Teradata
Le connecteur Teradata vous permet d'effectuer des opérations d'insertion, de suppression, de mise à jour et de lecture sur la base de données Teradata.
Avant de commencer
Avant d'utiliser le connecteur Teradata, effectuez les tâches suivantes :
- Dans votre projet Google Cloud :
- Assurez-vous que la connectivité réseau est configurée. Pour en savoir plus sur les schémas de réseau, consultez Connectivité réseau.
- Attribuez le rôle IAM roles/connectors.admin à l'utilisateur qui configure le connecteur.
- Attribuez les rôles IAM suivants au compte de service que vous souhaitez utiliser pour le connecteur :
roles/secretmanager.viewerroles/secretmanager.secretAccessor
Un compte de service est un type spécial de compte Google destiné à représenter un utilisateur non humain qui doit s'authentifier et obtenir les autorisations permettant d'accéder aux données des API Google. Si vous ne possédez pas de compte de service, vous devez en créer un. Le connecteur et le compte de service doivent appartenir au même projet. Pour en savoir plus, consultez Créer un compte de service.
- Activez les services suivants :
secretmanager.googleapis.com(API Secret Manager)connectors.googleapis.com(API Connectors)
Pour savoir comment activer des services, consultez Activer des services.
Si ces services ou autorisations n'ont pas encore été activés pour votre projet, vous êtes invité à les activer au moment de configurer le connecteur.
Configuration de Teradata
Pour créer une instance Teradata Vantage Express sur une VM Google Cloud, consultez Install Teradata on Google Cloud VM (Installer Teradata sur une VM Google Cloud). Si cette VM est exposée publiquement, son adresse IP externe peut être utilisée comme adresse d'hôte lorsque vous créez une connexion. Si la VM n'est pas exposée publiquement, créez une connectivité Private Service Connect et utilisez l'adresse IP de rattachement de point de terminaison réseau lorsque vous créez une connexion.
Configurer le connecteur
Une connexion est propre à une source de données. Cela signifie que si vous disposez de nombreuses sources de données, vous devez créer une connexion distincte pour chacune d'elles. Pour créer une connexion, procédez comme suit :
- Dans la console Cloud, accédez à la page Connecteurs d'intégration > Connexions, puis sélectionnez ou créez un projet Google Cloud.
- Cliquez sur + Créer pour ouvrir la page Créer une connexion.
- Dans la section Emplacement, choisissez l'emplacement de la connexion.
- Région : sélectionnez un emplacement dans la liste déroulante.
Pour obtenir la liste de toutes les régions disponibles, consultez Emplacements.
- Cliquez sur Suivant.
- Région : sélectionnez un emplacement dans la liste déroulante.
- Dans la section Détails de connexion, procédez comme suit :
- Connecteur : sélectionnez Teradata dans la liste déroulante des connecteurs disponibles.
- Version du connecteur : sélectionnez la version du connecteur dans la liste déroulante des versions disponibles.
- Dans le champ Nom de connexion, indiquez le nom de l'instance de connexion.
Les noms de connexion doivent répondre aux critères suivants :
- Ils peuvent contenir des lettres, des chiffres ou des traits d'union.
- Les lettres doivent être en minuscules.
- Ils doivent commencer par une lettre et se terminer par une lettre ou un chiffre.
- Ils ne peuvent pas dépasser 49 caractères.
- (Facultatif) Saisissez une description de l'instance de connexion.
- (Facultatif) Activez Cloud Logging, puis sélectionnez un niveau de journalisation. Par défaut, le niveau de journalisation est défini sur
Error. - Compte de service : sélectionnez un compte de service disposant des rôles requis.
- (Facultatif) Configurez les paramètres des nœuds de connexion :
- Nombre minimal de nœuds : saisissez le nombre minimal de nœuds de connexion.
- Nombre maximal de nœuds : saisissez le nombre maximal de nœuds de connexion.
Un nœud est une unité (ou instance répliquée) de connexion qui traite des transactions. Pour traiter davantage de transactions pour une connexion, vous devez disposer de plus de nœuds. À l'inverse, moins de nœuds sont nécessaires si une connexion traite moins de transactions. Pour comprendre comment les nœuds affectent la tarification de votre connecteur, consultez Tarifs des nœuds de connexion. Si vous ne saisissez aucune valeur, le nombre minimal de nœuds est défini par défaut sur 2 (pour améliorer la disponibilité) et le nombre maximal de nœuds sur 50.
- Base de données : base de données sélectionnée comme base de données par défaut lorsqu'une connexion Teradata est ouverte.
- Charset : spécifie le jeu de caractères de session pour l'encodage et le décodage des données de caractères transférées vers et depuis la base de données Teradata. La valeur par défaut est ASCII.
- (Facultatif) Cliquez sur + Ajouter une étiquette pour ajouter une étiquette à la connexion sous la forme d'une paire clé/valeur.
- Cliquez sur Suivant.
- Dans la section Destinations, saisissez des informations sur l'hôte distant (système backend) auquel vous souhaitez vous connecter.
- Type de destination : sélectionnez un type de destination.
- Pour spécifier le nom d'hôte ou l'adresse IP de la destination, sélectionnez Adresse de l'hôte, puis saisissez l'adresse dans le champ Hôte 1.
