Datastream est compatible avec le streaming de données provenant de bases de données Oracle, MySQL et PostgreSQL directement dans les ensembles de données BigQuery. Toutefois, si vous avez besoin de mieux contrôler la logique de traitement des flux, par exemple pour transformer les données ou définir manuellement les clés primaires logiques, vous pouvez intégrer Datastream aux modèles de tâches Dataflow.
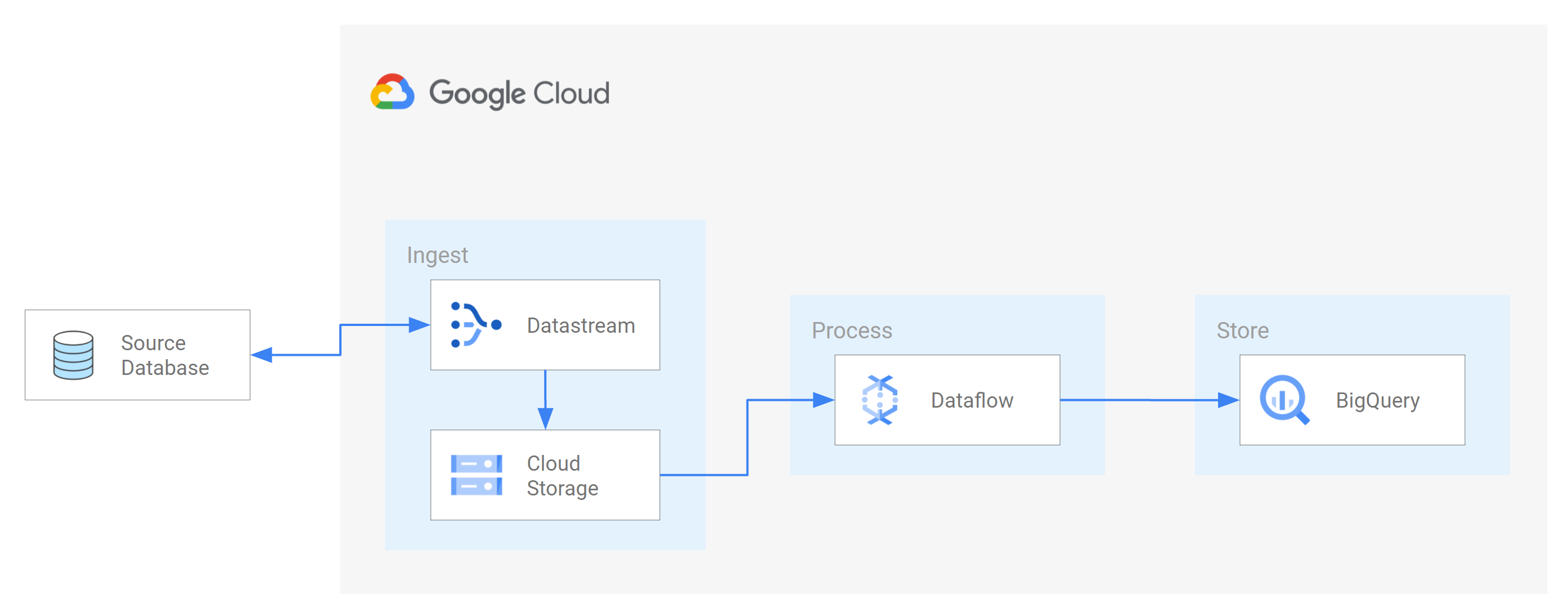
Ce tutoriel explique comment Datastream s'intègre à Dataflow en utilisant des modèles de tâches Dataflow pour diffuser des vues matérialisées à jour dans BigQuery à des fins d'analyse.
Pour les organisations disposant de nombreuses sources de données isolées, l'accès aux données de l'ensemble de l'organisation, en particulier en temps réel, peut être limité et lent. Cela limite la capacité d'introspection de l'organisation.
Datastream offre un accès en quasi-temps réel aux données modifiées de différentes sources de données sur site et dans le cloud. Datastream fournit une expérience de configuration qui ne nécessite pas beaucoup de configuration pour le streaming de données. Datastream s'en charge pour vous. Datastream dispose également d'une API de consommation unifiée qui démocratise l'accès aux données les plus récentes dans l'entreprise, ce qui rend possible des scénarios intégrés.
