Praktik terbaik penskalaan untuk Cloud Service Mesh di GKE
Panduan ini menjelaskan praktik terbaik untuk menyelesaikan masalah penskalaan untuk arsitektur Cloud Service Mesh terkelola di Google Kubernetes Engine. Tujuan utama rekomendasi ini adalah untuk memastikan performa, keandalan, dan pemanfaatan resource yang optimal untuk aplikasi microservice Anda seiring dengan pertumbuhannya.
Untuk memahami batasan pada skalabilitas, lihat Batas skalabilitas Cloud Service Mesh
Skalabilitas Cloud Service Mesh di GKE bergantung pada operasi yang efisien dari dua komponen utamanya, yaitu bidang data dan bidang kontrol. Dokumen ini terutama berfokus pada penskalaan bidang data.
Mengidentifikasi masalah penskalaan bidang kontrol versus bidang data
Di Cloud Service Mesh, masalah penskalaan dapat terjadi di bidang kontrol atau bidang data. Berikut cara mengidentifikasi jenis masalah penskalaan yang Anda hadapi:
Gejala masalah penskalaan bidang kontrol
Penemuan layanan yang lambat: Layanan atau endpoint baru membutuhkan waktu lama untuk ditemukan dan tersedia.
Penundaan konfigurasi: Perubahan pada aturan pengelolaan traffic atau kebijakan keamanan memerlukan waktu yang lama untuk diterapkan.
Peningkatan latensi dalam operasi bidang kontrol: Operasi seperti membuat, memperbarui, atau menghapus resource Cloud Service Mesh menjadi lambat atau tidak responsif.
Error terkait Traffic Director: Anda mungkin melihat error di log Cloud Service Mesh atau metrik bidang kontrol yang menunjukkan masalah pada konektivitas, kehabisan resource, atau pembatasan API.
Cakupan dampak: Masalah bidang kontrol biasanya memengaruhi seluruh mesh, menyebabkan penurunan performa yang meluas.
Gejala masalah penskalaan bidang data
Peningkatan latensi dalam komunikasi antar-layanan: Permintaan ke layanan dalam mesh mengalami latensi atau waktu tunggu yang lebih tinggi, tetapi tidak ada peningkatan penggunaan CPU/memori dalam container layanan.
Penggunaan CPU atau memori yang tinggi di proxy Envoy: Penggunaan CPU atau memori yang tinggi dapat menunjukkan bahwa proxy kesulitan menangani beban traffic.
Dampak yang dilokalkan: Masalah bidang data biasanya memengaruhi layanan atau workload tertentu, bergantung pada pola traffic dan pemanfaatan resource proxy Envoy.
Menskalakan bidang data
Untuk menskalakan bidang data, coba teknik berikut:
- Mengonfigurasi penskalaan otomatis pod horizontal (HPA)
- Mengoptimalkan konfigurasi proxy envoy
- Memantau dan menyesuaikan
Mengonfigurasi Penskalaan Otomatis Pod Horizontal (HPA) untuk workload
Gunakan Horizontal Pod Autoscaling (HPA) untuk menskalakan workload secara dinamis dengan pod tambahan berdasarkan penggunaan resource. Pertimbangkan hal berikut saat mengonfigurasi HPA:
Gunakan parameter
--horizontal-pod-autoscaler-sync-perioduntukkube-controller-managerguna menyesuaikan kecepatan polling pengontrol HPA. Rasio polling default adalah 15 detik dan Anda dapat mempertimbangkan untuk menyetelnya lebih rendah jika Anda memperkirakan lonjakan traffic yang lebih cepat. Untuk mempelajari lebih lanjut kapan harus menggunakan HPA dengan GKE, lihat Penskalaan otomatis Pod horizontal.Perilaku penskalaan default dapat menyebabkan sejumlah besar pod di-deploy (atau dihentikan) sekaligus, yang dapat menyebabkan lonjakan penggunaan resource. Pertimbangkan untuk menggunakan kebijakan penskalaan untuk membatasi kecepatan deployment pod.
Gunakan EXIT_ON_ZERO_ACTIVE_CONNECTIONS untuk menghindari terputusnya koneksi selama penskalaan ke bawah.
