针对 GKE 上的 Cloud Service Mesh 的扩缩最佳实践
本指南介绍了在 Google Kubernetes Engine 上解决托管式 Cloud Service Mesh 架构的扩缩问题的最佳实践。这些建议的主要目标是确保您的微服务应用在不断发展时具有最佳性能、可靠性和资源利用率。
如需了解可扩缩性的限制,请参阅 Cloud Service Mesh 可扩缩性限制
GKE 上的 Cloud Service Mesh 的可扩缩性取决于其两个主要组件(数据平面和控制平面)是否高效运行。本文档主要介绍如何扩缩数据平面。
确定控制平面与数据平面扩缩问题
在 Cloud Service Mesh 中,控制平面或数据平面可能会出现扩缩问题。您可以通过以下方式确定自己遇到的扩缩问题类型:
控制平面扩缩问题的症状
服务发现速度缓慢:新服务或端点需要很长时间才能被发现并变为可用。
配置延迟:对流量管理规则或安全政策所做的更改需要很长时间才能传播。
控制平面操作延迟增加:创建、更新或删除 Cloud Service Mesh 资源等操作变慢或无响应。
与 Traffic Director 相关的错误:您可能会在 Cloud Service Mesh 日志或控制平面指标中看到错误,这些错误指示连接、资源耗尽或 API 节流方面存在问题。
影响范围:控制平面问题通常会影响整个网格,导致广泛的性能下降。
数据平面扩缩问题的症状
服务间通信的延迟时间增加:对网格内服务的请求延迟时间更长或出现超时,但服务的容器中的 CPU/内存用量没有增加。
Envoy 代理中的 CPU 或内存用量较高:CPU 或内存用量较高可能表示代理难以处理流量负载。
局部影响:数据平面问题通常会影响特定服务或工作负载,具体取决于 Envoy 代理的流量模式和资源利用率。
扩缩数据平面
如需扩缩数据平面,请尝试以下技术:
为工作负载配置 Pod 横向自动扩缩 (HPA)
使用 Pod 横向自动扩缩 (HPA),根据资源利用率通过添加额外 Pod 来动态扩缩工作负载。配置 HPA 时,请考虑以下事项:
使用
kube-controller-manager的--horizontal-pod-autoscaler-sync-period参数来调整 HPA 控制器的轮询速率。 默认轮询速率为 15 秒,如果您预计流量高峰会更快出现,可以考虑将其设置得更低。如需详细了解何时将 HPA 与 GKE 搭配使用,请参阅 Pod 横向自动扩缩。默认的扩缩行为可能会导致大量 Pod 同时部署(或终止),从而导致资源使用量激增。考虑使用扩缩政策来限制部署 Pod 的速率。
使用 EXIT_ON_ZERO_ACTIVE_CONNECTIONS 来避免在缩减期间丢弃连接。
如需详细了解 HPA,请参阅 Kubernetes 文档中的 Pod 横向自动扩缩部分。
优化 Envoy 代理配置
如需优化 Envoy 代理配置,请考虑以下建议:
资源限制
您可以在 Pod 规范中为 Envoy 边车定义资源请求和限制。这样可以避免资源争用,并确保性能一致。
您还可以使用资源注解为网格中的所有 Envoy 代理配置默认资源限制。
Envoy 代理的最佳资源限制取决于流量、工作负载复杂性和 GKE 节点资源等因素。持续监控和微调服务网格,以确保最佳性能。
重要的考虑因素:
- 服务质量 (QoS):同时设置请求和限制可确保 Envoy 代理具有可预测的服务质量。
限定服务依赖项范围
考虑通过 Sidecar API 声明所有依赖项来裁剪网格的依赖项图表。这会限制发送到给定工作负载的配置的大小和复杂性,这对于较大的网格来说至关重要。
例如,以下是在 Online Boutique 示例应用的流量图表。
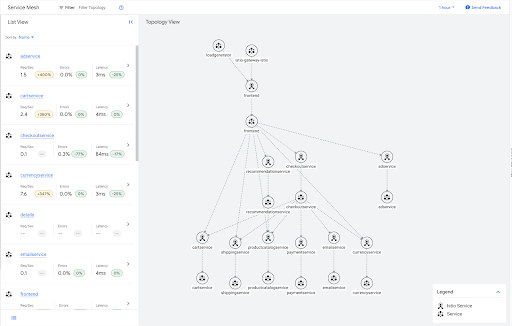
其中许多服务都是图表中的叶子,因此不需要网格中的任何其他服务的出站流量信息。您可以应用边车资源来限制这些叶子服务的边车配置范围,如以下示例所示。
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: leafservices
namespace: default
spec:
workloadSelector:
labels:
app: cartservice
app: shippingservice
app: productcatalogservice
app: paymentservice
app: emailservice
app: currencyservice
egress:
- hosts:
- "~/*"
如需详细了解如何部署此示例应用,请参阅 Online Boutique 示例应用。
边车限定范围另一个好处是减少不必要的 DNS 查询。 通过限定服务依赖项范围,可确保 Envoy 边车仅针对其实际通信的服务(而非服务网格中的每个集群)发出 DNS 查询。
对于面临边车中配置大小过大问题的任何大规模部署,强烈建议限定服务依赖项范围以提高网格可扩缩性。
如需限制单个命名空间内所有工作负载的配置范围,请在该命名空间中创建一个边车资源。这会指示该命名空间中的所有 Envoy 代理仅接收其自身命名空间中服务的配置。
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: sidecar
namespace: my-app
spec:
egress:
- hosts:
- "my-app/*"
您可以将单个边车资源应用于根命名空间(通常为 istio-system),从而为网格中的每个命名空间应用默认行为。
