Für Training, Aufbautraining oder Bewertung einer Prozessorversion ist ein Dataset aus Dokumenten mit Labels erforderlich.
Auf dieser Seite wird beschrieben, wie Sie ein Dataset erstellen, Dokumente importieren und ein Schema definieren. Informationen zum Labeln der importierten Dokumente finden Sie unter Dokumente labeln.
Auf dieser Seite wird davon ausgegangen, dass Sie bereits einen Prozessor erstellt haben, der Training, Aufbautraining oder Bewertung unterstützt. Wenn Ihr Prozessor unterstützt wird, sehen Sie den Tab Trainieren in der Google Cloud Console.
Optionen für den Dataset-Speicher
Sie haben zwei Möglichkeiten, Ihr Dataset zu speichern:
- Von Google verwaltet
- Benutzerdefinierter Cloud Storage-Speicherort
Sofern Sie keine besonderen Anforderungen haben (z. B. um Dokumente in einer Reihe von CMEK-fähigen Ordnern zu speichern), empfehlen wir die einfachere von Google verwaltete Speicheroption. Nachdem die Speicheroption für das Dataset erstellt wurde, kann sie für den Prozessor nicht mehr geändert werden.
Der Ordner oder Unterordner für einen benutzerdefinierten Cloud Storage-Speicherort muss leer sein und darf nur gelesen werden. Manuelle Änderungen am Inhalt können das Dataset unbrauchbar machen und zum Verlust führen. Bei der Option „Von Google verwalteter Speicherplatz“ besteht dieses Risiko nicht.
So stellen Sie Ihren Speicherort bereit:
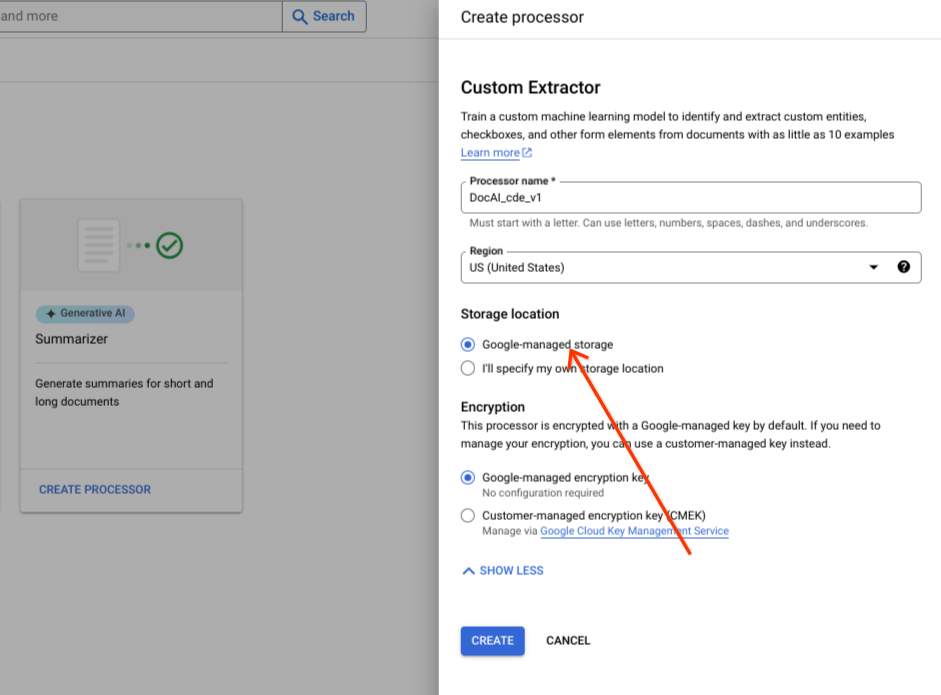
Von Google verwalteter Speicher (empfohlen)
Erweiterte Optionen beim Erstellen eines neuen Prozessors anzeigen
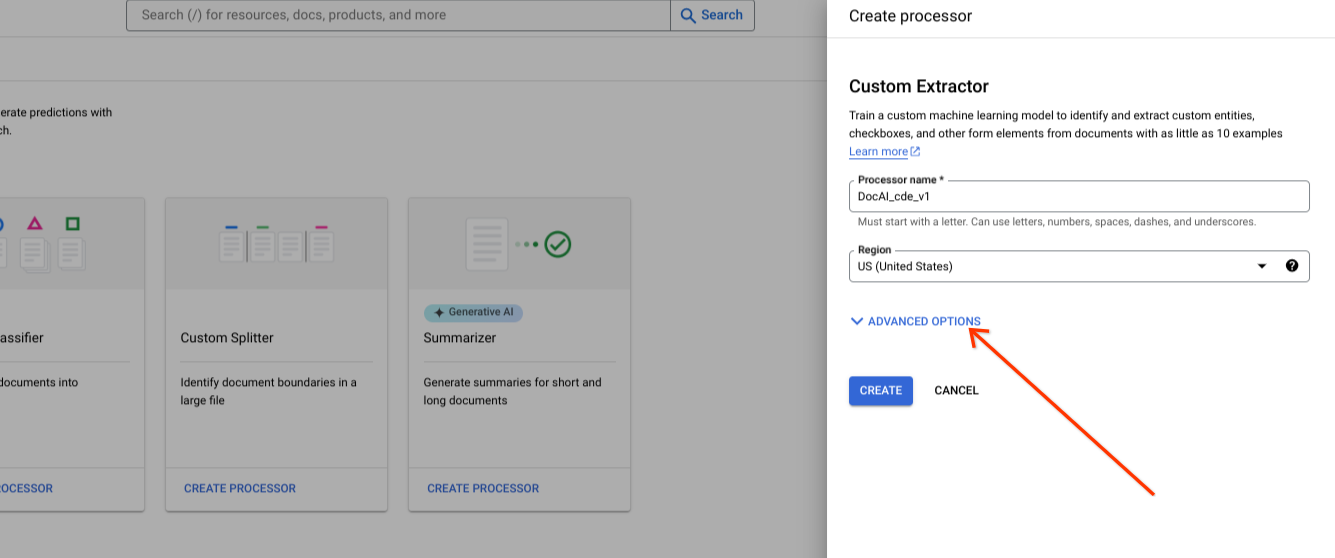
Behalten Sie die Standardoption für die Optionsgruppe Von Google verwaltet bei.
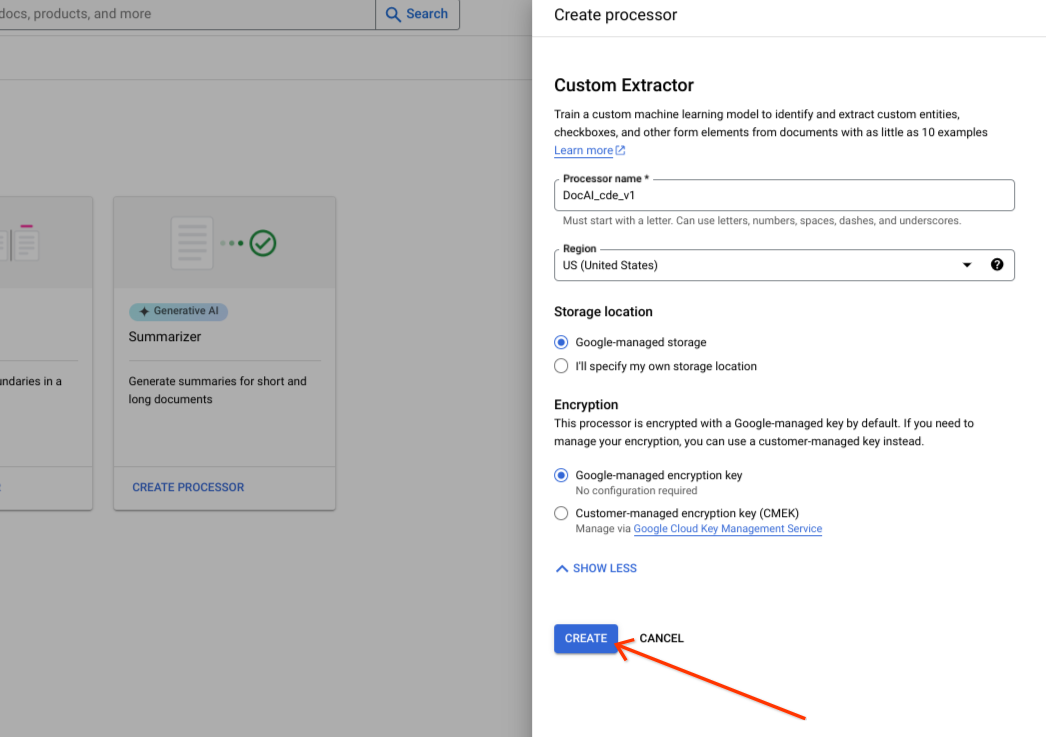
Wählen Sie Erstellen aus.