Une telle intégration consiste à transférer les données d'une base de données source vers une file d'attente ou un service de stockage basé sur le cloud. Une fois que Datastream a diffusé les données, celles-ci sont transformées dans un format lisible par d'autres applications et services. Dans ce tutoriel, Dataflow est le service Web qui communique avec le service de stockage ou la file d'attente de messages pour capturer et traiter les données sur Google Cloud.
Vous allez apprendre à utiliser Datastream pour diffuser en flux continu les modifications (données insérées, mises à jour ou supprimées) d'une base de données MySQL source vers un dossier d'un bucket Cloud Storage. Vous configurez ensuite le bucket Cloud Storage pour qu'il envoie des notifications que Dataflow utilise pour identifier les nouveaux fichiers contenant les modifications de données que Datastream diffuse à partir de la base de données source. Une tâche Dataflow traite ensuite les fichiers et transfère les modifications dans BigQuery.
Objectifs
Dans ce tutoriel, vous allez effectuer les tâches suivantes :- Créez un bucket dans Cloud Storage. Il s'agit du bucket de destination dans lequel Datastream diffuse les schémas, les tables et les données d'une base de données MySQL source.
- Activez les notifications Pub/Sub pour le bucket Cloud Storage. Vous configurez ainsi le bucket pour qu'il envoie des notifications que Dataflow utilise pour identifier les nouveaux fichiers prêts à être traités. Ces fichiers contiennent les modifications apportées aux données que Datastream diffuse en streaming de la base de données source vers le bucket.
- Créez des ensembles de données dans BigQuery. BigQuery utilise des ensembles de données pour contenir les données qu'il reçoit de Dataflow. Ces données représentent les modifications apportées à la base de données source que Datastream diffuse dans le bucket Cloud Storage.
- Créer et gérer des profils de connexion pour une base de données source et un bucket de destination dans Cloud Storage. Un flux Datastream utilise les informations des profils de connexion pour transférer les données de la base de données source vers le bucket.
- Créez et démarrez un flux. Ce flux transfère les données, les schémas et les tables de la base de données source vers le bucket.
- Vérifiez que Datastream transfère les données et les tables associées à un schéma de la base de données source vers le bucket.
- Créez un job dans Dataflow. Une fois que Datastream a diffusé les modifications de données de la base de données source dans le bucket Cloud Storage, des notifications sont envoyées à Dataflow concernant les nouveaux fichiers contenant les modifications. Le job Dataflow traite les fichiers et transfère les modifications dans BigQuery.
- Vérifiez que Dataflow traite les fichiers contenant les modifications associées à ces données et transfère les modifications dans BigQuery. Vous disposez ainsi d'une intégration de bout en bout entre Datastream et BigQuery.
- Nettoyez les ressources que vous avez créées dans Datastream, Cloud Storage, Pub/Sub, Dataflow et BigQuery afin qu'à l'avenir elles ne soient pas comptabilisées dans votre quota et ne vous soient pas facturées.
Coûts
Dans ce document, vous utilisez les composants facturables de Google Cloudsuivants :
- Datastream
- Cloud Storage
- Pub/Sub
- Dataflow
- BigQuery
Vous pouvez obtenir une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- Activez l'API Datastream.
- Assurez-vous que le rôle "Administrateur Datastream" est attribué à votre compte utilisateur.
- Assurez-vous de disposer d'une base de données MySQL source à laquelle Datastream peut accéder. Vérifiez également que la base de données contient des données, des tables et des schémas.
- Configurez votre base de données MySQL pour autoriser les connexions entrantes provenant d'adresses IP publiques Datastream. Pour obtenir la liste de toutes les régions Datastream et des adresses IP publiques associées, consultez Listes d'autorisation d'adresses IP et régions.
- Configurez la capture de données modifiées (CDC, Change Data Capture) pour la base de données source. Pour en savoir plus, consultez Configurer une base de données MySQL source.
Assurez-vous de remplir tous les prerequisites pour activer les notifications Pub/Sub pour Cloud Storage.
Dans ce tutoriel, vous allez créer un bucket de destination dans Cloud Storage et activer les notifications Pub/Sub pour ce bucket. Dataflow peut ainsi recevoir des notifications concernant les nouveaux fichiers que Datastream écrit dans le bucket. Ces fichiers contiennent les modifications apportées aux données que Datastream diffuse en streaming de la base de données source vers le bucket.
Exigences
Datastream propose différentes options de source, options de destination et méthodes de connectivité réseau.
