En este instructivo, se propone una estrategia de recuperación ante desastres y birregionales de continuidad empresarial mediante Dataproc Metastore. En el instructivo, se usan buckets birregionales para almacenar conjuntos de datos de Hive y exportaciones de metadatos de Hive.
Dataproc Metastore es un servicio de almacén de metadatos nativo de OSS completamente administrado, con alta disponibilidad, de reparación automática y con ajuste de escala automático que simplifica mucho la administración de metadatos técnicos. Nuestro servicio administrado se basa en Apache Hive Metastore y sirve como un componente crítico para los data lakes empresariales.
Este instructivo está diseñado para los clientes de Google Cloud que requieren alta disponibilidad para sus datos y metadatos de Hive. Usa Cloud Storage para el almacenamiento, Dataproc para el procesamiento y Dataproc Metastore (DPMS), un servicio de Hive Metastore completamente administrado en Google Cloud. En el instructivo, también se presentan dos formas diferentes de organizar las conmutaciones por error: una usa Cloud Run y Cloud Scheduler, la otra usa Cloud Composer.
El enfoque de la birregión que se usa en el instructivo tiene las siguientes ventajas y desventajas:
Ventajas
- Los buckets birregionales tienen redundancia geográfica.
- Los buckets multirregionales tienen un ANS de disponibilidad del 99.95%, en comparación con los buckets de una sola región del 99.9%.
- Los buckets birregionales tienen un rendimiento optimizado en dos regiones, mientras que los buckets de una sola región no tienen un buen rendimiento cuando se trabaja con recursos en otras regiones.
Desventajas
- Las escrituras de buckets birregionales no se replican de inmediato en ambas regiones.
- Los buckets birregionales tienen costos de almacenamiento más altos que los depósitos de una sola región.
Arquitectura de referencia
En los siguientes diagramas de arquitectura, se muestran los componentes que usas en este instructivo. En ambos diagramas, la X roja grande indica la falla de la región principal:
 Figura 1: Uso de Cloud Run y Cloud Scheduler
Figura 1: Uso de Cloud Run y Cloud Scheduler
 Figura 2: Uso de Cloud Composer
Figura 2: Uso de Cloud Composer
Los componentes de la solución y sus relaciones son los siguientes:
- Dos buckets birregionales de Cloud Storage: Crea un bucket para los datos de Hive y un bucket para las copias de seguridad periódicas de los metadatos de Hive. Crea ambos buckets birregionales de modo que usen las mismas regiones que los clústeres de Hadoop que acceden a los datos.
- Un almacén de metadatos de Hive con DPMS: crea este almacén de metadatos de Hive en la región principal (región A). La configuración del almacén de metadatos apunta al bucket de datos de Hive. Un clúster de Hadoop que usa Dataproc debe estar en la misma región que la instancia de DPMS a la que está conectado.
- Una segunda instancia de DPMS: crea una segunda instancia de DPMS en tu región en espera (región B) a fin de prepararte para una falla en toda la región. Luego, importas el archivo de exportación
hive.sqlmás reciente del bucket de exportación al DPMS en espera. También debes crear un clúster de Dataproc en tu región en espera y adjuntarlo a tu instancia de DPMS en espera. Por último, en una situación de recuperación ante desastres, redireccionas las aplicaciones cliente de tu clúster de Dataproc en la región A a tu clúster de Dataproc en la región B. Una implementación de Cloud Run: crea una implementación de Cloud Run en la región A que exporta de forma periódica los metadatos de DPMS a un bucket de copia de seguridad de metadatos mediante Cloud Scheduler (como se muestra en la Figura 1). La exportación toma la forma de un archivo SQL que contiene un volcado completo de los metadatos de DPMS.
Si ya tienes un entorno de Cloud Composer, puedes organizar tus importaciones y exportaciones de metadatos de DPMS si ejecutas un DAG de Airflow en ese entorno (como se muestra en la Figura 2). Este uso de un DAG de Airflow estaría en lugar del método de Cloud Run mencionado antes.
