Cloud Monitoring で Google Cloud のオブザーバビリティ コストを特定して削減する方法
Google Cloud Japan Team
※この投稿は米国時間 2023 年 4 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
重要ならば測定すべし。この格言は、過去 10 年間にわたって、モニタリングおよびオブザーバビリティ市場の爆発的な成長を下支えしています。残念ながら、多くの組織は使用しているツールのメリットを活用するのに苦労しており、より多くのインサイトを得られないまま予算が膨張する状況に陥っています。
Google Cloud では、Cloud オペレーション スイートが Google Cloud ワークロードのテレメトリーの最初のソースになります。2022 年の IDC レポートでは、アンケート回答者の半数以上が、パブリック クラウド プラットフォームの管理ツールとモニタリング ツールの方がサードパーティのツールより価値があると回答しています。
以前、私たちは Cloud Logging を使用してコストを削減する方法を紹介しました。今回は、Cloud Monitoring に関連するコストの削減方法を紹介します。
Cloud Monitoring の簡単な概要:
Google は、ロギングおよびモニタリング サービスのポートフォリオ全体でシンプルな従量課金制モデルを使用しています。ユーザーは、完全なコントロールと透明性が得られるため、使用した分だけ料金を支払います。
Google Cloud 全体のサービスについて、Google は複数の無料の指標を提供しています。サービスを有効にすると、これらのシステム指標を追加料金なしで取得できます。計測またはアクションも不要です。
Google は、ダッシュボード ビルダー、Metrics Explorer、アラートなどのツールも提供しています。これらを使用すると、指標の把握が容易になり、追加料金なしでプロアクティブな通知を受け取れます。
ワークロード用にデプロイするカスタム指標(Ops エージェント指標、カスタム指標、Prometheus 指標など)のみが課金対象ですので、オブザーバビリティの目標に合わせて請求額を簡単に調整できます。
以上を念頭に置いて、コストを削減するための実用的なヒントをいくつかご覧ください。
