データリネージを使用すると、データがシステム内をどのように移動するか、つまりデータがどこから来て、どこに渡され、どのような変換がデータに適用されるかを追跡できます。
データリネージが必要な理由
大規模なデータセットを扱うには、多くの場合、テキスト ファイル、テーブル、レポート、ダッシュボード、モデルという特定のプロジェクトのニーズに合わせてデータをエンティティに変換します。
たとえば、すべての購入を 1 つの SQL テーブルに記録するオンライン ショップがあるとします。アナリストがデータを扱いやすくするために、この単一のテーブルから情報を抽出し、地域、ブランド、販売価格ごとに小さなテーブルを生成するジョブを開始します。アナリストも同様に、変換をさらに実行し、これらの小さなテーブルを他のデータソースと統合して、さらに多くのテーブルを生成します。
これは、ステークホルダーにとって大きな課題になる可能性があります。
- データ コンシューマでは、セルフサービス ツールを使用してデータが信頼できるソースから来ているかどうかを判断できません。
- データ エンジニアは、すべてのデータ変換を追跡する信頼できる方法がないため、問題の根本原因を特定できません。
- データ エンジニアとアナリストは、テーブルを変更または削除する前に、考えられる影響を完全に評価することはできません。
- データ ガバナンスでは、組織全体でセンシティブ データがどのように使用されているかを把握することや、規制要件の遵守を確認することはできません。
データリネージは、以下を可能にする実践的な方法を提供するソリューションです。
- リネージグラフを使用して、データがどのように収集され、変換されるかを理解します。
- エントリとデータ処理に関するエラーを根本原因まで追跡します。
- インパクト分析を通じてチェンジ マネジメントを改善: ダウンタイムや予期せぬエラーを回避し、依存するエントリを理解して、関係者と協力します。
データリネージ情報モデル
基本的な形式で、リネージは、ソースからターゲットに変換されたデータのレコードです。Data Lineage API は、その情報を収集し、プロセス、実行、イベントのコンセプトを使用して階層型データモデルに整理します。
プロセス
プロセスは、特定のシステムでサポートされているデータ変換オペレーションの定義です。BigQuery リネージのコンテキストでは、process はサポート対象のジョブタイプの 1 つです。
実行
実行とは、プロセスの実行のことです。プロセスには複数の実行を指定できます。実行には、開始時間と終了時間、状態、追加の属性などの詳細情報が含まれます。詳細については、run リソース リファレンスをご覧ください。