- Pour établir une connexion privée, sélectionnez Rattachement de point de terminaison, puis choisissez le rattachement requis dans la liste Rattachement de point de terminaison.
Si vous souhaitez établir une connexion publique à vos systèmes backend avec une sécurité supplémentaire, vous pouvez envisager de configurer des adresses IP sortantes statiques pour vos connexions, puis de configurer vos règles de pare-feu pour ajouter à la liste d'autorisation uniquement les adresses IP statiques spécifiques.
Pour saisir d'autres destinations, cliquez sur + Ajouter une destination.
- Cliquez sur Suivant.
- Type de destination : sélectionnez un type de destination.
-
Dans la section Authentification, saisissez les informations d'authentification.
- Sélectionnez un type d'authentification, puis saisissez les informations appropriées.
Le type d'authentification suivant est compatible avec la connexion Teradata :
- Nom d'utilisateur et mot de passe
- Cliquez sur Suivant.
Pour savoir comment configurer ce type d'authentification, consultez Configurer l'authentification.
- Sélectionnez un type d'authentification, puis saisissez les informations appropriées.
- Vérifier : vérifiez vos informations de connexion et d'authentification.
- Cliquez sur Créer.
Configurer l'authentification
Saisissez les informations en fonction de l'authentification que vous souhaitez utiliser.
- Nom d'utilisateur et mot de passe
- Nom d'utilisateur : nom d'utilisateur pour le connecteur
- Mot de passe : secret Secret Manager contenant le mot de passe associé au connecteur
Exemples de configuration de connexion
Cette section fournit des exemples de valeurs pour les différents champs que vous configurez lorsque vous créez un connecteur Teradata.
Type de connexion avec authentification de base
| Nom du champ | Détails |
|---|---|
| Emplacement | us-central1 |
| Connecteur | teradata |
| Version du connecteur | 1 |
| Nom de connexion | teradata-vm-connection |
| Activer Cloud Logging | Oui |
| Compte de service | SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com |
| Base de données | TERADATA_TESTDB |
| Charset | ASCII |
| Nombre minimal de nœuds | 2 |
| Nombre maximal de nœuds | 2 |
| Type de destination | Adresse de l'hôte |
| hôte 1 | 203.0.113.255 |
| port 1 | 1025 |
| Nom d'utilisateur | NOM D'UTILISATEUR |
| Mot de passe | MOT DE PASSE |
| Version du secret | 1 |
Entités, opérations et actions
Tous les connecteurs Integration Connectors fournissent une couche d'abstraction pour les objets de l'application connectée. Vous ne pouvez accéder aux objets d'une application que par le biais de cette abstraction. L'abstraction vous est présentée en tant qu'entités, opérations et actions.
- Entité : une entité peut être considérée comme un objet ou un ensemble de propriétés dans l'application ou le service connectés. La définition d'une entité diffère d'un connecteur à l'autre. Par exemple, dans un connecteur de base de données, les tables sont les entités, alors que dans un connecteur de serveur de fichiers, ce sont les dossiers, et dans un connecteur de système de messagerie, ce sont les files d'attente.
Toutefois, il est possible qu'un connecteur n'accepte ou ne possède aucune entité. Dans ce cas, la liste
Entitiesest vide. - Opération : une opération est l'activité que vous pouvez effectuer sur une entité. Voici les opérations possibles :
Lorsque vous sélectionnez une entité dans la liste proposée, cela génère une liste d'opérations disponibles pour l'entité. Pour obtenir une description détaillée des opérations, consultez les opérations d'entité de la tâche "Connecteurs". Cependant, si un connecteur n'accepte pas l'une des opérations d'entité, cette opération non compatible ne figure pas dans la liste
Operations. - Action : une action est une fonction de première classe mise à la disposition de l'intégration par le biais de l'interface du connecteur. Une action vous permet de modifier une ou plusieurs entités, et varie d'un connecteur à l'autre. Normalement, une action comporte des paramètres d'entrée et un paramètre de sortie. Toutefois, il est possible qu'un connecteur n'accepte aucune action, auquel cas la liste
Actionsest vide.
Actions
Ce connecteur est compatible avec l'exécution des actions suivantes :
- Fonctions et procédures stockées définies par l'utilisateur : si votre backend contient des procédures et des fonctions stockées, elles sont listées dans la colonne
Actionsde la boîte de dialogueConfigure connector task. - Requêtes SQL personnalisées : pour exécuter des requêtes SQL personnalisées, le connecteur fournit l'action Exécuter une requête personnalisée.
Pour créer une requête personnalisée, procédez comme suit :
- Suivez les instructions détaillées pour ajouter une tâche "Connecteurs".
- Lorsque vous configurez la tâche "Connecteurs", sélectionnez Actions dans le type d'action à effectuer.
- Dans la liste Action, sélectionnez Exécuter une requête personnalisée, puis cliquez sur OK.
