Questo documento descrive come installare e utilizzare il plug-in JupyterLab di Dataproc su una macchina o una VM con accesso ai servizi Google, ad esempio la tua macchina locale o un'istanza VM Compute Engine. Descrive inoltre come sviluppare e eseguire il deployment del codice dei blocchi note Spark.
Dopo aver installato il plug-in JupyterLab di Dataproc, puoi utilizzarlo per svolgere le seguenti attività:
- Avvia sessioni di notebook interattive Dataproc Serverless per Spark
- Invia job batch Dataproc Serverless
Limitazioni e considerazioni di Dataproc Serverless
- I job Spark vengono eseguiti con l'identità dell'account di servizio, non con l'identità dell'utente che li invia.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc API.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc API.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init - Assicurati che nella subnet VPC regionale in cui eseguirai la sessione interattiva di Dataproc Serverless sia attivo l'accesso privato Google. Per saperne di più, consulta Creare un modello di runtime Dataproc Serverless
Installa il plug-in JupyterLab di Dataproc
Puoi installare e utilizzare il plug-in JupyterLab di Dataproc su una macchina o una VM con accesso ai servizi Google, ad esempio la tua macchina locale o un'istanza VM Compute Engine.
Per installare il plug-in:
Scarica e installa la versione 3.8 o successive di Python da
python.org/downloads.Verifica l'installazione di Python 3.8 o versioni successive.
python3 --version
Installa
JupyterLab 3.6.3+sulla tua macchina.pip3 install --upgrade jupyterlabVerifica l'installazione di JupyterLab 3.6.3 o versioni successive.
pip3 show jupyterlab
Installa il plug-in JupyterLab di Dataproc.
pip3 install dataproc-jupyter-pluginSe la tua versione di JupyterLab è precedente alla
4.0.0, abilita l'estensione del plug-in.jupyter server extension enable dataproc_jupyter_plugin
-
jupyter labLa pagina Avvio app di JupyterLab si apre nel browser. Contiene una sezione Job e sessioni Dataproc. Può anche contenere sezioni di notebook Dataproc Serverless e notebook cluster Dataproc se hai accesso a notebook Dataproc Serverless o cluster Dataproc con il componente facoltativo Jupyter in esecuzione nel tuo progetto.

Per impostazione predefinita, la sessione interattiva Dataproc Serverless per Spark viene eseguita nel progetto e nella regione impostati quando hai eseguito
gcloud initin Prima di iniziare. Puoi modificare le impostazioni del progetto e della regione per le sessioni dalla pagina Impostazioni > Impostazioni Dataproc di JupyterLab.
Crea un modello di runtime Dataproc Serverless
I modelli di runtime Dataproc Serverless (chiamati anche modelli session) contengono impostazioni di configurazione per l'esecuzione del codice Spark in una sessione. Puoi creare e gestire i modelli di runtime utilizzando Jupyterlab o gcloud CLI.
JupyterLab
Fai clic sulla scheda
New runtime templatenella sezione Dataproc Serverless Notebooks della pagina Avvio di JupyterLab.
Compila il modulo Modello di runtime.

Specifica un nome visualizzato e una descrizione, quindi inserisci o conferma le altre impostazioni.
Note:
Configurazione di rete: la subnet deve avere attivato l'accesso privato Google e deve consentire la comunicazione della subnet su tutte le porte (consulta Configurazione di rete di Dataproc Serverless per Spark).
Se la subnet della rete
defaultper la regione che hai configurato quando hai eseguitogcloud initin Prima di iniziare non è abilitata per l'accesso privato Google:- Attivala per l'accesso privato Google oppure
- Seleziona un'altra rete con una subnet regionale in cui è attivo l'accesso privato Google. Puoi modificare la regione utilizzata da Dataproc Serverless dalla pagina Impostazioni > Impostazioni Dataproc di JupyterLab.
Metastore: per utilizzare un servizio Dataproc Metastore nelle tue sessioni, seleziona l'ID progetto, la regione e il servizio del metastore.
Tempo di inattività massimo:il tempo di inattività massimo del notebook prima che la sessione venga chiusa. Intervallo consentito: da 10 minuti a 336 ore (14 giorni).
