BigQuery ist in Document AI integriert, um die Entwicklung von Dokumentanalysen und generativen KI-Anwendungsfällen zu unterstützen. Mit der beschleunigten digitalen Transformation generieren Unternehmen riesige Mengen an Text und anderen Dokumentdaten, die ein immenses Potenzial für Erkenntnisse und neue generative KI-Anwendungsfälle bieten. Um diese Daten besser nutzen zu können, haben wir eine Integration zwischen BigQuery und Document AI entwickelt. Damit können Sie Erkenntnisse aus Dokumentdaten gewinnen und neue Anwendungen für Large Language Models (LLMs) erstellen.
Übersicht
BigQuery-Kunden können jetzt Document AI-benutzerdefinierte Extraktoren erstellen, die auf den hochmodernen Foundation Models von Google basieren und die sie anhand ihrer eigenen Dokumente und Metadaten anpassen können. Diese benutzerdefinierten Modelle können dann aus BigQuery aufgerufen werden, um strukturierte Daten aus Dokumenten auf sichere und kontrollierte Weise zu extrahieren. Dabei wird die Einfachheit und Leistungsfähigkeit von SQL genutzt. Vor dieser Integration haben einige Kunden versucht, unabhängige Document AI-Pipelines zu erstellen, was die manuelle Zusammenstellung von Extraktionslogik und ‑schema erforderte. Da keine integrierten Integrationsfunktionen vorhanden waren, mussten sie eine maßgeschneiderte Infrastruktur entwickeln, um Daten zu synchronisieren und die Datenkonsistenz aufrechtzuerhalten. Dadurch wurde jedes Dokumentanalyseprojekt zu einem erheblichen Unterfangen, das erhebliche Investitionen erforderte. Mit dieser Integration können Kunden jetzt Remote-Modelle in BigQuery für ihre benutzerdefinierten Extraktoren in Document AI erstellen und damit Dokumentanalysen und generative KI im großen Maßstab durchführen. Das eröffnet eine neue Ära datengestützter Erkenntnisse und Innovationen.
Einheitliche, geregelte Daten-zu-KI-Lösung
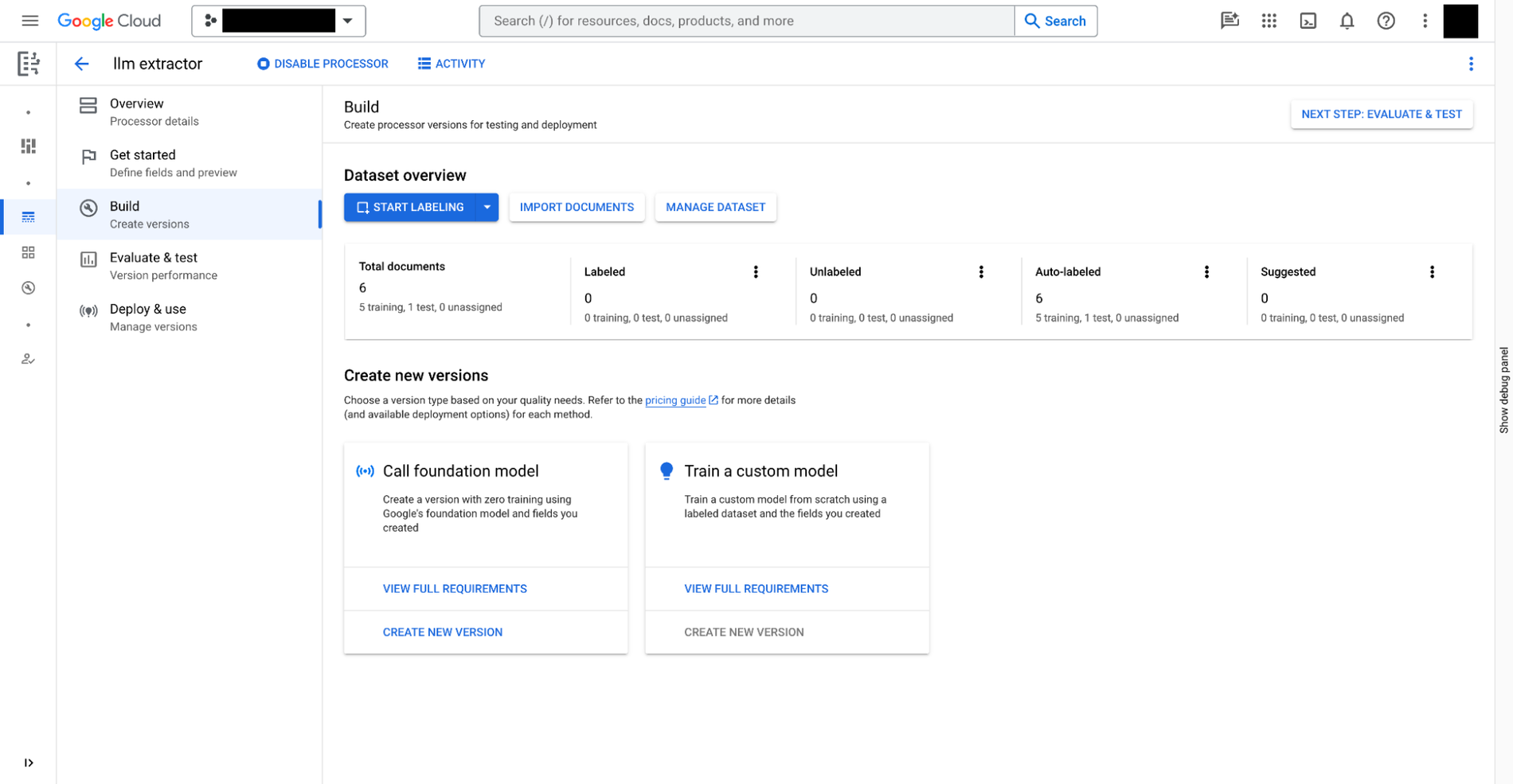
Sie können einen benutzerdefinierten Extraktor in Document AI in drei Schritten erstellen:
- Definieren Sie die Daten, die Sie aus Ihren Dokumenten extrahieren möchten. Das wird als
