Questo documento descrive gli strumenti e i file che puoi utilizzare per monitorare e risolvere i problemi relativi ai carichi di lavoro batch di Serverless per Apache Spark.
Risolvere i problemi relativi ai workload dalla console Google Cloud
Quando un job batch non riesce o ha un rendimento scarso, il primo passaggio consigliato è aprire la pagina Dettagli batch dalla pagina Batch nella console Google Cloud .
Utilizzare la scheda Riepilogo: il tuo hub per la risoluzione dei problemi
La scheda Riepilogo, selezionata per impostazione predefinita all'apertura della pagina Dettagli batch, mostra metriche critiche e log filtrati per aiutarti a eseguire una valutazione iniziale rapida dell'integrità del batch. Dopo questa valutazione iniziale, puoi eseguire un'analisi più approfondita utilizzando strumenti più specializzati elencati nella pagina Dettagli batch, come l'interfaccia utente di Spark, l'Esplora log e Gemini Cloud Assist.
Metriche batch in evidenza
La scheda Riepilogo nella pagina Dettagli batch include grafici che mostrano i valori delle metriche importanti del workload batch. I grafici delle metriche vengono compilati al termine e offrono un'indicazione visiva di potenziali problemi come contesa delle risorse, distorsione dei dati o pressione sulla memoria.
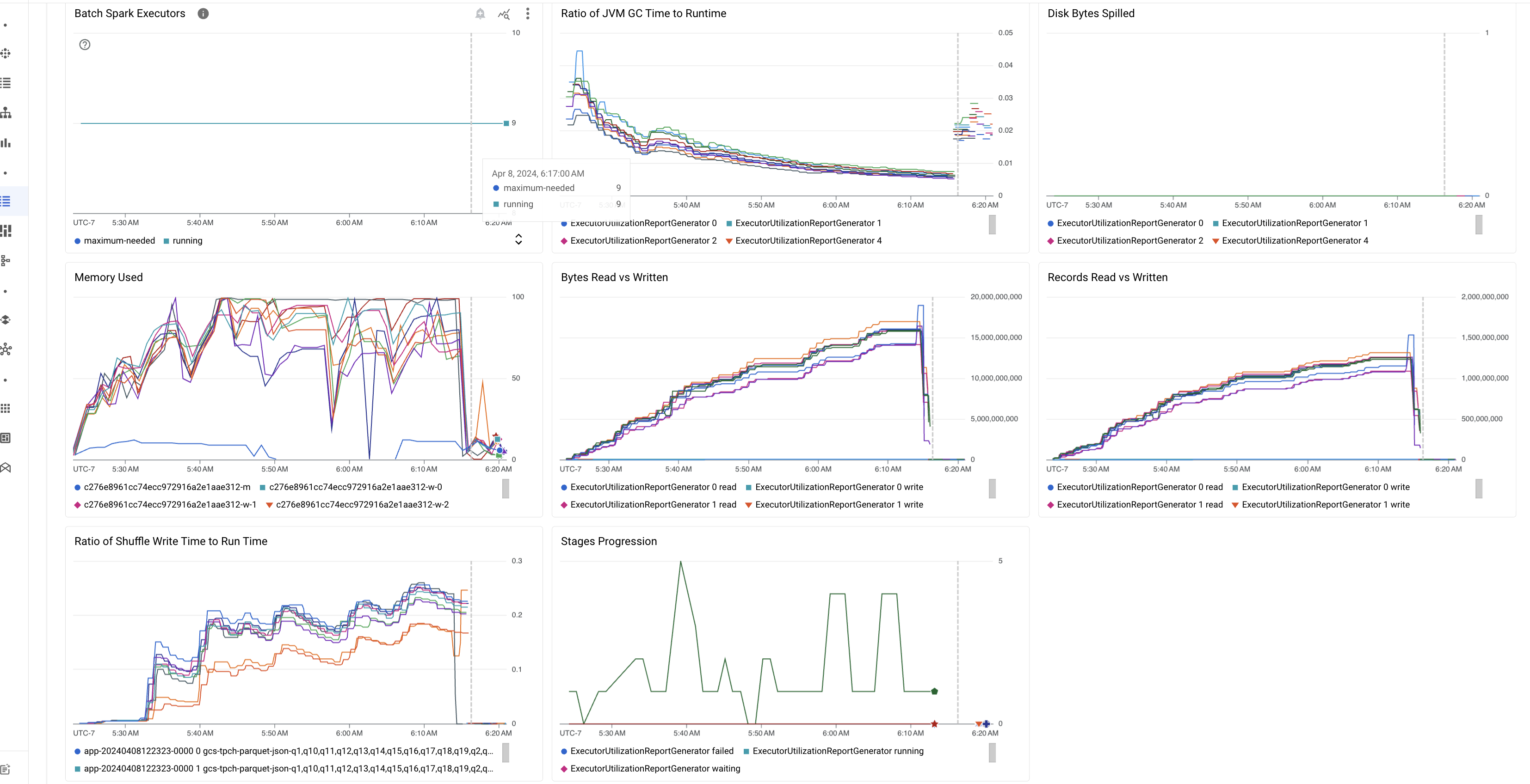
La tabella seguente elenca le metriche del carico di lavoro Spark visualizzate nella pagina Dettagli batch della console Google Cloud e descrive in che modo i valori delle metriche possono fornire informazioni sullo stato e sulle prestazioni del carico di lavoro.
