Die meisten Load Balancer nutzen Round-Robin-Hashing oder ablaufbasiertes Hashing, um den Traffic zu verteilen. Load-Balancers, die nach dieser Methode arbeiten, haben jedoch Schwierigkeiten, wenn der Bedarf die verfügbare Bereitstellungskapazität übersteigt. In diesem Artikel wird erläutert, wie Sie diese Probleme durch die Verwendung von Cloud Load Balancing lösen und die globale Anwendungskapazität optimieren können. Dies führt häufig zu einer nutzerfreundlicheren Umgebung und geringeren Kosten als bei traditionellen Load-Balancing-Lösungen.
Dieser Artikel ist Teil einer Reihe mit Best Practices für die Cloud Load Balancing-Produkte von Google. Ergänzende Informationen zu diesem Artikel finden Sie in der Anleitung zur Kapazitätsverwaltung mit Lastenausgleich. Ausführliche Informationen zur Latenz finden Sie unter Anwendungslatenz mithilfe von Load-Balancing optimieren.
Kapazitätsprobleme bei globalen Anwendungen
Die Skalierung von globalen Anwendungen kann eine echte Herausforderung sein, insbesondere wenn das IT-Budget begrenzt ist und unkalkulierbare Arbeitslasten mit sporadischen Lastspitzen auftreten. In öffentlichen Cloud-Umgebungen wie Google Cloudbieten Funktionen wie Autoscaling und Load Balancing mehr Flexibilität. Autoscaling unterliegt jedoch einigen Einschränkungen, die in diesem Abschnitt erläutert werden.
Latenz beim Starten neuer Instanzen
Das häufigste Problem bei der automatischen Skalierung besteht darin, dass die angeforderte Anwendung den Traffic nicht schnell genug bereitstellt. Abhängig von den Images der VM-Instanzen müssen normalerweise Skripts ausgeführt und Informationen geladen werden, bevor VM-Instanzen bereit sind. Es dauert oft einige Minuten, bis die Lastenausgleichsmodule Nutzer zu neuen VM-Instanzen weiterleiten können. In dieser Zeit wird der Traffic auf die vorhandenen VM-Instanzen verteilt, die möglicherweise bereits überlastet sind.
Durch Back-End-Kapazität eingeschränkte Anwendungen
Manche Anwendungen können gar nicht automatisch skaliert werden. Datenbanken etwa verfügen oft über eine eingeschränkte Back-End-Kapazität. Nur eine bestimmte Anzahl von Front-Ends kann auf eine Datenbank zugreifen, die nicht automatisch horizontal skaliert wird. Wenn die Anwendung externe APIs benötigt und diese nur eine begrenzte Anzahl von Requests pro Sekunde unterstützen, kann die Anwendung ebenfalls nicht automatisch skaliert werden.
Nicht elastische Lizenzen
Wenn Sie lizenzierte Software verwenden, umfasst die Lizenz oft nur eine voreingestellte maximale Kapazität. Sie können deshalb möglicherweise nur eingeschränkt automatisch skalieren, da Lizenzen nicht spontan hinzugefügt werden können.
Zu geringer Toleranzbereich für VM-Instanzen
Zum Auffangen plötzlicher Traffic-Bursts sollte die automatische Skalierung einen entsprechend großen Toleranzbereich bieten (z. B. durch die Auslösung bei 70 % der CPU-Kapazität). Um Kosten zu sparen, bietet es sich auf den ersten Blick an, diesen Zielwert zu erhöhen (z. B. auf 90 % der CPU-Kapazität). Auslöserwerte können jedoch beim Auftreten von Traffic-Bursts zu Skalierungsengpässen führen, etwa bei plötzlich steigender Nachfrage durch eine Werbekampagne. Legen Sie den Toleranzbereich in Abhängigkeit davon fest, wie viele Lastspitzen bei Ihrem Traffic auftreten und wie lange es dauert, bis neue VM-Instanzen bereit sind.
Regionale Kontingente
Wenn es in einer Region zu unerwarteten Bursts kommt, kann die Anzahl der Instanzen, die Sie skalieren können, durch die Ressourcenkontingente auf eine Anzahl begrenzt werden, die unter der erforderlichen Kapazität für die Unterstützung des aktuellen Bursts liegt. Die Bearbeitungszeit zum Erhöhen des Ressourcenkontingents kann einige Stunden oder Tage dauern.
Probleme durch globales Load-Balancing lösen
Die externen Application Load Balancer und externen Proxy-Netzwerk-Load Balancer sind globale Load Balancing-Produkte, die über global synchronisierte GFE-Server (Google Front End) weitergeleitet werden. Dadurch können Probleme mit diesen Load Balancing-Typen leichter gelöst werden. Diese Produkte bieten eine Lösung für die Probleme, da der Traffic auf andere Weise als bei den meisten regionalen Lastenausgleichslösungen auf die Back-Ends verteilt wird.
