Ce document explique comment utiliser l'exploration Dataplex Universal Catalog pour détecter des anomalies dans un ensemble de données sur les transactions de vente au détail.
L'interface d'exploration des données, ou Explorer, permet aux analystes de données d'interroger et d'explorer de manière interactive de grands ensembles de données en temps réel. Explorer vous aide à dégager des insights à partir de vos données et vous permet d'interroger les données stockées dans Cloud Storage et BigQuery. Explore utilise une plate-forme Spark sans serveur. Vous n'avez donc pas besoin de gérer ni d'évoluer l'infrastructure sous-jacente.
Objectifs
Ce guide vous explique comment effectuer les tâches suivantes :
- Utilisez l'atelier Spark SQL d'Explore pour écrire et exécuter des requêtes Spark SQL.
- Utilisez un notebook JupyterLab pour afficher les résultats.
- Planifiez l'exécution récurrente de votre notebook pour surveiller les anomalies dans vos données.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, vous pouvez éviter de continuer à payer des frais en supprimant les ressources que vous avez créées. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Create or select a Google Cloud project.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
-
Make sure that billing is enabled for your Google Cloud project.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Create or select a Google Cloud project.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
-
Make sure that billing is enabled for your Google Cloud project.
Préparer les données pour l'exploration
Téléchargez le fichier Parquet,
retail_offline_sales_march.Créez un bucket Cloud Storage nommé
offlinesales_curatedcomme suit:- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Importez le fichier
offlinesales_march_parquetque vous avez téléchargé dans le bucket Cloud Storageofflinesales_curatedque vous avez créé en suivant la procédure décrite dans la section Importer un objet à partir d'un système de fichiers.Créez un lac Dataplex Universal Catalog et nommez-le
operationsen suivant la procédure décrite dans Créer un lac.Dans le lac
operations, ajoutez une zone et nommez-laprocurementen suivant la procédure décrite dans Ajouter une zone.Dans la zone
procurement, ajoutez le bucket Cloud Storageofflinesales_curatedque vous avez créé en tant qu'élément en suivant la procédure décrite dans Ajouter un élément.
Sélectionner la table à explorer
