処理リクエストに対するレスポンスには、処理されたドキュメントに関する既知の情報をすべて保持する Document オブジェクトが含まれます。これには、Document AI が抽出できたすべての構造化情報が含まれます。
このページでは、サンプル ドキュメントを指定して、OCR 結果の側面を Document オブジェクト JSON の特定の要素にマッピングすることで、Document オブジェクトのレイアウトについて説明します。また、クライアント ライブラリのコードサンプルと Document AI Toolbox SDK のコードサンプルも提供されています。これらのコードサンプルではオンライン処理を使用していますが、Document オブジェクトの解析はバッチ処理でも同じように機能します。
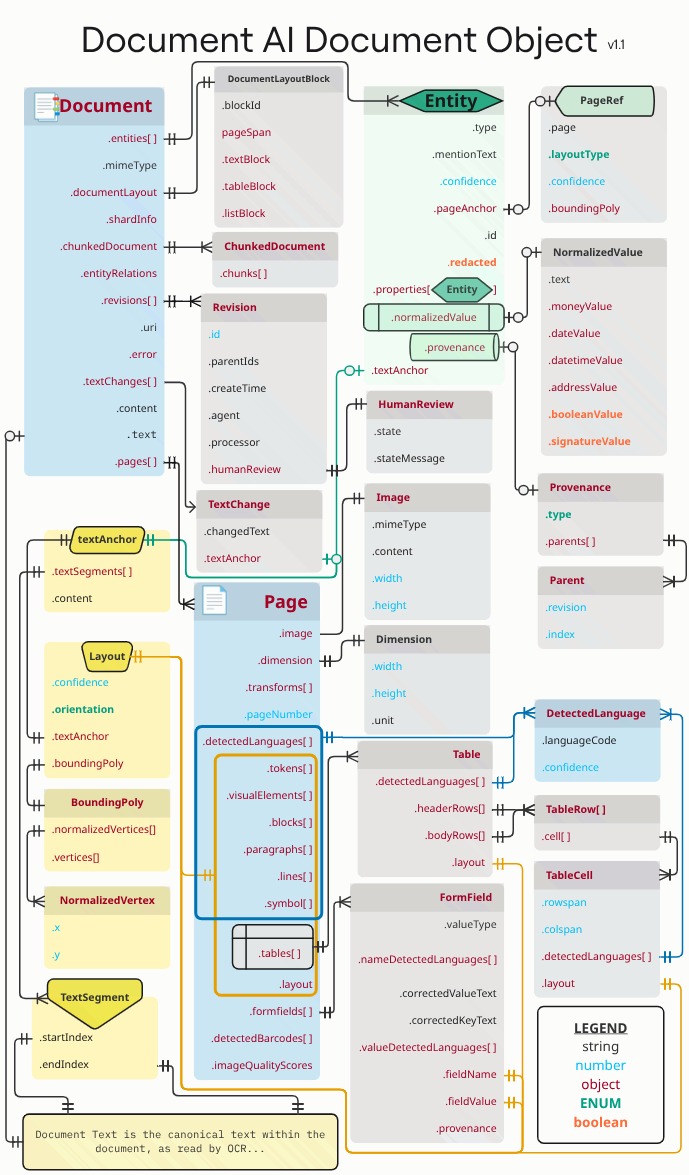
オレンジ色と青色の長方形と矢印は、接続されたオブジェクトの少なくとも 1 つのフィールドがそれぞれ .layout または detectedLanguage であることを表しています。この図では、カラスの足の表記を使用しています。
要素の展開や折りたたみに特化した JSON ビューアまたは編集ユーティリティを使用します。プレーン テキスト ユーティリティで未加工の JSON を確認するのは非効率的です。
テキスト、レイアウト、品質スコア
テキスト ドキュメントの例を次に示します。

Enterprise Document OCR プロセッサから返されるドキュメント オブジェクト全体を次に示します。
OCR はプロセッサによって実行されるため、この OCR 出力は常に Document AI プロセッサの出力に含まれます。既存の OCR データを使用するため、インライン ドキュメント オプションを使用して、このような JSON データを Document AI プロセッサに入力できます。
image=None, # all our samples pass this var
mime_type="application/json",
inline_document=document_response # pass OCR output to CDE input - undocumented
重要なフィールドをいくつか以下に示します。
生テキスト
text フィールドには、Document AI によって認識されたテキストが含まれます。このテキストには、スペース、タブ、改行以外のレイアウト構造は含まれていません。これは、ドキュメントのテキスト情報を保存し、ドキュメントのテキストの信頼できる唯一の情報源として機能する唯一のフィールドです。他のフィールドは、位置(startIndex と endIndex)でテキスト フィールドの一部を参照できます。
{
text: "Sample Document\nHeading 1\nLorem ipsum dolor sit amet, ..."