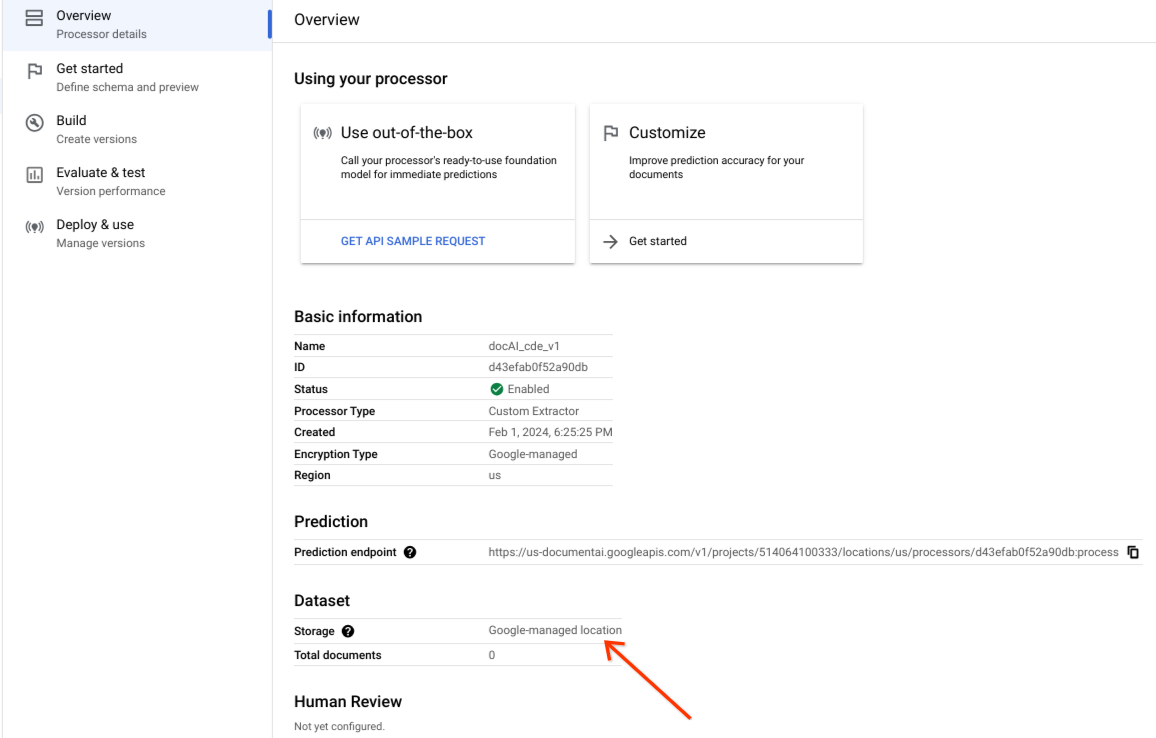
Prüfen Sie, ob das Dataset erfolgreich erstellt wurde und der Dataset-Speicherort Von Google verwalteter Speicherort ist.
Option für benutzerdefinierten Speicher
Aktivieren oder deaktivieren Sie die erweiterten Optionen.
Wählen Sie Ich gebe einen eigenen Speicherort an aus.
Wählen Sie im Eingabefeld einen Cloud Storage-Ordner aus.
Wählen Sie Erstellen aus.
Dataset API-Vorgänge
In diesem Beispiel wird gezeigt, wie Sie mit der Methode processors.updateDataset ein Dataset erstellen. Eine Dataset-Ressource ist eine Singleton-Ressource in einem Prozessor. Das bedeutet, dass es keinen RPC zum Erstellen von Ressourcen gibt. Stattdessen können Sie die RPC updateDataset verwenden, um die Einstellungen festzulegen. Mit Document AI können Sie die Dataset-Dokumente in einem von Ihnen bereitgestellten Cloud Storage-Bucket speichern oder automatisch von Google verwalten lassen.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
Bereitgestellter Bucket
Folgen Sie der Anleitung, um eine Dataset-Anfrage mit einem von Ihnen bereitgestellten Cloud Storage-Bucket zu erstellen.
HTTP-Methode
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetJSON-Anfrage:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"gcs_managed_config" {
"gcs_prefix" {
"gcs_uri_prefix": "GCS_URI"
}
}
"spanner_indexing_config" {}
}Von Google verwaltet
Wenn Sie ein von Google verwaltetes Dataset erstellen möchten, aktualisieren Sie die folgenden Informationen:
HTTP-Methode
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetJSON-Anfrage:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"unmanaged_dataset_config": {}
"spanner_indexing_config": {}
}Sie können Ihre Anfrage mit Curl senden:
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json. Führen Sie folgenden Befehl aus:
CURL
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Dokumente importieren
Ein neu erstelltes Dataset ist leer. Wenn Sie Dokumente hinzufügen möchten, wählen Sie Dokumente importieren aus und wählen Sie einen oder mehrere Cloud Storage-Ordner aus, die die Dokumente enthalten, die Sie Ihrem Dataset hinzufügen möchten.
Wenn sich Ihr Cloud Storage-Bucket in einem anderen Google Cloud Projekt befindet, müssen Sie den Zugriff so gewähren, dass Document AI Dateien von diesem Speicherort lesen darf. Sie müssen dem Hauptdienst-Agent von Document AI, service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com, die Rolle Storage-Objekt-Betrachter zuweisen. Weitere Informationen finden Sie unter Dienst-Agents.
