Data lineage helps you understand how data moves through your systems by tracking the relationships between data assets and the processes that transform them. You can view this lineage information as graphs and lists in the Google Cloud console.
This document provides an overview of the data lineage information model, details on table-level and column-level lineage granularity, and instructions on using graph and list views to explore data lineage.
Data lineage information model
Lineage is a record of data being transformed from sources to targets. The Data Lineage API collects this information and organizes it into a hierarchical data model that uses the concepts of processes, runs, and events.
- Process: a data transformation definition.
- Run: an execution of a process.
- Event: a record of data movement during a run.
Process
A process is the definition of a data transformation operation for a specific system. For BigQuery lineage, a process is a job of a supported job type. All executions of the same SQL query are linked to a single process, which lets you track every instance where a specific transformation logic is used.
For example, the following SQL query is a process. This query creates a table by counting the total number of trips for each vendor from two source tables.
CREATE TABLE `dataplex-docs.data_lineage_demo.total_green_trips_22_21`
AS
SELECT
vendor_id,
COUNT(*) AS number_of_trips
FROM
(
SELECT vendor_id
FROM `dataplex-docs.data_lineage_demo.nyc_green_trips_2022`
UNION ALL
SELECT vendor_id
FROM `dataplex-docs.data_lineage_demo.nyc_green_trips_2021`
)
GROUP BY
vendor_id;
The REST resource name format for a process is
projects/PROJECT_NUMBER/locations/LOCATION/processes/PROCESS_ID.
For example: projects/123456789123/locations/us/processes/sh-0548bbf4ff3c8072a6c7372ba1acafb6
For more information about the process resource, see the
Process resource reference.
Run
A run is a single execution of a process. Processes can have multiple runs.
Each run is a unique operation characterized by a startTime, an endTime, and
a final state, such as COMPLETED, FAILED, or ABORTED.
For example, executing the SQL query from the Process section at 9:00 AM creates a specific run. Executing the same query again at 10:00 AM creates a new, distinct run. Both runs are linked to the same parent process.
The REST resource name format for a run shows that it's a child of a process:
projects/PROJECT_NUMBER/locations/LOCATION/processes/PROCESS_ID/runs/RUN_ID.
For example: projects/123456789123/locations/us/processes/sh-0548bbf4ff3c8072a6c7372ba1acafb6/runs/83dd03a51cd2ac80f465c9e267a950b1
For more information about the run resource, see the
Run resource reference.
Event
An event represents a point in time when a data transformation moves data between a source and a target entity. An event is a granular record of a specific data movement that connects source and target tables for a specific run. An event can also have multiple sources and targets.
For example, if your run executes the SQL query discussed in the
Process section, a lineage event records that
the nyc_green_trips_2021 and nyc_green_trips_2022 source tables are used to
create the total_green_trips_22_21 target table.
A lineage event contains a list of links that define the source and target. Events are used to create lineage graphs. While the Google Cloud console presents these lineage graphs, it doesn't directly display individual events. You can create, read, and delete, but not update events by using the Data Lineage API.
Each link within an event defines a single path of data flow from a source entity to a target entity. An entity is a reference to a data asset, such as a BigQuery table, and is identified by its Fully Qualified Name (FQN). A single event can contain multiple links, which is common in operations like table joins where multiple sources contribute to one target.
For details on how events support column-level lineage, see Column-level lineage.
Lineage granularity
Data lineage lets you trace the origin and transformation path of your data at both the table and column level.
Table-level lineage
Table-level lineage provides a high-level overview of your data pipelines by showing the relationships between entire tables. Use table-level lineage for macro-level tasks such as the following:
Data discovery. An analyst building a new dashboard can use table-level lineage to trace a summary table back to its sources and confirm that the data originates from an authoritative database.
Migration planning. A database administrator planning to migrate a core database can use table-level lineage to identify every downstream report and dashboard that depends on it.
Auditing and governance. A data governor can use table-level and column-level lineage to check how data from a table that contains personally identifiable information (PII) flows through a pipeline.
Column-level lineage
Column-level lineage provides a more granular view by tracking the flow of data between individual columns. In this view, the links within a lineage event represent the relationship between a source column and a target column. Each of these column-level links has a dependency type that describes the transformation:
Exact copy: values are copied between columns.Other: other types of dependencies between columns.