イベント
イベントは、データ変換オペレーションが実行され、ソースとターゲットのエンティティ間でデータが移動した時点を表します。
イベントには、特定のイベントの送信元とターゲットを定義するリンクのリストが含まれます。イベントは、リネージグラフの計算に使用されますが、 Google Cloud コンソールに直接公開されることはありません。Data Lineage API を使用して、これらのテーブルの作成、読み取り、削除を行うことができます(更新はできません)。
例
BigQuery テーブル間でデータがコピーされる次の例について考えてみましょう。
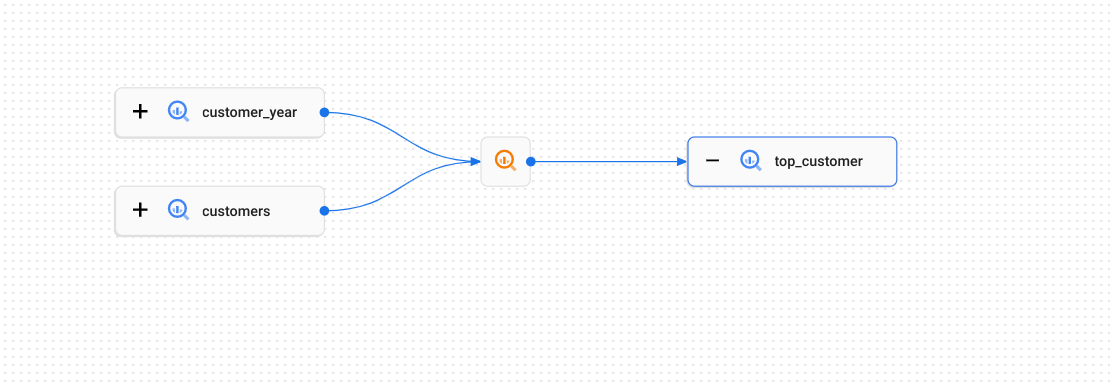
テーブル間のデータの移動方法は、リネージ プロセス(グラフで ![]() アイコンによって示される)で説明されています。これは SQL
アイコンによって示される)で説明されています。これは SQL CREATE TABLE AS SELECT クエリまたは INSERT ステートメントです。
その SQL ステートメントを実行するたびに、個々の実行が構成されます。実行にはイベントが含まれます。これらは、どのテーブルがソースとして使用され、どのテーブルがターゲットとして使用されたかを記録します。この例では、テーブル customer_year と customers はどちらも、ターゲット top_customer テーブルのソースです。
リネージグラフ
リネージグラフは、特定の Dataplex Universal Catalog 用の Data Lineage API によって収集される情報を表します。リネージグラフには、単一のルートエントリのアップストリームまたはダウンストリームのリネージが表示されます。「ルート」は、リネージを表示しているエントリを指します。
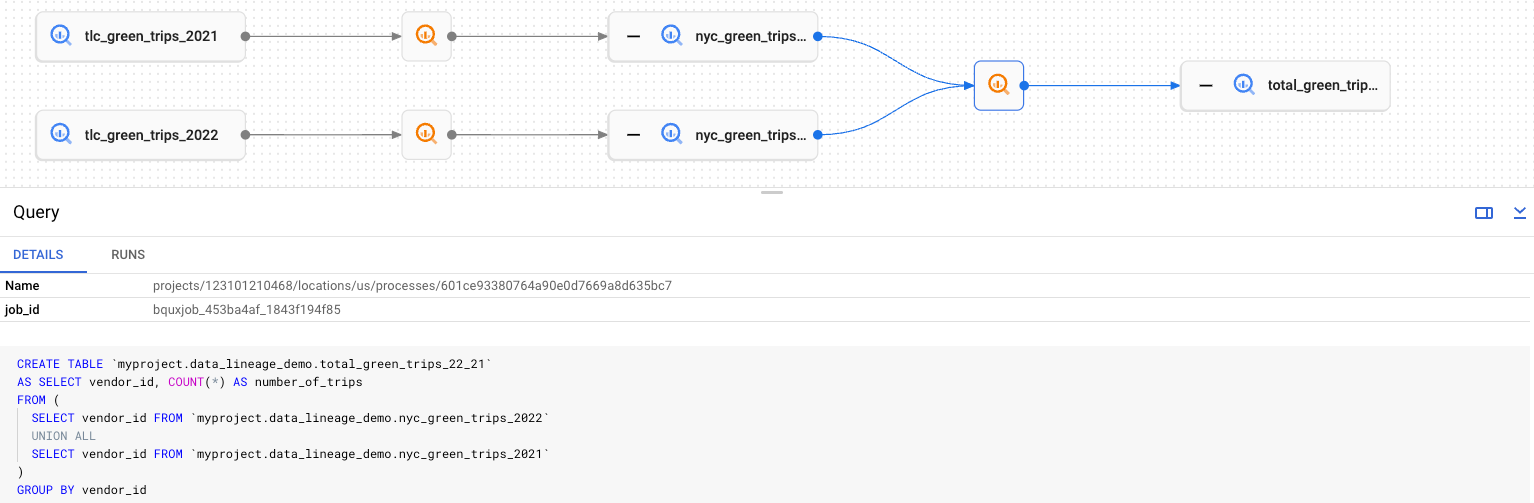
Dataplex Universal Catalog は Data Lineage API と連携して、完全修飾名がデータリネージで認識されるエンティティと一致するエントリを識別します。一致した Dataplex Universal Catalog エントリについては、詳細ページの [リネージ] タブにアクセスしてグラフを表示できます。
リネージグラフには、次の 2 種類の要素が表示されます。
リネージ情報の作成に関連するエンティティを表す横長の長方形のボタン。リネージ イベントのソースまたはターゲットになります。