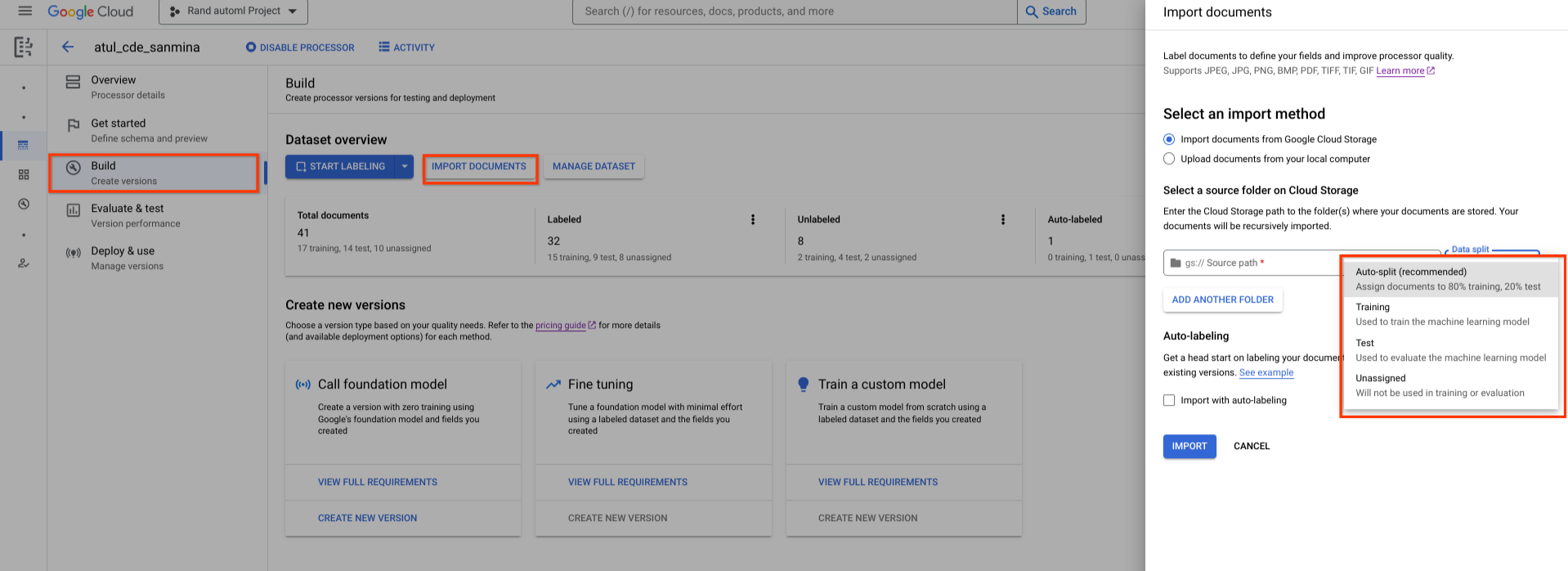
Wählen Sie dann eine der folgenden Zuweisungsoptionen aus:
- Training: Dem Trainings-Dataset zuweisen.
- Test: Dem Testset zuweisen.
- Automatische Aufteilung: Dokumente werden zufällig in Trainings- und Test-Datasets aufgeteilt.
- Nicht zugewiesen: Wird nicht für Training oder Tests verwendet. Sie können sie später manuell zuweisen.
Sie können die Zuweisungen später jederzeit ändern.
Wenn Sie Importieren auswählen, werden alle unterstützten Dateitypen sowie JSON-Dateien Document in das Dataset importiert. Bei JSON-Dateien Document importiert Document AI das Dokument und konvertiert die entities in Label-Instanzen.
Document AI ändert den Importordner nicht und liest nicht aus dem Ordner, nachdem der Import abgeschlossen ist.
Wählen Sie oben auf der Seite Aktivität aus, um den Bereich Aktivität zu öffnen. Dort werden die Dateien aufgeführt, die erfolgreich importiert wurden, sowie die Dateien, bei denen der Import fehlgeschlagen ist.
Wenn Sie bereits eine Version Ihres Prozessors haben, können Sie im Dialogfeld Dokumente importieren das Kästchen Mit automatischem Labeling importieren anklicken. Die Dokumente werden beim Importieren automatisch mit dem vorherigen Prozessor gelabelt. Sie können keine Trainings oder Up-Trainings für automatisch mit Labels versehene Dokumente durchführen oder sie im Testset verwenden, ohne sie als „Mit Label versehen“ zu markieren. Nachdem Sie automatisch gelabelte Dokumente importiert haben, müssen Sie sie manuell überprüfen und korrigieren. Wählen Sie dann Speichern aus, um die Korrekturen zu speichern und das Dokument als gelabelt zu kennzeichnen. Anschließend können Sie die Dokumente entsprechend zuweisen. Weitere Informationen finden Sie unter Automatisches Labeling.
RPC zum Importieren von Dokumenten
In diesem Beispiel wird gezeigt, wie Sie die Methode dataset.importDocuments verwenden, um Dokumente in das Dataset zu importieren.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
DATASET_TYPE: The dataset type to which you want to add documents. The value should be either `DATASET_SPLIT_TRAIN` or `DATASET_SPLIT_TEST`.