| Metrica | Che cosa mostra? |
|---|---|
| Metriche a livello di esecutore | |
| Rapporto tra tempo GC JVM e runtime | Questa metrica mostra il rapporto tra il tempo di GC (garbage collection) della JVM e il runtime per esecutore. Rapporti elevati possono indicare perdite di memoria all'interno delle attività in esecuzione su determinati executor o strutture di dati inefficienti, che possono portare a un elevato churn degli oggetti. |
| Byte con overflow su disco | Questa metrica mostra il numero totale di byte del disco spillati in diversi executor. Se un executor mostra un numero elevato di byte di disco spillati, ciò può indicare una distorsione dei dati. Se la metrica aumenta nel tempo, ciò può indicare che ci sono fasi con pressione sulla memoria o perdite di memoria. |
| Byte letti e scritti | Questa metrica mostra i byte scritti rispetto ai byte letti per executor. Grandi discrepanze nei byte letti o scritti possono indicare scenari in cui i join replicati comportano l'amplificazione dei dati su executor specifici. |
| Record letti e scritti | Questa metrica mostra i record letti e scritti per esecutore. Un numero elevato di record letti con un numero ridotto di record scritti può indicare un collo di bottiglia nella logica di elaborazione di executor specifici, il che comporta la lettura dei record durante l'attesa. I programmi di esecuzione che registrano costantemente ritardi nelle letture e nelle scritture possono indicare contese di risorse su questi nodi o inefficienze del codice specifiche del programma di esecuzione. |
| Rapporto tra il tempo di scrittura shuffling e il tempo di esecuzione | La metrica mostra la quantità di tempo che l'executor ha trascorso nel runtime di rimescolamento rispetto al runtime complessivo. Se questo valore è elevato per alcuni executor, può indicare una distorsione dei dati o una serializzazione inefficiente dei dati. Puoi identificare le fasi con tempi di scrittura shuffle lunghi nell'interfaccia utente di Spark. Cerca le attività anomale all'interno di queste fasi che richiedono più tempo del tempo medio per essere completate. Controlla se gli executor con tempi di scrittura shuffle elevati mostrano anche un'attività I/O del disco elevata. Una serializzazione più efficiente e passaggi di partizionamento aggiuntivi potrebbero essere utili. Scritture di record molto grandi rispetto alle letture di record possono indicare una duplicazione involontaria dei dati dovuta a join inefficienti o trasformazioni errate. |
| Metriche a livello di applicazione | |
| Avanzamento delle fasi | Questa metrica mostra il numero di fasi in stato Non riuscito, In attesa e In esecuzione. Un numero elevato di fasi non riuscite o in attesa può indicare una distorsione dei dati. Controlla le partizioni di dati e esegui il debug del motivo dell'errore della fase utilizzando la scheda Fasi nell'interfaccia utente di Spark. |
| Esecutori Spark batch | Questa metrica mostra il numero di esecutori che potrebbero essere necessari rispetto al numero di esecutori in esecuzione. Una grande differenza tra gli executor richiesti e quelli in esecuzione può indicare problemi di scalabilità automatica. |
| Metriche a livello di VM | |
| Memoria utilizzata | Questa metrica mostra la percentuale di memoria della VM in uso. Se la percentuale master è elevata, può indicare che il driver è sotto pressione della memoria. Per gli altri nodi VM, una percentuale elevata può indicare che gli executor stanno esaurendo la memoria, il che può comportare un elevato spillage del disco e un runtime del carico di lavoro più lento. Utilizza la UI di Spark per analizzare gli executor e verificare la presenza di tempi GC elevati e un numero elevato di errori delle attività. Esegui anche il debug del codice Spark per la memorizzazione nella cache di set di dati di grandi dimensioni e la trasmissione non necessaria di variabili. |
Log job
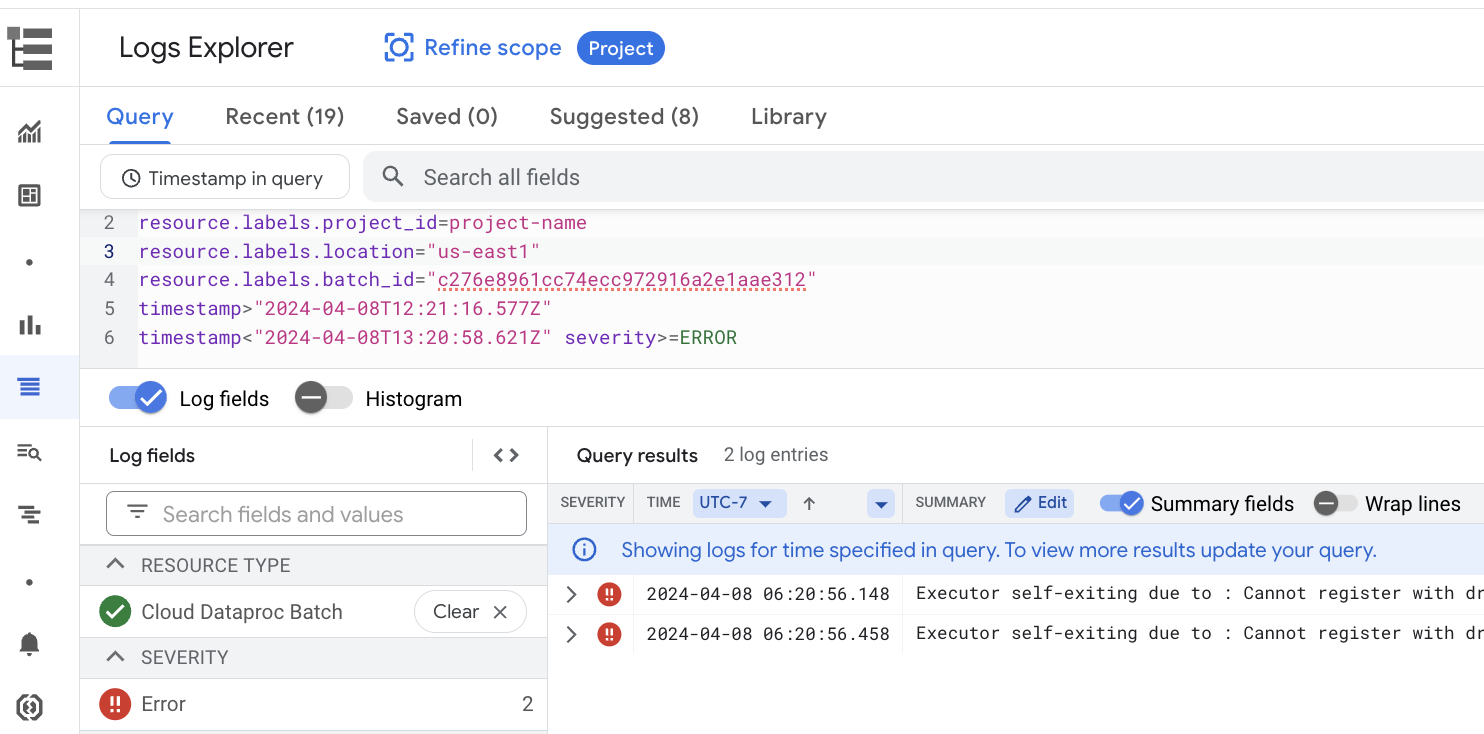
La pagina Dettagli batch include una sezione Log dei job che elenca gli avvisi e gli errori filtrati dai log del job (carico di lavoro batch). Questa funzionalità consente di identificare rapidamente i problemi critici senza dover analizzare manualmente file di log estesi. Puoi selezionare una gravità del log (ad esempio Error) dal menu a discesa e aggiungere un filtro di testo per restringere i risultati. Per eseguire un'analisi più approfondita, fai clic sull'icona Visualizza in Esplora log
per aprire i log batch selezionati in Esplora log.