Objetivos
- Configurar el almacenamiento birregionales para los datos de Hive y las copias de seguridad de Hive Metastore
- Implementar un Dataproc Metastore y un clúster de Dataproc en las regiones A y B
- Conmutar por error la implementación a la región B.
- Conmutar por error la implementación a la región A
- Crear copias de seguridad automáticas del almacén de metadatos de Hive.
- Organiza las exportaciones y las importaciones de metadatos a través de Cloud Run.
- Organizar las exportaciones y las importaciones de metadatos a través de Cloud Composer.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, and Dataproc Metastore APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, and Dataproc Metastore APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- En Cloud Shell, inicia una instancia de Cloud Shell.
Clona el repositorio de GitHub del instructivo:
git clone https://github.com/GoogleCloudPlatform/metastore-disaster-recovery.gitHabilita las siguientes Google Cloud APIs:
gcloud services enable dataproc.googleapis.com metastore.googleapis.comConfigura algunas variables de entorno:
export PROJECT=$(gcloud info --format='value(config.project)') export WAREHOUSE_BUCKET=${PROJECT}-warehouse export BACKUP_BUCKET=${PROJECT}-dpms-backups export DPMS_PRIMARY_REGION=us-central1 export DPMS_STANDBY_REGION=us-east1 export DPMS_PRIMARY_INSTANCE=dpms1 export DPMS_STANDBY_INSTANCE=dpms2 export HADOOP_PRIMARY=dataproc-cluster1 export HADOOP_STANDBY=dataproc-cluster2
Inicializa el entorno
Crea almacenamiento para datos de Hive y copias de seguridad de Hive Metastore
En esta sección, crearás buckets de Cloud Storage para alojar los datos de Hive y las copias de seguridad de Hive Metastore.
Crea almacenamiento de datos de Hive
En Cloud Shell, crea un bucket birregionales para alojar los datos de Hive:
gcloud storage buckets create gs://${WAREHOUSE_BUCKET} --location=NAM4Copia algunos datos de muestra en el bucket de datos de Hive:
gcloud storage cp gs://retail_csv gs://${WAREHOUSE_BUCKET}/retail --recursive
Crea almacenamiento para copias de seguridad de metadatos
En Cloud Shell, crea un bucket birregionales para alojar las copias de seguridad de metadatos de DPMS:
gcloud storage buckets create gs://${BACKUP_BUCKET} --location=NAM4
Implementa recursos de procesamiento en la región principal
En esta sección, implementarás todos los recursos de procesamiento en la región principal, incluida la instancia de DPMS y el clúster de Dataproc. También debes propagar Dataproc Metastore con metadatos de muestra.
Crea la instancia de DPMS
En Cloud Shell, crea la instancia de DPMS:
gcloud metastore services create ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --hive-metastore-version=3.1.2Este comando puede tardar varios minutos en completarse.
Establece el bucket de datos de Hive como el directorio de almacén predeterminado:
gcloud metastore services update ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --update-hive-metastore-configs="hive.metastore.warehouse.dir=gs://${PROJECT}- warehouse"Este comando puede tardar varios minutos en completarse.
Cree un clúster de Dataproc.
En Cloud Shell, crea un clúster de Dataproc y conéctalo a la instancia de DPMS:
gcloud dataproc clusters create ${HADOOP_PRIMARY} \ --dataproc-metastore=projects/${PROJECT}/locations/${DPMS_PRIMARY_REGION}/services/${DPMS_PRIMARY_INSTANCE} \ --region=${DPMS_PRIMARY_REGION} \ --image-version=2.0Especifica la imagen del clúster como la versión 2.0, que es la última versión disponible desde junio de 2021. También es la primera versión compatible con DPMS.