Tempo massimo della sessione:la durata massima di una sessione prima che venga chiusa. Intervallo consentito: da 10 minuti a 336 ore (14 giorni).
PHS: puoi selezionare un server di cronologia Spark permanente disponibile per accedere ai log delle sessioni durante e dopo le sessioni.
Proprietà Spark:fai clic su Aggiungi proprietà per ogni proprietà da impostare per le sessioni Spark serverless. Consulta Proprietà Spark per un elenco delle proprietà Spark supportate e non supportate, tra cui proprietà di runtime, risorse e scalabilità automatica di Spark.
Etichette:fai clic su Aggiungi etichetta per ogni etichetta da impostare sulle sessioni Spark serverless.
Visualizza i modelli di runtime dalla pagina Impostazioni > Impostazioni Dataproc.
- Puoi eliminare un modello dal menu Azione del modello.

Fai clic su Salva.
Apri e ricarica la pagina Avvio app di JupyterLab per visualizzare la scheda del modello di blocco note salvata nella pagina Avvio app di JupyterLab.

gcloud
Crea un file YAML con la configurazione del modello di runtime.
YAML semplice
environmentConfig: executionConfig: networkUri: default jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing description: Team A Development Environment
YAML complesso
environmentConfig: executionConfig: serviceAccount: sa1 # Choose either networkUri or subnetworkUri networkUri: default subnetworkUri: subnet networkTags: - tag1 kmsKey: key1 idleTtl: 3600s ttl: 14400s stagingBucket: staging-bucket peripheralsConfig: metastoreService: projects/my-project-id/locations/us-central1/services/my-metastore-id sparkHistoryServerConfig: dataprocCluster: projects/my-project-id/regions/us-central1/clusters/my-cluster-id jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing runtimeConfig: version: "1.1" containerImage: gcr.io/my-project-id/my-image:1.0.1 properties: "p1": "v1" description: Team A Development Environment
Se la subnet della rete
defaultper la regione che hai configurato quando hai eseguitogcloud initin Prima di iniziare non è attivata per l'accesso privato Google:- Attivala per l'accesso privato Google oppure
- Seleziona un'altra rete con una subnet regionale in cui è attivo l'accesso privato Google. Puoi modificare la regione utilizzata da Dataproc Serverless dalla pagina Impostazioni > Impostazioni Dataproc di JupyterLab.
Crea un modello di sessione (runtime) dal file YAML eseguendo il seguente comando gcloud beta dataproc session-templates import localmente o in Cloud Shell:
gcloud beta dataproc session-templates import TEMPLATE_ID \ --source=YAML_FILE \ --project=PROJECT_ID \ --location=REGION
- Consulta gcloud beta dataproc session-templates per i comandi per descrivere, elencare, esportare ed eliminare i modelli di sessione.
Avviare e gestire i notebook
Dopo aver installato il plug-in JupyterLab di Dataproc, puoi fare clic sulle schede dei modelli nella pagina Avvio di JupyterLab per:
Avvia un notebook Jupyter su Dataproc Serverless
La sezione Notebook Dataproc Serverless nella pagina di avvio di JupyterLab mostra schede dei modelli di notebook che mappano ai modelli di runtime Dataproc Serverless (consulta Creare un modello di runtime Dataproc Serverless).

Fai clic su una scheda per creare una sessione Dataproc Serverless e avviare un notebook. Al termine della creazione della sessione e quando il kernel del notebook è pronto per l'uso, lo stato del kernel cambia da
UnknownaIdle.Scrivere e testare il codice del notebook.
Copia e incolla il seguente codice
Pi estimationPySpark nella cella del notebook PySpark, quindi premi Maiusc+Invio per eseguire il codice.import random def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, 10000)) .filter(inside).count() print("Pi is roughly %f" % (4.0 * count / 10000))
Risultato del notebook:

Dopo aver creato e utilizzato un blocco note, puoi terminare la sessione facendo clic su Arrestare il kernel nella scheda Kernel.
- Per riutilizzare la sessione, crea un nuovo taccuino scegliendo Taccuino dal menu File>>Nuovo. Dopo aver creato il nuovo notebook, scegli la sessione esistente dalla finestra di dialogo di selezione del kernel. Il nuovo blocco note riutilizzerà la sessione e manterrà il contesto della sessione del blocco note precedente.
