多くの組織では、さまざまなビジネス目的でデータを分析できるように、クラウド データ ウェアハウスをデプロイし、機密情報を保存しています。このドキュメントでは、Enterprise Data Management Council が管理する Cloud Data Management Capabilities(CDMC)のキー コントロール フレームワークを BigQuery データ ウェアハウスに実装する方法について説明します。
CDMC キー コントロール フレームワークは、主にクラウド サービス プロバイダとテクノロジー プロバイダ向けに公開されました。このフレームワークには 14 のキー コントロールが記述されています。プロバイダは、これらのコントロールを実装することで、自社の顧客がクラウド上で機密データを効果的に管理し、統制できるようにすることができます。このコントロールは、100 社以上の 300 名を超える専門家が参加している CDMC ワーキング グループによって作成されています。CDMC ワーキング グループは、既存の法的要件と規制要件の多くを考慮し、フレームワークを策定しました。
この BigQuery と Data Catalog のリファレンス アーキテクチャは、CDMC キー コントロール フレームワークに基づく審査を受け、CDMC 認定クラウド ソリューションとして認定されています。このリファレンス アーキテクチャでは、さまざまな Google Cloud サービスと機能、公開ライブラリを使用して、CDMC キー コントロールと推奨される自動化を実装しています。このドキュメントでは、BigQuery データ ウェアハウス内でセンシティブ データを保護する際に役立つキー コントロールの実装方法について説明します。
アーキテクチャ
次の Google Cloud リファレンス アーキテクチャは、CDMC キー コントロール フレームワークのテスト仕様 v1.1.1 に準拠しています。図中の番号は、 Google Cloud サービスが対応しているキー コントロールを表しています。

このリファレンス アーキテクチャは、セキュア データ ウェアハウスのブループリントに元づいて構築されています。このブループリントは、機密情報が保存されている BigQuery データ ウェアハウスの保護に役立つアーキテクチャを提供します。前の図で、上のグレーの部分はセキュア データ ウェアハウスのブループリントに含まれているプロジェクトです。青い部分はデータ ガバナンス プロジェクトで、CDMC キー コントロール フレームワークの要件を満たすために追加されたサービスが含まれています。CDMC キー コントロール フレームワークを実装するため、このアーキテクチャではデータ ガバナンス プロジェクトを拡張しています。データ ガバナンス プロジェクトは、分類、ライフサイクル管理、データ品質管理などのコントロールから構成されています。また、プロジェクトでは、アーキテクチャを監査して検出結果を報告する手段も用意されています。
このリファレンス アーキテクチャの詳しい実装方法については、GitHub の Google Cloud CDMC リファレンス アーキテクチャをご覧ください。
CDMC キー コントロール フレームワークの概要
次の表に、CDMC キー コントロール フレームワークの概要を示します。
| # | CDMC キー コントロール | CDMC コントロール要件 |
|---|---|---|
| 1 | データ管理のコンプライアンス | クラウドのデータ マネジメントのビジネスケースが定義され、統制されている。機密データを含むすべてのデータアセットは、指標と自動通知を使用してモニタリングし、CDMC キー コントロールの遵守状況を確認する必要があります。 |
| 2 | 移行データとクラウド生成データの両方にデータの所有権が確立している | すべての機密データに対して、データカタログの Ownership フィールドが設定されている必要があります。そうでない場合は、定義済みのワークフローに報告される必要があります。 |
| 3 | データのソーシングと利用が統制され、自動化によってサポートされている | 機密データを含むすべてのデータアセットに対して、信頼できるデータソースとプロビジョニング ポイントの登録が行われる必要があります。そうでない場合は、定義済みのワークフローに報告される必要があります。 |
| 4 | データ主権と境界を越えるデータの移動が管理されている | 機密データのデータ主権と境界を越えた移動が、定義されたポリシーに従って記録、監査、管理されている必要があります。 |
| 5 | データカタログが実装、使用され、相互運用されている | データの作成または取り込みの時点で、すべてのデータに対してカタログ化が自動的に実行され、環境間で整合性が維持されるようにする必要があります。 |
| 6 | データ分類が定義され、使用されている | データの作成または取り込みの時点で、すべてのデータに対して分類が自動的に実行される必要があります。また、この機能は常に有効にしておく必要があります。分類は、次のものに対して自動的に実行されます。
|
| 7 | データの利用資格が管理、適用、追跡されている | このコントロールの要件は次のとおりです。
|
| 8 | データの倫理的アクセス、使用、結果が管理されている | 機密データを含むすべてのデータ共有の合意で、データの使用目的を提示する必要があります。この目的には、必要なデータの種類を指定する必要があります。また、グローバル組織の場合は、国や法人のスコープを指定する必要があります。 |
| 9 | データが保護され、コントロールが証明されている | このコントロールの要件は次のとおりです。
|
| 10 | データ プライバシー フレームワークが定義され、運用されている | 管轄区域によっては、すべての個人データに対してデータ保護影響評価(DPIA)を自動的にトリガーする必要があります。 |
| 11 | データ ライフサイクルが計画され、管理されている | 定義済みの保持スケジュールに従って、データの保持、アーカイブ、パージが管理されている必要があります。 |
| 12 | データ品質が管理されている | 利用可能であれば、指標が分散している機密データに対してデータ品質の測定を有効にする必要があります。 |
| 13 | 費用管理の原則が確立され、適用されている | 技術的な設計の原則が確立され、適用されています。データの使用、保存、移動に直接関連するコスト指標がカタログで利用可能になっている必要があります。 |
| 14 | データの来歴と系列が理解されている | すべての機密データに対して、データの系列情報が利用可能になっている必要があります。この情報には、少なくとも、データの取り込み元となっているソース、またはクラウド環境でデータが作成されたソースを含める必要があります。 |
1. データ管理のコンプライアンス
このコントロールの要件を満たすには、すべての機密データをモニタリングし、指標を使用してこのフレームワークの遵守状況を確認できるようにする必要があります。