}
ページサイズと言語
ドキュメント オブジェクト内の各 page は、サンプル ドキュメントの物理ページに対応しています。サンプル JSON 出力には、1 つの PNG 画像であるため、1 ページが含まれています。
{
"pages:" [
{
"pageNumber": 1,
"dimension": {
"width": 679.0,
"height": 460.0,
"unit": "pixels"
},
}
]
}
pages[].detectedLanguages[]フィールドには、特定のページで検出された言語と信頼スコアが含まれます。
{
"pages": [
{
"detectedLanguages": [
{
"confidence": 0.98009938,
"languageCode": "en"
},
{
"confidence": 0.01990064,
"languageCode": "und"
}
]
}
]
}
OCR データ
Document AI OCR は、テキスト ブロック、段落、トークン、記号など、ページ内のさまざまな粒度または構成でテキストを検出します(記号レベルのデータを出力するように構成されている場合、記号レベルは省略可能です)。これらはすべてページ オブジェクトのメンバーです。
すべての要素には、位置とテキストを記述する対応する layout があります。テキスト以外の視覚要素(チェックボックスなど)もページレベルです。
{
"pages": [
{
"paragraphs": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "16"
}
]
},
"confidence": 0.9939527,
"boundingPoly": {
"vertices": [ ... ],
"normalizedVertices": [ ... ]
},
"orientation": "PAGE_UP"
}
}
]
}
]
}
未加工のテキストは textAnchor オブジェクトで参照され、startIndex と endIndex を使用してメインテキスト文字列にインデックス登録されます。
boundingPolyの場合、ページの左上隅が原点(0,0)になります。X の正の値は右、Y の正の値は下です。verticesオブジェクトは元の画像と同じ座標を使用しますが、normalizedVerticesは[0,1]の範囲内です。画像の歪み補正と正規化のその他の属性を示す変換行列があります。
boundingPolyを描画するには、1 つの頂点から次の頂点まで線分を描画します。次に、最後の頂点から最初の頂点まで線分を描画して、ポリゴンを閉じます。レイアウトの orientation 要素は、テキストがページに対して回転しているかどうかを示します。
ドキュメントの構造を視覚化するために、次の図では page.paragraphs、page.lines、page.tokens の境界ポリゴンを描画しています。
段落

線

トークン

Blocks

Enterprise Document OCR プロセッサは、読みやすさに基づいてドキュメントの品質評価を行うことができます。
- API レスポンスでこのデータを取得するには、フィールド
processOptions.ocrConfig.enableImageQualityScoresをtrueに設定する必要があります。
