In diesem Dokument werden die Konzepte, Prinzipien, Terminologie und Architektur der Datenbankmigration, die praktisch ohne Ausfallzeiten erfolgt, für Cloud-Architekten erläutert, die Datenbanken von lokalen oder anderen Cloud-Umgebungen zu Google Cloud migrieren müssen.
Dieses Dokument ist Teil 1 von zwei Teilen. Teil 2 behandelt die Einrichtung und Ausführung des Migrationsprozesses, einschließlich Fehlerszenarien.
Bei der Datenbankmigration werden Daten aus einer oder mehreren Quelldatenbanken mithilfe eines Datenbank-Migrationsdienstes in eine oder mehrere Zieldatenbanken migriert. Wenn eine Migration abgeschlossen ist, befindet sich das Dataset aus den Quelldatenbanken vollständig, jedoch möglicherweise umstrukturiert, in den Quelldatenbanken. Clients, die auf die Quelldatenbanken zugegriffen haben, werden dann auf die Zieldatenbanken umgestellt und die Quelldatenbanken werden heruntergefahren.
Das folgende Diagramm veranschaulicht diesen Datenbank-Migrationsprozess.
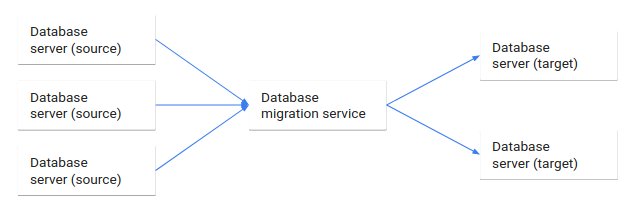
Dieses Dokument beschreibt die Datenbankmigration aus architektonischer Sicht:
- Die Dienste und Technologien, die an der Datenbankmigration beteiligt sind.
- Die Unterschiede zwischen der homogenen und heterogenen Datenbankmigrationen.
- Die Kompromisse und die Auswahl einer Toleranz für die Migrationsausfallzeit.
- Eine Einrichtungsarchitektur, die einen Fallback unterstützt, wenn während einer Migration unvorhergesehene Fehler auftreten.
In diesem Dokument wird nicht beschrieben, wie Sie eine bestimmte Technologie zur Datenbankmigration einrichten. Vielmehr werden die Grundsätze, Konzepte und Prinzipien der Datenbankmigration vorgestellt.
Architektur
Das folgende Diagramm zeigt eine allgemeine Architektur der Datenbankmigration.
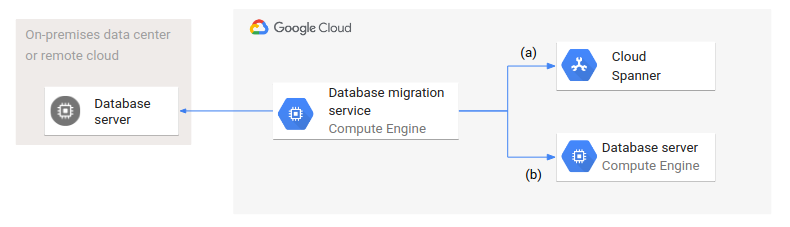
Ein Datenbank-Migrationsdienst wird in Google Cloud ausgeführt und greift sowohl auf Quell- als auch Zieldatenbanken zu. Es werden zwei Varianten dargestellt: (a) zeigt die Migration von einer Quelldatenbank in einem lokalen Rechenzentrum oder einer Remote-Cloud zu einer verwalteten Datenbank wie Spanner. (b) zeigt eine Migration zu einer Datenbank in Compute Engine.
Auch wenn sich die Zieldatenbanken in Typ (verwaltet und nicht verwaltet) und Einrichtung unterscheiden, ist die Architektur und Konfiguration der Datenbankmigration in beiden Fällen gleich.
Terminologie
Im Folgenden sind die wichtigsten Datenmigrationsbegriffe für diese Dokumente definiert:
Quelldatenbank: eine Datenbank mit Daten, die in eine oder mehrere Zieldatenbanken migriert werden sollen.
Zieldatenbank: eine Datenbank, die Daten aufnimmt, die aus einer oder mehreren Quelldatenbanken migriert wurden.
Datenbankmigration: eine Migration von Daten aus Quelldatenbanken zu Zieldatenbanken mit dem Ziel, die Quelldatenbanksysteme nach Abschluss der Migration herunterzufahren. Das Dataset wird vollständig oder teilweise migriert.
Homogene Migration: eine Migration von Quelldatenbanken zu Zieldatenbanken, bei der die Quell- und Zieldatenbanken dasselbe Datenbank-Verwaltungssystem desselben Anbieters haben.
Heterogene Migration: eine Migration von Quelldatenbanken zu Zieldatenbanken, bei der die Quell- und Zieldatenbanken verschiedene Datenbank-Verwaltungssysteme verschiedener Anbieter haben.
Datenbank-Migrationssystem: ein Softwaresystem oder -dienst, das bzw. der eine Verbindung zu Quelldatenbanken und Zieldatenbanken herstellt und Datenmigrationen von Quell- zu Zieldatenbanken ausführt.
Datenmigrationsprozess: ein konfigurierter oder implementierter Prozess, der vom Datenmigrationssystem ausgeführt wird, um Daten aus Quell- in Zieldatenbanken zu übertragen und die Daten während der Übertragung gegebenenfalls zu transformieren.
Datenbankreplikation: eine kontinuierliche Übertragung von Daten aus Quell- in Zieldatenbanken, ohne die Quelldatenbanken letztendlich herunterzufahren. Die Datenbankreplikation (manchmal als Datenbankstreaming bezeichnet) ist ein fortlaufender Prozess.
Klassifizierung von Datenbankmigrationen
Es gibt verschiedene Arten von Datenbankmigrationen, die zu verschiedenen Klassen gehören. In diesem Abschnitt werden die Kriterien beschrieben, die diese Klassen definieren.
Replikation oder Migration
Bei einer Datenbankmigration verschieben Sie Daten aus Quelldatenbanken in Zieldatenbanken. Wenn alle Daten migriert sind, löschen Sie die Quelldatenbanken und leiten den Clientzugriff zu den Zieldatenbanken um. Manchmal behalten Sie die Quelldatenbanken als Fallback-Maßnahme bei, falls unvorhergesehene Probleme mit den Zieldatenbanken auftreten. Allerdings werden die Quelldatenbanken letztendlich gelöscht, sobald die Zieldatenbanken zuverlässig funktionieren.
Bei der Datenbankreplikation übertragen Sie dagegen kontinuierlich Daten aus den Quelldatenbanken in die Zieldatenbanken, ohne die Quelldatenbanken zu löschen. Manchmal wird die Datenbankreplikation als Datenbankstreaming bezeichnet. Es gibt zwar eine definierte Startzeit, aber in der Regel keine definierte Abschlusszeit. Die Replikation kann angehalten werden oder in eine Migration übergehen.
In diesem Dokument wird nur die Datenbankmigration behandelt.
