本文說明可用於監控及排解 Serverless for Apache Spark 批次工作負載問題的工具和檔案。
透過 Google Cloud 控制台排解工作負載問題
如果批次作業失敗或成效不佳,建議您先從 Google Cloud 控制台的「Batches」(批次) 頁面,開啟該作業的「Batch details」(批次詳細資料) 頁面。
使用「摘要」分頁:疑難排解中心
開啟「批次詳細資料」頁面時,系統預設會選取「摘要」分頁,顯示重要指標和經過篩選的記錄,協助您快速初步評估批次健康狀態。完成初步評估後,您可以使用「批次詳細資料」頁面提供的更專業工具,進行更深入的分析,例如 Spark UI、記錄檔探索器和 Gemini Cloud Assist。
批次指標重點
「批次詳細資料」頁面的「摘要」分頁包含圖表,顯示重要的批次工作負載指標值。指標圖表會在完成後填入資料,並以視覺化方式指出潛在問題,例如資源爭用、資料偏斜或記憶體壓力。
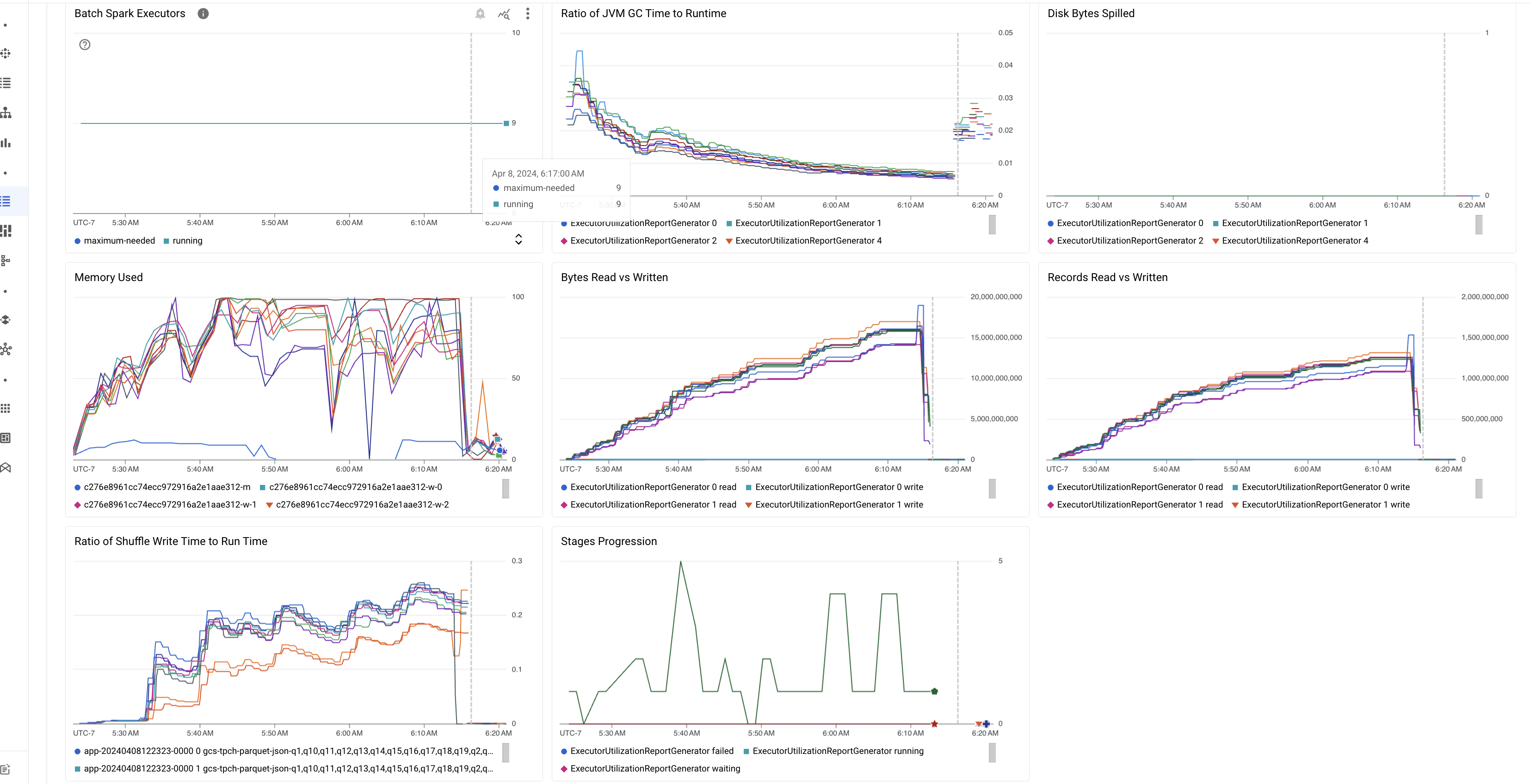
下表列出 Google Cloud 控制台「批次詳細資料」頁面中顯示的 Spark 工作負載指標,並說明指標值如何提供工作負載狀態和效能的深入分析。
| 指標 | 顯示內容 |
|---|---|
| 執行器層級的指標 | |
| JVM 垃圾收集時間與執行階段的比例 | 這項指標會顯示每個執行器的 JVM GC (垃圾收集) 時間與執行階段的比率。高比率可能表示在特定執行器上執行的工作發生記憶體洩漏,或是資料結構效率不彰,導致物件流失率偏高。 |
| 溢出至磁碟的位元組數 | 這項指標顯示不同執行器溢出的磁碟位元組總數。如果執行器顯示溢出的磁碟位元組數偏高,可能表示資料偏斜。如果指標隨著時間增加,可能表示有記憶體壓力或記憶體流失的階段。 |
| 讀取和寫入的位元組數 | 這項指標會顯示每個執行程式寫入的位元組數與讀取的位元組數。如果讀取或寫入的位元組數差異很大,可能表示複製的聯結導致特定執行器上的資料放大。 |
| 讀取和寫入的記錄 | 這項指標會顯示每個執行程式讀取和寫入的記錄。如果讀取的記錄數量較多,但寫入的記錄數量較少,可能表示特定執行器的處理邏輯出現瓶頸,導致系統在等待時讀取記錄。如果執行器持續在讀取和寫入作業中發生延遲,可能表示這些節點發生資源爭用,或是執行器專屬程式碼效率不彰。 |