この品質評価は [0, 1] の品質スコアです。1 は品質が完全であることを意味します。品質スコアは Page.imageQualityScores フィールドに返されます。検出された欠陥はすべて quality/defect_* としてリストされ、信頼値の降順で並べ替えられます。
以下は、暗くてぼやけていて読みにくい PDF の例です。
Enterprise Document OCR プロセッサから返されるドキュメントの品質情報は次のとおりです。
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
コードサンプル
次のコードサンプルは、処理リクエストを送信し、フィールドを読み取ってターミナルに出力する方法を示しています。
Java
詳細については、Document AI Java API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
Node.js
詳細については、Document AI Node.js API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
Python
詳細については、Document AI Python API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
フォームとテーブル
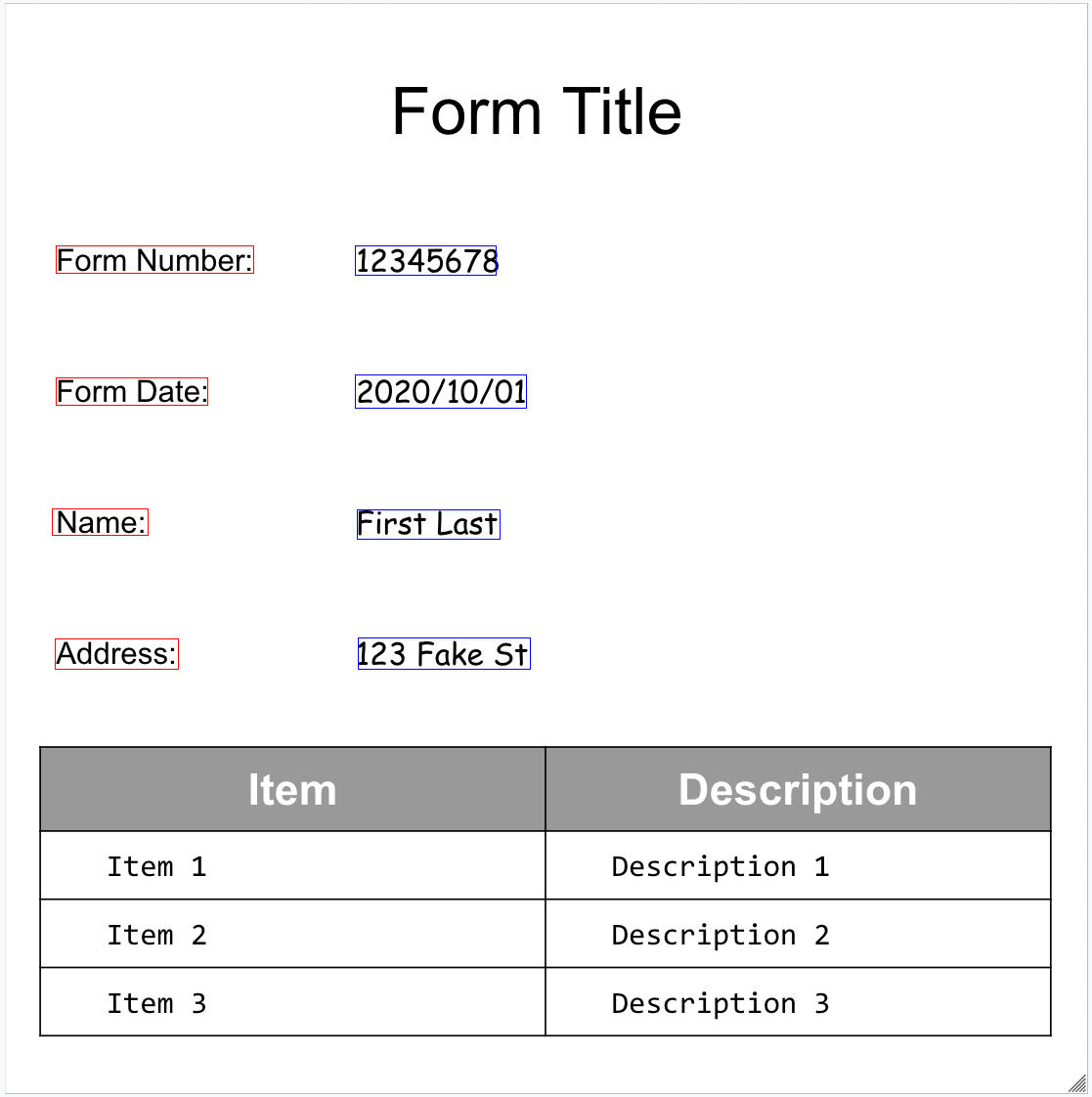
サンプル フォームは次のとおりです。
フォーム パーサーから返されるドキュメント オブジェクトの全体は次のとおりです。
重要なフィールドをいくつか以下に示します。
Form パーサーは、ページ内の FormFields を検出できます。各フォーム フィールドには名前と値があります。これらは Key-Value ペア(KVP)とも呼ばれます。KVP は、他の抽出ツールの(スキーマ)エンティティとは異なります。
エンティティ名が構成されている。KVP のキーは、ドキュメントのキーテキストそのものです。
{
"pages:" [
{
"formFields": [
{
"fieldName": { ... },
"fieldValue": { ... }
}
]
}
]
}
- Document AI では、ページ内の
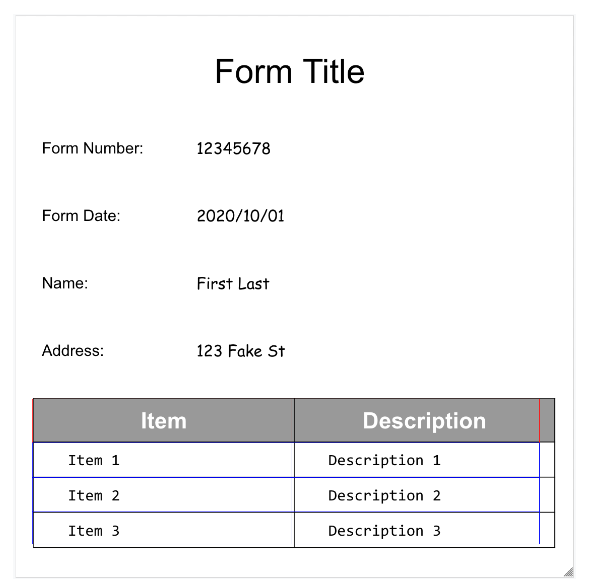
Tablesも検出できます。
{
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
フォーム パーサー内のテーブル抽出では、行または列にまたがるセルがない従来のテーブルのみが認識されます。したがって、rowSpan と colSpan は常に 1 です。
プロセッサ バージョン
pretrained-form-parser-v2.0-2022-11-10以降では、Form パーサーは汎用エンティティも認識できます。詳細については、フォーム パーサーをご覧ください。ドキュメントの構造を視覚化するために、次の図では
page.formFieldsとpage.tablesの境界ポリゴンを描画しています。表のチェックボックス。Form パーサーは、画像や PDF のチェックボックスを KVP としてデジタル化できます。チェックボックスのデジタル化の例を Key-Value ペアで提供します。