Die Unterschiede werden in den folgenden Abschnitten beschrieben.
Von anderen Lastenausgleichsmodulen verwendete Algorithmen
Die meisten Lastenausgleichsmodule verwenden dieselben Algorithmen, um den Traffic auf die Back-Ends zu verteilen:
- Round-Robin. Die Pakete werden unabhängig von der Quelle und dem Ziel eines Pakets gleichmäßig auf alle Back-Ends verteilt.
- Hashing. Die Pakete werden anhand der Hashes für Traffic-Informationen identifiziert, z. B. Quell-IP, Ziel-IP, Port und Protokoll. Traffic mit demselben Hashwert wird zum selben Backend weitergeleitet.
Das Load-Balancing per Hashing ist der aktuell verfügbare Algorithmus für den externen Passthrough-Netzwerk-Load-Balancer. Dieses Lastenausgleichsmodul unterstützt Hashing mit 2 Tupeln (basierend auf Quell- und Ziel-IP), Hashing mit 3 Tupeln (basierend auf Quell-IP, Ziel-IP und Protokoll) und Hashing mit 5 Tupeln (basierend auf Quell-IP, Ziel-IP, Quellport, Zielport und Protokoll).
Bei beiden Algorithmen werden instabile Instanzen aus der Verteilung genommen. Die aktuelle Auslastung der Back-Ends spielt bei der Lastverteilung jedoch kaum eine Rolle.
Einige Hardware- oder Software-Lastenausgleichsmodule verwenden Algorithmen, die den Traffic anhand von anderen Metriken weiterleiten, z. B. Round-Robin mit Gewichtung, niedrigste Last, schnellste Antwortzeit oder Anzahl von aktiven Verbindungen. Wenn die Last aufgrund von plötzlichen Traffic-Bursts jedoch das erwartete Maß übersteigt, wird der Traffic auch weiter an die überlasteten Back-End-Instanzen verteilt, sodass die Latenz spürbar zunimmt.
Einige Lastenausgleichsmodule unterstützen erweiterte Regeln, in denen Traffic, der die Kapazität des Back-Ends übersteigt, an einen anderen Pool oder an eine statische Website weitergeleitet wird. Auf diese Weise können Sie diesen Traffic effektiv ablehnen und eine Meldung des Typs "Der Dienst ist nicht verfügbar. Bitte versuchen Sie es später noch einmal." senden. Bei einigen Lastenausgleichsmodulen haben Sie die Möglichkeit, Requests in eine Warteschlange zu stellen.
Globale Load Balancing-Lösungen werden oft mit einem DNS-basierten Algorithmus implementiert, der dazu führt, dass verschiedene regionale Load Balancing-IPs basierend auf dem Standort des Nutzers und der Back-End-Last bereitgestellt werden. Diese Lösungen ermöglichen für den gesamten oder einen Teil des Traffics einer regionalen Bereitstellung die Durchführung eines Failovers in eine andere Region. Bei jeder DNS-basierten Lösung dauert das Failover abhängig von der Gültigkeitsdauer (TTL) der DNS-Einträge jedoch einige Minuten. Im Allgemeinen wird ein kleiner Teil des Traffics auch eine Weile nach Ablauf der TTL noch an die alten Server geleitet. Der DNS-basierte globale Lastenausgleich ist deshalb keine optimale Lösung für den Umgang mit Traffic in Burst-Szenarien.
Funktionsweise von externen Application Load Balancern
Der externe Application Load Balancer verwendet einen anderen Ansatz. Der Traffic wird über GFE-Server geleitet, die an den meisten Standorten am Rand des weltweiten Netzwerks von Google bereitgestellt werden. Aktuell sind dies mehr als 80 Standorte auf der ganzen Welt. Der Load-Balancing-Algorithmus wird auf den GFE-Servern angewendet.

Der externe Application Load Balancer ist über eine einzige stabile IP-Adresse verfügbar, die global in den Edge-Knoten angegeben wird. Die Verbindungen werden von einem der GFEs beendet.
Die GFEs sind über das weltweite Netzwerk von Google miteinander verbunden. Über eine globale Steuerungsebene werden Daten mit Angaben zu den verfügbaren Back-Ends und der verfügbaren Bereitstellungskapazität der einzelnen Load-Balancing-Ressourcen kontinuierlich an alle GFEs verteilt.