Pour ce tutoriel, nous partons du principe que vous utilisez une base de données MySQL autonome et un service Cloud Storage de destination. Pour la base de données source, vous devriez pouvoir configurer votre réseau afin d'ajouter une règle de pare-feu entrante. La base de données source peut être sur site ou chez un fournisseur de services cloud. Aucune configuration de connectivité n'est requise pour la destination Cloud Storage.
Ne connaissant pas les spécificités de votre environnement, nous ne pouvons pas fournir de procédure détaillée pour la configuration de votre réseau.
Pour ce tutoriel, sélectionnez Liste d'autorisation d'adresses IP comme méthode de connectivité réseau. La liste d'autorisation d'adresses IP est une fonctionnalité de sécurité souvent utilisée pour limiter et contrôler l'accès aux données de votre base de données source aux utilisateurs de confiance. Vous pouvez utiliser des listes d'adresses IP autorisées pour créer des listes d'adresses IP ou de plages d'adresses IP fiables à partir desquelles vos utilisateurs et d'autres services Google Cloud tels que Datastream peuvent accéder à ces données. Pour utiliser des listes d'autorisation d'adresses IP, vous devez ouvrir la base de données source ou le pare-feu aux connexions entrantes provenant de Datastream.
Créer un bucket dans Cloud Storage
Créez un bucket de destination dans Cloud Storage dans lequel Datastream transfère les schémas, les tables et les données d'une base de données MySQL source.
Dans la console Google Cloud , accédez à la page Navigateur pour Cloud Storage.
Cliquez sur Créer un bucket. La page Créer un bucket s'affiche.
Dans le champ de texte de la région Nommer votre bucket, saisissez un nom unique pour votre bucket, puis cliquez sur Continuer.
Acceptez les paramètres par défaut pour chaque région restante de la page. À la fin de chaque région, cliquez sur Continuer.
Cliquez sur Créer.
Activez les notifications Pub/Sub pour le bucket Cloud Storage.
Dans cette section, vous allez activer les notifications Pub/Sub pour le bucket Cloud Storage que vous avez créé. Vous configurez ainsi le bucket pour qu'il avertisse Dataflow de tout nouveau fichier que Datastream y écrit. Ces fichiers contiennent les modifications apportées aux données que Datastream diffuse depuis une base de données MySQL source vers le bucket.
Accédez au bucket Cloud Storage que vous avez créé. La page Détails du bucket s'affiche.
Cliquez sur Activer Cloud Shell.
Lorsque vous y êtes invité, saisissez la commande suivante :
gcloud storage buckets notifications create gs://bucket-name --topic=my_integration_notifs --payload-format=json --object-prefix=integration/tutorial/Facultatif : Si une fenêtre Autoriser Cloud Shell s'affiche, cliquez sur Autoriser.
Vérifiez que les lignes de code suivantes s'affichent :
Created Cloud Pub/Sub topic projects/project-name/topics/my_integration_notifs Created notification config projects/_/buckets/bucket-name/notificationConfigs/1
Dans la console Google Cloud , accédez à la page Sujets de Pub/Sub.
Cliquez sur le sujet my_integration_notifs que vous avez créé.
Sur la page my_integration_notifs, accédez au bas de la page. Vérifiez que l'onglet Abonnements est actif et que le message Aucun abonnement à afficher s'affiche.
Cliquez sur Créer un abonnement.
Dans le menu qui s'affiche, sélectionnez Créer un abonnement.
Sur la page Ajouter un abonnement au sujet :
- Dans le champ ID d'abonnement, saisissez
my_integration_notifs_sub. - Définissez la valeur Délai de confirmation sur
120secondes. Dataflow dispose ainsi de suffisamment de temps pour accuser réception des fichiers qu'il a traités, ce qui contribue à améliorer les performances globales du job Dataflow. Pour en savoir plus sur les propriétés des abonnements Pub/Sub, consultez Propriétés des abonnements. - Conservez toutes les autres valeurs par défaut sur la page.
- Cliquez sur Créer.
- Dans le champ ID d'abonnement, saisissez
Plus loin dans ce tutoriel, vous créerez un job Dataflow. Lorsque vous créez ce job, vous attribuez Dataflow en tant qu'abonné à l'abonnement my_integration_notifs_sub. Dataflow peut ainsi recevoir des notifications concernant les nouveaux fichiers que Datastream écrit dans Cloud Storage, traiter les fichiers et transférer les modifications de données dans BigQuery.
Créer des ensembles de données dans BigQuery
Dans cette section, vous allez créer des ensembles de données dans BigQuery. BigQuery utilise des ensembles de données pour contenir les données qu'il reçoit de Dataflow. Ces données représentent les modifications apportées à la base de données MySQL source que Datastream diffuse dans votre bucket Cloud Storage.
