadas. Para a migração da base de dados, este registo é extremamente útil, uma vez que a CDC garante que cada alteração é visível e é posteriormente migrada para a base de dados de destino sem perda e na ordem correta.
A CDC é a abordagem preferencial para captar alterações num sistema de gestão de bases de dados. A CDC está integrada na própria base de dados e tem o menor impacto de carga no sistema.
Consultas diferenciais
Se não existir nenhuma funcionalidade do sistema de gestão de base de dados que suporte a observação de todas as alterações na ordem correta, pode usar as consultas diferenciais como alternativa. Nesta abordagem, cada item de dados numa base de dados recebe um atributo adicional que contém uma data/hora ou um número de sequência. Sempre que o item de dados é alterado, a indicação de tempo da alteração é adicionada ou o número de sequência é aumentado. Um algoritmo de sondagem lê todos os itens de dados desde a última vez que foi executado ou desde o último número de sequência que usou. Assim que o algoritmo de sondagem determinar as alterações, regista a hora atual ou o número de sequência no respetivo estado interno e, em seguida, transmite as alterações à base de dados de destino.
Embora esta abordagem funcione sem problemas para inserções e atualizações, tem de conceber cuidadosamente as eliminações, porque uma eliminação remove um item de dados da base de dados. Após a eliminação dos dados, é impossível para o inquiridor detetar que ocorreu uma eliminação. Implementa uma eliminação através de um campo de estado adicional (um sinalizador de eliminação lógica) que indica que os dados foram eliminados. Em alternativa, os itens de dados eliminados podem ser recolhidos numa ou mais tabelas, e o inquiridor acede a essas tabelas para determinar se a eliminação ocorreu.
Para ver variantes sobre consultas diferenciais, consulte o artigo Captura de dados de alterações.
As consultas diferenciais são a abordagem menos preferível porque envolvem alterações ao esquema e à funcionalidade. A consulta da base de dados também adiciona uma carga de consulta que não está relacionada com a execução da lógica do cliente.
Adaptador e agente
O sistema de migração de bases de dados requer acesso à origem e aos sistemas de bases de dados. Os adaptadores são a abstração que encapsula as capacidades de acesso. Na forma mais simples, um adaptador pode ser um controlador JDBC para inserir dados numa base de dados de destino que suporte JDBC. Num caso mais complexo, um adaptador é executado no ambiente do destino (por vezes denominado agente), acedendo a uma interface de base de dados incorporada, como ficheiros de registo. Num caso ainda mais complexo, um adaptador ou um agente interage com outro sistema de software, que, por sua vez, acede à base de dados. Por exemplo, um agente acede ao Oracle GoldenGate, que, por sua vez, acede a uma base de dados do Oracle.
O adaptador ou o agente que acede a uma base de dados de origem implementa a interface CDC ou a interface de consulta diferencial, consoante a conceção do sistema de base de dados. Em ambos os casos, o adaptador ou o agente fornece alterações ao sistema de migração da base de dados, e o sistema de migração da base de dados não sabe se as alterações foram captadas pela CDC ou pela consulta diferencial.
Modificação de dados
Em alguns exemplos de utilização, os dados são migrados das bases de dados de origem para as bases de dados de destino sem alterações. Normalmente, estas migrações diretas são homogéneas.
No entanto, muitos exemplos de utilização requerem que os dados sejam modificados durante o processo de migração. Normalmente, é necessária uma modificação quando existem diferenças no esquema, diferenças nos valores dos dados ou oportunidades de limpar os dados enquanto estão em transição.
As secções seguintes abordam vários tipos de modificações que podem ser necessárias numa migração de dados: transformação de dados, enriquecimento ou correlação de dados e redução ou filtragem de dados.
Transformação de dados
A transformação de dados transforma alguns ou todos os valores de dados da base de dados de origem. Alguns exemplos incluem o seguinte:
- Transformação do tipo de dados. Por vezes, os tipos de dados entre as bases de dados de origem e de destino não são equivalentes. Nestes casos, a transformação do tipo de dados converte o valor de origem no valor de destino com base nas regras de transformação de tipo. Por exemplo, um tipo de data/hora da origem pode ser transformado numa string no destino.