現在のコストと主なコスト要因を把握する
クラウドまたは IT のコストと同様、コストの最適化を開始する前に、モニタリング コストのベースラインと主なコスト要因を把握することが重要です。それにより、適切にトレードオフを行い、不要なテレメトリーと支出を取り除くことができます。現在のコストと、それと引き換えに得られるものを把握するには、以下を確認してください。
Cloud Monitoring の料金体系を理解する
Google の料金体系には透明性があり、サービス全体で数千の Google Cloud 指標が自動的に追加料金なしで利用できます。ただし、次のような一部の指標とアクティビティは課金対象です。
Google の Ops エージェントによって生成された指標、カスタム指標、ログベースの指標の送信。これらはすべて取り込みが MiB 単位で課金され(アカウントごとに月あたり 150 MiB の無料枠があります)、保持については追加料金がかかりません。
Google Cloud Managed Service for Prometheus からの指標の送信。これは取り込まれたサンプルごとに課金され、保持期間は 2 年間です。
Cloud Monitoring API による指標の読み取り。これは 1,000 回の API 呼び出しごとに課金され、請求先アカウントごとに月あたり最初の 100 万回の API 呼び出しに無料枠が適用されます。
クラウド請求レポート
Cloud コンソールで [課金] に移動し、請求先アカウントを選んで [レポート] を選択します。次に、右側の [フィルタ] -> [サービス] で、サービスとして [モニタリング] を選択します。プロジェクトごとのモニタリング支出の内訳が表示され、経時的な傾向を比較できます。少数のプロジェクトが支出の大部分を占めていることを目にするケースが少なくないはずです。これは、おそらく本番環境アプリケーションの計測が多いことが理由です。予想どおりかもしれませんが、コスト要因を知ることは重要です。
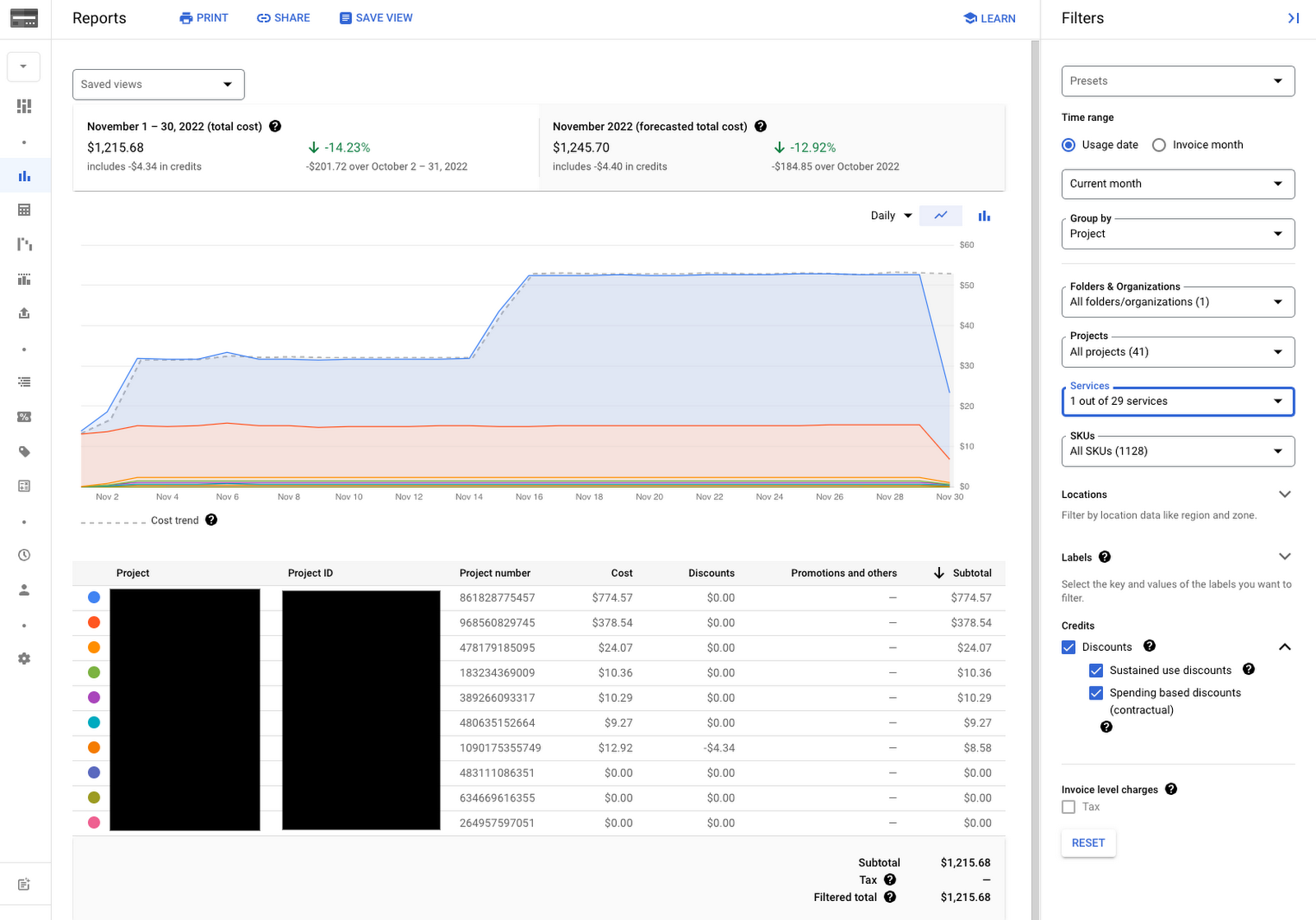