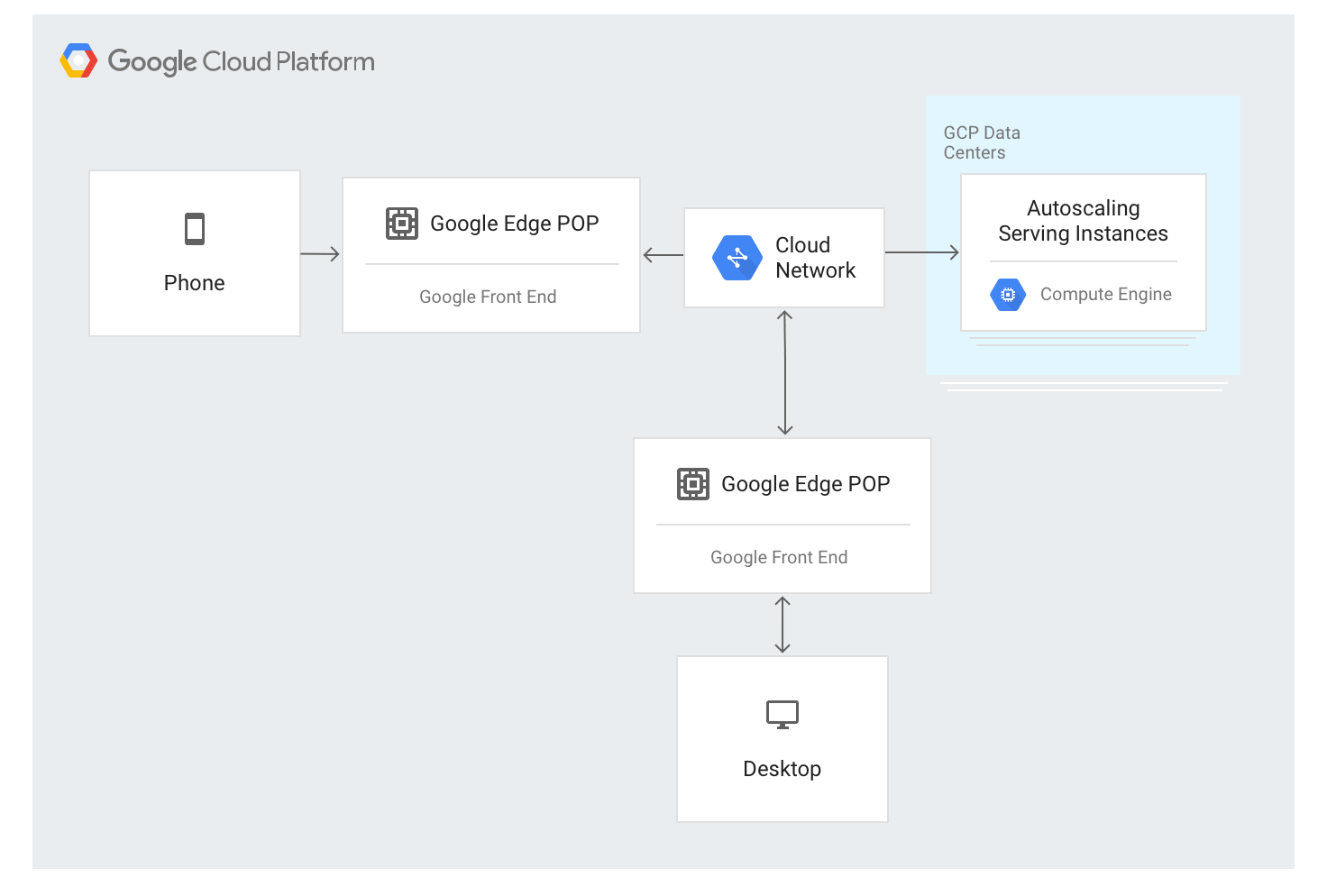
Der Traffic an IP-Adressen mit Load-Balancing wird an Backend-Instanzen weitergeleitet, die in der Konfiguration des externen Application Load Balancers definiert werden. Dazu wird der spezielle Load-Balancing-Algorithmus Wasserfall nach Region verwendet. Dieser Algorithmus bestimmt das optimale Backend für die Bereitstellung des Requests und berücksichtigt dabei die Nähe der Instanzen zum Nutzer, die eingehende Last und die verfügbare Kapazität der Backends in den einzelnen Zonen und Regionen. Selbst die Auslastung und Kapazität weltweit wird berücksichtigt.
Der externe Application Load Balancer verteilt den Traffic anhand der verfügbaren Instanzen. Der Algorithmus arbeitet mit der automatischen Skalierung von Instanzgruppen zusammen, um neue Instanzen lastenabhängig hinzuzufügen.