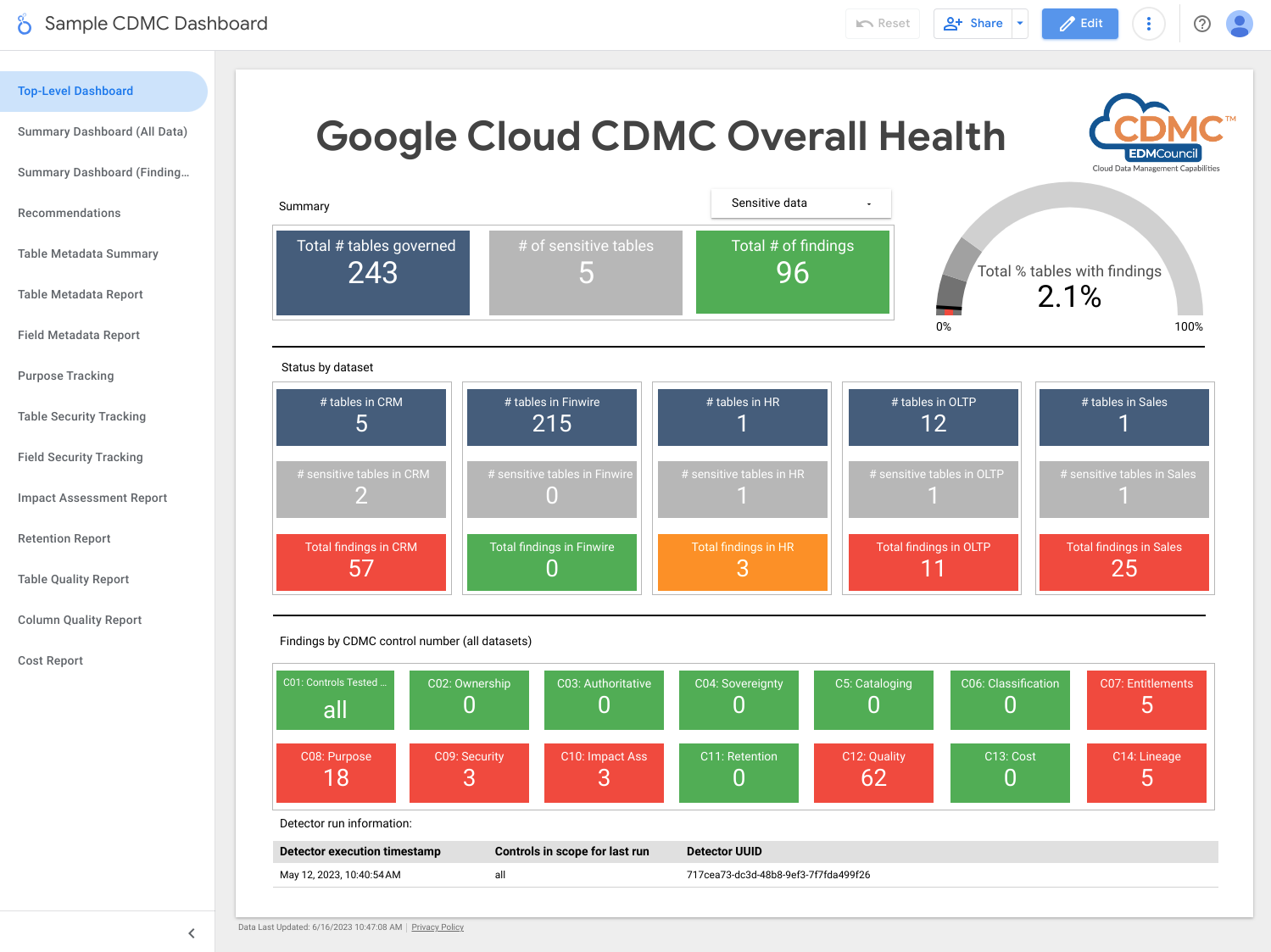
このアーキテクチャでは、各キー コントロールの運用範囲を示す指標を使用しています。また、指標が定義済みのしきい値を満たしていないことを示すダッシュボードも含まれています。
このアーキテクチャには、データアセットがキー コントロールを満たしていない場合に、検出結果と修復の推奨事項を公開する検出機能が含まれています。これらの検出結果と推奨事項は JSON 形式で、サブスクライバーに配布するために Pub/Sub トピックにパブリッシュされます。チケット発行システムでインシデントが自動的に作成されるように、内部サービスデスクやサービス管理ツールを Pub/Sub トピックと統合できます。
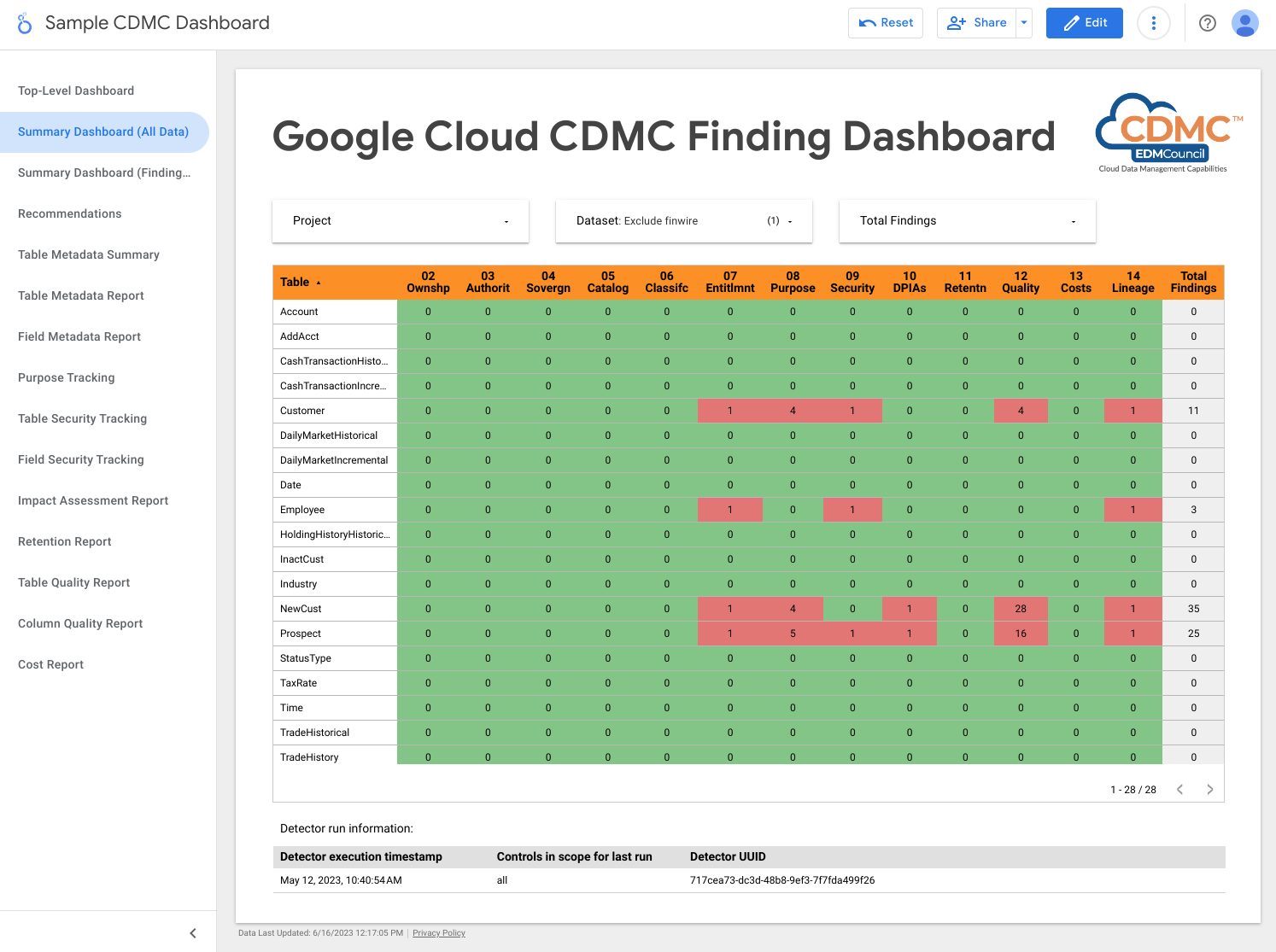
このアーキテクチャでは、Dataflow を使用して、検出結果イベントのサンプル サブスクライバーを作成します。その後、これらはデータ ガバナンス プロジェクトで実行される BigQuery インスタンスに保存されます。提供されたビューを使用すると、 Google Cloud コンソールの BigQuery Studio からデータをクエリできます。Looker Studio や他の BigQuery 互換のビジネス インテリジェンス ツールを使用してレポートを作成することもできます。表示されるレポートには、次の情報が含まれます。
- 前回の実行の検出結果の概要
- 前回の実行の検出結果の詳細
- 前回の実行のメタデータ
- 前回の実行のスコープ内のデータアセット
- 前回の実行のデータセットの統計情報
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- Pub/Sub が検出結果をパブリッシュします。
- Dataflow が BigQuery インスタンスに検出結果を読み込みます。
- BigQuery が検出結果のデータを保存し、概要ビューを提供します。
- Looker Studio がダッシュボードとレポートを提供します。
次のスクリーンショットは、Looker Studio の概要ダッシュボードのサンプルです。
次のスクリーンショットは、データアセット別の検出結果のサンプルビューです。
2. 移行データとクラウド生成データの両方にデータの所有権が確立している
コントロールの要件を満たすため、このアーキテクチャでは BigQuery データ ウェアハウス内のデータを自動的に確認し、すべての機密データについてオーナーが特定されていることを示すデータ分類タグを追加します。
Data Catalog は、テクニカル メタデータとビジネス メタデータの 2 種類のメタデータを処理します。Data Catalog は、特定のプロジェクトに対して BigQuery データセット、テーブル、ビューを自動的にカタログ化し、テクニカル メタデータを設定します。カタログ アセットとデータアセットの同期はほぼリアルタイムで維持されます。
このアーキテクチャでは、Tag Engine を使用して、次のビジネス メタデータのタグを Data Catalog の CDMC controls タグ テンプレートに追加します。
is_sensitive: データアセットに機密データが含まれているかどうか(データ分類のコントロール 6 を参照)owner_name: データのオーナーowner_email: オーナーのメールアドレス
タグは、データ ガバナンス プロジェクトの BigQuery 参照テーブルに格納されているデフォルト値を使用して挿入されます。
デフォルトでは、テーブルレベルで所有権のメタデータが設定されますが、列レベルでメタデータを設定するようにアーキテクチャを変更することもできます。詳細については、Data Catalog タグとタグ テンプレートをご覧ください。
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- 2 つの BigQuery データ ウェアハウス。1 つは機密データを保存し、もう 1 つはデータアセット所有権のデフォルトを保存します。
- Data Catalog がタグ テンプレートとタグにより所有権のメタデータを格納します。
- 次の 2 つの Cloud Run インスタンス。
- 1 つのインスタンスが Report Engine を実行します。タグが適用されたかどうかを確認し、結果を公開します。
- もう 1 つのインスタンスが Tag Engine を実行し、セキュア データ ウェアハウス内のデータにタグを設定します。
- Pub/Sub が検出結果をパブリッシュします。
コントロールに関連する問題を検出するため、このアーキテクチャでは、機密データがオーナー名タグに割り当てられているかどうかを確認します。
3. データのソーシングと利用が統制され、自動化によってサポートされている
このコントロールの要件を満たすには、データアセットの分類と、信頼できるソースおよび認定ディストリビューターのデータ レジストリが必要です。このアーキテクチャでは、Data Catalog を使用して is_authoritative タグを CDMC
controls タグ テンプレートに追加します。このタグは、データアセットが信頼できるものかどうかを示します。
Data Catalog は、テクニカル メタデータとビジネス メタデータを使用して、BigQuery のデータセット、テーブル、ビューをカタログ化します。テクニカル メタデータは自動的に入力されます。これには、プロビジョニング ポイントであるリソース URL が含まれます。ビジネス メタデータは Tag Engine 構成ファイルに定義されます。これには is_authoritative タグが含まれます。
スケジュールされた次回の実行中に、BigQuery の参照テーブルに保存されたデフォルト値から CDMC controls タグ テンプレートの is_authoritative タグが設定されます。
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- 2 つの BigQuery データ ウェアハウス。1 つは機密データを保存し、もう 1 つはデータアセットの信頼できるソースのデフォルトを保存します。
- Data Catalog は、タグを使用して信頼できるソース メタデータを保存します。
- 次の 2 つの Cloud Run インスタンス。
- 1 つのインスタンスが Report Engine を実行します。タグが適用されたかどうかを確認し、結果を公開します。
- もう 1 つのインスタンスが Tag Engine を実行し、セキュア データ ウェアハウス内のデータにタグを設定します。
- Pub/Sub が検出結果をパブリッシュします。
コントロールに関連する問題を検出するため、このアーキテクチャでは、信頼できるソースタグが機密データに割り当てられているかどうかを確認します。
4. データ主権と境界を越えるデータの移動が管理されている
