Die verwaltete Migration ist eine automatisierte Funktion, mit der Sie Daten aus einem selbstverwalteten Hive-Metastore zu einem Dataproc Metastore-Dienst migrieren können, ohne dass es zu längeren Ausfallzeiten kommt (auch als Flag Day bezeichnet).
Architektur der verwalteten Migration
Das folgende Diagramm zeigt die allgemeine Architektur einer verwalteten Migration.
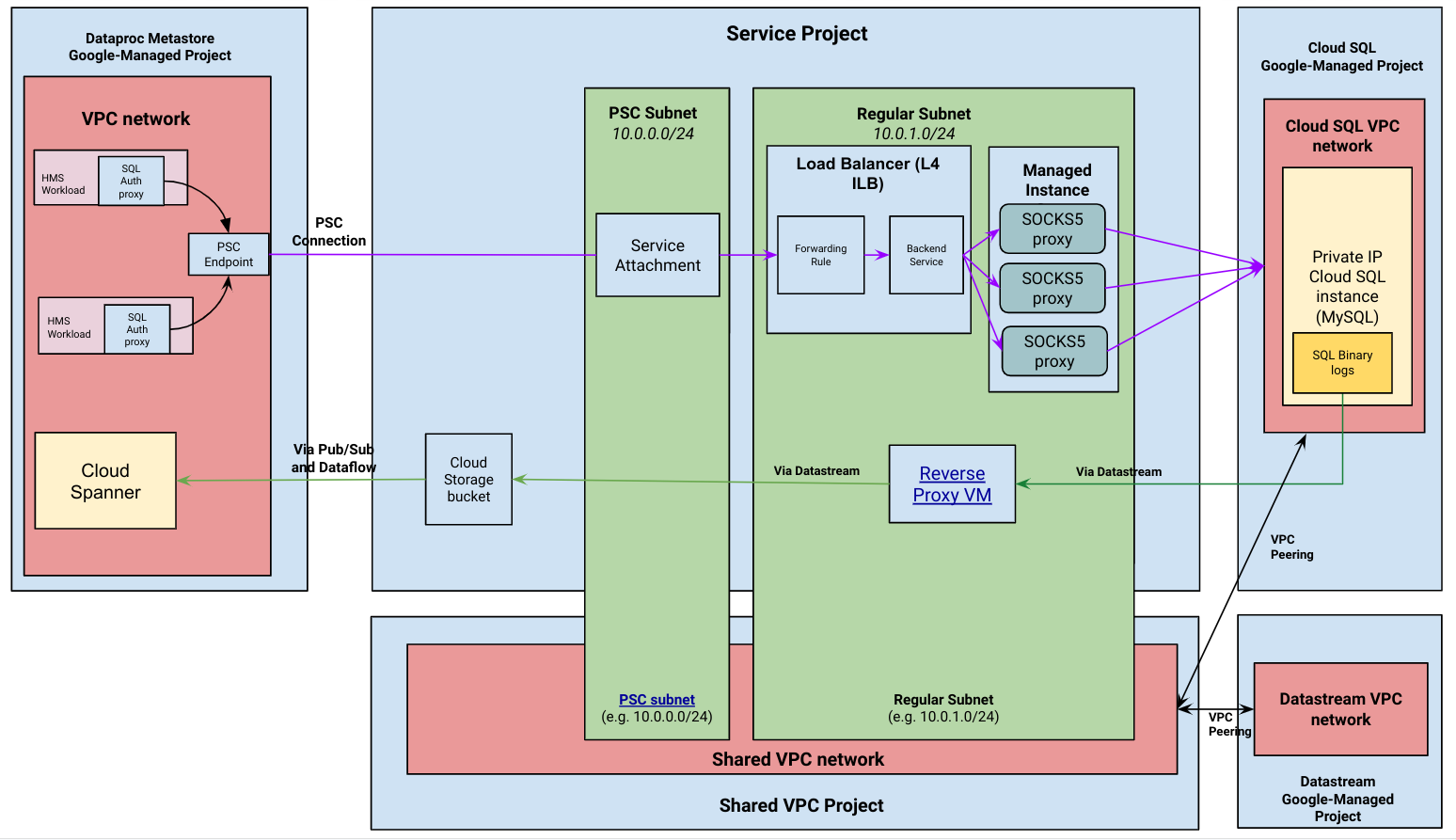
Ablauf der verwalteten Migration
Für eine verwaltete Migration durchläuft Ihr Dienst zwei Migrationsprozesse: Migration starten und Migration abschließen. Sie können eine Migration jederzeit mit dem Vorgang Migration abbrechen abbrechen. Es gibt auch eine Reihe von Betriebs-Befehlen, die Sie ausführen können, die aber für die Migration nicht erforderlich sind. Beispiele: list migrations oder delete migrations.