Propaga el metastore
En Cloud Shell, actualiza el
retail.hqlde muestra que se proporciona en el repositorio de este instructivo con el nombre del bucket de datos de Hive:sed -i -- 's/${WAREHOUSE_BUCKET}/'"$WAREHOUSE_BUCKET"'/g' retail.hqlEjecuta las consultas que contiene el archivo
retail.hqlpara crear las definiciones de tablas en el almacén de metadatos:gcloud dataproc jobs submit hive \ --cluster=${HADOOP_PRIMARY} \ --region=${DPMS_PRIMARY_REGION} \ --file=retail.hqlVerifica que se hayan creado las definiciones de tabla correctamente:
gcloud dataproc jobs submit hive \ --cluster=${HADOOP_PRIMARY} \ --region=${DPMS_PRIMARY_REGION} \ --execute=" desc departments; desc categories; desc products; desc order_items; desc orders; desc customers; select count(*) as num_departments from departments; select count(*) as num_categories from categories; select count(*) as num_products from products; select count(*) as num_order_items from order_items; select count(*) as num_orders from orders; select count(*) as num_customers from customers; "El resultado se parece al siguiente:
+------------------+------------+----------+ | col_name | data_type | comment | +------------------+------------+----------+ | department_id | int | | | department_name | string | | +------------------+------------+----------+
El resultado también contiene la cantidad de elementos en cada tabla, por ejemplo:
+----------------+ | num_customers | +----------------+ | 12435 | +----------------+
Conmuta por error a la región en espera
En esta sección, se proporcionan los pasos para realizar una conmutación por error desde la región principal (región A) hasta la región en espera (región B).
En Cloud Shell, exporta los metadatos de la instancia de DPMS principal al bucket de copias de seguridad:
gcloud metastore services export gcs ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --destination-folder=gs://${BACKUP_BUCKET}El resultado se parece al siguiente:
metadataManagementActivity: metadataExports: ‐ databaseDumpType: MYSQL destinationGcsUri: gs://qa01-300915-dpms-backups/hive-export-2021-05-04T22:21:53.288Z endTime: '2021-05-04T22:23:35.982214Z' startTime: '2021-05-04T22:21:53.308534Z' state: SUCCEEDEDTen en cuenta el valor del atributo
destinationGcsUri. Este atributo almacena la copia de seguridad que creaste.Crea una instancia de DPMS nueva en la región en espera:
gcloud metastore services create ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --hive-metastore-version=3.1.2Establece el bucket de datos de Hive como el directorio de almacén predeterminado:
gcloud metastore services update ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --update-hive-metastore-configs="hive.metastore.warehouse.dir=gs://${PROJECT}-warehouse"Recupera la ruta de acceso de la copia de seguridad de metadatos más reciente:
IMPORT_DIR=`gcloud storage ls gs://${BACKUP_BUCKET} | sort -k 1 | tail -1` IMPORT_SQL="${IMPORT_DIR}hive.sql" echo ${IMPORT_SQL}Importa los metadatos con copia de seguridad en la nueva instancia de Dataproc Metastore:
gcloud metastore services import gcs ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --dump-type=mysql \ --database-dump=${IMPORT_SQL} \ --import-id=import-$(date +"%Y-%m-%d-%H-%M-%S")Crea un clúster de Dataproc en la región en espera (región B):
gcloud dataproc clusters create ${HADOOP_STANDBY} \ --dataproc-metastore=projects/${PROJECT}/locations/${DPMS_STANDBY_REGION}/services/${DPMS_STANDBY_INSTANCE} \ --region=${DPMS_STANDBY_REGION} \ --image-version=2.0Verifica que los metadatos se hayan importado de forma correcta:
gcloud dataproc jobs submit hive \ --cluster ${HADOOP_STANDBY} \ --region ${DPMS_STANDBY_REGION} \ --execute "select count(*) as num_orders from orders;"El resultado de
num_orderses lo más importante para el instructivo. Se ve de la siguiente manera:+-------------+ | num_orders | +-------------+ | 68883 | +-------------+El Dataproc Metastore principal se ha convertido en el nuevo almacén de metadatos en espera, y el Dataproc Metastore en espera se ha convertido en el nuevo almacén de metadatos principal.