| 重組寫入時間與執行時間的比率 | 這項指標會顯示執行器在 Shuffle 執行階段所花費的時間,與整體執行階段相比的比例。如果部分執行器的這個值偏高,可能表示資料傾斜或資料序列化效率不彰。 您可以在 Spark UI 中找出改組寫入時間較長的階段。找出這些階段中完成時間超過平均值的異常工作。檢查執行器的隨機寫入時間是否較長,以及磁碟 I/O 活動是否頻繁。更有效率的序列化和額外的分割步驟可能有幫助。如果記錄寫入作業遠多於記錄讀取作業,可能表示因聯結效率不佳或轉換錯誤,導致資料重複。 |
| 應用程式層級的指標 | |
| 階段進展 | 這項指標會顯示失敗、等待和執行階段的階段數。如果失敗或等待的階段數量過多,可能表示資料偏斜。檢查資料分區,並使用 Spark UI 中的「階段」分頁,偵錯階段失敗的原因。 |
| 批次 Spark 執行器 | 這項指標會顯示可能需要的執行者數量,以及正在執行的執行者數量。如果必要執行器和執行中的執行器之間有很大差異,可能表示自動調度資源有問題。 |
| VM 層級指標 | |
| 已使用的記憶體 | 這項指標會顯示 VM 記憶體的使用百分比。如果主機百分比偏高,可能表示驅動程式的記憶體壓力過大。如果是其他 VM 節點,百分比偏高可能表示執行器記憶體不足,導致磁碟溢出量偏高,工作負載執行時間也較長。使用 Spark UI 分析執行器,檢查 GC 時間是否過長,以及任務失敗次數是否過多。此外,您也可以偵錯大型資料集快取和不必要的變數廣播作業的 Spark 程式碼。 |
工作記錄
「批次詳細資料」頁面包含「作業記錄」部分,列出從作業 (批次工作負載) 記錄檔篩選出的警告和錯誤。這項功能可快速找出重大問題,不必手動剖析大量記錄檔。您可以從下拉式選單中選取記錄嚴重程度 (例如 Error),並新增文字篩選條件來縮小結果範圍。如要進行更深入的分析,請按一下「在記錄檔探索工具中查看」圖示,在記錄檔探索工具中開啟所選批次記錄。
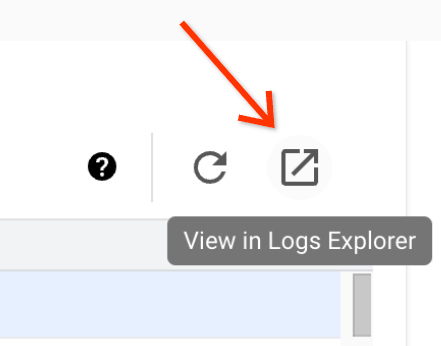
示例:在 Google Cloud 控制台的「批次詳細資料」頁面中,從「嚴重程度」選取器選擇 Errors 後,系統會開啟「記錄檔探索工具」。