ソース エンティティまたはターゲット エンティティの作成または更新を行うプロセスを表す小さな正方形ボタン。プロセスボタンには、Data Lineage API に報告したソースシステムに固有のアイコンが使用されます。たとえば、BigQuery ジョブは
 アイコンを使用します。
アイコンを使用します。
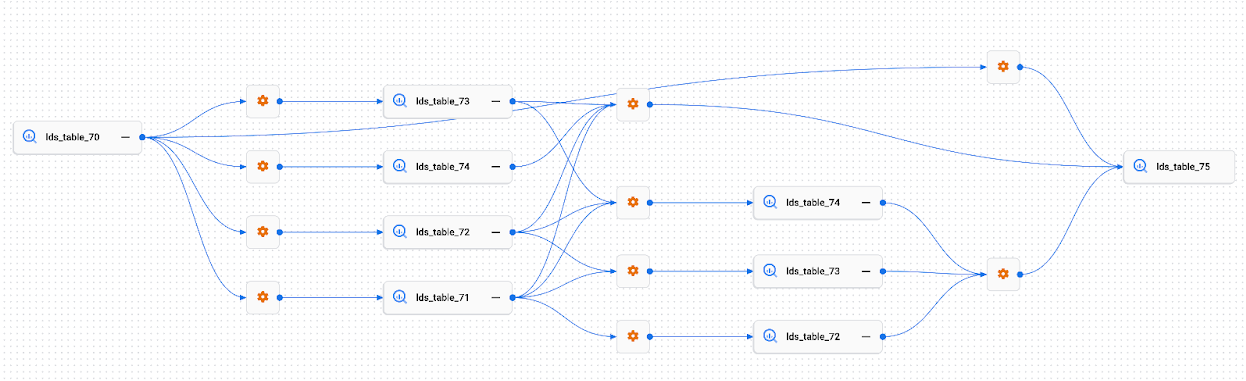
リネージパスの可視化
リネージパスの可視化は、選択した 2 つのリソース間のリネージリンクを把握するために役立ちます(これとは対照的にリネージグラフでは、単一のルートエントリのアップストリームまたはダウンストリームのリネージを表示します。複数のソースまたはターゲットの場合もあります)。
ルートリソースとターゲット リソースを選択すると、Google Cloud コンソールに 2 つのリソース間のリネージリンクが表示されます。2 つのリソース間のパスにない他のリソースとプロセスは、パスの可視化では表示されません。
リネージのリスト表示
リネージのリスト表示には、エンティティの詳細なリネージ情報が 1 つのテーブルに表示されます。
リネージ可視化グラフは比較的小規模なリネージグラフの表示に適していますが、リネージのリスト表示では、接続数の多いエンティティのリネージ情報を表示できます。
次の画像は、Google Cloud コンソールでのリネージのリスト表示の例を示しています。以下に、画像について詳しく説明します。
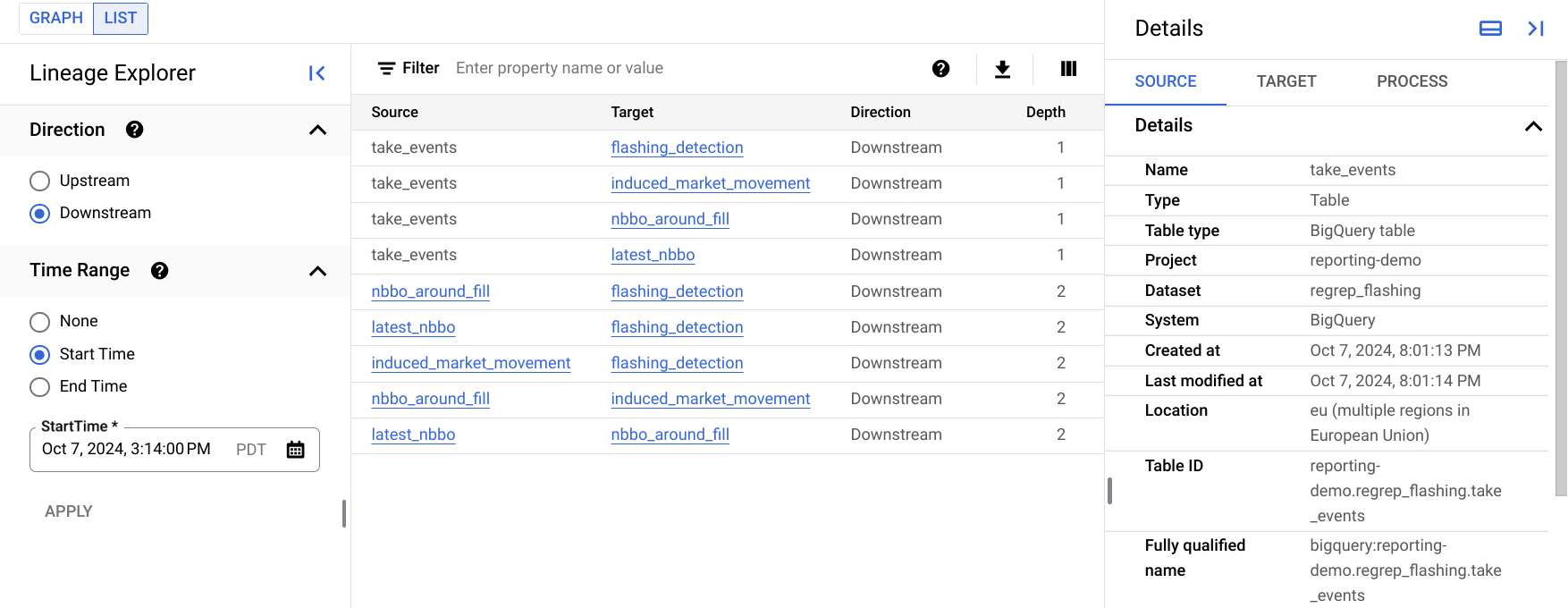
テーブルの各行は、2 つのエントリ間の単一のリネージリンクを表します。グラフでは、これらの名前は、2 つのエントリ間のリネージリンクとして表示されます(間にプロセスノードがある場合も同様です)。たとえば、
SourceとTargetはアセットノードであり、間に複数のプロセスノードが存在する場合があります。[方向] オプションでは、ルートアセットを基準として、リストに表示するデータフローの部分を指定します。
アップストリーム: 選択したエントリのデータソースであるエントリのリネージ情報を表示します。リネージグラフでは、これらのエントリは選択したエントリの左側に表示されます。
ダウンストリーム: 選択したエントリを使用するエントリまたは選択したエントリから派生したエントリのリネージ情報を表示します。リネージグラフでは、これらのエントリは選択したエントリの右側に表示されます。
[期間] オプションを使用すると、リネージが発生した時間に基づいてリネージ情報をフィルタできます。
開始時間: 開始時間以降に発生したリネージが表示されます。
終了時刻: 終了時刻以前に発生したリネージが表示されます。
