Le niveau Standard de Memorystore pour Redis permet de faire évoluer les requêtes de lecture de votre application à l'aide d'instances dupliquées avec accès en lecture. Dans cette page, nous partons du principe que vous connaissez les différentes fonctionnalités de niveau Redis de Memorystore.
Les instances dupliquées avec accès en lecture vous permettent de faire évoluer votre charge de travail de lecture en interrogeant les instances dupliquées. Un point de terminaison en lecture est fourni pour faciliter la distribution des requêtes entre les instances dupliquées par les applications. Pour en savoir plus, consultez la page Scaling des lectures avec un point de terminaison en lecture.
Pour savoir comment gérer une instance Redis avec des instances dupliquées avec accès en lecture, consultez la page Gérer les instances dupliquées avec accès en lecture.
Cas d'utilisation des instances dupliquées avec accès en lecture
Les magasins de sessions, les classements, les moteurs de recommandations et d'autres cas d'utilisation nécessitent que l'instance soit hautement disponible. Ces cas d'utilisation comptent beaucoup plus de lectures que d'écritures, et sont généralement capables de tolérer des lectures non actualisées. Dans de tels cas, il est judicieux d'utiliser des instances dupliquées avec accès en lecture pour augmenter la disponibilité et l'évolutivité de l'instance.
Comportement des instances dupliquées avec accès en lecture
- Les instances dupliquées avec accès en lecture ne sont pas activées par défaut sur les instances de niveau standard.
- Une fois les instances dupliquées avec accès en lecture activées sur une instance, il n'est plus possible de les désactiver pour cette instance.
- Les instances de niveau standard peuvent avoir entre une et cinq instances dupliquées avec accès en lecture.
- Le point de terminaison en lecture fournit un point de terminaison unique pour la distribution des requêtes sur les nœuds d'instances dupliquées.
- Les instances dupliquées avec accès en lecture sont gérées à l'aide de la réplication asynchrone de Redis.
Mises en garde et limites
- Les instances dupliquées avec accès en lecture ne sont compatibles qu'avec les instances de taille >= 5 Go.
- Les instances dupliquées avec accès en lecture ne peuvent être activées que sur des instances utilisant Redis 5.0 ou version ultérieure.
- Si vous désignez une zone et une zone alternative pour le provisionnement des nœuds, Memorystore utilise ces zones pour les premier et second nœuds de l'instance. Ensuite, Memorystore sélectionne les zones pour tous les nœuds restants provisionnés pour l'instance.
- Vous devez provisionner l'instance avec une plage d'adresses IP CIDR définie sur
/28ou une valeur supérieure. Les tailles de plage plus grandes, telles que/27et/26, sont valides. Les plages plus petites, telles que/29, ne sont pas compatibles avec cette fonctionnalité.
Architecture