Partielle Migration oder vollständige Migration
Unter Datenbankmigration versteht man eine vollständige und konsistente Übertragung von Daten. Sie definieren das zu übertragende anfängliche Dataset entweder als vollständige Datenbank oder als Teildatenbank (eine Teilmenge der Daten in einer Datenbank) sowie jede Änderung, für die anschließend im Quelldatenbanksystem ein Commit durchgeführt wird.
Heterogene Migration oder homogene Migration
Eine homogene Datenbankmigration ist eine Migration zwischen Quell- und Zieldatenbanken derselben Datenbanktechnologie, z. B. die Migration von einer MySQL-Datenbank zu einer anderen MySQL-Datenbank oder von einer Oracle®-Datenbank zu einer anderen Oracle-Datenbank. Homogene Migrationen umfassen auch Migrationen von einem selbst gehosteten Datenbanksystem wie PostgreSQL zu einer verwalteten Version dieses Systems wie Cloud SQL for PostgreSQL oder AlloyDB for PostgreSQL.
Bei einer homogenen Datenbankmigration sind die Schemas für die Quell- und Zieldatenbank wahrscheinlich identisch. Wenn sich die Schemas unterscheiden, müssen die Daten aus den Quelldatenbanken während der Migration transformiert werden.
Die heterogene Datenbankmigration ist eine Migration zwischen Quell- und Zieldatenbanken unterschiedlicher Datenbanktechnologien, z. B. von einer Oracle-Datenbank zu Spanner. Eine heterogene Datenbankmigration kann zwischen denselben Datenmodellen (z. B. von einem relationalen zu einem anderen relationalen Modell) oder zwischen verschiedenen Datenmodellen (z. B. von einem relationalen zu einem Schlüssel/Wert-Modell) erfolgen.
Die Migration zwischen unterschiedlichen Datenbanktechnologien bedeutet nicht zwangsläufig, dass verschiedene Datenmodelle beteiligt sind. Zum Beispiel unterstützen Oracle, MySQL, PostgreSQL und Spanner alle das relationale Datenmodell. Allerdings unterstützten Multi-Modell-Datenbanken wie Oracle, MySQL oder PostgreSQL unterschiedliche Datenmodelle. Daten, die als JSON-Dokumente in einer Multi-Modell-Datenbank gespeichert sind, können mit keinen oder geringfügigen Transformationen zu MongoDB migriert werden, da das Datenmodell in der Quell- und Zieldatenbank identisch ist.
Obwohl die Unterscheidung zwischen homogener und heterogener Migration auf Datenbanktechnologien beruht, basiert eine alternative Kategorisierung auf den beteiligten Datenbankmodellen. Beispielsweise ist eine Migration von einer Oracle-Datenbank zu Spanner homogen, wenn beide Datenbanken das relationale Datenmodell verwenden. Eine Migration ist heterogen, wenn zum Beispiel Daten, die als JSON-Objekte in Oracle gespeichert sind, zu einem relationalen Modell in Spanner migriert werden.
Die Kategorisierung von Migrationen nach Datenmodellen gibt die Komplexität und den erforderlichen Aufwand für die Migration der Daten präziser wieder als die Kategorisierung nach beteiligten Datenbanksystemen. Da die in der Branche übliche Kategorisierung jedoch auf den beteiligten Datenbanksystemen beruht, basieren die übrigen Abschnitte auf dieser Unterscheidung.
Migrationsausfallzeit: null, minimal oder erheblich
Nachdem Sie ein Dataset erfolgreich von der Quell- zur Zieldatenbank migriert haben, schalten Sie den Clientzugriff auf die Zieldatenbank um und löschen die Quelldatenbank.
Das Umschalten von Clients von den Quelldatenbanken auf die Zieldatenbanken umfasst mehrere Prozesse:
- Damit Clients die Verarbeitung fortsetzen können, müssen sie bestehende Verbindungen zu den Quelldatenbanken schließen und neue Verbindungen zu den Zieldatenbanken erstellen. Im Idealfall erfolgt das Schließen von Verbindungen ordnungsgemäß, was bedeutet, dass Sie keine Rollbacks für laufende Transaktionen unnötigerweise durchführen müssen.
- Nachdem die Verbindungen zu den Quelldatenbanken geschlossen wurden, müssen Sie die verbleibenden Änderungen aus den Quelldatenbanken zu den Zieldatenbanken migrieren (sogenanntes Draining), um alle Änderungen auch wirklich zu erfassen.
- Unter Umständen müssen Sie Zieldatenbanken testen, um zu bestätigen, dass diese Datenbanken funktionieren und dass Clients im Rahmen ihrer definierten Service Level Objectives (SLOs) funktionstüchtig und betriebsbereit sind.
Eine Migration ohne jegliche Ausfallzeit für Clients ist nicht realisierbar, da es Zeiten gibt, in denen Clients keine Anfragen verarbeiten können. Allerdings lässt sich die Zeitspanne, in der die Anfrageverarbeitung durch Clients nicht möglich ist, mit mehreren Methoden (auf nahezu keine Ausfallzeit) minimieren:
- Sie können die Testclients im Lesemodus für die Zieldatenbanken starten, lange bevor Sie die Clients umstellen. Bei diesem Ansatz werden die Tests gleichzeitig mit der Migration ausgeführt.
- Sie können die zu migrierende Datenmenge (also die zwischen den Quell- und Zieldatenbanken in Übertragung befindliche Menge) so klein wie möglich halten, wenn der Umstellungszeitraum näher rückt. Dieser Schritt verkürzt die Zeit für das Draining, da es weniger Unterschiede zwischen den Quell- und Zieldatenbanken gibt.
- Wenn die für Zieldatenbanken ausgeführten neuen Clients gleichzeitig mit den für Quelldatenbanken ausgeführten vorhandenen Clients gestartet werden können, lässt sich die Umstellungszeit verkürzen, da die neuen Clients zur Ausführung bereit sind, sobald das Draining auf alle Daten angewendet wurde.
Während eine Umstellung ganz ohne Ausfallzeit unrealistisch ist, können Sie die Ausfallzeit dadurch minimieren, dass Sie Aktivitäten möglichst gleichzeitig mit der laufenden Datenmigration starten.
In einigen Szenarien der Datenbankmigration sind erhebliche Ausfallzeiten akzeptabel. Wie lang diese sein dürfen, hängt in der Regel von geschäftlichen Anforderungen ab. In solchen Fällen können Sie Ihren Ansatz vereinfachen. Beispielsweise sind bei einer homogenen Datenbankmigration unter Umständen keine Datenänderungen erforderlich. Hier stellen Export und Import oder Sicherung und Wiederherstellung perfekte Ansätze dar. Bei heterogenen Migrationen muss sich das Datenbank-Migrationssystem während der Migration nicht um Aktualisierungen der Quelldatenbanksysteme kümmern.
Sie müssen jedoch dafür sorgen, dass die akzeptable Ausfallzeit lang genug ist, damit die Datenbankmigration und die nachfolgenden Tests ausgeführt werden können. Wenn diese Ausfallzeit nicht klar festgelegt werden kann oder inakzeptabel lang ist, müssen Sie eine Migration mit minimaler Ausfallzeit planen.