Spark UI
Spark UI 會從 Serverless for Apache Spark 批次工作負載收集 Apache Spark 執行詳細資料。Spark UI 功能預設為啟用,且不收取任何費用。
Spark UI 功能收集的資料會保留 90 天。您可以使用這個網頁介面監控 Spark 工作負載並進行偵錯,不必建立永久記錄伺服器。
所需的 Identity and Access Management 權限和角色
如要搭配批次工作負載使用 Spark UI 功能,必須具備下列權限。
資料收集權限:
dataproc.batches.sparkApplicationWrite。必須將這項權限授予執行批次工作負載的服務帳戶。這項權限包含在Dataproc Worker角色中,系統會自動將該角色授予 Serverless for Apache Spark 預設使用的 Compute Engine 預設服務帳戶 (請參閱「Serverless for Apache Spark 服務帳戶」)。不過,如果您為批次工作負載指定自訂服務帳戶,則必須將dataproc.batches.sparkApplicationWrite權限新增至該服務帳戶 (通常是授予服務帳戶 DataprocWorker角色)。Spark UI 存取權限:
dataproc.batches.sparkApplicationRead。必須授予使用者這項權限,才能在Google Cloud 控制台中存取 Spark UI。Dataproc Viewer、Dataproc Editor和Dataproc Administrator角色都具有這項權限。如要在 Google Cloud 控制台中開啟 Spark UI,您必須具備下列其中一個角色,或是包含這項權限的自訂角色。
開啟 Spark UI
您可以在 Google Cloud 控制台批次工作負載中查看 Spark UI 頁面。
前往 Serverless for Apache Spark 互動工作階段頁面。
按一下「批次 ID」,開啟「批次詳細資料」頁面。
按一下頂端選單中的「View Spark UI」(查看 Spark UI)。
在下列情況中,「查看 Spark UI」按鈕會停用:
- 如果未授予必要權限