Se non termini la sessione, Dataproc la termina quando scade il timer di inattività della sessione. Puoi configurare il tempo di inattività della sessione nella configurazione del modello di runtime. Il tempo di inattività predefinito della sessione è un'ora.
Avvia un blocco note su un cluster Dataproc su Compute Engine
Se hai creato un cluster Jupyter Dataproc su Compute Engine, la pagina Avvio di JupyterLab contiene una sezione Notebook cluster Dataproc con schede del kernel preinstallate.

Per avviare un notebook Jupyter sul tuo cluster Dataproc su Compute Engine:
Fai clic su una scheda nella sezione Notebook cluster Dataproc.
Quando lo stato del kernel cambia da
UnknownaIdle, puoi iniziare a scrivere ed eseguire il codice del notebook.Dopo aver creato e utilizzato un blocco note, puoi terminare la sessione facendo clic su Arrestare il kernel nella scheda Kernel.
Gestire i file di input e di output in Cloud Storage
L'analisi dei dati esplorativi e la creazione di modelli ML spesso implicano input e output basati su file. Dataproc Serverless accede a questi file su Cloud Storage.
Per accedere al browser Cloud Storage, fai clic sull'icona del browser Cloud Storage nella barra laterale della pagina Avvio di JupyterLab, quindi fai doppio clic su una cartella per visualizzarne i contenuti.

Puoi fare clic sui tipi di file supportati da Jupyter per aprirli e modificarli. Quando salvate le modifiche ai file, queste vengono scritte in Cloud Storage.
Per creare una nuova cartella Cloud Storage, fai clic sull'icona della nuova cartella, quindi inserisci il nome della cartella.
Per caricare file in un bucket Cloud Storage o in una cartella, fai clic sull'icona di caricamento, quindi seleziona i file da caricare.
Sviluppare il codice del notebook Spark
Dopo aver installato il plug-in JupyterLab di Dataproc, puoi avviare i notebook Jupyter dalla pagina Avvio app di JupyterLab per sviluppare il codice dell'applicazione.
Sviluppo di codice PySpark e Python
I cluster Dataproc Serverless e Dataproc su Compute Engine supportano i kernel PySpark. Dataproc su Compute Engine supporta anche i kernel Python.
Fai clic su una scheda PySpark nella sezione Notebook Dataproc Serverless o Notebook cluster Dataproc nella pagina Avvio di JupyterLab per aprire un notebook PySpark.
Fai clic su una scheda del kernel Python nella sezione Notebook del cluster Dataproc della pagina Avvio app di JupyterLab per aprire un notebook Python.
Sviluppo di codice SQL
Per aprire un blocco note PySpark per scrivere ed eseguire codice SQL, nella pagina JupyterLab Avvio, fai clic sulla scheda del kernel PySpark nella sezione Notebook Dataproc Serverless o Notebook cluster Dataproc.
Magia Spark SQL: poiché il kernel PySpark che avvia
Dataproc Serverless Notebooks
è precaricato con la magia Spark SQL, anziché utilizzare spark.sql('SQL STATEMENT').show()
per inserire un a capo nell'istruzione SQL, puoi digitare
%%sparksql magic nella parte superiore di una cella, quindi digitare l'istruzione SQL nella cella.
BigQuery SQL: il connettore BigQuery Spark consente al codice del tuo notebook di caricare i dati dalle tabelle BigQuery, eseguire analisi in Spark e scrivere i risultati in una tabella BigQuery.