Accédez à la page Espace de travail SQL pour BigQuery dans la console Google Cloud .
Dans le volet Explorateur, à côté du nom de votre projet Google Cloud , cliquez sur Afficher les actions.
Dans le menu qui s'affiche, sélectionnez Créer un ensemble de données.
Dans la fenêtre Créer un ensemble de données :
- Dans le champ ID de l'ensemble de données, saisissez un ID pour l'ensemble de données. Pour ce tutoriel, saisissez
My_integration_dataset_logdans le champ. - Conservez toutes les autres valeurs par défaut dans la fenêtre.
- Cliquez sur Créer un ensemble de données.
- Dans le champ ID de l'ensemble de données, saisissez un ID pour l'ensemble de données. Pour ce tutoriel, saisissez
Dans le volet Explorateur, à côté du nom de votre projet Google Cloud , cliquez sur Développer le nœud, puis vérifiez que l'ensemble de données que vous avez créé s'affiche.
Suivez les étapes de cette procédure pour créer un deuxième ensemble de données : My_integration_dataset_final.
À côté de chaque ensemble de données, développez Développer le nœud.
Vérifiez que chaque ensemble de données est vide.
Une fois que Datastream a diffusé les modifications de données de la base de données source dans votre bucket Cloud Storage, une tâche Dataflow traite les fichiers contenant les modifications et transfère ces modifications dans les ensembles de données BigQuery.
Créer des profils de connexion dans Datastream
Dans cette section, vous allez créer des profils de connexion dans Datastream pour une base de données source et une destination. Lorsque vous créez les profils de connexion, sélectionnez MySQL comme type de profil pour votre profil de connexion source et Cloud Storage comme type de profil pour votre profil de connexion de destination.
Datastream utilise les informations définies dans les profils de connexion pour se connecter à la source et à la destination. Il peut ainsi diffuser des données de la base de données source vers votre bucket de destination dans Cloud Storage.
Créer un profil de connexion source pour votre base de données MySQL
Dans la console Google Cloud , accédez à la page Profils de connexion de Datastream.
Cliquez sur Créer un profil.
Pour créer un profil de connexion source pour votre base de données MySQL, cliquez sur le type de profil MySQL sur la page Créer un profil de connexion.
Dans la section Définir les paramètres de connexion de la page Créer un profil MySQL, fournissez les informations suivantes :
- Dans le champ Nom du profil de connexion, saisissez
My Source Connection Profile. - Conservez l'ID du profil de connexion généré automatiquement.
Sélectionnez la région dans laquelle vous souhaitez stocker le profil de connexion.
Saisissez les informations sur la connexion :
- Dans le champ Nom d'hôte ou adresse IP, saisissez un nom d'hôte ou une adresse IP publique que Datastream peut utiliser pour se connecter à la base de données source. Vous fournissez une adresse IP publique, car vous utilisez la liste d'autorisation d'adresses IP comme méthode de connectivité réseau pour ce tutoriel.
- Dans le champ Port, saisissez le numéro de port réservé à la base de données source. Pour une base de données MySQL, le port par défaut est généralement
3306. - Saisissez un nom d'utilisateur et un mot de passe pour vous authentifier auprès de votre base de données source.
- Dans le champ Nom du profil de connexion, saisissez
Dans la section Définir les paramètres de connexion, cliquez sur Continuer. La section Sécuriser votre connexion à la source de la page Créer un profil MySQL est active.
Dans le menu Type de chiffrement, sélectionnez Aucun. Pour en savoir plus sur ce menu, consultez Créer un profil de connexion pour une base de données MySQL.
Dans la section Sécurisez votre connexion à la source, cliquez sur Continuer. La section Définir une méthode de connectivité de la page Créer un profil MySQL est active.
Dans le menu déroulant Méthode de connectivité, choisissez la méthode de mise en réseau que vous souhaitez utiliser pour établir la connectivité entre Datastream et la base de données source. Pour ce tutoriel, sélectionnez Liste d'autorisation d'adresses IP comme méthode de connectivité.
Configurez votre base de données source pour autoriser les connexions entrantes provenant des adresses IP publiques Datastream qui s'affichent.
Dans la section Définir la méthode de connectivité, cliquez sur Continuer. La section Tester le profil de connexion de la page Créer un profil MySQL est active.