Kardinalität der Datenbankmigration
In vielen Fällen findet die Datenbankmigration zwischen einer einzelnen Quelldatenbank und einer einzelnen Zieldatenbank statt. In solchen Situationen ist die Kardinalität 1:1 (direkte Zuordnung). Das heißt, eine Quelldatenbank wird ohne Änderungen zu einer Zieldatenbank migriert.
Eine direkte Zuordnung ist jedoch nicht die einzige Möglichkeit. Weitere Kardinalitäten sind unter anderem:
- Konsolidierung (n:1): Bei einer Konsolidierung migrieren Sie Daten aus mehreren Quelldatenbanken zu einer kleineren Anzahl von Zieldatenbanken (oder sogar zu einer einzigen Zieldatenbank). Sie können diesen Ansatz verwenden, um die Datenbankverwaltung zu vereinfachen oder eine skalierbare Zieldatenbank zu verwenden.
- Verteilung (1:n): Bei einer Verteilung migrieren Sie Daten aus einer einzigen Quelldatenbank in mehrere Zieldatenbanken. Sie können diesen Ansatz beispielsweise verwenden, wenn Sie eine große zentralisierte Datenbank mit regionalen Daten in mehrere regionale Zieldatenbanken migrieren müssen.
- Umverteilung (n:m): Bei einer Umverteilung migrieren Sie Daten aus mehreren Quelldatenbanken in mehrere Zieldatenbanken. Sie können diesen Ansatz verwenden, wenn Sie fragmentierte Quelldatenbanken mit Shards von sehr unterschiedlicher Größe haben. Bei der Umverteilung werden die fragmentierten Daten gleichmäßig auf mehrere Zieldatenbanken verteilt, die die Shards darstellen.
Die Datenbankmigration bietet Ihnen neben der reinen Migration von Daten die Möglichkeit, Ihre Datenbankarchitektur neu zu gestalten und diese zu implementieren.
Migrationskonsistenz
Es wird erwartet, dass eine Datenbankmigration konsistent ist. Im Kontext der Migration bedeutet konsistent Folgendes:
- Vollständig: Alle Daten, die als zu migrierende Daten angegeben sind, werden tatsächlich migriert. Die angegebenen Daten können alle Daten in einer Quelldatenbank oder eine Teilmenge der Daten sein.
- Ohne Duplikate: Jedes Datenelement wird nur genau einmal migriert. Es werden keine doppelten Daten in die Zieldatenbank eingefügt.
- Geordnet: Die Datenänderungen aus der Quelldatenbank werden in derselben Reihenfolge auf die Zieldatenbank angewendet, wie sie in der Quelldatenbank vorgenommen wurden. Dieser Aspekt ist wichtig, um die Konsistenz der Daten zu wahren.
Alternativ lässt sich Migrationskonsistenz so beschreiben, dass der Datenzustand nach Abschluss einer Migration in den Quell- und Zieldatenbanken äquivalent ist. Bei einer homogenen Migration mit direkter Zuordnung einer relationalen Datenbank müssen beispielsweise in den Quell- und Zieldatenbanken dieselben Tabellen und Zeilen vorhanden sein.
Diese alternative Beschreibung der Migrationskonsistenz ist wichtig, da nicht alle Datenmigrationen darauf basieren, dass Transaktionen aus der Quelldatenbank sequenziell auf die Zieldatenbank angewendet werden. Sie können beispielsweise die Quelldatenbank sichern und den Inhalt der Quelldatenbank mithilfe der Sicherung in der Zieldatenbank wiederherstellen, wenn eine erhebliche Ausfallzeit im Rahmen des Möglichen ist.
Aktiv/Passiv-Migration oder Aktiv/Aktiv-Migration
Eine wichtige Unterscheidung besteht darin, ob sowohl die Quell- als auch die Zieldatenbank die Verarbeitung von Abfragen zulässt, die Änderungen vornehmen. Bei einer Aktiv/Passiv-Datenbankmigration können die Quelldatenbanken während der Migration geändert werden, während die Zieldatenbanken nur Lesezugriff zulassen.
Eine Aktiv/Aktiv-Migration unterstützt Clients, die während der Migration sowohl in die Quell- als auch in die Zieldatenbanken schreiben. Bei dieser Art der Migration können Konflikte auftreten. Wenn beispielsweise dasselbe Datenelement in der Quell- und Zieldatenbank so geändert wird, dass es zu einem semantischen Konflikt kommt, müssen Sie möglicherweise Konfliktlösungsregeln ausführen, um den Konflikt zu lösen.
Bei einer Aktiv/Aktiv-Migration müssen Sie in der Lage sein, alle Datenkonflikte mithilfe von Konfliktlösungsregeln zu lösen. Wenn dies nicht möglich ist, kann es zu Dateninkonsistenzen kommen.
Architektur der Datenbankmigration
Die Architektur einer Datenbankmigration beschreibt die verschiedenen Komponenten, die für die Ausführung einer Datenbankmigration erforderlich sind. In diesem Abschnitt wird eine allgemeine Bereitstellungsarchitektur vorgestellt und das Datenbank-Migrationssystem als separate Komponente behandelt. Außerdem werden die Features eines Datenbank-Verwaltungssystems erläutert, die die Datenmigration und nicht funktionale Attribute unterstützen, die für viele Anwendungsfälle wichtig sind.
Bereitstellungsarchitektur
Eine Datenbankmigration kann zwischen Quell- und Zieldatenbanken in beliebigen Umgebungen erfolgen, z. B. lokal oder in verschiedenen Clouds. Jede Quell- und Zieldatenbank kann sich in einer anderen Umgebung befinden. Es ist nicht erforderlich, dass alle Datenbanken in derselben Umgebung angesiedelt sind.
Das folgende Diagramm zeigt ein Beispiel für eine Bereitstellungsarchitektur mit mehreren Umgebungen.
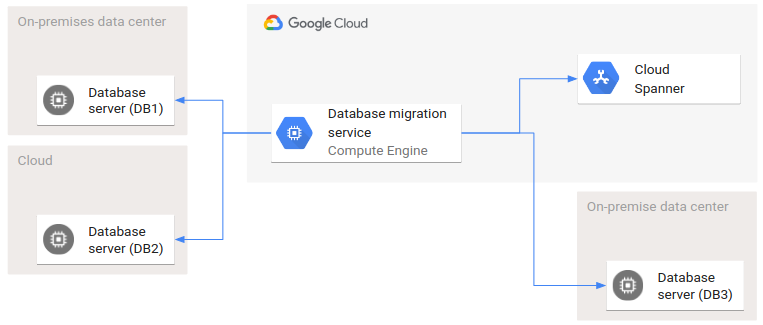
DB1 und DB2 sind zwei Quelldatenbanken und DB3 und Spanner sind die Zieldatenbanken. An dieser Datenbankmigration sind zwei Clouds und zwei lokale Rechenzentren beteiligt. Die Pfeile stellen die Aufrufbeziehungen dar: Der Datenbank-Migrationsdienst ruft Schnittstellen von allen Quell- und Zieldatenbanken auf.