Traffic-Fluss in einer Region
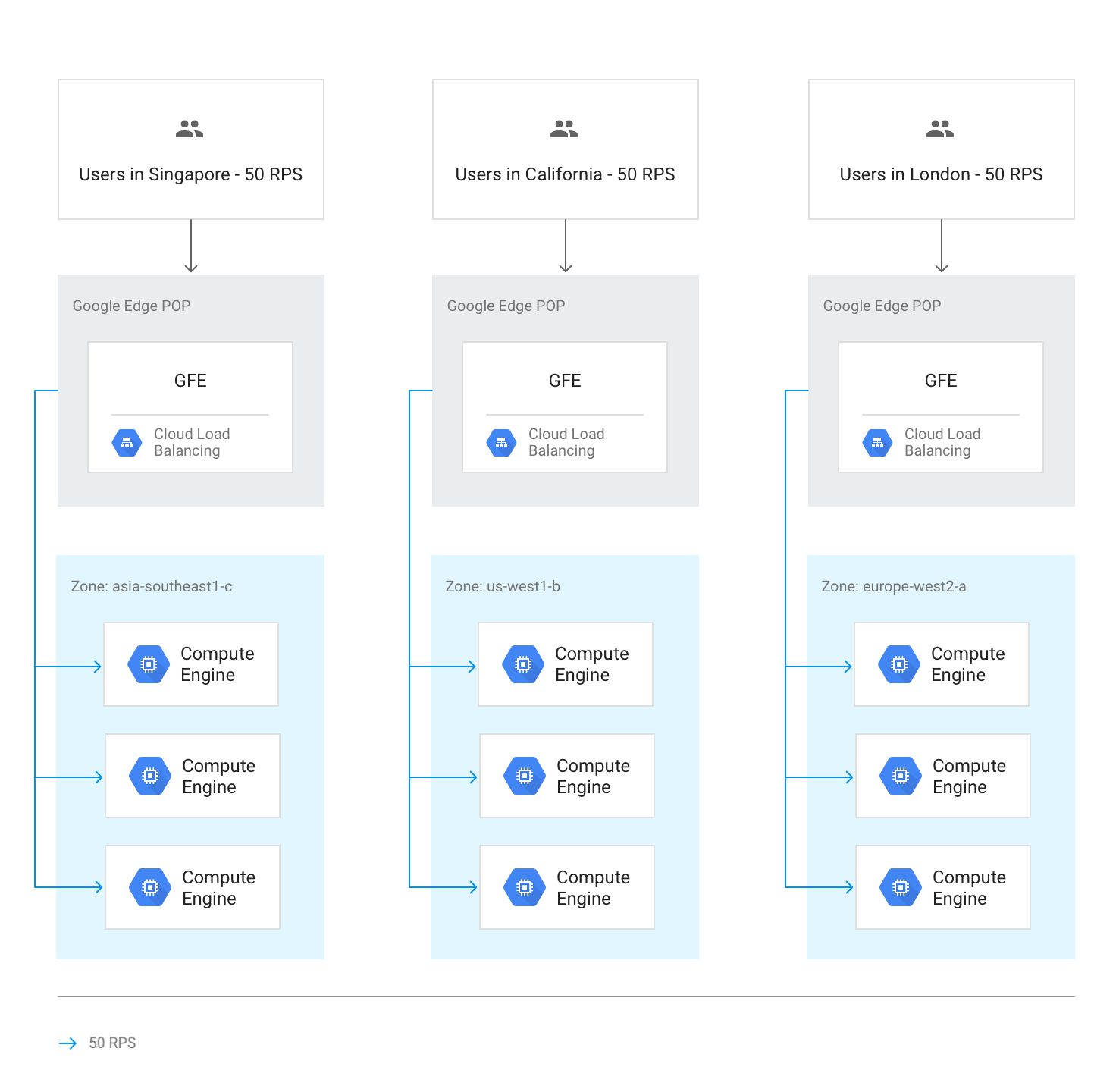
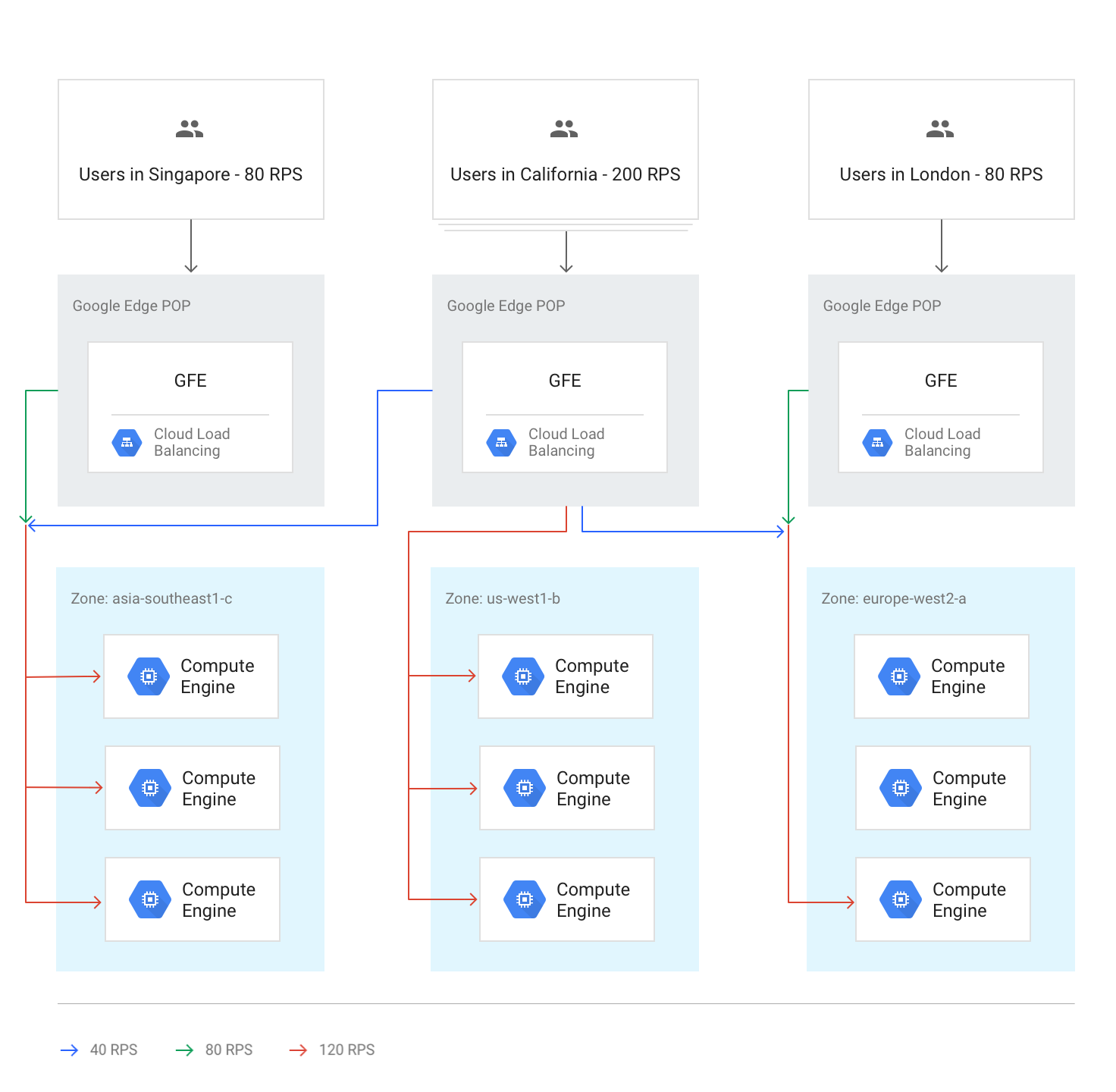
Unter normalen Umständen wird der gesamte Traffic an die Region gesendet, die dem Nutzer am nächsten ist. Der Lastenausgleich erfolgt dann nach den folgenden Richtlinien:
In jeder Region wird der Traffic auf Instanzgruppen verteilt, die sich je nach Gruppenkapazität in mehreren Zonen befinden können.
Wenn die Kapazität zwischen den Zonen ungleich verteilt ist, werden die Zonen entsprechend ihrer verfügbaren Bereitstellungskapazität ausgelastet.
In den Zonen werden Requests gleichmäßig auf die Instanzen in den einzelnen Instanzgruppen verteilt.
Sitzungen werden basierend auf der Client-IP-Adresse oder dem Wert eines Cookies und abhängig von der Einstellung der Sitzungsaffinität beibehalten.
Vorhandene TCP-Verbindungen werden nur dann zu einem anderen Back-End verschoben, wenn das Back-End nicht mehr verfügbar ist.
Im folgenden Diagramm wird die Lastverteilung in diesem Fall gezeigt, wobei jede Region über ausreichend Kapazität verfügt, um die Last der Nutzer zu übernehmen, die dieser Region am nächsten sind.