Dans la console Google Cloud , accédez à la page Explorer du catalogue universel Dataplex.
Dans le champ Lac, sélectionnez le lac
operations.Cliquez sur le lac
operations.Accédez à la zone
procurement, puis cliquez sur la table pour explorer ses métadonnées.Dans l'image suivante, la zone d'approvisionnement sélectionnée comporte une table appelée
Offline, qui contient les métadonnées suivantes:orderid,product,quantityordered,unitprice,orderdateetpurchaseaddress.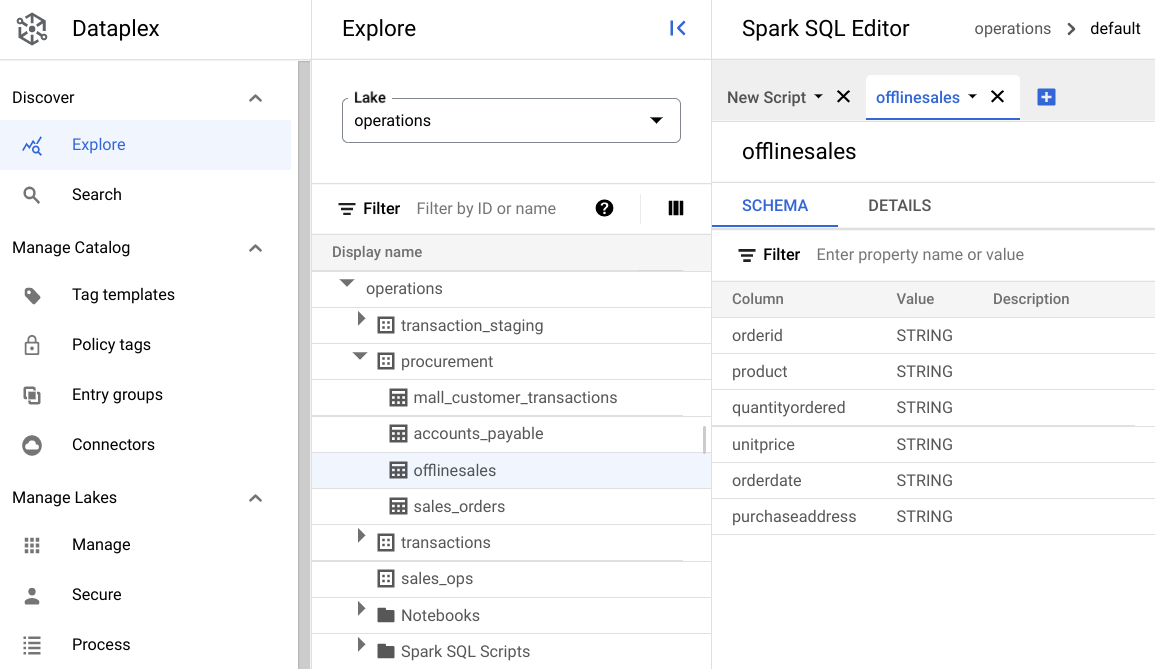
Dans l'Éditeur Spark SQL, cliquez sur Ajouter. Un script Spark SQL s'affiche.
Facultatif: Ouvrez le script en mode Vue d'onglets fractionnés pour afficher les métadonnées et le nouveau script côte à côte. Cliquez sur Plus dans l'onglet du nouveau script, puis sélectionnez Diviser l'onglet vers la droite ou Diviser l'onglet vers la gauche.
Explorer les données
Un environnement fournit des ressources de calcul sans serveur pour que vos requêtes et notebooks Spark SQL puissent s'exécuter dans un lac. Avant d'écrire des requêtes Spark SQL, créez un environnement dans lequel exécuter vos requêtes.
Explorez vos données à l'aide des requêtes SparkSQL suivantes. Dans l'Éditeur SparkSQL, saisissez la requête dans le volet Nouveau script.
Exemple de 10 lignes du tableau
Saisissez la requête suivante :
select * from procurement.offlinesales where orderid != 'orderid' limit 10;Cliquez sur Exécuter.
Obtenir le nombre total de transactions dans l'ensemble de données
Saisissez la requête suivante :
select count(*) from procurement.offlinesales where orderid!='orderid';Cliquez sur Exécuter.
Déterminer le nombre de types de produits différents dans l'ensemble de données
Saisissez la requête suivante :
select count(distinct product) from procurement.offlinesales where orderid!='orderid';Cliquez sur Exécuter.
Identifier les produits dont la valeur de transaction est élevée
Déterminez les produits qui génèrent une valeur de transaction élevée en répartissant les ventes par type de produit et par prix de vente moyen.
Saisissez la requête suivante :
select product,avg(quantityordered * unitprice) as avg_sales_amount from procurement.offlinesales where orderid!='orderid' group by product order by avg_sales_amount desc;Cliquez sur Exécuter.
L'image suivante affiche un volet Results qui utilise une colonne appelée product pour identifier les articles vendus avec des valeurs de transaction élevées, affichées dans la colonne avg_sales_amount.