Ein hier nicht behandelter Sonderfall ist die Migration von Daten zwischen ein und derselben Datenbank. In diesem Sonderfall wird das Datenbank-Migrationssystem nur für die Datentransformation verwendet, nicht für die Migration von Daten zwischen verschiedenen Systemen in verschiedenen Umgebungen.
Grundsätzlich gibt es drei Ansätze für die Datenbankmigration, auf die in diesem Abschnitt eingegangen wird:
- Datenbank-Migrationssystem verwenden
- Replikationsfunktion des Datenbank-Verwaltungssystems verwenden
- Benutzerdefinierte Datenbank-Migrationsfunktionen verwenden
Datenbank-Migrationssystem
Das Datenbank-Migrationssystem bildet den Kern der Datenbankmigration. Das System führt die eigentliche Datenextraktion aus den Quelldatenbanken aus, überträgt die Daten in die Zieldatenbanken und ändert die Daten wahlweise während der Übertragung. In diesem Abschnitt werden die grundlegenden Funktionen des Datenbank-Migrationssystems im Allgemeinen erläutert. Beispiele für Datenbank-Migrationssysteme sind Database Migration Service, Striim, Debezium, tcVision und Cloud Data Fusion.
Datenmigrationsprozess
Der wichtigste technische Baustein eines Datenbank-Migrationssystems ist der Datenmigrationsprozess. Der Datenmigrationsprozess wird von einem Entwickler festgelegt und definiert die Quelldatenbanken, aus denen Daten extrahiert werden, die Zieldatenbanken, in die Daten migriert werden, und gegebenenfalls eine Datenänderungslogik, die während der Migration auf die Daten angewendet wird.
Sie können einen oder mehrere Datenmigrationsprozesse angeben und diese je nach den Anforderungen der Migration nacheinander oder gleichzeitig ausführen. Wenn Sie beispielsweise unabhängige Datenbanken migrieren, können die entsprechenden Datenmigrationsprozesse parallel ausgeführt werden.
Datenextraktion und -einfügung
Es gibt zwei Methoden, um Änderungen (Einfüge-, Aktualisierungs-, Löschvorgänge) in einem Datenbanksystem zu erkennen: datenbankgestütztes Change Data Capture (CDC) auf Basis eines Transaktionslogs und differenzielle Abfragen der Daten selbst über die Abfrageschnittstelle eines Datenbank-Verwaltungssystems.
CDC auf Basis eines Transaktionslogs
Datenbankgestütztes CDC basiert auf Datenbank-Verwaltungsfeatures, die von der Abfrageschnittstelle unabhängig sind. Ein Ansatz basiert auf Transaktionslogs (z. B. dem Binärlog in MySQL). Ein Transaktionslog enthält die Änderungen an Daten in der richtigen Reihenfolge. Das Transaktionslog wird kontinuierlich gelesen, sodass jede Änderung beobachtet werden kann. Für die Datenbankmigration ist dieses Logging äußerst nützlich, da CDC dafür sorgt, dass jede Änderung sichtbar ist und anschließend verlustfrei und in der richtigen Reihenfolge in die Zieldatenbank migriert wird.
CDC ist der bevorzugte Ansatz zum Erfassen von Änderungen in einem Datenbank-Verwaltungssystem. CDC ist in die Datenbank selbst eingebunden und hat die geringste Auswirkung auf die Systemlast.
Differenzielle Abfragen
Wenn das Datenbank-Verwaltungssystem kein Feature zum Beobachten aller Änderungen in der richtigen Reihenfolge bietet, können Sie alternativ differenzielle Abfragen verwenden. Bei diesem Ansatz erhält jedes Datenelement in einer Datenbank ein zusätzliches Attribut, das einen Zeitstempel oder eine Sequenznummer enthält. Bei jeder Änderung des Datenelements wird der Änderungszeitstempel hinzugefügt oder die Sequenznummer erhöht. Ein Abfragealgorithmus liest alle Datenelemente seit seiner letzten Ausführung oder seit der letzten von ihm verwendeten Sequenznummer. Sobald der Abfragealgorithmus die Änderungen ermittelt hat, zeichnet er die aktuelle Uhrzeit oder Sequenznummer in seinem internen Status auf und übergibt die Änderungen dann an die Zieldatenbank.
Während dieser Ansatz für Einfüge- und Aktualisierungsvorgänge problemlos funktioniert, müssen Sie Löschvorgänge sorgfältig entwerfen, da bei diesen Vorgängen ein Datenelement aus der Datenbank entfernt wird. Nachdem die Daten gelöscht wurden, kann der Abfragedienst nicht mehr erkennen, dass ein Löschvorgang stattgefunden hat. Sie implementieren einen Löschvorgang mithilfe eines zusätzlichen Statusfeldes (eines logischen Lösch-Flags), das angibt, dass die Daten gelöscht wurden. Alternativ können gelöschte Datenelemente in einer oder mehreren Tabellen gesammelt werden. Der Abfragedienst greift dann auf diese Tabellen zu, um festzustellen, ob ein Löschvorgang stattgefunden hat.
Varianten zu differenziellen Abfragen finden Sie unter Change Data Capture.
Differenzielle Abfragen sind der am wenigsten bevorzugte Ansatz, da dafür Schema- und Funktionsänderungen erforderlich sind. Durch das Abfragen der Datenbank kommt außerdem eine Abfragelast hinzu, die nicht mit der Ausführung von Clientlogik zusammenhängt.
Adapter und Agent
Das Datenbank-Migrationssystem benötigt Zugriff auf die Quelle und die Datenbanksysteme. Adapter sind die Abstraktion, die die Zugriffsfunktionen kapselt. In der einfachsten Form kann ein Adapter ein JDBC-Treiber zum Einfügen von Daten in eine Zieldatenbank sein, die JDBC unterstützt. In einem komplexeren Fall wird ein Adapter in der Umgebung des Ziels ausgeführt (manchmal als Agent bezeichnet) und greift auf eine integrierte Datenbankschnittstelle wie Logdateien zu. In einem noch komplexeren Fall interagiert ein Adapter oder Agent mit einem weiteren Softwaresystem, das wiederum auf die Datenbank zugreift. Beispiel: Ein Agent greift auf Oracle GoldenGate zu, das wiederum auf eine Oracle-Datenbank zugreift.
Der Adapter oder Agent, der auf eine Quelldatenbank zugreift, implementiert je nach Design des Datenbanksystems die CDC-Schnittstelle oder die Schnittstelle für differenzielle Abfragen. In beiden Fällen stellt der Adapter oder Agent dem Datenbank-Migrationssystem Änderungen bereit. Das Datenbank-Migrationssystem weiß nicht, ob die Änderungen von CDC oder differenziellen Abfragen erfasst wurden.
