This page provides details about the Cloud Logging agent's default and custom configurations.
Most users don't need to read this page. Read this page if:
You're interested in learning deep technical details of the Cloud Logging agent's configuration.
You want to change the configuration of the Cloud Logging agent.
Default configuration
The Logging agent google-fluentd is a modified version of the
fluentd log data collector.
The Logging agent comes with a default configuration; in most
common cases, no additional configuration is required.
In its default configuration, the Logging agent streams logs, as included in the list of default logs, to Cloud Logging. You can configure the agent to stream additional logs; for details, go to Customizing the Logging agent configuration on this page.
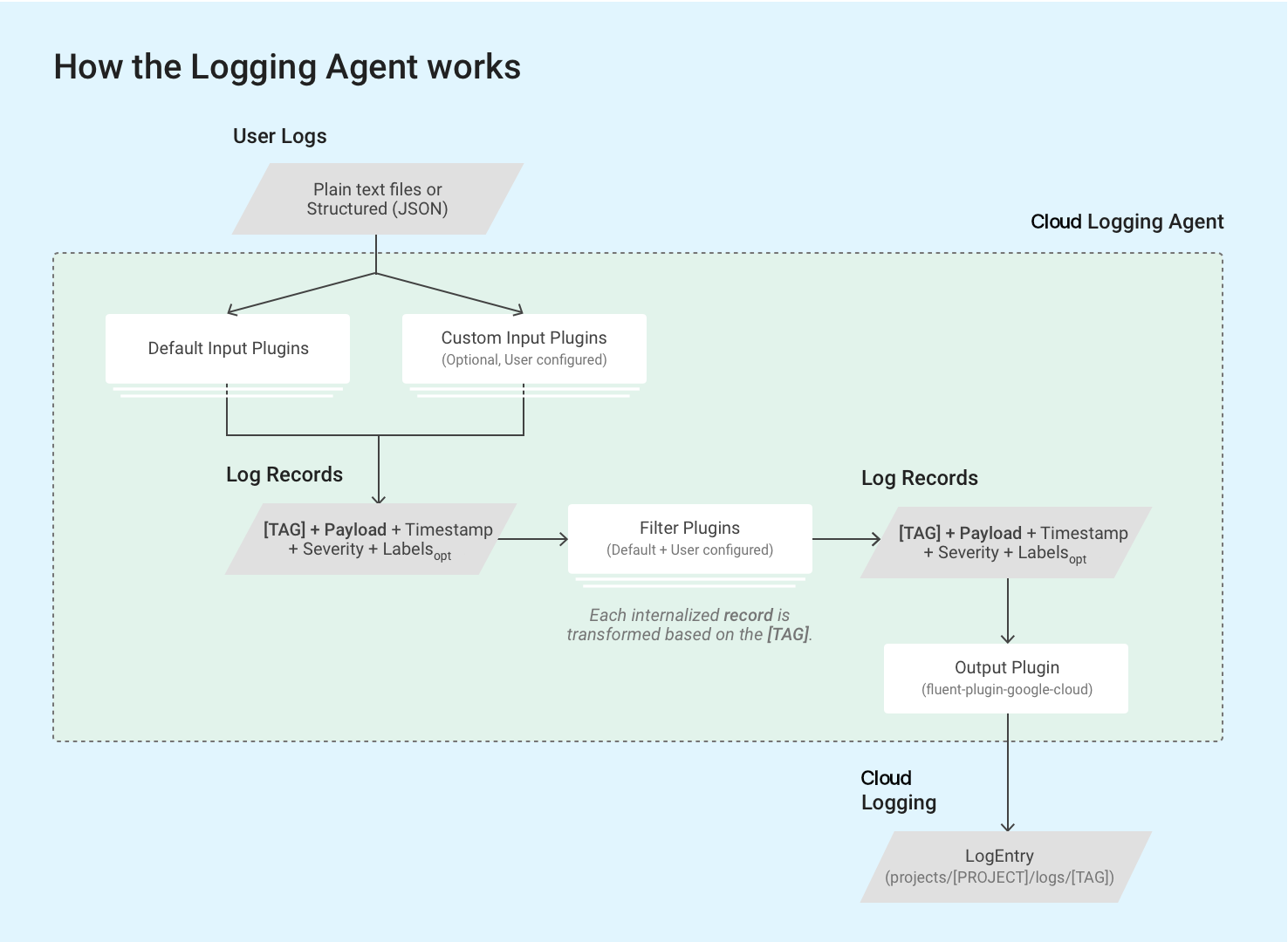
The Logging agent uses fluentd input plugins to
retrieve and pull event logs from external sources, such as files on disk, or
to parse incoming log records. Input plugins are bundled with the agent or can
be installed separately as Ruby gems; review the list of
bundled plugins.