Actualiza las variables de entorno según estas nuevas funciones:
export DPMS_PRIMARY_REGION=us-east1 export DPMS_STANDBY_REGION=us-central1] export DPMS_PRIMARY_INSTANCE=dpms2 export DPMS_STANDBY_INSTANCE=dpms1 export HADOOP_PRIMARY=dataproc-cluster2 export HADOOP_STANDBY=dataproc-cluster1Verifica que puedas escribir en el nuevo Dataproc Metastore principal en la región B:
gcloud dataproc jobs submit hive \ --cluster ${DPMS_PRIMARY_INSTANCE} \ --region ${DPMS_PRIMARY_REGION} \ --execute "create view completed_orders as select * from orders where order_status = 'COMPLETE';" gcloud dataproc jobs submit hive \ --cluster ${HADOOP_PRIMARY} \ --region ${DPMS_PRIMARY_REGION} \ --execute "select * from completed_orders limit 5;"El resultado contiene lo siguiente:
+----------------------------+------------------------------+-------------------------------------+--------------------------------+ | completed_orders.order_id | completed_orders.order_date | completed_orders.order_customer_id | completed_orders.order_status | +----------------------------+------------------------------+-------------------------------------+--------------------------------+ | 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE | | 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE | | 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE | | 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE | | 15 | 2013-07-25 00:00:00.0 | 2568 | COMPLETE | +----------------------------+------------------------------+-------------------------------------+--------------------------------+
Se completó la conmutación por error. Ahora deberías redireccionar tus aplicaciones cliente al nuevo clúster principal de Dataproc en la región B mediante la actualización de tus archivos de configuración del cliente de Hadoop.
Conmuta por error a la región original
En esta sección, se proporcionan los pasos para volver a la región original (región A).
En Cloud Shell, exporta los metadatos de la instancia de DPMS:
gcloud metastore services export gcs ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --destination-folder=gs://${BACKUP_BUCKET}Recupera la ruta de acceso de la copia de seguridad de metadatos más reciente:
IMPORT_DIR=`gcloud storage ls gs://${BACKUP_BUCKET} | sort -k 1 | tail -1` IMPORT_SQL="${IMPORT_DIR}hive.sql" echo ${IMPORT_SQL}Importa los metadatos a la instancia de DPMS en espera en la región original (región A):
gcloud metastore services import gcs ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --dump-type=mysql \ --database-dump=${IMPORT_SQL} \ --import-id=import-$(date +"%Y-%m-%d-%H-%M-%S")Verifica que los metadatos se hayan importado de forma correcta:
gcloud dataproc jobs submit hive \ --cluster ${HADOOP_STANDBY} \ --region ${DPMS_STANDBY_REGION} \ --execute "select * from completed_orders limit 5;"Se muestra el siguiente resultado:
+----------------------------+------------------------------+-------------------------------------+--------------------------------+ | completed_orders.order_id | completed_orders.order_date | completed_orders.order_customer_id | completed_orders.order_status | +----------------------------+------------------------------+-------------------------------------+--------------------------------+ | 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE | | 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE | | 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE | | 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE | | 15 | 2013-07-25 00:00:00.0 | 2568 | COMPLETE | +----------------------------+------------------------------+-------------------------------------+--------------------------------+
El Dataproc Metastore principal y el Dataproc Metastore en espera cambiaron las funciones.
Actualiza las variables de entorno a estas nuevas funciones:
export DPMS_PRIMARY_REGION=us-central1 export DPMS_STANDBY_REGION=us-east1 export DPMS_PRIMARY_INSTANCE=dpms1 export DPMS_STANDBY_INSTANCE=dpms12 export HADOOP_PRIMARY=dataproc-cluster1 export HADOOP_STANDBY=dataproc-cluster2
La conmutación por error se completó. Ahora deberías redireccionar tus aplicaciones cliente al nuevo clúster principal de Dataproc en la región A mediante la actualización de tus archivos de configuración del cliente de Hadoop.
Crea copias de seguridad automáticas de metadatos
En esta sección, se describen dos métodos diferentes para automatizar las importaciones y las exportaciones de copias de seguridad de metadatos. El primer método, Opción 1: Cloud Run y Cloud Scheduler, usa Cloud Run y Cloud Scheduler. El segundo método, Opción 2: Cloud Composer, usa Cloud Composer. En ambos ejemplos, un trabajo de exportación crea una copia de seguridad de los metadatos del DPMS principal en la región A. Un trabajo de importación propaga el DPMS en espera en la región B desde la copia de seguridad.