Datenänderung
In einigen Anwendungsfällen werden Daten unverändert aus Quelldatenbanken in Zieldatenbanken migriert. Diese direkten Migrationen sind normalerweise homogen.
In vielen Anwendungsfällen müssen Daten jedoch während des Migrationsprozesses geändert werden. In der Regel sind Änderungen erforderlich, wenn sich das Schema oder die Datenwerte unterscheiden oder es Möglichkeiten zum Bereinigen von Daten während der Übertragung gibt.
In den folgenden Abschnitten werden verschiedene Arten von Änderungen beschrieben, die bei einer Datenmigration erforderlich sein können: Datentransformation, Datenanreicherung oder -korrelation und Datenreduzierung oder -filterung.
Datentransformation
Bei der Datentransformation werden einige oder alle Datenwerte aus der Quelldatenbank umgewandelt. Einige Beispiele:
- Datentyptransformation: Manchmal sind die Datentypen zwischen den Quell- und Zieldatenbanken nicht identisch. In diesen Fällen wandelt die Datentyptransformation den Quellwert gemäß Typtransformationsregeln in den Zielwert um. Beispielsweise kann ein Zeitstempeltyp aus der Quelle in einen String im Ziel umgewandelt werden.
- Datenstrukturtransformation: Die Datenstrukturtransformation ändert die Struktur im selben Datenbankmodell oder zwischen verschiedenen Datenbankmodellen. In einem relationalen System könnte beispielsweise eine Quelltabelle in zwei Zieltabellen aufgeteilt werden. Außerdem könnten mehrere Quelltabellen mithilfe eines Joins zu einer einzigen Zieltabelle denormalisiert werden. Eine 1:n-Beziehung in der Quelldatenbank ließe sich in eine Beziehung mit über- und untergeordneten Elementen in Spanner umwandeln. Dokumente aus einem Quelldatenbanksystem für Dokumente könnten in einen Satz relationaler Zeilen in einem Zielsystem aufgeteilt werden.
- Datenwerttransformation: Die Datenwerttransformation ist von der Datentyptransformation getrennt. Bei der Datenwerttransformation wird der Wert geändert, ohne den Datentyp zu ändern. Eine lokale Zeitzone wird beispielsweise in die koordinierte Weltzeit (Coordinated Universal Time, UTC) umgewandelt. Oder eine als String dargestellte kurze US-amerikanische Postleitzahl (fünf Ziffern) wird in eine lange Postleitzahl umgewandelt (fünf Ziffern gefolgt von einem Bindestrich gefolgt von vier Ziffern, auch ZIP+4 genannt).
Datenanreicherung und -korrelation
Die Datentransformation wird auf die vorhandenen Daten ohne Bezug auf zusätzliche, verwandte Referenzdaten angewendet. Bei der Datenanreicherung werden zusätzliche Daten abgefragt, um Quelldaten anzureichern, bevor sie in der Zieldatenbank gespeichert werden.
- Datenkorrelation: Es ist möglich, Quelldaten zu korrelieren. Zum Beispiel lassen sich Daten aus zwei Tabellen in zwei Quelldatenbanken kombinieren. So könnten Sie in einer Zieldatenbank einen Kunden mit allen offenen, erledigten und stornierten Bestellungen in Beziehung setzen, wobei die Kundendaten und die Bestelldaten aus zwei verschiedenen Quelldatenbanken stammen.
- Datenanreicherung: Bei der Datenanreicherung werden Referenzdaten hinzugefügt. Sie könnten beispielsweise Datensätze anreichern, die nur eine Postleitzahl enthalten, und dafür den Namen der Stadt hinzufügen, die der Postleitzahl entspricht. Eine Referenztabelle mit Postleitzahlen und den entsprechenden Städtenamen ist ein statisches Dataset, auf das für diesen Anwendungsfall zugegriffen wird. Referenzdaten können auch dynamisch sein. Sie könnten beispielsweise eine Liste aller bekannten Kunden als Referenzdaten verwenden.
Datenreduzierung und -filterung
Eine weitere Art der Datentransformation besteht darin, die Quelldaten vor der Migration in eine Zieldatenbank zu reduzieren oder zu filtern.
- Datenreduzierung: Bei der Datenreduzierung werden Attribute aus einem Datenelement entfernt. Wenn beispielsweise eine Postleitzahl in einem Datenelement vorhanden ist, könnte der entsprechende Name der Stadt überflüssig sein und gelöscht werden, da er neu berechnet werden kann oder nicht mehr benötigt wird. Manchmal werden diese Informationen aus historischen Gründen aufbewahrt, um den vom Nutzer eingegebenen Namen der Stadt aufzuzeichnen, auch wenn sich der Name der Stadt im Laufe der Zeit ändert.
- Datenfilterung: Bei der Datenfilterung wird ein Datenelement vollständig entfernt. Beispielsweise könnten alle stornierten Bestellungen entfernt und nicht in die Zieldatenbank übertragen werden.
Datenkombination oder -neukombination
Wenn Daten aus verschiedenen Quelldatenbanken in verschiedene Zieldatenbanken migriert werden, kann es erforderlich sein, Daten zwischen Quell- und Zieldatenbanken anders zu kombinieren.
Angenommen, Kunden und Bestellungen werden in zwei verschiedenen Quelldatenbanken gespeichert. Eine Quelldatenbank enthält alle Bestellungen und eine zweite Quelldatenbank alle Kunden. Nach der Migration werden Kunden und ihre Bestellungen in einer 1:n-Beziehung in einem einzigen Zieldatenbankschema gespeichert. Allerdings nicht in einer einzigen Zieldatenbank, sondern in mehreren Zieldatenbanken, wobei jede eine Partition der Daten enthält. Jede Zieldatenbank stellt eine Region dar und enthält alle Kunden und deren Bestellungen in dieser Region.
Adressierung der Zieldatenbank
Sofern nicht nur eine Zieldatenbank vorhanden ist, muss jedes migrierte Datenelement an die richtige Zieldatenbank gesendet werden. Es gibt mehrere Ansätze zur Adressierung der Zieldatenbank, darunter folgende:
- Schemabasierte Adressierung: Bei der schemabasierten Adressierung wird die Zieldatenbank anhand des Schemas bestimmt. Beispiel: Alle Datenelemente einer Kundensammlung oder alle Zeilen einer Kundentabelle werden in dieselbe Zieldatenbank zum Speichern von Kundeninformationen migriert, obwohl diese Informationen auf mehrere Quelldatenbanken verteilt waren.
- Inhaltsbasiertes Routing: Beim inhaltsbasierten Routing (z. B. mit einem inhaltsbasierten Router) wird die Zieldatenbank anhand von Datenwerten bestimmt. Beispiel: Alle Kunden in der Region Lateinamerika werden in eine bestimmte Zieldatenbank migriert, die diese Region darstellt.
Sie können bei einer Datenbankmigration beide Adressierungsarten gleichzeitig verwenden. Unabhängig von der verwendeten Adressierungsart muss die Zieldatenbank das richtige Schema haben, damit Datenelemente gespeichert werden.