Lorsque vous activez les instances répliquées avec accès en lecture, vous spécifiez le nombre d'instances répliquées souhaité pour l'instance. Memorystore distribue automatiquement les nœuds principaux et d'instances dupliquées avec accès en lecture sur les zones disponibles d'une région.
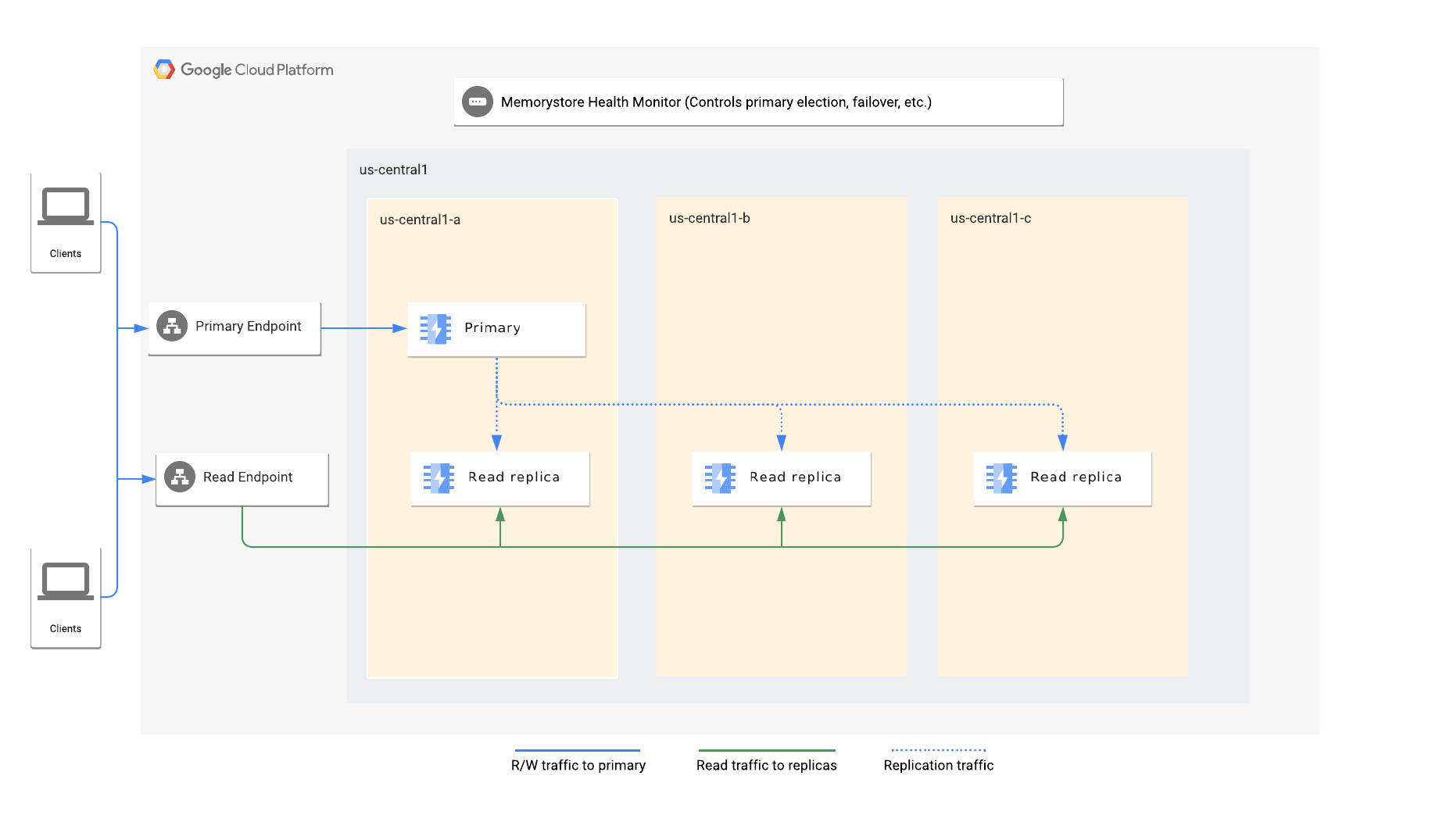
Chaque instance possède un point de terminaison principal et un point de terminaison de lecture. Le point de terminaison principal dirige toujours le trafic vers le nœud principal, tandis que le point de terminaison de lecture équilibre automatiquement la charge des requêtes de lecture sur les instances dupliquées disponibles.
Le service de surveillance de l'état de Memorystore pour Redis surveille l'instance et est chargé de détecter toute défaillance du nœud principal. Il choisit une instance dupliquée en tant que nouvelle instance principale et lance un basculement automatique vers la nouvelle instance principale.
Basculements pour les instances avec instances dupliquées avec accès en lecture
Lorsqu'une instance principale échoue, le service de surveillance de l'état de Memorystore lance le basculement et la nouvelle instance principale est mise à disposition pour les lectures et les écritures. Le basculement prend généralement moins de 30 secondes.
Lorsqu'un basculement se produit, le point de terminaison principal redirige automatiquement le trafic vers le nouveau point de terminaison principal. Cependant, toutes les connexions client au point de terminaison principal sont déconnectées pendant un basculement. Les applications avec une logique de nouvelle tentative de connexion se reconnectent automatiquement une fois la nouvelle instance principale en ligne. Certaines connexions client au point de terminaison en lecture subissent également des déconnexions de l'instance dupliquée avec accès en lecture qui est promue en instance principale lors du basculement. Les connexions aux instances dupliquées restantes persistent lors d'un basculement. Lors de la nouvelle tentative, les connexions seront redirigées vers les nouvelles instances dupliquées.
Lorsqu'un basculement se produit, en raison de la nature asynchrone de la réplication, les instances dupliquées peuvent présenter un délai de réplication différent. Cependant, le processus de basculement tente au mieux de basculer vers l'instance dupliquée avec le moins de temps de latence possible. Cela permet de minimiser le risque de perte de données et de réduction du débit en lecture lors d'un basculement. L'instance principale nouvellement promue peut se trouver dans la même zone ou dans une zone différente de l'ancienne instance principale. Une instance dupliquée est sélectionnée en tant que nouvelle instance principale si elle se trouve dans la même zone que l'ancienne instance principale et qu'elle présente le temps de latence le plus faible. Sinon, une instance dupliquée d'une zone différente peut devenir la nouvelle instance principale.