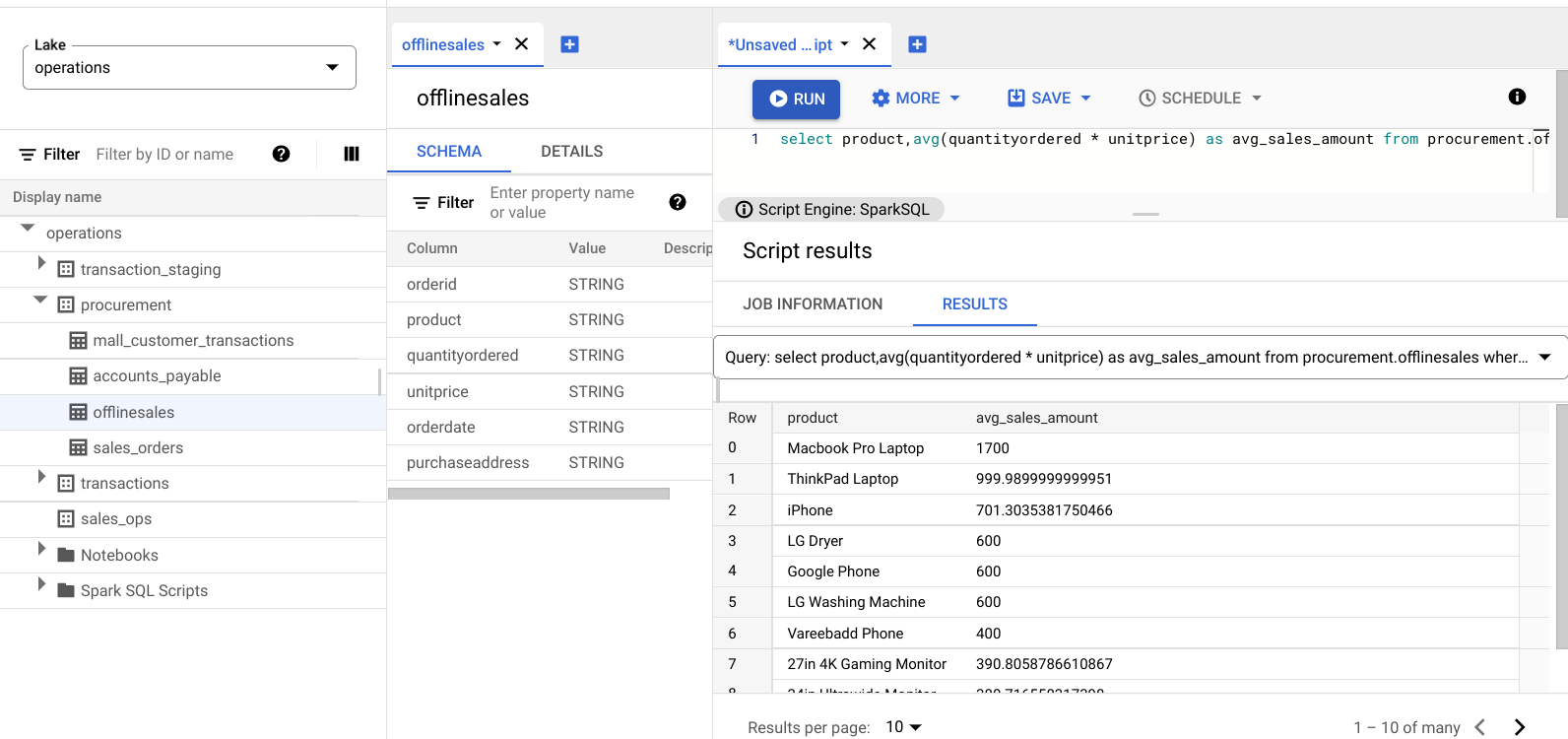
Détecter les anomalies à l'aide du coefficient de variation
La dernière requête a montré que les ordinateurs portables enregistrent un montant de transaction moyen élevé. La requête suivante montre comment détecter les transactions d'ordinateurs portables qui ne sont pas anormales dans l'ensemble de données.
La requête suivante utilise la métrique "coefficient de variation", rsd_value, pour trouver les transactions qui ne sont pas inhabituelles, où l'écart des valeurs est faible par rapport à la valeur moyenne. Un coefficient de variation inférieur indique moins d'anomalies.