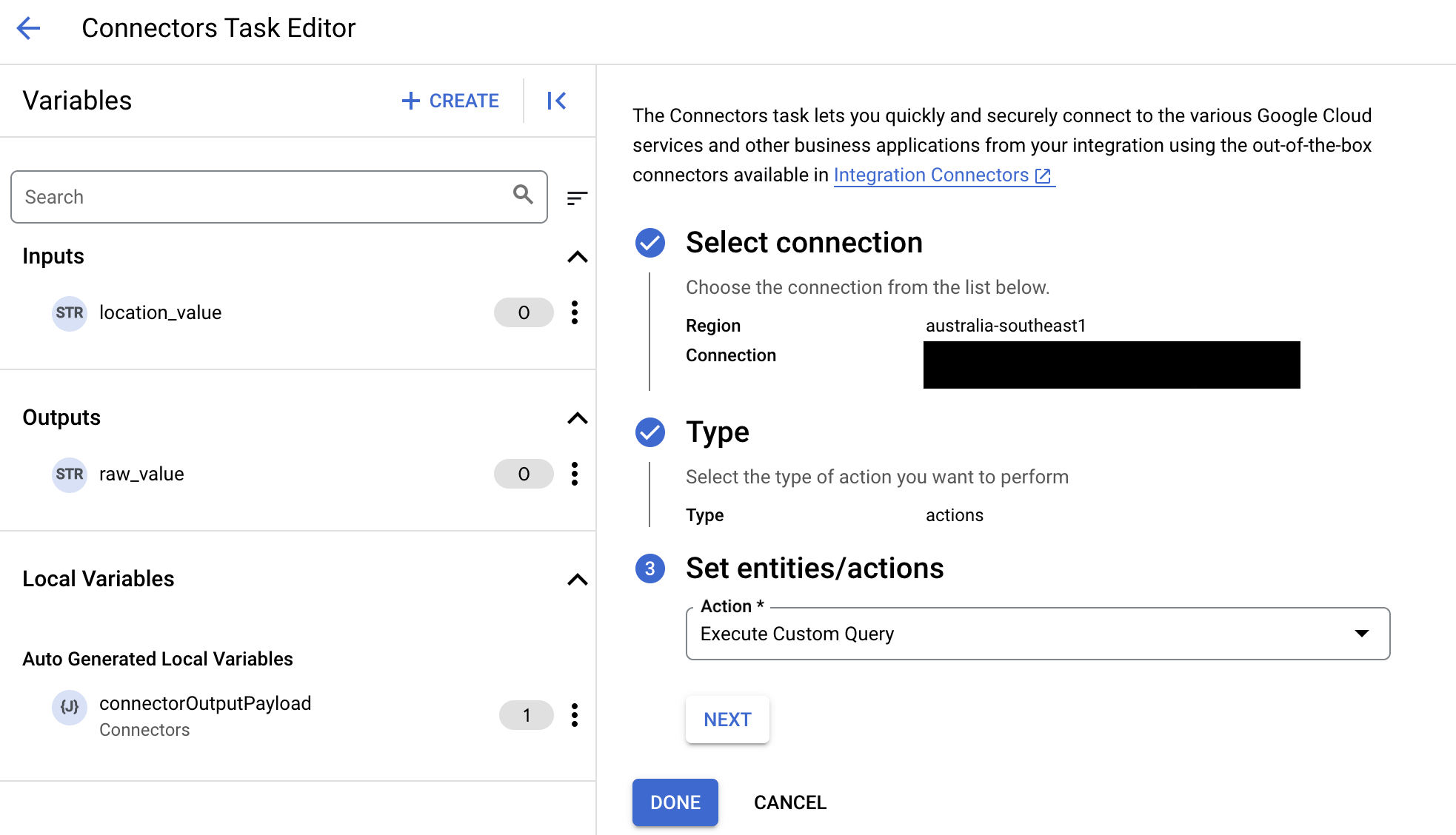
- Développez la section Entrée de la tâche, puis procédez comme suit :
- Dans le champ Délai d'inactivité après, saisissez le nombre de secondes d'attente jusqu'à l'exécution de la requête.
Valeur par défaut :
180secondes - Dans le champ Nombre maximal de lignes, saisissez le nombre maximal de lignes à renvoyer à partir de la base de données.
Valeur par défaut :
25 - Pour mettre à jour la requête personnalisée, cliquez sur Modifier le script personnalisé. La boîte de dialogue Éditeur de script s'ouvre.