TRAINING_SPLIT_RATIO: The ratio of documents which you want to autoassign to the training set.
Trainings- oder Test-Dataset
So fügen Sie dem Trainings- oder Test-Dataset Dokumente hinzu:
HTTP-Methode
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsJSON-Anfrage:
{
"batch_documents_import_configs": {
"dataset_split": DATASET_TYPE
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": GCS_URI
}
}
}
}Trainings- und Test-Dataset
So teilen Sie die Dokumente automatisch in Trainings- und Test-Datasets auf:
HTTP-Methode
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsJSON-Anfrage:
{
"batch_documents_import_configs": {
"auto_split_config": {
"training_split_ratio": TRAINING_SPLIT_RATIO
},
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": "gs://test_sbindal/pdfs-1-page/"
}
}
}
}Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments"Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}RPC zum Löschen von Dokumenten
In diesem Beispiel wird gezeigt, wie Sie die Methode dataset.batchDeleteDocuments verwenden, um Dokumente aus dem Dataset zu löschen.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
DOCUMENT_ID: The document ID blob returned by <code>ImportDocuments</code> request
Dokumente löschen
HTTP-Methode
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocumentsJSON-Anfrage:
{
"dataset_documents": {
"individual_document_ids": {
"document_ids": DOCUMENT_ID
}
}
}Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments"Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Dokumente dem Trainings- oder Testset zuweisen
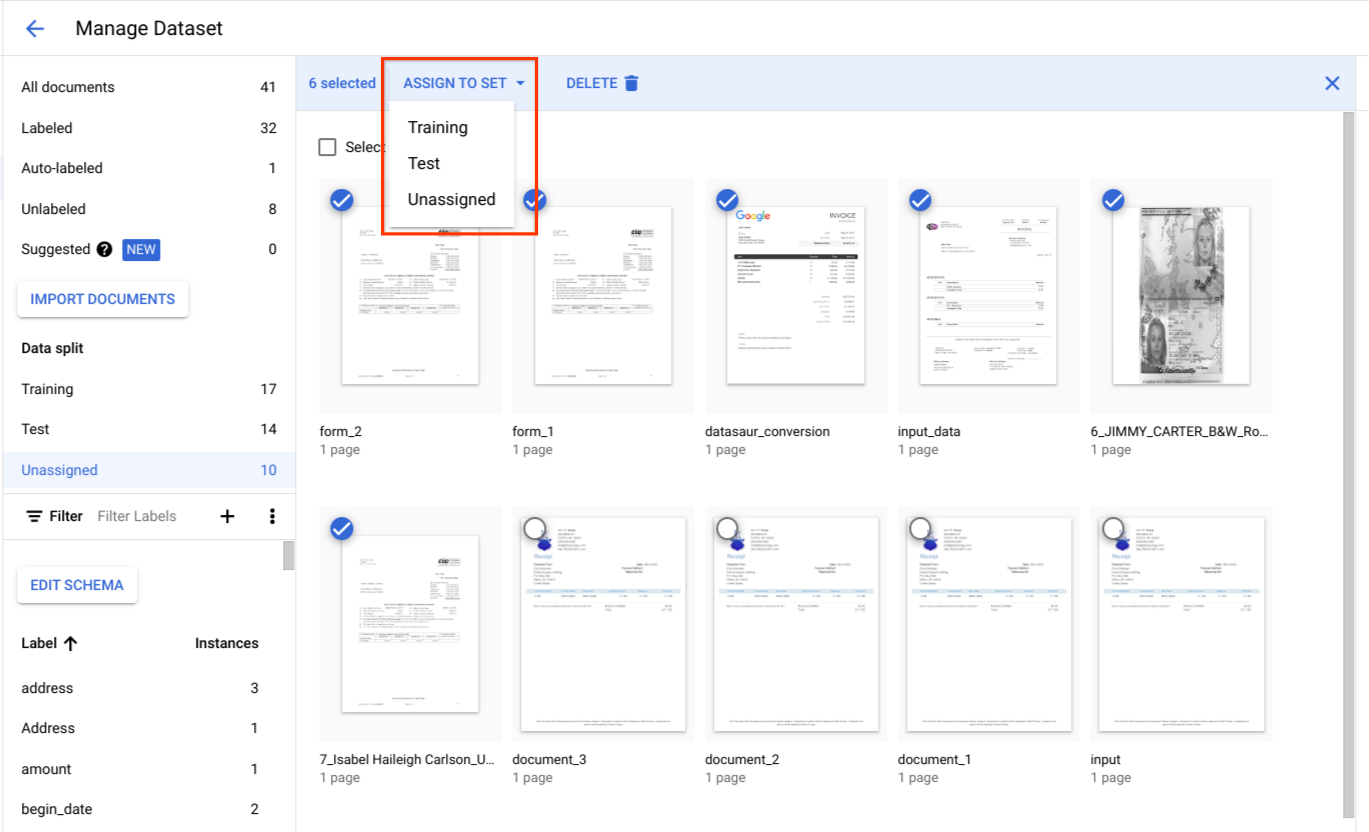
Wählen Sie unter Datenaufteilung Dokumente aus und weisen Sie sie dem Trainings-Dataset, dem Test-Dataset oder „Nicht zugewiesen“ zu.
