Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
In dieser Anleitung wird gezeigt, wie Sie mit Cloud Composer einen Apache Airflow-DAG (Directed Acyclic Graph) erstellen, der einen Apache Hadoop-Wordcount-Job in einem Dataproc-Cluster ausführt.
Ziele
- Auf Ihre Cloud Composer-Umgebung zugreifen und die Airflow-UI verwenden
- Airflow-Umgebungsvariablen erstellen und aufrufen
- DAG mit nachfolgenden Aufgaben erstellen und ausführen:
- Erstellt einen Dataproc-Cluster.
- Führt einen Apache Hadoop-Wordcount-Job im Cluster aus.
- Gibt Ergebnisse der Wortzählung in einen Cloud Storage-Bucket aus.
- Löscht den Cluster.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Cloud Composer
- Dataproc
- Cloud Storage
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweise
Prüfen Sie, ob die folgenden APIs in Ihrem Projekt aktiviert sind:
Console
Enable the Dataproc, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud
Enable the Dataproc, Cloud Storage APIs:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable dataproc.googleapis.com
storage-component.googleapis.com Erstellen Sie in Ihrem Projekt einen Cloud Storage-Bucket einer beliebigen Speicherklasse und Region zum Speichern der Ergebnisse des Hadoop-Wordcount-Jobs.
Notieren Sie sich den Pfad des Buckets, den Sie erstellt haben, z. B.
gs://example-bucket. Für diesen Pfad definieren Sie eine Airflow-Variable, die dann im Beispiel-DAG verwendet wird.Erstellen Sie eine Cloud Composer-Umgebung mit Standardparametern. Warten Sie, bis die Erstellung der Umgebung abgeschlossen ist. Danach wird links neben dem Umgebungsnamen ein grünes Häkchen angezeigt.
Notieren Sie sich die Region, in der Sie Ihre Umgebung erstellt haben, z. B.
us-central. Im nächsten Schritt definieren Sie für diese Region eine Airflow-Variable und verwenden sie im Beispiel-DAG, um einen Dataproc-Cluster in derselben Region auszuführen.
Airflow-Variablen festlegen
Legen Sie die Airflow-Variablen fest, die später im Beispiel-DAG verwendet werden. Sie können beispielsweise Airflow-Variablen in der Airflow-UI festlegen.
| Airflow-Variable | Wert |
|---|---|
gcp_project
|
Die Projekt-ID des Projekts, das Sie für diese Anleitung verwenden, z. B. example-project. |
gcs_bucket
|
Der URI des Cloud Storage-Bucket, den Sie für diese Anleitung erstellt haben, z. B. gs://example-bucket |
gce_region
|
Die Region, in der Sie Ihre Umgebung erstellt haben, z. B. us-central1.
Dies ist die Region, in der Ihr Dataproc-Cluster erstellt wird. |
Beispielworkflow ansehen
Ein Airflow-DAG ist eine Sammlung strukturierter Aufgaben, die Sie planen und ausführen möchten. DAGs werden in Standard-Python-Dateien definiert. Der in hadoop_tutorial.py angezeigte Code ist der Workflowcode.
Operatoren
Zur Orchestrierung der drei Aufgaben im Beispielworkflow importiert der DAG die folgenden drei Airflow-Operatoren:
DataprocClusterCreateOperator: Erstellt einen Dataproc-Cluster.DataProcHadoopOperator: Sendet einen Hadoop-Wordcount-Job und schreibt Ergebnisse in einen Cloud Storage-Bucket.DataprocClusterDeleteOperator: Löscht den Cluster, um fortlaufende Compute Engine-Gebühren zu vermeiden.
Abhängigkeiten
Sie strukturieren die Aufgaben, die Sie ausführen möchten, so, dass die Struktur deren Beziehungen und Abhängigkeiten wiedergibt. Die Aufgaben in diesem DAG werden nacheinander ausgeführt.
Planung
Der Name des DAG lautet composer_hadoop_tutorial. Er wird einmal pro Tag ausgeführt. Da das an default_dag_args übergebene Startdatum start_date auf yesterday festgelegt ist, plant Cloud Composer den Workflow so, dass er unmittelbar nach dem Upload des DAG in den Bucket der Umgebung startet.