Während Ihr Dienst diesen Prozess durchläuft, wechselt er auch zwischen verschiedenen Migrationsstatus und Migrationsphasen. Diese Status und Phasen stellen die Prozesse dar, die im Hintergrund ablaufen. Der Status MIGRATING gibt beispielsweise an, dass Ihr Dienst aktiv Daten aus Ihrer Cloud SQL-Datenbank in Dataproc Metastore überträgt.
Migration starten
Dataproc Metastore stellt eine Verbindung zu Ihrer privaten Cloud SQL-Instanz her. Nachdem die Verbindung hergestellt wurde, verwendet Dataproc Metastore die Cloud SQL-Instanz als HMS-Backend-Datenbank (Hive Metastore). Sie bleibt auch während der Migration die Quelle der Wahrheit für Ihre Daten. Während der Migration werden weiterhin Metadaten in Cloud SQL gelesen und geschrieben.
Eine CDC-Pipeline (Change Data Capture) wird gestartet. Diese Pipeline sorgt dafür, dass die Cloud SQL-Instanz in Ihrem Projekt und Spanner im verwalteten Dataproc Metastore-Projekt synchronisiert werden. Das bedeutet, dass alle Änderungen an der HMS-Datenbank in der Cloud SQL-Instanz über Datastream erfasst und in die Dataproc Metastore-Spanner-Datenbank geschrieben werden.
Nachdem die Migration erfolgreich gestartet wurde, können Sie Datenarbeitslasten an Dataproc Metastore weiterleiten. Zu diesem Zeitpunkt ist Cloud SQL weiterhin die Quelle der Wahrheit für Ihre Daten.
Migration abschließen
Nachdem Sie Ihre Arbeitslasten zu Dataproc Metastore migriert haben, können Sie die Migration abschließen. Wenn ein vollständiger Migrationsprozess aufgerufen wird, passiert Folgendes:
- Dataproc Metastore wechselt in den schreibgeschützten Modus, bis die vollständige Migration abgeschlossen ist.
- Über den CDC-Stream werden alle Daten, die sich in der Übertragung befinden, an Dataproc Metastore übertragen.
- Dataproc Metastore stellt eine Verbindung zu Spanner her und trennt die Verbindung zu Cloud SQL. Dataproc Metastore ist jetzt die Source of Truth für Ihre HMS-Daten.
Proxy- und Pipeline-Überlegungen
Proxys
Dataproc Metastore verwendet einen Cloud SQL Auth-Proxy, der mit einem SOCKS5-Proxy verkettet ist, um eine Verbindung zu Ihrer Cloud SQL-Instanz mit privater IP-Adresse herzustellen. Die SOCKS5-Proxyserver werden über eine Dienstanhänge bereitgestellt, wie im vorherigen Architekturdiagramm dargestellt.
Für jede Migration ist ein dediziertes NAT-Subnetz erforderlich. Das liegt daran, dass ein NAT-Subnetz nicht mehr als einen Dienstanhang haben kann.
Um latenzbedingte Probleme zwischen Regionen zu vermeiden, geben Sie Subnetze an, die sich in derselben Region wie Ihre Cloud SQL-Instanz befinden, um den SOCKS5-Proxy zu hosten. Beispiel:
proxy_subnetundnat_subnet.
Change Data Capture-Pipeline
Die CDC-Pipeline verwendet VPC-Peering, um eine Verbindung zwischen Datastream und Cloud SQL mit privater IP-Adresse herzustellen.
Für jede Migration wird eine neue private Verbindung erstellt und eine neue Peering-Verbindung hergestellt.
Das VPC-Netzwerk, in dem die Cloud SQL-Instanz gehostet wird, hat so viele Peering-Verbindungen wie aktive Migrationen. Ihr VPC-Netzwerk muss genügend Kapazität für alle erforderlichen Peering-Verbindungen haben.