Saisissez la requête suivante :
WITH stats AS ( SELECT product, AVG(quantityordered * unitprice) AS avg_value, STDDEV(quantityordered * unitprice) / AVG(quantityordered * unitprice) AS rsd_value FROM procurement.offlinesales GROUP BY product) SELECT orderid, orderdate, product, (quantityordered * unitprice) as sales_amount, ABS(1 - (quantityordered * unitprice)/ avg_value) AS distance_from_avg FROM procurement.offlinesales INNER JOIN stats USING (product) WHERE rsd_value <= 0.2 ORDER BY distance_from_avg DESC LIMIT 10Cliquez sur Exécuter.
Voir les résultats du script
Dans l'image suivante, un volet "Résultats" utilise une colonne appelée "Produit" pour identifier les articles vendus dont la valeur de transaction se situe dans le coefficient de variation de 0,2.
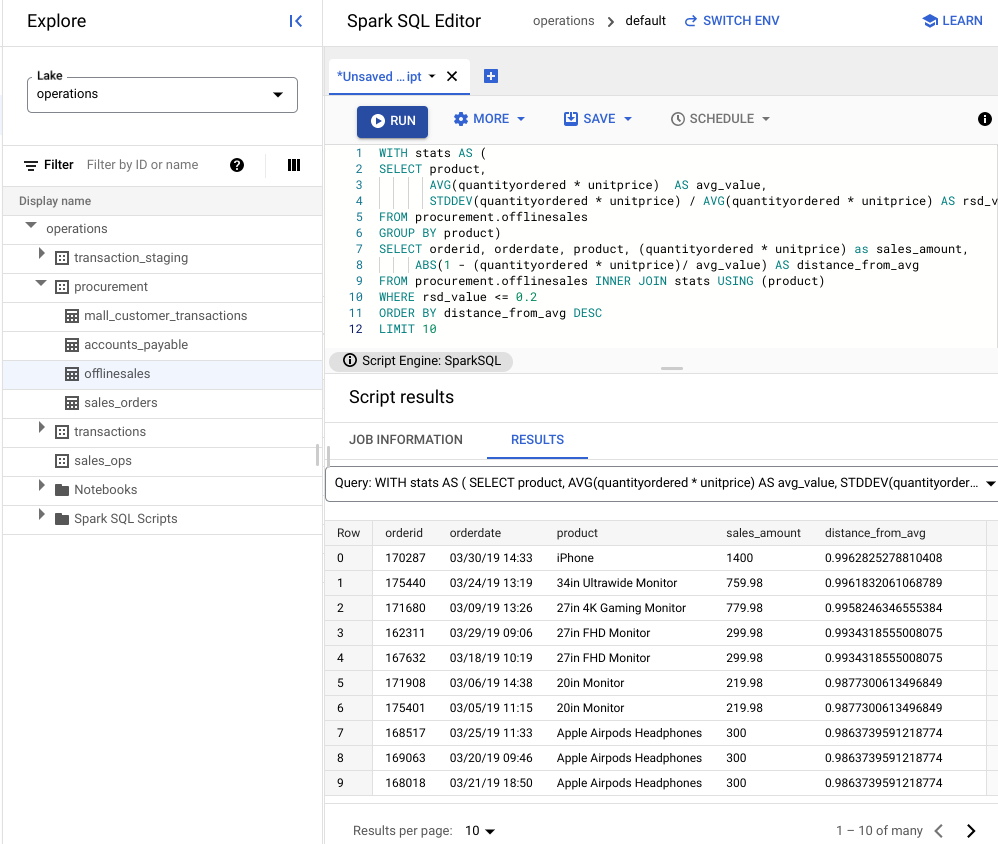
Visualiser les anomalies à l'aide d'un notebook JupyterLab
Créez un modèle de ML pour détecter et visualiser les anomalies à grande échelle.
Ouvrez le notebook dans un nouvel onglet et attendez qu'il se charge. La session dans laquelle vous avez exécuté les requêtes Spark SQL se poursuit.