Esempio: Esplora log si apre dopo aver scelto Errors dal selettore Gravità nella pagina Dettagli batch della console Google Cloud .
UI Spark
La UI di Spark raccoglie i dettagli di esecuzione di Apache Spark dai workload batch di Serverless per Apache Spark. Non è previsto alcun costo per la funzionalità UI di Spark, che è attivata per impostazione predefinita.
I dati raccolti dalla funzionalità UI di Spark vengono conservati per 90 giorni. Puoi utilizzare questa interfaccia web per monitorare ed eseguire il debug dei carichi di lavoro Spark senza dover creare un server di cronologia permanente.
Ruoli e autorizzazioni Identity and Access Management richiesti
Per utilizzare la funzionalità UI di Spark con i carichi di lavoro batch sono necessarie le seguenti autorizzazioni.
Autorizzazione alla raccolta dei dati:
dataproc.batches.sparkApplicationWrite. Questa autorizzazione deve essere concessa alaccount di serviziot che esegue i carichi di lavoro batch. Questa autorizzazione è inclusa nel ruoloDataproc Worker, che viene concesso automaticamente al account di servizio predefinito di Compute Engine utilizzato per impostazione predefinita da Serverless for Apache Spark (vedi Service account Serverless for Apache Spark). Tuttavia, se specifichi un service account personalizzato per il tuo workload batch, devi aggiungere l'autorizzazionedataproc.batches.sparkApplicationWritea questo account di servizio (in genere, concedendo al account di servizio il ruoloWorkerDataproc).Autorizzazione di accesso alla UI Spark:
dataproc.batches.sparkApplicationRead. Questa autorizzazione deve essere concessa a un utente per accedere alla UI di Spark nella consoleGoogle Cloud . Questa autorizzazione è inclusa nei ruoliDataproc Viewer,Dataproc EditoreDataproc Administrator. Per aprire la UI di Spark nella console Google Cloud , devi disporre di uno di questi ruoli o di un ruolo personalizzato che includa questa autorizzazione.
Apri la UI Spark
La pagina dell'interfaccia utente di Spark è disponibile nei carichi di lavoro batch della console Google Cloud .
Vai alla pagina Sessioni interattive serverless per Apache Spark.
Fai clic su un ID batch per aprire la pagina Dettagli batch.
Fai clic su Visualizza UI Spark nel menu in alto.
Il pulsante Visualizza UI di Spark è disattivato nei seguenti casi:
- Se un'autorizzazione obbligatoria non viene concessa
- Se deselezioni la casella di controllo Abilita UI Spark nella pagina Dettagli batch
- Se imposti la proprietà
spark.dataproc.appContext.enabledsufalsequando invii un carico di lavoro batch
Indagini basate sull'AI con Gemini Cloud Assist (anteprima)
Panoramica
La funzionalità di anteprima Indagini di Gemini Cloud Assist utilizza le funzionalità avanzate di Gemini per assistere nella creazione e nell'esecuzione di workload batch di Serverless per Apache Spark. Questa funzionalità analizza i workload non riusciti e a esecuzione lenta per identificare le cause principali e consigliare correzioni. Crea un'analisi persistente che puoi esaminare, salvare e condividere con l' Google Cloud assistenza per facilitare la collaborazione e accelerare la risoluzione dei problemi.
Funzionalità
Utilizza questa funzionalità per creare indagini dalla console Google Cloud :
- Aggiungi una descrizione del contesto in linguaggio naturale a un problema prima di creare un'indagine.
- Analizza i carichi di lavoro batch lenti e non riusciti.
- Ottieni informazioni sulle cause principali dei problemi con le correzioni consigliate.
- Crea Google Cloud richieste di assistenza con il contesto completo dell'indagine allegato.
Prima di iniziare
Per iniziare a utilizzare la funzionalità Indagine, nel tuo progetto Google Cloud , abilita l'API Gemini Cloud Assist.
Avviare un'indagine
Per avviare un'indagine, procedi in uno dei seguenti modi:
Opzione 1: nella console Google Cloud , vai alla pagina dell'elenco dei batch. Per qualsiasi batch con stato
Failed, nella colonna Approfondimenti con Gemini viene visualizzato un pulsante ANALIZZA. Fai clic sul pulsante per avviare un'indagine.
Opzione 2: apri la pagina dei dettagli del batch del workload batch da esaminare. Per i carichi di lavoro batch
SucceededeFailed, nella sezione Panoramica dello stato della scheda Riepilogo, nel riquadro Approfondimenti con Gemini viene visualizzato un pulsante ESAMINA. Fai clic sul pulsante per avviare un'indagine.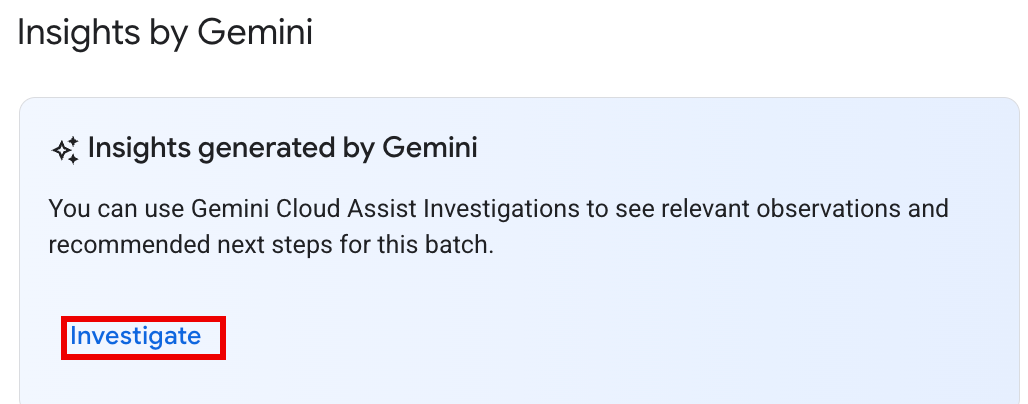
Il testo del pulsante di indagine indica lo stato dell'indagine:
- INDAGA:non è stata eseguita alcuna indagine per questo batch_details. Fai clic sul pulsante per avviare un'indagine.
- VISUALIZZA INDAGINE:un'indagine è stata completata. Fai clic sul pulsante Per visualizzare i risultati.
- IN CORSO DI INDAGINE: è in corso un'indagine.
Interpretare i risultati dell'indagine
Una volta completata un'indagine, viene aperta la pagina Dettagli indagine. Questa pagina contiene l'analisi completa di Gemini, organizzata nelle seguenti sezioni:
- Problema: una sezione compressa contenente i dettagli compilati automaticamente del carico di lavoro batch in fase di analisi.