- 如果清除「批次詳細資料」頁面上的「啟用 Spark UI」核取方塊
- 如果您在提交批次工作負載時,將
spark.dataproc.appContext.enabled屬性設為false
Serverless for Apache Spark 記錄
Serverless for Apache Spark 預設會啟用記錄功能,工作負載記錄會在工作負載完成後保留。Serverless for Apache Spark 會在 Cloud Logging 中收集工作負載記錄。
您可以在記錄檔探索器中,存取 Cloud Dataproc Batch 資源下的 Serverless for Apache Spark 記錄。
查詢 Serverless for Apache Spark 記錄
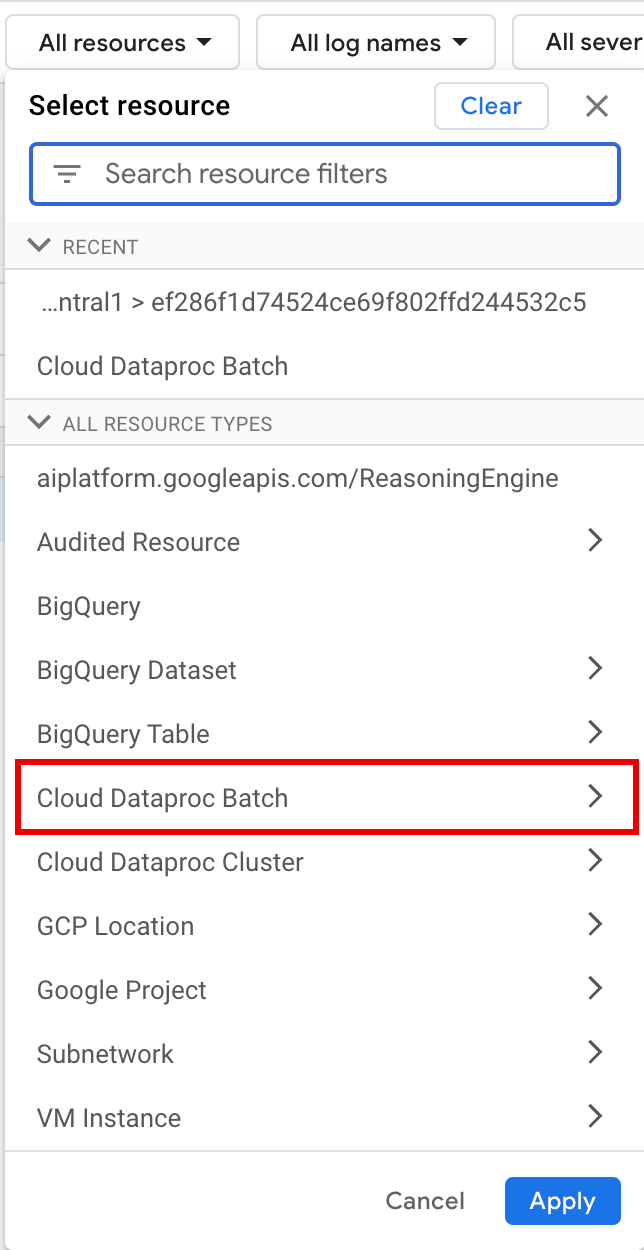
Google Cloud 控制台中的記錄檔探索工具提供查詢窗格,可協助您建構查詢,檢查批次工作負載記錄。如要建立查詢來檢查批次工作負載記錄,請按照下列步驟操作:
- 系統會選取目前的專案。您可以點選「Refine scope Project」,選取其他專案。
定義批次記錄查詢。
使用篩選選單,篩選批次工作負載。
使用查詢編輯器,篩選出 VM 專屬記錄。
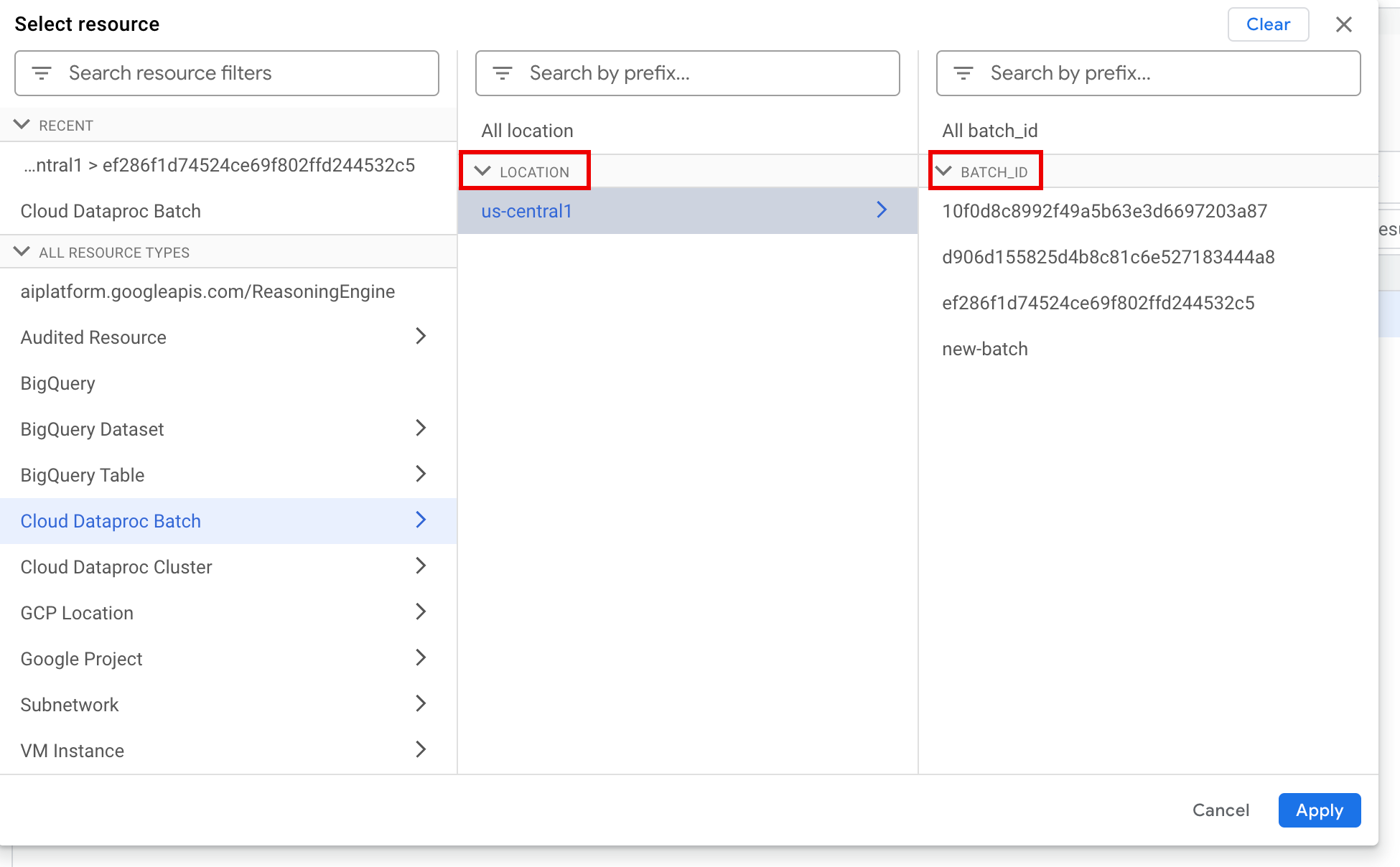
指定資源類型和 VM 資源名稱,如下列範例所示:
resource.type="cloud_dataproc_batch" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
- BATCH_UUID:批次 UUID 會列在 Google Cloud 控制台的「Batch details」(批次詳細資料) 頁面中。如要開啟這個頁面,請在「Batches」(批次) 頁面中點選批次 ID。
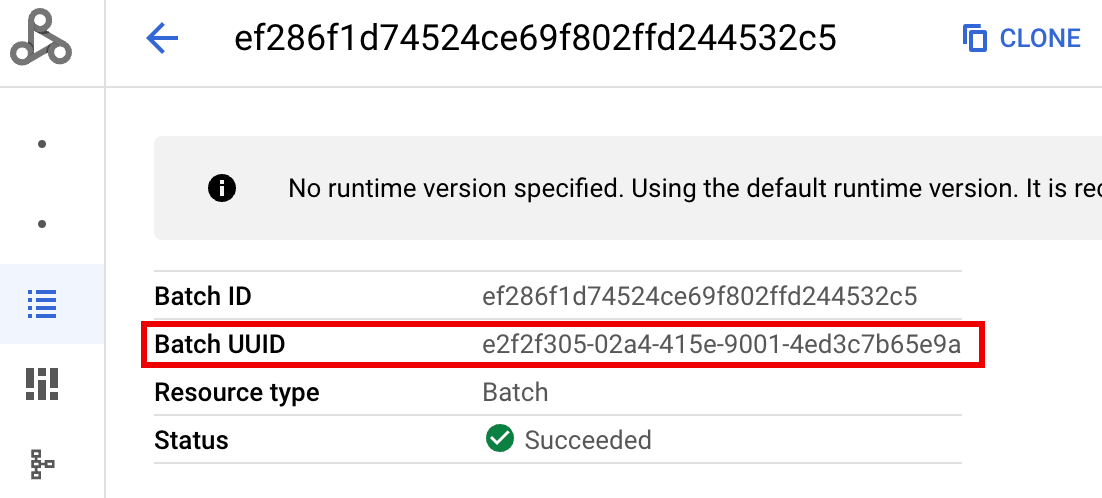
批次記錄也會在 VM 資源名稱中列出批次 UUID。 以下是批次 driver.log 的範例:
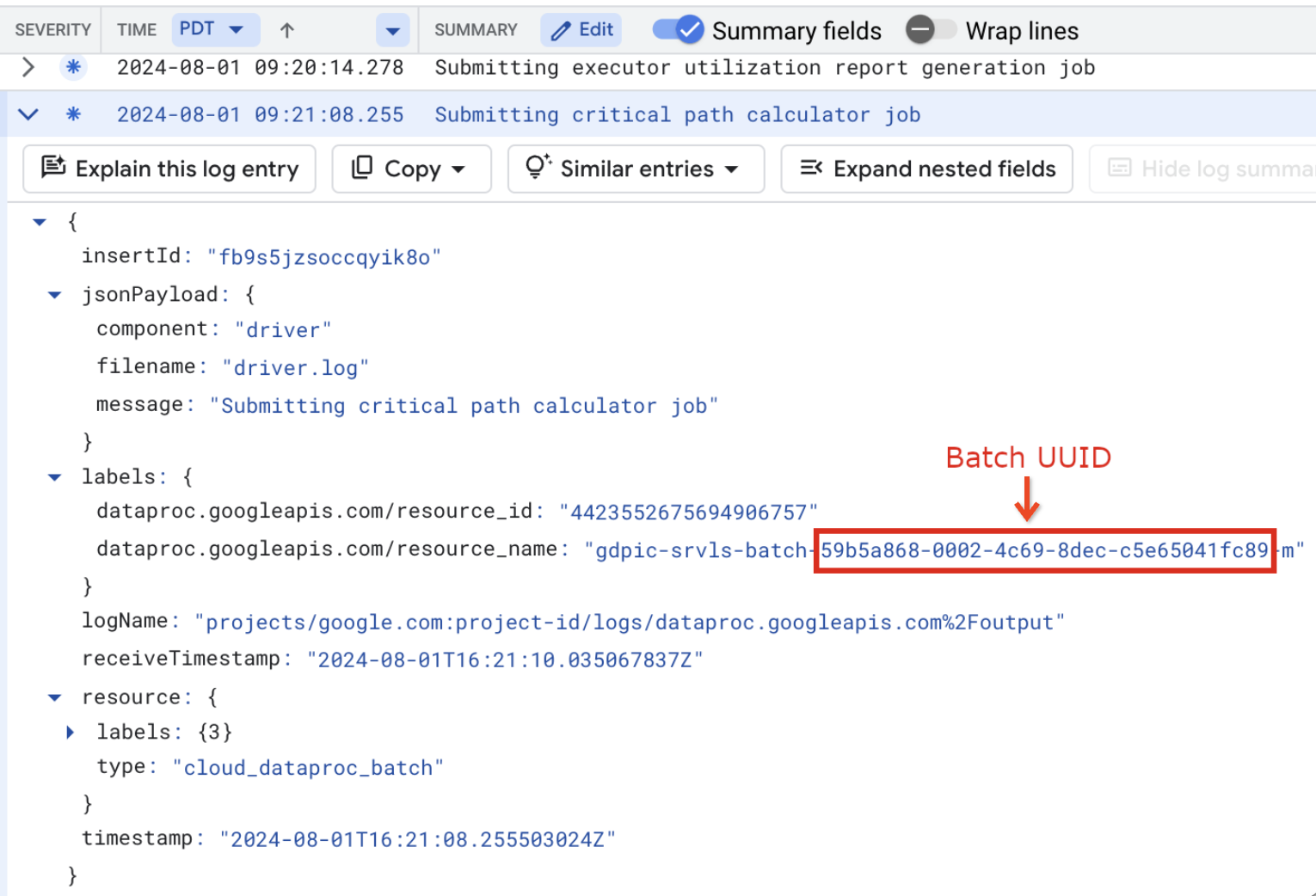