The agent reads log records stored in log files on the VM instance via
fluentd's built-in in_tail plugin. Each log record is converted to a
log entry structure for
Cloud Logging. The content of each log record is mostly recorded in
the payload of the log entries, but log entries also contain standard
elements like a timestamp and severity. The Logging
agent requires every log record to be tagged with a string-format tag; all of
the queries and output plugins match a specific set of tags. The log name
usually follows the format,
projects/[PROJECT-ID]/logs/[TAG]. For example, this log name includes the
tag structured-log:
projects/my-sample-project-12345/logs/structured-log
The output plugin transforms each internalized structured message to a log entry in Cloud Logging. The payload becomes the text or JSON payload.
The following sections on this page discuss the default configuration in detail.
Default configuration definitions
The following sections describe the default configuration definitions for
syslog, the forward input plugin, input configurations for third-party
application logs, such as those in the
list of default logs, and our Google
Cloud fluentd output plugin.
Root configuration file location
Linux:
/etc/google-fluentd/google-fluentd.confThis root configuration file imports all configuration files from the
/etc/google-fluentd/config.dfolder as well.Windows:
C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.confIf you are running a Logging agent before v1-5, the location is:
C:\GoogleStackdriverLoggingAgent\fluent.conf
Syslog configuration
Configuration file locations:
/etc/google-fluentd/config.d/syslog.confDescription: This file includes the configuration to specify syslog as a log input.
Review the config repository.
| Configuration name | Type | Default | Description |
|---|---|---|---|
format |
string | /^(?<message>(?<time>[^ ]*\s*[^ ]* [^ ]*) .*)$/ |
The format of the syslog. |
path |
string | /var/log/syslog |
The path of the syslog file. |
pos_file |
string | /var/lib/google-fluentd/pos/syslog.pos |
The path of the position file for this log input. fluentd records the position it last read into this file. Review the detailed fluentd documentation. |
read_from_head |
bool | true |
Whether to start to read the logs from the head of file instead of the bottom. Review the detailed fluentd documentation. |
tag |
string | syslog |
The log tag for this log input. |
in_forward input plugin configuration
Configuration file locations:
/etc/google-fluentd/config.d/forward.confDescription: This file includes the configuration to configure the
in_forwardfluentdinput plugin. Thein_forwardinput plugin allows you to pass in logs via a TCP socket.Review the detailed
fluentddocumentation for this plugin and the config repository.
| Configuration name | Type | Default | Description |
|---|---|---|---|
port |
int | 24224 |
The port to monitor. |
bind |
string | 127.0.0.1 |
The bind address to monitor. By default, only connections from localhost are accepted. To open this up, this configuration needs to be changed to 0.0.0.0. |
Third-party application log input configuration
Configuration file locations:
/etc/google-fluentd/config.d/[APPLICATION_NAME].confDescription: This directory includes configuration files to specify third-party applications' log files as log inputs. Each file, except
syslog.confandforward.conf, represents one application (e.g.,apache.conffor the Apache application).Review the config repository.
| Configuration name | Type | Default | Description |
|---|---|---|---|
format1 |
string | Varies per application | The format of the log. Review the detailed fluentd documentation. |
path |
string | Varies per application | The path of the log file(s). Multiple paths can be specified, separated by ','. * and strftime format can be included to add/remove watch file dynamically. Review the detailed fluentd documentation. |
pos_file |
string | Varies per application | The path of the position file for this log input. fluentd records the position it last read into this file. Review the detailed fluentd documentation). |
read_from_head |
bool | true |
Whether to start to read the logs from the head of file instead of the bottom. Review the detailed fluentd documentation. |
tag |
string | Varies; the name of the application. | The log tag for this log input. |
1 If you are using the <parse> stanza, then specify the format of
the log by using @type.