Billing UI には、コスト内訳、予算編成、予算アラートのためのさまざまなツールも用意されています。これらはすべて、すべての課金対象の Google Cloud サービス(Cloud Logging や Cloud Trace などの他の Cloud オペレーション プロダクトや、お客様が使用している他のすべての Cloud プロダクトを含む)で利用できます。
指標の診断
Cloud Monitoring でどのプロジェクトに支出しているかがわかったら、ツールを使用して、オブザーバビリティ コストに影響している指標を簡単に把握し、使用されていないノイズの多い指標への支出を削減する方法を確認しましょう。まず、[モニタリング] → [指標の診断] に移動します。このページには、指標の取り込みと Monitoring API の使用状況を把握するためのさまざまなツールがあります。そうしたツールの一つは「指標」表です。この表では、(a)取り込まれた量またはサンプル、(b)指標のカーディナリティ、(c)指標の名前とドメイン、(d)指標ラベル、(e)プロジェクト、(f)エラー率などによって、指標の並べ替えと絞り込みを行えます。カーディナリティやドメインなどの情報の使用方法についてはこのブログの後半で詳しく説明しますが、最初は、取り込み量に影響している主な指標を正確に特定するために、[指標データの取り込み] で指標を降順に並べ替えることをおすすめします。多くの場合、少数の指標または指標タイプのみが消費の大部分に影響していることに気づくはずです。それらはコストの削減と最適化を行う機が熟している指標であると言えます。
また、各指標の右側にあるその他メニューを使用すると、Metrics Explorer で特定の指標を詳しく調べたり、指標のアラート(たとえば、特定の指標の急増と急減などの傾向を知らせるアラートなど)を簡単に作成したり、指標に関連する監査ログを確認したりすることができます。ページの上部では、クリックするだけで表の時間範囲を変更してデータを再計算することができます。
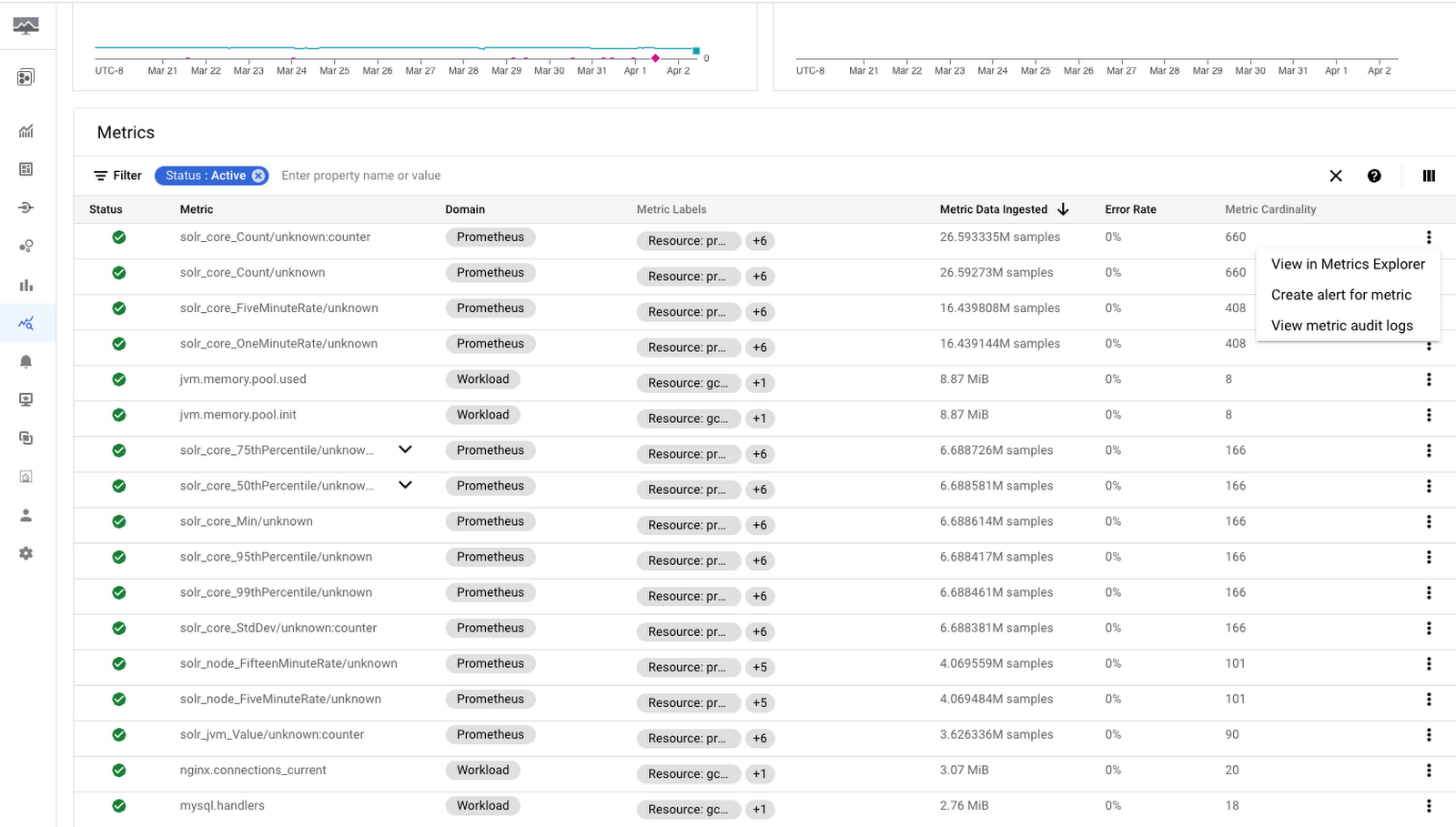
Cloud Monitoring でどのプロジェクトに支出しているかがわかったので、請求額を削減するための一般的なオプションをいくつか見てみましょう。
課金対象の指標を使用するタイミングを決定する
前述のように、Cloud Monitoring の多くの指標は無料で提供されています。では、課金対象の指標を含めるべきシナリオにはどのようなものがあるでしょうか?