- Osservazioni pertinenti: una sezione compressa che elenca i punti dati chiave e le anomalie rilevate da Gemini durante l'analisi di log e metriche.
- Ipotesi: questa è la sezione principale, che viene espansa per impostazione predefinita.
Viene visualizzato un elenco di potenziali cause principali del problema osservato. Ogni ipotesi
include:
- Panoramica: una descrizione della possibile causa, ad esempio "Tempo di scrittura shuffle elevato e potenziale asimmetria delle attività".
- Correzioni consigliate: un elenco di passaggi attuabili per risolvere il potenziale problema.
Intervieni
Dopo aver esaminato le ipotesi e i consigli:
Applica una o più delle correzioni suggerite alla configurazione o al codice del job e poi esegui di nuovo il job.
Fornisci un feedback sull'utilità dell'indagine facendo clic sulle icone Mi piace o Non mi piace nella parte superiore del riquadro.
Esaminare e riassegnare le indagini
I risultati di un'indagine eseguita in precedenza possono essere esaminati facendo clic sul nome dell'indagine nella pagina Indagini di Cloud Assist per aprire la pagina Dettagli indagine.
Se hai bisogno di ulteriore assistenza, puoi aprire una Google Cloud richiesta di assistenza. Questa procedura fornisce all'tecnico del servizio di assistenza il contesto completo dell'indagine eseguita in precedenza, incluse le osservazioni e le ipotesi generate da Gemini. Questa condivisione del contesto riduce notevolmente la comunicazione bidirezionale necessaria con il team di assistenza e porta a una risoluzione più rapida della richiesta.
Per creare una richiesta di assistenza da un'indagine:
Nella pagina Dettagli indagine, fai clic su Richiedi assistenza.
Stato dell'anteprima e prezzi
Non è previsto alcun costo per le indagini di Gemini Cloud Assist durante l'anteprima pubblica. Gli addebiti verranno applicati alla funzionalità quando sarà disponibile pubblicamente (GA).
Per maggiori informazioni sui prezzi dopo la disponibilità generale, consulta la pagina Prezzi di Gemini Cloud Assist.
Anteprima di Gemini (ritiro il 22 settembre 2025)
La funzionalità di anteprima Chiedi a Gemini forniva l'accesso con un clic a informazioni approfondite sulle pagine Batch e Dettagli batch nella console Google Cloud tramite un pulsante Chiedi a Gemini. Questa funzione ha generato un riepilogo di errori, anomalie e potenziali miglioramenti delle prestazioni in base a log e metriche del carico di lavoro.
Dopo il ritiro dell'anteprima "Chiedi a Gemini" il 22 settembre 2025, gli utenti potranno continuare a ricevere assistenza basata sull'AI utilizzando la funzionalità Indagini di Gemini Cloud Assist.
Importante:per garantire un'assistenza AI per la risoluzione dei problemi senza interruzioni, è consigliabile attivare Gemini Cloud Assist Investigations prima del 22 settembre 2025.
Log di Serverless per Apache Spark
Il logging è abilitato per impostazione predefinita in Serverless per Apache Spark e i log dei workload vengono conservati al termine di un workload. Serverless per Apache Spark raccoglie i log dei workload in Cloud Logging.
Puoi accedere ai log di Serverless per Apache Spark nella risorsa
Cloud Dataproc Batch in Esplora log.
Eseguire query sui log di Serverless per Apache Spark
Esplora log nella console Google Cloud fornisce un riquadro delle query per aiutarti a creare una query per esaminare i log dei carichi di lavoro batch. Ecco i passaggi da seguire per creare una query per esaminare i log del carico di lavoro batch:
- Il progetto attuale è selezionato. Puoi fare clic su Perfeziona ambito Progetto per selezionare un progetto diverso.
Definisci una query sui log batch.
Utilizza i menu dei filtri per filtrare un carico di lavoro batch.
In Tutte le risorse, seleziona la risorsa Batch Cloud Dataproc.
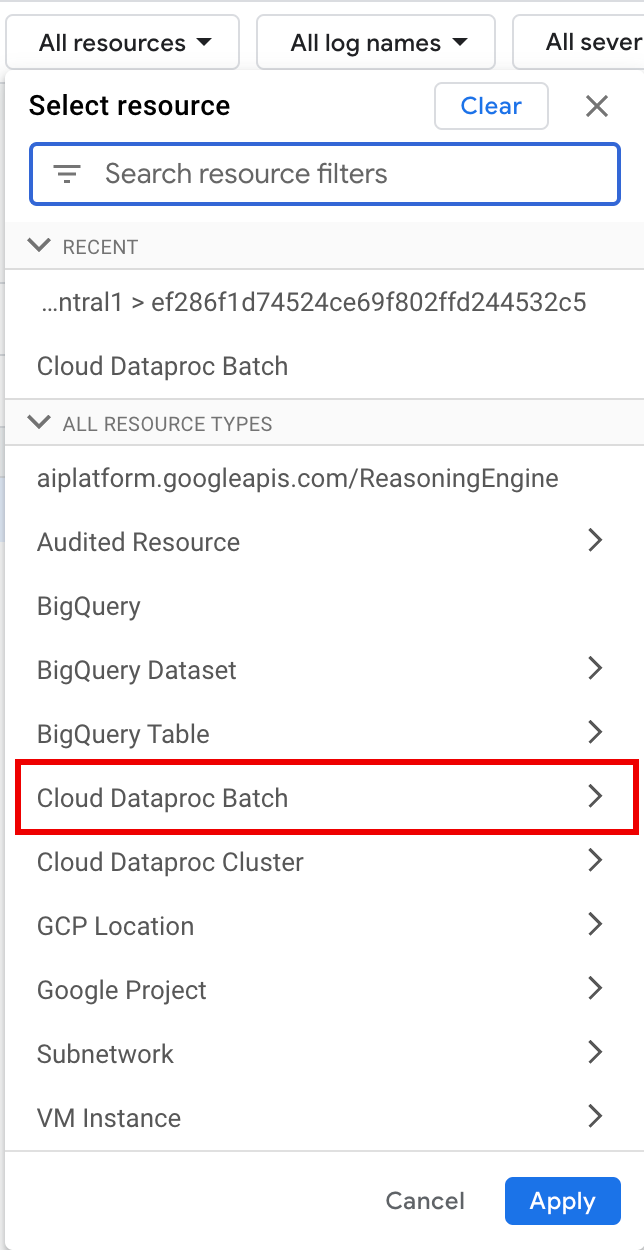
Nel riquadro Seleziona risorsa, seleziona il batch LOCATION, quindi l'ID BATCH. Questi parametri batch sono elencati nella pagina Batch di Dataproc nella console Google Cloud .
