L-Diversität ist ein Attribut eines Datasets und eine Erweiterung von k-Anonymität, das/die die Vielfalt vertraulicher Werte für jede Spalte misst, in der sie auftreten. Ein Dataset hat l-Diversität, wenn in allen Zeilengruppen mit identischen Quasi-Identifikatoren mindestens l verschiedene Werte für jedes Sensibilitätsattribut vorhanden sind.
Sie können den l-Diversitätswert basierend auf einzelnen oder mehreren Spalten oder Feldern eines Datasets berechnen. In diesem Thema wird gezeigt, wie Sie mithilfe von Sensitive Data Protection l-Diversitätswerte für ein Dataset berechnen. Bevor Sie fortfahren, lesen Sie weitere Informationen zur l-Diversität oder zur Risikoanalyse im Allgemeinen im Thema zum Konzept der Risikoanalyse.
Hinweise
Führen Sie folgende Schritte aus, bevor Sie fortfahren:
- Melden Sie sich bei Ihrem Google-Konto an.
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines. Projektauswahl aufrufen
- Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein. Weitere Informationen zur Abrechnung Ihres Projekts.
- Aktivieren Sie den Schutz sensibler Daten. Schutz sensibler Daten aktivieren
- Wählen Sie das zu analysierende BigQuery-Dataset aus. Der Schutz sensibler Daten berechnet den l-Diversitätsmesswert durch Scannen einer BigQuery-Tabelle.
- Bestimmen Sie eine ID für vertrauliche Felder (falls zutreffend) und mindestens eine Quasi-Identifikator im Dataset. Weitere Informationen finden Sie unter Begriffe und Techniken der Risikoanalyse.
l-Diversität berechnen
Sensitive Data Protection führt bei jeder Ausführung eines Risikoanalysejobs eine Risikoanalyse durch. Sie müssen den Job zuerst erstellen. Dazu nutzen Sie entweder die Google Cloud Console, senden eine DLP API-Anfrage oder verwenden eine Clientbibliothek für den Schutz sensibler Daten.
Console
Rufen Sie in der Google Cloud Console die Seite Risikoanalyse erstellen auf.
Geben Sie im Abschnitt Eingabedaten auswählen die zu scannende BigQuery-Tabelle an. Dazu geben Sie die Projekt-ID des Projekts ein, das Die Tabelle enthält, die Dataset-ID der Tabelle und den Namen der Tabelle.
Wählen Sie unter Datenschutzmesswert zur Berechnung () l-Diversität aus.
Im Abschnitt Job-ID können Sie dem Job optional eine benutzerdefinierte Kennung geben und einen Ressourcenstandort auswählen, an dem der Schutz sensibler Daten Ihre Daten verarbeitet. Wenn Sie fertig sind, klicken Sie auf Weiter.
Im Abschnitt Felder definieren geben Sie sensible Felder und Quasi-Identifikatoren für den l-Diversitäts-Risikojob an. Der Schutz sensibler Daten greift auf die Metadaten der BigQuery-Tabelle zu, die Sie im vorherigen Schritt angegeben haben, und versucht, die Liste der Felder auszufüllen.
- Klicken Sie auf das entsprechende Kästchen, um ein Feld als ein vertrauliches Feld (S) oder eine Quasi-Identifikator (QI) anzugeben. Sie müssen ein Feld mit vertraulichen Daten und mindestens eine Quasi-Identifikator auswählen.
- Wenn der Schutz sensibler Daten die Felder nicht füllen kann, klicken Sie auf Feldnamen eingeben, um ein oder mehrere Felder manuell einzugeben, und legen Sie jedes Feld als vertrauliches Feld oder Quasi-Identifikator fest. Wenn Sie fertig sind, klicken Sie auf Weiter.
Im Abschnitt Aktionen hinzufügen () können Sie optionale Aktionen hinzufügen, die ausgeführt werden, wenn der Risikojob abgeschlossen ist. Folgende Optionen sind verfügbar:
- In BigQuery speichern (): Die Ergebnisse des Risikoanalysescans werden in einer BigQuery-Tabelle gespeichert.