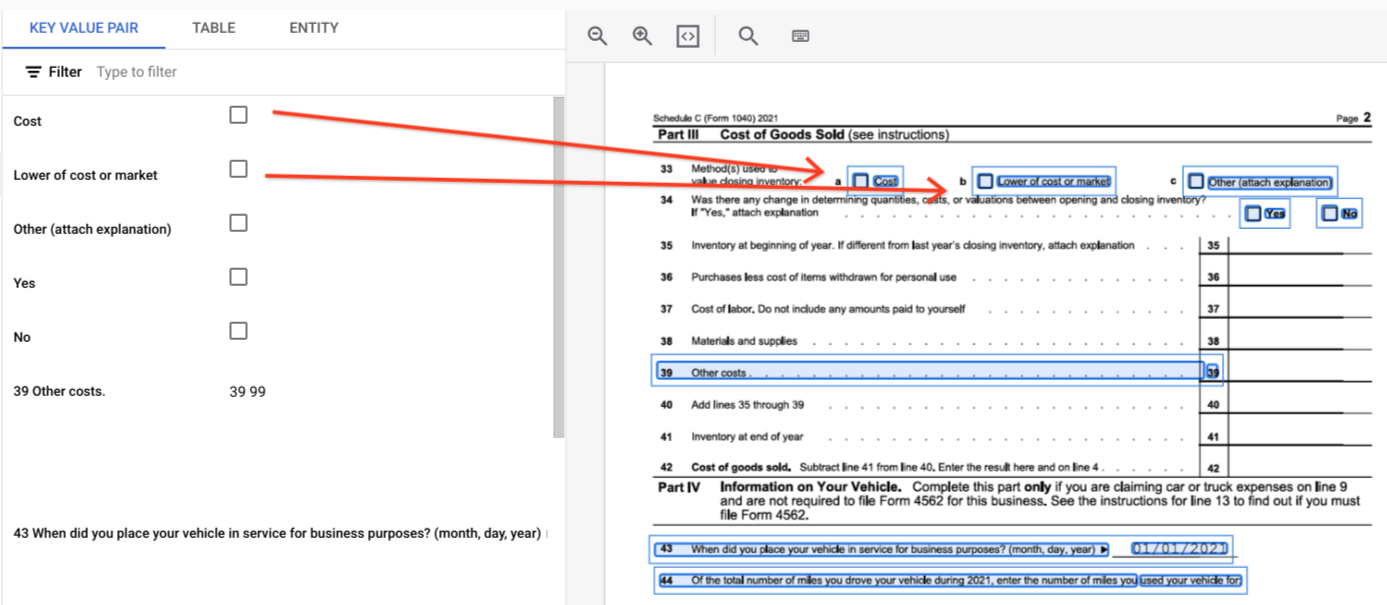
テーブル以外では、チェックボックスは Form パーサー内の視覚要素として表されます。UI のチェックマーク付きの四角いボックスと JSON の Unicode ✓ をハイライト表示。
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
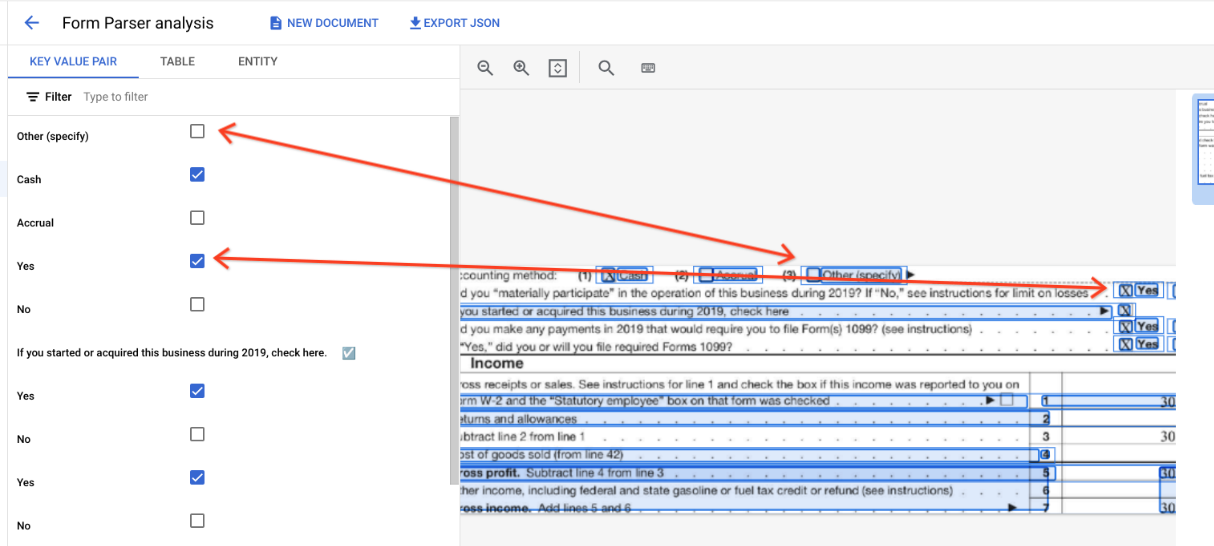
表では、チェックボックスは ✓(オン)や ☐(オフ)などの Unicode 文字として表示されます。
チェックボックスがオンになっている場合、値は filled_checkbox になります。
under pages > x > formFields > x > fieldValue > valueType.。チェックされていないチェックボックスの値は unfilled_checkbox です。
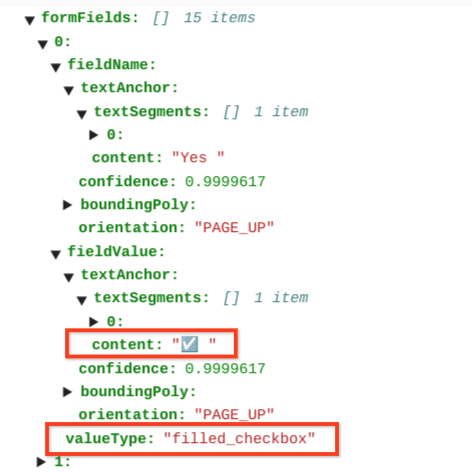
コンテンツの項目には、パス pages>formFields>x>fieldValue>textAnchor>content のチェックボックスのコンテンツ値がハイライト表示された ✓ として表示されます。
ドキュメントの構造を視覚化するために、次の図では page.formFields と page.tables の境界ポリゴンを描画しています。
フォームのフィールド
テーブル
コードサンプル
次のコードサンプルは、処理リクエストを送信し、フィールドを読み取ってターミナルに出力する方法を示しています。
Java
詳細については、Document AI Java API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
Node.js
詳細については、Document AI Node.js API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
Python
詳細については、Document AI Python API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
エンティティ、ネストされたエンティティ、正規化された値
多くの特殊なプロセッサは、明確に定義されたスキーマにグラウンディングされた構造化データを抽出します。たとえば、請求書パーサーは、invoice_date や supplier_name などの特定のフィールドを検出します。請求書のサンプルは次のとおりです。
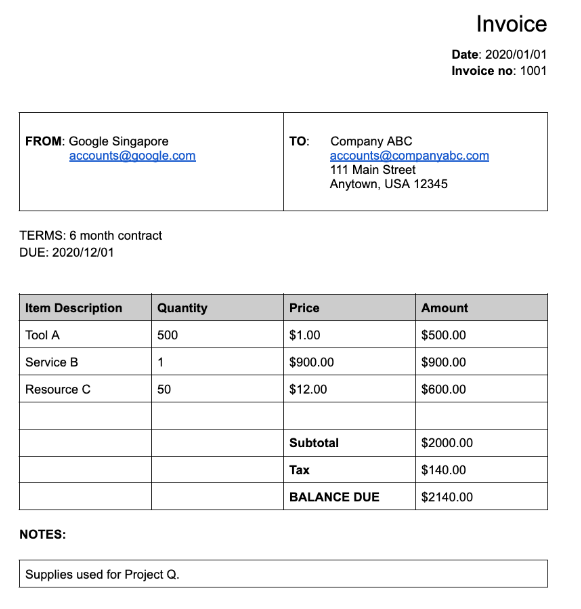
Invoice パーサーから返される完全なドキュメント オブジェクトは次のとおりです。
ドキュメント オブジェクトの重要な部分をいくつか紹介します。
検出されたフィールド:
Entitiesには、プロセッサが検出できたフィールド(invoice_dateなど)が含まれます。{ "entities": [ { "textAnchor": { "textSegments": [ { "startIndex": "14", "endIndex": "24" } ], "content": "2020/01/01" }, "type": "invoice_date", "confidence": 0.9938466, "pageAnchor": { ... }, "id": "2", "normalizedValue": { "text": "2020-01-01", "dateValue": { "year": 2020, "month": 1, "day": 1 } } } ] }一部のフィールドでは、プロセッサは値を正規化します。この例では、日付が
2020/01/01から2020-01-01に正規化されています。正規化: サポートされている多くの特定のフィールドでは、プロセッサは値を正規化し、
entityも返します。normalizedValueフィールドは、各エンティティのtextAnchorを介して取得された未加工の抽出フィールドに追加されます。そのため、リテラル テキストを正規化し、テキスト値をサブフィールドに分割することがよくあります。たとえば、2024 年 9 月 1 日は次のように表されます。
normalizedValue": {
"text": "2020-09-01",
"dateValue": {
"year": 2024,
"month": 9,
"day": 1
}
この例では、日付が 2020/01/01 から 2020-01-01 に正規化されています。これは、後処理を減らし、選択した形式への変換を可能にする標準化された形式です。
住所は正規化されることも多く、住所の要素が個々のフィールドに分割されます。数値は、整数または浮動小数点数を normalizedValue として正規化されます。
- 拡充: 特定のプロセッサとフィールドでは、拡充もサポートされています。たとえば、ドキュメント
Google Singaporeの元のsupplier_nameは、Enterprise Knowledge Graph に対して正規化され、Google Asia Pacific, Singaporeになっています。また、Enterprise Knowledge Graph に Google に関する情報が含まれているため、サンプル ドキュメントにsupplier_addressが含まれていなくても、Document AI はsupplier_addressを推論します。
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "supplier_name",
"confidence": 0.39170802,
"pageAnchor": { ... },
"id": "12",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
},
{
"type": "supplier_address",
"id": "17",
"normalizedValue": {
"text": "70 Pasir Panjang Rd #03-71 Mapletree Business City II Singapore 117371",
"addressValue": {
"regionCode": "SG",
"languageCode": "en-US",
"postalCode": "117371",
"addressLines": [