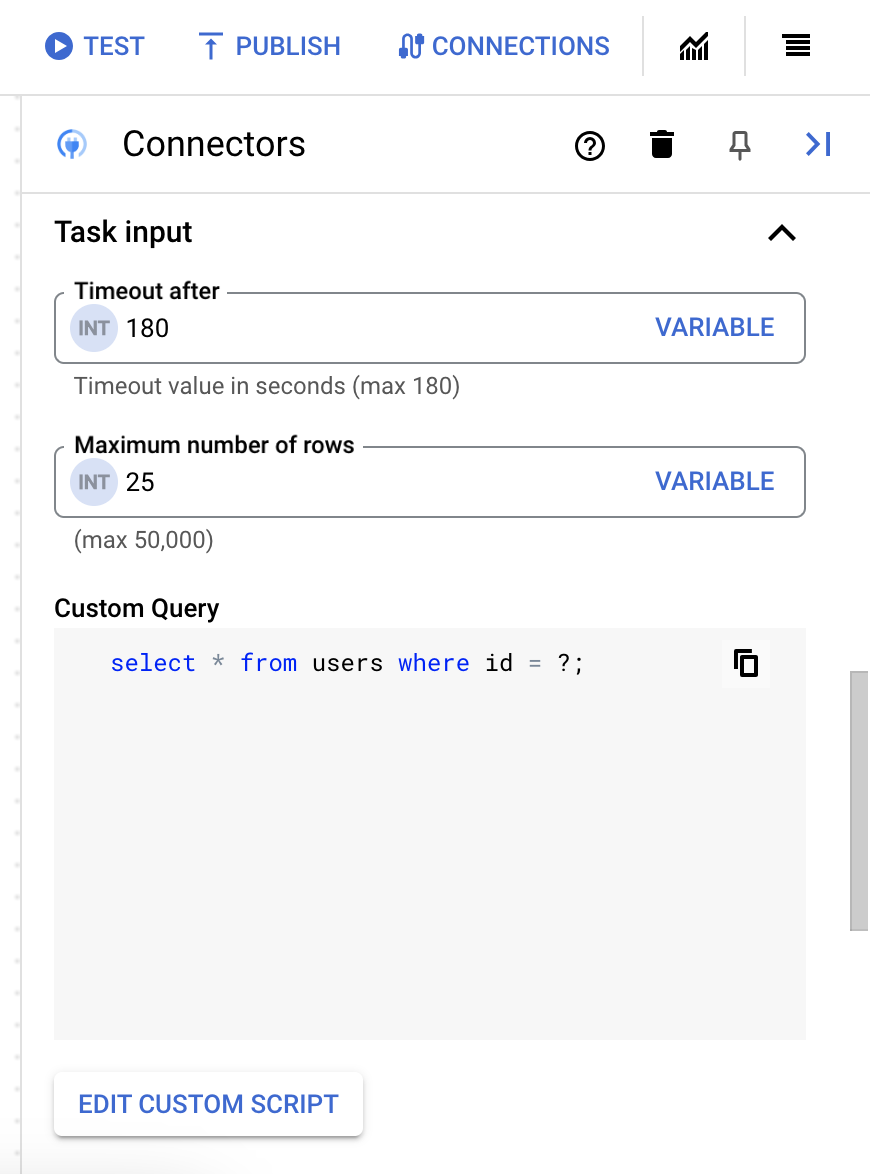
- Dans la boîte de dialogue Éditeur de script, saisissez la requête SQL, puis cliquez sur Enregistrer.
Vous pouvez utiliser un point d'interrogation (?) dans une instruction SQL pour représenter un seul paramètre devant être spécifié dans la liste des paramètres de requête. Par exemple, la requête SQL suivante sélectionne toutes les lignes de la table
Employeescorrespondant aux valeurs spécifiées pour la colonneLastName:SELECT * FROM Employees where LastName=?
- Si vous avez utilisé des points d'interrogation dans votre requête SQL, vous devez ajouter le paramètre en cliquant sur + Ajouter un nom de paramètre pour chaque point d'interrogation. Lors de l'exécution de l'intégration, ces paramètres remplacent les points d'interrogation (?) de la requête SQL de manière séquentielle. Par exemple, si vous avez ajouté trois points d'interrogation (?), vous devez ajouter trois paramètres dans l'ordre de séquence.
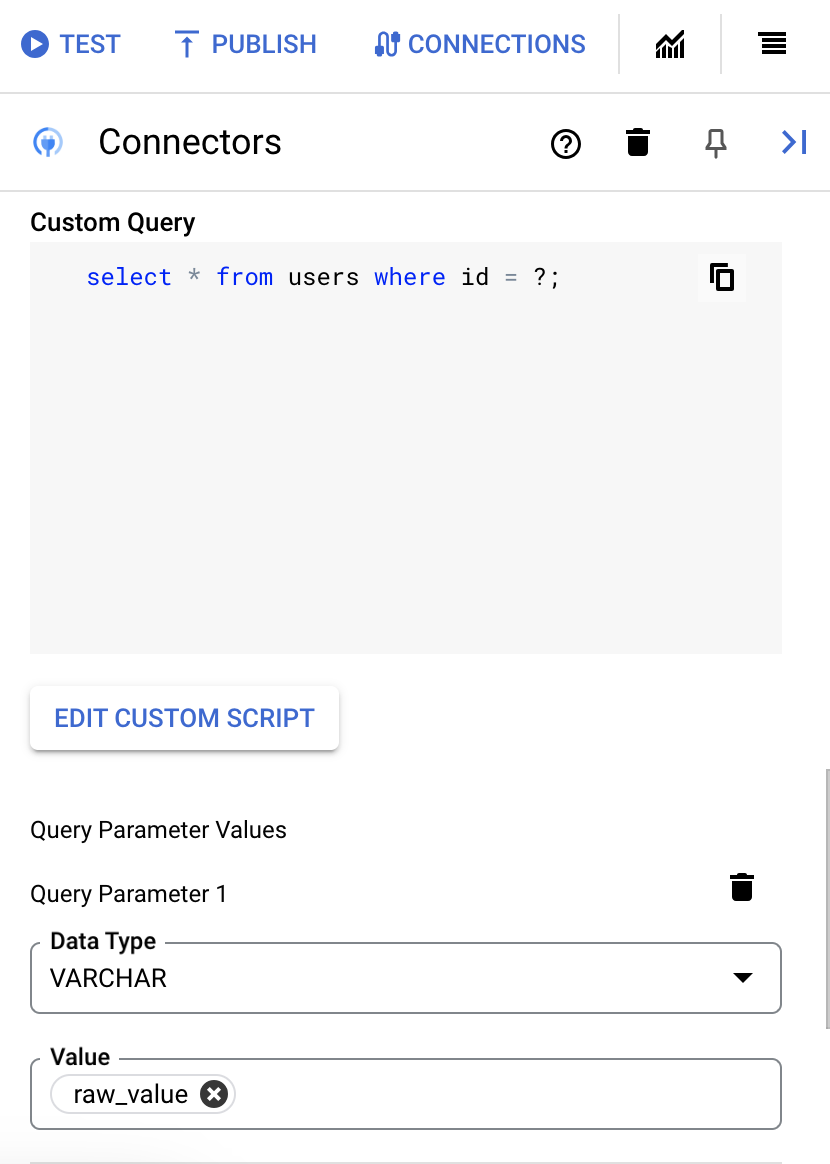
Pour ajouter des paramètres de requête, procédez comme suit :
- Dans la liste Type, sélectionnez le type de données du paramètre.