Best Practices für Testsets
Die Qualität Ihres Test-Datasets bestimmt die Qualität Ihrer Auswertung.
Das Testset sollte zu Beginn des Entwicklungszyklus für den Prozessor erstellt und gesperrt werden, damit Sie die Qualität des Prozessors im Laufe der Zeit verfolgen können.
Wir empfehlen mindestens 100 Dokumente pro Dokumenttyp für den Testsatz. Es ist wichtig, dass das Testset repräsentativ für die Arten von Dokumenten ist, die Kunden für das entwickelte Modell verwenden.
Die Testgruppe sollte in Bezug auf die Häufigkeit repräsentativ für den Produktionstraffic sein. Wenn Sie beispielsweise W2-Formulare verarbeiten und 70% für das Jahr 2020 und 30% für das Jahr 2019 erwartet werden, sollten etwa 70% des Testsets aus W2-Dokumenten für 2020 bestehen. Eine solche Zusammensetzung des Testsatzes sorgt dafür, dass jeder Dokumentuntertyp bei der Bewertung der Prozessorleistung angemessen berücksichtigt wird. Wenn Sie Namen von Personen aus internationalen Formularen extrahieren, muss Ihr Testset Formulare aus allen Zielländern enthalten.
Best Practices für den Trainingsdatensatz
Dokumente, die bereits im Test-Dataset enthalten sind, sollten nicht im Trainings-Dataset enthalten sein.
Im Gegensatz zum Testset muss das finale Trainingsset nicht so streng repräsentativ für die Kundennutzung in Bezug auf Dokumentvielfalt oder ‑häufigkeit sein. Einige Labels sind schwieriger zu trainieren als andere. Daher kann es sein, dass Sie eine bessere Leistung erzielen, wenn Sie das Trainings-Dataset auf diese Labels ausrichten.
Anfangs gibt es keine gute Möglichkeit, herauszufinden, welche Labels schwierig sind. Beginnen Sie mit einem kleinen, zufällig ausgewählten ersten Trainings-Dataset, das auf dieselbe Weise erstellt wird wie das Test-Dataset. Dieser erste Trainingssatz sollte etwa 10% der Gesamtzahl der Dokumente enthalten, die Sie annotieren möchten. Anschließend können Sie die Qualität des Prozessors iterativ bewerten (nach bestimmten Fehlermustern suchen) und weitere Trainingsdaten hinzufügen.
Prozessorschema definieren
Nachdem Sie ein Dataset erstellt haben, können Sie ein Prozessorschema entweder vor oder nach dem Importieren von Dokumenten definieren.
Im schema des Prozessors werden die Labels wie Name und Adresse definiert, die aus Ihren Dokumenten extrahiert werden sollen.
Wählen Sie Schema bearbeiten aus und erstellen, bearbeiten, aktivieren und deaktivieren Sie Labels nach Bedarf.
Klicken Sie abschließend auf Speichern.
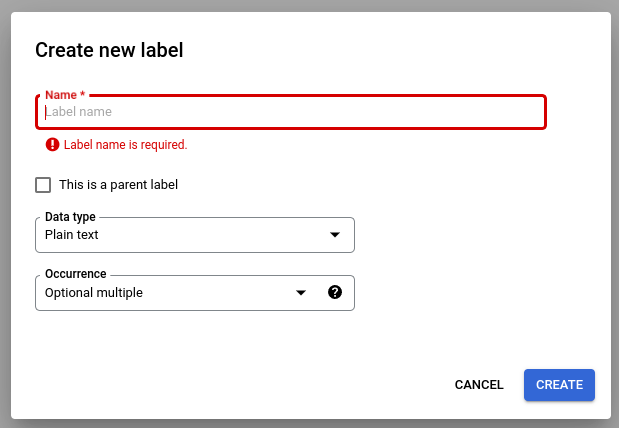
Hinweise zur Verwaltung von Schemalabels:
Nachdem ein Schemalabel erstellt wurde, kann sein Name nicht mehr bearbeitet werden.
Ein Schemalabel kann nur bearbeitet oder gelöscht werden, wenn keine trainierten Prozessorversionen vorhanden sind. Nur Datentyp und Vorkommenstyp können bearbeitet werden.
Das Deaktivieren eines Labels hat auch keine Auswirkungen auf die Vorhersage. Wenn Sie eine Verarbeitungsanfrage senden, werden mit der Prozessorversion alle Labels extrahiert, die zum Zeitpunkt des Trainings aktiv waren.
