Passaggio 1: stabilisci i carichi di lavoro
Questa pagina ti guida nel passaggio iniziale della configurazione della base di dati, il fulcro di Cortex Framework. Basata sull'archiviazione BigQuery, la base di dati organizza i dati in entrata provenienti da varie origini. Questi dati organizzati semplificano l'analisi e la loro applicazione nello sviluppo dell'AI.
Configura l'integrazione dei dati
Inizia definendo alcuni parametri chiave che fungano da modello per organizzare e utilizzare i tuoi dati in modo efficiente all'interno di Cortex Framework. Ricorda che questi parametri possono variare a seconda del carico di lavoro specifico, del flusso di dati scelto e del meccanismo di integrazione. Il seguente diagramma fornisce una panoramica dell'integrazione dei dati all'interno della base dati di Cortex Framework:

Definisci i seguenti parametri prima del deployment per un utilizzo efficiente ed efficace dei dati all'interno di Cortex Framework.
Progetti
- Progetto di origine:il progetto in cui si trovano i dati non elaborati. Hai bisogno di almeno un progetto Google Cloud per archiviare i dati ed eseguire il processo di deployment.
- Progetto di destinazione (facoltativo): progetto in cui Cortex Framework Data Foundation memorizza i modelli di dati elaborati. Può essere lo stesso del progetto di origine o uno diverso, a seconda delle tue esigenze.
Se vuoi avere set separati di progetti e set di dati per ogni carico di lavoro (ad esempio, un set di progetti di origine e di destinazione per SAP e un set diverso di progetti di destinazione e di origine per Salesforce), esegui deployment separati per ogni carico di lavoro. Per ulteriori informazioni, vedi Utilizzare progetti diversi per separare l'accesso nella sezione dei passaggi facoltativi.
Modello dei dati
- Esegui il deployment dei modelli:scegli se devi eseguire il deployment dei modelli per tutti i workload o solo per un insieme di modelli (ad esempio SAP, Salesforce e Meta). Per maggiori informazioni, consulta le origini dati e i carichi di lavoro disponibili.
Set di dati di BigQuery
- Set di dati di origine (non elaborato): set di dati BigQuery in cui vengono replicati i dati di origine o in cui vengono creati i dati di test. Il consiglio è di avere set di dati separati, uno per ogni origine dati. Ad esempio, un set di dati non elaborati per SAP e uno per Google Ads. Questo set di dati appartiene al progetto di origine.
- Set di dati CDC: set di dati BigQuery in cui i dati elaborati CDC contengono i record più recenti disponibili. Alcuni carichi di lavoro consentono la mappatura dei nomi dei campi. Il consiglio è di avere un set di dati CDC separato per ogni origine. Ad esempio, un set di dati CDC per SAP e un set di dati CDC per Salesforce. Questo set di dati appartiene al progetto di origine.
- Set di dati dei report di destinazione:set di dati BigQuery in cui vengono implementati i modelli di dati predefiniti di Data Foundation. Ti consigliamo di avere un set di dati dei report separato per ogni origine. Ad esempio, un set di dati dei report per SAP e uno per Salesforce. Questo set di dati viene creato automaticamente durante il deployment se non esiste. Questo set di dati appartiene al progetto di destinazione.
- Pre-processing K9 Dataset:set di dati BigQuery in cui
possono essere implementati componenti DAG riutilizzabili e cross-workload, come le dimensioni
time. I carichi di lavoro hanno una dipendenza da questo set di dati, a meno che non vengano modificati. Questo set di dati viene creato automaticamente durante il deployment se non esiste. Questo set di dati appartiene al progetto di origine. - Set di dati K9 post-elaborazione:set di dati BigQuery in cui possono essere implementati report cross-workload e DAG di origini esterne aggiuntive (ad esempio, l'importazione di Google Trends). Questo set di dati viene creato automaticamente durante il deployment se non esiste. Questo set di dati appartiene al progetto di destinazione.
(Facoltativo) Genera dati di esempio
Cortex Framework può generare dati e tabelle di esempio se non hai accesso ai tuoi dati, agli strumenti di replica per configurare i dati o anche se vuoi solo vedere come funziona Cortex Framework. Tuttavia, devi comunque creare e identificare in anticipo i set di dati CDC e Raw.
Crea set di dati BigQuery per i dati non elaborati e CDC per origine dati, seguendo le istruzioni riportate di seguito.
Console
Apri la pagina BigQuery nella console Google Cloud .
Nel riquadro Explorer, seleziona il progetto in cui vuoi creare il set di dati.