Cliquez sur Exécuter le test pour vérifier que la base de données source et Datastream peuvent communiquer entre eux.
Vérifiez que l'état Test réussi s'affiche.
Cliquez sur Créer.
Créer un profil de connexion de destination pour Cloud Storage
Dans la console Google Cloud , accédez à la page Profils de connexion de Datastream.
Cliquez sur Créer un profil.
Pour créer un profil de connexion de destination pour Cloud Storage, sur la page Créer un profil de connexion, cliquez sur le type de profil Cloud Storage.
Sur la page Créer un profil Cloud Storage, fournissez les informations suivantes :
- Dans le champ Nom du profil de connexion, saisissez
My Destination Connection Profile. - Conservez l'ID du profil de connexion généré automatiquement.
- Sélectionnez la région dans laquelle vous souhaitez stocker le profil de connexion.
Dans le volet Détails de la connexion, cliquez sur Parcourir pour sélectionner le bucket Cloud Storage que vous avez créé précédemment dans ce tutoriel. Il s'agit du bucket dans lequel Datastream transfère les données de la base de données source. Après avoir effectué votre sélection, cliquez sur Sélectionner.
Votre bucket s'affiche dans le champ Nom du bucket du volet Informations de connexion.
Dans le champ Préfixe de chemin du profil de connexion, indiquez un préfixe pour le chemin que vous souhaitez ajouter au nom du bucket lorsque Datastream diffuse des données vers la destination. Assurez-vous que Datastream écrit les données dans un chemin d'accès à l'intérieur du bucket, et non dans le dossier racine du bucket. Pour ce tutoriel, utilisez le chemin d'accès que vous avez défini lorsque vous avez configuré votre notification Pub/Sub. Saisissez
/integration/tutorialdans le champ.
- Dans le champ Nom du profil de connexion, saisissez
Cliquez sur Créer.
Après avoir créé un profil de connexion source pour votre base de données MySQL et un profil de connexion de destination pour Cloud Storage, vous pouvez utiliser ces profils pour créer un flux.
Créer un flux dans Datastream
Dans cette section, vous allez créer un flux. Ce flux utilise les informations des profils de connexion pour transférer les données d'une base de données MySQL source vers un bucket Cloud Storage de destination.
Définir les paramètres du flux
Dans la console Google Cloud , accédez à la page Flux de Datastream.
Cliquez sur Créer un flux.
Indiquez les informations suivantes dans le panneau Définir les détails du flux de la page Créer un flux :
- Dans le champ Nom du flux, saisissez
My Stream. - Conservez l'ID de flux généré automatiquement.
- Dans le menu Région, sélectionnez la région dans laquelle vous avez créé vos profils de connexion source et de destination.
- Dans le menu Type de source, sélectionnez le type de profil MySQL.
- Dans le menu Type de destination, sélectionnez le type de profil Cloud Storage.
- Dans le champ Nom du flux, saisissez
Passez en revue les conditions préalables générées automatiquement qui reflètent la façon dont votre environnement doit être préparé pour un flux. Ces prérequis peuvent inclure la configuration de la base de données source et la connexion de Datastream au bucket Cloud Storage de destination.
Cliquez sur Continuer. Le panneau Définir le profil de connexion MySQL de la page Créer un flux s'affiche.
Spécifier des informations sur le profil de connexion source
Dans cette section, vous sélectionnez le profil de connexion que vous avez créé pour votre base de données source (profil de connexion source). Pour ce tutoriel, il s'agit de Mon profil de connexion source.
Dans le menu Profil de connexion source, sélectionnez votre profil de connexion source pour la base de données MySQL.
Cliquez sur Exécuter le test pour vérifier que la base de données source et Datastream peuvent communiquer entre eux.
Si le test échoue, le problème associé au profil de connexion s'affiche. Pour connaître les étapes de dépannage, consultez la page Diagnostiquer les problèmes. Apportez les modifications nécessaires pour corriger le problème, puis recommencez le test.
Cliquez sur Continuer. Le panneau Configurer la source du flux de la page Créer un flux s'affiche.
Configurer les informations sur la base de données source du flux
Dans cette section, vous allez configurer des informations sur la base de données source du flux en spécifiant les tables et les schémas de la base de données source dans Datastream :
- Transfert possible vers la destination.
- Transfert restreint vers la destination.
Vous pouvez également déterminer si Datastream remplira les données de l'historique, diffusera les modifications en cours vers la destination ou ne diffusera que les modifications apportées aux données.