Datenschema abrufen
In diesem Beispiel wird gezeigt, wie Sie das Dataset verwenden und mit getDatasetSchema das aktuelle Schema abrufen. DatasetSchema ist eine Singleton-Ressource, die automatisch erstellt wird, wenn Sie eine Dataset-Ressource erstellen.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
Datenschema abrufen
HTTP-Methode
GET https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaCURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema",
"documentSchema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": $LABEL_NAME,
"valueType": $VALUE_TYPE,
"occurrenceType": $OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}Dokumentschema aktualisieren
In diesem Beispiel wird gezeigt, wie Sie mit dataset.updateDatasetSchema das aktuelle Schema aktualisieren. In diesem Beispiel sehen Sie einen Befehl zum Aktualisieren des Dataset-Schemas, sodass es nur ein Label enthält. Wenn Sie ein neues Label hinzufügen möchten, ohne vorhandene Labels zu löschen oder zu aktualisieren, können Sie zuerst getDatasetSchema aufrufen und entsprechende Änderungen in der Antwort vornehmen.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
LABEL_NAME: The label name which you want to add
LABEL_DESCRIPTION: Describe what the label represents
DATA_TYPE: The type of the label. You can specify this as string, number, currency, money, datetime, address, boolean.
OCCURRENCE_TYPE: Describes the number of times this label is expected. Pick an enum value.
Schema aktualisieren
HTTP-Methode
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaJSON-Anfrage:
{
"document_schema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": LABEL_NAME,
"description": LABEL_DESCRIPTION,
"valueType": DATA_TYPE,
"occurrenceType": OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"Label-Attribute auswählen
Datentyp
Plain text: Ein Stringwert.Number: Eine Zahl (Ganzzahl oder Gleitkommazahl).Money: Ein Geldwertbetrag. Lassen Sie das Währungssymbol bei der Beschriftung weg.- Wenn die Einheit extrahiert wird, wird sie auf
google.type.Moneynormalisiert.
- Wenn die Einheit extrahiert wird, wird sie auf
Currency: ein Währungssymbol.Datetime: Ein Datums- oder Zeitwert.- Wenn die Entität extrahiert wird, wird sie in das Textformat
ISO 8601normalisiert.
- Wenn die Entität extrahiert wird, wird sie in das Textformat
Address: eine Standortadresse.- Wenn die Entität extrahiert wird, wird sie normalisiert und mit EKG angereichert.
Checkbox– ein boolescher Wert (trueoderfalse).Signature: Ein boolescher Wert (trueoderfalse) innormalized_value.signature_value, der angibt, ob eine Signatur vorhanden ist. Es unterstützt diederive-Methoden.mention_text: Ein boolescher Wert vom TypDetectedoder ein leerer boolescher Wert vom Typ""inhas_signed, der angibt, ob eine Signatur vorhanden ist. Es unterstützt diederive-Methoden.normalized_value.text: Ein boolescher Wert vom TypDetectedoder ein leerer boolescher Wert vom Typ""inhas_signed, der angibt, ob eine Signatur vorhanden ist. Es unterstützt diederive-Methoden.normalized_value.boolean_valueist nicht ausgefüllt.
Methode
- Wenn das Element
extractedist, sind die FeldertextAnchor,type,mentionTextundpageAnchorausgefüllt. - Wenn die Einheit
derivedist, sind die abgeleiteten Werte möglicherweise nicht im Dokumenttext enthalten. Die FeldertextAnchorundpageAnchor.pageRefs[].bounding_polysind nicht ausgefüllt.
Vorkommen
Wählen Sie REQUIRED aus, wenn eine Entität immer in Dokumenten eines bestimmten Typs vorkommen soll. Wählen Sie OPTIONAL aus, wenn es keine solche Erwartung gibt.
Wählen Sie ONCE aus, wenn eine Entität einen Wert haben soll, auch wenn derselbe Wert mehrmals im selben Dokument vorkommt. Wählen Sie MULTIPLE aus, wenn eine Einheit mehrere Werte haben soll.
Übergeordnete und untergeordnete Labels
Mit Über- und Unterordnungslabels (auch als tabellarische Einheiten bezeichnet) werden Daten in einer Tabelle gekennzeichnet. Die folgende Tabelle enthält 3 Zeilen und 4 Spalten.

Sie können solche Tabellen mit Labels für übergeordnete und untergeordnete Elemente definieren. In diesem Beispiel definiert das übergeordnete Label line-item eine Zeile der Tabelle.
Übergeordnetes Label erstellen
Wählen Sie auf der Seite Schema bearbeiten die Option Label erstellen aus.
Klicken Sie das Kästchen Das ist ein übergeordnetes Label an und geben Sie die anderen Informationen ein. Das übergeordnete Label muss entweder
optional_multipleoderrequire_multipleenthalten, damit es wiederholt werden kann, um alle Zeilen in der Tabelle zu erfassen.Klicken Sie auf Speichern.