このコントロールの要件を満たすには、アーキテクチャでリージョン固有のストレージ要件についてデータ レジストリを確認し、使用ルールを適用する必要があります。レポートには、データアセットの地理的位置が記述されています。
このアーキテクチャでは、Data Catalog を使用して approved_storage_location タグを CDMC controls タグ テンプレートに追加します。このタグは、データアセットの保存が許可されている地理的位置を定義します。
データの実際の場所は、BigQuery テーブルの詳細にテクニカル メタデータとして保存されます。BigQuery では、管理者はデータセットまたはテーブルのロケーションを変更できません。管理者がデータの場所を変更する場合は、データセットをコピーする必要があります。
リソース ロケーションの組織のポリシー サービスの制約で、データを保存できる Google Cloud リージョンを定義します。デフォルトでは、機密データ プロジェクトに制約が設定されますが、必要に応じて組織レベルまたはフォルダレベルで制約を設定することもできます。Tag Engine は、許可されたロケーションを Data Catalog タグ テンプレートに複製し、ロケーションを approved_storage_location タグに保存します。Security Command Center のプレミアム ティアが有効な状態で、リソース ロケーションの組織のポリシー サービスの制約が更新されると、Security Command Center は、更新されたポリシーの外部に保存されているリソースに対して脆弱性の検出結果を生成します。
Access Context Manager は、ユーザーがデータアセットにアクセスする前にいる必要がある地理的位置を定義します。アクセスレベルを使用すると、リクエストの送信元となるリージョンを指定できます。次に、機密データ プロジェクトの VPC Service Controls の境界にアクセス ポリシーを追加します。
データの移動を追跡するため、BigQuery は、各データセットに対してすべてのジョブとクエリの完全な監査証跡を保持します。監査証跡は BigQuery の情報スキーマジョブに保存されます。
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- 組織のポリシー サービスは、リソース ロケーションの制約を定義して適用します。
- Access Context Manager では、ユーザーがデータにアクセスできるロケーションを定義します。
- 2 つの BigQuery データ ウェアハウス: 1 つは機密データを格納し、もう 1 つはロケーション ポリシーの検査に使用されるリモート機能をホストします。
- Data Catalog が、承認されたストレージのロケーションをタグとして保存します。
- 次の 2 つの Cloud Run インスタンス。
- 1 つのインスタンスが Report Engine を実行します。タグが適用されたかどうかを確認し、結果を公開します。
- もう 1 つのインスタンスが Tag Engine を実行し、セキュア データ ウェアハウス内のデータにタグを設定します。
- Pub/Sub が検出結果をパブリッシュします。
- Cloud Logging が監査ログを書き込みます。
- Security Command Center が、リソースのロケーションまたはデータアクセスに関連するあらゆる検出結果を報告します。
コントロールに関連する問題を検出するため、このアーキテクチャには、承認されたロケーション タグに機密データのロケーションが含まれているかどうかを示す検出結果が含まれています。
5. データカタログが実装、使用され、相互運用されている
このコントロールの要件を満たすには、データカタログが存在している必要があります。また、アーキテクチャが必要に応じて新しいアセットと更新されたアセットをスキャンし、メタデータを追加できるようにする必要があります。
このコントロールの要件を満たすため、アーキテクチャは Data Catalog を使用します。Data Catalog は、BigQuery データセット、テーブル、ビューなどのGoogle Cloud アセットを自動的にロギングします。BigQuery で新しいテーブルを作成すると、Data Catalog は新しいテーブルのテクニカル メタデータとスキーマを自動的に登録します。BigQuery でテーブルを更新すると、ほぼ同時に Data Catalog のエントリが更新されます。
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- 2 つの BigQuery データ ウェアハウス。1 つは機密データを格納し、もう 1 つは非機密データを格納します。
- Data Catalog は、テーブルとフィールドのテクニカル メタデータを保存します。
このアーキテクチャのデフォルトでは、Data Catalog が BigQuery のテクニカル メタデータを保存します。必要に応じて、Data Catalog を他のデータソースと統合できます。
6. データ分類が定義され、使用されている
この要件を満たすには、PII かどうか、クライアントが特定されるかどうか、組織が定義するその他の標準を満たしているかどうかなど、機密性に基づいてデータを分類できる必要があります。このコントロールの要件を満たすため、アーキテクチャはデータアセットとその機密性に関するレポートを作成します。このレポートを使用して、機密性の設定が正しいかどうかを確認できます。新しいデータアセットの追加や既存のデータアセットへの変更が発生するたびに、データカタログが更新されます。
分類は、テーブルレベルと列レベルで Data Catalog タグ テンプレートの sensitive_category タグに格納されます。分類参照テーブルにより、利用可能な Sensitive Data Protection 情報タイプ(infoType)をランク付けし、より機密性の高いコンテンツに対してより高いランクを設定できます。
このコントロールの要件を満たすため、このアーキテクチャでは、Sensitive Data Protection、Data Catalog、Tag Engine を使用して、BigQuery テーブルの機密列に次のタグを追加します。
is_sensitive: データアセットが機密情報を含むかどうかsensitive_category: データのカテゴリ。次のいずれかです。- 個人を特定できる機密情報
- 個人を特定できる情報
- 機密性の高い個人情報
- 個人情報
- 公開情報
データのカテゴリは要件に合わせて変更できます。たとえば、分類に重要未公開情報(MNPI)を追加できます。
Sensitive Data Protection がデータを検査した後、Tag Engine がアセットごとに DLP results テーブルを読み取り、検出結果を編集します。テーブルに 1 つ以上の機密 infoType を含む列がある場合、最も顕著な infoType を特定し、その機密情報を含む列とテーブル全体の両方を最高ランクのカテゴリとしてタグ付けします。Tag Engine はまた、対応するポリシータグを列に割り当て、is_sensitive ブール値タグをテーブルに割り当てます。