Utilisez le menu Objets à inclure pour spécifier les tables et les schémas de votre base de données source que Datastream peut transférer vers un dossier du bucket Cloud Storage de destination. Le menu ne se charge que si votre base de données contient jusqu'à 5 000 objets.
Pour ce tutoriel, vous souhaitez que Datastream transfère toutes les tables et tous les schémas. Par conséquent, sélectionnez Toutes les tables de tous les schémas dans le menu.
Vérifiez que le panneau Sélectionner des objets à exclure est défini sur Aucun. Vous ne souhaitez pas empêcher Datastream de transférer des tables et des schémas de votre base de données source vers Cloud Storage.
Vérifiez que le panneau Choisir le mode de remplissage pour les données historiques est défini sur Automatique. Datastream diffuse toutes les données existantes, en plus des modifications apportées aux données, de la source vers la destination.
Cliquez sur Continuer. Le panneau Définir un profil de connexion Cloud Storage de la page Créer un flux s'affiche.
Sélectionner un profil de connexion de destination
Dans cette section, vous allez sélectionner le profil de connexion que vous avez créé pour Cloud Storage (le profil de connexion de destination). Pour ce tutoriel, il s'agit de Mon profil de connexion de destination.
Dans le menu Profil de connexion de destination, sélectionnez votre profil de connexion de destination pour Cloud Storage.
Cliquez sur Continuer. Le panneau Configurer la destination du flux de la page Créer un flux s'affiche.
Configurer les informations sur la destination du flux
Dans cette section, vous allez configurer des informations sur le bucket de destination du flux. Voici quelques exemples :
- Format de sortie des fichiers écrits dans Cloud Storage.
- Dossier du bucket de destination dans lequel Datastream transfère les schémas, les tables et les données de la base de données source.
Dans le champ Format de sortie, sélectionnez le format des fichiers écrits dans Cloud Storage. Datastream accepte deux formats de sortie : Avro et JSON. Pour ce tutoriel, Avro est le format de fichier.
Cliquez sur Continuer. Le panneau Vérifier les détails et créer le flux de la page Créer un flux s'affiche.
Créer le flux
Vérifiez les détails du flux, ainsi que les profils de connexion source et de destination que le flux utilise pour transférer des données d'une base de données MySQL source vers un bucket Cloud Storage de destination.
Pour valider le flux, cliquez sur Exécuter la validation. En validant un flux, Datastream vérifie que la source est correctement configurée, vérifie que le flux peut se connecter à la source et à la destination, et vérifie la configuration de bout en bout du flux.
Une fois toutes les vérifications de validation effectuées, cliquez sur Créer.
Dans la boîte de dialogue Créer un flux ?, cliquez sur Créer.
Démarrer le flux
Pour ce tutoriel, vous allez créer et démarrer un flux séparément au cas où le processus de création de flux entraînerait une charge accrue sur votre base de données source. Pour libérer cette charge, créez le flux sans le démarrer. Revenez ensuite à l'étape de démarrage lorsque votre base de données peut gérer la charge.
Lorsque vous démarrez un flux, Datastream peut transférer des données, des schémas et des tables de la base de données source vers la destination.
Dans la console Google Cloud , accédez à la page Flux de Datastream.
Cochez la case située à côté du flux que vous souhaitez démarrer. Pour ce tutoriel, il s'agit de Mon flux.
Cliquez sur Démarrer.
Dans la boîte de dialogue, cliquez sur Démarrer. L'état du flux passe de
Not startedàStarting, puis àRunning.
Après avoir démarré un flux, vous pouvez vérifier que Datastream a transféré les données de la base de données source vers la destination.
Vérifier le flux
Dans cette section, vous vérifiez que Datastream transfère les données de toutes les tables d'une base de données MySQL source dans le dossier /integration/tutorial de votre bucket de destination Cloud Storage.
Dans la console Google Cloud , accédez à la page Flux de Datastream.
Cliquez sur le flux que vous avez créé. Pour ce tutoriel, il s'agit de Mon flux.
Sur la page Informations sur le flux, cliquez sur le lien bucket-name/integration/tutorial, où bucket-name est le nom que vous avez donné à votre bucket Cloud Storage. Ce lien s'affiche après le champ Chemin d'écriture de la destination. La page Détails du bucket de Cloud Storage s'ouvre dans un nouvel onglet.
Vérifiez que les dossiers représentent les tables de la base de données source.
Cliquez sur l'un des dossiers de la table, puis sur chaque sous-dossier jusqu'à ce que vous voyiez les données associées à la table.