粒度
Compute Engine インスタンスの CPU 使用率の測定またはアラートに焦点を当てた非常にシンプルな例を見てみましょう。これには、次の無料の指標を使用できます。
compute.googleapis.com/instance/cpu/utilization
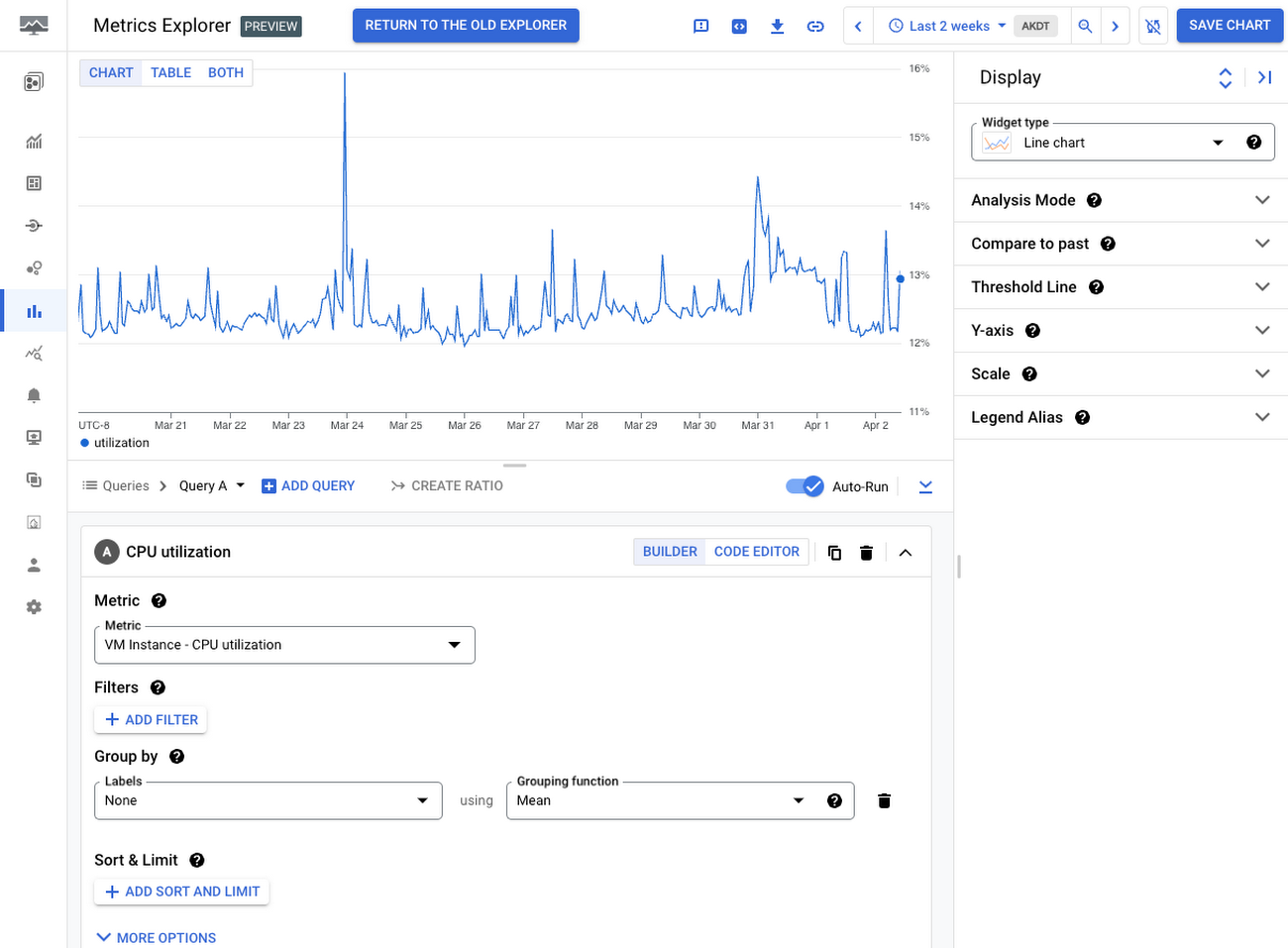
上のビューの指標は、Compute Engine インスタンスが実行されているハイパーバイザ ホストから取得されています。Compute Engine インスタンスを効率的にモニタリングするには、これだけで十分かもしれません。たとえば、組織の多くは、特定のワークロードとアプリケーションに対して無料のシステム指標のみを使用することを選択しており、カスタム指標またはエージェント指標の粒度を上げる必要は特に感じていません。
これに対して、SLO が厳しい本番環境の顧客向けアプリケーションの多くでは、アプリケーションの健全性をプロアクティブにモニタリングし、より効率的にトラブルシューティングを行い、チームの平均検出時間と解決時間を短縮するために、粒度の高い高度な指標が必要です。
前の例で言うと、おそらくは VM が実際に CPU をどの程度使用しているかについて、より詳細な分析情報が必要になります。そのためには、Ops エージェントをデプロイして、オペレーティング システム内から指標を収集します。次の例は同じホストを示しており、OS 自体が CPU の使用率に関する状態を実際に報告していることがわかります。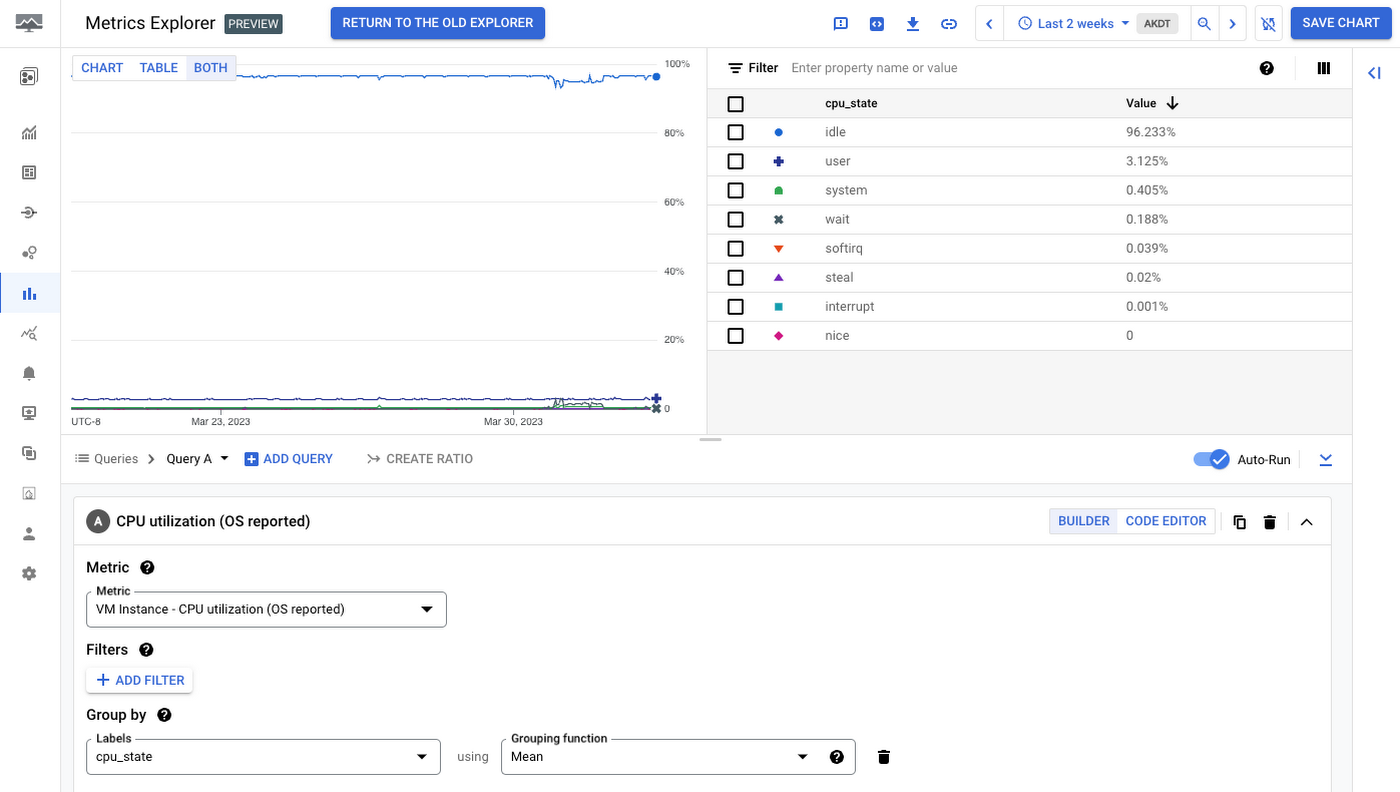
次に、この VM または VM のセットで実際に CPU 消費を促しているライブプロセスを把握します。Ops エージェントから取得される課金対象の指標を使用すると、プロセス、コマンド、PID などで CPU 使用率を細かく切り分けて分析できます。
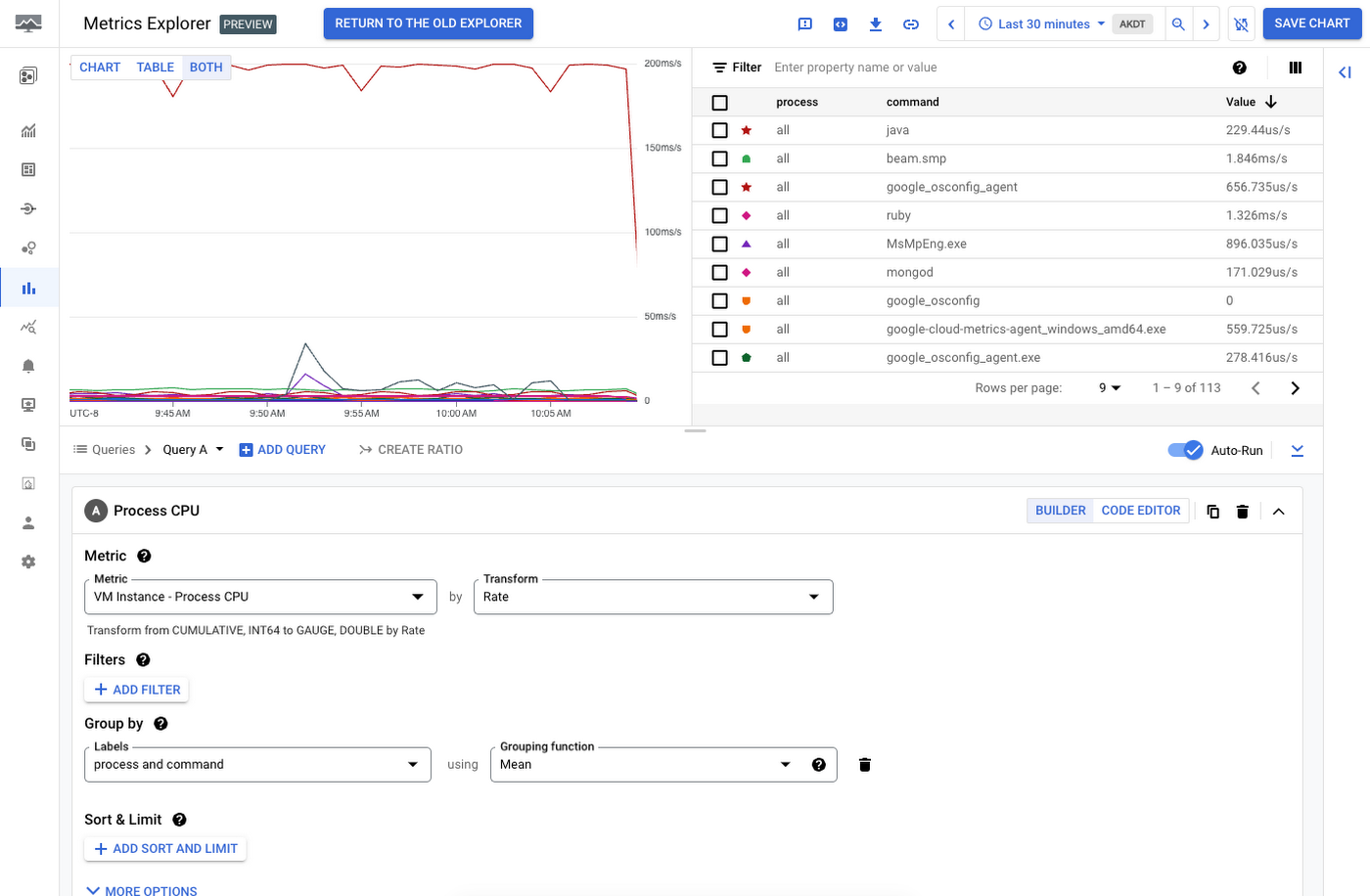