Cloud Scheduler を使用して Sensitive Data Protection 検査を自動化できます。
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- 4 つの BigQuery データ ウェアハウス。次の情報が保存されます。
- 機密データ
- Sensitive Data Protection の結果情報
- データ分類の参照データ
- タグのエクスポート情報
- Data Catalog は分類タグを保存します。
- Sensitive Data Protection はアセットを検査し、機密 infoType が含まれるかどうか調査します。
- Compute Engine がデータセットを検査するスクリプトを実行します。このスクリプトは、各 BigQuery データセットに対して Sensitive Data Protection ジョブをトリガーします。
- 次の 2 つの Cloud Run インスタンス。
- 1 つのインスタンスが Report Engine を実行します。タグが適用されたかどうかを確認し、結果を公開します。
- もう 1 つのインスタンスが Tag Engine を実行し、セキュア データ ウェアハウス内のデータにタグを設定します。
- Pub/Sub が検出結果をパブリッシュします。
コントロールに関連する問題を検出するため、このアーキテクチャには次の検出結果が含まれています。
- 機密データに機密性の高いカテゴリのタグが割り当てられているかどうか。
- 機密データに列レベルの機密性タイプのタグが割り当てられているかどうか。
7. データの利用資格が管理、適用、追跡されている
デフォルトでは、作成者とオーナーにのみ利用資格が割り当てられ、機密データにアクセスが許可されています。また、このコントロールの要件を満たすには、アーキテクチャが機密データへのすべてのアクセスを追跡する必要があります。
このコントロールの要件を満たすため、アーキテクチャでは BigQuery の cdmc
sensitive data classification ポリシータグ分類を使用して、BigQuery テーブルで機密データを含む列に対するアクセスを制御します。分類には、次のポリシータグが含まれます。
- 個人を特定できる機密情報
- 個人を特定できる情報
- 機密性の高い個人情報
- 個人情報
ポリシータグにより、BigQuery テーブルで機密の列を表示できるユーザーを制御できます。アーキテクチャ タグは、これらのポリシータグを Sensitive Data Protection の infoType から導出される機密分類にマッピングします。たとえば、sensitive_personal_identifiable_information ポリシータグと機密カテゴリは、AGE、DATE_OF_BIRTH、PHONE_NUMBER、EMAIL_ADDRESS などの infoType にマッピングされます。
アーキテクチャでは、Identity and Access Management(IAM)を使用して、データへのアクセスが必要なグループ、ユーザー、サービス アカウントを管理します。IAM 権限は、テーブルレベルのアクセスを行うために特定のアセットに付与されます。また、ポリシータグに基づく列レベルのアクセスにより、機密データアセットへのきめ細かなアクセス制御が可能になります。デフォルトでは、ユーザーには定義されたポリシータグを持つ列へのアクセスは許可されません。
認証されたユーザーのみがデータにアクセスできるように、Google Cloud では Cloud Identity を使用します。これにより、既存の ID プロバイダと連携させてユーザーの認証を行うことができます。
また、このコントロールの要件を満たすには、利用資格が定義されていないデータアセットを定期的にチェックする必要があります。検出機能は Cloud Scheduler によって管理され、次のシナリオをチェックします。
- データアセットに機密性の高いカテゴリが含まれているが、関連するポリシータグがない。
- カテゴリがポリシータグと一致しない。
これらのシナリオが発生すると、検出機能は検出結果を生成します。これは Pub/Sub によってパブリッシュされてから、Dataflow によって BigQuery の events テーブルに書き込まれます。その後、検出結果を修復ツールに配信できます。1. データ管理のコンプライアンスをご覧ください。
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- BigQuery データ ウェアハウスは、きめ細かいアクセス制御のため、機密データとポリシータグ バインディングを保存します。
- IAM はアクセスを管理します。
- 機密性の高いカテゴリの場合、Data Catalog はテーブルレベルと列レベルのタグを保存します。
- 次の 2 つの Cloud Run インスタンス。
- 1 つのインスタンスが Report Engine を実行します。タグが適用されたかどうかを確認し、結果を公開します。
- もう 1 つのインスタンスが Tag Engine を実行し、セキュア データ ウェアハウス内のデータにタグを設定します。
コントロールに関連する問題を検出するため、このアーキテクチャでは、機密データに対応するポリシータグがあるかどうかを確認します。
8. データの倫理的アクセス、使用、結果が管理されている
このコントロールの要件を満たすには、データ プロバイダとデータ利用者の両方からのデータ共有の合意(承認された利用目的のリストを含む)がアーキテクチャに保存されている必要があります。機密データの利用目的は、クエリラベルを使用して、BigQuery に保存されている利用資格にマッピングされます。利用者が BigQuery の機密データをクエリする場合、利用資格に一致する有効な目的(たとえば、SET @@query_label = “use:3”;)を指定する必要があります。
このアーキテクチャでは、Data Catalog を使用して、次のタグを CDMC controls タグ テンプレートに追加します。以下のタグは、データ プロバイダとのデータ共有の合意を表します。
approved_use: データアセットの承認済みの用途またはユーザーsharing_scope_geography: データアセットを共有できる地理的な場所のリストsharing_scope_legal_entity: データアセットを共有できる合意済みのエンティティのリスト
別の BigQuery データ ウェアハウスには、次のテーブルを含む entitlement_management データセットが含まれています。