Créer une tâche Dataflow
Dans cette section, vous allez créer un job dans Dataflow. Une fois que Datastream a diffusé les modifications de données d'une base de données MySQL source dans votre bucket Cloud Storage, Pub/Sub envoie des notifications à Dataflow concernant les nouveaux fichiers contenant les modifications. Le job Dataflow traite les fichiers et transfère les modifications dans BigQuery.
Dans la console Google Cloud , accédez à la page Tâches pour Dataflow.
Cliquez sur Create job from template (Créer une tâche à partir d'un modèle).
Dans le champ Nom de la tâche de la page Créer une tâche à partir d'un modèle, saisissez un nom pour la tâche Dataflow que vous créez. Pour ce tutoriel, saisissez
my-dataflow-integration-jobdans le champ.Dans le menu Point de terminaison régional, sélectionnez la région dans laquelle vous souhaitez stocker le job. Il s'agit de la même région que celle que vous avez sélectionnée pour le profil de connexion source, le profil de connexion de destination et le flux que vous avez créés.
Dans le menu Modèle Dataflow, sélectionnez le modèle que vous utilisez pour créer le job. Pour ce tutoriel, sélectionnez Datastream vers BigQuery.
Une fois cette option sélectionnée, d'autres champs liés à ce modèle s'affichent.
Dans le champ Emplacement des fichiers Datastream dans Cloud Storage, saisissez le nom de votre bucket Cloud Storage au format suivant :
gs://bucket-name.Dans le champ Abonnement Pub/Sub utilisé dans une règle de notification Cloud Storage, saisissez le chemin d'accès contenant le nom de votre abonnement Pub/Sub. Pour ce tutoriel, saisissez
projects/project-name/subscriptions/my_integration_notifs_sub.Dans le champ Format de fichier de sortie Datastream (avro/json), saisissez
avro, car pour ce tutoriel, Avro est le format de fichier des fichiers que Datastream écrit dans Cloud Storage.Dans le champ Nom ou modèle de l'ensemble de données qui contient des tables intermédiaires, saisissez
My_integration_dataset_log, car Dataflow utilise cet ensemble de données pour déployer les modifications de données qu'il reçoit de Datastream.Dans le champ Modèle de l'ensemble de données qui contient des tables dupliquées, saisissez
My_integration_dataset_final, car il s'agit de l'ensemble de données dans lequel les modifications déployées dans l'ensemble de données My_integration_dataset_log sont fusionnées pour créer une instance dupliquée 1 à 1 des tables de la base de données source.Dans le champ Répertoire de la file d'attente des messages non distribués, saisissez le chemin d'accès contenant le nom de votre bucket Cloud Storage et un dossier pour la file d'attente des messages non distribués. Assurez-vous de ne pas utiliser de chemin d'accès dans le dossier racine et que le chemin d'accès est différent de celui dans lequel Datastream écrit les données. Toutes les modifications de données que Dataflow ne parvient pas à transférer dans BigQuery sont stockées dans la file d'attente. Vous pouvez corriger le contenu de la file d'attente pour que Dataflow puisse le retraiter.
Pour ce tutoriel, saisissez
gs://bucket-name/dlqdans le champ Répertoire de la file d'attente des messages non distribués (où bucket-name est le nom de votre bucket et dlq est le dossier de la file d'attente des messages non distribués).Cliquez sur Run Job (Exécuter la tâche).
Valider l'intégration
Dans la section Vérifier le flux de ce tutoriel, vous avez vérifié que Datastream a transféré les données de toutes les tables d'une base de données MySQL source vers le dossier /integration/tutorial de votre bucket de destination Cloud Storage.
Dans cette section, vous allez vérifier que Dataflow traite les fichiers contenant les modifications associées à ces données et transfère les modifications dans BigQuery. Vous disposez ainsi d'une intégration de bout en bout entre Datastream et BigQuery.
Dans la console Google Cloud , accédez à la page Espace de travail SQL pour BigQuery.
Dans le volet Explorateur, développez le nœud à côté du nom de votre projet Google Cloud .
Développez les nœuds à côté des ensembles de données My_integration_dataset_log et My_integration_dataset_final.
Vérifiez que chaque ensemble de données contient désormais des données. Cela confirme que Dataflow a traité les fichiers contenant les modifications associées aux données que Datastream a diffusées dans Cloud Storage, et qu'il a transféré ces modifications dans BigQuery.