すべての本番環境ワークロードでこのレベルの粒度が必要になるわけではありませんが、特に重要なワークロードでは、このような追加のテレメトリーと分析情報が必要になる場合があります。同様に、多くの本番環境ワークロードでは、組織が使用しているクラウド設定に固有のカスタム指標が必要になる場合があります。最終的には、どのような場合にシステム指標で十分なのか、どのような場合に追加のカスタム テレメトリーが必要なのかを、プラットフォーム チームとエンジニアリング チームが協力して決定する必要があります。
モニタリング コストを削減するための戦略
全体的なモニタリング コストに大きく影響する可能性のあるモニタリング コストを削減できる戦略は、片手で数えるほどしかありません。
カーディナリティを減らす
テレメトリーとオブザーバビリティに携わる人のほとんどはカーディナリティの概念に精通しているでしょうが、重要なのは、カーディナリティが全体的なコストに大きく影響する可能性を認識することです。上記の指標の診断 UI の [カーディナリティ] 列と [指標ラベル] 列を見ると、取り込み量が多い指標はカーディナリティも高いかどうかを確認できます。また、追加のラベルとカーディナリティが本当にオブザーバビリティの価値を高めているのか、それともノイズとコストを増やしているだけなのかを判断できます。たとえば、エンドポイントごとの粒度が有用な指標もありますが、他の指標は、エンドポイント単位の定期的な分析は不要で、すべてのパスで集約的にモニタリングしてもまったく問題ないことがあります。最も深刻なケースとして、ユーザーが「sessionID」や IP アドレスなどの情報のラベルを不注意に追加しようとすることがあります。この種のカーディナリティの高いメタデータは、ほぼ間違いなく、指標ラベルとして記録するのではなく、生のログに記録する必要があります。
