BigQuery 管理者リファレンス ガイド: ジョブと予約モデル

Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
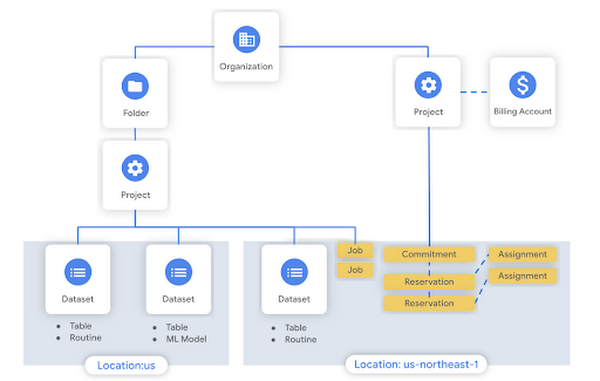
これまで、BigQuery 管理者リファレンス ガイドでは、BigQuery リソースモデルとさまざまな種類のテーブルとルーティンについて説明してきました。今週は、階層内の実行とワークロードの管理リソース(ジョブ、コミットメント、予約、割り当て)について説明します。いつもどおり、SQL と API のサンプルを参照できるよう、ドキュメントにはリンクを掲載しています。
BigQuery のジョブ
ジョブはプロジェクト内のリソースであり、BigQuery が自動で実行するアクションを表しています。ジョブにはいくつかの種類があり、それぞれにプロジェクトごとの割り当てがあります。
読み込み: POST リクエストや Google Cloud Storage などのソースからデータを取り込み、管理テーブルを作成します
クエリ: クエリエンジンを呼び出し、SQL クエリを実行します。これには、SELECT ステートメント、DML、DDL、スクリプト(およびプロシージャ呼び出し)が含まれます
コピー: commit されたデータを 1 つ以上のソースのテーブルから宛先のテーブルへと移動します
エクスポート: 特定の形式とオプションを使用して、テーブルのコンテンツを Cloud Storage に書き込みます
リソースのリストやリソースに関するメタデータの取得などの他のアクションはジョブで管理されません。データを読み込み、クエリ、コピー、エクスポートする際は、BigQuery が自動でジョブをスケジュールして実行します。ジョブには、ユーザー ID(ジョブを実行したユーザー)とロケーション(ジョブを実行した場所)があります。ジョブ自体はデータの保存場所と同じリージョンで実行される必要があるため、BigQuery は、リクエストで参照されるデータセットに基づいてジョブを実行するロケーションを決定します。ジョブで使用するデータは、ジョブ自体の実行場所とは異なる BigQuery プロジェクト内に保存されている場合もあります。
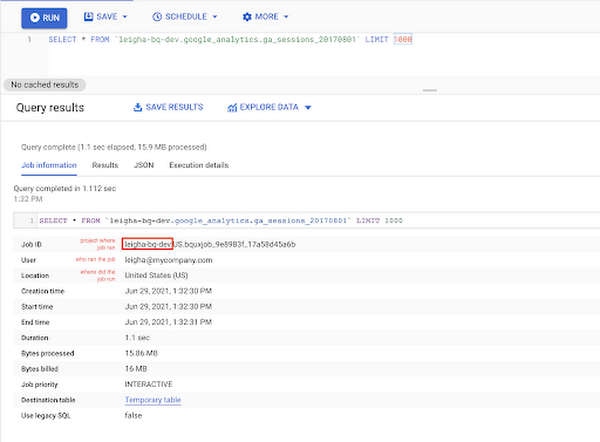
ジョブは完了までに長時間かかることがあるため、BigQuery はジョブを非同期で実行します。各ジョブは独立して実行され、次のジョブを開始する前にジョブを終了させる必要はありません。各ジョブは完了状態になることが保証されています。ジョブが進むにつれ、ジョブの状態をポーリングできます。これは、API を通して、またはクエリジョブのクエリ履歴パネルまたは他のジョブのジョブ履歴パネルのステータスを確認して行えます。ジョブ ID を使用すると、リンクを共有して他の BigQuery ユーザーがジョブに関するメタデータをコンソールで確認することや、情報スキーマをクエリして実行の詳細をクエリすることもできます。

コンピューティング容量
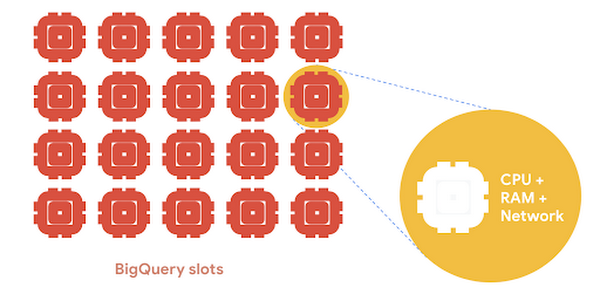
BigQuery 内のデータをクエリする度に、ジョブリソースが自動で作成されて実行されることを学びました。しかし、そのジョブを実行するには、コンピューティング リソースへのアクセスが必要です。それには BigQuery スロットが役立ちます。
スロットはコンピューティング容量の単位です。これは、基本的には、CPU、RAM、ネットワークで構成されるワーカーです。BigQuery は、各タスクの部分を並行して実行する、分割統治の作業を好むため、通常はスロットが多いほどクエリが高速に実行されます。
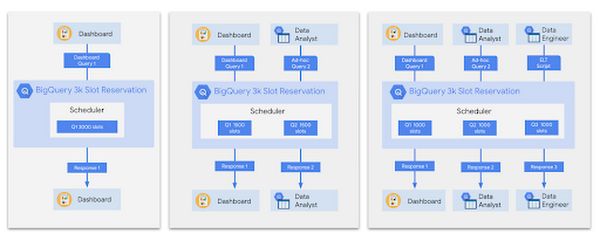