In Pub/Sub veröffentlichen: Veröffentlicht eine Benachrichtigung in einem Cloud Pub/Sub-Thema.
Per E-Mail benachrichtigen: Sendet Ihnen eine E-Mail mit Ergebnissen. Wenn Sie fertig sind, klicken Sie auf Erstellen.
Der l-Diversitäts-Risikoanalyse-Job beginnt sofort.
C#
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
PHP
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Informationen zum Installieren und Verwenden der Clientbibliothek für den Schutz sensibler Daten finden Sie unter Clientbibliotheken für den Schutz sensibler Daten.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Sensitive Data Protection zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
REST
Wenn Sie einen neuen Risikoanalysejob zur Berechnung der l-Diversität ausführen möchten, senden Sie eine Anfrage an die Ressource projects.dlpJobs, wobei PROJECT_ID für Ihre Projekt-ID steht.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
Die Anfrage enthält ein RiskAnalysisJobConfig-Objekt, das Folgendes umfasst:
Ein
PrivacyMetric-Objekt. Hier geben Sie durch Einschließen einesLDiversityConfig-Objekts an, dass l-Diversität berechnet wird.Ein
BigQueryTable-Objekt. Geben Sie die zu untersuchende BigQuery-Tabelle an. Dazu beziehen Sie die folgenden Parameter ein:projectId: die Projekt-ID des Projekts, das die Tabelle enthältdatasetId: die Dataset-ID der TabelletableId: der Name der Tabelle
Ein oder mehrere
Action-Objekte für Aktionen, die nach Abschluss des Jobs in der angegebenen Reihenfolge ausgeführt werden sollen. JedesAction-Objekt kann eine der folgenden Aktionen enthalten:SaveFindings-Objekt: speichert die Ergebnisse des Risikoanalysescans in einer BigQuery-TabellePublishToPubSub-Objekt: Veröffentlicht eine Benachrichtigung in einem Cloud Pub/Sub-ThemaJobNotificationEmails-Objekt: Sendet Ihnen eine E-Mail mit Ergebnissen.
Geben Sie im Objekt
LDiversityConfigFolgendes an:quasiIds[]: eine Gruppe von Quasi-Identifikatoren (FieldId-Objekten), die angeben, wie Äquivalenzklassen für die Berechnung der l-Diversität definiert werden. Wie beiKAnonymityConfigwerden sie auch hier als ein einzelner zusammengesetzter Schlüssel betrachtet, wenn Sie mehrere Felder angeben.sensitiveAttribute: Feld mit vertraulichen Daten (FieldId-Objekt) zur Berechnung des l-Diversitätswerts.
Sobald Sie eine Anfrage an die DLP API senden, wird der Risikoanalysejob gestartet.
Abgeschlossene Risikoanalysejobs auflisten
Sie können eine Liste der Risikoanalysejobs aufrufen, die im aktuellen Projekt ausgeführt wurden.
Console
So listen Sie laufende und zuvor ausgeführte Risikoanalysejobs in der Google Cloud Console auf:
Öffnen Sie in der Google Cloud Console den Bereich „Schutz sensibler Daten“.
Klicken Sie oben auf der Seite auf den Tab Jobs und Job-Trigger.
Klicken Sie auf den Tab Risikojobs.
Die Liste der Risikojobs wird angezeigt.
Protokoll
Senden Sie eine GET-Anfrage an die Ressource projects.dlpJobs, um gerade ausgeführte und zuvor ausgeführte Risikoanalysejobs aufzulisten. Durch Hinzufügen eines Jobtypfilters (?type=RISK_ANALYSIS_JOB) wird die Antwort auf nur Risikoanalysejobs beschränkt.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
Die erhaltene Antwort enthält eine JSON-Darstellung aller aktuellen und vorherigen Risikoanalysejobs.