Persistenz von Daten während der Übertragung
Während einer Migration können Datenbank-Migrationssysteme oder die Umgebungen, in denen sie ausgeführt werden, ausfallen und damit Daten bei der Übertragung verloren gehen. Wenn Fehler auftreten, müssen Sie das Datenbank-Migrationssystem neu starten und dafür sorgen, dass die in der Quelldatenbank gespeicherten Daten konsistent und vollständig in die Zieldatenbanken migriert werden.
Im Rahmen der Wiederherstellung muss das Datenbank-Migrationssystem das zuletzt erfolgreich migrierte Datenelement identifizieren, um zu bestimmen, wo mit dem Extrahieren aus den Quelldatenbanken begonnen werden soll. Damit der Vorgang an der Fehlerstelle fortgesetzt werden kann, muss das System einen internen Status zum Migrationsfortschritt unterhalten.
Der Status lässt sich auf verschiedene Arten verwalten:
- Sie können alle extrahierten Datenelemente im Datenbank-Migrationssystem speichern, bevor irgendwelche Datenbankänderungen stattfinden, und dann das jeweilige Datenelement entfernen, sobald die geänderte Version erfolgreich in der Zieldatenbank gespeichert wurde. Dieser Ansatz gewährleistet, dass das Datenbank-Migrationssystem genau bestimmen kann, was extrahiert und gespeichert wird.
- Sie können eine Liste von Verweisen auf die in Übertragung befindlichen Datenelemente verwalten. Eine Möglichkeit besteht darin, die Primärschlüssel oder andere eindeutige Kennungen jedes Datenelements zusammen mit einem Statusattribut zu speichern. Nach einem Fehler ist dieser Status die Grundlage für die konsistente Wiederherstellung des Systems.
- Sie können die Quell- und Zieldatenbanken nach einem Fehler abfragen, um den Unterschied zwischen den Quell- und Zieldatenbanksystemen zu ermitteln. Das nächste zu extrahierende Datenelement wird anhand des Unterschieds bestimmt.
Andere Ansätze zum Verwalten des Status können von den jeweiligen Quelldatenbanken abhängen. Beispielsweise kann ein Datenbank-Migrationssystem verfolgen, welche Transaktionslogeinträge aus der Quelldatenbank abgerufen und welche in die Zieldatenbank eingefügt werden. Wenn ein Fehler auftritt, kann die Migration ab dem letzten erfolgreich eingefügten Eintrag neu gestartet werden.
Die Persistenz von Daten während der Übertragung ist auch aus anderen Gründen als Fehlern oder Ausfällen wichtig. Vielleicht ist es beispielsweise nicht möglich, Daten aus der Quelldatenbank abzurufen, um ihren Status zu bestimmen. Wenn in der Quelldatenbank etwa eine Warteschlange enthalten war, könnten die Nachrichten in dieser Warteschlange irgendwann entfernt worden sein.
Ein weiterer Anwendungsfall für die Persistenz von Daten während der Übertragung ist die Verarbeitung von Daten in großen Zeitfenstern. Während der Datenänderung können Datenelemente unabhängig voneinander umgewandelt werden. Gelegentlich hängt die Datenänderung jedoch von mehreren Datenelementen ab (z. B. Nummerierung der pro Tag verarbeiteten Datenelemente, beginnend bei null pro Tag).
Ein letzter Anwendungsfall für die Persistenz von Daten während der Übertragung besteht darin, die Wiederholbarkeit der Daten während der Datenänderung zu gewährleisten, falls das Datenbanksystem nicht mehr auf die Quelldatenbanken zugreifen kann. Vielleicht müssen Sie beispielsweise die Datenänderungen mit anderen Änderungsregeln noch einmal ausführen und dann die Ergebnisse prüfen und mit den ursprünglichen Datenänderungen vergleichen. Dieser Ansatz kann erforderlich sein, wenn Sie aufgrund einer falschen Datenänderung Inkonsistenzen in der Zieldatenbank verfolgen müssen.
Vollständigkeits- und Konsistenzprüfung
Sie müssen die Datenbankmigration auf Vollständigkeit und Konsistenz prüfen. Mit dieser Prüfung wird gewährleistet, dass jedes Datenelement nur einmal migriert wurde, die Datasets in den Quell- und Zieldatenbanken identisch sind und die Migration abgeschlossen ist.
Abhängig von den Datenänderungsregeln ist es möglich, dass ein Datenelement extrahiert, aber nicht in eine Zieldatenbank eingefügt wird. Aus diesem Grund ist der direkte Vergleich der Quell- und Zieldatenbanken kein verlässlicher Ansatz für die Prüfung auf Vollständigkeit und Konsistenz. Wenn das Datenbank-Migrationssystem jedoch die herausgefilterten Elemente verfolgt, können Sie die Quell- und Zieldatenbanken zusammen mit den gefilterten Elementen vergleichen.
Replikationsfunktion des Datenbankverwaltungssystems
Ein spezieller Anwendungsfall ergibt sich bei einer homogenen Migration, wenn die Zieldatenbank eine Kopie der Quelldatenbank ist. Insbesondere wenn die Schemas und die Datenwerte in den Quell- und Zieldatenbanken identisch sind und jede Quelldatenbank eine direkte Zuordnung (1:1) zu einer Zieldatenbank ist.
In diesem Fall können Sie die integrierte Replikationsfunktion der meisten Datenbankverwaltungssysteme verwenden, um eine Datenbank in eine andere zu replizieren.
Es gibt zwei Arten von Datenreplizierung: logisch und physisch.
Logische Replikation: Bei der logischen Replikation werden Änderungen an Datenbankobjekten basierend auf ihren Replikations-IDs (in der Regel Primärschlüssel) übertragen. Der Vorteil der logischen Replikation besteht darin, dass sie flexibel und detailliert ist und angepasst werden kann. In einigen Fällen können Sie mithilfe der logischen Replikation Änderungen zwischen verschiedenen Datenbankmodulversionen replizieren. Viele Datenbank-Engines unterstützen logische Replikationsfilter, mit denen Sie die zu replizierenden Daten angeben können. Die Hauptnachteile bestehen darin, dass die logische Replikation zu einem gewissen Leistungsaufwand führen kann und die Latenz dieser Replikationsmethode in der Regel höher ist als die der physischen Replikation.
Physische Replikation: Die physische Replikation funktioniert dagegen auf Blockebene und bietet eine bessere Leistung bei niedrigerer Replikationslatenz. Bei großen Datensätzen kann die physische Replikation einfacher und effizienter sein, insbesondere bei nicht relationalen Datenstrukturen. Sie ist jedoch nicht anpassbar und hängt stark von der Version der Datenbank-Engine ab.
Beispiele hierfür sind die MySQL-Replikation, PostgreSQL-Replikation (siehe auch pglogical) oder Microsoft SQL Server-Replikation.
Wenn jedoch Daten geändert werden müssen oder eine andere Kardinalität als eine direkte Zuordnung vorliegt, sind die Funktionen eines Systems zur Datenbankmigration für einen solchen Anwendungsfall erforderlich.
