Cloud Run と Vertex AI で Inference as a Service を活用する
Jason (Jay) Smith
Customer Engineer - AppMod Specialist
※この投稿は米国時間 2025 年 2 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
大規模言語モデル(LLM)や生成 AI がアプリケーション分野の重要な一部となっていることは、もはや周知の事実です。しかし、基盤となる LLM はサービスとして利用されている、つまり、第三者によってホストおよび提供され、API 経由でアクセスされているのが現状です。最終的に、この外部 API への依存はデベロッパーにとってのボトルネックを生み出します。
アプリケーションのホスト方法には、確立されたものが多数あります。つい最近まで、それらのアプリケーションを支える LLM については同じことが言えませんでしたが、それは変化しています。生産性を向上させるために、デベロッパーは Inference as a Service と呼ばれるアプローチを検討できます。これにより、LLM を活用したアプリケーションにどのようなメリットがあるのかを詳しく見ていきましょう。
Inference as a Service とは
クラウドにおいては、すべてがサービスです。たとえば、アプリケーションやデータベースをホストするために物理サーバーを購入するのではなく、クラウド プロバイダからそれらを従量制のサービスとして購入します。ここでのキーワードは「従量制」です。エンドユーザーとして、使用したコンピューティング時間やストレージに対して料金をオンラインで支払います。「Software as a Service」、「Platform as a Service」、「Functions as a Service」などは、10 年以上前からクラウド用語として使われています。
「Inference as a Service」は、運用上のオーバーヘッドを抑えながら、エンタープライズ アプリケーションを ML モデル(この場合は LLM)と連携させることができます。つまり、インフラストラクチャにとらわれず、LLM と連携するためのコードを実行できるということです。
Inference as a Service に Cloud Run を選ぶ理由
Cloud Run は、Google Cloud のサーバーレス コンテナ プラットフォームであり、簡単に言うと、デベロッパーがインフラストラクチャを気にすることなくコンテナ ランタイムを活用できるよう支援します。従来、サーバーレスは関数を中心に展開されてきました。Cloud Run は サーバーレスで、サービスが実行されているときのみ料金が発生するため、LLM を活用したアプリケーションの実行に適しています。
Cloud Run を利用して LLM の推論を実行する方法は多数あります。今回は、Cloud Run 上で GPU を使用してオープン LLM をホストする方法を紹介します。
まずは、Vertex AI について理解しましょう。Vertex AI は、企業が ML モデルをトレーニングし運用するために必要な基本機能を備えた、Google Cloud の統合型 AI / ML プラットフォームです。Vertex AI では、ファーストパーティ モデル(Gemini)、サードパーティ モデル、オープンソース モデルを含む 160 以上の基盤モデルを提供する Model Garden にアクセスできます。
Vertex AI で推論を行うには、まず Gemini API を有効にします。Vertex AI の標準モードまたはエクスプレス モードを使用できます。次に、適切な Google Cloud の認証情報をアプリケーションに追加します。これだけで、アプリケーションをコンテナとして Cloud Run にデプロイし、Vertex AI とシームレスに連携させて推論を実行できます。こちらの GitHub サンプルを使用して、ご自身でお試しいただけます。
Vertex AI はマネージド推論エンドポイントを提供していますが、Google Cloud は Cloud Run 向け GPU で新たなレベルの柔軟性も提供しています。これは推論のパラダイムを根本的に変えるでしょう。その理由は、Vertex AI のインフラストラクチャのみに依存する代わりに、LLM(または他のモデル)をコンテナ化して Cloud Run に直接デプロイできるようになったからです。
つまり、単に LLM の周りにサーバーレスのレイヤを構築するのではなく、LLM 自体をサーバーレス アーキテクチャ上でホストできるということです。モデルは非アクティブ時にはゼロまでスケールダウンし、需要に応じて動的にスケールするため、コストとパフォーマンスを最適化できます。たとえば、LLM を 1 つの Cloud Run サービス上にホストし、チャット エージェントを別のサービス上にホストすることで、それぞれを独立してスケールおよび管理できるようになります。さらに、GPU アクセラレーションを活用すれば、Cloud Run のサービスは 30 秒以内に推論を実行できる状態になります。
RAG を活用して LLM をカスタマイズする
LLM では、ホスティングやスケーリングだけでなく、特定のドメインやデータセットに合わせて応答のカスタマイズが必要になることがよくあります。ここで登場するのが検索拡張生成(RAG)です。これは LLM のエクスペリエンスを充実させるための中核的な要素であり、コンテキストに応じたカスタマイズの標準として急速に普及しています。
このように考えてみてください。LLM は広範なデータセットでトレーニングされていますが、お客様のアプリケーションはお客様独自のデータを活用する必要があります。RAG は AlloyDB のようなベクトル データベースを使用して、プライベート データのエンベディングを保存します。アプリケーションが LLM にクエリを実行すると、RAG は関連するエンベディングを取得し、LLM に必要なコンテキストを提供することで、具体的で正確な応答を生成できるようにします。
ここで Inference as a Service を活用する方法がいくつかあります。たとえば、このアーキテクチャを見ると、Cloud Run がコアとなる推論ロジックを処理し、Vertex AI と AlloyDB とのやり取りをオーケストレートしていることがわかります。具体的には、Cloud Run は AlloyDB からデータを取得し、Vertex AI にクエリを渡す役割を果たし、RAG のデータフロー全体を効果的に管理します。
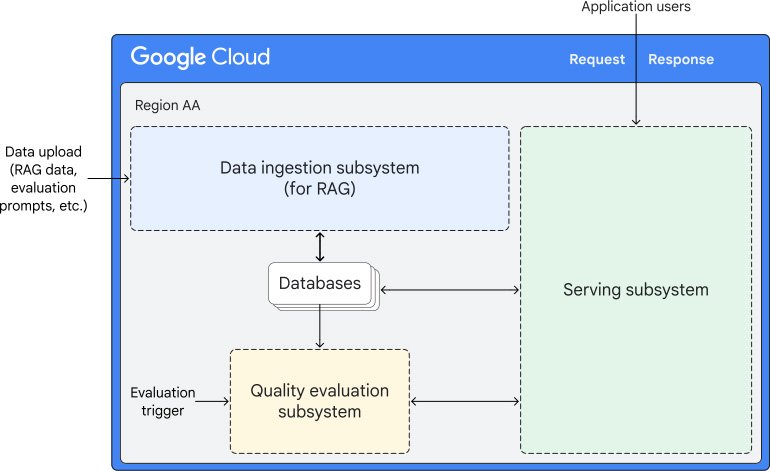
具体的な例で考えてみる
chatbot のアーキテクチャを考えてみましょう。以下のアーキテクチャでは、Cloud Run を使用して chatbot をホストしています。開発者は、Streamlit や LangChain などの一般的な chatbot ツールを使用してアプリケーションを作成できます。その後、Vertex AI Model Garden でホストされている LLM で推論を行い(または別の Cloud Run インスタンスを使用することも可能)、エンベディングを AlloyDB に保存できます。これにより、すべてがサーバーレスの環境上で動作する、カスタマイズ可能な生成 AI chatbot を実現できます。