document schemabezeichnet und mit jeder Version des benutzerdefinierten Extraktors gespeichert. Es ist über BigQuery zugänglich. - Sie können optional zusätzliche Dokumente mit Anmerkungen als Beispiele für die Extraktion bereitstellen.
- Trainieren Sie das Modell für den benutzerdefinierten Extraktor auf der Grundlage der in Document AI bereitgestellten Foundation Models.
Neben benutzerdefinierten Extraktoren, die manuelles Training erfordern, bietet Document AI in der Prozessorgalerie auch sofort einsatzbereite Extraktoren für Ausgaben, Belege, Rechnungen, Steuerformulare, amtliche Ausweise und viele andere Szenarien.
Sobald Sie den benutzerdefinierten Extraktor erstellt haben, können Sie in BigQuery Studio die Dokumente mit SQL analysieren. Gehen Sie dazu so vor:
- Registrieren Sie ein BigQuery-Remote-Modell für den Extractor mit SQL. Das Modell kann das oben erstellte Dokumentschema verstehen, den benutzerdefinierten Extraktor aufrufen und die Ergebnisse parsen.
- Objekttabellen mit SQL für die in Cloud Storage gespeicherten Dokumente erstellen Sie können die unstrukturierten Daten in den Tabellen verwalten, indem Sie Zugriffsrichtlinien auf Zeilenebene festlegen. Dadurch wird der Zugriff von Nutzern auf bestimmte Dokumente eingeschränkt und die KI-Leistung für Datenschutz und Sicherheit wird begrenzt.
- Verwenden Sie die Funktion
ML.PROCESS_DOCUMENTin der Objekttabelle, um relevante Felder zu extrahieren, indem Sie Inferenzaufrufe an den API-Endpunkt senden. Sie können die Dokumente für die Extraktionen auch mit einerWHERE-Klausel außerhalb der Funktion herausfiltern. Die Funktion gibt eine strukturierte Tabelle zurück, wobei jede Spalte ein extrahiertes Feld ist. - Führen Sie die extrahierten Daten mit anderen BigQuery-Tabellen zusammen, um strukturierte und unstrukturierte Daten zu kombinieren und so einen geschäftlichen Mehrwert zu schaffen.
Das folgende Beispiel veranschaulicht die Nutzererfahrung:
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.
CREATE OR REPLACE EXTERNAL TABLE `my_dataset.document`
WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://my_bucket/path/*'],
metadata_cache_mode= 'AUTOMATIC',
max_staleness= INTERVAL 1 HOUR
);