Use column-level lineage for tasks such as the following:
Root cause analysis. If a data analyst finds an incorrect value in a column, they can use column-level lineage to trace it back to the source columns to find the root cause.
Impact analysis. Before a data engineer deprecates a column, they can use column-level lineage to find every downstream column that depends on it.
Data source verification for metrics. A data analyst can use column-level lineage to identify which source columns are used to calculate a metric without deciphering a complex SQL query.
Column-level lineage is automatically collected for the following types of BigQuery jobs:
Lineage views in the Google Cloud console
Data lineage in the Google Cloud console lets you interact with lineage information in two ways: you can explore the lineage graph across multiple available regions, or you can use the Lineage explorer panel to get a more focused view within a specific region. You can also switch between the Graph view and the List view to analyze data flow at different levels of detail.
Lineage views are only available for Dataplex Universal Catalog entries, BigQuery assets, and Vertex AI resources (models, datasets, feature store views, and feature groups).
To see the different views discussed in this page, see Use data lineage with Google Cloud systems.
Lineage graph view
The Graph view visualizes data asset flow and relationships across systems and regions, helping you understand data architecture, trace origins and destinations, and identify patterns. These lineage graphs, generated by the Data Lineage API service for a specific Dataplex Universal Catalog entry, show how data is transformed over time, displaying upstream, downstream, or both flows from a selected root entry.
The Data Lineage API automatically receives asset information from supported systems and through API calls for custom sources.
The key elements in the graph are described as follows:
Nodes. Represent the data entities. In a table-level view, a node shows the table name and its columns. In a column-level view, each node represents a specific table and column.
Edges. The lines that connect nodes and represent the processes that occur between them. The appearance of an edge depends on the lineage view:
- In the table-level view, edges have icons to indicate data transformations.
- In the column-level view, edges have labels to indicate data