provider_agreement: データ プロバイダとのデータ共有の合意(合意した法人と地理的範囲などを含む)。このデータは、shared_scope_geographyタグとsharing_scope_legal_entityタグのデフォルトになります。consumer_agreement: データ利用者とのデータ共有の合意(合意済みの法人と地理的範囲を含む)。それぞれの合意がデータアセットの IAM バインディングに関連付けられます。use_purpose: 利用目的(データアセットの使用状況の説明、許可されたオペレーションなど)。data_asset: データアセットに関する情報(アセット名、データオーナーの詳細など)。
データ共有の合意を監査するため、BigQuery は、各データセットに対してすべてのジョブとクエリの完全な監査証跡を保持します。監査証跡は BigQuery の情報スキーマジョブに保存されます。クエリラベルをセッションに関連付けてセッション内でクエリを実行すると、そのクエリラベルを持つクエリの監査ログを収集できます。詳細については、BigQuery の監査ログ リファレンスをご覧ください。
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- 2 つの BigQuery データ ウェアハウス: 1 つは機密データを保存し、もう 1 つは利用資格データ(プロバイダと利用者のデータ共有の合意と承認された利用目的を含む)を保存します。
- Data Catalog は、プロバイダのデータ共有の合意情報をタグとして保存します。
- 次の 2 つの Cloud Run インスタンス。
- 1 つのインスタンスが Report Engine を実行します。タグが適用されたかどうかを確認し、結果を公開します。
- もう 1 つのインスタンスが Tag Engine を実行し、セキュア データ ウェアハウス内のデータにタグを設定します。
- Pub/Sub が検出結果をパブリッシュします。
コントロールに関連する問題を検出するため、このアーキテクチャには次の検出結果が含まれています。
entitlement_managementデータセットにデータアセットのエントリがあるかどうか。- 期限切れのユースケース(たとえば、
consumer_agreement tableのvalid_until_dateが経過した場合)で機密テーブルに対してオペレーションを実行するかどうか。 - 誤ったラベルキーの機密テーブルに対してオペレーションが実行されているかどうか。
- 空白または未承認のユースケースのラベル値を持つ機密テーブルに対してオペレーションを実行するかどうか。
- 承認されていないオペレーション方法(たとえば、
SELECTまたはINSERT)で機密テーブルをクエリするかどうか。 - 機密データをクエリする際に、利用者が指定した目的がデータ共有の合意と一致しているかどうか。
9. データが保護され、コントロールが証明されている
このコントロールの要件を満たすには、機密データの保護とこれらのコントロールの記録を提供するために、データの暗号化と匿名化が実装されている必要があります。
このアーキテクチャは、保存データの暗号化を含む Google のデフォルト セキュリティ上に構築されています。さらに、アーキテクチャで顧客管理の暗号鍵(CMEK)を使用して独自の鍵を管理することもできます。Cloud KMS により、ソフトウェア格納型暗号鍵または FIPS 140-2 レベル 3 検証済みのハードウェア セキュリティ モジュール(HSM)でデータを暗号化できます。
このアーキテクチャでは、ポリシータグを通じて構成された列レベルの動的データ マスキングを使用し、機密データを別の VPC Service Controls の境界内に保存します。アプリケーション レベルの匿名化を追加することもできます。この匿名化は、オンプレミスまたはデータ取り込みパイプラインの一部として実装できます。
デフォルトでは、このアーキテクチャは HSM による CMEK 暗号化を実装しますが、Cloud External Key Manager(Cloud EKM)もサポートしています。
次の表に、アーキテクチャが us-central1 リージョンに実装するセキュリティ ポリシーの例を示します。ポリシーは要件に合わせて調整できます(別のリージョンに対する異なるポリシーの追加など)。
| データの機密性 | デフォルトの暗号化方式 | その他の許可された暗号化方式 | デフォルトの匿名化方式 | その他の許可された匿名化方式 |
|---|---|---|---|---|
| 公開情報 | デフォルトの暗号化 | 指定なし | なし | 指定なし |
| 個人を特定できる機密情報 | HSM を使用した CMEK | EKM | null 化 | SHA-256 ハッシュ値またはデフォルトのマスキング値 |
| 個人を特定できる情報 | HSM を使用した CMEK | EKM | SHA-256 ハッシュ | null 値またはデフォルトのマスキング値 |
| 機密性の高い個人情報 | HSM を使用した CMEK | EKM | デフォルトのマスキング値 | SHA-256 ハッシュまたは Nullify |
| 個人情報 | HSM を使用した CMEK | EKM | デフォルトのマスキング値 | SHA-256 ハッシュまたは Nullify |
アーキテクチャでは、Data Catalog を使用して、encryption_method タグをテーブルレベルの CDMC controls タグ テンプレートに追加します。encryption_method は、データアセットで使用される暗号化方法を定義します。
このアーキテクチャでは、特定のフィールドに適用する匿名化方式を識別するために security policy template タグを作成します。アーキテクチャでは、動的データ マスキングで適用される platform_deid_method を使用します。app_deid_method を追加できます。また、保護されたデータ ウェアハウスのブループリントに含まれている Dataflow と Sensitive Data Protection データ取り込みパイプラインによりデータを自動的に入力できます。
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- Dataflow の 2 つのオプション インスタンス。1 つはアプリケーション レベルの匿名化を実行し、もう 1 つは再識別を実行します。
- 3 つの BigQuery データ ウェアハウス: 1 つは機密データを格納し、1 つは非機密データを格納します。3 つめはセキュリティ ポリシーを保存します。
- Data Catalog では、暗号化と匿名化のタグ テンプレートを保存します。
- 次の 2 つの Cloud Run インスタンス。
- 1 つのインスタンスが Report Engine を実行します。タグが適用されたかどうかを確認し、結果を公開します。
- もう 1 つのインスタンスが Tag Engine を実行し、セキュア データ ウェアハウス内のデータにタグを設定します。
- Pub/Sub がパブリッシュする検出結果
コントロールに関連する問題を検出するため、このアーキテクチャには次の検出結果が含まれています。