# Create a remote model to register your Doc AI processor in BigQuery.
CREATE OR REPLACE MODEL `my_dataset.layout_parser`
REMOTE WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
remote_service_type = 'CLOUD_AI_DOCUMENT_V1',
document_processor='PROCESSOR_ID'
);
# Invoke the registered model over the object table to parse PDF document
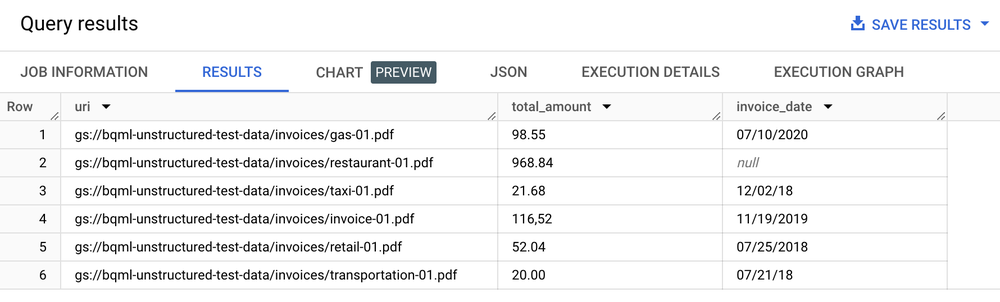
SELECT uri, total_amount, invoice_date
FROM ML.PROCESS_DOCUMENT(
MODEL `my_dataset.layout_parser`,
TABLE `my_dataset.document`,
PROCESS_OPTIONS => (
JSON '{"layout_config": {"chunking_config": {"chunk_size": 250}}}')
)
WHERE content_type = 'application/pdf';
Ergebnistabelle
Textanalyse, Zusammenfassung und andere Anwendungsfälle für die Dokumentanalyse
Nachdem Sie Text aus Ihren Dokumenten extrahiert haben, können Sie die Dokumente auf verschiedene Arten analysieren:
- BigQuery ML für die Textanalyse verwenden: BigQuery ML unterstützt das Trainieren und Bereitstellen von Einbettungsmodellen auf verschiedene Arten. Mit BigQuery ML können Sie beispielsweise die Stimmung von Kunden bei Supportanrufen ermitteln oder Produktfeedback in verschiedene Kategorien einteilen. Wenn Sie Python verwenden, können Sie auch BigQuery DataFrames für pandas und scikit-learn-ähnliche APIs für die Textanalyse Ihrer Daten verwenden.
- Mit dem
text-embedding-004-LLM Einbettungen aus den in Chunks aufgeteilten Dokumenten generieren: BigQuery hat eineML.GENERATE_EMBEDDING-Funktion, mit der dastext-embedding-004-Modell aufgerufen wird, um Einbettungen zu generieren. Sie können beispielsweise Document AI verwenden, um Kundenfeedback zu extrahieren, und das Feedback mit PaLM 2 zusammenfassen lassen – alles mit BigQuery SQL. - Dokumentmetadaten mit anderen strukturierten Daten in BigQuery-Tabellen zusammenführen:
Sie können beispielsweise Einbettungen mit den in Chunks aufgeteilten Dokumenten generieren und für die Vektorsuche verwenden.
# Example 1: Parse the chunked data
CREATE OR REPLACE TABLE docai_demo.demo_result_parsed AS (SELECT
uri,
JSON_EXTRACT_SCALAR(json , '$.chunkId') AS id,
JSON_EXTRACT_SCALAR(json , '$.content') AS content,
JSON_EXTRACT_SCALAR(json , '$.pageFooters[0].text') AS page_footers_text,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageStart') AS page_span_start,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end
FROM docai_demo.demo_result, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json)
# Example 2: Generate embedding
CREATE OR REPLACE TABLE `docai_demo.embeddings` AS
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL `docai_demo.embedding_model`,
TABLE `docai_demo.demo_result_parsed`
);
Anwendungsfälle für Suche und generative KI implementieren
Nachdem Sie strukturierten Text aus Ihren Dokumenten extrahiert haben, können Sie mithilfe der Such- und Indexierungsfunktionen von BigQuery Indizes erstellen, die für „Nadel im Heuhaufen“-Abfragen optimiert sind. Diese Integration ermöglicht auch neue generative LLM-Anwendungen wie die Ausführung der Verarbeitung von Textdateien für Datenschutzfilterung, Inhaltsüberprüfung und Token-Chunking mit SQL und benutzerdefinierten Document AI-Modellen. Der extrahierte Text in Kombination mit anderen Metadaten vereinfacht die Zusammenstellung des Trainingskorpus, der zum Feinabstimmen von Large Language Models erforderlich ist. Außerdem erstellen Sie LLM-Anwendungsfälle auf Grundlage von verwalteten Unternehmensdaten, die durch die Funktionen von BigQuery zur Generierung von Einbettungen und zur Verwaltung von Vektorindexen fundiert sind. Wenn Sie diesen Index mit Vertex AI synchronisieren, können Sie RAG-Anwendungsfälle (Retrieval Augmented Generation) implementieren und so eine besser verwaltete und optimierte KI-Umgebung schaffen.
Beispielanwendung
Beispiel für eine End-to-End-Anwendung mit dem Document AI Connector:
- Demo dieser Spesenabrechnung auf GitHub
- Begleitender Blogpost
- Sehen Sie sich das Video von der Google Cloud Next 2021 an.