Si ya tienes un clúster de Cloud Composer existente, debes considerar la Opción 2: Cloud Composer (suponiendo que tu clúster tiene suficiente capacidad de procesamiento). De lo contrario, dirígete a la Opción 1: Cloud Run y Cloud Scheduler. Esta opción usa un modelo de precios prepagos y es más económico que Cloud Composer, que requiere el uso de recursos de procesamiento persistentes.
Opción 1: Cloud Run y Cloud Scheduler
En esta sección, se muestra cómo usar Cloud Run y Cloud Scheduler para automatizar las exportaciones de importaciones de metadatos de DPMS.
Servicios de Cloud Run
En esta sección, se muestra cómo compilar dos servicios de Cloud Run para ejecutar los trabajos de importación y exportación de metadatos.
En Cloud Shell, habilita las APIs de Cloud Run, Cloud Scheduler, Cloud Build y App Engine:
gcloud services enable run.googleapis.com cloudscheduler.googleapis.com cloudbuild.googleapis.com appengine.googleapis.comHabilita la API de App Engine porque el servicio de Cloud Scheduler requiere App Engine.
Compila la imagen de Docker con el Dockerfile proporcionado:
cd metastore-disaster-recovery gcloud builds submit --tag gcr.io/$PROJECT/dpms_drImplementa la imagen de contenedor en un servicio de Cloud Run en la región principal (región A). Esta implementación es responsable de crear las copias de seguridad de metadatos del almacén de metadatos principal:
gcloud run deploy dpms-export \ --image gcr.io/${PROJECT}/dpms_dr \ --region ${DPMS_PRIMARY_REGION} \ --platform managed \ --update-env-vars DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE},DPMS_PRIMARY_INSTANCE=${DPMS_PRIMARY_INSTANCE},DPMS_PRIMARY_REGION=${DPMS_PRIMARY_REGION} \ --allow-unauthenticated \ --timeout=10mDe forma predeterminada, una solicitud de servicio de Cloud Run agota el tiempo de espera después de 5 minutos. Para garantizar que todas las solicitudes tengan tiempo suficiente para completarse con éxito, la muestra de código anterior extiende el valor de tiempo de espera a 10 minutos como mínimo.
Recupera la URL de implementación del servicio de Cloud Run:
EXPORT_RUN_URL=$(gcloud run services describe dpms-export --platform managed --region ${DPMS_PRIMARY_REGION} --format ` "value(status.address.url)") echo ${EXPORT_RUN_URL}Crea un segundo servicio de Cloud Run en la región en espera (región B). Este servicio es responsable de importar las copias de seguridad de metadatos de
BACKUP_BUCKETal almacén de datos en espera:gcloud run deploy dpms-import \ --image gcr.io/${PROJECT}/dpms_dr \ --region ${DPMS_STANDBY_REGION} \ --platform managed \ --update-env-vars DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE} \ --allow-unauthenticated \ --timeout=10mRecupera la URL de implementación del segundo servicio de Cloud Run:
IMPORT_RUN_URL=$(gcloud run services describe dpms-import --platform managed --region ${REGION_B} --format "value(status.address.url)") echo ${IMPORT_RUN_URL}
Programación de trabajos
En esta sección, se muestra cómo usar Cloud Scheduler para activar los dos servicios de Cloud Run.
En Cloud Shell, crea una aplicación de App Engine, que Cloud Scheduler requiere:
gcloud app create --region=${REGION_A}Crea un trabajo de Cloud Scheduler para programar las exportaciones de metadatos del almacén de metadatos principal:
gcloud scheduler jobs create http dpms-export \ --schedule "*/15 * * * *" \ --http-method=post \ --uri=${EXPORT_RUN_URL}/export\
El trabajo de Cloud Scheduler realiza una solicitud http al servicio de Cloud Run cada 15 minutos. El servicio de Cloud Run ejecuta una aplicación de Flask en contenedores con una función de importación y exportación. Cuando se activa la función de exportación, se exportan los metadatos a Cloud Storage mediante el comando gcloud metastore services export.