Espandi l'opzione Azioni e fai clic su Crea set di dati:
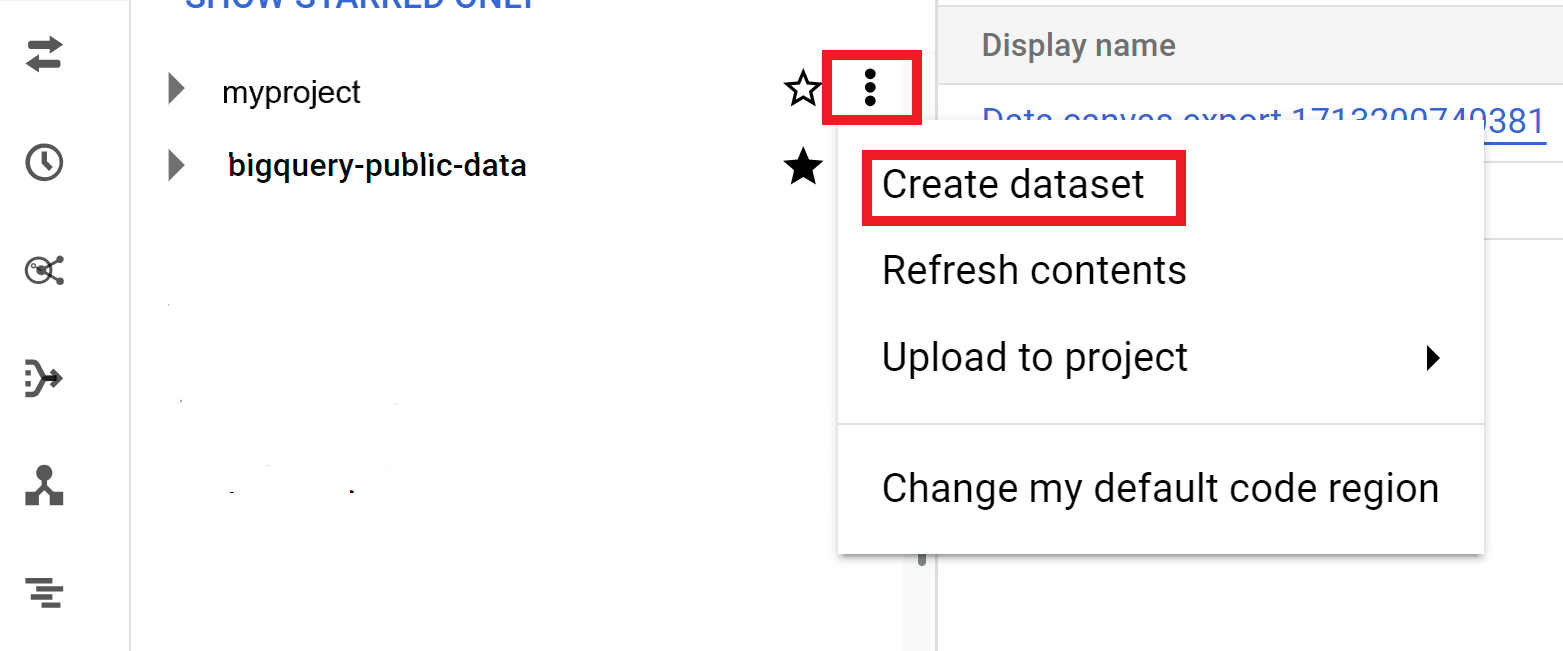
Nella pagina Crea set di dati:
- In ID set di dati, inserisci un nome univoco per il set di dati.
Per Tipo di località, scegli una località geografica per il set di dati. Una volta creato un set di dati, la posizione non può essere modificata.
(Facoltativo) Per ulteriori dettagli sulla personalizzazione del set di dati, vedi Creare set di dati: console.
Fai clic su Crea set di dati.
BigQuery
Crea un nuovo set di dati per i dati non elaborati copiando il seguente comando:
bq --location= LOCATION mk -d SOURCE_PROJECT: DATASET_RAWSostituisci quanto segue:
LOCATIONcon la posizione del set di dati.SOURCE_PROJECTcon l'ID progetto di origine.DATASET_RAWcon il nome del set di dati per i dati non elaborati. Ad esempio,CORTEX_SFDC_RAW.
Crea un nuovo set di dati per i dati CDC copiando il seguente comando:
bq --location=LOCATION mk -d SOURCE_PROJECT: DATASET_CDCSostituisci quanto segue:
LOCATIONcon la posizione del set di dati.SOURCE_PROJECTcon l'ID progetto di origine.DATASET_CDCcon il nome del set di dati per i dati CDC. Ad esempio,CORTEX_SFDC_CDC.
Verifica che i set di dati siano stati creati con il seguente comando:
bq ls(Facoltativo) Per saperne di più sulla creazione di set di dati, vedi Creare set di dati.
Passaggi successivi
Dopo aver completato questo passaggio, procedi con i seguenti passaggi di deployment:
- Stabilisci i carichi di lavoro (questa pagina).
- Clona il repository.
- Determinare il meccanismo di integrazione.
- Configura i componenti.
- Configurare il deployment.
- Esegui il deployment.