Migrate for Compute Engine 通过 Google Cloud Observability 提供迁移组件的指标。这些指标的类别包括:
- Migrate for Compute Engine 基础架构的运行状况
- 存储空间用量
- 网络用量
在 Google Cloud Observability 中查看指标
在 Google Cloud 控制台中,选择 Google Cloud Observability > Monitoring。
确认托管 Migrate for Compute Engine 基础设施的项目显示在 Google Cloud Observability 徽标的右侧。
在屏幕左侧,选择 Resources > Metrics Explorer。
对于 Resource Type,选择 Generic Node。
如果您的项目托管多个 Velostrata Manager,则您可以按 Namespace 进行 Filter。
从下拉列表中选择 Metric,或从以下列表中复制粘贴指标名称。
查找命名空间
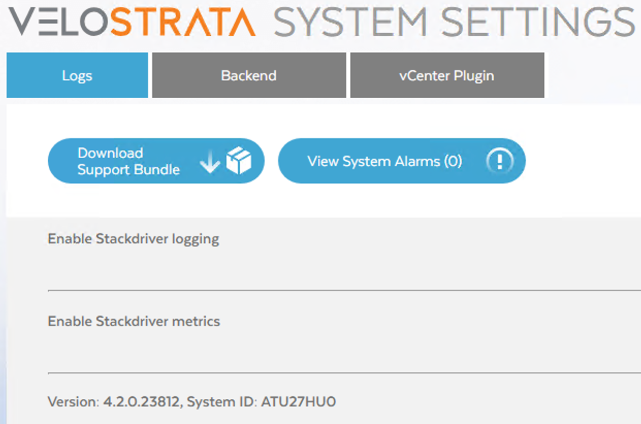
- 登录 Velostrata Manager
- 点击系统设置。
- 点击日志标签页。
- 命名空间即为页面底部系统 ID 后的值。
 。
。
附录:指标名称
| 类别 | Google Cloud Observability 指标名称 | 说明 |
|---|---|---|
| 磁盘用量 | scsi_target/data_access/received_command_count | Cloud Extensions 收到的命令 |
| 磁盘用量 | scsi_target/data_access/command_latency/avg | Cloud Extensions 执行的命令的平均延迟时间 |
| 磁盘用量 | scsi_target/data_access/total_bytes_count | Cloud Extensions 发送或接收的总字节数 |
| 磁盘用量 | scsi_target/usage/active_vms | Cloud Extensions 托管的活跃虚拟机数量 |
| 磁盘用量 | scsi_target/rpc/received_bytes_count | Cloud Extensions 接收的总字节数 |
| 磁盘用量 | scsi_target/rpc/sent_bytes_count | Cloud Extensions 发送的总字节数 |
| 磁盘用量 | scsi_target/remote_access/received_command_count | Cloud Extensions 接收的总命令数 |
| 磁盘用量 | scsi_target/remote_access/total_bytes_count | Cloud Extensions 从源平台读取的总字节数 |
| 网络运行状况 | network/pinger/latency/min | Cloud Extensions 发送的 Ping 的最短延迟时间 |
| 网络运行状况 | network/pinger/latency/avg | Cloud Extensions 发送的 Ping 的平均延迟时间 |
| 网络运行状况 | network/pinger/latency/max | Cloud Extensions 发送的 Ping 的最长延迟时间 |
| 网络运行状况 | network/pinger/failed_request_count | Cloud Extensions 发送的 Ping 的失败计数 |
| 系统运行状况 | healthchecks/healthcheck_severity | Cloud Extension 上健康检查的严重性 |
| Velostrata Manager | management/management_tasks/finished_count | 由 Velostrata Manager 启动的已完成任务的计数 |
| Velostrata Manager | management/management_tasks/failed_count | 由 Velostrata Manager 启动的失败任务的计数 |
| Velostrata Manager | management/management_tasks/duration_in_seconds/p50 | 由 Velostrata Manager 启动的任务的平均时长 |
| Velostrata Manager | management/management_tasks/duration_in_seconds/p95 | 由 Velostrata Manager 启动的任务的第 95 百分位时长 |
| Velostrata Manager | management/management_tasks/running_count | 由 Velostrata Manager 启动的当前正在运行的任务数 |
| Velostrata Manager | management/management_tasks/total_count | 由 Velostrata Manager 启动的任务总数 |
| Velostrata Manager | management/management_api_impl/failed_api_calls_count | 由 Velostrata Manager 启动的失败的 API 调用 |
| Velostrata Manager | management/cloud_provider/request_count | 由 Velostrata Manager 启动的向 GCP 发出的请求计数 |
| Velostrata Manager | management/cloud_provider/failed_request_count | 由 Velostrata Manager 启动的向 GCP 发出的失败请求计数 |
| Velostrata Manager | management/mux_connectivity/backend_reconnect_count | Velostrata 后端与 Velostrata Manager 之间的重新连接计数 |
| Velostrata Manager | system/cpu_utilization/used | Velostrata Manager 的 CPU 使用率 |
| Velostrata Manager | system/process/tomcat8/jvm/gct | 托管 Velostrata Manager 的 Tomcat JVM 的垃圾回收时间 |
| Velostrata Manager | system/service_start_count/management | Velostrata Manager 的停止/启动计数 |
| Velostrata Manager | healthchecks/healthcheck_severity | Velostrata Manager 上健康检查的严重性 |
| 后端 | read_storage_pool/concurrency | 对 Velostrata 后端读取存储池的并发请求 |
| 后端 | read_storage_pool/received_command_count | Velostrata 后端收到的命令 |
| 后端 | read_storage_pool/total_bytes_count | Velostrata 后端读取存储池读取的总字节数 |
| 后端 | read_storage_pool/failed_command_count | 失败的 Velostrata 后端读取存储池命令 |
| 后端 | read_storage_pool/high_latency/num_above_10000_ms | Velostrata 后端发出的需要 10 秒以上时间才能完成的请求计数 |
| 后端 | read_storage_pool/command_latency/avg | 发送到 Velostrata 后端读取存储池的平均延迟时间命令 |
| 后端 | vsphere/received_command_count | Velostrata 后端发送给 vSphere 的命令计数 |
| 后端 | vsphere/total_bytes_count | Velostrata 后端从 vSphere 读取的总字节数 |
| 后端 | vsphere/command_latency/avg | Velostrata 后端发送给 vSphere 的命令的平均延迟时间 |
| 后端 | rpc/received_bytes_count | Velostrata 后端从 Velostrata Manager 接收到的命令字节数 |
| 后端 | rpc/sent_bytes_count | Velostrata 后端从 Velostrata Manager 发送的命令字节数 |
| 后端 | system/service_start_count/backend | Velostrata 后端服务的停止/启动计数 |
| 后端 | healthchecks/healthcheck_severity | Velostrata 后端上健康检查的严重性。 |
| 后端 | vsphere/failed_command_count | Velostrata 后端发送给 vSphere 的失败命令计数 |