Comme la réplication est asynchrone, il est toujours possible de lire des données obsolètes lors d'un basculement. En outre, pendant la promotion de la nouvelle instance principale, certaines écritures peuvent être perdues sur l'instance. Les applications doivent pouvoir gérer ce comportement.
Redis tente au mieux d'éviter les autres instances dupliquées nécessitant une synchronisation complète lors du basculement, mais cela peut se produire dans de rares cas. Une synchronisation complète peut prendre de quelques minutes à une heure, selon le taux d'écriture et la taille de l'ensemble de données répliqué. Pendant le processus de synchronisation complète, les instances dupliquées ne sont pas disponibles pour les lectures. Une fois la synchronisation terminée, les instances dupliquées sont accessibles pour les lectures.
Modes de défaillance pour les instances dupliquées avec accès en lecture
Les instances avec des instances dupliquées avec accès en lecture peuvent rencontrer diverses défaillances et conditions non opérationnelles qui ont une incidence sur l'application. Le comportement varie selon que l'instance possède une ou plusieurs instances dupliquées. Cette section décrit certains modes de défaillance courants ainsi que le comportement de l'instance dans ces conditions.
L'instance dupliquée n'est pas disponible
Lorsqu'une instance dupliquée plante pour une raison quelconque, l'instance dupliquée est marquée comme indisponible et toutes les connexions à cette instance sont interrompues après un certain délai. Une fois l'instance dupliquée récupérée, de nouvelles connexions sont acheminées vers l'instance dupliquée restaurée. Le temps nécessaire à la récupération d'une instance dupliquée varie en fonction du mode de défaillance.
En cas d'indisponibilité ou de défaillance de la zone Compute Engine, l'instance dupliquée ne récupère pas tant que la condition n'est pas résolue.
Défaillance de la zone
Si la zone où se trouve l'instance principale échoue, l'instance principale bascule automatiquement vers une instance dupliquée d'une autre zone. Si l'instance ne dispose que d'une seule instance dupliquée, le point de terminaison en lecture est indisponible pendant toute la durée de la défaillance de zone. Si l'instance comporte plusieurs instances dupliquées, les instances dupliquées en dehors de la zone affectée sont disponibles pour les lectures.
Si la zone dans laquelle se trouve une ou plusieurs instances dupliquées subit une défaillance, ces instances dupliquées sont indisponibles pendant toute la durée de la défaillance de zone. En cas de défaillance de deux zones impliquant au moins deux instances dupliquées, l'instance dupliquée présentant le moins de décalage dans les zones restantes est promue en tant qu'instance principale. Toutes les instances dupliquées restantes dans les zones non affectées sont disponibles pour les lectures.
Partition réseau
Une partition réseau est un scénario dans lequel les nœuds restent en cours d'exécution mais ne peuvent pas atteindre tous les clients, zones ou nœuds pairs. Memorystore utilise un système basé sur le quorum pour empêcher les nœuds isolés de diffuser des écritures. Dans le cas d'une partition réseau, toute instance principale située dans une partition minoritaire est automatiquement rétrogradée. La partition majoritaire (le cas échéant) choisit une nouvelle instance principale si elle n'en a pas déjà une. Les instances dupliquées isolées continuent de diffuser les lectures. Toutefois, elles peuvent devenir obsolètes si elles ne parviennent pas à se synchroniser à partir de l'instance principale.
Pour déterminer si le lien est non fonctionnel, surveillez les métriques master_link_down_since_seconds et offset_diff pour identifier les nœuds isolés.
Indisponibilité
Il arrive que des ressources Compute Engine requises par Memorystore ne soient pas disponibles dans une zone, ce qui entraîne une indisponibilité. En cas d'indisponibilité dans la région où vous essayez de provisionner une instance, l'opération de création d'instance échoue.
Synchronisation complète
Lorsqu'une instance dupliquée prend trop de retard par rapport à l'instance principale, elle déclenche une synchronisation complète afin de copier un instantané complet de l'instance principale vers une instance dupliquée. Cette opération peut durer de quelques minutes à une heure dans le pire des cas. Une synchronisation complète n'entraîne pas d'échec d'instance. Toutefois, pendant cette période, l'instance dupliquée en cours de synchronisation complète n'est pas disponible pour les lectures et l'utilisation de processeur et de mémoire de l'instance principale est plus élevée.
Le point de terminaison principal renvoie READONLY
Vos écritures sur le point de terminaison principal d'une instance Memorystore pour Redis avec des instances répliquées en lecture peuvent recevoir des erreurs -READONLY You can't write against a read
only replica. de manière inattendue. Nous vous recommandons de fermer les connexions à l'instance et de les recréer. Dans la plupart des cas, le redémarrage de l'application cliente peut atténuer le problème. Si ces options ne sont pas réalisables ou si le problème persiste, veuillez contacter l'équipe d'assistance Google Cloud .