DAG in den Bucket der Umgebung hochladen
Cloud Composer speichert DAGs im Ordner /dags im Bucket Ihrer Umgebung.
So laden Sie den DAG hoch:
Speichern Sie
hadoop_tutorial.pyauf Ihrem lokalen Computer.Rufen Sie in der Google Cloud Console die Seite Umgebungen auf.
Klicken Sie in der Liste der Umgebungen in der Spalte DAGs-Ordner für Ihre Umgebung auf den Link DAGs.
Klicken Sie auf Dateien hochladen.
Wählen Sie
hadoop_tutorial.pyauf Ihrem lokalen Computer aus und klicken Sie auf Öffnen.
Cloud Composer fügt den DAG zu Airflow hinzu und plant ihn automatisch. DAG-Änderungen werden innerhalb von 3 bis 5 Minuten wirksam.
DAG-Ausführungen ansehen
Aufgabenstatus ansehen
Wenn Sie Ihre DAG-Datei in den Ordner dags/ in Cloud Storage hochladen, parst Cloud Composer die Datei. Wenn der Vorgang erfolgreich abgeschlossen wurde, wird der Name des Workflows in der DAG-Liste angezeigt und der Workflow in die Warteschlange gestellt, um sofort ausgeführt zu werden.
Rufen Sie zur Anzeige des Aufgabenstatus die Airflow-Weboberfläche auf und klicken Sie in der Symbolleiste auf DAGs.
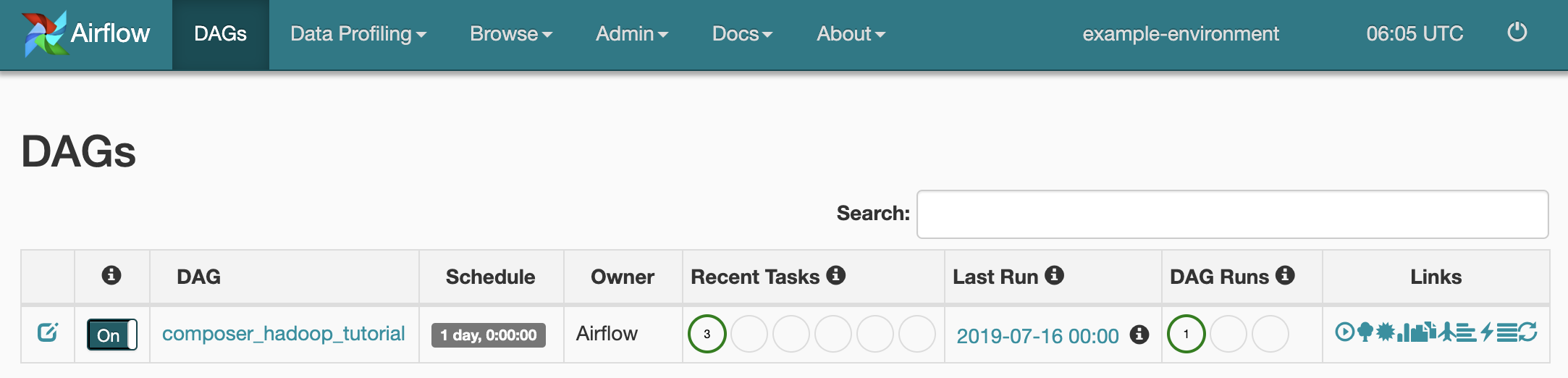
Klicken Sie zum Öffnen der DAG-Detailseite auf
composer_hadoop_tutorial. Diese Seite enthält eine grafische Darstellung der Workflowaufgaben und -abhängigkeiten.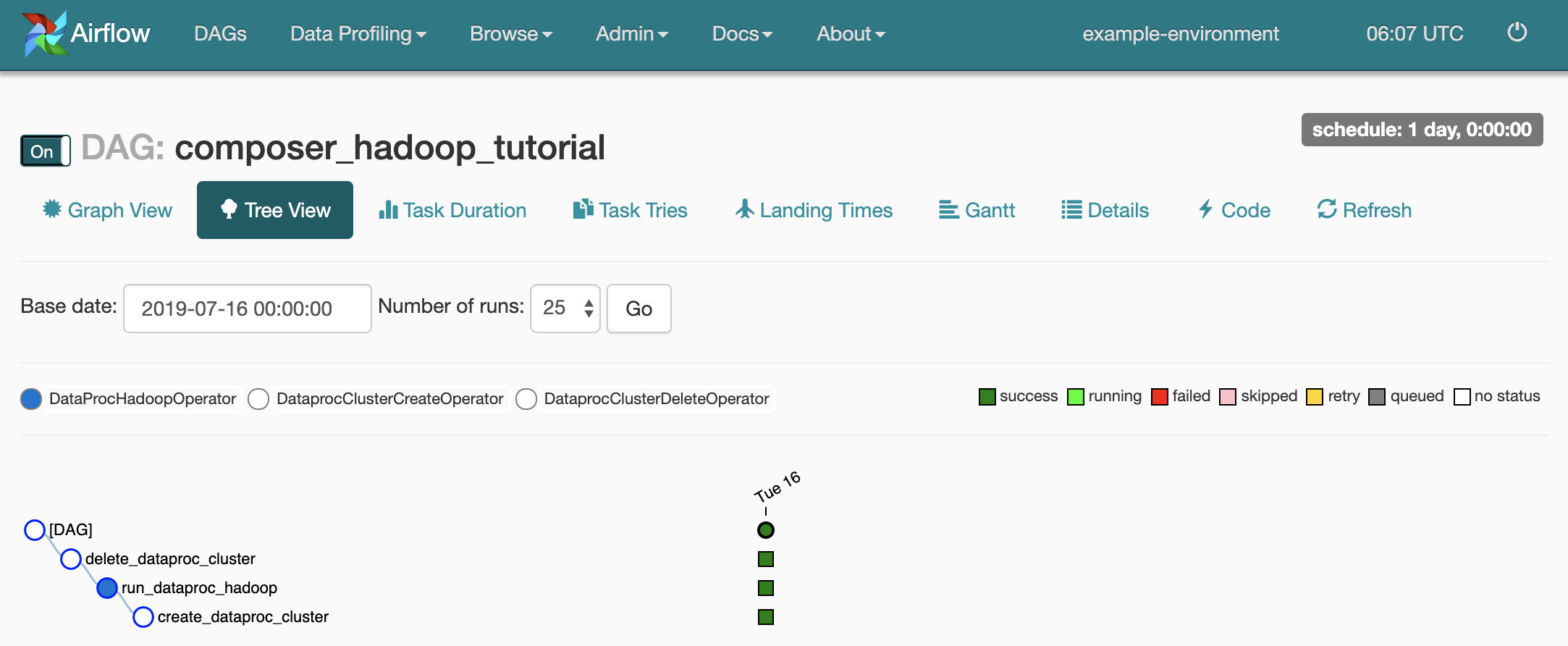
Klicken Sie zur Anzeige des Status jeder Aufgabe auf Graph View und bewegen Sie den Mauszeiger auf die Grafik für jede Aufgabe.