- Transformação da estrutura de dados. A transformação da estrutura de dados modifica a estrutura no mesmo modelo de base de dados ou entre diferentes modelos de base de dados. Por exemplo, num sistema relacional, uma tabela de origem pode ser dividida em duas tabelas de destino ou várias tabelas de origem podem ser desnormalizadas numa tabela de destino através de uma junção. Uma relação 1:n na base de dados de origem pode ser transformada numa relação principal e secundária no Spanner. Os documentos de um sistema de base de dados de documentos de origem podem ser decompostos num conjunto de linhas relacionais num sistema de destino.
- Transformação do valor dos dados. A transformação de valores de dados é separada da transformação de tipos de dados. A transformação do valor dos dados altera o valor sem alterar o tipo de dados. Por exemplo, um fuso horário local é convertido no Tempo Universal Coordenado (UTC). Em alternativa, um código postal curto (cinco dígitos) representado como uma string é convertido num código postal longo (cinco dígitos seguidos de um traço seguido de 4 dígitos, também conhecido como ZIP+4).
Enriquecimento e correlação de dados
A transformação de dados é aplicada aos dados existentes sem referência a dados de referência adicionais relacionados. Com o enriquecimento de dados, são consultados dados adicionais para enriquecer os dados de origem antes de serem armazenados na base de dados de destino.
- Correlação de dados. É possível correlacionar dados de origem. Por exemplo, pode combinar dados de duas tabelas em duas bases de dados de origem. Numa base de dados de destino, por exemplo, pode relacionar um cliente com todas as encomendas abertas, concluídas e canceladas, em que os dados do cliente e os dados da encomenda são provenientes de duas bases de dados de origem diferentes.
- Enriquecimento de dados. O enriquecimento de dados adiciona dados de referência. Por exemplo, pode enriquecer registos que apenas contêm um código postal adicionando o nome da cidade correspondente ao código postal. Uma tabela de referência que contém códigos postais e os nomes das cidades correspondentes é um conjunto de dados estático acedido para este exemplo de utilização. Os dados de referência também podem ser dinâmicos. Por exemplo, pode usar uma lista de todos os clientes conhecidos como dados de referência.
Redução e filtragem de dados
Outro tipo de transformação de dados é a redução ou a filtragem dos dados de origem antes de os migrar para uma base de dados de destino.
- Redução de dados. A redução de dados remove atributos de um item de dados. Por exemplo, se um código postal estiver presente num item de dados, o nome da cidade correspondente pode não ser necessário e é ignorado, porque pode ser recalculado ou porque já não é necessário. Por vezes, estas informações são mantidas por motivos históricos para registar o nome da cidade introduzido pelo utilizador, mesmo que o nome da cidade mude ao longo do tempo.
- Filtragem de dados. A filtragem de dados remove completamente um item de dados. Por exemplo, todas as encomendas canceladas podem ser removidas e não transferidas para a base de dados de destino.
Combinação ou recombinação de dados
Se os dados forem migrados de diferentes bases de dados de origem para diferentes bases de dados de destino, pode ser necessário combinar os dados de forma diferente entre as bases de dados de origem e de destino.
Suponhamos que os clientes e as encomendas estão armazenados em duas bases de dados de origem diferentes. Uma base de dados de origem contém todas as encomendas e uma segunda base de dados de origem contém todos os clientes. Após a migração, os clientes e as respetivas encomendas são armazenados numa relação de 1:n num único esquema da base de dados de destino. No entanto, não são armazenados numa única base de dados de destino, mas sim em várias bases de dados de destino, cada uma das quais contém uma partição dos dados. Cada base de dados de destino representa uma região e contém todos os clientes e respetivas encomendas localizados nessa região.
Endereçamento da base de dados de destino
A menos que exista apenas uma base de dados de destino, cada item de dados migrado tem de ser enviado para a base de dados de destino correta. Seguem-se algumas abordagens para resolver o problema da base de dados de destino:
- Endereçamento baseado em esquemas. A endereçagem baseada em esquemas determina a base de dados de destino com base no esquema. Por exemplo, todos os itens de dados de uma coleção de clientes ou todas as linhas de uma tabela de clientes são migrados para a mesma base de dados de destino que armazena informações dos clientes, mesmo que estas informações tenham sido distribuídas em várias bases de dados de origem.
