Looker reduces the load on your database and improves performance by using cached results of prior SQL queries when they are available and when this function is permitted by your caching policy. This page describes Looker's default caching policy, along with the available options for modifying the duration of cached results on your Looker instance.
How Looker uses cached queries
For SQL queries, the caching mechanism in Looker works as follows:
When a SQL query is run from an Explore, a Look, or a dashboard, Looker checks the cache to see if there are already cached results for that query. Cached results will be used only if all aspects of the query are the same, including fields, filters, parameters, and row limits.
If cached results are found, then Looker checks the caching policy that is defined in the LookML model to determine if the cached results have expired. If the cached results have not expired, then Looker uses the cached results for the query.
If no cached results are found for the query, or if the cached results have expired, then Looker will run the query against the database. The new query results will then be cached.
The default cache retention policy is one hour. The next section, Modifying cache retention policies, discusses how to shorten or lengthen this amount of time, as well as describing options for synchronizing your cache retention policy to your database's ETL (extract, transform, and load) process.
Modifying cache retention policies
You can specify cache retention policies at the LookML Explore level and at the LookML model level.
The recommended caching mechanism is to use a datagroup parameter at the model level. Datagroups let you synchronize a model's cache retention policy with your database's ETL schedule by using the sql_trigger parameter and by setting a cache expiration interval with the max_cache_age parameter. For more information, see the Caching queries and rebuilding PDTs with datagroups section.
For a simpler approach, you can instead use the persist_for parameter at the model level or the Explore level. Using the persist_for parameter in this way lets you set a cache expiration interval that overrides the default interval of one hour. However, using persist_for is less robust than using datagroups for a few reasons, as discussed in the Caching queries with persist_for section.
If an Explore or model has a datagroup or persist_for defined, then the caching policy is modified as follows:
- Before the
persist_forinterval or the datagroup'smax_cache_ageinterval expires: If the query is rerun, Looker pulls data from the cache. - At the time that the
persist_forinterval or the datagroup'smax_cache_ageinterval expires: Looker deletes data from the cache. - After the
persist_forinterval or the datagroup'smax_cache_ageinterval expires: If the query is rerun, Looker pulls the data from the database directly and resets thepersist_forormax_cache_ageinterval.
One key point here is that the data is deleted from the cache when the persist_for or max_cache_age interval expires.
If the cache reaches the storage limit, data is ejected based on a Least Recently Used (LRU) algorithm, with no guarantee that data with expired persist_for or max_cache_age intervals will be deleted all at once.
Minimizing the time that your data spends in the cache
Looker will always write query results to cache. Even if the persist_for and max_cache_age intervals are set to zero, cached data may still be stored for up to 10 minutes. All customer data that is stored on the disk cache is Advanced Encryption Standard (AES) encrypted.
To minimize the amount of time that data is stored in the cache:
- For any
persist_forparameter (for a model or an Explore) ormax_cache_ageparameter (for a datagroup), set the value to0 minutes. Looker deletes the cache when thepersist_forinterval expires, or when the data reaches themax_cache_ageinterval that is specified in its datagroup. (It is not necessary to set thepersist_forparameter of PDTs to0 minutesto minimize the amount of data that is stored in the cache. PDTs are written to the database itself, and not to the cache.) - Set the
suggest_persist_forparameter to a small interval. Thesuggest_persist_forvalue specifies how long Looker should keep filter suggestions in the cache. The filter suggestions are based on a query of the values for the field that is being filtered. These query results are kept in the cache so Looker can quickly provide suggestions as the user types in the filter text field. The default is to cache the filter suggestions for 6 hours. To minimize the amount of time your data is in the cache, set thesuggest_persist_forvalue to something lower, such as5 minutes.
Checking whether a query was returned from cache
In an Explore window, you can determine whether a query has been returned from the cache by looking in the upper right corner after you run a query.
When a query is returned from the cache, "from cache" is shown. Otherwise, the amount of time that it took to return the query is shown.

Forcing new results to be generated from the database
In an Explore window, you can force new results to be retrieved from the database. After you run a query (including merged results queries), select the Clear Cache & Refresh option from the Explore Actions gear menu, which is located in the upper right of the screen.
![]()
Caching queries and rebuilding PDTs with datagroups
Use datagroups to coordinate your database's ETL (extract, transform, and load) schedule with Looker's caching policy and PDT rebuilding schedule.
