Mit Dataplex Universal Catalog-Datenqualitätsaufgaben können Sie Datenqualitätsprüfungen für Tabellen in BigQuery und Cloud Storage definieren und ausführen. Mit Dataplex Universal Catalog-Datenqualitätsaufgaben können Sie auch regelmäßige Datenkontrollen in BigQuery-Umgebungen anwenden.
Zeitpunkt der Erstellung von Datenqualitätsaufgaben in Dataplex Universal Catalog
Dataplex Universal Catalog-Datenqualitätsaufgaben können Ihnen bei Folgendem helfen:
- Validieren Sie Daten als Teil einer Datenproduktionspipeline.
- Überprüfen Sie regelmäßig die Qualität der Datasets im Hinblick auf Ihre Erwartungen.
- Erstellen Sie Datenqualitätsberichte für rechtliche Anforderungen.
Vorteile
- Anpassbare Spezifikationen. Sie können die hochflexible YAML-Syntax zum Deklarieren von Datenqualitätsregeln verwenden.
- Serverlose Implementierung. Dataplex Universal Catalog erfordert keine Infrastruktureinrichtung.
- Nullkopie und automatischer Push-down. YAML-Prüfungen werden in SQL konvertiert und an BigQuery übertragen, sodass keine Datenkopie entsteht.
- Planbare Prüfungen der Datenqualität. Sie können Datenqualitätsprüfungen über den serverlosen Planer in Dataplex Universal Catalog planen oder die Dataplex API über externe Planer wie Cloud Composer für die Pipelineintegration verwenden.
- Verwaltete Erfahrung. Dataplex Universal Catalog verwendet eine Open-Source-Datenqualitäts-Engine, CloudDQ, um Datenqualitätsprüfungen auszuführen. Dataplex Universal Catalog bietet jedoch eine nahtlos verwaltete Lösung für die Durchführung Ihrer Datenqualitätsprüfungen.
Funktionsweise von Datenqualitätsaufgaben
Das folgende Diagramm zeigt, wie Datenqualitätsaufgaben in Dataplex Universal Catalog funktionieren:
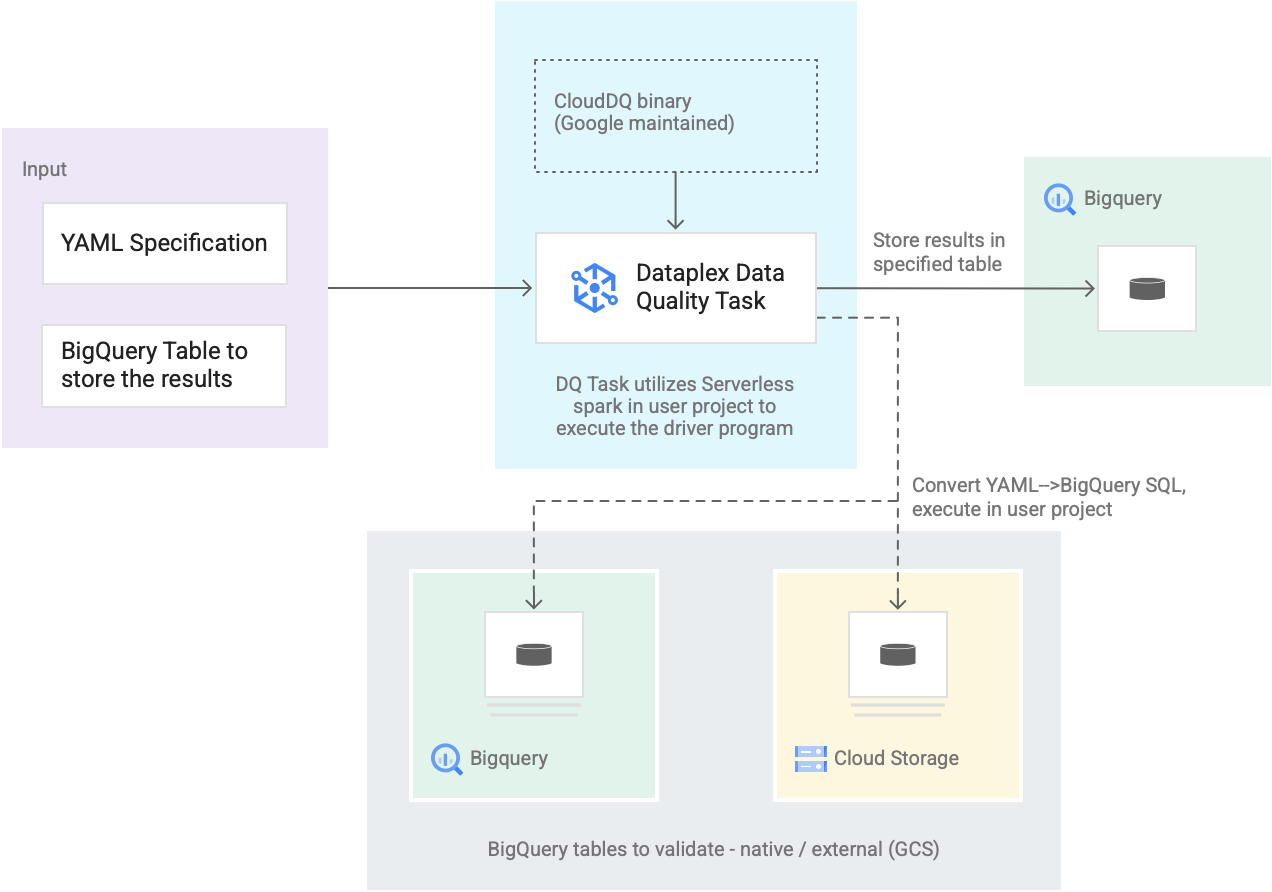
- Eingabe von Nutzern
- YAML-Spezifikation: Eine oder mehrere YAML-Dateien, die Regeln zur Datenqualität anhand der Spezifikationssyntax definieren. Sie speichern die YAML-Dateien in einem Cloud Storage-Bucket in Ihrem Projekt. Nutzer können mehrere Regeln gleichzeitig ausführen. Diese Regeln können auf verschiedene BigQuery-Tabellen angewendet werden, einschließlich Tabellen in verschiedenen Datasets oder Google Cloud-Projekten. Die Spezifikation unterstützt inkrementelle Ausführungen nur für die Validierung neuer Daten. Informationen zum Erstellen einer YAML-Spezifikation finden Sie unter Spezifikationsdatei erstellen.