- Dans le champ Valeur, saisissez la valeur du paramètre.
- Pour ajouter plusieurs paramètres, cliquez sur + Ajouter un paramètre de requête.
L'action Exécuter une requête personnalisée n'est pas compatible avec les variables de tableau.
- Dans le champ Délai d'inactivité après, saisissez le nombre de secondes d'attente jusqu'à l'exécution de la requête.
Limites du système
Le connecteur Teradata peut traiter au maximum 70 transactions par seconde et par nœud, et limite les transactions au-delà de ce seuil. Par défaut, Integration Connectors alloue deux nœuds (pour améliorer la disponibilité) à une connexion.
Pour en savoir plus sur les limites applicables à Integration Connectors, consultez Limites.
Types de données acceptés
Voici les types de données acceptés pour ce connecteur :
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- TIME
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
Actions
Le connecteur Oracle DB vous permet d'exécuter vos procédures stockées, vos fonctions et vos requêtes SQL personnalisées au format compatible avec votre base de données Oracle. Pour exécuter des requêtes SQL personnalisées, le connecteur fournit l'action ExecuteCustomQuery.
Action ExecuteCustomQuery
Cette action vous permet d'exécuter des requêtes SQL personnalisées.
Paramètres d'entrée de l'action ExecuteCustomQuery
| Nom du paramètre | Type de données | Obligatoire | Description |
|---|---|---|---|
| query | STRING | Oui | Requête à exécuter. |
| queryParameters | Tableau JSON au format suivant :[{"value": "VALUE", "dataType": "DATA_TYPE"}]
|
Non | Paramètres de requête. |
| maxRows | NUMBER | Non | Nombre maximal de lignes à renvoyer. |
| timeout | NUMBER | Non | Nombre de secondes d'attente jusqu'à l'exécution de la requête. |
Paramètres de sortie de l'action ExecuteCustomQuery
Si cette action aboutit, elle renvoie l'état 200 (OK) avec un corps de réponse contenant les résultats de la requête.
Pour obtenir des exemples de configuration de l'action ExecuteCustomQuery, consultez Exemples.
Pour savoir comment utiliser l'action ExecuteCustomQuery, consultez Exemples d'actions.
Exemples d'actions
Cette section explique comment effectuer certaines actions dans ce connecteur.
Exemple : Exécuter une requête GROUP BY
- Dans la boîte de dialogue
Configure connector task, cliquez surActions. - Sélectionnez l'action
ExecuteCustomQuery, puis cliquez sur OK. - Dans la section Entrée de la tâche de la tâche Connecteurs, cliquez sur
connectorInputPayload, puis saisissez une valeur semblable à la suivante dans le champDefault Value:{ "query": "select E.EMPLOYEE_ID,E.EMPLOYEE_NAME,E.CITY from EMPLOYEES E LEFT JOIN EMPLOYEE_DEPARTMENT ED ON E.EMPLOYEE_ID=ED.ID where E.EMPLOYEE_NAME = 'John' Group by E.CITY,E.EMPLOYEE_ID,E.EMPLOYEE_NAME" }
Cet exemple sélectionne les enregistrements d'employés dans les tables EMPLOYEES et EMPLOYEE_DEPARTMENT. Si l'action aboutit, le paramètre de réponse connectorOutputPayload de la tâche "Connecteurs" contiendra l'ensemble de résultats de la requête.
Exemple : Exécuter une requête paramétrée
- Dans la boîte de dialogue
Configure connector task, cliquez surActions. - Sélectionnez l'action
ExecuteCustomQuery, puis cliquez sur OK. - Dans la section Entrée de la tâche de la tâche Connecteurs, cliquez sur
connectorInputPayload, puis saisissez une valeur semblable à la suivante dans le champDefault Value:{ "query": "select C.ID,C.NAME,C.CITY,C.O_DATE,E.EMPLOYEE_ID from customqueries C,Employees E where C.ID=E.Employee_id and C.NAME=?", "queryParameters": [{ "value": "John", "dataType": "VARCHAR" }], "timeout":10, "maxRows":3 }
Cet exemple sélectionne les enregistrements correspondant à un employé nommé John.
Notez que le nom de l'employé est paramétré avec queryParameters.