"70 Pasir Panjang Rd",
"#03-71 Mapletree Business City II"
]
}
}
}
]
}
ネストされたフィールド: ネストされたスキーマ(フィールド)は、まずエンティティを親として宣言し、その親の下に子エンティティを作成することで作成できます。親の解析レスポンスには、親フィールドの
properties要素に子フィールドが含まれます。次の例では、line_itemは 2 つの子フィールド(line_item/descriptionとline_item/quantity)を持つ親フィールドです。{ "entities": [ { "textAnchor": { ... }, "type": "line_item", "confidence": 1.0, "pageAnchor": { ... }, "id": "19", "properties": [ { "textAnchor": { "textSegments": [ ... ], "content": "Tool A" }, "type": "line_item/description", "confidence": 0.3461604, "pageAnchor": { ... }, "id": "20" }, { "textAnchor": { "textSegments": [ ... ], "content": "500" }, "type": "line_item/quantity", "confidence": 0.8077843, "pageAnchor": { ... }, "id": "21", "normalizedValue": { "text": "500" } } ] } ] }
次のパーサーはこれに従います。
- 抽出(カスタム エクストラクタ)
- 以前のバージョン
- 銀行明細書パーサー
- 経費パーサー
- Invoice パーサー
- PaySlip パーサー
- W2 パーサー
コードサンプル
次のコードサンプルは、処理リクエストを送信し、専用プロセッサからフィールドを読み取ってターミナルに出力する方法を示しています。
Java
詳細については、Document AI Java API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
Node.js
詳細については、Document AI Node.js API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
Python
詳細については、Document AI Python API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
カスタム ドキュメント エクストラクタ
カスタム ドキュメント エクストラクタ プロセッサは、事前トレーニング済みのプロセッサが利用できないドキュメントからカスタム エンティティを抽出できます。これは、カスタムモデルをトレーニングするか、生成 AI 基盤モデルを使用してトレーニングなしで固有表現を抽出することで実現できます。詳細については、コンソールでカスタム ドキュメント抽出器を作成するをご覧ください。
- カスタムモデルをトレーニングする場合、プロセッサは事前トレーニング済みのエンティティ抽出プロセッサとまったく同じ方法で使用できます。