深さは、ソースリソースまたは派生リソースがルートリソースからどの程度離れているかを示します。リスト表示には最大 1,000 個のリネージリンクが表示され、ルートからの最大深さは 10 個のリネージリンクです。この範囲外のリネージがある場合は、通知されます。この範囲外のリネージを表示するには、リスト表示で別のエンティティの名前を選択します。
[詳細] パネルには、リンクのソース、リンクのターゲット、このリンクを作成したすべてのプロセスの情報が表示されます。
テーブルに表示する列のカスタマイズや、結果のフィルタができます。結果を CSV ファイルにエクスポートすることもできます。
データリネージの自動追跡
Data Lineage API を有効にすると、データリネージをサポートしている Google Cloud システムがデータの移動の報告を開始します。統合された各システムは、異なる範囲のデータソースのリネージ情報を送信できます。サポートされているすべてのプロダクトの詳細については、以降のセクションをご覧ください。
BigQuery
BigQuery プロジェクトでデータリネージを有効にすると、Dataplex Universal Catalog によって次のリネージ情報が自動的に記録されます。
次の BigQuery ジョブの結果として新しいテーブル:
GoogleSQL で次のデータ操作言語(DML)ステートメントを使用した結果としての既存のテーブル:
- 次にリストされたテーブルタイプのいずれかに関連付けられた SELECT。
- INSERT SELECT
- MERGE
- UPDATE
- DELETE
BigQuery のコピー、クエリ、読み込みジョブは、プロセスとして表されます。プロセスの詳細を表示するには、リネージグラフで ![]() をクリックします。各プロセスでは、最新の BigQuery ジョブの属性リストに BigQuery job_id が含まれています。
をクリックします。各プロセスでは、最新の BigQuery ジョブの属性リストに BigQuery job_id が含まれています。
その他のサービス
データリネージは、次のGoogle Cloud サービスとのインテグレーションをサポートしています。
カスタム データソースのデータリネージ
Data Lineage API を使用すると、統合されたシステムでサポートされていないデータソースのリネージ情報を手動で記録できます。
