BigQuery Admin reference guide: Jobs & reservation model

Leigha Jarett
Developer Advocate, Looker at Google Cloud
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialSo far in our BigQuery Admin Reference Guide, we’ve discussed the BigQuery resource model and talked through the different types of tables and routines. This week, we’re talking about execution and workload management resources within the hierarchy - jobs, commitments, reservations and assignments. As always, we’ll include links back to the documentation so you can walk through SQL and API examples.
BigQuery jobs
A job is a resource within a project, it represents an action that BigQuery runs on your behalf. There are several different job types, each with its own per-project quota.
- Load: ingests data from a POST request, Google Cloud Storage or other sources to create a managed table
- Query: invokes the query engine to execute a SQL query. This includes SELECT statements, DML, DDL, and scripts (as well as procedure calls)
- Copy: moves committed data from one (or more) source tables to a destination table
- Export: writes the contents of a table out to Cloud Storage using the specified format and options
Other actions like listing resources or getting metadata about resources are not managed by a job. When you load, query, copy or export data, BigQuery schedules and runs the job for you. A Job has a user identity (who ran the job), and a location (where the job was run). BigQuery determines the location to run the job based on the datasets referenced in the request, since the job itself must be run in the same region where the data is stored. The data you are leveraging in the job may be stored in a different BigQuery project than where the job itself is executed.
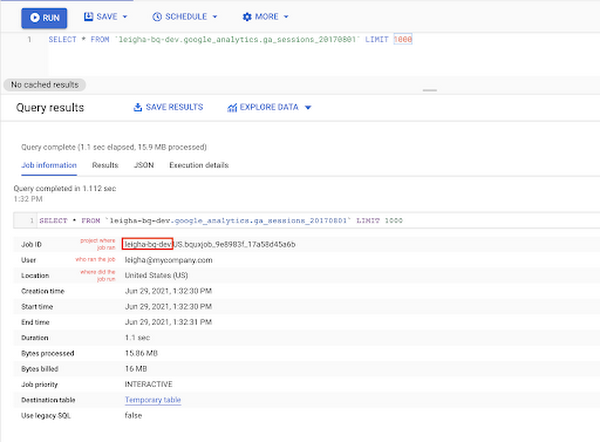
Because jobs can potentially take a long time to complete, BigQuery executes them asynchronously - each job is run independently, and you don’t need one to finish before starting the next. Each job is guaranteed to make progress to a Done state. You can poll the job for its state as it progresses - either through the API or by checking the status in the Query History panel for query jobs or the Job History panel for other jobs. Using the Job ID, you can also share a link so that other BigQuery users can view metadata about the job in the console, or query the information schema for execution details.

Compute capacity
So now you know that each time you’re querying data inside of BigQuery, a job resource is created and executed on your behalf. But, in order for that job to run it needs access to computational resources. This is where a BigQuery slot comes into play!
A slot is a unit of computational capacity. It’s basically a worker, made up of CPU, RAM and Network. Since BigQuery likes to divide-and-conquer work - running parts of each task in parallel - more slots usually means that the query will run faster.

When it comes to executing jobs, BigQuery uses a fair scheduler. This means that if one query is running in a specific project, that query will have access to all of the slots available for that project - so it should run really fast! If, instead, two queries are executing then they will each get access to half the amount of slots, and so on. BigQuery uses its dynamic query planning capabilities to check in at various times throughout execution and figure out how many other queries are running to determine how many slots are available for each one. For you, this means that it’s very unlikely that one query will hog all the compute resources!
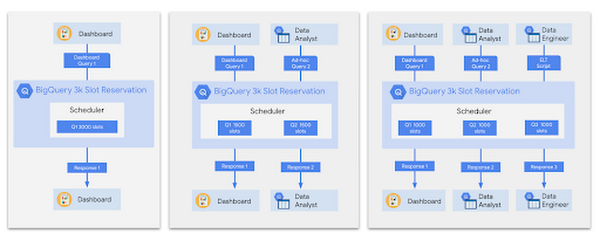
How do I control the number of slots?
If you use on-demand pricing, where you pay for the number of bytes processed by queries, then you’ll get access to 2,000 slots in each project. With flat-rate pricing you can purchase a dedicated number of slots by buying a capacity commitment. Commitments purchase a specified number of slots, over some duration of time, in a certain location. This can either be an annual commitment, monthly commitment or a flex commitment. Flex commitments are only 60 seconds, meaning you can cancel any time after 60 seconds. While longer term commitments offer reduced per-slot pricing, shorter term commitments can be useful to handle seasonality in your workloads (e.g. everyone is analyzing your retail transactions data after Black Friday) or test out queries with access to specific slots.
The BigQuery reservation model
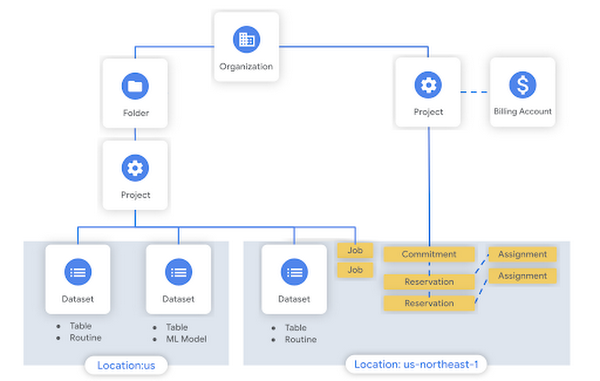
Once you have your slots, you can go one step further and create a reservation. This is essentially a bucket of slots that can be allocated in ways that make sense for your organization. With a reservation in place, you can create an assignment that delegates the slots to specific projects, folders, or the entire organization. For example, we might create a reservation to be used for data science (ds) workloads, and then assign the data science folder (containing ds_project_a, ds_project_b and ds_project_c) to it. One great thing about BigQuery is that it automatically shares idle slots, so if no one is running queries in the ds folder, workloads from elt or dashboard projects can use them instead.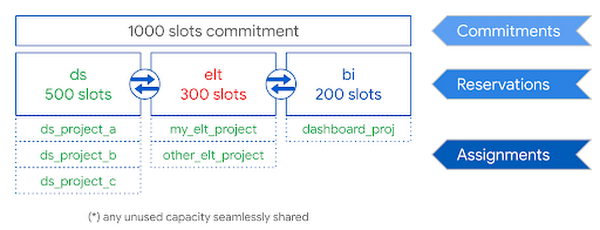
Who needs a reservation?
Flat-rate pricing is most applicable for two reasons: (1) you want to increase the number of slots available to improve a query’s performance, or (2) you want to have predictable and controlled costs. Many times customers use BigQuery on-demand when workloads are predictable, meaning they have a good idea of how much data the queries will scan. On the flip side, workloads like ad-hoc querying are not predictable, so it makes sense to assign a reservation - it might be the case that the query runs a bit slower, if you have allocated less than the 2,000 slot default, but there will be no surprises when you get your bill.
Fortunately, you do not need to pick one pricing model for all your BigQuery workloads - you can have designated projects without an assignment that will run on-demand. If you’re just getting started with reservations you’re probably wondering - how many slots do I need to buy? We’ll be going into details on monitoring slot utilization and sizing your reservation in a few weeks, but in the meantime check out this blog post, and look into these Data Studio templates and the Looker BigQuery Monitoring Block.
Be sure to keep an eye out for more in this series by following me on LinkedIn and Twitter!