Traffic-Überlauf in andere Regionen
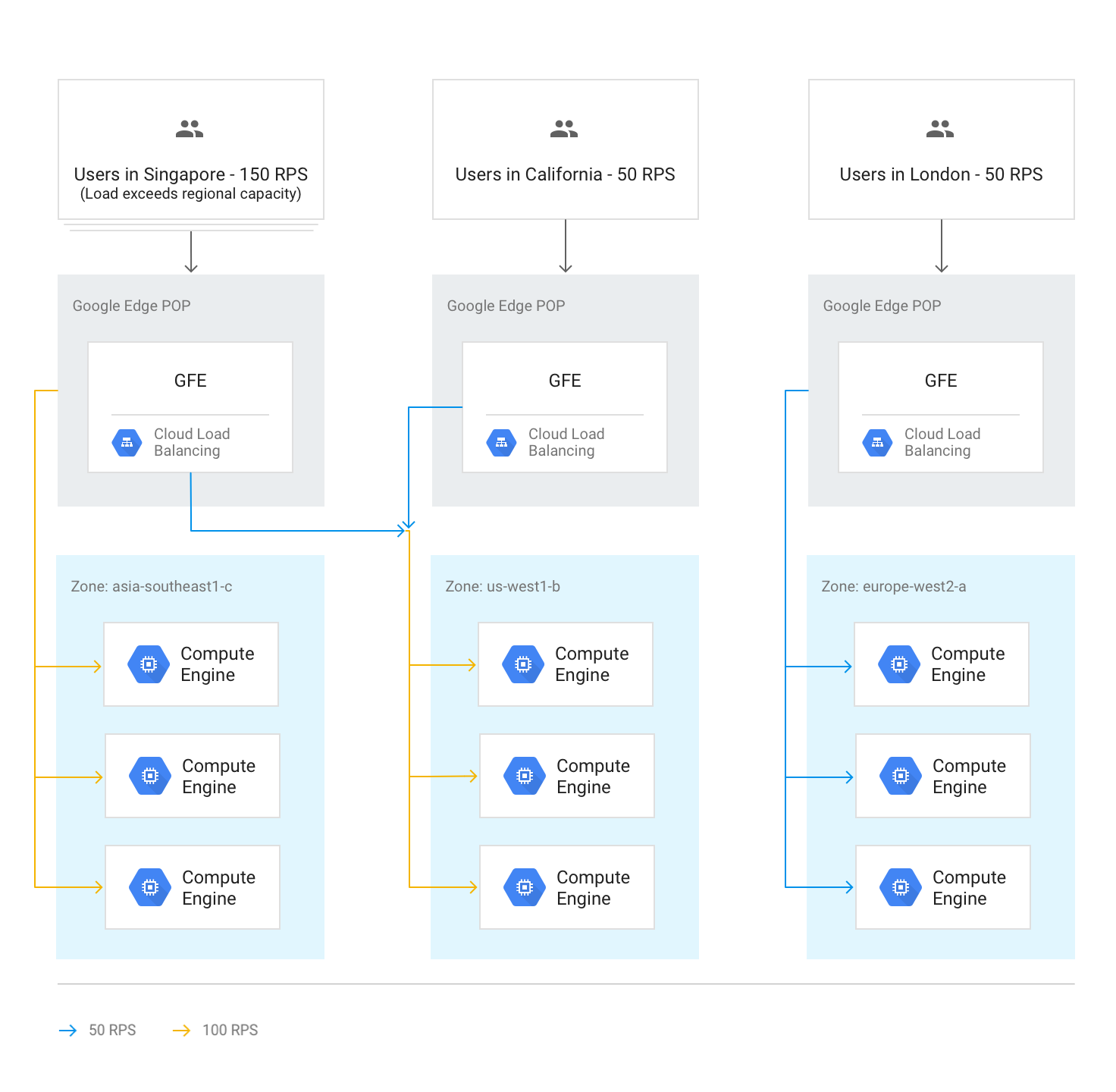
Wenn eine ganze Region die zulässige Kapazität ausschöpft, die in der Einstellung für die Bereitstellungskapazität in den Back-End-Diensten angegeben wurde, wird der Algorithmus "Wasserfall nach Region" ausgelöst. Daraufhin läuft der Traffic in die nächstgelegene Region mit verfügbarer Kapazität über. Sobald die Kapazitätsgrenze für eine Region erreicht ist, läuft der Traffic in die nächstgelegene Region über usw. Die Nähe einer Region zum Nutzer wird über die Netzwerkumlaufzeit vom GFE zu den Back-Ends der Instanzen definiert.
Im folgenden Diagramm wird der Überlauf zur nächstgelegenen Region gezeigt, wenn eine Region mehr Traffic empfängt, als sie regional verarbeiten kann.