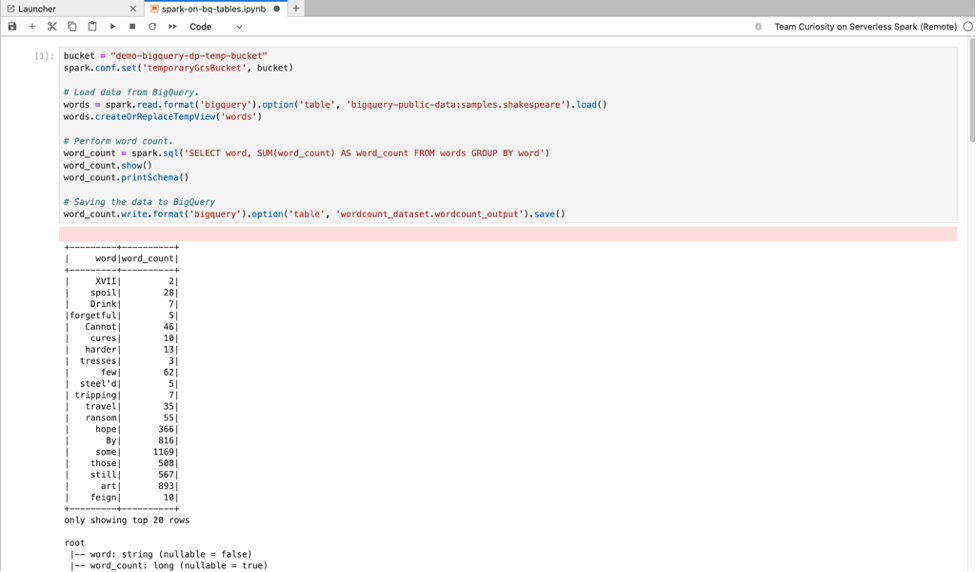
Il runtime Dataproc Serverless 2.1 include il connettore BigQuery Spark. Se utilizzi il runtime Dataproc Serverless 2.0 o una versione precedente per avviare i notebook Dataproc Serverless, puoi installare il connettore BigQuery di Spark aggiungendo la seguente proprietà Spark al modello di runtime Dataproc Serverless:
spark.jars: gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.25.2.jar
Sviluppo di codice Scala
I cluster Dataproc su Compute Engine creati con l'immagine nella versione 2.0 e successive, 2.1 e successive, includono Apache Toree, un kernel Scala per la piattaforma Jupyter Notebook che fornisce accesso interattivo a Spark.
Fai clic sulla scheda Apache Toree nella sezione Notebook cluster Dataproc nella pagina Avvio app di JupyterLab per aprire un notebook per lo sviluppo di codice Scala.
Figura 1. Scheda del kernel Apache Toree nella pagina Avvio app di JupyterLab.
Esplora metadati
Se un'istanza Dataproc Metastore (DPMS) è collegata a un modello di runtime Dataproc Serverless o a un cluster Dataproc su Compute Engine, lo schema dell'istanza DPMS viene visualizzato in JupyterLab Metadata Explorer quando viene aperto un notebook. DPMS è un servizio Hive Metastore (HMS) completamente gestito e scalabile orizzontalmente suGoogle Cloud.
Per visualizzare i metadati HMS in Metadata Explorer:
Abilita l'API Data Catalog nel tuo progetto.
Attiva la sincronizzazione di Data Catalog nel servizio DPMS.
Specifica un'istanza DPMS quando crei il modello di runtime Dataproc serverless o crei il cluster Dataproc su Compute Engine.
Per aprire JupyterLab Metadata Explorer, fai clic sull'icona nella barra laterale.