- Encaminhamento com base no conteúdo. A reencaminhamento com base no conteúdo (através de um router com base no conteúdo, por exemplo) determina a base de dados de destino com base nos valores dos dados. Por exemplo, todos os clientes localizados na região da América Latina são migrados para uma base de dados de destino específica que representa essa região.
Pode usar ambos os tipos de endereçamento em simultâneo numa migração de base de dados. Independentemente do tipo de endereçamento usado, a base de dados de destino tem de ter o esquema correto implementado para que os itens de dados sejam armazenados.
Persistência dos dados em trânsito
Os sistemas de migração de bases de dados ou os ambientes nos quais são executados podem falhar durante uma migração, e os dados em trânsito podem ser perdidos. Quando ocorrem falhas, tem de reiniciar o sistema de migração da base de dados e garantir que os dados armazenados na base de dados de origem são migrados de forma consistente e completa para as bases de dados de destino.
Como parte da recuperação, o sistema de migração da base de dados tem de identificar o item de dados migrado com êxito mais recente para determinar onde começar a extrair das bases de dados de origem. Para retomar no ponto de falha, o sistema tem de manter um estado interno sobre o progresso da migração.
Pode manter o estado de várias formas:
- Pode armazenar todos os itens de dados extraídos no sistema de migração da base de dados antes de qualquer modificação da base de dados e, em seguida, remover o item de dados assim que a versão modificada for armazenada com êxito na base de dados de destino. Esta abordagem garante que o sistema de migração da base de dados consegue determinar exatamente o que é extraído e armazenado.
- Pode manter uma lista de referências aos itens de dados em trânsito. Uma possibilidade é armazenar as chaves principais ou outros identificadores únicos de cada item de dados juntamente com um atributo de estado. Após uma falha, este estado é a base para recuperar o sistema de forma consistente.
- Pode consultar as bases de dados de origem e de destino após uma falha para determinar a diferença entre os sistemas de base de dados de origem e de destino. O item de dados seguinte a ser extraído é determinado com base na diferença.
Outras abordagens para manter o estado podem depender das bases de dados de origem específicas. Por exemplo, um sistema de migração de bases de dados pode monitorizar as entradas do registo de transações obtidas da base de dados de origem e as que são inseridas na base de dados de destino. Se ocorrer uma falha, a migração pode ser reiniciada a partir da última entrada inserida com êxito.
A persistência dos dados em trânsito também é importante por outros motivos que não erros ou falhas. Por exemplo, pode não ser possível consultar dados da base de dados de origem para determinar o respetivo estado. Por exemplo, se a base de dados de origem contiver uma fila, as mensagens nessa fila podem ter sido removidas em algum momento.
Outro exemplo de utilização da persistência de dados em trânsito é o processamento de dados de grandes janelas. Durante a modificação de dados, os itens de dados podem ser transformados independentemente uns dos outros. No entanto, por vezes, a modificação dos dados depende de vários itens de dados (por exemplo, numerar os itens de dados processados por dia, começando em zero todos os dias).
Um último exemplo de utilização da persistência de dados em trânsito é fornecer repetibilidade dos dados durante a modificação de dados quando o sistema de base de dados não consegue aceder novamente às bases de dados de origem. Por exemplo, pode ter de voltar a executar as modificações de dados com regras de modificação diferentes e, em seguida, validar e comparar os resultados com as modificações de dados iniciais. Esta abordagem pode ser necessária se precisar de acompanhar quaisquer inconsistências na base de dados de destino devido a uma modificação incorreta dos dados.
Validação da integridade e consistência
Tem de verificar se a migração da base de dados está concluída e é consistente. Esta verificação garante que cada item de dados é migrado apenas uma vez e que os conjuntos de dados nas bases de dados de origem e de destino são idênticos e que a migração está concluída.
Consoante as regras de modificação de dados, é possível que um item de dados seja extraído, mas não inserido numa base de dados de destino. Por este motivo, a comparação direta das bases de dados de origem e de destino não é uma abordagem sólida para verificar a integridade e a consistência. No entanto, se o sistema de migração da base de dados monitorizar os itens filtrados, pode comparar as bases de dados de origem e de destino juntamente com os itens filtrados.