Regionsübergreifender Überlauf bei fehlerhaften Back-Ends
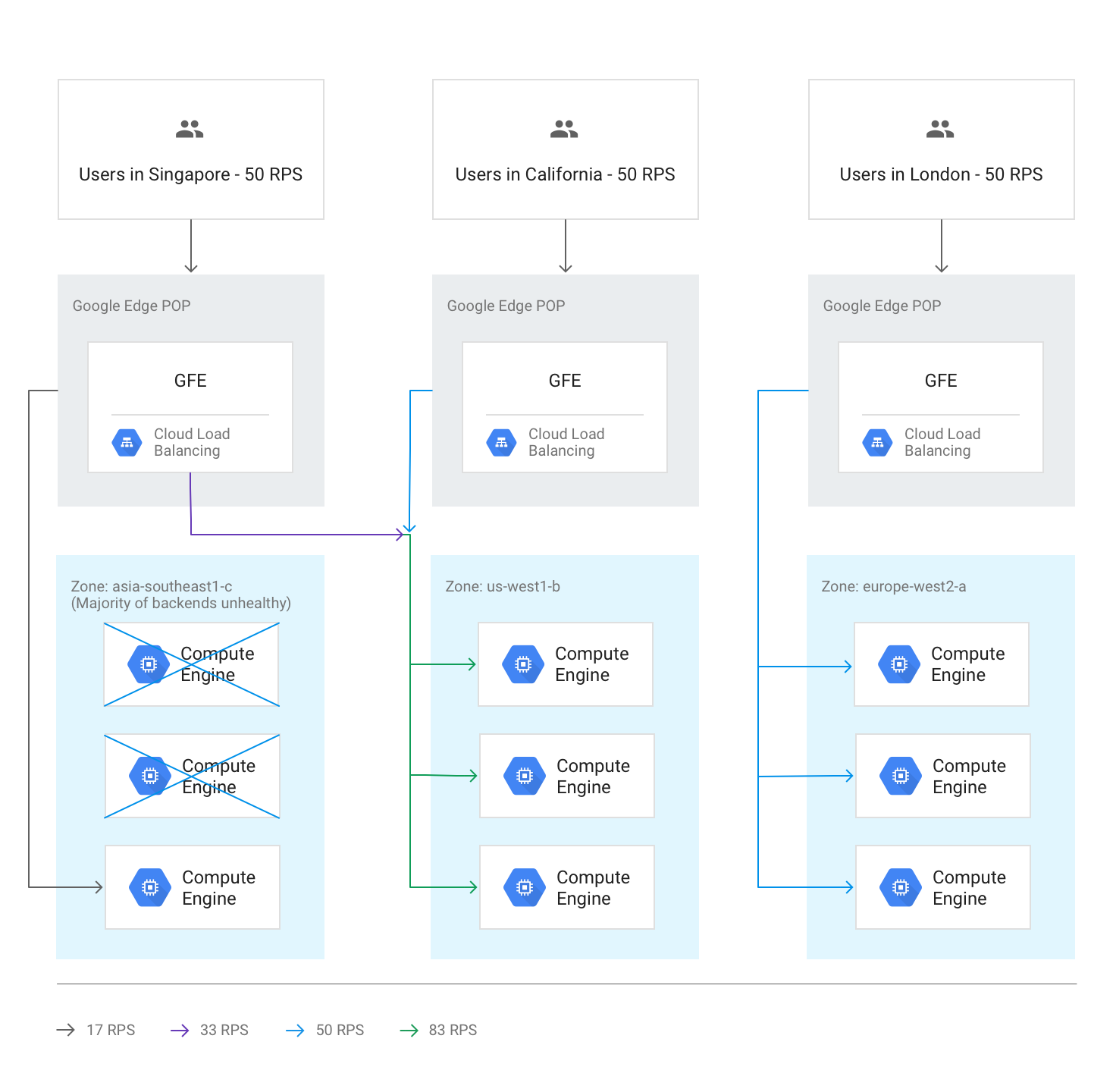
Wenn bei der Systemdiagnose festgestellt wird, dass mehr als die Hälfte der Back-Ends in einer Region fehlerhaft sind, lassen die GFEs präemptiv einen Teil des Traffics in die nächstgelegene Region überlaufen. Dadurch soll verhindert werden, dass der Traffic vollständig zum Erliegen kommt, wenn die Region nicht mehr intakt ist. Der Überlauf findet auch dann statt, wenn die verbleibende Kapazität in der Region mit den fehlerhaften Back-Ends ausreichend ist.
Im folgenden Diagramm wird der Überlaufmechanismus in Aktion gezeigt, nachdem die meisten Back-Ends in einer Zone fehlerhaft geworden sind.
Alle Regionen über der Kapazitätsgrenze
Wenn der Traffic in allen Regionen die Kapazitätsgrenze erreicht oder übersteigt, wird er so ausgeglichen, dass jede Region denselben relativen Überlaufpegel im Vergleich zu ihrer Kapazität aufweist. Wenn beispielsweise der Gesamtbedarf die Gesamtkapazität um 20 % überschreitet, wird der Traffic so verteilt, dass alle Regionen Requests über 20 % ihrer regionalen Kapazität erhalten. Dennoch wird der Traffic so lokal wie möglich verteilt.
Im folgenden Diagramm wird die globale Überlaufregel in Aktion gezeigt. In diesem Fall empfängt eine einzelne Region so viel Traffic, dass dieser auch mit der global verfügbaren Bereitstellungskapazität nicht verteilt werden kann.
Temporärer Überlauf beim Autoscaling
Die automatische Skalierung basiert auf den Kapazitätsgrenzen, die für die einzelnen Back-End-Dienste konfiguriert wurden. Es werden neue Instanzen erstellt, wenn der Traffic sich den konfigurierten Kapazitätsgrenzen nähert. Abhängig davon, wie schnell die Requests zunehmen und wie schnell neue Instanzen online bereitstehen, ist möglicherweise kein Überlauf in andere Regionen erforderlich. Falls es doch zum Überlauf kommt, kann dieser als temporärer Puffer dienen, bis neue lokale Instanzen online und für die Bereitstellung von Live-Traffic verfügbar sind. Sobald die durch die automatische Skalierung erweiterte Kapazität ausreicht, werden alle neuen Sitzungen auf die nächstgelegene Region verteilt.