Google Cloud fluentd output plugin configuration
Configuration file locations:
- Linux:
/etc/google-fluentd/google-fluentd.conf Windows:
C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.confIf you are running a Logging agent before v1-5, the location is:
C:\GoogleStackdriverLoggingAgent\fluent.conf
- Linux:
Description: This file includes configuration options to control the Google Cloud
fluentdoutput plugin's behavior.Go to the config repository.
| Configuration name | Type | Default | Description |
|---|---|---|---|
buffer_chunk_limit |
string | 512KB |
As log records come in, those that cannot be written to downstream components fast enough are pushed into a queue of chunks. This configuration sets the size limit of each chunk. By default, we set the chunk limit conservatively to avoid exceeding the recommended chunk size of 5MB per write request in Logging API. Log entries in the API request can be 5X - 8X times larger than the original log size with all the additional metadata attached. A buffer chunk gets flushed if one of the two conditions are met: 1. flush_interval kicks in. 2. The buffer size reaches buffer_chunk_limit. |
flush_interval |
string | 5s |
As log records come in, those that cannot be written to downstream components fast enough are pushed into a queue of chunks. The configuration sets how long before we have to flush a chunk buffer. A buffer chunk gets flushed if one of the two conditions are met: 1. flush_interval kicks in. 2. The buffer size reaches buffer_chunk_limit. |
disable_retry_limit |
bool | false |
Enforces a limit on the number of retries of failed flush of buffer chunks. Review detailed specifications in retry_limit, retry_wait and max_retry_wait. |
retry_limit |
int | 3 |
When a buffer chunk fails to be flushed, fluentd by default retries later. This configuration sets how many retries to perform before dropping one problematic buffer chunk. |
retry_wait |
int | 10s |
When a buffer chunk fails to be flushed, fluentd by default retries later. This configuration sets the wait interval in seconds before the first retry. The wait interval doubles on each following retry (20s, 40s,...) until eitherretry_ limit or max_retry_wait is reached. |
max_retry_wait |
int | 300 |
When a buffer chunk fails to be flushed, fluentd by default retries later. The wait interval doubles on each following retry (20s, 40s,...) This configuration sets the maximum of wait intervals in seconds. If the wait interval reaches this limit, the doubling stops. |
num_threads |
int | 8 |
The number of simultaneous log flushes that can be processed by the output plugin. |
use_grpc |
bool | true |
Whether to use gRPC instead of REST/JSON to communicate to the Logging API. With gRPC enabled, CPU usage is typically lower |
grpc_compression_algorithm |
enum | none |
If using gRPC, sets which compression schema to use. Can be none or gzip. |
partial_success |
bool | true |
Whether to support partial success for logs ingestion. If true, invalid log entries in a full set are dropped, and valid log entries are successfully ingested into the Logging API. If false, the full set would be dropped if it contained any invalid log entries. |
enable_monitoring |
bool | true |
When set to true, the Logging agent exports internal telemetry. See Output plugin telemetry for details. |
monitoring_type |
string | opencensus |
The type of monitoring. The supported options are opencensus and prometheus. See Output plugin telemetry for details. |
autoformat_stackdriver_trace |
bool | true |
When set to true, the trace is reformatted if the value of structured payload field logging.googleapis.com/trace matches ResourceTrace traceId format. Details of the autoformatting can be found in Special fields in structured payloads on this page. |
Monitoring configuration
Output plugin telemetry
The enable_monitoring option controls whether the Google Cloud fluentd
output plugin collects its internal telemetry. When set to true, the
Logging agent keeps track of the number of log entries requested
to be sent to Cloud Logging and the actual number of log entries successfully
ingested by Cloud Logging. When set to false, no metrics are collected by
the output plugin.
The monitoring_type option controls how this telemetry is exposed by the
agent. See the following for the list of metrics.
When set to prometheus, the Logging agent exposes metrics in
Prometheus format on the Prometheus endpoint (localhost:24231/metrics by
default; see
prometheus and prometheus_monitor plugin configuration for
details on customizing this). On Compute Engine VMs, in order for those
metrics to be written to the Monitoring API, the
Monitoring agent has
to be installed and running as well.
When set to opencensus (default since
v1.6.25),
the Logging agent directly writes its own health metrics to the
Monitoring API. This requires the roles/monitoring.metricWriter
role to be granted to the
Compute Engine default service account,
even if the Monitoring agent is not installed.
The following metrics are written to the Monitoring API by both
the Monitoring agent and the Logging agent in
opencensus mode:
agent.googleapis.com/agent/uptimewith aversionlabel: Uptime of the Logging agent.agent.googleapis.com/agent/log_entry_countwith aresponse_codelabel: Count of log entries written by the Logging agent.agent.googleapis.com/agent/log_entry_retry_countwith aresponse_codelabel: Count of log entries written by the Logging agent.agent.googleapis.com/agent/request_countwith aresponse_codelabel: Count of API requests from the Logging agent.