Si l'action aboutit, le paramètre de réponse connectorOutputPayload de la tâche "Connecteurs" aura une valeur semblable à la suivante :
[{ "NAME": "John", "O_DATE": "2023-06-01 00:00:00.0", "EMPLOYEE_ID": 1.0 }, { "NAME": "John", "O_DATE": "2021-07-01 00:00:00.0", "EMPLOYEE_ID": 3.0 }, { "NAME": "John", "O_DATE": "2022-09-01 00:00:00.0", "EMPLOYEE_ID": 4.0 }]
Exemple : Insérer un enregistrement à l'aide d'une valeur de séquence
- Dans la boîte de dialogue
Configure connector task, cliquez surActions. - Sélectionnez l'action
ExecuteCustomQuery, puis cliquez sur OK. - Dans la section Entrée de la tâche de la tâche Connecteurs, cliquez sur
connectorInputPayload, puis saisissez une valeur semblable à la suivante dans le champDefault Value:{ "query": "INSERT INTO AUTHOR(id,title) VALUES(author_table_id_seq.NEXTVAL,'Sample_book_title')" }
Cet exemple insère un enregistrement dans la table AUTHOR à l'aide d'un objet de séquence author_table_id_seq existant. Si l'action aboutit, le paramètre de réponse connectorOutputPayload de la tâche "Connecteurs" aura une valeur semblable à la suivante :
[{ }]
Exemple : Exécuter une requête avec une fonction d'agrégation
- Dans la boîte de dialogue
Configure connector task, cliquez surActions. - Sélectionnez l'action
ExecuteCustomQuery, puis cliquez sur OK. - Dans la section Entrée de la tâche de la tâche Connecteurs, cliquez sur
connectorInputPayload, puis saisissez une valeur semblable à la suivante dans le champDefault Value:{ "query": "SELECT SUM(SALARY) as Total FROM EMPLOYEES" }
Cet exemple calcule la valeur globale des salaires dans la table EMPLOYEES. Si l'action aboutit, le paramètre de réponse connectorOutputPayload de la tâche "Connecteurs" aura une valeur semblable à la suivante :
[{ "TOTAL": 13000.0 }]
Exemple : Créer une table
- Dans la boîte de dialogue
Configure connector task, cliquez surActions. - Sélectionnez l'action
ExecuteCustomQuery, puis cliquez sur OK. - Dans la section Entrée de la tâche de la tâche Connecteurs, cliquez sur
connectorInputPayload, puis saisissez une valeur semblable à la suivante dans le champDefault Value:{ "query": "CREATE TABLE TEST1 (ID INT, NAME VARCHAR(40),DEPT VARCHAR(20),CITY VARCHAR(10))" }
Cet exemple crée la table TEST1. Si l'action aboutit, le paramètre de réponse connectorOutputPayload de la tâche "Connecteurs" aura une valeur semblable à la suivante :
[{ }]
Exemples d'opérations d'entité
Exemple : Lister tous les employés
Cet exemple liste tous les employés de l'entité Employee.
- Dans la boîte de dialogue
Configure connector task, cliquez surEntities. - Sélectionnez
Employeedans la listeEntity. - Sélectionnez l'opération
List, puis cliquez sur OK. - (Facultatif) Dans la section Entrée de la tâche de la tâche Connecteurs, vous pouvez filtrer votre ensemble de résultats en spécifiant une clause de filtre.
Exemple : Récupérer les informations sur un employé
Cet exemple récupère les informations sur l'employé dont l'ID est spécifié, à partir de l'entité Employee.
- Dans la boîte de dialogue
Configure connector task, cliquez surEntities. - Sélectionnez
Employeedans la listeEntity. - Sélectionnez l'opération
Get, puis cliquez sur OK. - Dans la section Entrée de la tâche de la tâche Connecteurs, cliquez sur EntityId, puis saisissez
45dans le champ Valeur par défaut.Ici,
45est la valeur de la clé primaire de l'entitéEmployee.
Exemple : Créer un enregistrement d'employé
Cet exemple ajoute un nouvel enregistrement d'employé dans l'entité Employee.
- Dans la boîte de dialogue
Configure connector task, cliquez surEntities. - Sélectionnez
Employeedans la listeEntity. - Sélectionnez l'opération
Create, puis cliquez sur OK. - Dans la section Entrée de la tâche de la tâche Connecteurs, cliquez sur
connectorInputPayload, puis saisissez une valeur semblable à la suivante dans le champDefault Value:{ "EMPLOYEE_ID": 69.0, "EMPLOYEE_NAME": "John", "CITY": "Bangalore" }
Si l'intégration aboutit, le champ
connectorOutputPayloadde la tâche "Connecteurs" aura une valeur semblable à la suivante :{ "ROWID": "AAAoU0AABAAAc3hAAF" }
Exemple : Mettre à jour un enregistrement d'employé
Cet exemple met à jour l'enregistrement d'employé dont l'ID est 69 dans l'entité Employee.