En general, si tus trabajos de Hadoop escriben con frecuencia en Hive Metastore, te recomendamos que hagas una copia de seguridad de tu almacén de metadatos a menudo. Una buena programación de copia de seguridad estaría en el rango de cada 15 minutos a 60 minutos.
Activa una ejecución de prueba del servicio de Cloud Run:
gcloud scheduler jobs run dpms-exportVerifica que Cloud Scheduler haya activado correctamente la operación de exportación de DPMS:
gcloud metastore operations list --location ${REGION_A}El resultado se parece al siguiente:
OPERATION_NAME LOCATION TYPE TARGET DONE CREATE_TIME DURATION ... operation-a520936204508-5v23bx4y23f60-920f0a0f-9c2b56b5 us-central1 update dpms1 True 2021-05-13T20:05:04 2M23S
Si el valor de
DONEesFalse, la exportación todavía está en curso. Para confirmar que la operación se completó, vuelve a ejecutar el comandogcloud metastore operations list --location ${REGION_A}hasta que el valor seaTrue.Obtén más información sobre los comandos
gcloud metastore operationsen la documentación de referencia.Crea un trabajo de Cloud Scheduler para programar las importaciones en el almacén de metadatos en espera (opcional):
gcloud scheduler jobs create http dpms-import \ --schedule "*/15 * * * *" \ --http-method=post \ --uri=${IMPORT_RUN_URL}/import
Este paso depende de los requisitos del objetivo de tiempo de recuperación (RTO).
Si deseas una espera activa para minimizar el tiempo de conmutación por error, debes programar este trabajo de importación. Actualiza el DPMS en espera cada 15 minutos.
Si una instancia en espera pasiva es suficiente para tus necesidades de RTO, puedes omitir este paso y también borrar el DPMS en espera y el clúster de Dataproc a fin de reducir aún más tu factura mensual general. Cuando realices una conmutación por error a la región en espera (región B), aprovisiona el DPMS en espera y el clúster de Dataproc, y ejecuta también un trabajo de importación. Debido a que los archivos de copia de seguridad se almacenan en un bucket birregionales se puede acceder a ellos incluso si la región principal (región A) falla.
Controla las conmutaciones por error
Una vez que hayas conmutado por error a la región B, debes aplicar los siguientes pasos para conservar tus requisitos de recuperación ante desastres y proteger tu infraestructura contra una posible falla en la región B:
- Detén tus trabajos existentes de Cloud Scheduler.
- Actualiza la región de DPMS de la instancia principal a la región B (
us-east1). - Actualiza la región de DPMS en espera a la región A (
us-central1). - Actualiza la instancia principal de DPMS a
dpms2. - Actualiza la instancia en espera de DPMS a
dpms1. - Vuelve a implementar los servicios de Cloud Run según las variables actualizadas.
- Crea trabajos de Cloud Scheduler nuevos que apunten a tus servicios de Cloud Run nuevos.
En los pasos necesarios de la lista anterior, se repiten muchos pasos de las secciones anteriores, solo con ajustes menores (como intercambiar los nombres de región). Usa la información de la Opción 1: Cloud Run y Cloud Scheduler para completar este trabajo obligatorio.
Opción 2: Cloud Composer
En esta sección, se muestra cómo usar Cloud Composer para ejecutar los trabajos de importación y exportación dentro de un único grafo acíclico dirigido (DAG) por Airflow.
En Cloud Shell, habilita la API de Cloud Composer:
gcloud services enable composer.googleapis.comCrea un entorno de Cloud Composer:
export COMPOSER_ENV=comp-env gcloud beta composer environments create ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --image-version composer-1.17.0-preview.1-airflow-2.0.1 \ --python-version 3- La imagen
composer-1.17.0-preview.1-airflow-2.0.1de Composer es la versión más reciente desde su publicación. - Los entornos de Composer solo pueden usar una versión principal de Python. Se seleccionó Python 3 porque tiene problemas de compatibilidad.