These metrics are described in more detail on the Agent metrics page.
In addition, the following Prometheus metrics are exposed by the output plugin
in prometheus mode:
uptimewith aversionlabel: Uptime of the Logging agent.stackdriver_successful_requests_countwithgrpcandcodelabels: The number of successful requests to the Logging API.stackdriver_failed_requests_countwithgrpcandcodelabels: The number of failed requests to the Logging API, broken down by the error code.stackdriver_ingested_entries_countwithgrpcandcodelabels: The number of log entries ingested by the Logging API.stackdriver_dropped_entries_countwithgrpcandcodelabels: The number of log entries rejected by the Logging API.stackdriver_retried_entries_countwithgrpcandcodelabels: The number of log entries that failed to be ingested by the Google Cloudfluentdoutput plugin due to a transient error and were retried.
prometheus and prometheus_monitor plugin configuration
Configuration file locations:
/etc/google-fluentd/google-fluentd.confDescription: This file includes configuration options to control the behavior of the
prometheusandprometheus_monitorplugins. Theprometheus_monitorplugin monitors Fluentd's core infrastructure. Theprometheusplugin exposes the metrics including the ones from theprometheus_monitorplugin and the ones from thegoogle_cloudplugin above via a local port in Prometheus format. See more details at https://docs.fluentd.org/deployment/monitoring-prometheus.Go to the config repository.
For monitoring Fluentd, the built-in Prometheus http metrics server is enabled by default. You can remove the following section from the configuration to stop this endpoint from starting:
# Prometheus monitoring.
<source>
@type prometheus
port 24231
</source>
<source>
@type prometheus_monitor
</source>
Processing payloads
Most of the supported logs under the default configuration of the Logging agent are from log files and are ingested as unstructured (text) payloads in the log entries.
The only exception is that the in_forward input plugin, which is also enabled
by default, only accepts structured logs and ingests them as structured
(JSON) payloads in the log entries. For details, read
Streaming structured (JSON) log records via in_forward plugin
on this page.
When the log line is a serialized JSON object and the
detect_json option is enabled, the output plugin transforms
the log entry into a structured (JSON) payload. This option is enabled by
default in VM instances running on App Engine flexible environment and
Google Kubernetes Engine. This option isn't enabled by default in VM instances
running on App Engine standard environment. Any JSON parsed with the
detect_json option enabled is always ingested as
jsonPayload.
You can customize the agents's configuration to support ingesting structured logs from additional resources. See Streaming structured (JSON) log records to Cloud Logging for details.
The payload of log records streamed by a custom-configured
Logging agent can be either
a single unstructured text message (textPayload) or a structured JSON message
(jsonPayload).
Special fields in structured payloads
When the Logging agent receives a structured log record, it moves any key that
matches the following table into the corresponding field in the
LogEntry object. Otherwise, the key becomes part of the
LogEntry.jsonPayload field. This behavior lets you set specific fields in the
LogEntry object, which is what is written to the Logging API.
For example, if the structured log record contains a key of severity,
then the Logging agent populates the LogEntry.severity field.
| JSON log field |
LogEntry
field
|
Cloud Logging agent function | Example value |
|---|---|---|---|
severity
|
severity
|
The Logging agent attempts to match a variety of common severity strings, which includes the list of LogSeverity strings recognized by the Logging API. | "severity":"ERROR"
|
message
|
textPayload
(or part of
jsonPayload)
|
The message that appears on the log entry line in the Logs Explorer. | "message":"There was an error in the application." Note: message is saved as textPayload if it is the
only field remaining after the Logging
agent moves the other special-purpose fields and
detect_json wasn't enabled; otherwise message
remains in jsonPayload. detect_json is not applicable to managed
logging environments like Google Kubernetes Engine. If your log entry contains an
exception stack trace, the exception stack trace should
be set in this message JSON log field, so that the exception
stack trace can be parsed and saved to Error Reporting. |
log
(legacy
Google Kubernetes Engine
only) |
textPayload
|
Only applies to legacy Google Kubernetes Engine:
if, after moving special purpose
fields, only a log field remains, then
that field is saved as textPayload. |
|
httpRequest
|
httpRequest
|
A structured record in the format
of the LogEntry
HttpRequest field. |
"httpRequest":{"requestMethod":"GET"}
|
| time-related fields | timestamp
|
For more information, see Time-related fields. | "time":"2020-10-12T07:20:50.52Z"
|
logging.googleapis.com/insertId
|
insertId
|
For more information,
see insertId
on the LogEntry page. |
"logging.googleapis.com/insertId":"42"
|
logging.googleapis.com/labels
|
labels
|
The value of this field
must be a structured record.