Untuk mengetahui detail selengkapnya tentang HPA, lihat Penskalaan Otomatis Pod Horizontal dalam dokumentasi Kubernetes.
Mengoptimalkan Konfigurasi Proxy Envoy
Untuk mengoptimalkan konfigurasi proxy Envoy, pertimbangkan rekomendasi berikut:
Batas resource
Anda dapat menentukan permintaan dan batas resource untuk sidecar Envoy dalam spesifikasi Pod. Hal ini mencegah perebutan resource dan memastikan performa yang konsisten.
Anda juga dapat mengonfigurasi batas resource default untuk semua proxy Envoy di mesh menggunakan anotasi resource.
Batas resource optimal untuk proxy Envoy Anda bergantung pada faktor-faktor seperti volume traffic, kompleksitas workload, dan resource node GKE. Terus pantau dan sesuaikan mesh layanan Anda untuk memastikan performa yang optimal.
Pertimbangan Penting:
- Kualitas Layanan (QoS): Menetapkan permintaan dan batas memastikan proxy Envoy Anda memiliki kualitas layanan yang dapat diprediksi.
Mencakup dependensi layanan
Pertimbangkan untuk memangkas grafik dependensi mesh Anda dengan mendeklarasikan semua dependensi Anda melalui Sidecar API. Hal ini membatasi ukuran dan kompleksitas konfigurasi yang dikirim ke beban kerja tertentu, yang sangat penting untuk mesh yang lebih besar.
Sebagai contoh, berikut adalah grafik traffic untuk aplikasi contoh butik online.
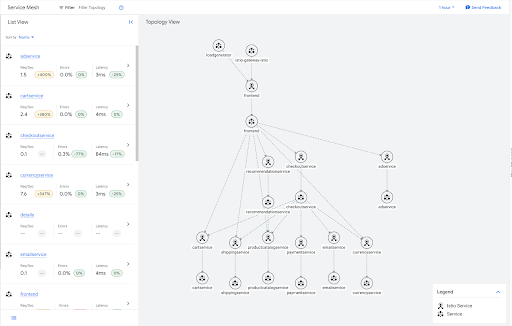
Banyak layanan ini merupakan leaf dalam grafik, dan oleh karena itu tidak memerlukan informasi keluar untuk layanan lain dalam mesh. Anda dapat menerapkan resource Sidecar yang membatasi cakupan konfigurasi sidecar untuk layanan leaf ini seperti yang ditunjukkan dalam contoh berikut.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: leafservices
namespace: default
spec:
workloadSelector:
labels:
app: cartservice
app: shippingservice
app: productcatalogservice
app: paymentservice
app: emailservice
app: currencyservice
egress:
- hosts:
- "~/*"
Lihat Contoh aplikasi Butik Online untuk mengetahui detail tentang cara men-deploy contoh aplikasi ini.
Manfaat lain dari cakupan sidecar adalah mengurangi kueri DNS yang tidak perlu. Mencakup dependensi layanan memastikan bahwa sidecar Envoy hanya membuat kueri DNS untuk layanan yang akan berkomunikasi dengannya, bukan setiap cluster di mesh layanan.
Untuk deployment skala besar yang menghadapi masalah dengan ukuran konfigurasi besar di sidecar, cakupan dependensi layanan sangat direkomendasikan untuk skalabilitas mesh.
Untuk membatasi cakupan konfigurasi untuk semua workload dalam satu namespace, buat satu resource Sidecar di namespace tersebut. Hal ini menginstruksikan semua proxy Envoy dalam namespace tersebut untuk hanya menerima konfigurasi layanan di namespace-nya sendiri.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: sidecar
namespace: my-app
spec:
egress:
- hosts:
- "my-app/*"
Anda dapat menerapkan perilaku default untuk setiap namespace di mesh dengan menerapkan satu resource Sidecar ke namespace root, biasanya istio-system.
Sidecar berikut membatasi traffic keluar setiap sidecar di mesh ke layanan yang berada dalam namespace-nya sendiri.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: sidear
namespace: istio-system
spec:
egress:
- hosts:
- "./*"
Perhatikan bahwa Cloud Service Mesh menerapkan batas pada jumlah total resource Sidecar yang dapat dibuat dalam satu mesh. Karena batasan ini, membuat Sidecar tingkat namespace adalah praktik yang direkomendasikan.