- La imagen
Configura el entorno de Cloud Composer con las siguientes variables de entorno:
gcloud composer environments update ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --update-env-variables=DPMS_PRIMARY_REGION=${DPMS_PRIMARY_REGION},DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_PRIMARY_INSTANCE=${DPMS_PRIMARY_INSTANCE},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE}Sube el archivo de DAG a tu entorno de Composer:
gcloud composer environments storage dags import \ --environment ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --source dpms_dag.pyRecupera la URL de Airflow:
gcloud composer environments describe ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --format "value(config.airflowUri)"En tu navegador, abre la URL que muestra el comando anterior.
Deberías ver una nueva entrada del DAG llamada
dpms_dag. Dentro de una sola ejecución, el DAG ejecuta una exportación, seguida de una importación. El DAG supone que el DPMS en espera siempre está activo. Si no necesitas una espera activa y solo deseas ejecutar la tarea de exportación, debes marcar como comentario todas las tareas relacionadas con la importación en el código (find_backup, wait_for_ready_status, current_ts,dpms_import).Haz clic en el ícono de flecha para activar el DAG y realizar una ejecución de prueba:
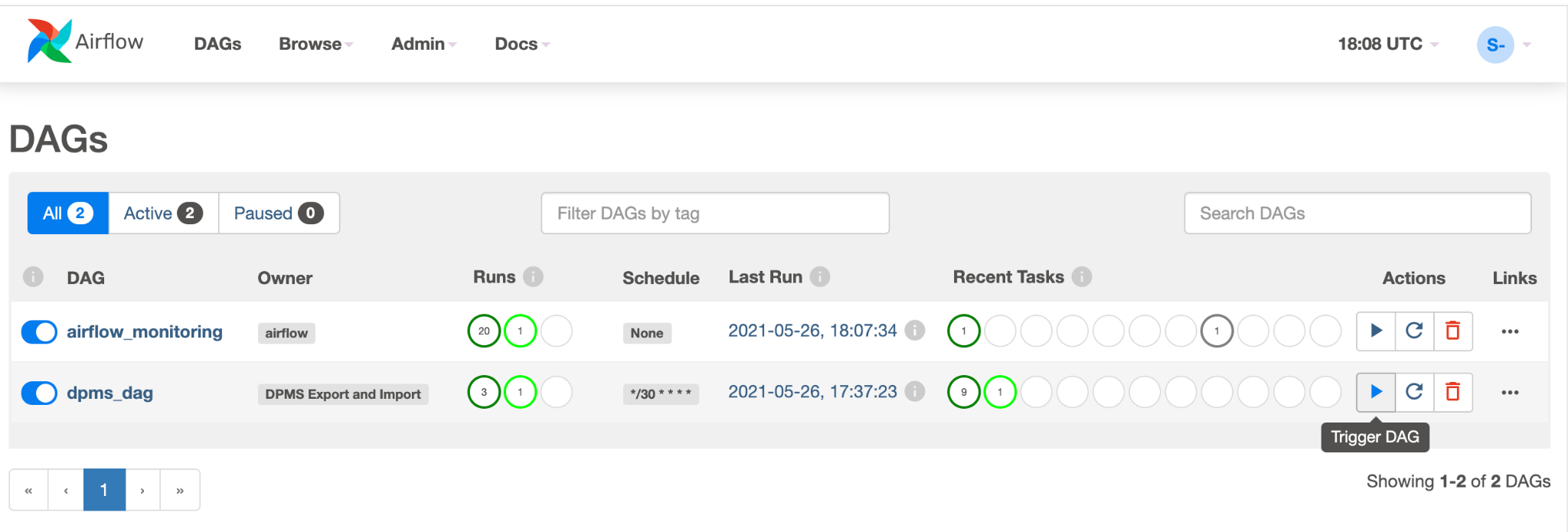
Haz clic en Vista de gráfico del DAG en ejecución para verificar el estado de cada tarea:
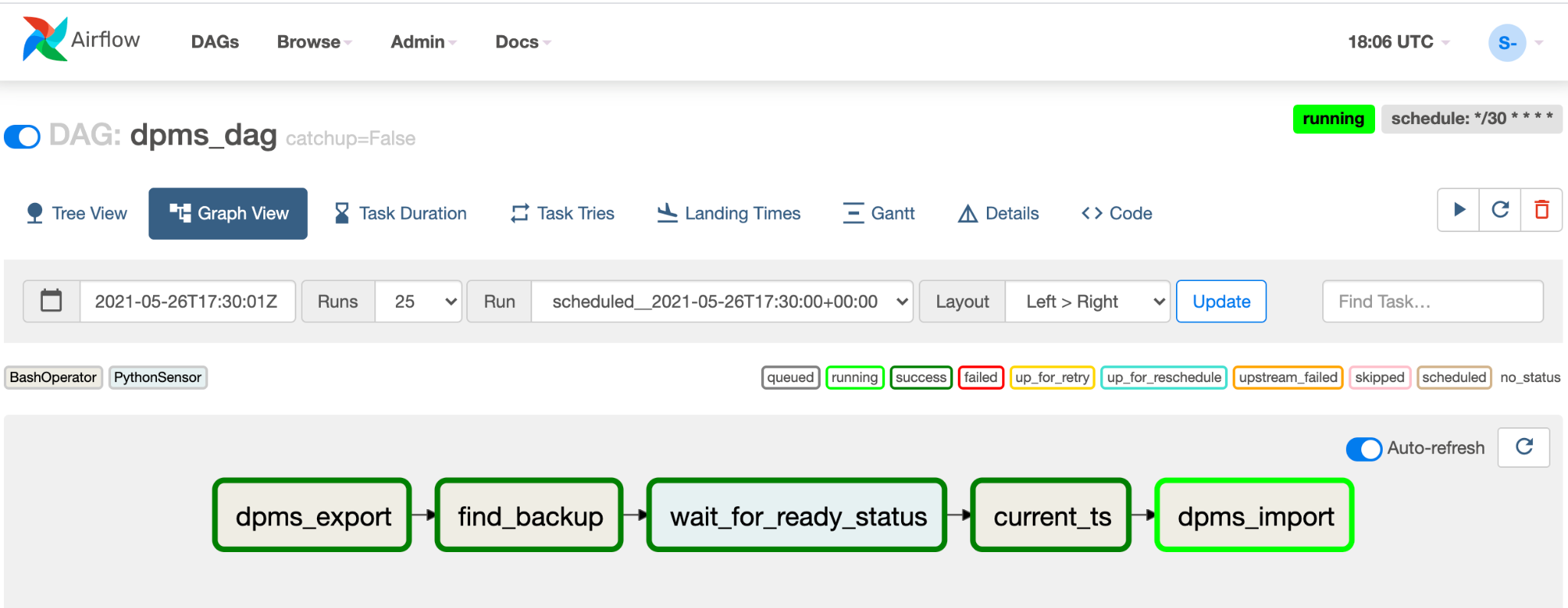