For more information, see
labels on
the LogEntry page. |
"logging.googleapis.com/labels":
{"user_label_1":"value_1","user_label_2":"value_2"}
|
logging.googleapis.com/operation
|
operation
|
The value of this field
is also used by
the Logs Explorer to
group related log entries.
For more information,
see operation on
the LogEntry page. |
"logging.googleapis.com/operation":
{"id":"get_data","producer":"github.com/MyProject/MyApplication",
"first":"true"}
|
logging.googleapis.com/sourceLocation
|
sourceLocation
|
Source code location
information associated
with the log entry,
if any.
For more information,
see LogEntrySourceLocation
on the LogEntry page. |
"logging.googleapis.com/sourceLocation":
{"file":"get_data.py","line":"142","function":"getData"}
|
logging.googleapis.com/spanId
|
spanId
|
The span ID within the
trace associated with
the log entry.
For more information,
see spanId
on the LogEntry page. |
"logging.googleapis.com/spanId":"000000000000004a"
|
logging.googleapis.com/trace
|
trace
|
Resource name of the trace
associated with
the log entry
if any.
For more information,
see trace
on the LogEntry page.
|
"logging.googleapis.com/trace":"projects/my-projectid/traces/0679686673a" Note: If not writing to stdout or stderr,
the value of this field should be formatted as
projects/[PROJECT-ID]/traces/[TRACE-ID],
so it can be used by the Logs Explorer and
the Trace Viewer to group log entries
and display them in line with traces.
If autoformat_stackdriver_trace is true and
[V] matches the format of ResourceTrace
traceId the LogEntry trace field has the value
projects/[PROJECT-ID]/traces/[V]. |
logging.googleapis.com/trace_sampled
|
traceSampled
|
The value of this field
must be either true or
false.
For more information,
see traceSampled
on the LogEntry page. |
"logging.googleapis.com/trace_sampled": false
|
Time-related fields
In general, time-related information about a log entry is stored in the
timestamp
field of the LogEntry object:
{
insertId: "1ad8d08f-6529-47ea-832e-467f869a2da4"
...
resource: {2}
timestamp: "2023-10-30T16:33:15.505196Z"
}
When the source for a log entry is structured data, the
Logging agent uses the following rules to search the fields in the
jsonPayload entry for time-related information:
Search for a
timestampfield that is a JSON object that includes thesecondsandnanosfields, representing, respectively, a signed number of seconds from the UTC epoch and a nonnegative number of fractional seconds:jsonPayload: { ... "timestamp": { "seconds": CURRENT_SECONDS, "nanos": CURRENT_NANOS } }If the previous search fails, then search for a pair of
timestampSecondsandtimestampNanosfields:jsonPayload: { ... "timestampSeconds": CURRENT_SECONDS, "timestampNanos": CURRENT_NANOS }If the previous search fails, then search for a
timefield that is a string in RFC 3339 format:jsonPayload: { ... "time": CURRENT_TIME_RFC3339 }
When time-related information is found, the Logging agent uses that information
to set the value of the LogEntry.timestamp, and it doesn't copy that
information from the structured record into the LogEntry.jsonPayload object.
Time-related fields that aren't used to set the value of the
LogEntry.timestamp field are copied from the structured record into the
LogEntry.jsonPayload object. For example, if the
structured record contains a timestamp JSON object and a time field,
then the data in the timestamp JSON object is used to set the
LogEntry.timestamp field. The LogEntry.jsonPayload object contains a time
field, because this field wasn't used to set the LogEntry.timestamp value.
Customizing agent configuration
Besides the list of default logs that the Logging agent streams by default, you can customize the Logging agent to send additional logs to Logging or to adjust agent settings by adding input configurations.
The configuration definitions in these sections apply to the
fluent-plugin-google-cloud output plugin only and specify how logs are
transformed and ingested into Cloud Logging.
Main configuration file locations:
- Linux:
/etc/google-fluentd/google-fluentd.conf Windows:
C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.confIf you are running a Logging agent before v1-5, the location is:
C:\GoogleStackdriverLoggingAgent\fluent.conf
- Linux:
Description: This file includes configuration options to control the
fluent-plugin-google-cloudoutput plugin's behavior.Review the config repository.