transformations. For example, an edge label might say
Exact copyto describe how a source column was copied to a target column.
Process icons and labels. Appear on edges to provide more information about the transformation.
- Icons. Represent the transformation process. When you manually explore the graph, icons on edges represent the source system of the process (for example, BigQuery or Vertex AI). If multiple processes are involved, a 'multiple processes' icon is displayed. If the process source system is unknown, a gear icon is used. When you apply filters, a gear icon is used for all processes.
- Labels. In the column-level lineage view, a label describes the type
of dependency between columns:
Exact copyorOther.
Manually explore the lineage graph
When you open the Lineage tab, you see the default Graph view. The default view provides a high-level overview across systems and regions, with manual and incremental graph expansion that can load five nodes at a time. Process icons on edges represent the source system or indicate multiple processes.
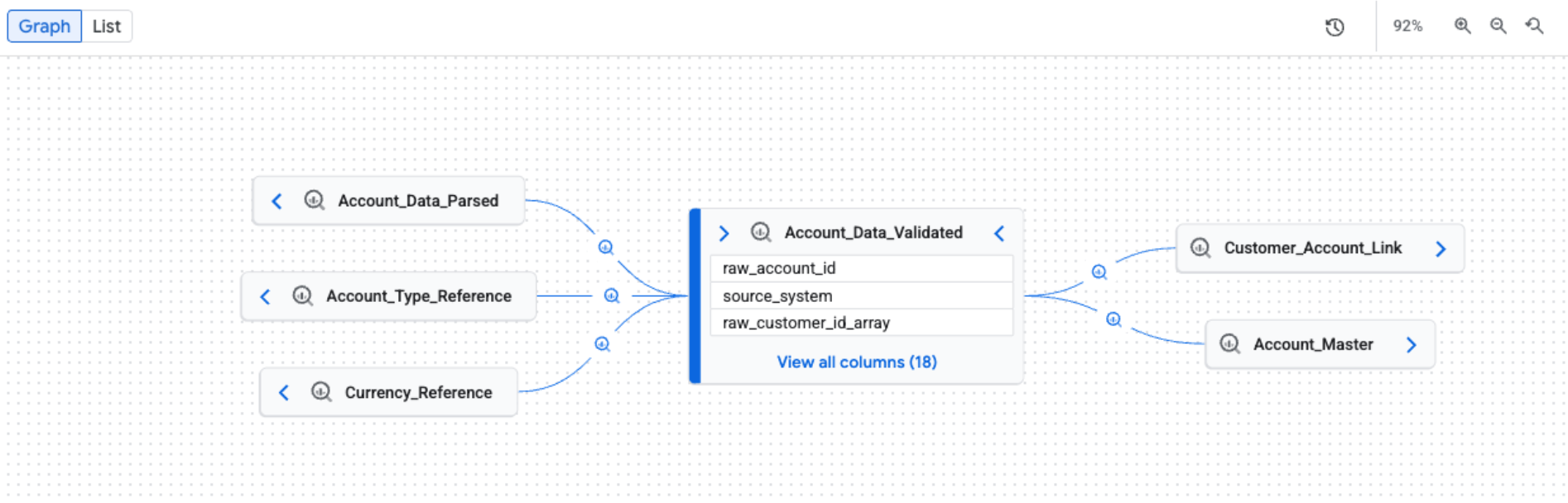
Apply filters for a focused lineage view
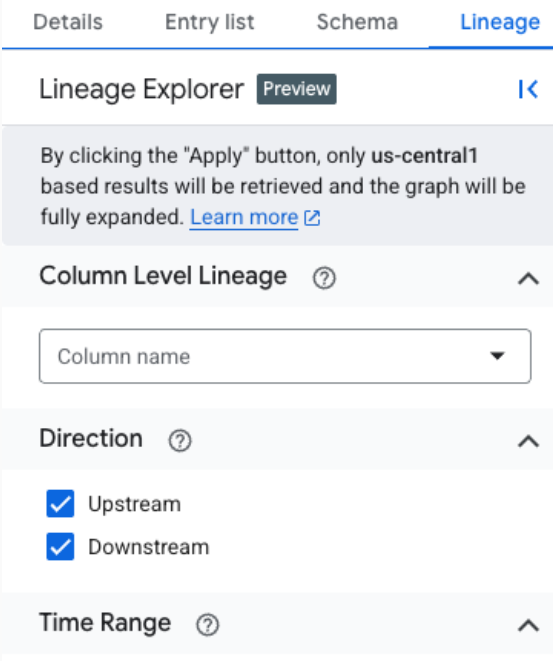
To filter lineage data for focused analysis within a specific region, use the Lineage explorer panel. Here are some criteria that you can use to switch to a focused view:
- Column name: Filter lineage by column name to see column-level details.
- Direction: Show upstream or downstream lineage, or both.
- Time range: Filter lineage based on a specific start or end time.
- Dependency type: Filter column-level lineage based on dependency type.
Examples of available options include
AllorExact copy.
The focused view automatically expands the graph up to three levels, loading all lineage matching the filter criteria. It supports both table-level and column-level lineage, including path visualization from any selected node back to the root. In this focused view, a generic gear icon is used for all processes.

To view column-level lineage, you can follow one of the following methods:
In a focused Graph view, click the column icon on a table to switch to column-level lineage.
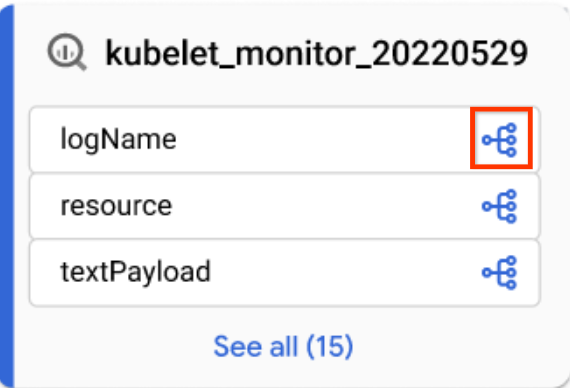
Column icon In default Graph view or focused Graph view, apply a column name in the Lineage explorer panel.

To remove all filters and return to the default view, click reset.