特に Prometheus 指標については、指標の量が多いケースや、ユーザーが不要なカーディナリティを追加するケースがよくあります。Google が提供している Metrics Explorer の追加ツールを使用すると、取り込み量に大きく影響している指標を迅速に特定し、それらを生成している名前空間と簡単に結び付けることができます。
指標を書き込む頻度を減らす
有用な課金対象の指標でコスト削減が必要な場合、容易ではあるが見過ごされがちな対処法として、指標の送信頻度を減らすという方法があります。もう一度 Ops エージェントの例を取り上げると、プロセスごとのメモリ指標は有用であるとはいえ、おそらく 1 分ごとではなく 2 分ごとの報告が許容できます。次のように Ops エージェントの指標構成を変更すると、60 秒間隔ではなく 120 秒間隔で書き込むようにすることができます。
あとはエージェントを再起動するだけです。最終的に同じ料金ティアになると仮定すると、この指標の全体的なコストは約半分に削減されます。同様に、カスタム指標を Cloud Monitoring に書き込む場合は、指標が必要になる頻度と、精度と頻度に関する全体的な要件を考慮し、それに応じて指標を減らしてください。たとえば、特定のカスタム指標または Prometheus 指標は、5~10 秒のような高い頻度の間隔で書き込むのではなく、数分ごとにサンプリングすればよい場合があります。
不要な指標を削除する
過去にオブザーバビリティに必要だった指標が不要になったことや、特定の Ops エージェント指標は必要であるものの、他の指標は有用でないことに気づいた場合は、当然ながら、使用していない指標を消費して料金を支払わないようにすることをおすすめします。Ops エージェント構成 YAML を使用すると、包含フィルタまたは除外フィルタを簡単に追加して、必要と思われる指標のみを指定できます。上記の例を見ると、プロセス指標はアプリケーションのモニタリングとデバッグにとって必要不可欠ですが、VM によって送信されたネットワーク パケットの総数はおそらくそれほど有用ではありません。この場合は、Ops エージェントがそれを取り込まないように、exclude_metrics フィルタを追加するだけで済みます。