- BATCH_UUID:批次 UUID 會列在 Google Cloud 控制台的「Batch details」(批次詳細資料) 頁面中。如要開啟這個頁面,請在「Batches」(批次) 頁面中點選批次 ID。
點選「執行查詢」
Serverless for Apache Spark 記錄類型和範例查詢
下表說明不同的 Serverless for Apache Spark 記錄類型,並提供每種記錄類型的記錄檢視器查詢範例。
dataproc.googleapis.com/output:這個記錄檔包含批次工作負載輸出內容。 Serverless for Apache Spark 會將批次輸出內容串流至output命名空間,並將檔案名稱設為JOB_ID.driver.log。輸出記錄的記錄檔探索工具查詢範例:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Foutput"
dataproc.googleapis.com/spark:spark命名空間會彙整在 Dataproc 叢集主機和工作站 VM 上執行的精靈和執行器 Spark 記錄。每筆記錄項目都包含master、worker或executor元件標籤,用於識別記錄來源,如下所示:executor:來自使用者程式碼執行器的記錄。通常是分散式記錄。master:Spark 獨立資源管理員主機的記錄檔,與 Dataproc on Compute Engine YARNResourceManager記錄檔類似。worker:Spark 獨立資源管理員工作站的記錄,與 Dataproc on Compute Engine YARNNodeManager記錄類似。
以下是
spark命名空間中所有記錄的記錄檔探索工具查詢範例:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark"
以下是
spark命名空間中 Spark 獨立元件記錄的記錄檔探索工具查詢範例:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark" jsonPayload.component="COMPONENT"