- BigQuery-Ergebnistabelle: Eine benutzerdefinierte Tabelle, in der die Ergebnisse der Datenqualitätsvalidierung gespeichert werden. Das Google Cloud -Projekt, in dem sich diese Tabelle befindet, kann ein anderes Projekt sein als das Projekt, in dem die Dataplex Universal Catalog-Datenqualitätsaufgabe verwendet wird.
- Zu validierende Tabellen
- Innerhalb der YAML-Spezifikation müssen Sie angeben, welche Tabellen Sie für welche Regeln validieren möchten. Dies wird auch als Regelbindung bezeichnet. Die Tabellen können native BigQuery-Tabellen oder externe BigQuery-Tabellen in Cloud Storage sein. Mit der YAML-Spezifikation können Sie Tabellen innerhalb oder außerhalb einer Dataplex Universal Catalog-Zone angeben.
- BigQuery- und Cloud Storage-Tabellen, die in einer einzelnen Ausführung validiert werden, können zu verschiedenen Projekten gehören.
- Dataplex Universal Catalog-Datenqualitätsaufgabe: Eine Dataplex Universal Catalog-Datenqualitätsaufgabe wird mit einer vordefinierten, verwalteten CloudDQ-PySpark-Binärdatei konfiguriert und verwendet die YAML-Spezifikation und die BigQuery-Ergebnistabelle als Eingabe. Ähnlich wie andere Dataplex Universal Catalog-Aufgaben wird die Dataplex Universal Catalog-Datenqualitätsaufgabe in einer serverlosen Spark-Umgebung ausgeführt, konvertiert die YAML-Spezifikation in BigQuery-Abfragen und führt diese Abfragen dann auf den Tabellen aus, die in der Spezifikationsdatei definiert sind.
Preise
Wenn Sie Datenqualitätsaufgaben in Dataplex Universal Catalog ausführen, wird Ihnen die Nutzung von BigQuery und Serverless for Apache Spark (Batches) in Rechnung gestellt.
Die Dataplex Universal Catalog-Datenqualitätsaufgabe konvertiert die Spezifikationsdatei in BigQuery-Abfragen und führt sie im Nutzerprojekt aus. Siehe BigQuery-Preise.
Dataplex Universal Catalog verwendet Spark, um das vordefinierte, von Google verwaltete Open-Source-Treiberprogramm CloudDQ auszuführen, um die Nutzerspezifikation in BigQuery-Abfragen zu konvertieren. Weitere Informationen
Für die Verwendung von Dataplex Universal Catalog zum Organisieren von Daten oder die Verwendung des serverlosen Planers in Dataplex Universal Catalog zum Planen von Datenqualitätsprüfungen fallen keine Gebühren an. Siehe Dataplex Universal Catalog-Preise.