Benutzerdefinierte Datenbankmigrationsfunktionen
Im Folgenden finden Sie einige Gründe, die für das Erstellen eigener Datenbank-Migrationsfunktionen sprechen, anstatt die Funktionen eines Datenbank-Migrationssystems oder Datenbank-Verwaltungssystems zu verwenden:
- Sie benötigen volle Kontrolle über jedes Detail.
- Sie möchten die Funktionen zur Datenbankmigration wiederverwenden.
- Sie möchten die Kosten senken oder Ihre technologische Landschaft vereinfachen.
Zu den Bausteinen für das Erstellen von Migrationsfunktionen gehören:
- Export und Import: Wenn Ausfallzeiten keine Rolle spielen, können Sie den Datenbankexport und -import verwenden, um Daten in homogenen Datenbankmigrationen zu migrieren. Beim Export/Import müssen Sie jedoch die Quelldatenbank stilllegen, um Aktualisierungen vor dem Export der Daten zu verhindern. Andernfalls werden Änderungen im Export möglicherweise nicht erfasst und die Zieldatenbank ist dann keine exakte Kopie der Quelldatenbank.
- Sicherung und Wiederherstellung: Wie beim Export und Import kommt es bei der Sicherung und Wiederherstellung zu Ausfallzeiten, da Sie die Quelldatenbank stilllegen müssen, damit die Sicherung alle Daten und die letzten Änderungen enthält. Die Ausfallzeit dauert so lange, bis die Wiederherstellung in der Zieldatenbank erfolgreich abgeschlossen wurde.
- Differenzielle Abfragen: Wenn das Ändern des Datenbankschemas eine Option ist, können Sie das Schema so erweitern, dass Datenbankänderungen über die Abfrageschnittstelle abgefragt werden können. Zu diesem Zweck wird ein zusätzliches Zeitstempelattribut eingefügt, das den Zeitpunkt der letzten Änderung angibt. Ein weiteres Lösch-Flag kann hinzugefügt werden, um anzugeben, ob das Datenelement gelöscht wird oder nicht (logisches Löschen). Mit diesen beiden Änderungen kann ein regelmäßig ausgeführter Abfragedienst alle Änderungen seit seiner letzten Ausführung abfragen. Die Änderungen werden auf die Zieldatenbank angewendet. Weitere Ansätze werden unter Change Data Capture erläutert.
Dies sind nur einige der möglichen Optionen zum Erstellen einer benutzerdefinierten Datenbankmigration. Obwohl eine benutzerdefinierte Lösung die größte Flexibilität und Kontrolle über die Implementierung bietet, erfordert sie auch eine ständige Wartung, um Fehler, Skalierbarkeitsbeschränkungen und andere Probleme zu beheben, die während einer Datenbankmigration auftreten können.
Weitere Überlegungen zur Datenbankmigration
In den folgenden Abschnitten werden nicht funktionale Aspekte, die im Zusammenhang mit der Datenbankmigration wichtig sind, kurz besprochen. Zu diesen Aspekten gehören Fehlerbehandlung, Skalierbarkeit, Hochverfügbarkeit und Notfallwiederherstellung.
Fehlerbehandlung
Fehler während der Datenbankmigration dürfen nicht zu Datenverlusten oder einer Verarbeitung von Datenbankänderungen in der falschen Reihenfolge führen. Die Datenintegrität muss unabhängig von der Ursache des Fehlers (z. B. Programmfehler im System, Netzwerkunterbrechung, VM-Absturz oder Zonenausfall) gewahrt werden.
Ein Datenverlust tritt auf, wenn ein Migrationssystem die Daten aus den Quelldatenbanken abruft und aufgrund eines Fehlers nicht in den Zieldatenbanken speichert. Wenn Daten verloren gehen, stimmen die Zieldatenbanken nicht mit den Quelldatenbanken überein und sind daher inkonsistent und unvollständig. Die Funktion zur Vollständigkeits- und Konsistenzprüfung meldet diesen Status (Vollständigkeits- und Konsistenzprüfung).
Skalierbarkeit
Bei einer Datenbankmigration ist die Migrationszeit ein wichtiger Messwert. Bei einer Migration ohne Ausfallzeit (im Sinne einer minimalen Ausfallzeit) erfolgt die Migration der Daten, während sich die Quelldatenbanken weiterhin ändern. Damit die Migration innerhalb eines angemessenen Zeitrahmens abgeschlossen ist, muss die Datenübertragungsrate deutlich höher sein als die Aktualisierungsrate der Quelldatenbanksysteme, insbesondere wenn das Quelldatenbanksystem groß ist. Je höher die Übertragungsrate ist, desto schneller kann die Datenbankmigration abgeschlossen werden.
Wenn die Quelldatenbanksysteme stillgelegt sind und nicht geändert werden, verläuft die Migration möglicherweise schneller, da keine Änderungen eingebunden werden müssen. In einer homogenen Datenbank kann die Migrationszeit sehr kurz sein, da Sie Sicherungs-/Wiederherstellungs- oder Export-/Importfunktionen verwenden können und die Übertragung von Dateien skaliert wird.
Hochverfügbarkeit und Notfallwiederherstellung
Im Allgemeinen sind Quell- und Zieldatenbanken für Hochverfügbarkeit konfiguriert. Eine primäre Datenbank hat ein entsprechendes Lesereplikat, das bei einem Fehler zur primären Datenbank hochgestuft wird.
Wenn eine Zone ausfällt, wird für die Quell- oder Zieldatenbanken ein Failover auf eine andere Zone ausgeführt, um kontinuierlich verfügbar zu sein. Bei einem Zonenausfall während einer Datenbankmigration ist das Migrationssystem selbst betroffen, da mehrere Quell- oder Zieldatenbanken, auf die es zugreift, nicht mehr zugänglich sind. Das Migrationssystem muss eine Verbindung zu den neu hochgestuften primären Datenbanken herstellen, die nach einem Fehler ausgeführt werden. Sobald das Datenbank-Migrationssystem wieder verbunden ist, muss es die Migration selbst wiederherstellen, um die Vollständigkeit und Konsistenz der Daten in den Zieldatenbanken zu gewährleisten. Das Migrationssystem muss die letzte konsistente Übertragung ermitteln, um zu bestimmen, wo die Migration fortgesetzt werden soll.
Fällt das Datenbank-Migrationssystem selbst aus (z. B. wenn die Zone, in der es ausgeführt wird, nicht mehr zugänglich ist), muss es wiederhergestellt werden. Ein Ansatz zur Wiederherstellung ist ein Kaltstart. Bei diesem Ansatz wird das Datenbank-Migrationssystem in einer funktionsfähigen Zone installiert und neu gestartet. Das größte zu bewältigende Problem besteht darin, dass das Migrationssystem in der Lage sein muss, die letzte konsistente Datenübertragung vor dem Fehler zu bestimmen und von diesem Punkt aus fortzufahren, um die Vollständigkeit und Konsistenz der Daten in den Zieldatenbanken zu gewährleisten.