Importez les packages nécessaires et connectez-vous à la table externe BigQuery contenant les données sur les transactions. Exécutez le code suivant :
from google.cloud import bigquery from google.api_core.client_options import ClientOptions import os import warnings warnings.filterwarnings('ignore') import pandas as pd project = os.environ['GOOGLE_CLOUD_PROJECT'] options = ClientOptions(quota_project_id=project) client = bigquery.Client(client_options=options) client = bigquery.Client() #Load data into DataFrame sql = '''select * from procurement.offlinesales limit 100;''' df = client.query(sql).to_dataframe()Exécutez l'algorithme de forêt d'isolation pour détecter les anomalies dans l'ensemble de données:
to_model_columns = df.columns[2:4] from sklearn.ensemble import IsolationForest clf=IsolationForest(n_estimators=100, max_samples='auto', contamination=float(.12), \ max_features=1.0, bootstrap=False, n_jobs=-1, random_state=42, verbose=0) clf.fit(df[to_model_columns]) pred = clf.predict(df[to_model_columns]) df['anomaly']=pred outliers=df.loc[df['anomaly']==-1] outlier_index=list(outliers.index) #print(outlier_index) #Find the number of anomalies and normal points here points classified -1 are anomalous print(df['anomaly'].value_counts())Représentez les anomalies prédites à l'aide d'une visualisation Matplotlib:
import numpy as np from sklearn.decomposition import PCA pca = PCA(2) pca.fit(df[to_model_columns]) res=pd.DataFrame(pca.transform(df[to_model_columns])) Z = np.array(res) plt.title("IsolationForest") plt.contourf( Z, cmap=plt.cm.Blues_r) b1 = plt.scatter(res[0], res[1], c='green', s=20,label="normal points") b1 =plt.scatter(res.iloc[outlier_index,0],res.iloc[outlier_index,1], c='green',s=20, edgecolor="red",label="predicted outliers") plt.legend(loc="upper right") plt.show()
Cette image montre les données de transaction, avec les anomalies mises en surbrillance en rouge.
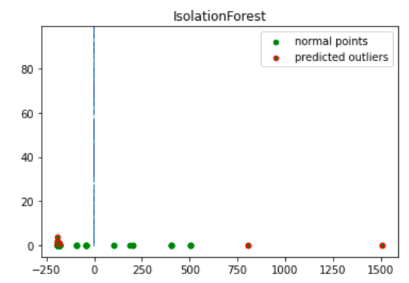
Programmer le notebook
Explorer vous permet de programmer l'exécution périodique d'un notebook. Suivez la procédure pour planifier le notebook Jupyter que vous avez créé.
Dataplex Universal Catalog crée une tâche de planification pour exécuter votre notebook régulièrement. Pour surveiller la progression de la tâche, cliquez sur Afficher les plannings.
Partager ou exporter le notebook
Explorer vous permet de partager un bloc-notes avec d'autres membres de votre organisation à l'aide d'autorisations IAM.
Examinez les rôles. Accordez ou révoquez les rôles Lecteur Dataplex Universal Catalog (roles/dataplex.viewer), Éditeur Dataplex Universal Catalog (roles/dataplex.editor) et Administrateur Dataplex Universal Catalog (roles/dataplex.admin) aux utilisateurs pour ce notebook. Une fois que vous avez partagé un notebook, les utilisateurs disposant des rôles Lecteur ou Éditeur au niveau du lac peuvent y accéder et travailler sur le notebook partagé.
Pour partager ou exporter un notebook, consultez Partager un notebook ou Exporter un notebook.
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer le projet
Delete a Google Cloud project:
gcloud projects delete PROJECT_ID
Supprimer des ressources individuelles
-
Supprimez le bucket :
gcloud storage buckets delete BUCKET_NAME
-
Supprimez l'instance.
gcloud compute instances delete INSTANCE_NAME
Étapes suivantes
- En savoir plus sur Dataplex Universal Catalog Explore
- Planifier des scripts et des notebooks