- 基盤モデルを使用する場合は、プロセッサ バージョンを作成して、リクエストごとに特定のエンティティを抽出するか、リクエストごとに構成できます。
出力構造については、エンティティ、ネストされたエンティティ、正規化された値をご覧ください。
コードサンプル
カスタムモデルを使用している場合、または基盤モデルを使用してプロセッサ バージョンを作成した場合は、エンティティ抽出のコードサンプルを使用します。
次のコードサンプルは、リクエストごとに基盤モデルのカスタム ドキュメント抽出用に特定のエンティティを構成し、抽出されたエンティティを出力する方法を示しています。
Python
詳細については、Document AI Python API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
要約
サマライザ プロセッサは、生成 AI 基盤モデルを使用して、ドキュメントから抽出されたテキストを要約します。レスポンスの長さと形式は、次の方法でカスタマイズできます。
- 長さ
BRIEF: 1 ~ 2 文の簡単な概要MODERATE: 段落の長さの要約COMPREHENSIVE: 最長のオプション
- 形式
特定の長さと形式のプロセッサ バージョンを作成するか、リクエストごとに構成できます。
要約されたテキストが Document.entities.normalizedValue.text に表示されます。完全な出力 JSON ファイルのサンプルは、プロセッサの出力例をご覧ください。
詳細については、コンソールでドキュメントの要約ツールを構築するをご覧ください。
コードサンプル
次のコードサンプルは、処理リクエストで特定の長さと形式を構成し、要約されたテキストを出力する方法を示しています。
Python
詳細については、Document AI Python API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
分割と分類
さまざまな種類のドキュメントやフォームを含む 10 ページの複合 PDF の例を次に示します。
貸与ドキュメントの分割と分類によって返されるドキュメント オブジェクト全体は次のとおりです。
スプリッタによって検出された各ドキュメントは、entity で表されます。次に例を示します。
{
"entities": [
{
"textAnchor": {
"textSegments": [
{
"startIndex": "13936",
"endIndex": "21108"
}
]
},
"type": "1040se_2020",
"confidence": 0.76257163,
"pageAnchor": {
"pageRefs": [
{
"page": "6"
},
{
"page": "7"
}
]
}
}
]
}
Entity.pageAnchorは、このドキュメントが 2 ページであることを示します。pageRefs[].pageは 0 から始まるdocument.pages[]フィールドのインデックスです。Entity.typeは、このドキュメントが 1040 Schedule SE フォームであることを指定します。識別できるドキュメント タイプの完全なリストについては、プロセッサのドキュメントの識別されたドキュメント タイプをご覧ください。