l-Diversität-Jobergebnisse anzeigen
Der Schutz sensibler Daten in der Google Cloud Console bietet integrierte Visualisierungen für abgeschlossene l-Diversitätsjobs. Nachdem Sie der Anleitung im vorherigen Abschnitt gefolgt sind, wählen Sie aus der Liste der Risikoanalysejobs den Job aus, für den Sie Ergebnisse ansehen möchten. Wenn der Job erfolgreich ausgeführt wurde, sieht die Seite Risikoanalysedetails oben so aus:
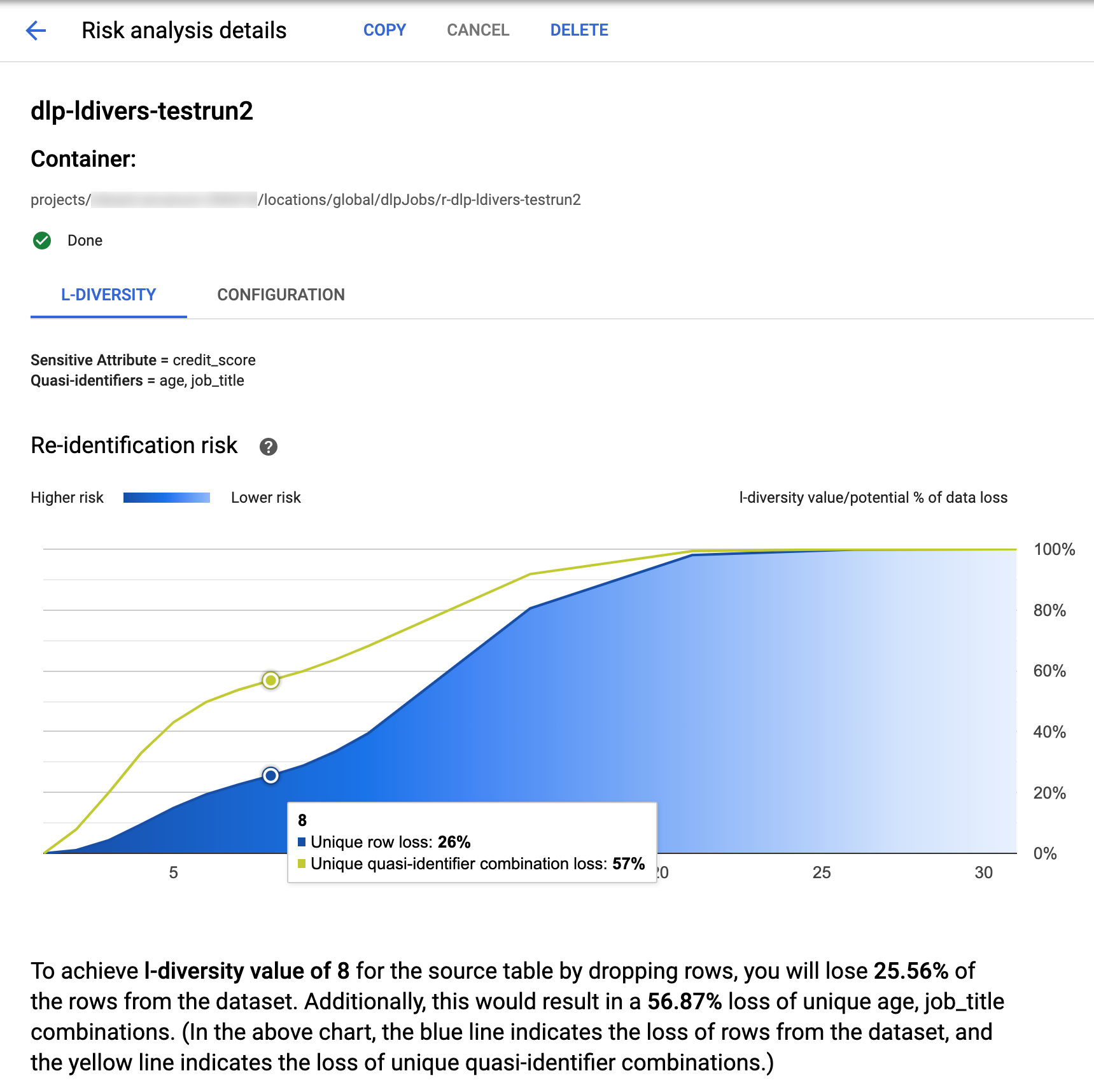
Oben auf der Seite finden Sie Informationen zum l-Diversitäts-Risikojob, einschließlich seiner Job-ID und unter Container seine Ressourcenstandort.