既存の Dataplex Universal Catalog エントリの完全修飾名と一致する fullyQualifiedName を使用すると、Dataplex Universal Catalog は手動で記録されたリネージのリネージグラフを作成できます。カスタム データソースのリネージを記録する場合は、まずカスタム エントリを作成します。
カスタム データソースの各プロセスでは、属性リストに sql キーを含めることができます。このようなキーの値は、データリネージ グラフの詳細パネルでコードのハイライトをレンダリングするために使用されます。記載のとおりに SQL ステートメントが表示されます。機密情報を除外する責任はユーザーにあります。鍵名 sql では、大文字と小文字が区別されます。
OpenLineage
すでに OpenLineage を使用して他のデータソースからリネージ情報を収集している場合は、OpenLineage イベントを Dataplex Universal Catalog にインポートし、 Google Cloud コンソールにそれらのイベントを表示できます。詳しくは、OpenLineage との統合をご覧ください。
制限事項
- すべてのリネージ情報は、システムに 30 日間のみ保持されます。
- リネージ情報は、関連するデータソースを削除しても保持されます。つまり、BigQuery テーブルとその Dataplex Universal Catalog エントリを削除しても、API を使用してそのテーブルのリネージを最大 30 日間読み取ることができます。
データリネージにアクセスする
データリネージにアクセスする方法の詳細については、 Google Cloud システムでデータリネージを使用すると Data Lineage API をご覧ください。
料金
Dataplex Universal Catalog は、プレミアム処理 SKU を使用してデータリネージの料金を課金します。詳細については、料金をご覧ください。
Dataplex Universal Catalog プレミアム処理 SKU で、データリネージの課金を他の課金と分離するには、Cloud Billing レポートで、ラベル
goog-dataplex-workload-typeを値LINEAGEで使用します。CUSTOM以外の値を指定して Data Lineage APIOriginsourceTypeを呼び出すと、追加費用が発生します。
次のステップ
クイックスタートに沿って、BigQuery テーブルのコピージョブとクエリジョブのデータリネージを追跡します。
Google Cloud システムでデータリネージを使用する方法を学習する。
管理情報については、リネージに関する考慮事項とデータリネージの監査ロギングをご覧ください。