Una vez que hayas validado el DAG, permite que Airflow lo ejecute de forma periódica. El programa se establece en un intervalo de 30 minutos, pero se puede ajustar si cambias el parámetro
schedule_intervalen el código para cumplir con los requisitos de tiempo.
Controla las conmutaciones por error
Una vez que hayas conmutado por error a la región B, debes aplicar los siguientes pasos para conservar tus requisitos de recuperación ante desastres y proteger tu infraestructura contra una posible falla en la región B:
- Actualiza la región de DPMS de la instancia principal a la región B (
us-east1). - Actualiza la región de DPMS en espera a la región A (
us-central1). - Actualiza la instancia principal de DPMS a
dpms2. - Actualiza la instancia en espera de DPMS a
dpms1. - Crea un nuevo entorno de Cloud Composer en la región B (
us-east1). - Configura el entorno de Cloud Composer con las variables de entorno actualizadas.
- Importa el mismo DAG de Airflow
dpms_dagque antes a tu nuevo entorno de Cloud Composer.
En los pasos necesarios de la lista anterior, se repiten muchos pasos de las secciones anteriores, solo con ajustes menores (como intercambiar los nombres de región). Usa la información de la Opción 2: Cloud Composer para completar este trabajo obligatorio.
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
¿Qué sigue?
- Aprende a supervisar tu instancia de Dataproc Metastore
- Comprende cómo sincronizar tu almacén de metadatos de Hive con Data Catalog
- Obtén más información para desarrollar servicios de Cloud Run
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.