- 暗号化方式のタグの値が、指定された機密性とロケーションで許可されている暗号化方式と一致しません。
- テーブルには機密性の高い列が含まれていますが、セキュリティ ポリシー テンプレート タグに無効なプラットフォーム レベルの匿名化方式が含まれています。
- テーブルに機密性の高い列が含まれているが、セキュリティ ポリシー テンプレート タグがありません。
10. データ プライバシー フレームワークが定義され、運用されている
このコントロールの要件を満たすには、アーキテクチャでデータカタログと分類を検査して、データ保護影響評価(DPIA)レポートまたはプライバシー影響評価(PIA)レポートを作成する必要があるかどうかを判断する必要があります。プライバシー評価は、地域と規制機関によってかなり異なります。このアーキテクチャでは、影響評価が必要かどうかを判断するため、データの所在地とデータ主体の所在地を考慮する必要があります。
このアーキテクチャでは、Data Catalog を使用して、次のタグを Impact assessment タグ テンプレートに追加します。
subject_locations: このアセットのデータによって参照されるサブジェクトのロケーション。is_dpia: このアセットについてデータ プライバシー影響評価(DPIA)が完了しているかどうか。is_pia: このアセットについてプライバシー影響評価(PIA)が完了したかどうか。impact_assessment_reports: 影響評価レポートを保存する外部リンク。most_recent_assessment: 最新の影響評価の日付。oldest_assessment: 最初の影響の評価の日付。
タグエンジンでは、コントロール 6 で定義されているように、これらのタグを各機密データアセットに追加します。検出機能は、BigQuery のポリシー テーブルに対してこれらのタグを検証します。これには、データの所在地、サブジェクトのロケーション、データの機密性(たとえば、PII であるかどうか)、どの影響評価タイプ(PIA または DPIA)が必要か、などが含まれます。
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- 4 つの BigQuery データ ウェアハウス。次の情報が保存されます。
- 機密データ
- 機密ではないデータ
- 影響評価ポリシーと利用資格のタイムスタンプ
- ダッシュボードで使用されるタグ エクスポート
- Data Catalog では、影響評価の詳細がタグ テンプレート内のタグに保存されます。
- 次の 2 つの Cloud Run インスタンス。
- 1 つのインスタンスが Report Engine を実行します。タグが適用されたかどうかを確認し、結果を公開します。
- もう 1 つのインスタンスが Tag Engine を実行し、セキュア データ ウェアハウス内のデータにタグを設定します。
- Pub/Sub が検出結果をパブリッシュします。
コントロールに関連する問題を検出するため、このアーキテクチャには次の検出結果が含まれています。
- 機密データ存在しますが、影響評価テンプレートがありません。
- 機密データが存在しますが、DPIA または PIA のレポートへのリンクがありません。
- タグがポリシー テーブルの要件を満たしていません。
- 影響評価が、利用者の合意テーブルのデータアセットに対して最近承認された使用資格よりも古くなっています。
11. データ ライフサイクルが計画され、管理されている
このコントロールの要件を満たすには、すべてのデータアセットを調査して、データ ライフサイクル ポリシーが存在し、遵守されていることを確認する必要があります。
このアーキテクチャでは、Data Catalog を使用して、次のタグを CDMC controls タグ テンプレートに追加します。
retention_period: テーブルを保持する日数expiration_action: 保持期間の終了時にテーブルをアーカイブまたはパージするかどうか
デフォルトでは、アーキテクチャは次の保持期間と有効期限のアクションを使用します。
| データのカテゴリ | 保持期間(日数) | 期限切れのアクション |
|---|---|---|
| 個人を特定できる機密情報 | 60 | パージ |
| 個人を特定できる情報 | 90 | アーカイブ |
| 機密性の高い個人情報 | 180 | アーカイブ |
| 個人情報 | 180 | アーカイブ |
BigQuery のオープンソース アセットである Record Manager は、上記のタグ値と構成ファイルに基づいて、BigQuery テーブルのパージとアーカイブを自動化します。パージ手順では、テーブルに有効期限を設定し、Record Manager の構成で定義されている有効期限スナップショット テーブルを作成します。デフォルトでは、有効期限は 30 日間です。ソフト削除期間中にテーブルを取得できます。アーカイブ手順では、保持期間を経過する BigQuery テーブルごとに外部テーブルを作成します。テーブルは Parquet 形式で Cloud Storage に保存され、BigLake テーブルにアップグレードされます。これにより、外部ファイルには Data Catalog のメタデータ内のタグが付きます。
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- 2 つの BigQuery データ ウェアハウス。1 つは機密データを保存し、もう 1 つはデータ保持ポリシーを保存します。
- 2 つの Cloud Storage インスタンス。1 つはアーカイブ ストレージを提供し、もう 1 つはレコードを保存します。
- Data Catalog は、保持期間とアクションをタグ テンプレートとタグに保存します。
- 2 つの Cloud Run インスタンス。1 つはレコード マネージャーを実行し、もう 1 つは検出機能をデプロイします。
- 次の 3 つの Cloud Run インスタンス。
- 1 つのインスタンスが Report Engine を実行します。タグが適用されたかどうかを確認し、結果を公開します。
- もう 1 つのインスタンスが Tag Engine を実行し、セキュア データ ウェアハウス内のデータにタグを設定します。
- 別のインスタンスでレコード マネージャーを実行し、これが BigQuery テーブルのパージとアーカイブを自動化します。
- Pub/Sub が検出結果をパブリッシュします。
コントロールに関連する問題を検出するため、このアーキテクチャには次の検出結果が含まれています。
- 機密性の高いアセットの場合は、保持方式がアセットのロケーションに関するポリシーと整合していることを確認してください。
- 機密性の高いアセットの場合は、保持期間がアセットのロケーションに関するポリシーと整合していることを確認してください。
12. データ品質が管理されている
このコントロールの要件を満たすには、データ プロファイリングまたはユーザー定義の指標に基づいてデータの品質を測定する機能が必要です。