Klicken Sie auf den Tab L-Diversität, um die Ergebnisse der l-Diversitätsberechnung anzuzeigen. Klicken Sie zum Anzeigen der Konfiguration des Risikoanalysejobs auf den Tab Konfiguration.
Auf dem Tab L-Diversität werden zuerst der sensible Wert und die Quasi-Kennzeichnungen zur Berechnung der l-Diversität aufgeführt.
Risikodiagramm
Das Diagramm Re-Identifikationsrisiko stellt auf der y-Achse den potenziellen Prozentsatz des Datenverlusts sowohl für eindeutige Zeilen als auch für eindeutige Quasi-Kennzeichnungs-Kombinationen dar, um auf der x-Achse einen l-Diversitätswert anzugeben. Die Farbe des Diagramms zeigt auch das Risikopotenzial an. Dunklere Blautöne weisen auf ein höheres Risiko hin, hellere auf ein geringeres Risiko.
Höhere l-Diversitätswerte weisen auf eine geringere Vielfalt von Werten hin. Dadurch kann ein Dataset weniger re-identifizierbarer und sicherer werden. Um höhere I-Diversitätswerte zu erreichen, müssten Sie jedoch höhere Prozentsätze der gesamten Zeilen und höhere eindeutige Quasi-Kennzeichnungs-Kombinationen entfernen, was den Nutzen der Daten verringern könnte. Bewegen Sie den Mauszeiger über das Diagramm, um einen bestimmten potenziellen prozentualen Verlustwert für einen bestimmten I-Diversitätswert anzuzeigen. Wie im Screenshot dargestellt, wird im Diagramm eine Kurzinfo angezeigt.
Klicken Sie auf den entsprechenden Datenpunkt, um weitere Details zu einem bestimmten l-Diversitätswert anzuzeigen. Unter dem Diagramm wird eine detaillierte Erläuterung angezeigt und weiter unten auf der Seite wird eine Beispieldatentabelle angezeigt.
Risiko-Beispieldatentabelle