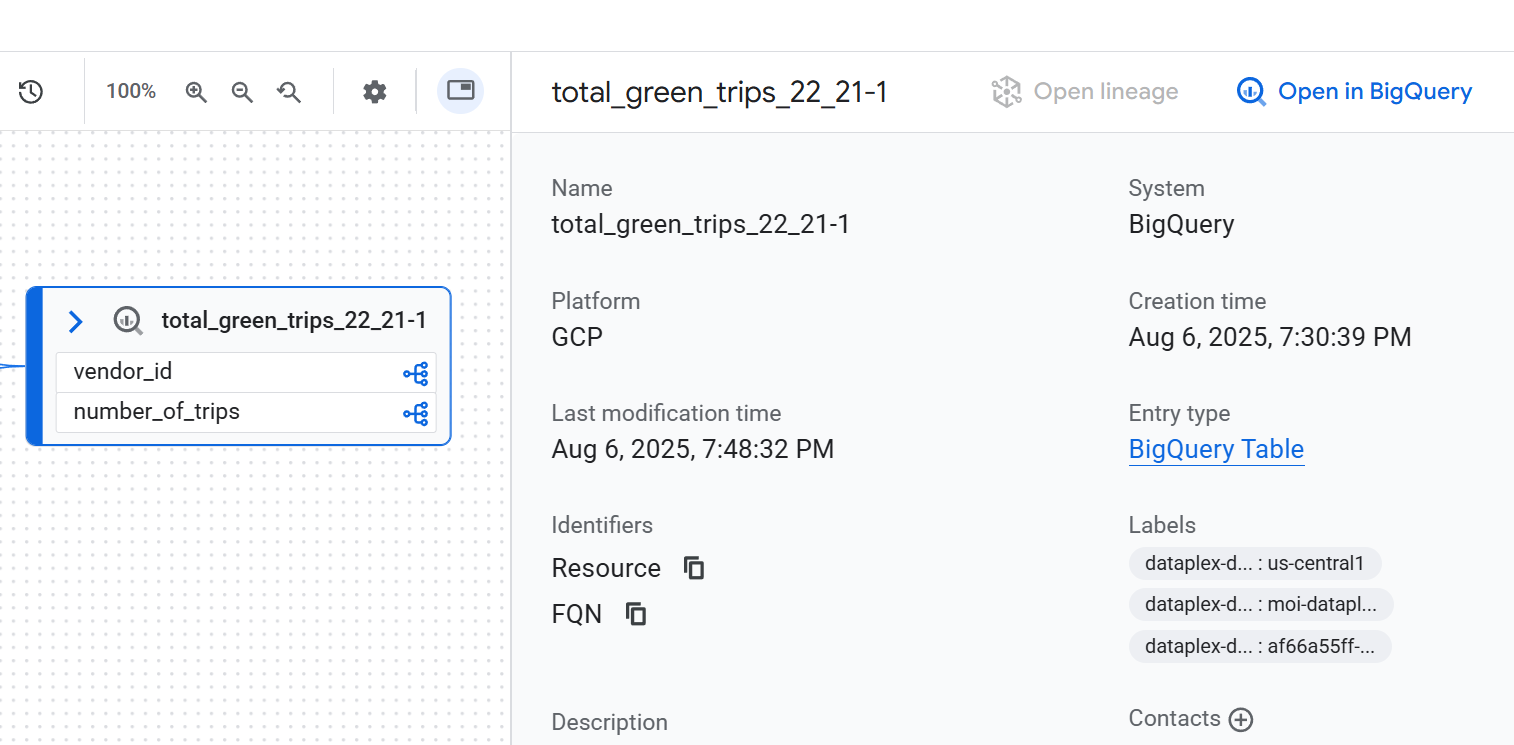
Node details
To see the details of a node, click the node. A side panel appears and displays detailed information about the selected data asset. For example, in a table-level lineage view, clicking a node displays information such as the asset's fully qualified name, type, and other relevant attributes.
Audit and history of runs
A complete lineage graph is the result of runs from many different jobs, with each job creating a specific link in the graph. Multiple executions are logged as new runs but don't change the static appearance of the graph.
To see the details of these individual executions, click an edge with a process on the graph. In the Query panel that appears, click the Runs tab.