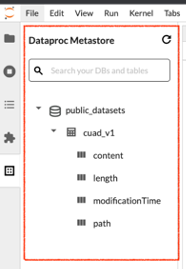
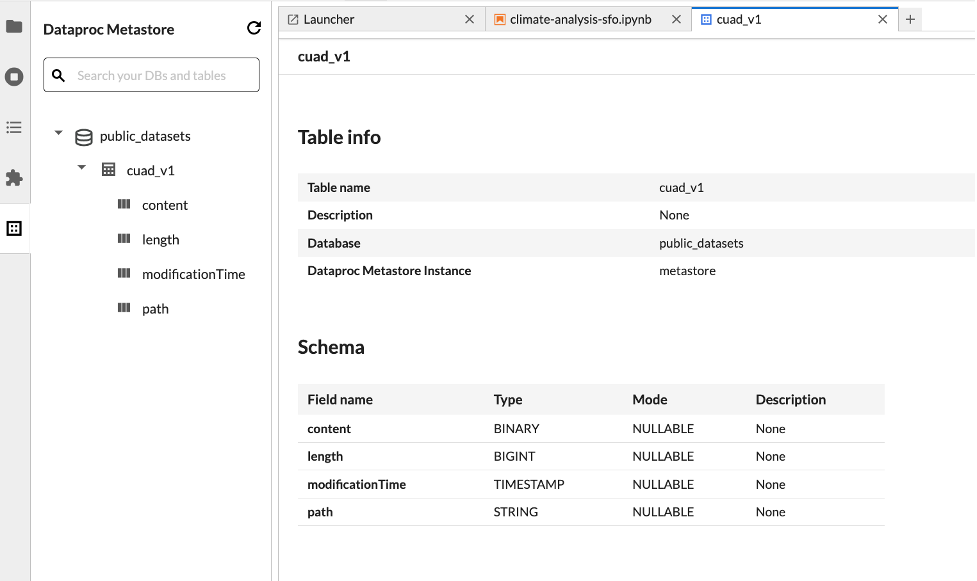
Puoi cercare un database, una tabella o una colonna in Esplora metadati. Fai clic sul nome di un database, di una tabella o di una colonna per visualizzare i metadati associati.
Esegui il deployment del codice
Dopo aver installato il plug-in JupyterLab di Dataproc, puoi utilizzare JupyterLab per:
Esegui il codice del tuo notebook sull'infrastruttura Dataproc Serverless
Invia job batch all'infrastruttura Dataproc Serverless o al tuo cluster Dataproc su Compute Engine.
Eseguire il codice del notebook su Dataproc Serverless
Per eseguire il codice in una cella del notebook, fai clic su Esegui o premi i tasti Maiusc-Invio.
Per eseguire il codice in una o più celle del notebook, utilizza il menu Esegui.
Inviare un job batch a Dataproc Serverless
Fai clic sulla scheda Serverless nella sezione Job e sessioni Dataproc nella pagina Avvio di JupyterLab.
Fai clic sulla scheda Batch, quindi su Crea batch e compila i campi Informazioni batch.
Fai clic su Invia per inviare il job.
Invia un job batch a un cluster Dataproc su Compute Engine
Fai clic sulla scheda Cluster nella sezione Job e sessioni Dataproc nella pagina Avvio di JupyterLab.
Fai clic sulla scheda Job, quindi su Invia job.
Seleziona un cluster, quindi compila i campi Job.
Fai clic su Invia per inviare il job.
Visualizzare e gestire le risorse
Dopo aver installato il plug-in JupyterLab di Dataproc, puoi visualizzare e gestire Dataproc Serverless e Dataproc su Compute Engine dalla sezione Job e sessioni Dataproc nella pagina Avvio di JupyterLab.
Fai clic sulla sezione Job e sessioni Dataproc per visualizzare le schede Cluster e Serverless.
Per visualizzare e gestire le sessioni Dataproc Serverless:
- Fai clic sulla scheda Serverless.
- Fai clic sulla scheda Sessioni, quindi su un ID sessione per aprire la pagina Dettagli sessione per visualizzare le proprietà della sessione, i log in Esplora log Google Cloud e terminare una sessione. Nota: viene creata una sessione Dataproc Serverless univoca per avviare ogni notebook Dataproc Serverless.
Per visualizzare e gestire i batch Dataproc Serverless:
- Fai clic sulla scheda Batch per visualizzare l'elenco dei batch Dataproc Serverless nel progetto e nella regione corrente. Fai clic su un ID batch per visualizzarne i dettagli.
Per visualizzare e gestire i cluster Dataproc su Compute Engine:
- Fai clic sulla scheda Cluster. La scheda Cluster è selezionata per elencare i cluster Dataproc su Compute Engine attivi nel progetto e nella regione correnti. Puoi fare clic sulle icone nella colonna Azioni per avviare, arrestare o riavviare un cluster. Fai clic sul nome di un cluster per visualizzarne i dettagli. Puoi fare clic sulle icone nella colonna Azioni per clonare, interrompere o eliminare un job.
Per visualizzare e gestire i job Dataproc su Compute Engine:
- Fai clic sulla scheda Job per visualizzare l'elenco dei job nel progetto corrente. Fai clic su un ID job per visualizzarne i dettagli.