Memantau dan menyesuaikan
Setelah menetapkan batas resource awal, Anda harus memantau proxy Envoy untuk memastikan performanya optimal. Gunakan dasbor GKE untuk memantau penggunaan CPU dan memori serta menyesuaikan batas resource sesuai kebutuhan.
Untuk menentukan apakah proxy Envoy memerlukan peningkatan batas resource, pantau konsumsi resource-nya dalam kondisi traffic umum dan puncak. Berikut yang harus diperhatikan:
Penggunaan CPU Tinggi: Jika penggunaan CPU Envoy secara konsisten mendekati atau melampaui batasnya, Envoy mungkin kesulitan memproses permintaan, sehingga menyebabkan peningkatan latensi atau permintaan yang dibatalkan. Pertimbangkan untuk menaikkan batas CPU.
Anda mungkin cenderung melakukan penskalaan menggunakan penskalaan horizontal dalam kasus ini, tetapi jika proxy sidecar secara konsisten tidak dapat memproses permintaan secepat penampung aplikasi, menyesuaikan batas CPU dapat memberikan hasil terbaik.
Penggunaan Memori Tinggi: Jika penggunaan memori Envoy mendekati atau melampaui batasnya, Envoy dapat mulai menghentikan koneksi atau mengalami error kehabisan memori (OOM). Tingkatkan batas memori untuk mencegah masalah ini.
Log Error: Periksa log Envoy untuk mengetahui error terkait kelelahan resource, seperti error upstream connect error atau disconnect or reset before headers atau too many open files. Error ini dapat menunjukkan bahwa proxy memerlukan lebih banyak resource. Lihat dokumen pemecahan masalah penskalaan untuk mengetahui error lain yang terkait dengan masalah penskalaan.
Metrik Performa: Pantau metrik performa utama seperti latensi permintaan, tingkat error, dan throughput. Jika Anda melihat penurunan performa yang berkorelasi dengan penggunaan sumber daya yang tinggi, batas yang lebih tinggi mungkin diperlukan.
Dengan menetapkan dan memantau batas resource secara aktif untuk proxy bidang data, Anda dapat memastikan bahwa service mesh Anda diskalakan secara efisien di GKE.
Menskalakan bidang kontrol
Bagian ini menjelaskan setelan yang perlu disesuaikan untuk menskalakan bidang kontrol.
Pemilih penemuan
Pemilih penemuan adalah kolom di MeshConfig yang memungkinkan Anda menentukan kumpulan namespace yang dipertimbangkan bidang kontrol saat menghitung update konfigurasi untuk sidecar.
Secara default, Cloud Service Mesh memantau semua namespace di cluster. Hal ini dapat menjadi hambatan bagi cluster besar yang tidak perlu memantau semua resource.
Gunakan discoverySelectors untuk mengurangi beban komputasi pada bidang kontrol
dengan membatasi jumlah resource Kubernetes (seperti layanan, pod, dan
endpoint) yang dipantau dan diproses.
Saat menggunakan implementasi bidang kontrol TRAFFIC_DIRECTOR, Cloud Service Mesh hanya membuat resource Google Cloud , seperti Backend Service dan Network Endpoint Group, untuk resource Kubernetes di namespace yang ditentukan dalam discoverySelectors.
Untuk mengetahui informasi selengkapnya, lihat Pemilih penemuan dalam dokumentasi Istio.
Membangun ketahanan
Anda dapat menyesuaikan setelan berikut untuk membangun ketahanan di mesh layanan Anda:
Deteksi outlier
Deteksi pencilan memantau host di layanan upstream dan menghapusnya dari kumpulan load balancing setelah mencapai beberapa batas error.
- Konfigurasi Utama:
outlierDetection: Setelan yang mengontrol penghapusan host yang tidak responsif dari kumpulan load balancing.
- Manfaat: Mempertahankan kumpulan host yang responsif di kumpulan load balancing.
Untuk mengetahui informasi selengkapnya, lihat Deteksi Penyimpangan dalam dokumentasi Istio.
Upaya coba lagi
Kurangi error sementara dengan otomatis mencoba lagi permintaan yang gagal.