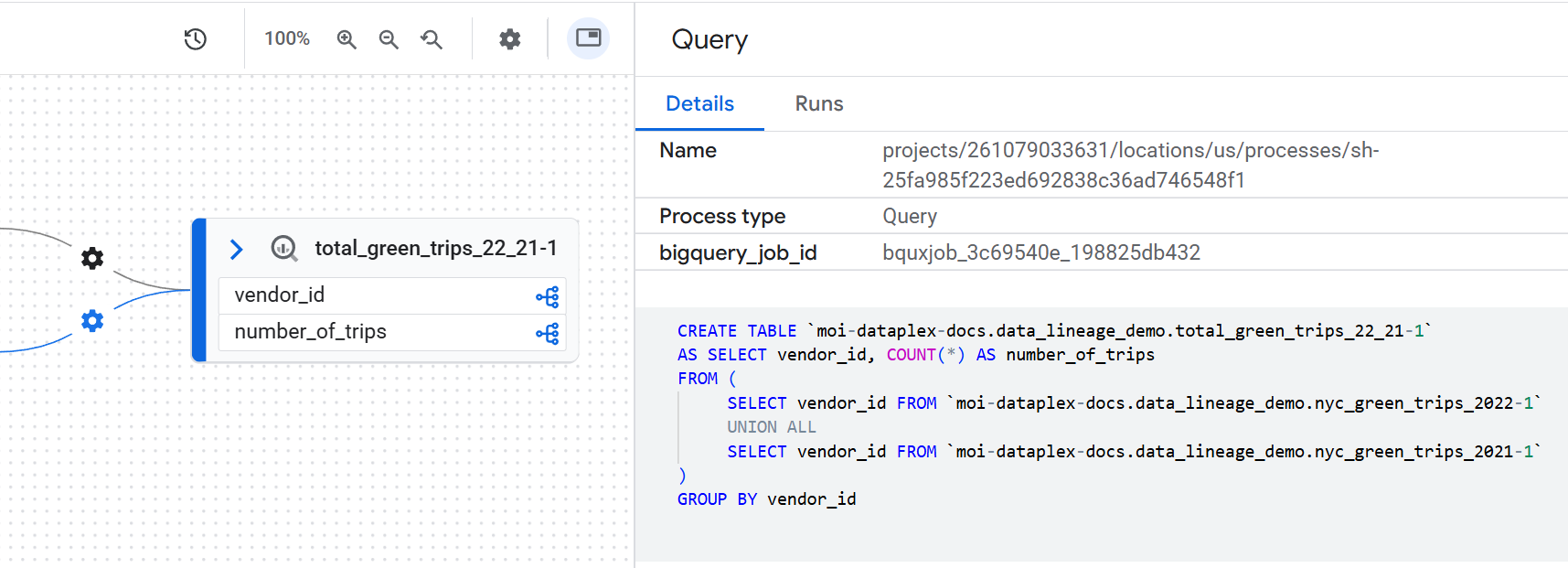
Inspect transformation logic
To understand the business logic of a transformation without searching for the code, you can view the exact SQL query that was run. To view the SQL code, click an edge with a process on the graph. In the side panel that appears, click the Details tab.
Lineage path visualization
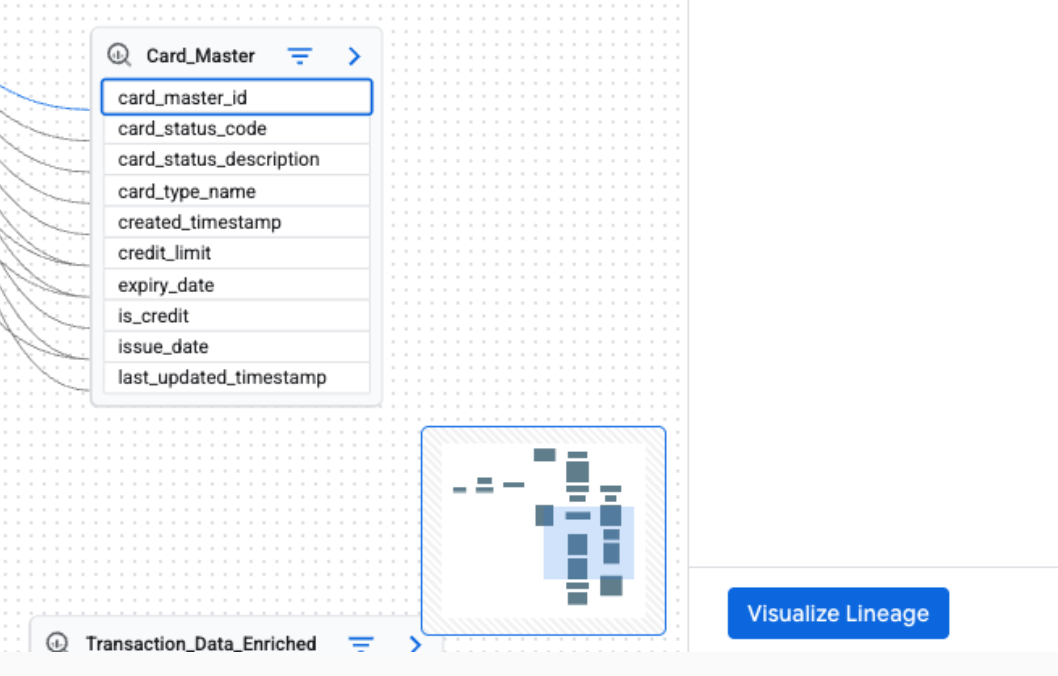
Lineage path visualization helps you trace the path from any selected node in the graph back to the root entry. When you select a node and click Visualize path, the graph highlights only the nodes and processes that form the direct lineage path to the root entry.