You can use a datagroup to specify the rebuilding trigger for PDTs based on when new data is added to your database. Then you can apply the same datagroup to your Explore or model so that cached results also expire when your PDTs rebuild.
Alternatively, you can use a datagroup to decouple the PDT rebuilding trigger from your maximum cache age. This can be useful if you have an Explore that is both based on data that updates very frequently and joined to a PDT that is rebuilt less frequently. In this case, you may want your query cache to reset more frequently than your PDT is rebuilt.
Defining a datagroup
Define a datagroup with the datagroup parameter, either in a model file or in its own LookML file. You can define multiple datagroups if you want different caching and PDT rebuild policies for different Explores and/or PDTs in your project.
The datagroup parameter can have the following subparameters:
label— Specifies an optional label for the datagroup.description— Specifies an optional description for the datagroup that can be used to explain the datagroup's purpose and mechanism.max_cache_age— Specifies a string that defines a time period. When the age of a query's cache exceeds the time period, Looker invalidates the cache. The next time the query is issued, Looker sends the query to the database for fresh results.sql_trigger— Specifies a SQL query that returns one row with one column. If the value that is returned by the query is different from the query's prior results, then the datagroup goes into a triggered state.interval_trigger— Specifies a time schedule for triggering the datagroup, such as"24 hours".
See the datagroup documentation page for more information on these parameters.
At a minimum, a datagroup must have at least the max_cache_age parameter, the sql_trigger parameter, or the interval_trigger parameter.
Here is an example of a datagroup that has a sql_trigger set up to rebuild the PDT every day. In addition, the max_cache_age is set to clear the query cache every two hours, in case any Explores join PDTs to other data that refreshes more frequently than once a day.
datagroup: customers_datagroup {
sql_trigger: SELECT DATE(NOW());;
max_cache_age: "2 hours"
}
Once you define the datagroup, you can assign it to Explores and PDTs:
- To assign the datagroup to a PDT, use the
datagroup_triggerparameter under thederived_tableparameter. See the Using a datagroup to specify a rebuild trigger for PDTs section on this page for an example. - To assign the datagroup to an Explore, use the
persist_withparameter at the model level or the Explore level. See the Using a datagroup to specify query cache reset for Explores section on this page for an example.
Using a datagroup to specify a rebuild trigger for PDTs
To define a PDT rebuilding trigger using datagroups, create a datagroup parameter with either the sql_trigger or the interval_trigger subparameter. Then assign the datagroup to individual PDTs using the datagroup_trigger subparameter in the PDT's derived_table definition. If you use datagroup_trigger for your PDT, you don't need to specify any other persistence strategy for the derived table. If you specify multiple persistence strategies for a PDT, you will get a warning in the Looker IDE, and only the datagroup_trigger will be used.
Here is an example of a PDT definition that uses the customers_datagroup datagroup. This definition also adds several indexes, on both customer_id and first_order_date. For more information about defining PDTs, see the Derived tables in Looker documentation page.
view: customer_order_facts {
derived_table: {
sql: ... ;;
datagroup_trigger: customers_datagroup
indexes: ["customer_id", "first_order_date"]
}
}
If you have cascading PDTs, PDTs that are dependent on other PDTs, be careful not to specify incompatible datagroup caching policies.
For connections that have user attributes to specify the connection parameters, you must create a separate connection using the PDT override fields if you want to do either of the following:
- Use PDTs in your model
- Use a datagroup to define a PDT rebuild trigger
Without the PDT overrides, you can still use a datagroup with
max_cache_ageto define the caching policy for Explores.
See the Derived tables in Looker documentation page for more information how datagroups work with PDTs.
Using a datagroup to specify query cache reset for Explores
When a datagroup is triggered, the Looker regenerator will rebuild the PDTs that use that datagroup as a persistence strategy. Once the datagroup's PDTs are rebuilt, Looker will clear the cache for Explores that use the datagroup's rebuilt PDTs. You can add the max_cache_age parameter to your datagroup definition if you want to customize a query cache reset schedule for the datagroup. The max_cache_age parameter lets you clear the query cache on a specified schedule, in addition to the automatic query cache reset that Looker performs when the datagroup's PDTs are rebuilt.
To define a query caching policy with datagroups, create a datagroup parameter with the max_cache_age subparameter.