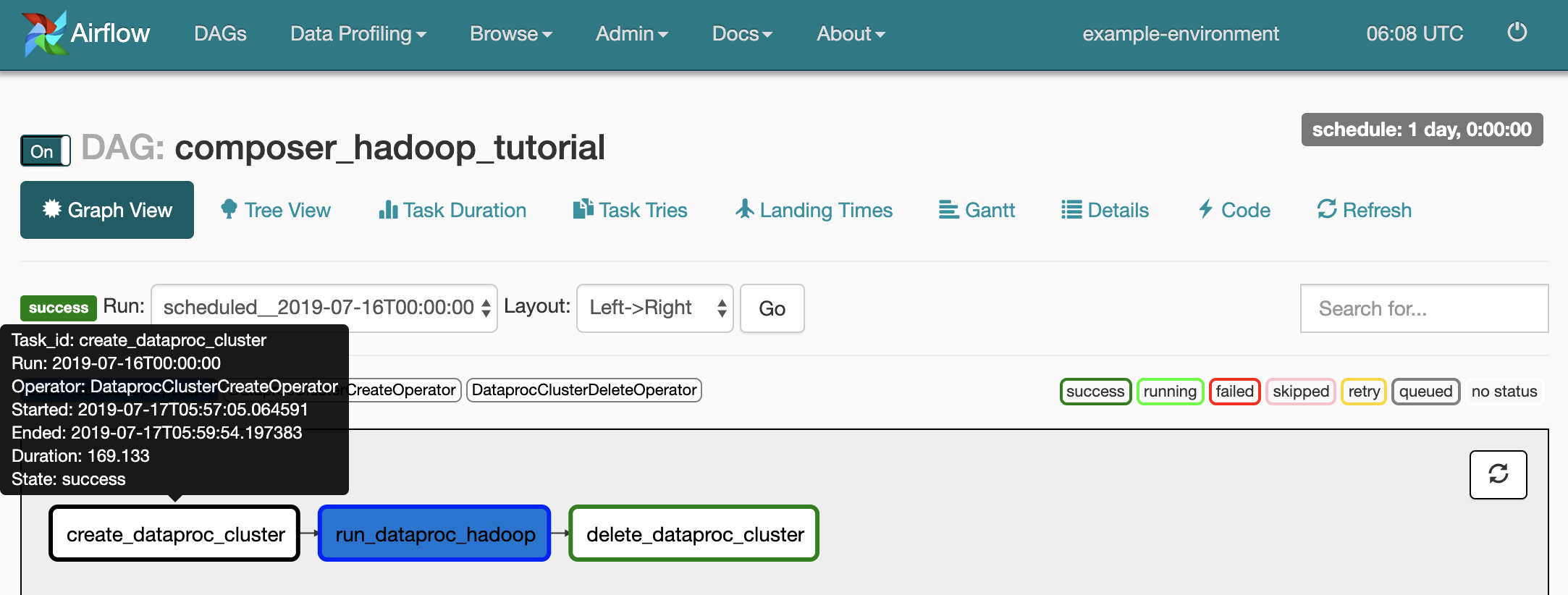
Workflow wieder in die Warteschlange stellen
So führen Sie den Workflow über die Grafikansicht noch einmal aus:
- Klicken Sie in der Grafikansicht der Airflow-Benutzeroberfläche auf die Grafik
create_dataproc_cluster. - Klicken Sie zum Zurücksetzen der drei Aufgaben auf Clear und anschließend auf OK.
- Klicken Sie in der Grafikansicht noch einmal auf
create_dataproc_cluster. - Zum nochmaligen Übergeben des Workflows an die Warteschlange klicken Sie auf Run.
Aufgabenergebnisse ansehen
Sie können den Status und die Ergebnisse des Workflows composer_hadoop_tutorial auch auf den folgenden Google Cloud Console-Seiten prüfen:
Dataproc-Cluster: zum Monitoring des Erstellens und Löschens von Clustern. Beachten Sie, dass der vom Workflow erstellte Cluster sitzungsspezifisch ist. Er ist nur für die Dauer des Workflows vorhanden und wird mit der letzten Workflowaufgabe gelöscht.
Dataproc-Jobs: zur Anzeige oder zum Monitoring eines Apache Hadoop-Wordcount-Jobs. Klicken Sie auf die Job-ID, um die Ausgabe des Job-Logs aufzurufen.
Cloud Storage-Browser: zur Anzeige der Ergebnisse der Wortzählung im Ordner
wordcountdes Cloud Storage-Bucket, den Sie für diese Anleitung erstellt haben.
Bereinigen
Löschen Sie die in dieser Anleitung verwendeten Ressourcen:
Löschen Sie die Cloud Composer-Umgebung und löschen Sie den Bucket der Umgebung manuell.
Löschen Sie den Cloud Storage-Bucket, in dem die Ergebnisse des Hadoop-Wordcount-Jobs gespeichert sind.