Funcionalidade de replicação do sistema de gestão de bases de dados
Um exemplo de utilização especial numa migração homogénea é quando a base de dados de destino é uma cópia da base de dados de origem. Especificamente, os esquemas nas bases de dados de origem e de destino são os mesmos, os valores dos dados são os mesmos e cada base de dados de origem é um mapeamento direto (1:1) para uma base de dados de destino.
Neste caso, pode usar a funcionalidade de replicação integrada que acompanha a maioria dos sistemas de gestão de bases de dados para replicar uma base de dados para outra.
Existem dois tipos de replicação de dados: lógica e física.
Replicação lógica: no caso da replicação lógica, as alterações nos objetos da base de dados são transferidas com base nos respetivos identificadores de replicação (normalmente, chaves primárias). As vantagens da replicação lógica são a flexibilidade, a granularidade e a possibilidade de personalização. Em alguns casos, a replicação lógica permite replicar alterações entre diferentes versões do motor de base de dados. Muitos motores de base de dados suportam filtros de replicação lógica, onde pode definir o conjunto de dados a replicar. As principais desvantagens são que a replicação lógica pode introduzir alguma sobrecarga de desempenho e a latência deste método de replicação é geralmente superior à da replicação física.
Replicação física: por outro lado, a replicação física funciona ao nível do bloco do disco e oferece um melhor desempenho com uma latência de replicação mais baixa. Para grandes conjuntos de dados, a replicação física pode ser mais simples e eficiente, especialmente no caso de estruturas de dados não relacionais. No entanto, não é personalizável e depende muito da versão do motor da base de dados.
Alguns exemplos são a replicação do MySQL, a replicação do PostgreSQL (veja também o pglogical) ou a replicação do Microsoft SQL Server.
No entanto, se for necessária a modificação de dados ou tiver uma cardinalidade diferente de um mapeamento direto, são necessárias as capacidades de um sistema de migração de base de dados para abordar esse exemplo de utilização.
Funcionalidade de migração de base de dados personalizada
Alguns motivos para criar funcionalidades de migração de bases de dados em vez de usar um sistema de migração de bases de dados ou um sistema de gestão de bases de dados incluem o seguinte:
- Precisa de controlo total sobre todos os detalhes.
- Quer reutilizar as capacidades de migração de bases de dados.
- Quer reduzir os custos ou simplificar a sua pegada tecnológica.
As bases para criar funcionalidades de migração incluem o seguinte:
- Exportação e importação: se o tempo de inatividade não for um fator, pode usar a exportação e a importação de bases de dados para migrar dados em migrações de bases de dados homogéneas. No entanto, a exportação e a importação requerem que coloque a base de dados de origem em estado inativo para impedir atualizações antes de exportar os dados. Caso contrário, as alterações podem não ser captadas na exportação, e a base de dados de destino não é uma cópia exata da base de dados de origem.
- Cópia de segurança e restauro: tal como no caso da exportação e importação, a cópia de segurança e o restauro implicam tempo de inatividade porque tem de desativar a base de dados de origem para que a cópia de segurança contenha todos os dados e as alterações mais recentes. O tempo de inatividade continua até a restauração ser concluída com êxito na base de dados de destino.
- Consultas diferenciais: se alterar o esquema da base de dados for uma opção, pode expandir o esquema para que as alterações à base de dados possam ser consultadas na interface de consulta. É adicionado um atributo de data/hora adicional, que indica a hora da última alteração. Pode ser adicionada uma flag de eliminação adicional, que indica se o item de dados foi eliminado ou não (eliminação lógica). Com estas duas alterações, um inquiridor que é executado a intervalos regulares pode consultar todas as alterações desde a última execução. As alterações são aplicadas à base de dados de destino. São abordadas abordagens adicionais em Captura de dados de alterações.
Estas são apenas algumas das opções possíveis para criar uma migração de base de dados personalizada. Embora uma solução personalizada ofereça a maior flexibilidade e controlo sobre a implementação, também requer manutenção constante para resolver erros, limitações de escalabilidade e outros problemas que possam surgir durante uma migração da base de dados.
Considerações adicionais sobre a migração de bases de dados
As secções seguintes abordam brevemente aspetos não funcionais que são importantes no contexto da migração de bases de dados. Estes aspetos incluem o processamento de erros, a escalabilidade, a alta disponibilidade e a recuperação de desastres.