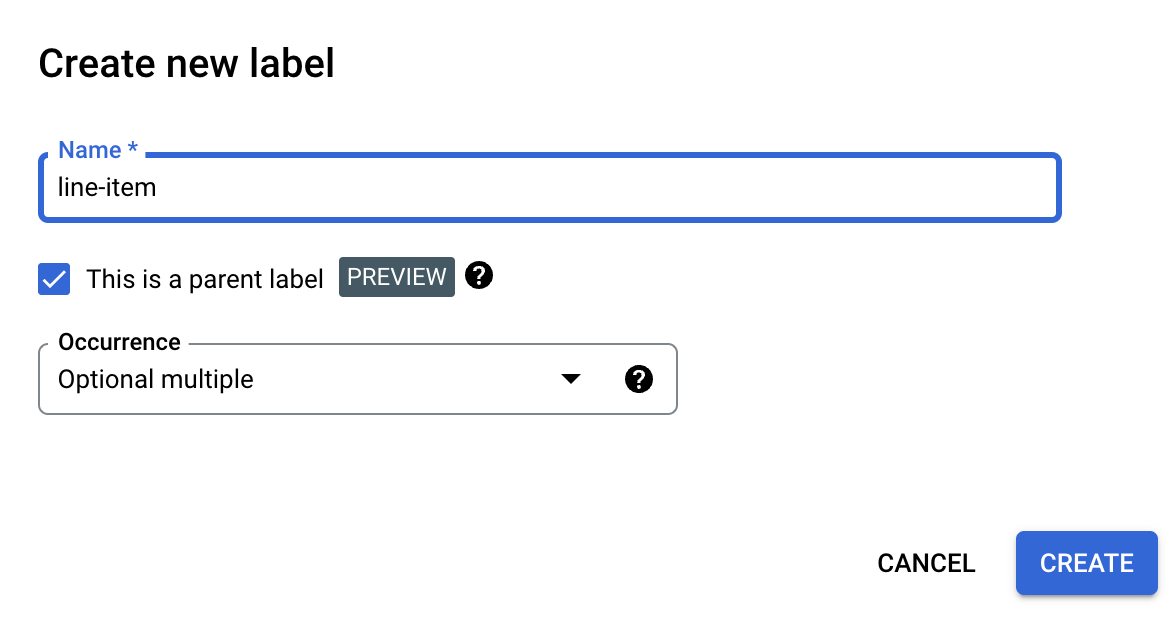
Das übergeordnete Label wird auf der Seite Schema bearbeiten angezeigt. Daneben befindet sich die Option Untergeordnetes Label hinzufügen.
Unterlabel erstellen
Wählen Sie auf der Seite Schema bearbeiten neben dem übergeordneten Label Untergeordnetes Label hinzufügen aus.
Geben Sie die Informationen für das untergeordnete Label ein.
Klicken Sie auf Speichern.
Wiederholen Sie den Vorgang für jedes untergeordnete Label, das Sie hinzufügen möchten.
Die untergeordneten Labels werden auf der Seite Schema bearbeiten unter dem übergeordneten Label eingerückt angezeigt.

Untergeordnete Labels sind eine Vorschaufunktion und werden nur für Tabellen unterstützt. Die Schachtelungstiefe ist auf 1 begrenzt. Untergeordnete Entitäten können also keine weiteren untergeordneten Entitäten enthalten.
Schema-Labels aus Dokumenten mit Labels erstellen
Schemalabels automatisch erstellen, indem Sie vorab mit Labels versehene Document-JSON-Dateien importieren.
Während der Document-Import läuft, werden neu hinzugefügte Schemalabels dem Schema-Editor hinzugefügt. Wählen Sie „Schema bearbeiten“ aus, um den Datentyp und den Vorkommenstyp neuer Schemalabels zu prüfen oder zu ändern. Wählen Sie nach der Bestätigung Schemalabels aus und klicken Sie auf Aktivieren.
Beispieldatensätze
Um den Einstieg in Document AI Workbench zu erleichtern, werden Datasets in einem öffentlichen Cloud Storage-Bucket bereitgestellt, der vorab gelabelte und nicht gelabelte Document-JSON-Beispieldateien verschiedener Dokumenttypen enthält.
Sie können je nach Dokumenttyp für das Nachtrainieren oder für benutzerdefinierte Extraktoren verwendet werden.
gs://cloud-samples-data/documentai/Custom/
gs://cloud-samples-data/documentai/Custom/1040/
gs://cloud-samples-data/documentai/Custom/Invoices/
gs://cloud-samples-data/documentai/Custom/Patents/
gs://cloud-samples-data/documentai/Custom/Procurement-Splitter/
gs://cloud-samples-data/documentai/Custom/W2-redacted/
gs://cloud-samples-data/documentai/Custom/W2/
gs://cloud-samples-data/documentai/Custom/W9/