IBM メインフレームは、組織が重要なコンピューティング タスクを実行するために使用されます。近年、メインフレームを利用している多くの企業が、クラウドへの移行を進めています。Mainframe Connector を使用すると、メインフレーム データをGoogle Cloud に移動して、CPU 使用率の高いレポート ワークロードを Google Cloudにオフロードできます。
Mainframe Connector の主なメリット
Mainframe Connector を使用してメインフレーム データを Google Cloudに移行する主なメリットは次のとおりです。
- データ転送の簡素化: メインフレーム データを Cloud Storage や BigQuery などのGoogle Cloud ストレージ サービスに移行するプロセスを簡素化します。
- バッチジョブの統合: ジョブ制御言語(JCL)で定義されたメインフレーム バッチジョブを使用して BigQuery ジョブを送信できます。クエリはデータセットまたはファイルから読み取られるため、アナリストはメインフレーム環境に関する最小限の知識と理解で、スケジュールされたジョブを使用できます。
- 簡単なモニタリング: メインフレームの運用担当者は、JCL を使用してジョブが使い慣れたスケジュールで送信されるため、別の環境をモニタリングする必要がありません。
- MIPS の削減: Mainframe Connector は、ほとんどの処理に Java 仮想マシン(JVM)を使用し、データ転送中のメインフレーム プロセッサのワークロードを最小限に抑えます。これにより、100 万命令/秒(MIPS)が削減され、コストが削減されます。Mainframe Connector は、プロセッサ負荷の高い作業のほとんどを補助プロセッサにオフロードします。補助プロセッサに負荷がかかっている場合は、Compute Engine を使用してトランスコーディングと変換を実行するように Mainframe Connector を構成することもできます。Mainframe Connector の構成の詳細については、Mainframe Connector の構成をご覧ください。