ジョブの実行では、BigQuery は公平なスケジューラを使用します。これは、1 つのクエリが特定のプロジェクトで実行中の場合、そのクエリはそのプロジェクトで利用可能なすべてのスロットへのアクセス権を持つことを意味します。そのため、非常に高速に実行されます。代わりに、2 つのクエリが実行中の場合は、それぞれがスロットの半分の量へのアクセス権を持つことになります。BigQuery は動的クエリ計画機能を使用して、実行を通して何度かチェックインを行い、他に実行中のクエリ数を調査し、それぞれに利用できるスロットの数を判断します。ユーザーにとっては、これは 1 つのクエリがすべてのコンピューティング リソースを独占する可能性が非常に低いことを意味します。
スロット数の制御方法
クエリによって処理されるバイト数に対して支払う、オンデマンド料金を使用する場合は、各プロジェクトで 2,000 スロットを使用できます。定額料金の場合は、容量コミットメントを購入して、専用の数のスロットを購入できます。コミットメントでは、一定の期間、特定のロケーションで、特定の数のスロットを購入します。これは、年間コミットメント、月間コミットメント、Flex コミットメントのいずれかとなります。Flex コミットメントは 60 秒間のみで、60 秒経過後はいつでもキャンセルできます。コミットメントの期間が長いほどスロットあたりの料金は安くなりますが、短い期間のコミットメントは、ワークロードの季節性に対応(ブラック フライデー後に全員が小売のトランザクションのデータを確認する場合など)したり、特定のスロットへのアクセス権を持つクエリをテストしたりする場合に便利です。
BigQuery 予約モデル
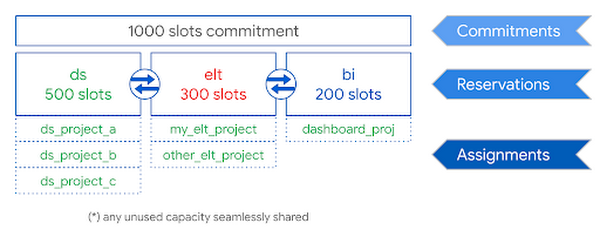
スロットを用意したら、次のステップに進んで予約を作成できます。これは本質的に、組織にとって有益な方法で割り当て可能な、スロットのバケットです。予約を行うと、スロットを特定のプロジェクト、フォルダ、または組織全体に委任する、割り当てを作成できます。たとえば、データ サイエンス(ds)ワークロードに使用される予約を作成し、それにデータ サイエンス フォルダ(ds_project_a、ds_project_b、ds_project_c を含む)を割り当てることができます。BigQuery の大きな特徴の一つとして、アイドル スロットが自動で共有されます。そのため、ds フォルダで誰もクエリを実行していない場合は、ELT またはダッシュボード プロジェクトのワークロードがそれらを代わりに使用できることがあります。
予約が適しているユーザー
次の 2 つのケースに当てはまる場合は、定額料金が最適です。(1)クエリのパフォーマンスを向上させるために、利用可能なスロットの数を増やしたい、(2)費用の予測性と制御性を高めたい。ワークロードが予測可能な場合、つまり、クエリがスキャンするデータ量を把握できる場合は、多くの場合 BigQuery オンデマンドが使用されます。一方、アドホック クエリなどのワークロードは予測できないため、予約を割り当てるのが理にかなっています。2,000 個のスロットのデフォルト以下を割り当てた場合はクエリの実行速度が少し遅くなることがあるものの、請求書の額に驚くようなことはないでしょう。
幸い、すべての BigQuery ワークロードに対して 1 つの料金モデルを選択する必要はありません。オンデマンドで実行される割り当てなしの指定プロジェクトを持つことができます。予約を使い始めたばかりの場合は、何個のスロットを購入する必要があるのかがわからないことがあります。今後数週間でスロットの使用率の監視と予約のサイジングなどの詳細について学びますが、現時点ではこちらのブログ投稿をご覧いただき、これらのデータポータルのテンプレートと Looker BigQuery モニタリング ブロックをご確認ください。
このシリーズの最新情報を見逃さないように、ぜひ LinkedIn と Twitter で私をフォローしてください。
-デベロッパー アドボケイト Leigha Jarett