- Konfigurasi Utama:
attempts: Jumlah upaya percobaan ulang.perTryTimeout: Waktu tunggu per upaya percobaan ulang. Tetapkan waktu tunggu ini lebih singkat daripada waktu tunggu keseluruhan. Setelan ini menentukan durasi tunggu untuk setiap upaya percobaan ulang.retryBudget: Jumlah maksimum percobaan ulang serentak.
- Manfaat: Tingkat keberhasilan permintaan yang lebih tinggi, dampak kegagalan sesekali yang lebih kecil.
Faktor yang Perlu Dipertimbangkan:
- Idempoten: Pastikan operasi yang dicoba ulang bersifat idempoten, yang berarti dapat diulang tanpa efek samping yang tidak diinginkan.
- Percobaan Ulang Maksimum: Batasi jumlah percobaan ulang (misalnya, maksimum 3 percobaan ulang) untuk menghindari loop tanpa henti.
- Pemutus Rangkaian: Integrasikan percobaan ulang dengan pemutus rangkaian untuk mencegah percobaan ulang saat layanan terus gagal.
Untuk mengetahui informasi selengkapnya, lihat Upaya Coba Lagi dalam dokumentasi Istio.
Waktu tunggu
Gunakan waktu tunggu untuk menentukan waktu maksimum yang diizinkan untuk pemrosesan permintaan.
- Konfigurasi Utama:
timeout: Waktu tunggu permintaan habis untuk layanan tertentu.idleTimeout: Waktu koneksi dapat tetap tidak ada aktivitas sebelum ditutup.
- Manfaat: Peningkatan responsivitas sistem, pencegahan kebocoran resource, penguatan terhadap traffic berbahaya.
Faktor yang Perlu Dipertimbangkan:
- Latensi Jaringan: Perhitungkan waktu perjalanan pulang pergi (RTT) yang diharapkan antara layanan. Sisakan beberapa waktu untuk keterlambatan yang tidak terduga.
- Grafik Dependensi Layanan: Untuk permintaan berantai, pastikan waktu tunggu layanan panggilan lebih singkat daripada waktu tunggu kumulatif dependensinya untuk menghindari kegagalan berjenjang.
- Jenis Operasi: Tugas yang berjalan lama mungkin memerlukan waktu tunggu yang jauh lebih lama daripada pengambilan data.
- Penanganan Error: Waktu tunggu harus memicu logika penanganan error yang sesuai (misalnya, percobaan ulang, penggantian, penghentian sirkuit).
Untuk mengetahui informasi selengkapnya, lihat Waktu tunggu dalam dokumentasi Istio.
Memantau dan menyesuaikan
Pertimbangkan untuk memulai dengan setelan default untuk waktu tunggu, deteksi pencilan, dan percobaan ulang, lalu sesuaikan secara bertahap berdasarkan persyaratan layanan spesifik dan pola traffic yang diamati. Misalnya, lihat data dunia nyata tentang berapa lama waktu yang biasanya diperlukan layanan Anda untuk merespons. Kemudian, sesuaikan waktu tunggu agar sesuai dengan karakteristik spesifik setiap layanan atau endpoint.
Telemetri
Gunakan telemetri untuk terus memantau mesh layanan dan menyesuaikan konfigurasinya untuk mengoptimalkan performa dan keandalan.
- Metrik: Gunakan metrik yang komprehensif, khususnya, volume permintaan, latensi, dan tingkat error. Integrasikan dengan Cloud Monitoring untuk visualisasi dan pemberitahuan.
- Pelacakan Terdistribusi: Aktifkan integrasi pelacakan terdistribusi dengan Cloud Trace untuk mendapatkan insight mendalam tentang alur permintaan di seluruh layanan Anda.
- Logging: Konfigurasi logging akses untuk merekam informasi mendetail tentang permintaan dan respons.
Bacaan Tambahan
- Untuk mempelajari Cloud Service Mesh lebih lanjut, lihat ringkasan Cloud Service Mesh.
- Untuk panduan umum site reliability engineering (SRE) tentang skalabilitas, lihat bab Menangani Kelebihan Beban dan Menangani Kegagalan Beruntun dalam buku Google SRE.