Procéder au scaling des lectures avec le point de terminaison de lecture
Les instances dupliquées avec accès en lecture permettent aux applications de procéder au scaling de leurs lectures en lisant à partir des instances dupliquées. Les applications peuvent se connecter aux instances dupliquées avec accès en lecture via le point de terminaison de lecture.
Point de terminaison de lecture
Le point de terminaison de lecture est une adresse IP à laquelle votre application se connecte. Il équilibre la charge des connexions entre les instances dupliquées de l'instance. Les connexions à l'instance dupliquée avec accès en lecture peuvent envoyer des requêtes en lecture, mais pas de requêtes d'écriture. Toutes les instances de niveau standard pour lesquelles des instances dupliquées avec accès en lecture sont activées disposent d'un point de terminaison de lecture. Pour savoir comment afficher le point de terminaison de lecture de votre instance, consultez la section Afficher des informations sur les instances dupliquées avec accès en lecture pour votre instance.
Comportement du point de terminaison de lecture
- Le point de terminaison de lecture répartit automatiquement les connexions entre toutes les instances dupliquées disponibles. Les connexions ne sont pas dirigées vers l'instance principale.
- Une instance dupliquée est considérée comme disponible tant qu'elle est en mesure de diffuser le trafic client. Cela exclut les moments où une instance dupliquée est en cours de synchronisation complète avec son instance principale.
- Une instance dupliquée avec un délai de réplication élevé continue de diffuser du trafic. Les applications avec un volume d'écriture élevé peuvent lire des données obsolètes à partir d'une instance dupliquée diffusant un grand nombre d'écritures.
- Dans le cas où un nœud dupliqué devient l'instance principale, les connexions à ce nœud sont interrompues et les nouvelles connexions sont redirigées vers un nouveau nœud d'instance dupliquée.
- Les connexions individuelles au point de terminaison de lecture ciblent la même instance dupliquée pendant toute la durée de vie de la connexion. Il n'est pas certain que différentes connexions provenant du même hôte client ciblent le même nœud d'instance dupliquée.
Cohérence en lecture
Les instances dupliquées avec accès en lecture sont gérées à l'aide de la réplication asynchrone OSS Redis native. En raison de la nature de la réplication asynchrone, il est possible que l'instance dupliquée soit en retard par rapport à l'instance principale. Les applications avec des écritures constantes qui lisent également des données à partir de l'instance dupliquée doivent pouvoir tolérer des lectures incohérentes.
Si l'application nécessite une cohérence de type "lecture de vos écritures", nous vous recommandons d'utiliser le point de terminaison principal pour les écritures et les lectures. L'utilisation du point de terminaison principal garantit que les lectures sont toujours dirigées vers l'instance principale. Même dans ce cas, il est possible d'avoir des lectures de données non actualisées après un basculement.
La définition de valeurs TTL sur les clés de l'instance principale garantit de ne pas lire des clés expirées à partir de l'instance principale ou de l'instance dupliquée. En effet, Redis garantit qu'une clé arrivée à expiration ne peut pas être lue à partir de l'instance dupliquée.
Comportement de l'activation des instances répliquées avec accès en lecture sur une instance existante
L'activation des instances dupliquées avec accès en lecture sur une instance Redis existante est une opération exclusive. Cela signifie que vous ne pouvez pas effectuer d'autres modifications d'instance d'opération de mise à jour dans le cadre de la même opération qui active les instances dupliquées avec accès en lecture.
Pour activer les instances dupliquées avec accès en lecture sur une instance Redis existante, vous devez allouer une plage d'adresses IP secondaires valide pour le placement des nœuds. Il doit s'agir d'une plage CIDR (Classless Inter-Domain Routing) de taille
/28, quelle que soit la taille de la plage d'adresses IP existante allouée à Memorystore pour Redis.- Vous devez fournir la plage d'adresses IP supplémentaire lorsque vous activez les instances répliquées avec accès en lecture pour l'instance Redis. Vous pouvez choisir une plage spécifique ou laisser Memorystore en sélectionner une automatiquement.
L'adresse IP en lecture/écriture de votre instance ne change pas lorsque vous activez les répliques en lecture. L'adresse IP du point de terminaison de lecture se trouve dans la plage d'origine allouée à votre instance Memorystore, et non dans la plage supplémentaire que vous fournissez lorsque vous activez les instances répliquées avec accès en lecture.