Streaming logs from additional inputs
You can customize the Logging agent to send additional logs to Logging by adding input configurations.
Streaming unstructured (text) logs via log files
From the Linux command prompt, create a log file:
touch /tmp/test-unstructured-log.logCreate a new configuration file labeled
test-unstructured-log.confin the additional configuration directory/etc/google-fluentd/config.d:sudo tee /etc/google-fluentd/config.d/test-unstructured-log.conf <<EOF <source> @type tail <parse> # 'none' indicates the log is unstructured (text). @type none </parse> # The path of the log file. path /tmp/test-unstructured-log.log # The path of the position file that records where in the log file # we have processed already. This is useful when the agent # restarts. pos_file /var/lib/google-fluentd/pos/test-unstructured-log.pos read_from_head true # The log tag for this log input. tag unstructured-log </source> EOFAn alternative to creating a new file, is to add the configuration information to an existing configuration file.
Restart the agent to apply the configuration changes:
sudo service google-fluentd restartGenerate a log record into the log file:
echo 'This is a log from the log file at test-unstructured-log.log' >> /tmp/test-unstructured-log.logCheck the Logs Explorer to see the ingested log entry:
{ insertId: "eps2n7g1hq99qp" labels: { compute.googleapis.com/resource_name: "add-unstructured-log-resource" } logName: "projects/my-sample-project-12345/logs/unstructured-log" receiveTimestamp: "2018-03-21T01:47:11.475065313Z" resource: { labels: { instance_id: "3914079432219560274" project_id: "my-sample-project-12345" zone: "us-central1-c" } type: "gce_instance" } textPayload: "This is a log from the log file at test-unstructured-log.log" timestamp: "2018-03-21T01:47:05.051902169Z" }
Streaming structured (JSON) logs via log files
You can configure the Logging agent to require each log entry for certain log inputs to be structured. You can also customize the Logging agent to ingest JSON formatted content from a log file. When the agent is configured to ingest JSON content, the input must be formatted so that each JSON object is on a newline:
{"name" : "zeeshan", "age" : 28}
{"name" : "reeba", "age" : 15}
To configure the Logging agent to ingest JSON formatted content, do the following:
From the Linux command prompt, create a log file:
touch /tmp/test-structured-log.logCreate a new configuration file labeled
test-structured-log.confin the additional configuration directory/etc/google-fluentd/config.d:sudo tee /etc/google-fluentd/config.d/test-structured-log.conf <<EOF <source> @type tail <parse> # 'json' indicates the log is structured (JSON). @type json </parse> # The path of the log file. path /tmp/test-structured-log.log # The path of the position file that records where in the log file # we have processed already. This is useful when the agent # restarts. pos_file /var/lib/google-fluentd/pos/test-structured-log.pos read_from_head true # The log tag for this log input. tag structured-log </source> EOFAn alternative to creating a new file, is to add the configuration information to an existing configuration file.
Restart the agent to apply the configuration changes:
sudo service google-fluentd restartGenerate a log record into the log file:
echo '{"code": "structured-log-code", "message": "This is a log from the log file at test-structured-log.log"}' >> /tmp/test-structured-log.logCheck the Logs Explorer to see the ingested log entry:
{ insertId: "1m9mtk4g3mwilhp" jsonPayload: { code: "structured-log-code" message: "This is a log from the log file at test-structured-log.log" } labels: { compute.googleapis.com/resource_name: "add-structured-log-resource" } logName: "projects/my-sample-project-12345/logs/structured-log" receiveTimestamp: "2018-03-21T01:53:41.118200931Z" resource: { labels: { instance_id: "5351724540900470204" project_id: "my-sample-project-12345" zone: "us-central1-c" } type: "gce_instance" } timestamp: "2018-03-21T01:53:39.071920609Z" }In the Logs Explorer, filter by your resource type and a logName of
structured-log.
For additional options to customize your log input format for common third-party applications, see Common Log Formats and How To Parse Them.
Streaming structured (JSON) logs via in_forward plugin
Additionally, you can send logs via the fluentd in_forward plugin.
fluentd-cat is a built-in tool that helps easily send logs to the in_forward
plugin. The
fluentd documentation
contains more details for this tool.