To specify a datagroup to use for query cache resets on Explores, use the persist_with parameter:
- To assign the datagroup as the default for all Explores in a model, use the
persist_withparameter at the model level (in a model file). - To assign the datagroup to individual Explores, use the
persist_withparameter under anexploreparameter.
The following examples shows a datagroup named orders_datagroup that is defined in a model file. The datagroup has a sql_trigger parameter, which specifies that the query select max(id) from my_tablename will be used to detect when an ETL has happened. Even if that ETL doesn't happen for a while, the datagroup's max_cache_age specifies that the cached data will be used only for a maximum of 24 hours.
The model's persist_with parameter points to the orders_datagroup caching policy, which means this will be the default caching policy for all Explores in the model. However, we don't want to use the model's default caching policy for the customer_facts and customer_background Explores, so we can add the persist_with parameter to specify a different caching policy for these two Explores. The orders and orders_facts Explores don't have a persist_with parameter, so they will use the model's default caching policy: orders_datagroup.
datagroup: orders_datagroup {
sql_trigger: SELECT max(id) FROM my_tablename ;;
max_cache_age: "24 hours"
}
datagroup: customers_datagroup {
sql_trigger: SELECT max(id) FROM my_other_tablename ;;
}
persist_with: orders_datagroup
explore: orders { ... }
explore: order_facts { ... }
explore: customer_facts {
persist_with: customers_datagroup
...
}
explore: customer_background {
persist_with: customers_datagroup
...
}
If both persist_with and persist_for are specified, then you will receive a validation warning and the persist_with will be used.
Using a datagroup to trigger scheduled deliveries
Datagroups can also be used to trigger a delivery of a dashboard or a Look. With this option, Looker will send your data when the datagroup completes, so that the scheduled content is up to date.
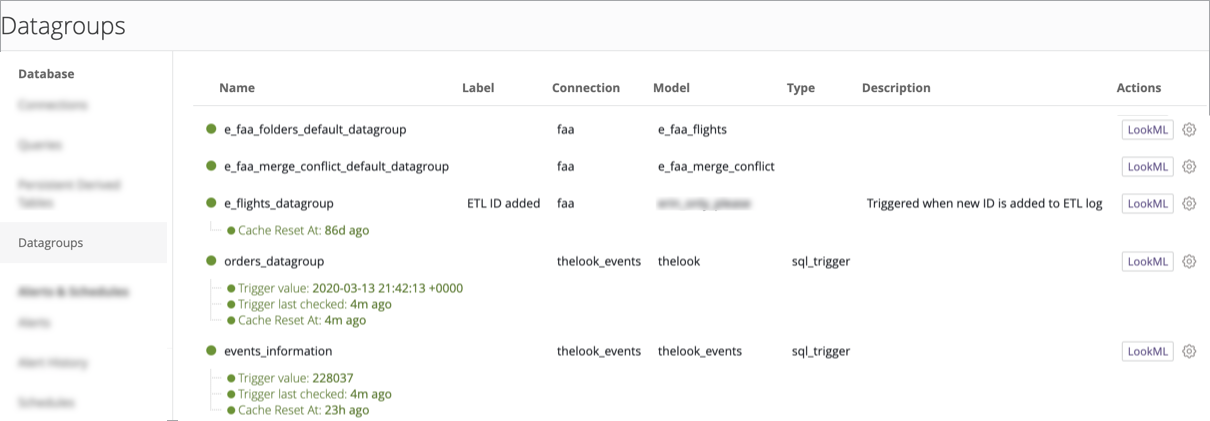
Using the Admin panel for datagroups
If you have the Looker admin role, you can use the Admin panel's Datagroups page to view the existing datagroups. You can see the connection, model, and current status of each datagroup and — if specified in the LookML — a label and description for each datagroup. You can also reset the cache for a datagroup, trigger the datagroup, or navigate to the datagroup's LookML.
Caching queries with persist_for
Use the persist_for parameter at the model level or the Explore level to modify Looker's default cache retention interval of 1 hour. You can set intervals as small as 0 minutes and intervals as high as 8760 hours (1 year) or higher.
Defining persist_for parameters can be faster and simpler, but less robust, than defining datagroups. Datagroups are recommended over persist_for for the following reasons:
- Datagroups can synchronize with your database's ETL process.
- You can reuse datagroups across several models and Explores. This means that you can update the
max_cache_ageof a datagroup, and it will update the caching policy in each place the datagroup is used. - You can clear all cache that is associated with a datagroup from the Datagroups page.