このアーキテクチャには、個々の値または集計した値に対してデータ品質ルールを定義し、特定のテーブル列にしきい値を割り当てる機能があります。また、正確性と完全性のためのタグ テンプレートも用意されています。Data Catalog は、各タグ テンプレートに次のタグを追加します。
column_name: 指標が適用される列の名前metric: 指標または品質のルールの名前rows_validated: 検証された行数success_percentage: この指標を満たす値の割合acceptable_threshold: この指標の許容しきい値meets_threshold: 品質スコア(success_percentage値)が許容しきい値を満たしているかどうかmost_recent_run: 指標または品質のルールが最後に実行された時刻
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- 3 つの BigQuery データ ウェアハウス: 1 つは機密データを格納し、1 つは非機密データを保存します。3 番目は品質ルールの指標を保存します。
- Data Catalog では、データ品質の結果がタグ テンプレートとタグに保存されます。
- Cloud Scheduler は、Cloud Data Quality Engine が実行されるタイミングを定義します。
- 次の 3 つの Cloud Run インスタンス。
- 1 つのインスタンスが Report Engine を実行します。タグが適用されたかどうかを確認し、結果を公開します。
- もう 1 つのインスタンスが Tag Engine を実行し、セキュア データ ウェアハウス内のデータにタグを設定します。
- 3 番目のインスタンスは Cloud Data Quality Engine を実行します。
- Cloud Data Quality Engine はデータ品質ルールを定義し、テーブルと列のデータ品質チェックをスケジューリングします。
- Pub/Sub が検出結果をパブリッシュします。
Looker Studio のダッシュボードには、テーブルレベルと列レベルの両方のデータ品質レポートが表示されます。
コントロールに関連する問題を検出するため、このアーキテクチャには次の検出結果が含まれています。
- 機密性の高いデータですが、データ品質タグ テンプレート(正確性と完全性)が適用されていません。
- 機密性の高いデータですが、データ品質タグが機密性の高い列に適用されません。
- 機密性の高いデータですが、データ品質の結果がルールで設定されているしきい値内にありません。
- 機密性の高いデータではなく、データ品質の結果がルールによって設定されているしきい値内にありません。
Cloud Data Quality Engine の代わりに Dataplex Universal Catalog データ品質タスクを構成することもできます。
13. 費用管理の原則が確立され、適用されている
このコントロールの要件を満たすには、データアセットを調査し、ポリシー要件とデータ アーキテクチャに基づいて費用の使用状況を確認する機能が必要です。費用の指標は包括的であり、ストレージの使用と移動に限定されない必要があります。
このアーキテクチャでは、Data Catalog を使用して、次のタグを cost_metrics タグ テンプレートに追加します。
total_query_bytes_billed: 今月の初めから、このデータアセットに対して課金されたクエリのバイト数の合計。total_storage_bytes_billed: 今月の初めから、このデータアセットに対して課金されたストレージのバイト数の合計。total_bytes_transferred: リージョン間でこのデータアセットに転送されたバイト数の合計。estimated_query_cost: 今月のデータアセットの推定クエリ費用(米ドル)。estimated_storage_cost: 今月のデータアセットの推定ストレージ費用(米ドル)。estimated_egress_cost: データアセットが宛先テーブルとして使用された今月の推定下り(外向き)値(米ドル)。
このアーキテクチャは、Cloud Billing から cloud_pricing_export という名前の BigQuery テーブルに料金情報をエクスポートします。
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- Cloud Billing は課金情報を提供します。
- Data Catalog は、費用情報をタグ テンプレートとタグに保存します。
- BigQuery には、組み込みの INFORMATION_SCHEMA ビューを通じて、エクスポートされた料金情報とクエリ履歴ジョブ情報が保存されます。
- 次の 2 つの Cloud Run インスタンス。
- 1 つのインスタンスが Report Engine を実行します。タグが適用されたかどうかを確認し、結果を公開します。
- もう 1 つのインスタンスが Tag Engine を実行し、セキュア データ ウェアハウス内のデータにタグを設定します。
- Pub/Sub が検出結果をパブリッシュします。
コントロールに関連する問題を検出するために、このアーキテクチャでは、関連付けられている費用指標なしで機密データアセットが存在しているかどうかを確認します。
14. データの来歴と系列が理解されている
このコントロールの要件を満たすには、ソースからのデータアセットのトレーサビリティと、データアセットの系列へのあらゆる変更を検査する機能が必要です。
データの来歴と系列に関する情報を維持するために、このアーキテクチャでは Data Catalog の組み込みのデータ系列機能を使用します。さらに、データ取り込みスクリプトは最終的なソースを定義し、ソースをデータ系列グラフに追加のノードとして追加します。
コントロールの要件を満たすため、このアーキテクチャでは Data Catalog を使用して、ultimate_source タグを CDMC
controls タグ テンプレートに追加します。ultimate_source タグは、このデータアセットのソースを定義します。
次の図は、このコントロールに適用されるサービスを示しています。

コントロールの要件を満たすために、このアーキテクチャでは次のようにサービスを使用しています。
- 2 つの BigQuery データ ウェアハウス: 1 つは機密データを格納し、もう 1 つは最終的なソースデータを保存します。
- Data Catalog は、最終的なテンプレートをタグ テンプレートとタグに保存します。
- データ取り込みスクリプトは、Cloud Storage からデータを読み込み、最終的なソースを定義し、ソースをデータ系列グラフに追加します。
- 次の 2 つの Cloud Run インスタンス。
- 1 つのインスタンスが Report Engine を実行します。タグが適用されたかどうかを確認し、結果を公開します。