- Dans la boîte de dialogue
Configure connector task, cliquez surEntities. - Sélectionnez
Employeedans la listeEntity. - Sélectionnez l'opération
Update, puis cliquez sur OK. - Dans la section Entrée de la tâche de la tâche Connecteurs, cliquez sur
connectorInputPayload, puis saisissez une valeur semblable à la suivante dans le champDefault Value:{ "EMPLOYEE_NAME": "John", "CITY": "Mumbai" }
- Cliquez sur entityId, puis saisissez
69dans le champ Valeur par défaut.Sinon, au lieu de spécifier l'entityId, vous pouvez définir la filterClause sur
69.Si l'intégration aboutit, le champ
connectorOutputPayloadde la tâche "Connecteurs" aura une valeur semblable à la suivante :{ }
Exemple : Supprimer un enregistrement d'employé
Cet exemple supprime l'enregistrement d'employé avec l'ID spécifié dans l'entité Employee.
- Dans la boîte de dialogue
Configure connector task, cliquez surEntities. - Sélectionnez
Employeedans la listeEntity. - Sélectionnez l'opération
Delete, puis cliquez sur OK. - Dans la section Entrée de la tâche de la tâche Connecteurs, cliquez sur entityId, puis saisissez
35dans le champ Valeur par défaut.
Créer des connexions à l'aide de Terraform
Vous pouvez utiliser la ressource Terraform pour créer une connexion.
Pour savoir comment appliquer ou supprimer une configuration Terraform, consultez Commandes Terraform de base.
Pour afficher un exemple de modèle Terraform permettant de créer une connexion, consultez Exemple de modèle.
Lorsque vous créez cette connexion à l'aide de Terraform, vous devez définir les variables suivantes dans votre fichier de configuration Terraform :
| Nom du paramètre | Type de données | Obligatoire | Description |
|---|---|---|---|
| client_charset | STRING | True | Spécifie le jeu de caractères Java pour l'encodage et le décodage des données de caractères transférées vers et depuis la base de données Teradata. |
| database | STRING | True | Base de données sélectionnée comme base de données par défaut lorsqu'une connexion Teradata est ouverte. |
| account | STRING | False | Spécifie une chaîne de compte pour remplacer la chaîne de compte par défaut définie pour l'utilisateur de la base de données Teradata. |
| charset | STRING | True | Spécifie le jeu de caractères de session pour l'encodage et le décodage des données de caractères transférées vers et depuis la base de données Teradata. La valeur par défaut est ASCII. |
| column_name | INTEGER | True | Contrôle le comportement des méthodes ResultSetMetaData getColumnName et getColumnLabel. |
| connect_failure_ttl | STRING | False | Cette option permet au fournisseur CData ADO.NET pour Teradata de mémoriser l'heure du dernier échec de connexion pour chaque combinaison adresse IP/port. En outre, le fournisseur CData ADO.NET pour Teradata ignore les tentatives de connexion à cette adresse IP/ce port lors des connexions suivantes pendant le nombre de secondes spécifié par la valeur TTL (Time To Live) d'échec de connexion (CONNECTFAILURETTL). |
| connect_function | STRING | False | Indique si la base de données Teradata doit allouer un numéro de séquence d'ouverture de session (LSN, Logon Sequence Number) pour cette session ou associer cette session à un LSN existant. |
| cop | STRING | False | Indique si la découverte COP est effectuée. |
| cop_last | STRING | False | Indique comment la découverte COP détermine le dernier nom d'hôte COP. |
| ddstats | ENUM | False | Spécifiez la valeur de DDSTATS. Valeurs acceptées : ON et OFF. |
| disable_auto_commit_in_batch | BOOLEAN | True | Indique si le commit automatique doit être désactivé lors de l'exécution de l'opération par lot. |
| encrypt_data | ENUM | False | Spécifiez la valeur EncryptData. Valeurs acceptées : ON et OFF. |
| error_query_count | STRING | False | Spécifie le nombre maximal de tentatives d'interrogation de la table d'erreurs FastLoad 1 par JDBC FastLoad après une opération JDBC Fastload. |
| error_query_interval | STRING | False | Spécifie la durée en millisecondes pendant laquelle JDBC FastLoad attend entre les tentatives d'interrogation de la table d'erreurs FastLoad 1 après une opération JDBC FastLoad. |
| error_table1_suffix | STRING | False | Spécifie le suffixe du nom de la table d'erreurs Fastload 1 créée par JDBC FastLoad et du fichier CSV JDBC FastLoad. |
| error_table2_suffix | STRING | False | Spécifie le suffixe du nom de la table d'erreurs Fastload 2 créée par JDBC FastLoad et du fichier CSV JDBC FastLoad. |
| error_table_database | STRING | False | Spécifie le nom de la base de données pour les tables d'erreurs FastLoad créées par JDBC FastLoad et du fichier CSV JDBC FastLoad. |
| field_sep | STRING | False | Spécifie un séparateur de champs à utiliser uniquement avec le fichier CSV JDBC FastLoad. Le séparateur par défaut est "," (virgule). |
| finalize_auto_close | STRING | False | Spécifiez la valeur de FinalizeAutoClose : ON ou OFF. |
| geturl_credentials | STRING | False | Spécifiez la valeur de GeturlCredentials : ON ou OFF. |
| govern | STRING | False | Spécifiez la valeur de GOVERN : ON ou OFF. |
| literal_underscore | STRING | False | Échappez automatiquement les modèles de prédicat LIKE dans les appels DatabaseMetaData, tels que schemPattern et tableNamePattern. |
| lob_support | STRING | False | Spécifiez la valeur de LobSupport : ON ou OFF. |