To send logs via the fluentd in_forward plugin, read the following
instructions:
Execute the following command on the VM with the Logging agent installed:
echo '{"code": "send-log-via-fluent-cat", "message": "This is a log from in_forward plugin."}' | /opt/google-fluentd/embedded/bin/fluent-cat log-via-in-forward-pluginCheck the Logs Explorer to see the ingested log entry:
{ insertId: "1kvvmhsg1ib4689" jsonPayload: { code: "send-log-via-fluent-cat" message: "This is a log from in_forward plugin." } labels: { compute.googleapis.com/resource_name: "add-structured-log-resource" } logName: "projects/my-sample-project-12345/logs/log-via-in-forward-plugin" receiveTimestamp: "2018-03-21T02:11:27.981020900Z" resource: { labels: { instance_id: "5351724540900470204" project_id: "my-sample-project-12345" zone: "us-central1-c" } type: "gce_instance" } timestamp: "2018-03-21T02:11:22.717692494Z" }
Streaming structured (JSON) log records from application code
You can enable connectors in various languages to send structured logs from
application code; for more
information, review the fluentd documentation.
These connectors are built based on the in_forward plugin.
Setting log entry labels
The following configuration options let you override LogEntry labels and MonitoredResource labels when ingesting logs to Cloud Logging. All log entries are associated with monitored resources; for more information, review the list of Cloud Logging monitored resource types.
| Configuration name | Type | Default | Description |
|---|---|---|---|
label_map |
hash | nil | label_map (specified as a JSON object) is an unordered set of fluentd field names whose values are sent as labels rather than as part of the structured payload. Each entry in the map is a {field_name: label_name} pair. When field_name (as parsed by the input plugin) is encountered, a label with the corresponding label_name is added to the log entry. The value of the field is used as the value of the label. The map gives you the additional flexibility in specifying label names, including the ability to use characters which wouldn't be legal as part of fluentd field names. For an example, go to Setting labels in structured log entries. |
labels |
hash | nil | labels (specified as a JSON object) is a set of custom labels provided at configuration time. It allows you to inject extra environmental information into every message or to customize labels otherwise detected automatically. Each entry in the map is a {label_name: label_value} pair. |
The Logging agent output plugin supports three ways to set LogEntry labels:
- Dynamically, replacing specific labels in a structured entry with different labels. For details, go to Setting labels in structured log entries on this page.
- Statically, attaching a label to any occurrence of a value. For details, go to Setting labels statically on this page.
Setting labels in structured log entries
Suppose you wrote a structured log entry payload like this:
{ "message": "This is a log message", "timestamp": "Aug 10 20:07:00", "env": "production" }
And suppose you want to translate the payload field env to a metadata
label environment. To do this, add the following to your output plugin
configuration in the main configuration file
(/etc/google-fluentd/google-fluentd.conf on Linux or
C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.conf on Windows):
# Configure all sources to output to Cloud Logging
<match **>
@type google_cloud
label_map {
"env": "environment"
}
...
</match>
The label_map setting here replaces the env label in the payload with
environment, so the resulting log entry has a label environment with
the value production.
Setting labels statically
If you don't have this information in the payload, and simply want to add a
static metadata label called environment, add the following to your output
plugin configuration in the main configuration file
(/etc/google-fluentd/google-fluentd.conf on Linux or
C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.conf on Windows):
# Configure all sources to output to Cloud Logging
<match **>
@type google_cloud
labels {
"environment": "production"
}
...
</match>
In this case, instead of using a map to replace one label with another, we use a
labels setting to attach a label with a given literal value to a log entry,
regardless of whether the entry already has a label or not. This approach can be
used even if you are sending unstructured logs.
For more on how to configure labels, label_map and other
Logging agent settings, go to
Setting Log Entry Labels on this page.
Modifying Log Records
Fluentd provides built-in filter plugins that can be used to modify log entries.
The most commonly used filter plugin is filter_record_transformer. It enables
you to:
- Add new fields to log entries
- Update fields in log entries
- Delete fields in log entries
Some output plugins also let you modify log entries.
The fluent-plugin-record-reformer output plugin provides functionality similar to
the filter_record_transformer
filter plugin, except that it also allows you to modify log tags.
More resource usage is expected with this plugin: each time a log tag is
updated, it generates a new log entry with the new tag.
Note that the tag field in the configuration is required; we also
recommend that you modify this field to avoid entering a dead loop.