Processamento de erros
As falhas durante a migração da base de dados não devem causar perda de dados nem o processamento de alterações da base de dados fora de ordem. A integridade dos dados tem de ser preservada independentemente do que causou a falha (como um erro no sistema, uma interrupção da rede, uma falha de VM ou uma falha de zona).
Ocorre uma perda de dados quando um sistema de migração obtém os dados das bases de dados de origem e não os armazena nas bases de dados de destino devido a algum erro. Quando os dados são perdidos, as bases de dados de destino não correspondem às bases de dados de origem e, por isso, são inconsistentes e incompletas. A funcionalidade de validação de integridade e consistência sinaliza este estado (Validação de integridade e consistência).
Escalabilidade
Numa migração de base de dados, o tempo de migração é uma métrica importante. Numa migração sem inatividade (no sentido de inatividade mínima), a migração dos dados ocorre enquanto as bases de dados de origem continuam a mudar. Para migrar num período razoável, a taxa de transferência de dados tem de ser significativamente mais rápida do que a taxa de atualizações dos sistemas de base de dados de origem, especialmente quando o sistema de base de dados de origem é grande. Quanto mais elevada for a taxa de transferência, mais rápida será a conclusão da migração da base de dados.
Quando os sistemas de base de dados de origem estão inativos e não estão a ser modificados, a migração pode ser mais rápida porque não existem alterações a incorporar. Numa base de dados homogénea, o tempo de migração pode ser bastante rápido porque pode usar funcionalidades de cópia de segurança e restauro ou de exportação e importação, e a transferência de ficheiros é escalável.
Alta disponibilidade e recuperação de desastres
Em geral, as bases de dados de origem e de destino são configuradas para alta disponibilidade. Uma base de dados principal tem uma réplica de leitura correspondente que é promovida a base de dados principal quando ocorre uma falha.
Quando uma zona falha, as bases de dados de origem ou de destino mudam para uma zona diferente para estarem continuamente disponíveis. Se ocorrer uma falha de zona durante uma migração de base de dados, o próprio sistema de migração é afetado porque várias das bases de dados de origem ou de destino a que acede ficam inacessíveis. O sistema de migração tem de voltar a ligar-se às bases de dados principais recém-promovidas que estão em execução após uma falha. Assim que o sistema de migração da base de dados for novamente ligado, tem de recuperar a própria migração para garantir a integridade e a consistência dos dados nas bases de dados de destino. O sistema de migração tem de determinar a última transferência consistente para estabelecer onde retomar.
Se o próprio sistema de migração da base de dados falhar (por exemplo, a zona em que é executado ficar inacessível), tem de ser recuperado. Uma abordagem de recuperação é um reinício a frio. Nesta abordagem, o sistema de migração da base de dados é instalado numa zona operacional e reiniciado. O principal problema a resolver é que o sistema de migração tem de conseguir determinar a última transferência de dados consistente antes da falha e continuar a partir desse ponto para garantir a integridade e a consistência dos dados nas bases de dados de destino.
Se o sistema de migração da base de dados estiver ativado para alta disponibilidade, pode mudar para um sistema alternativo e continuar o processamento posteriormente. Se for importante ter um tempo de inatividade limitado do sistema de migração da base de dados, tem de selecionar uma base de dados e implementar uma elevada disponibilidade.
Em termos de recuperação da migração da base de dados, a recuperação de desastres é muito semelhante à elevada disponibilidade. Em vez de voltar a ligar a bases de dados primárias recentemente promovidas numa zona diferente, o sistema de migração de bases de dados tem de voltar a ligar a bases de dados numa região diferente (uma região de alternativa). O mesmo se aplica ao próprio sistema de migração da base de dados. Se a região onde o sistema de migração da base de dados é executado ficar inacessível, o sistema de migração da base de dados tem de mudar para uma região diferente e continuar a partir da última transferência de dados consistente.
Armadilhas
Existem várias armadilhas que podem causar dados inconsistentes nas bases de dados de destino. Seguem-se alguns erros comuns que deve evitar:
- Violação de encomenda. Se a escalabilidade do sistema de migração for alcançada através da expansão, vários processos de transferência de dados são executados em simultâneo (em paralelo). As alterações num sistema de base de dados de origem são ordenadas de acordo com as transações confirmadas. Se as alterações forem recolhidas do registo de transações, a ordem tem de ser mantida durante toda a migração. A transferência de dados paralela pode alterar a ordem devido à variação da velocidade entre os processos subjacentes. É necessário garantir que os dados são inseridos nas bases de dados de destino pela mesma ordem em que são recebidos das bases de dados de origem.