dataproc.googleapis.com/startup:startup命名空間包含批次 (叢集) 啟動記錄。其中包含任何初始化指令碼記錄。元件會以標籤識別,例如:startup-script[855]: ... activate-component-spark[3050]: ... enable spark-worker
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fstartup" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
dataproc.googleapis.com/agent:agent命名空間會彙整 Dataproc 代理程式記錄。每個記錄項目都包含檔案名稱標籤,可識別記錄來源。指定工作站 VM 產生的代理程式記錄檔的記錄檔探索工具查詢範例:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fagent" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
dataproc.googleapis.com/autoscaler:autoscaler命名空間會彙整 Serverless for Apache Spark 自動調整程式記錄。指定工作站 VM 產生的代理程式記錄檔的記錄檔探索工具查詢範例:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fautoscaler" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
詳情請參閱「Dataproc 記錄」。
如要瞭解 Serverless for Apache Spark 稽核記錄,請參閱「Dataproc 稽核記錄」。
工作負載指標
Serverless for Apache Spark 提供批次和 Spark 指標,您可以在 Metrics Explorer 或 Google Cloud 控制台的「Batch details」(批次詳細資料) 頁面中查看。
批次指標
Dataproc batch 資源指標可深入瞭解批次資源,例如批次執行器數量。批次指標的前置字串是 dataproc.googleapis.com/batch。