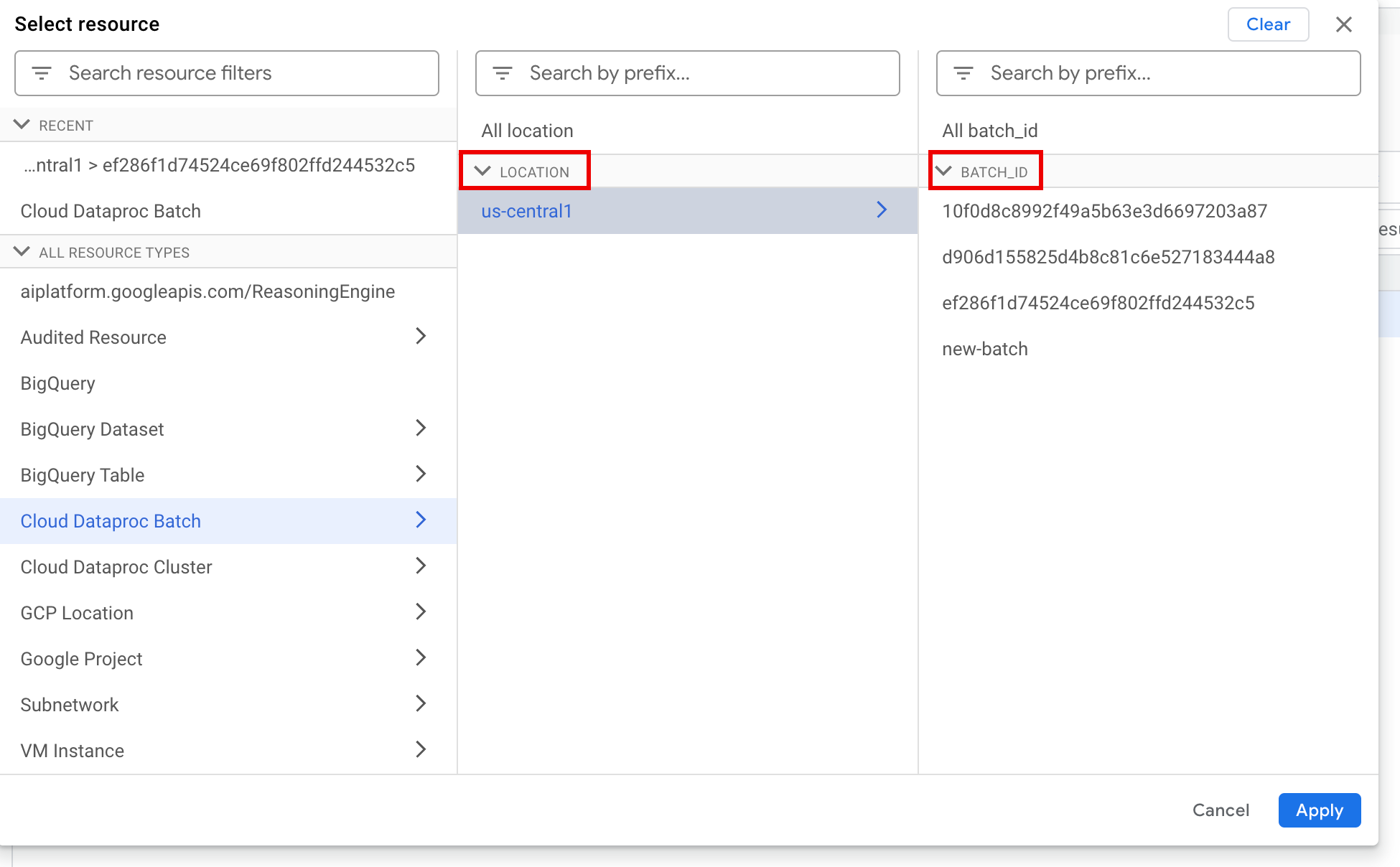
Fai clic su Applica.
Nella sezione Seleziona nomi log, inserisci
dataproc.googleapis.comnella casella Cerca nomi log per limitare i tipi di log da interrogare. Seleziona uno o più nomi di file di log elencati.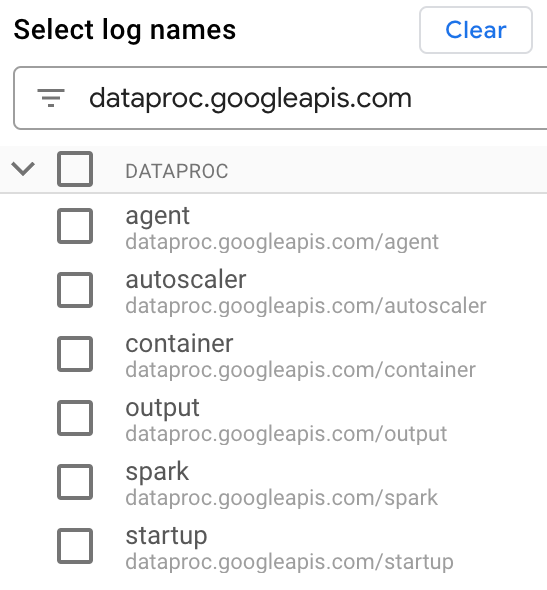
Utilizza l'editor di query per filtrare i log specifici della VM.
Specifica il tipo di risorsa e il nome della risorsa VM come mostrato nell'esempio seguente:
resource.type="cloud_dataproc_batch" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
- BATCH_UUID: l'UUID batch è elencato nella pagina Dettagli batch
della console Google Cloud , che si apre quando fai clic sull'ID batch nella pagina Batch.