Latenzeffekte beim Überlauf
Der Algorithmus „Wasserfall nach Region“ kann zum Überlauf eines Traffic-Teils durch den externen Application Load Balancer in andere Regionen führen. TCP-Sitzungen und SSL-Traffic werden jedoch weiter vom GFE, der dem Nutzer am nächsten ist, beendet. Dies ist vorteilhaft für die Anwendungslatenz. Weitere Informationen dazu finden Sie unter Anwendungslatenz durch Lastenausgleich optimieren.
Praxis: Auswirkungen der Kapazitätsverwaltung messen
Lesen Sie die Anleitung zur Kapazitätsverwaltung mit Load-Balancing, die als Begleitmaterial zu diesem Artikel verfügbar ist, um zu erfahren, wie es zum Überlauf kommt und wie Sie diesen mit dem HTTP-Load-Balancer verwalten können.
Externen Application Load Balancer zum Behandeln von Kapazitätsproblemen verwenden
Zur Lösung der zuvor erläuterten Herausforderungen können externe Application Load Balancer und externe Proxy-Netzwerk-Load-Balancer die Kapazität in andere Regionen überlaufen lassen. Bei globalen Anwendungen ist eine leicht erhöhte Gesamtlatenz auf Nutzerseite besser als die Verwendung eines regionalen Back-Ends. Anwendungen mit einem regionalen Backend weisen eine niedrigere Latenz auf, sie können jedoch überlastet werden.
Rufen wir uns in Erinnerung, wie ein externer Application Load Balancer dabei helfen kann, die zu Beginn des Artikels genannten Szenarien zu berücksichtigen:
Latenz beim Starten neuer Instanzen. Wenn beim Autoscaling während lokaler Traffic-Bursts nicht schnell genug Kapazität hinzugefügt werden kann, erfolgt ein Überlauf von Verbindungen in die nächstgelegene Region durch den externen Application Load Balancer. So wird erreicht, dass vorhandene Nutzersitzungen in der ursprünglichen Region in der optimalen Geschwindigkeit ausgeführt werden, da sie auf vorhandenen Back-Ends verbleiben. Bei neuen Nutzersitzungen kommt es nur zu einer leichten Erhöhung der Latenz. Sobald in der ursprünglichen Region weitere Back-End-Instanzen erstellt wurden, wird der neue Traffic wieder in die Region geleitet, die dem Nutzer am nächsten liegt.
Durch Back-End-Kapazität eingeschränkte Anwendungen. Bei Anwendungen, die nicht automatisch skaliert werden können, aber in mehreren Regionen zur Verfügung stehen, kann es dennoch zu einem Überlauf in die nächstgelegene Region kommen, wenn der Bedarf in einer Region die bereitgestellte Kapazität für normale Traffic-Anforderungen übersteigt.
Nicht elastische Lizenzen. Wenn die Anzahl der Softwarelizenzen beschränkt und der Lizenzpool in der aktuellen Region erschöpft ist, kann der Traffic vom externen Application Load Balancer in eine Region mit verfügbaren Lizenzen verschoben werden. Damit dies funktionieren kann, wird für die maximale Instanzenzahl die maximale Anzahl von Lizenzen bei der automatischen Skalierung festgelegt.
Zu geringer Toleranzbereich für VM-Instanzen. Da die Möglichkeit eines regionalen Überlaufs besteht, können Sie Geld sparen, indem Sie zur automatischen Skalierung einen höheren Trigger für die CPU-Auslastung festlegen. Außerdem können Sie die verfügbare Back-End-Kapazität unter dem regionalen Maximalwert konfigurieren, da durch den Überlauf in andere Regionen sichergestellt wird, dass die Gesamtkapazität immer ausreicht.
Regionale Kontingente. Wenn die Compute Engine-Ressourcenkontingente den Bedarf nicht decken, wird ein Teil des Traffics beim Überlauf durch den externen Application Load Balancer in eine Region umgeleitet, in der noch eine Skalierung innerhalb des regionalen Kontingents möglich ist.
Nächste Schritte
Auf den folgenden Seiten finden Sie weitere Informationen und Hintergrundwissen zu den Lastenausgleichsoptionen von Google:
- Anleitung zur Kapazitätsverwaltung mit Load-Balancing
- Anwendungslatenz durch Load-Balancing optimieren
- Codelab "Networking 101"
- Externer Passthrough Network Load Balancer
- Externer Application Load Balancer
- Externer Proxy-Network Load Balancer