以下边车将网格中每个边车的出站流量限制为其自身命名空间中的服务。
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: sidear
namespace: istio-system
spec:
egress:
- hosts:
- "./*"
请注意,Cloud Service Mesh 对单个网格中可创建的边车资源总数施加了限制。由于此限制,建议的实践是创建命名空间级边车。
监控和微调
设置初始资源限制后,监控 Envoy 代理以确保其性能达到最佳状态至关重要。使用 GKE 信息中心来监控 CPU 和内存用量,并根据需要调整资源限制。
如需确定 Envoy 代理是否需要增加资源限制,请在典型流量和高峰流量条件下监控资源消耗。请注意以下事项:
CPU 使用率较高:如果 Envoy 的 CPU 使用率始终接近或超过限制,则可能难以处理请求,从而导致延迟时间增加或请求丢弃。考虑提高 CPU 限制。
在这种情况下,您可能倾向于使用横向缩容进行扩缩,但如果边车代理始终无法像应用容器那样快速处理请求,调整 CPU 限制可能会产生最佳效果。
内存用量较高:如果 Envoy 的内存用量接近或超过限制,可能会开始中断连接或遇到内存不足 (OOM) 错误。提高内存限制,以避免出现这些问题。
错误日志:检查 Envoy 的日志,查找与资源耗尽相关的错误,例如“上游连接错误”“在标头之前断开连接或重置”或“打开的文件过多”错误。这些错误可能表明代理需要更多资源。如需了解与扩缩问题相关的其他错误,请参阅扩缩问题排查文档。
性能指标:监控请求延迟时间、错误率和吞吐量等关键性能指标。如果您发现性能下降与高资源利用率相关,则可能需要提高限制。
通过主动为数据平面代理设置和监控资源限制,您可以确保您的服务网格在 GKE 上高效扩缩。
扩缩控制平面
本部分介绍了可调整的设置,以扩缩控制平面。
发现选择器
发现选择器是 MeshConfig 中的一个字段,可用于指定控制平面在计算边车的配置更新时考虑的命名空间集。
默认情况下,Cloud Service Mesh 会监控集群中的所有命名空间。对于不需要监控所有资源的大型集群,这可能会成为瓶颈。
使用 discoverySelectors 可限制所监控和处理的 Kubernetes 资源(例如服务、Pod 和端点)的数量,从而减少控制平面的计算负载。
使用 TRAFFIC_DIRECTOR 控制平面实现时,Cloud Service Mesh 仅会为 discoverySelectors 中指定的命名空间中的 Kubernetes 资源创建 Google Cloud 资源,例如后端服务和网络端点组。
如需了解详情,请参阅 Istio 文档中的发现选择器。
增强弹性
您可以调整以下设置,以在服务网格中构建弹性:
离群值检测
离群值检测会监控上游服务中的主机,并在达到某个错误阈值时将其从负载均衡池中移除。
- 主要配置:
outlierDetection:控制从负载均衡池中逐出健康状况不佳的主机的设置
- 优势:在负载均衡池中维护一组健康状况良好的主机。
如需了解详情,请参阅 Istio 文档中的离群值检测。
重试
通过自动重试失败的请求来缓解暂时性错误。
- 主要配置:
attempts:重试次数。perTryTimeout:每次重试的超时。将此值设置为低于您的总超时。它决定了您需要等待多长时间才能进行下一次重试。retryBudget:并发重试次数上限。
- 优势:提高请求成功率,减少间歇性故障的影响。
要考虑的因素:
- 幂等性:确保要重试的操作具有幂等性,也就是说,可以重复执行而不会产生意外副作用。
- 尝试次数上限:限制重试次数(例如,最多 3 次重试),以避免无限循环。
- 熔断:将重试与熔断器集成,以防止在服务持续失败时重试。
如需了解详情,请参阅 Istio 文档中的重试。
超时
使用超时来定义请求处理所允许的时间上限。
- 主要配置:
timeout:特定服务的请求超时。idleTimeout:连接在关闭前可以保持空闲状态的时间。
- 优势:提高系统响应速度、防止资源泄露、加强防范恶意流量。
要考虑的因素:
- 网络延迟时间:考虑服务之间的预期往返时间 (RTT)。为意外延误留出一些缓冲时间。
- 服务依赖项图表:对于链式请求,请确保调用服务的超时时间短于依赖项的累计超时时间,以避免发生级联故障。
- 操作类型:长时间运行的任务可能需要的超时时间比数据检索要长得多。
- 错误处理:超时应触发相应的错误处理逻辑(例如重试、回退、熔断)。
如需了解详情,请参阅 Istio 文档中的超时。
监控和微调
建议您先从超时、离群值检测和重试的默认设置开始,然后根据您的特定服务要求和观察到的流量模式逐步调整。例如,查看您的服务通常需要多长时间才能响应真实数据。然后调整超时,以匹配每项服务或端点的特定特征。
Telemetry
使用遥测数据持续监控服务网格并调整配置,以优化性能和可靠性。
- 指标:使用全面的指标,特别是请求量、延迟时间和错误率。与 Cloud Monitoring 集成,以实现可视化和提醒。
- 分布式跟踪:启用与 Cloud Trace 的分布式跟踪集成,以深入了解各项服务的请求流。
- 日志记录:配置访问日志记录以捕获有关请求和响应的详细信息。
附加阅读材料
- 如需详细了解 Cloud Service Mesh,请参阅 Cloud Service Mesh 概览。
- 如需了解有关可扩缩性的一般站点可靠性工程 (SRE) 指南,请参阅《Google SRE》一书中的处理过载和解决级联故障章节。