- Violação de consistência. Com as consultas diferenciais, as bases de dados de origem têm atributos de dados adicionais que contêm, por exemplo, marcações de tempo de confirmação. As bases de dados de destino não têm datas/horas de confirmação, porque as datas/horas de confirmação só são implementadas para estabelecer a gestão de alterações nas bases de dados de origem. É importante garantir que as inserções nas bases de dados de destino têm de ser consistentes com a data/hora, o que significa que todas as alterações com a mesma data/hora têm de estar na mesma transação de inserção, atualização ou inserção/atualização. Caso contrário, a base de dados de destino pode ter um estado inconsistente (temporariamente) se algumas alterações forem inseridas e outras com a mesma data/hora não forem. Este estado temporário inconsistente não tem importância se não for acedido às bases de dados de destino para processamento. No entanto, se forem usados para testes, a consistência é fundamental. Outro aspeto é a criação dos valores de data/hora na base de dados de origem e a forma como se relacionam com a hora de confirmação da transação em que são definidos. Devido às dependências de confirmação de transações, uma transação com uma data/hora anterior pode ficar visível após uma transação com uma data/hora posterior. Se a consulta diferencial for executada entre as duas transações, não vai ver a transação com a data/hora anterior, o que resulta numa inconsistência na base de dados de destino.
- Dados em falta ou duplicados. Quando ocorre uma ativação pós-falha, é necessária uma recuperação cuidadosa se alguns dados não forem replicados entre a réplica principal e a de ativação pós-falha. Por exemplo, uma base de dados de origem sofre uma ativação pós-falha e nem todos os dados são replicados para a réplica de ativação pós-falha. Ao mesmo tempo, os dados já foram migrados para a base de dados de destino antes da falha. Após a comutação por falha, a base de dados principal recentemente promovida está atrasada em termos de alterações de dados na base de dados de destino (denominada reversão). Um sistema de migração tem de reconhecer esta situação e recuperar de tal forma que a base de dados de destino e a base de dados de origem voltem a um estado consistente.
- Transações locais. Para que a base de dados de origem e de destino recebam as mesmas alterações, uma abordagem comum consiste em fazer com que os clientes escrevam nas bases de dados de origem e de destino, em vez de usarem um sistema de migração de dados. Esta abordagem tem várias armadilhas. Um erro comum é que a escrita em duas bases de dados são duas transações separadas. Pode ocorrer uma falha após a conclusão da primeira e antes da conclusão da segunda. Este cenário causa dados inconsistentes dos quais tem de recuperar. Além disso, existem vários clientes em geral, e não estão coordenados. Os clientes não conhecem a ordem de confirmação da transação da base de dados de origem e, por isso, não podem escrever nas bases de dados de destino que implementam essa ordem de transação. Os clientes podem alterar a ordem, o que pode levar a inconsistências nos dados. A menos que todo o acesso passe por clientes coordenados e todos os clientes garantam a ordem das transações de destino, esta abordagem pode levar a um estado inconsistente com a base de dados de destino.
Em geral, existem outras armadilhas a ter em atenção. A melhor forma de encontrar problemas que possam levar a inconsistências nos dados é fazer uma análise completa de falhas que itere todos os cenários de falhas possíveis. Se a simultaneidade for implementada no sistema de migração da base de dados, têm de ser examinadas todas as ordens de execução possíveis do processo de migração de dados para garantir que a consistência dos dados é preservada. Se for implementada a elevada disponibilidade ou a recuperação de desastres (ou ambas), têm de ser examinadas todas as combinações de falhas possíveis.
O que se segue?
- Leia o artigo Migrações de bases de dados: conceitos e princípios (parte 2).
- Leia acerca da migração de bases de dados nos seguintes documentos:
- Consulte o artigo Migração de base de dados para ver mais guias de migração de bases de dados.
- Explore arquiteturas de referência, diagramas e práticas recomendadas sobre o Google Cloud. Consulte o nosso Centro de arquitetura na nuvem.