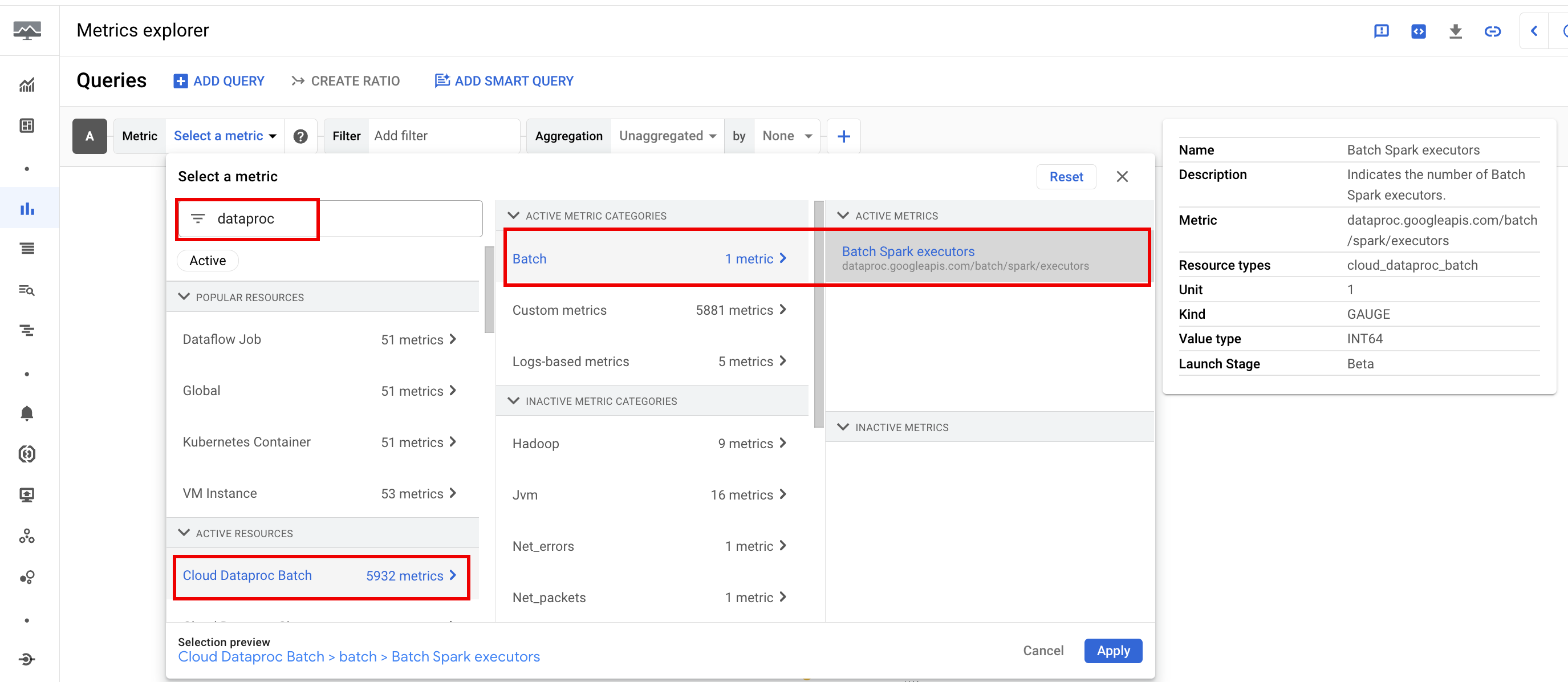
Spark 指標
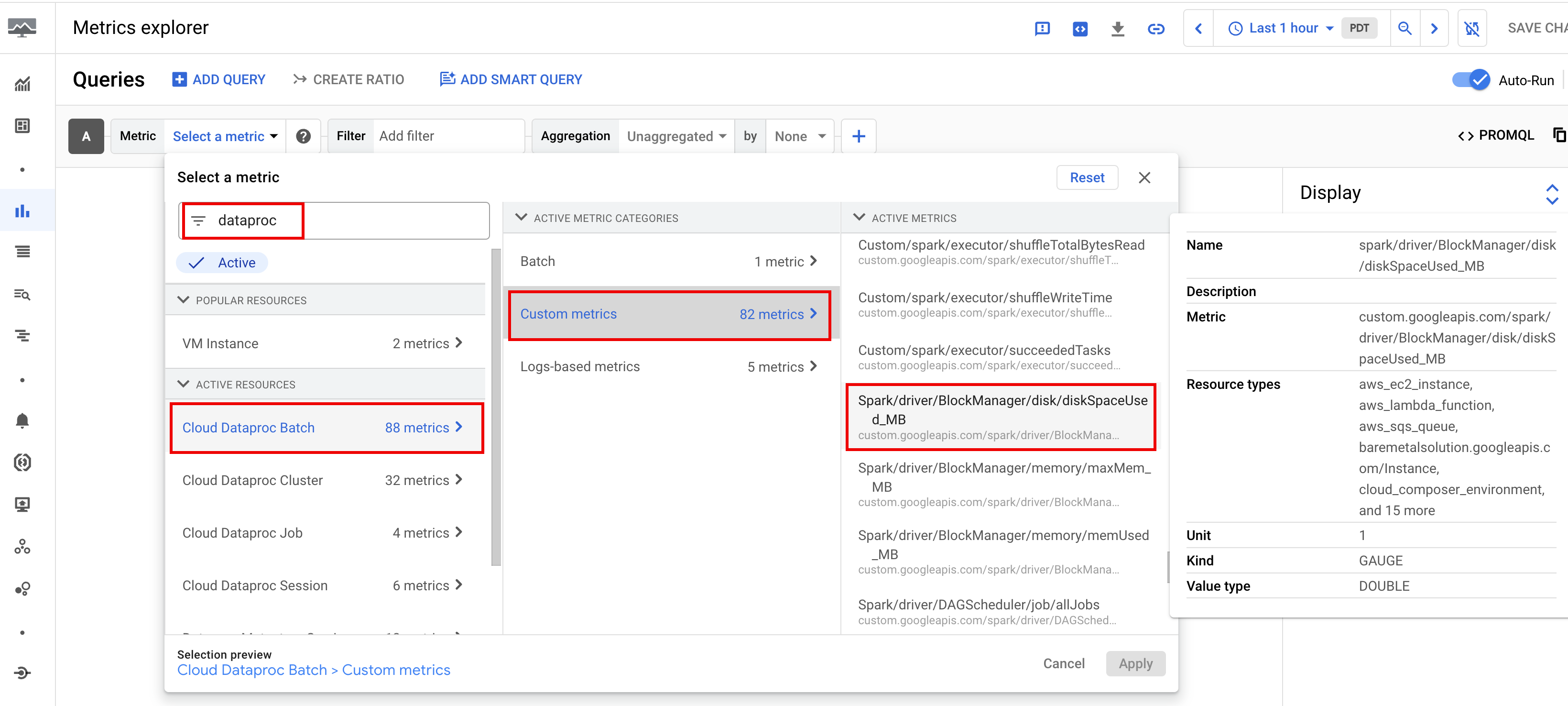
根據預設,Serverless for Apache Spark 會收集可用的 Spark 指標,除非您使用 Spark 指標收集屬性停用或覆寫一或多個 Spark 指標的收集作業。
可用的 Spark 指標包括 Spark 驅動程式和執行器指標,以及系統指標。可用的 Spark 指標會加上 custom.googleapis.com/ 前置字元。
設定指標快訊
您可以建立 Dataproc 指標快訊,以便在工作負載發生問題時收到通知。
建立圖表
您可以在Google Cloud 控制台中使用 Metrics Explorer 建立圖表,以視覺化方式呈現工作負載指標。舉例來說,您可以建立圖表來顯示 disk:bytes_used,然後依 batch_id 篩選。
Cloud Monitoring
監控功能會使用工作負載中繼資料和指標,深入瞭解 Serverless for Apache Spark 工作負載的健康狀態和效能。工作負載指標包括 Spark 指標、批次指標和作業指標。
您可以在 Google Cloud 控制台 中使用 Cloud Monitoring 探索指標、新增圖表、建立資訊主頁及建立快訊。
建立資訊主頁
您可以建立資訊主頁,使用多個專案和不同 Google Cloud 產品的指標監控工作負載。詳情請參閱「建立及管理自訂資訊主頁」一文。
永久記錄伺服器
Serverless for Apache Spark 會建立執行工作負載所需的運算資源,並在這些資源上執行工作負載,然後在工作負載完成時刪除資源。工作負載完成後,工作負載指標和事件不會保留。不過,您可以使用永久記錄伺服器 (PHS),將工作負載應用程式記錄 (事件記錄) 保存在 Cloud Storage 中。
如要將 PHS 與批次工作負載搭配使用,請按照下列步驟操作:
自動調整
- 為 Serverless for Apache Spark 啟用自動調校功能:使用 Google Cloud 控制台、gcloud CLI 或 Dataproc API 提交每個週期性 Spark 批次工作負載時,可以為 Serverless for Apache Spark 啟用自動調校功能。