詳細については、ドキュメント分割ツールの動作をご覧ください。
コードサンプル
分割ツールはページの境界を特定しますが、入力ドキュメントを実際に分割することはありません。Document AI Toolbox を使用して、ページ境界を使用して PDF ファイルを物理的に分割できます。次のコードサンプルは、PDF を分割せずにページ範囲を印刷します。
Java
詳細については、Document AI Java API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
Node.js
詳細については、Document AI Node.js API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
Python
詳細については、Document AI Python API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
Document のページ境界を使用して PDF ファイルを分割します。Python
詳細については、Document AI Python API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
Document AI ツールボックス
Document AI Toolbox は、ドキュメント レスポンスの情報の管理、操作、抽出を行うユーティリティ関数を提供する Python 用の SDK です。Cloud Storage の JSON ファイル、ローカル JSON ファイル、または process_document() メソッドから直接出力された処理済みドキュメント レスポンスから「ラップされた」ドキュメント オブジェクトを作成します。
次の操作を行うことができます。
- バッチ処理の断片化された
DocumentJSON ファイルを 1 つの「ラップされた」ドキュメントに結合します。 - シャードを統合された
Documentとしてエクスポートします。 -
次のコマンドから
Document出力を取得します。 Layout情報を処理せずに、Pages、Lines、Paragraphs、FormFields、Tablesからテキストにアクセスします。- ターゲット文字列を含むか、正規表現に一致する
Pagesを検索します。 FormFieldsを名前で検索します。- タイプ別に
Entitiesを検索します。 Tablesを Pandas Dataframe または CSV に変換します。EntitiesとFormFieldsを BigQuery テーブルに挿入します。- Splitter/Classifier プロセッサの出力に基づいて PDF ファイルを分割します。
Document境界ボックスから画像Entitiesを抽出します。-
Documentsを一般的な形式に変換する、または一般的な形式から変換する:- Cloud Vision API
AnnotateFileResponse - hOCR
- サードパーティのドキュメント処理形式
- Cloud Vision API
- Cloud Storage フォルダから処理するドキュメントのバッチを作成します。
コードサンプル
次のコードサンプルは、Document AI Toolbox の使用方法を示しています。