To see the lineage path visualization, in the Lineage explorer panel, apply a filter to create a focused Graph view. Then, in the focused Graph view, select a node. In the details panel for the selected node, click Visualize Path.
Lineage path visualization is available for table-level and column-level lineage. You can also use lineage path visualization in the List view.
Lineage list view
The List view offers a tabular, structured representation of lineage, synchronized with the Graph view. It facilitates sorting, filtering, and downloading data assets. This view is ideal for analyzing source-target relationships, detailing involved assets, and exporting lineage data.
The List view is available for both table-level and column-level lineage. You can toggle between the following detailed and simplified list views.
Simplified list view: this view is useful for getting a condensed, unique list of all assets involved in the lineage. The columns such as System, Project, Entity, FQN (Fully Qualified Name), Direction, and Depth help you see all the data assets in the lineage, where they reside, their original source, and their distance from the central asset being analyzed. It is ideal for a high-level overview of all entities participating in the data flow. It is the default view.
Detailed list view: this view is designed for analyzing individual source-target relationships. By providing separate columns for Source and Target, you can see each specific data transformation link. This view is ideal for tasks requiring a deep understanding of how data moves between specific pairs of assets, such as auditing individual data flows, understanding dependencies between tables, or exporting detailed lineage records for each connection.
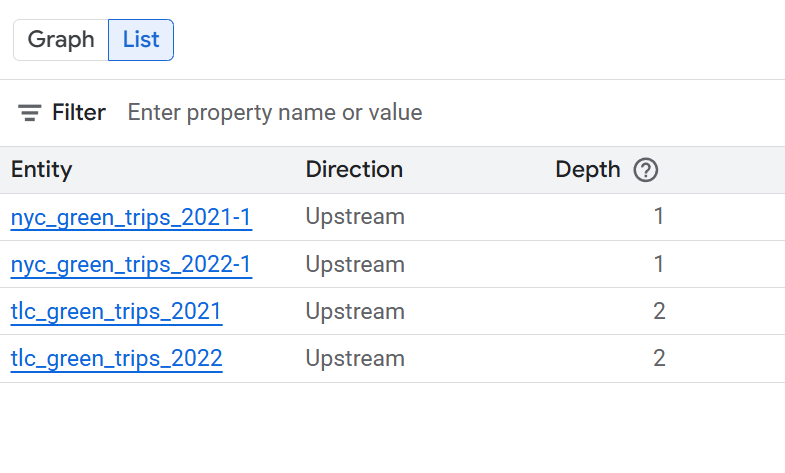
Table-level lineage list view
This view shows relationships between tables as a whole. Use the provided filters to select the columns that you require.
Expand the following sections to see the columns available in the table-level list views.
Columns available in simplified table-level list view
- System: the system where the data asset is located. Examples include BigQuery.
- Project: the Google Cloud project ID containing the data asset.
- Entity: the name of the data asset. Examples include a table name.
- FQN: the Fully Qualified Name (FQN) of the original source entity or column.
- Direction: indicates whether the listed asset is upstream (source) or downstream (target) in the lineage flow.
- Depth: the number of lineage steps from the central asset being analyzed.
Columns available in detailed table-level list view
- Source system: the system where the source data asset is located. Examples include BigQuery.