| lob_temp_table | STRING | False | Spécifie le nom d'une table avec les colonnes suivantes : "id integer", "bval blob" et "cval clob". |
| log | STRING | False | Spécifie le niveau de journalisation (verbosité) d'une connexion. La journalisation est toujours activée. Les niveaux de journalisation figurent dans l'ordre, de "terse" à "verbose". |
| log_data | STRING | False | Spécifie les données supplémentaires requises par un mécanisme d'ouverture de session, comme un jeton sécurisé, un nom distinctif ou un nom de domaine. |
| log_mech | STRING | False | Spécifie le mécanisme d'ouverture de session, qui détermine les fonctionnalités d'authentification et de chiffrement de la connexion. |
| logon_sequence_number | STRING | False | Spécifie un numéro de séquence d'ouverture de session (LSN) existant auquel associer cette session. |
| max_message_body | STRING | False | Spécifie la taille maximale du message de réponse en octets. |
| maybe_null | STRING | False | Contrôle le comportement de la méthode ResultSetMetaData.isNullable. |
| new_password | STRING | False | Ce paramètre de connexion permet à une application de modifier automatiquement un mot de passe arrivé à expiration. |
| partition | STRING | False | Spécifie la partition de base de données Teradata pour la connexion. |
| prep_support | STRING | False | Spécifie si la base de données Teradata effectue une opération de préparation lorsqu'un objet PreparedStatement ou CallableStatement est créé. |
| reconnect_count | STRING | False | Active la reconnexion de session Teradata. Spécifie le nombre maximal de tentatives de reconnexion de la session par le pilote JDBC Teradata. |
| reconnect_interval | STRING | False | Active la reconnexion de session Teradata. Indique la durée en secondes pendant laquelle le pilote JDBC Teradata attend entre les tentatives de reconnexion de la session. |
| redrive | STRING | False | Active la reconnexion de session Teradata et permet la récupération automatique des requêtes SQL interrompues lors du redémarrage de la base de données. |
| run_startup | STRING | False | Spécifiez la valeur de RunStartup : ON ou OFF. |
| sessions | STRING | False | Spécifie le nombre de connexions FastLoad ou FastExport à créer, où 1 <= nombre de connexions FastLoad ou FastExport <= nombre d'AMP. |
| sip_support | STRING | False | Contrôle si la base de données Teradata et le pilote JDBC Teradata utilisent SIP (StatementInfo Parcel) pour transmettre des métadonnées. |
| slob_receive_threshold | STRING | False | Contrôle la façon dont les valeurs LOB faibles sont reçues de la base de données Teradata. Les valeurs LOB faibles sont préchargées à partir de la base de données Teradata avant que l'application ne lise explicitement les données des objets Blob/Clob. |
| slob_transmit_threshold | STRING | False | Contrôle la manière dont les valeurs LOB faibles sont transmises à la base de données Teradata. |
| sp_spl | STRING | False | Spécifie le comportement de création ou de remplacement des procédures stockées Teradata. |
| strict_encode | STRING | False | Spécifie le comportement d'encodage des données de caractères à transmettre à la base de données Teradata. |
| tmode | STRING | False | Spécifie le mode de transaction de la connexion. |
| tnano | STRING | False | Spécifie la précision des fractions de seconde pour toutes les valeurs java.sql.Time liées à une PreparedStatement ou CallableStatement, et transmises à la base de données Teradata en tant que valeurs TIME ou TIME WITH TIME ZONE. |
| tsnano | STRING | False | Spécifie la précision de fractions de seconde pour toutes les valeurs java.sql.Timestamp liées à une PreparedStatement ou CallableStatement, et transmises à la base de données Teradata en tant que TIMESTAMP ou TIMESTAMP WITH TIME ZONE. |
| tcp | STRING | False | Spécifie un ou plusieurs paramètres de socket TCP, séparés par un signe plus (+). |
| trusted_sql | STRING | False | Spécifiez la valeur de TrustedSql. |
| type | STRING | False | Spécifie le type de protocole à utiliser avec la base de données Teradata pour les instructions SQL. |
| upper_case_identifiers | BOOLEAN | False | Cette propriété indique tous les identifiants en majuscules. Il s'agit de l'option par défaut pour les bases de données Oracle. Elle permet donc une meilleure intégration avec les outils Oracle comme la passerelle de base de données Oracle. |
| use_xviews | STRING | False | Spécifie les vues de dictionnaire de données à interroger pour renvoyer des ensembles de résultats à partir de méthodes DatabaseMetaData. |
Utiliser la connexion Teradata dans une intégration
Une fois la connexion créée, elle devient disponible dans Apigee Integration et Application Integration. Vous pouvez utiliser la connexion dans une intégration au moyen de la tâche "Connecteurs".
- Pour savoir comment créer et utiliser la tâche "Connecteurs" dans Apigee Integration, consultez Tâche "Connecteurs".
- Pour savoir comment créer et utiliser la tâche "Connecteurs" dans Application Integration, consultez Tâche "Connecteurs".
Demander de l'aide à la communauté Google Cloud
Vous pouvez publier vos questions et discuter de ce connecteur sur les forums Cloud de la communauté Google Cloud.Étapes suivantes
- Découvrez comment suspendre et reprendre une connexion.
- Découvrez comment surveiller l'utilisation des connecteurs.
- Découvrez comment afficher les journaux des connecteurs.