同様に、カスタム指標、ログベースの指標、または Prometheus 指標の取り込み量が多い場合も、同じ対処法をおすすめします。チームがモニタリング、アラート、またはその他のトラブルシューティングのシナリオで使用していない指標がある場合は、それらを完全に除外するか、少なくとも頻度とカーディナリティを減らすことを検討してください。
ヒストグラム / 分布としてではなく集約された単一ポイントとして指標を書き込む
値タイプの分布の指標は、ヒートマップなどの斬新な方法でデータを可視化する場合や、50 パーセンタイルや 99 パーセンタイルの統計を迅速に計算する場合に効果的です。ただし、分布では取り込みのコストが高くなる可能性もあります。その原因は、Prometheus の料金体系ではゼロでない各ヒストグラム バケットが追加ポイントとして課金されることや、Prometheus 以外の取り込みで書き込まれたデータポイントごとに 80 バイトで課金が発生することです。
特にカスタム指標については、ヒストグラムが実際に必要かどうか、中央値、平均値、最大値を事前に計算して単一ポイントとして書き込むだけで十分かどうかを慎重に検討してください。たとえば、ある種のアプリケーションでは、最大または平均のレイテンシをトラッキングするだけでよく、分布指標タイプで可能なより複雑な統計モデリングを行う必要はおそらくありません。
より多くの Prometheus 指標を使用することを検討する
以前に説明したように、Prometheus 向けのマネージド サービスでは、指標は MiB 単位ではなくサンプルごとに課金されます。Prometheus は Kubernetes モニタリングの事実上の標準であり、この効率的なサンプルごとの料金体系は、Kubernetes ワークロードが大量のテレメトリーを生成できるという前提に基づいて設計されています。最近 Google は、Ops エージェントに組み込まれた Prometheus のサポートを発表しました。