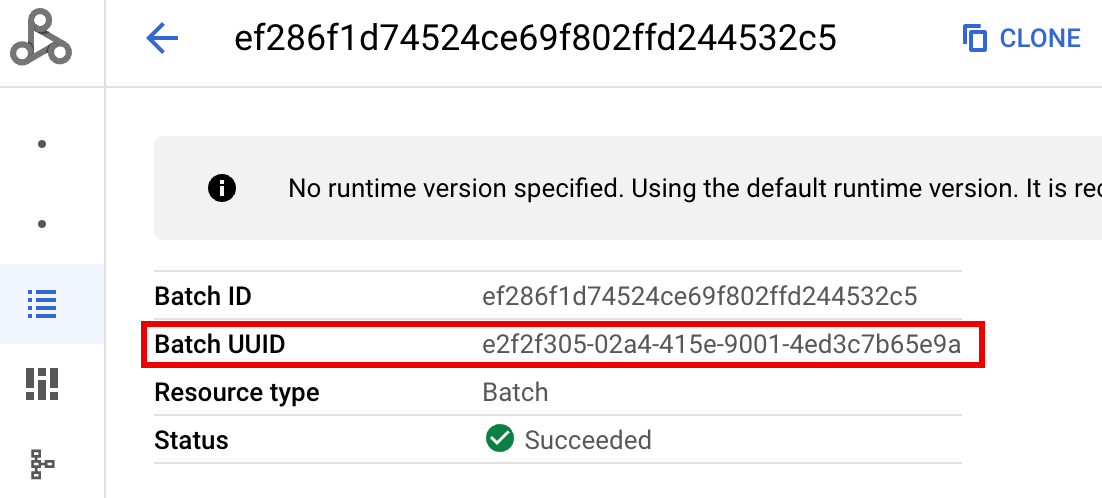
I log batch elencano anche l'UUID batch nel nome della risorsa VM. Ecco un esempio di un file driver.log batch:
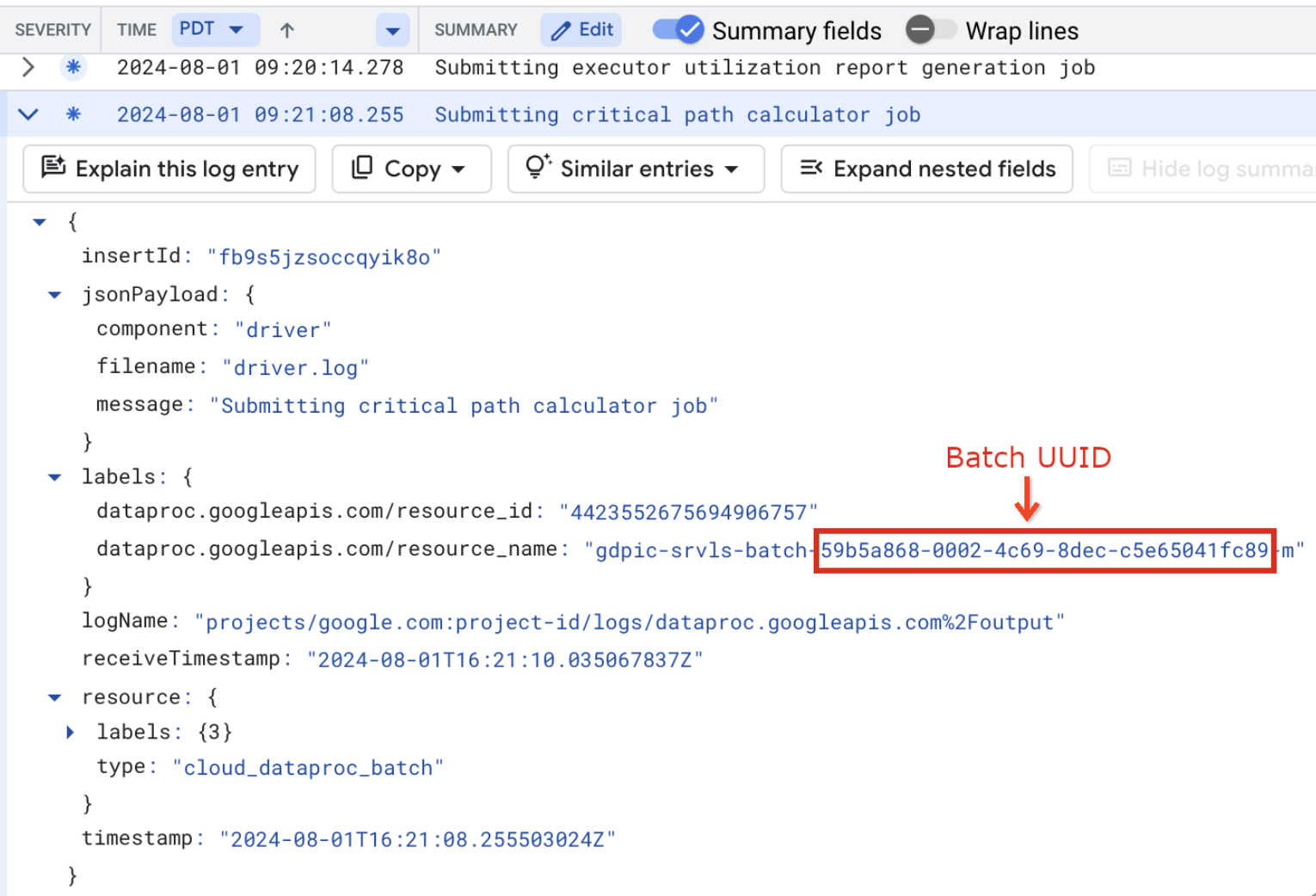
- BATCH_UUID: l'UUID batch è elencato nella pagina Dettagli batch
della console Google Cloud , che si apre quando fai clic sull'ID batch nella pagina Batch.
Fai clic su Esegui query.
Tipi di log e query di esempio di Serverless per Apache Spark
L'elenco seguente descrive i diversi tipi di log di Serverless for Apache Spark e fornisce query di esempio di Esplora log per ogni tipo di log.
dataproc.googleapis.com/output: Questo file di log contiene l'output del batch. Serverless per Apache Spark trasmette l'output batch allo spazio dei nomioutpute imposta il nome file suJOB_ID.driver.log.Query di esempio di Esplora log per i log di output:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Foutput"
dataproc.googleapis.com/spark: lo spazio dei nomisparkaggrega i log di Spark per i daemon e gli executor in esecuzione sulle VM master e worker del cluster Dataproc. Ogni voce di log include un'etichetta del componentemaster,workeroexecutorper identificare l'origine del log, come segue:executor: Log degli esecutori di codice utente. In genere, si tratta di log distribuiti.master: log del master di Spark standalone Resource Manager, simili ai log di Dataproc su Compute Engine YARNResourceManager.worker: log del worker di Spark standalone Resource Manager, simili ai log di Dataproc su Compute Engine YARNNodeManager.