Die zweite Komponente der Ergebnisseite für Risikojobs ist die Beispieldatentabelle. Darin werden Quasi-Identifikatoren-Kombinationen für einen bestimmten Ziel-l-Diversitätswert angezeigt.
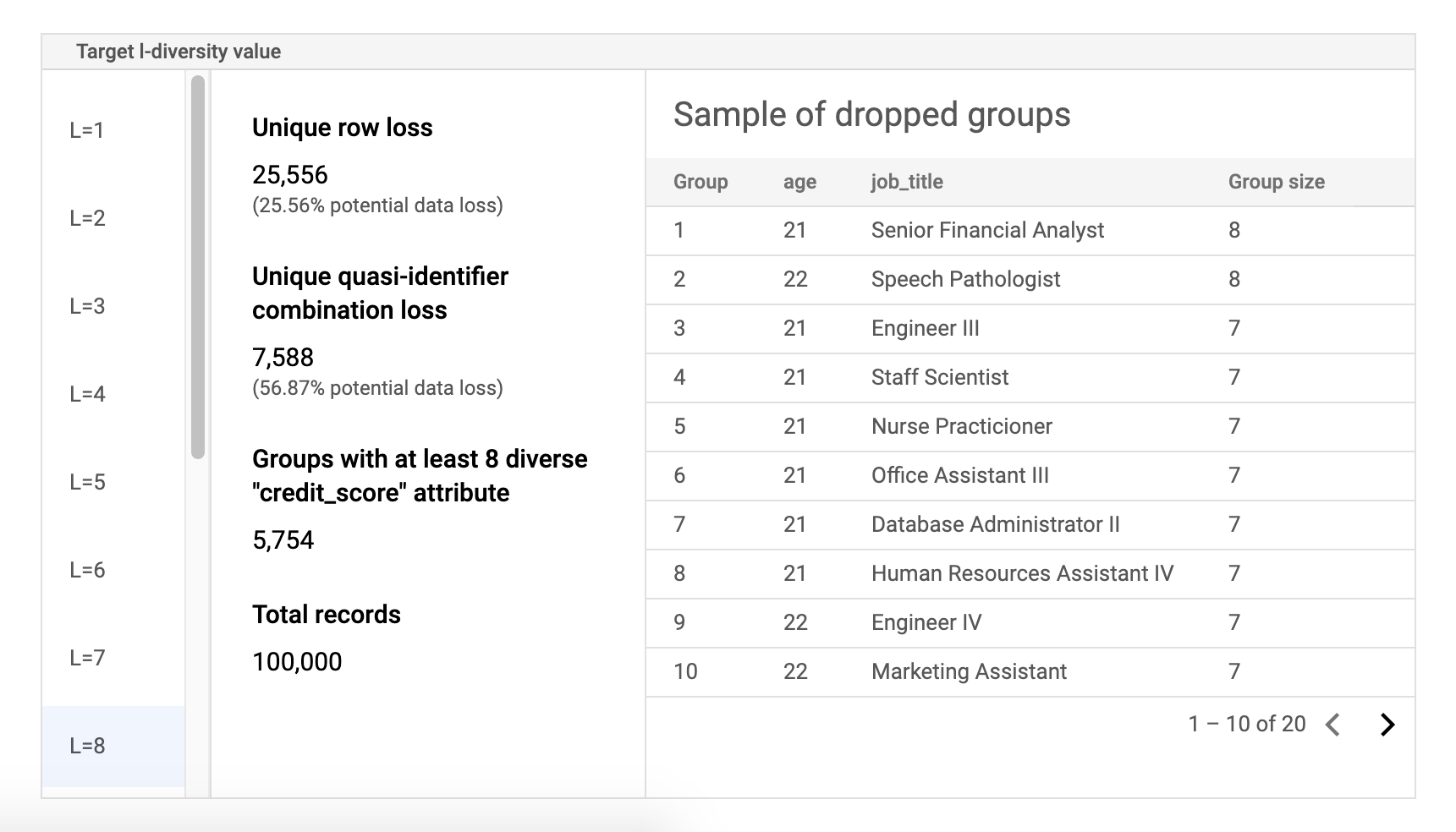
Die erste Spalte der Tabelle enthält die k-Anonymitätswerte. Klicken Sie auf einen l-Diversitätswert, um die entsprechenden Beispieldaten anzuzeigen, die gelöscht werden müssten, um diesen Wert zu erreichen.
Die zweite Spalte zeigt den jeweiligen potenziellen Datenverlust von einzigartigen Zeilen und Quasi-Identifikatoren-Kombinationen zum Erzielen des ausgewählten l-Diversitätswerts sowie die Anzahl der Gruppen mit mindestens l vertraulichen Attributen und die Gesamtzahl der Datensätze an.
Die letzte Spalte enthält eine Auswahl an Gruppen die eine Quasi-Identifikatoren-Kombination gemeinsam nutzen und die Anzahl der Datensätze, die für diese Kombination vorhanden sind.
Jobdetails mit REST abrufen
Wenn Sie die Ergebnisse des l-Diversitäts-Risikoanalysejobs mit der REST API abrufen möchten, senden Sie die folgende GET-Anfrage an die projects.dlpJobs-Ressource. Ersetzen Sie PROJECT_ID durch Ihre Projekt-ID und JOB_ID durch die ID des Jobs, für den Sie Ergebnisse erhalten möchten.
Die Job-ID wurde beim Start des Jobs zurückgegeben und kann auch durch Auflisten aller Jobs abgerufen werden.
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
Die Anfrage gibt ein JSON-Objekt zurück, das eine Instanz des Jobs enthält. Die Ergebnisse der Analyse befinden sich im Schlüssel "riskDetails" in einem AnalyzeDataSourceRiskDetails-Objekt. Weitere Informationen finden Sie in der API-Referenz zur Ressource DlpJob.
Nächste Schritte
- k-Anonymitätswert für ein Dataset berechnen
- k-map-Wert für ein Dataset berechnen
- δ-Präsenzwert für ein Dataset berechnen