ストリーミング変換: Google Cloud などのサービスと互換性のある ORC、JSON、CSV 形式にファイルをコード変換します。Mainframe Connector は、次のファイル形式のトランスコードをサポートしています。
- 拡張バイナリコード(EBCDIC)の COBOL コピーブックに関連付けられたキューに入れられた順次アクセス方式(QSAM)または仮想ストレージ アクセス方式(VSAM)のメインフレーム データセット
- ASCII UTF-8 のファイル
デフォルトでは、Mainframe Connector はデータセットを US EBCDIC: Cp037 文字セットから ORC、JSON、CSV 形式にトランスコードします。ただし、Mainframe Connector は、次のリージョン EBCDIC 文字セットからのデータセットのコード変換もサポートしています。
- フランス語: Cp297
- ドイツ語: Cp1141
- スペイン語: Cp1145
適切な文字セットが IBM JVM に含まれていない場合は、カスタム文字セットを実装できます。
Mainframe Connector の仕組み
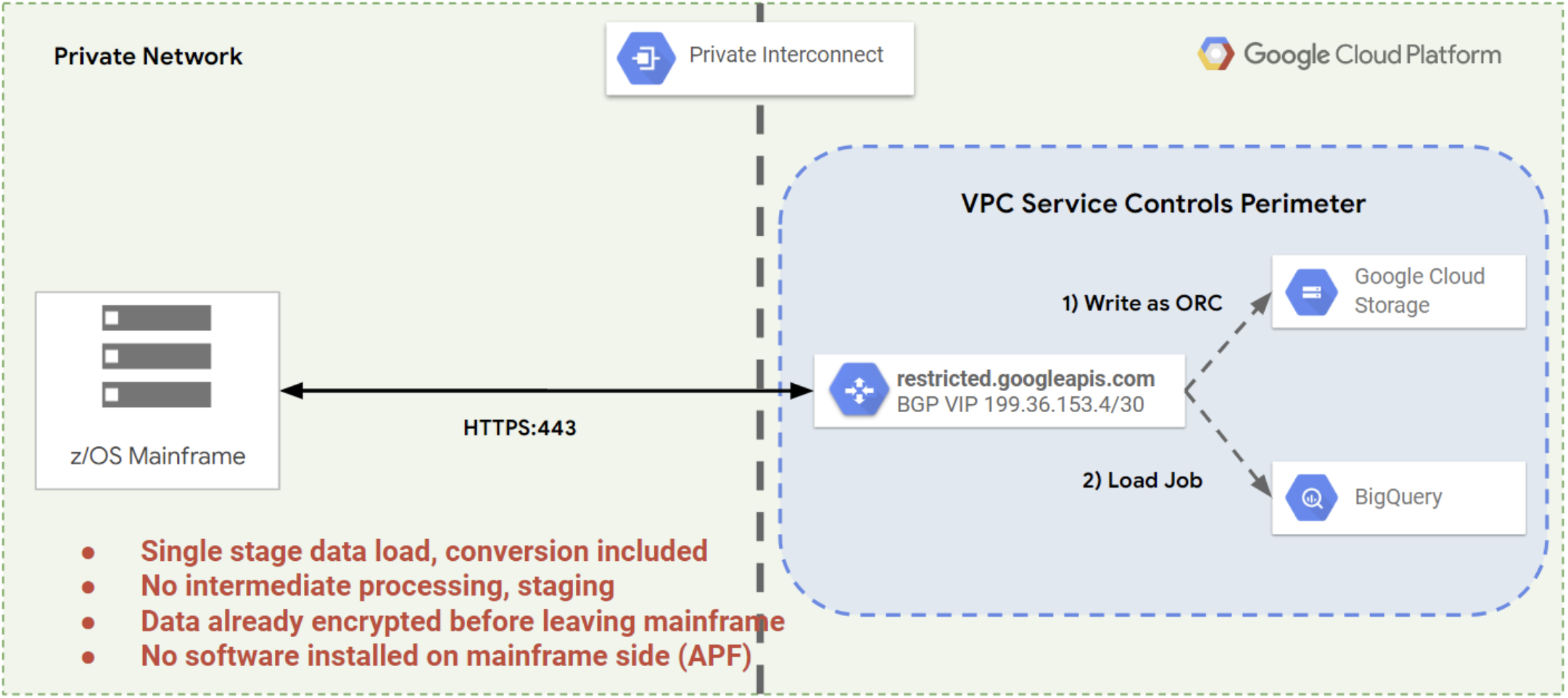
Mainframe Connector を使用すると、メインフレームにあるデータを Cloud Storage との間で移動できます。また、JCL で定義されるメインフレーム ベースのバッチジョブから BigQuery ジョブを送信できます。Mainframe Connector を使用すると、メインフレームのデータセットを Optimized Row Columnar(ORC)形式に直接コード変換できます。