- Source project: the Google Cloud project ID containing the source data asset.
- Source: the name of the source data asset. Examples include a table name.
- Source FQN: the FQN of the source entity.
- Target system: the system where the target data asset is located. Examples include BigQuery.
- Target project: the Google Cloud project ID containing the target data asset.
- Target: the name of the target data asset. Examples include a table name.
- Target FQN: the FQN of the target entity.
- Direction: indicates whether the listed asset is upstream (source) or downstream (target) in the lineage flow.
- Depth: the number of lineage steps from the central asset being analyzed.
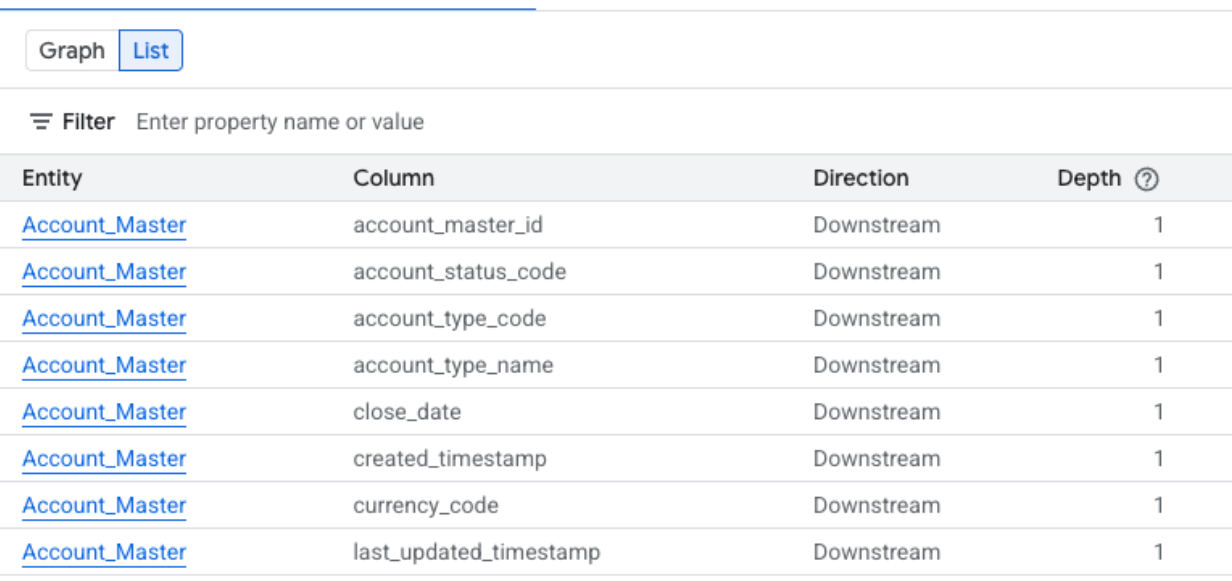
Column-level lineage list view
This view shows relationships between individual columns in the source and target tables. Use the provided filters to select the columns that you require.
Expand the following sections to see the columns available in the column-level list views.
Columns available in simplified column-level list view
- System: the system where the data asset is located. Examples include BigQuery.
- Project: the Google Cloud project ID containing the data asset.
- Entity: the name of the data asset. Examples include a table name.
- Column: the specific column chosen in the Lineage Explorer panel within the entity.
- FQN: the Fully Qualified Name (FQN) of the original source entity or column.
- Direction: indicates whether the listed asset is upstream (source) or downstream (target) in the lineage flow.
- Depth: the number of lineage steps from the central asset being analyzed.
Columns available in detailed column-level list view
- Source system: the system where the source data asset is located.
- Source project: the Google Cloud project ID containing the source data asset.
- Source FQN: the FQN of the source column.
- Target system: the system where the target data asset is located.
- Target project: the Google Cloud project ID containing the target data asset.
- Target FQN: the FQN of the target column.
- Direction: indicates if the data flow is upstream or downstream.
- Dependency types: describes the nature of the relationship between the columns.
- Depth: the number of lineage steps from the central asset being analyzed.
What's next
Learn about lineage sources.
Learn how to track data lineage for a BigQuery table copy and query jobs.
Learn how to use data lineage with Google Cloud systems.