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans ce tutoriel ne soient facturées sur votre compte Google Cloud , utilisez la console Google Cloud pour effectuer les opérations suivantes :
- Supprimez votre projet, votre flux Datastream et vos profils de connexion Datastream.
- Arrêtez la tâche Dataflow.
- Supprimez les ensembles de données BigQuery, le sujet et l'abonnement Pub/Sub, et le bucket Cloud Storage.
Nettoyez les ressources que vous avez créées dans Datastream, Dataflow, BigQuery, Pub/Sub et Cloud Storage afin qu'à l'avenir elles ne soient pas comptabilisées dans votre quota et ne vous soient pas facturées.
Supprimer votre projet
Le moyen le plus simple d'empêcher la facturation est de supprimer le projet que vous avez créé pour ce tutoriel.
Dans la console Google Cloud , accédez à la page Gérer les ressources.
Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
Pour supprimer le projet, saisissez son ID dans la boîte de dialogue, puis cliquez sur Arrêter.
Supprimer le flux
Dans la console Google Cloud , accédez à la page Flux de Datastream.
Cliquez sur le flux que vous souhaitez supprimer. Pour ce tutoriel, il s'agit de Mon flux.
Cliquez sur Suspendre.
Dans la boîte de dialogue, cliquez sur Suspendre.
Dans le volet État du flux de la page Détails du flux, vérifiez que l'état du flux est
Paused.Cliquez sur Supprimer.
Dans la boîte de dialogue, saisissez
Deletedans le champ de texte, puis cliquez sur Supprimer.
Supprimer les profils de connexion
Dans la console Google Cloud , accédez à la page Profils de connexion de Datastream.
Cochez la case à côté de chaque profil de connexion que vous souhaitez supprimer : Mon profil de connexion source et Mon profil de connexion de destination.
Cliquez sur Supprimer.
Dans la boîte de dialogue, cliquez sur Supprimer.
Arrêter la tâche Dataflow
Dans la console Google Cloud , accédez à la page Tâches pour Dataflow.
Cliquez sur la tâche que vous souhaitez arrêter. Pour ce tutoriel, il s'agit de my-dataflow-integration-job.
Cliquez sur Arrêter.
Dans la boîte de dialogue Arrêter la tâche, sélectionnez l'option Drainer, puis cliquez sur Arrêter la tâche.
Supprimer les ensembles de données BigQuery
Dans la console Google Cloud , accédez à la page Espace de travail SQL pour BigQuery.
Dans le volet Explorateur, développez le nœud à côté du nom de votre projet Google Cloud .
Cliquez sur le bouton Afficher les actions à droite de l'un des ensembles de données que vous avez créés dans Créer des ensembles de données dans BigQuery. Ce bouton ressemble à des points de suspension verticaux.
Pour ce tutoriel, cliquez sur le bouton Afficher les actions à droite de My_integration_dataset_log.
Sélectionnez Supprimer dans le menu déroulant qui s'affiche.
Dans la boîte de dialogue Supprimer l'ensemble de données ?, saisissez
deletedans le champ de texte, puis cliquez sur Supprimer.Répétez les étapes de cette procédure pour supprimer le deuxième ensemble de données que vous avez créé : My_integration_dataset_final.
Supprimez l'abonnement et le sujet Pub/Sub.
Dans la console Google Cloud , accédez à la page Abonnements pour Pub/Sub.
Cochez la case à côté de l'abonnement que vous souhaitez supprimer. Pour ce tutoriel, cochez la case à côté de l'abonnement my_integration_notifs_sub.
Cliquez sur Supprimer.
Dans la boîte de dialogue Supprimer l'abonnement, cliquez sur Supprimer.
Dans la console Google Cloud , accédez à la page Sujets de Pub/Sub.
Cochez la case à côté du sujet my_integration_notifs.
Cliquez sur Supprimer.
Dans la boîte de dialogue Supprimer le thème, saisissez
deletedans le champ de texte, puis cliquez sur Supprimer.
Supprimer votre bucket Cloud Storage
Dans la console Google Cloud , accédez à la page Navigateur pour Cloud Storage.
Cochez la case située à côté de votre bucket.
Cliquez sur Supprimer.
Dans la boîte de dialogue, saisissez
Deletedans le champ de texte, puis cliquez sur Supprimer.
Étape suivante
- En savoir plus sur Datastream.
- Utilisez l'ancienne API de streaming pour effectuer des opérations avancées avec les données en streaming dans BigQuery.
- Testez d'autres fonctionnalités Google Cloud . Consultez nos tutoriels.