Wenn Hochverfügbarkeit für das Datenbank-Migrationssystem aktiviert ist, kann es ein Failover ausführen und die Verarbeitung anschließend fortsetzen. Falls die Begrenzung der Ausfallzeit des Datenbank-Migrationssystems wichtig ist, müssen Sie eine Datenbank auswählen und Hochverfügbarkeit implementieren.
In Bezug auf die Wiederherstellung der Datenbankmigration ist die Notfallwiederherstellung der Hochverfügbarkeit sehr ähnlich. Anstatt eine Verbindung zu neu hochgestuften primären Datenbanken in einer anderen Zone herzustellen, muss das Datenbank-Migrationssystem eine Verbindung zu Datenbanken in einer anderen Region (einer Failover-Region) herstellen. Dies gilt auch für das Datenbank-Migrationssystem selbst. Wenn die Region, in der das Datenbank-Migrationssystem ausgeführt wird, nicht mehr zugänglich ist, muss das Datenbank-Migrationssystem per Failover auf eine andere Region übergehen und ab der letzten konsistenten Datenübertragung fortfahren.
Häufige Stolperfallen
Mehrere Stolperfallen können zu inkonsistenten Daten in den Zieldatenbanken führen. Hier sind einige, die häufig vorkommen und zu vermeiden sind:
- Falsche Reihenfolge: Wenn die Skalierbarkeit des Migrationssystems über horizontale Skalierung realisiert wird, werden mehrere Datenübertragungsprozesse gleichzeitig (parallel) ausgeführt. Änderungen in einem Quelldatenbanksystem werden nach den für Transaktionen durchgeführten Commits geordnet. Wenn Änderungen aus dem Transaktionslog übernommen werden, muss die Reihenfolge während der gesamten Migration beibehalten werden. Die parallele Datenübertragung kann die Reihenfolge ändern, da die Geschwindigkeit der zugrunde liegenden Prozesse variiert. Sie müssen unbedingt dafür sorgen, dass die Daten in derselben Reihenfolge wie sie aus den Quelldatenbanken eingehen in die Zieldatenbanken eingefügt werden.
- Keine Konsistenz: Bei differenziellen Abfragen haben die Quelldatenbanken zusätzliche Datenattribute, die beispielsweise Commit-Zeitstempel enthalten. Die Zieldatenbanken haben keine Commit-Zeitstempel, da die Commit-Zeitstempel nur implementiert werden, um das Änderungsmanagement in den Quelldatenbanken einzurichten. Es ist also wichtig, dass Einfügevorgänge in die Zieldatenbank konsistent in Bezug auf die Zeitstempel sind. Das bedeutet, dass sich alle Änderungen mit demselben Zeitstempel in derselben Insert-, Update- oder Upsert-Transaktion befinden müssen. Andernfalls ist der Zustand der Zieldatenbank möglicherweise (vorübergehend) inkonsistent, wenn einige Änderungen eingefügt werden und andere mit demselben Zeitstempel nicht. Dieser temporäre inkonsistente Zustand spielt keine Rolle, wenn auf die Zieldatenbanken nicht zur Verarbeitung zugegriffen wird. Wenn sie jedoch zu Testzwecken verwendet werden, ist Konsistenz von größter Bedeutung. Ein weiterer Aspekt ist die Erstellung der Zeitstempelwerte in der Quelldatenbank und ihrer Beziehung zum Commit-Zeitpunkt der Transaktion, in der sie festgelegt werden. Aufgrund von Commit-Abhängigkeiten kann eine Transaktion mit einem früheren Zeitstempel nach einer Transaktion mit einem späteren Zeitstempel sichtbar werden. Wenn eine differenzielle Abfrage zwischen den beiden Transaktionen ausgeführt wird, wird die Transaktion mit dem früheren Zeitstempel nicht angezeigt. Dies führt zu einer Inkonsistenz in der Zieldatenbank.
- Fehlende oder doppelte Daten: Bei einem Failover ist eine präzise Wiederherstellung erforderlich, wenn einige Daten nicht zwischen dem primären und dem Failover-Replikat repliziert werden. Beispiel: Für eine Quelldatenbank wird ein Failover ausgeführt und nicht alle Daten werden auf das Failover-Replikat repliziert. Gleichzeitig werden die Daten bereits vor dem Fehler in die Zieldatenbank migriert. Nach dem Failover liegt die neu hochgestufte primäre Datenbank in Bezug auf Datenänderungen hinter der Zieldatenbank zurück (sogenanntes Flashback). Ein Migrationssystem muss diese Situation erkennen und die Wiederherstellung so ausführen, dass die Zieldatenbank und die Quelldatenbank wieder in einen konsistenten Zustand versetzt werden.
- Lokale Transaktionen: Damit die Quell- und Zieldatenbanken dieselben Änderungen erhalten, besteht ein üblicher Ansatz darin, dass Clients sowohl in die Quell- als auch die Zieldatenbanken schreiben, anstatt ein Datenmigrationssystem zu verwenden. Dieser Ansatz birgt einige Stolperfallen. Ein Problem besteht darin, dass zwei Datenbank-Schreibvorgänge zwei separate Transaktionen sind. Nach Abschluss des ersten Vorgangs und vor dem Start des zweiten kann es zu einem Fehler kommen. Dieses Szenario führt zu inkonsistenten Daten, was eine Wiederherstellung erforderlich macht. Außerdem gibt es im Allgemeinen mehrere Clients, die nicht koordiniert sind. Die Clients kennen die Commit-Reihenfolge der Transaktionen in der Quelldatenbank nicht und können daher nicht unter Berücksichtigung dieser Transaktionsreihenfolge in die Zieldatenbanken schreiben. Möglicherweise ändern die Clients die Reihenfolge, was Dateninkonsistenzen zur Folge haben kann. Sofern nicht alle Zugriffe über koordinierte Clients erfolgen und alle Clients die Zieltransaktionsreihenfolge wahren, kann dieser Ansatz zu einem inkonsistenten Zustand in der Zieldatenbank führen.
Grundsätzlich gibt es noch andere Stolperfallen, auf die Sie achten müssen. Die beste Möglichkeit zum Erkennen von Problemen, die zu Dateninkonsistenzen führen können, ist die Ausführung einer vollständigen Fehleranalyse, die alle möglichen Fehlerszenarien durchläuft. Wenn im Datenbank-Migrationssystem Gleichzeitigkeit implementiert ist, müssen alle möglichen Ausführungsreihenfolgen von Datenmigrationsprozessen untersucht werden, um für die Wahrung der Datenkonsistenz zu sorgen. Wenn Hochverfügbarkeit oder Notfallwiederherstellung (oder beides) implementiert ist, müssen alle möglichen Fehlerkombinationen untersucht werden.
Nächste Schritte
- Datenbankmigration: Konzepte und Prinzipien (Teil 2) lesen
- Mehr über die Datenbankmigration in folgenden Dokumenten erfahren:
- Weitere Anleitungen zur Datenbankmigration unter Datenbankmigration durchsehen
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center