Query di esempio di Esplora log per tutti i log nello spazio dei nomi
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark"
Query di esempio di Esplora log per i log dei componenti autonomi di Spark nello spazio dei nomi
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark" jsonPayload.component="COMPONENT"
dataproc.googleapis.com/startup: lo spazio dei nomistartupinclude i log di avvio batch (cluster). Sono inclusi tutti i log degli script di inizializzazione. I componenti sono identificati dall'etichetta, ad esempio:startup-script[855]: ... activate-component-spark[3050]: ... enable spark-worker
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fstartup" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
dataproc.googleapis.com/agent: lo spazio dei nomiagentaggrega i log dell'agente Dataproc. Ogni voce di log include l'etichetta del nome file che identifica l'origine del log.Query di esempio di Esplora log per i log dell'agente generati da una VM worker specificata:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fagent" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
dataproc.googleapis.com/autoscaler: lo spazio dei nomiautoscaleraggrega i log del gestore della scalabilità automatica di Serverless per Apache Spark.Query di esempio di Esplora log per i log dell'agente generati da una VM worker specificata:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fautoscaler" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
Per saperne di più, consulta Log di Dataproc.
Per informazioni sui log di controllo di Serverless per Apache Spark, consulta Audit logging di Dataproc.
Metriche dei carichi di lavoro
Serverless per Apache Spark fornisce metriche batch e Spark che puoi visualizzare da Metrics Explorer o dalla pagina Dettagli batch nella console Google Cloud .
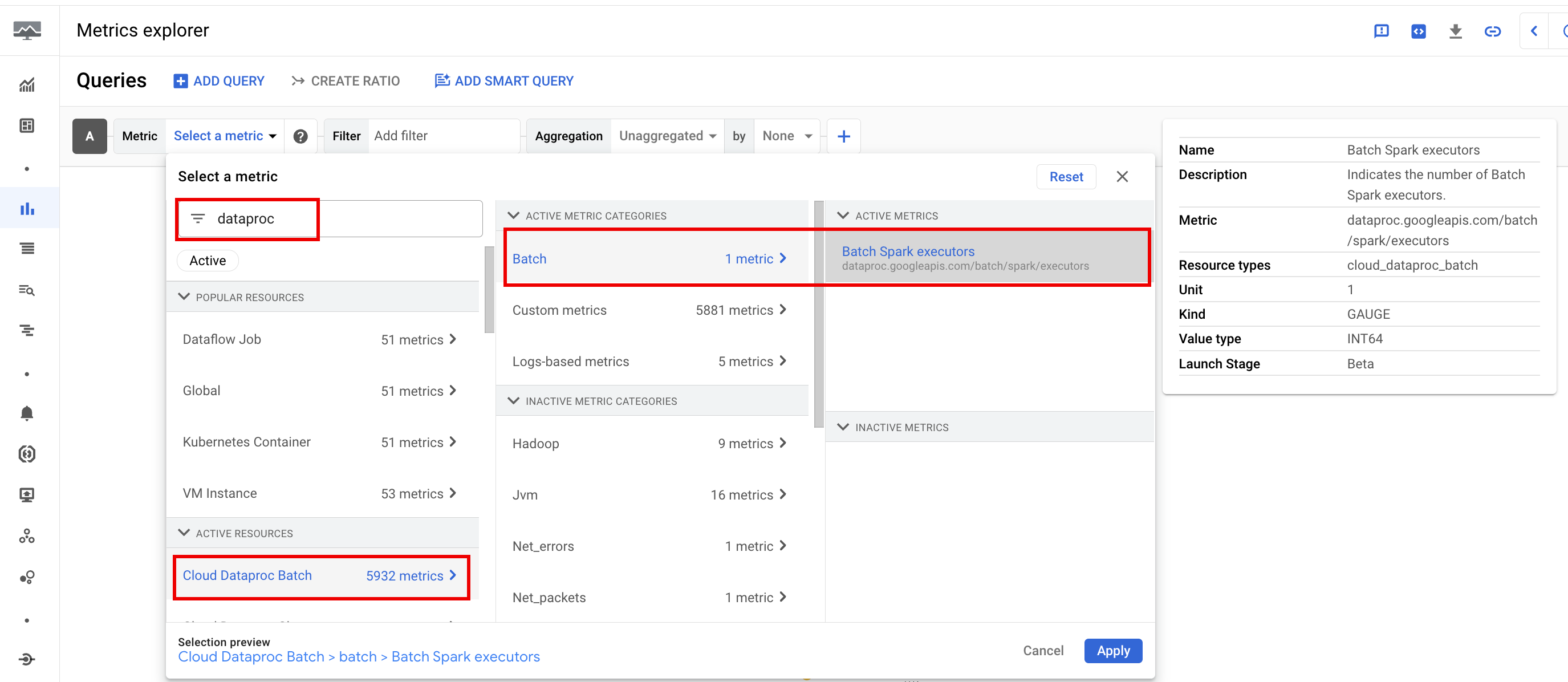
Metriche batch
Le metriche delle risorse batch di Dataproc forniscono informazioni sulle risorse batch, ad esempio il numero di esecutori batch. Le metriche batch hanno il prefisso
dataproc.googleapis.com/batch.