Pour trouver le nouveau point de terminaison de lecture, affichez les informations sur les instances dupliquées avec accès en lecture pour votre instance une fois l'opération d'activation des instances dupliquées avec accès en lecture terminée.
Réaliser le scaling d'une instance
Vous pouvez adapter le nombre d'instances dupliquées avec accès en lecture pour votre instance et modifier la taille de nœud :
Pour savoir comment ajouter et supprimer des nœuds, consultez la page Ajouter ou supprimer des nœuds d'instances dupliquées à votre instance Redis.
Pour obtenir des instructions sur le scaling de la taille des nœuds Redis, consultez la section Scaling de la taille des nœuds Redis.
Nous vous recommandons de procéder au scaling de votre instance pendant une période de faible trafic en lecture et en écriture afin de minimiser tout impact sur l'application.
L'ajout d'une nouvelle instance dupliquée entraîne une charge supplémentaire sur l'instance principale pendant que l'instance dupliquée effectue une synchronisation complète. Lorsque vous ajoutez des nœuds, les connexions existantes ne sont pas affectées ni transférées. Une fois que la nouvelle instance dupliquée est disponible, elle commence à recevoir les connexions du point de terminaison et à diffuser des lectures. La suppression d'une instance dupliquée ferme toutes les connexions actives acheminées vers cette instance dupliquée. L'application cliente doit être configurée de manière à se reconnecter automatiquement au point de terminaison de lecture pour rétablir les connexions aux instances dupliquées restantes.
Bonnes pratiques
Gestion de la mémoire
Redis ne permet pas aux écritures client de dépasser la limite maxmemory de l'instance. Cependant, une surcharge résultant de la fragmentation, des tampons de réplication ou de commandes coûteuses telles que EVAL peut augmenter l'utilisation de la mémoire au-delà de cette limite. Dans ce cas, Memorystore fait échouer les écritures jusqu'à ce que la saturation de la mémoire soit réduite. Pour en savoir plus, consultez les bonnes pratiques pour la gestion de la mémoire.
Si Memorystore fait l'objet d'une opération BGSAVE en raison d'une exportation ou d'une réplication de synchronisation complète et qu'une condition OOM se produit, le processus enfant est supprimé. Dans ce cas, l'opération BGSAVE échoue et le serveur de nœud Redis reste disponible.
Pour garantir la réplication et la création d'instantanés dans toutes les circonstances, nous vous recommandons de maintenir une utilisation de la mémoire inférieure à 50 % lors d'opérations importantes telles que l'exportation, le scaling, etc… Vous pouvez déclencher manuellement l'exportation ou le basculement afin de voir l'impact de ces opérations sur les performances.
Gestion du processeur
Memorystore fournit des métriques sur l'utilisation du processeur et le nombre de connexions pour chaque nœud. Nous vous recommandons d'allouer suffisamment de ressources pour pouvoir tolérer la perte d'une seule zone de disponibilité. La cible idéale peut varier en fonction du nombre d'instances répliquées et des modèles d'utilisation, mais un bon point de départ consiste à maintenir l'utilisation du processeur des instances répliquées en dessous de 50 %.
Les nœuds individuels peuvent rencontrer une utilisation élevée si les modèles d'utilisation du client sont déséquilibrés ou si les opérations de basculement entraînent une distribution déséquilibrée des connexion. Dans ce cas, nous vous recommandons de fermer régulièrement les connexions pour permettre à Memorystore de rééquilibrer automatiquement les connexions. Memorystore ne rééquilibre pas les connexions ouvertes.
Gestion de l'équilibrage de connexion
Chaque fois que les connexions d'un nœud sont fermées, les clients doivent se reconnecter (généralement en activant la reconnexion automatique sur la bibliothèque cliente de votre choix). Lorsque le nœud est réintroduit, les connexions existantes ne sont pas réacheminées mais de nouvelles connexions sont associées au nouveau nœud. Les clients peuvent régulièrement interrompre les connexions pour s'assurer qu'elles sont équilibrées entre les nœuds disponibles.
Gestion du délai de réplication
Il est possible que les instances dupliquées soient en retard, en particulier lorsque le taux d'écriture est très élevé. Dans de tels scénarios, l'instance dupliquée reste disponible pour les lectures. Dans ce cas, les lectures de l'instance dupliquée peuvent être obsolètes et l'application doit pouvoir le gérer. Si cela n'est pas possible, le taux d'écriture élevé doit être résolu.
Étape suivante
- Apprenez à gérer les instances dupliquées avec accès en lecture.
- Découvrez comment exporter des sauvegardes pour Redis.
- Découvrez la haute disponibilité de Memorystore pour Redis.