- もう 1 つのインスタンスが Tag Engine を実行し、セキュア データ ウェアハウス内のデータにタグを設定します。
- Pub/Sub が検出結果をパブリッシュします。
コントロールに関連する問題を検出するために、このアーキテクチャには次のチェックが含まれています。
- 最終的なソースタグがない状態で機密データが識別される。
- 機密データアセットの系列グラフにデータが挿入されていない。
タグ リファレンス
このセクションでは、このアーキテクチャが CDMC キー コントロールの要件を満たすために使用するタグ テンプレートとタグについて説明します。
テーブルレベルの CDMC コントロール タグ テンプレート
次の表に、CDMC コントロール タグ テンプレートに含まれ、テーブルに適用されるタグを示します。
| タグ | タグ ID | 該当するキー コントロール |
|---|---|---|
| 承認されたストレージのロケーション | approved_storage_location |
4 |
| 承認済みの用途 | approved_use |
8 |
| データオーナーのメールアドレス | data_owner_email |
2 |
| データオーナーの名前 | data_owner_name |
2 |
| 暗号化方式 | encryption_method |
9 |
| 期限切れのアクション | expiration_action |
11 |
| 信頼できるかどうか | is_authoritative |
3 |
| 機密かどうか | is_sensitive |
6 |
| デリケートなカテゴリ | sensitive_category |
6 |
| 共有スコープの地域 | sharing_scope_geography |
8 |
| 共有スコープの法人 | sharing_scope_legal_entity |
8 |
| 保持期間 | retention_period |
11 |
| 最終的なソース | ultimate_source |
14 |
影響評価のタグ テンプレート
次の表に、影響評価タグ テンプレートに含まれ、テーブルに適用されるタグを示します。
| タグ | タグ ID | 該当するキー コントロール |
|---|---|---|
| サブジェクトのロケーション | subject_locations |
10 |
| DPIA の影響評価 | is_dpia |
10 |
| PIA の影響評価 | is_pia |
10 |
| 影響評価レポート | impact_assessment_reports |
10 |
| 最新の影響の評価 | most_recent_assessment |
10 |
| 最も古い影響評価 | oldest_assessment |
10 |
費用指標のタグ テンプレート
次の表に、費用指標タグ テンプレートに含まれ、テーブルに適用されるタグを示します。
| タグ | タブ ID | 該当するキー コントロール |
|---|---|---|
| 推定クエリ費用 | estimated_query_cost |
13 |
| 推定ストレージ費用 | estimated_storage_cost |
13 |
| 推定下り(外向き)費用 | estimated_egress_cost |
13 |
| 課金されるクエリのバイト数の合計 | total_query_bytes_billed |
13 |
| ストレージのバイト数の合計 | total_storage_bytes_billed |
13 |
| 転送バイト数の合計 | total_bytes_transferred |
13 |
データ機密性のタグ テンプレート
次の表に、データ機密性タグ テンプレートに含まれ、フィールドに適用されるタグを示します。
| タグ | タグ ID | 該当するキー コントロール |
|---|---|---|
| 機密フィールド | sensitive_field |
6 |
| 機密タイプ | sensitive_category |
6 |
セキュリティ ポリシーのタグ テンプレート
次の表に、セキュリティ ポリシータグ テンプレートに含まれ、フィールドに適用されるタグを示します。
| タグ | タグ ID | 該当するキー コントロール |
|---|---|---|
| アプリケーション匿名化方式 | app_deid_method |
9 |
| プラットフォーム匿名化方式 | platform_deid_method |
9 |
データ品質のタグ テンプレート
次の表に、完全性と正確性のデータ品質タグ テンプレートに含まれ、フィールドに適用されるタグを示します。
| タグ | タグ ID | 該当するキー コントロール |
|---|---|---|
| 許容しきい値 | acceptable_threshold |
12 |
| 列名 | column_name |
12 |
| しきい値を満たす | meets_threshold |
12 |
| 指標 | metric |
12 |
| 最新の実行 | most_recent_run |
12 |
| 検証された行 | rows_validated |
12 |
| 成功率 | success_percentage |
12 |
フィールド レベルの CDMC ポリシータグ
次の表に、CDMC 機密データ分類ポリシータグの分類に含まれ、フィールドに適用されるポリシータグを示します。これらのポリシータグは、フィールド レベルのアクセスを制限し、プラットフォーム レベルでデータの匿名化を有効にします。
| データ分類 | タグ名 | 該当するキー コントロール |
|---|---|---|
| 個人を特定できる情報 | personal_identifiable_information |
7 |
| 個人情報 | personal_information |
7 |
| 個人を特定できる機密情報 | sensitive_personal_identifiable_information |
7 |
| 機密性の高い個人情報 | sensitive_personal_data |
7 |
事前入力されたテクニカル メタデータ
次の表に、すべての BigQuery データアセットに関して Data Catalog においてデフォルトで同期されるテクニカル メタデータを示します。
| メタデータ | 該当するキー コントロール |
|---|---|
| アセットのタイプ | — |
| 作成時刻 | — |
| 有効期限 | 11 |
| ロケーション | 4 |
| リソース URL | 3 |
次のステップ
- CDMC の詳細。
- 保護されたデータ ウェアハウスのブループリントで使用されるセキュリティ管理について確認する。
- Data Catalog について調べる。
- Dataplex Universal Catalog の詳細。
- Tag Engine の詳細。
- GitHub の Google Cloud CDMC リファレンス アーキテクチャを使用して、このソリューションを実装する。