すでに組織で Google Cloud Managed Service for Prometheus を使用または評価している場合、またはその予定がある場合は、サンプルごとの Prometheus コレクションでテレメトリー コレクションを統合することにより、MiB 単位のカスタム料金に比べて大幅なコスト削減も実現できます。こちらでは、上記のヒントと戦略に基づき、Prometheus ユーザー向けにコスト管理と属性について詳しく説明しています。
Prometheus の使用の決定に際しては、複数のオープンソース Prometheus エクスポート ツールが、VM で通常生成されるよりはるかに多くのサンプルを生成することが重要なヒントの一つになります。そのため、1 対 1 の指標ベースでコスト削減を確認できるとはいえ、Prometheus を使用する場合は上記の方法を使用することと、組織にとって適切なテレメトリーを確実にキャプチャすることを強くおすすめします。
運用上の負担と手間が増えないように注意する
結局のところ、オブザーバビリティ ソリューションを選択する際はコストを要因として考慮しなければなりませんが、ほとんどの組織にとってコストは唯一の要因ではないことを覚えておく必要があります。モニタリング ソリューションを評価する際は、自社製または社内のモニタリング スタックを実行および維持するために必要となる継続的な運用上のオーバーヘッド、メンテナンス、サポートを考慮に入れて、総所有コストを検討することが重要です。組織の従業員、チーム、全体的な組織文化にどのような影響を与えるかを認識せずに、完全に「無料」のソリューションを使用すれば十分であると思い込む罠にも注意しましょう。
上記のヒントがお役に立てば幸いです。ご不明な点がありましたら、Google Cloud コミュニティから質問をお寄せください。
- Cloud Ops、プロダクト マネージャー Kyle Benson
- シニア プロダクト マネージャー Haskell Garon