控制台
如要為每個週期性 Spark 批次工作負載啟用自動調整功能,請執行下列步驟:
在 Google Cloud 控制台中,前往 Dataproc 的「Batches」(批次) 頁面。
如要建立批次工作負載,請按一下「建立」。
在「容器」部分,填寫「同類群組」名稱,用來將批次識別為一系列週期性工作負載之一。Gemini 輔助分析會套用至以這個同類群組名稱提交的第二個和後續工作負載。舉例來說,如果排程工作負載每天都會執行 TPC-H 查詢,您可以將群組名稱指定為
TPCH-Query1。視需要填寫「建立批次」頁面的其他部分,然後按一下「提交」。詳情請參閱「提交批次工作負載」。
gcloud
在本機終端機視窗或 Cloud Shell 中執行下列 gcloud CLI gcloud dataproc batches submit 指令,為每個週期性 Spark 批次工作負載啟用自動調整功能:
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ other arguments ...
更改下列內容:
- COMMAND:Spark 工作負載類型,例如
Spark、PySpark、Spark-Sql或Spark-R。 - REGION:工作負載執行的區域。
- COHORT:同類群組名稱,用於將批次識別為一系列週期性工作負載之一。Gemini 輔助分析會套用至以這個同類群組名稱提交的第二個和後續工作負載。舉例來說,如果排定工作負載每天執行 TPC-H 查詢,您可以將群組名稱指定為
TPCH Query 1。
API
在 batches.create 要求中加入 RuntimeConfig.cohort 名稱,即可為每個週期性 Spark 批次工作負載啟用自動調整功能。系統會將自動調整功能套用至以這個同類群組名稱提交的第二個和後續工作負載。舉例來說,如果排定工作負載每天執行 TPC-H 查詢,您可以將同類群組名稱指定為 TPCH-Query1。
範例:
...
runtimeConfig:
cohort: TPCH-Query1
...