The fluent-plugin-detect-exceptions output plugin scans a log stream, either
unstructured (text) or JSON-format log records, for multi-line exception stack
traces. If a consecutive sequence of log entries forms an exception stack trace,
the log entries are forwarded as a single, combined log message. Otherwise,
the log entry is forwarded as it was.
Advanced (non-default) configuration definitions
If you want to customize the configuration of your Logging agent, beyond its default configuration, continue to read this page.
Buffer-related configuration options
The following configuration options let you adjust the Logging agent's internal buffering mechanism.
| Configuration name | Type | Default | Description |
|---|---|---|---|
buffer_type |
string | buf_memory |
Records that cannot be written to the Logging API fast enough are pushed into a buffer. The buffer can be in memory or in actual files. Recommended value: buf_file. The default buf_memory is fast but not persistent. There is risk of losing logs. If buffer_type is buf_file, buffer_path needs to be specified as well. |
buffer_path |
string | User-specified | The path where buffer chunks are stored. This parameter is required if buffer_type is file. This configuration must be unique to avoid a race condition. |
buffer_queue_limit |
int | 64 |
Specifies the length limit of the chunk queue. When the buffer queue reaches this many chunks, the buffer behavior is controlled by buffer_queue_full_action. By default, it throws exceptions. This option in combination with buffer_chunk_limit determines the maximum disk space fluentd takes for buffering. |
buffer_queue_full_action |
string | exception |
Controls the buffer behavior when the buffer queue is full. Possible values: 1. exception: Throw BufferQueueLimitError when the queue is full. How BufferQueueLimitError is handled depends on input plugins. For example, the in_tail input plugin stops reading new lines while the in_forward input plugin returns an error. 2. block: This mode stops input plugin thread until the buffer full condition is resolved. This action is a good for batch-like use cases. fluentd doesn't recommend using block action to avoid BufferQueueLimitError. If you hit BufferQueueLimitError frequently, it means your destination capacity is insufficient for your traffic. 3. drop_oldest_chunk: This mode drops the oldest chunks. |
Project- and monitored resource-related configuration options
The following configuration options let you manually specify a project and certain fields from the MonitoredResource object. These values are automatically gathered by the Logging agent; it is not recommended that you manually specify them.
| Configuration name | Type | Default | Description |
|---|---|---|---|
project_id |
string | nil | If specified, this overrides the project_id identifying the underlying Google Cloud or AWS project in which the Logging agent is running. |
zone |
string | nil | If specified, this overrides the zone. |
vm_id |
string | nil | If specified, this overrides the VM id. |
vm_name |
string | nil | If specified, this overrides the VM name. |
Other output plugin configuration options
| Configuration name | Type | Default | Description |
|---|---|---|---|
detect_json1 |
bool | false |
Whether to try to detect if the log record is a text log entry with JSON content that needs to be parsed. If this option is true, and an unstructured (text) log entry is detected as in JSON format, then it is parsed and sent as a structured (JSON) payload. |
coerce_to_utf8 |
bool | true |
Whether to allow non-UTF-8 characters in user logs. If set to true, any non-UTF-8 character would be replaced by the string specified by non_utf8_replacement_string. If set to false, any non-UTF-8 character would trigger the plugin to error out. |
require_valid_tags |
bool | false |
Whether to reject log entries with invalid tags. If this option is set to false, tags are made valid by converting any non-string tag to a string, and sanitizing any non-UTF-8 or other invalid characters. |
non_utf8_replacement_string |
string | ""(space) |
If coerce_to_utf8 is set to true, any non-UTF-8 character would be replaced by the string specified here. |
1This feature is enabled by default in VM instances running on App Engine flexible environment and Google Kubernetes Engine.
Applying customized agent configuration
Customizing the Logging agent allows you to add your own
fluentd configuration files:
Linux instance
Copy your configuration files into the following directory:
/etc/google-fluentd/config.d/The Logging agent installation script populates this directory with the default catch-all configuration files. For more information, see Getting the Logging agent source code.
Optional. Validate your configuration change by running the following command:
sudo service google-fluentd configtestRestart the agent by running the following command:
sudo service google-fluentd force-reload
Windows instance
Copy your config files into the
config.dsubdirectory of your agent-installation directory. If you accepted the default installation directory, this directory is:C:\Program Files (x86)\Stackdriver\LoggingAgent\config.d\Restart the agent by running the following commands in a command-line shell:
net stop StackdriverLogging net start StackdriverLogging
For more information on fluentd configuration files, see
fluentd's Configuration File Syntax documentation.