トランスコードとは、ある形式のコード表現から別の形式(この場合は ORC)に情報を変換するプロセスです。ORC は、Apache Hadoop エコシステムで広く使用されているオープンソースの列指向のデータ形式で、BigQuery でサポートされています。
Mainframe Connector は、Google Cloud SDK コマンドライン ユーティリティのサブセットを提供し、データの転送と Google Cloud サービスとのやり取りを可能にします。シェル インタプリタと、JVM ベースで実装された gsutil および bq コマンドライン ユーティリティによって、既存のジョブ スケジューラを維持したまま、抽出、読み込み、変換(ELT)パイプライン全体を IBM z/OS から完全に管理できます。
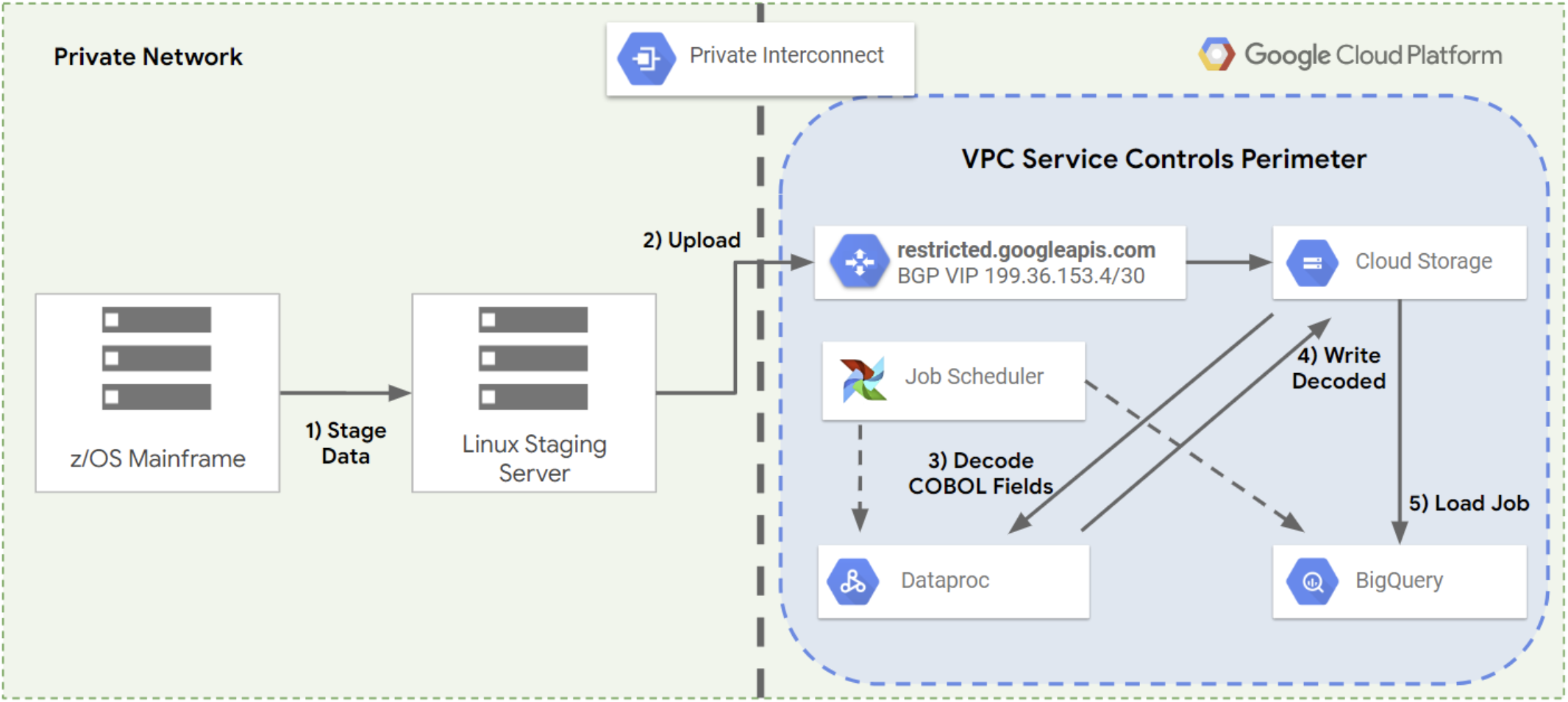
クラウドとの間でメインフレーム データを転送する際の主な課題の 1 つは、複数のステップから構成されるプロセスであることです。このプロセスには通常、次のステップの実行が含まれます。
- データをファイル サーバーにコピーします。
- ファイル サーバーから別の場所にデータをコピーして処理します。
- データ処理スタックを使用してデータを最新の形式に変換します。
- 処理されたデータを別の場所に書き戻します。
- 処理されたデータを、データのクエリや使用が可能なデータベースまたはデータ ウェアハウスに読み込みます。
次の図は、メインフレームから Google Cloudにデータを転送するために通常使用されるマルチステップのプロセスを示しています。
Mainframe Connector を使用すると、Cloud Storage を中間ストレージの場所として使用して、これらのすべての手順を 1 つのコマンドで実行できます。これにより、次の図に示すように、メインフレーム データの処理とデータベースまたはデータ ウェアハウスでの利用が可能になるまでの時間が短縮されます。