Metriche Spark
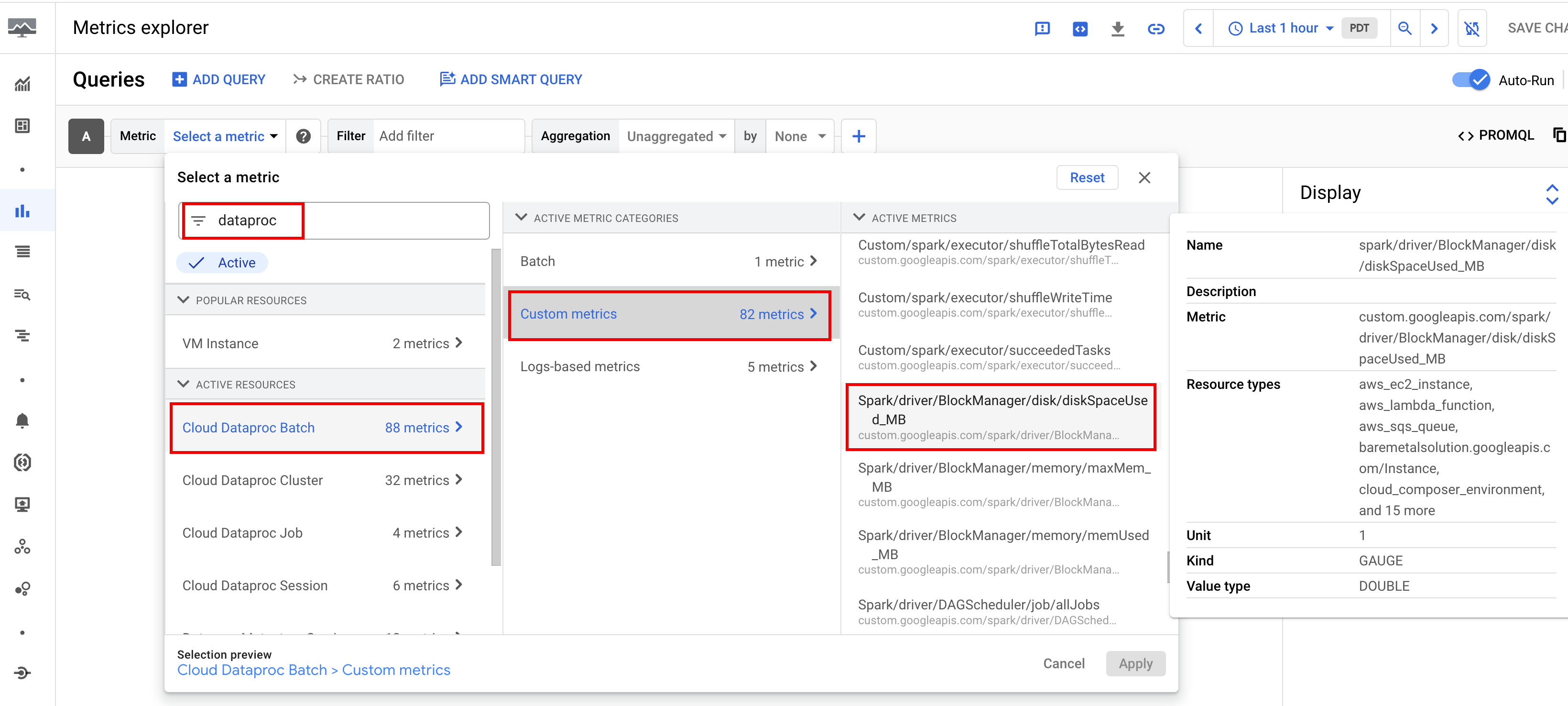
Per impostazione predefinita, Serverless per Apache Spark abilita la raccolta delle metriche Spark disponibili, a meno che tu non utilizzi le proprietà di raccolta delle metriche Spark per disattivare o sostituire la raccolta di una o più metriche Spark.
Le metriche Spark disponibili
includono le metriche del driver e dell'executor Spark e le metriche di sistema. Le metriche Spark disponibili hanno il prefisso
custom.googleapis.com/.
Configurare avvisi sulle metriche
Puoi creare avvisi per le metriche Dataproc per ricevere una notifica dei problemi relativi al workload.
Creare grafici
Puoi creare grafici che visualizzano le metriche del workload utilizzando
Esplora metriche nella
consoleGoogle Cloud . Ad esempio, puoi
creare un grafico per visualizzare disk:bytes_used e poi filtrare per batch_id.
Cloud Monitoring
Il monitoraggio utilizza i metadati e le metriche del workload per fornire informazioni dettagliate sull'integrità e sulle prestazioni dei workload Serverless for Apache Spark. Le metriche del workload includono le metriche Spark, batch e delle operazioni.
Puoi utilizzare Cloud Monitoring nella console Google Cloud per esplorare le metriche, aggiungere grafici, creare dashboard e creare avvisi.
Creare dashboard
Puoi creare una dashboard per monitorare i workload utilizzando le metriche di più progetti e di diversi prodotti Google Cloud . Per saperne di più, vedi Creare e gestire dashboard personalizzate.
Server di cronologia permanente
Serverless for Apache Spark crea le risorse di calcolo necessarie per eseguire un carico di lavoro, esegue il carico di lavoro su queste risorse e poi le elimina al termine del carico di lavoro. Le metriche e gli eventi del workload non vengono mantenuti dopo il completamento di un workload. Tuttavia, puoi utilizzare un server di cronologia permanente (PHS) per conservare la cronologia delle applicazioni dei carichi di lavoro (log degli eventi) in Cloud Storage.
Per utilizzare un PHS con un carico di lavoro batch:
Specifica il tuo PHS quando invii un carico di lavoro.
Utilizza il Component Gateway per connetterti a PHS e visualizzare i dettagli dell'applicazione, le fasi dello scheduler, i dettagli a livello di attività e le informazioni su ambiente ed executor.
Ottimizzazione automatica
- Attiva l'ottimizzazione automatica per Serverless per Apache Spark:puoi attivare l'ottimizzazione automatica per Serverless per Apache Spark quando invii ogni workload batch Spark ricorrente utilizzando la console Google Cloud , gcloud CLI o l'API Dataproc.
Console
Per attivare l'ottimizzazione automatica su ogni carico di lavoro batch Spark ricorrente, segui questi passaggi:
Nella console Google Cloud , vai alla pagina Batch di Dataproc.
Per creare un workload batch, fai clic su Crea.
Nella sezione Container, compila il nome del Cohort, che identifica il batch come parte di una serie di carichi di lavoro ricorrenti. L'analisi assistita da Gemini viene applicata al secondo e ai successivi carichi di lavoro inviati con questo nome di coorte. Ad esempio, specifica
TPCH-Query1come nome del coorte per un carico di lavoro pianificato che esegue una query TPC-H giornaliera.Compila le altre sezioni della pagina Crea batch in base alle tue esigenze, poi fai clic su Invia. Per ulteriori informazioni, consulta Inviare un carico di lavoro batch.
gcloud
Esegui il seguente comando gcloud CLI
gcloud dataproc batches submit
localmente in una finestra del terminale o in Cloud Shell
per attivare l'ottimizzazione automatica su ogni workload batch Spark ricorrente:
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ other arguments ...
Sostituisci quanto segue:
- COMMAND: il tipo di workload Spark, ad esempio
Spark,PySpark,Spark-SqloSpark-R. - REGION: la regione in cui verrà eseguito il carico di lavoro.
- COHORT: il nome della coorte, che identifica il batch come parte di una serie di carichi di lavoro ricorrenti.
L'analisi assistita da Gemini viene applicata al secondo e ai successivi carichi di lavoro inviati
con questo nome di coorte. Ad esempio, specifica
TPCH Query 1come nome della coorte per un carico di lavoro pianificato che esegue una query TPC-H giornaliera.
API
Includi il nome RuntimeConfig.cohort in una richiesta batches.create per abilitare l'ottimizzazione automatica su ogni carico di lavoro batch Spark ricorrente. L'ottimizzazione automatica viene applicata al secondo e ai successivi carichi di lavoro inviati con questo nome di coorte. Ad esempio, specifica TPCH-Query1 come nome della coorte per un carico di lavoro pianificato che esegue una query TPC-H giornaliera.
Esempio:
...
runtimeConfig:
cohort: TPCH-Query1
...