BigQuery ML の新機能でデータから AI への移行を加速
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
AI は転換期を迎えており、さまざまな業界やユースケースで AI の影響を目の当たりにする機会が増えています。魅力的なカスタマー エクスペリエンスの創出から運営の最適化や定型業務の自動化まで、さまざまなレベルの ML の専門知識を持つ組織が AI を使ってビジネス的に重要な問題を解決しています。これらの組織は、イノベーションを加速させ、最終的には市場で優位に立つために学んでいます。しかし、多くの組織で AI や機械学習システムはデータ ウェアハウスやデータレイクから分離され、サイロ化されているケースが散見されます。これによって、データと AI のギャップが広がり、データを活用したイノベーションが制限されています。
Google Cloud は、AI 開発における長年の経験を生かし、お客様がデータから AI に可能な限りシームレスに移行できるようにしました。Google のデータクラウドは、チームによるデータ活用を簡素化します。Google の組み込みの AI / ML 機能は、ユーザーが現在いる場所から現在もっているスキルで対応できるように設計されています。また、Google のインフラストラクチャ、ガバナンス、MLOps の機能は、組織による AI の大規模な活用を支援します。
このブログでは、BigQuery ML と Vertex AI を使用して ML ワークフローを簡素化する方法について説明し、BigQuery ML における最新のイノベーションを紹介します。
BigQuery ML と Vertex AI で機械学習ワークフローを簡素化する
データベース、分析、機械学習の管理に対してサイロ化されたアプローチを取っている組織では、多くの場合、データをあるシステムから別のシステムに移動する必要があります。これは、信頼できる唯一の情報源がないためデータの重複につながり、セキュリティとガバナンスの要件の遵守を困難にします。
さらに、ML パイプラインを構築する場合、モデルのトレーニングとデプロイを行う必要があるため、スケールに応じたインフラストラクチャの計画が必要になります。また、ML モデルがインフラストラクチャ上で効率的に実行されるように調整と最適化を行う必要もあります。たとえば、モデルを迅速にトレーニングできるように、大規模な Kubernetes クラスタのセットや、GPU ベースのクラスタへのアクセスが必要になる場合があります。このため、組織は、Python や Java などのプログラミング言語に関する深い知識と高度なスキルをもつ専門家を雇用せざるを得ません。
Google のデータクラウドは、これらの課題を克服し、機械学習ワークフローを簡素化するために役立つ、データと AI の統合ソリューションを提供します。BigQuery のサーバーレスでスケーラブルなアーキテクチャにより、データに対して、強力で信頼できる唯一の情報源を作成できます。BigQuery ML は、使い慣れた SQL インターフェースを通じて機械学習機能をデータ ウェアハウスに直接提供します。BigQuery ML と Vertex AI のネイティブな統合により、MLOps ツールを活用してモデルのデプロイ、スケーリング、管理を行うことができます。
BigQuery ML と Vertex AI は、組織全体における AI の導入を加速させます。
簡単なデータ管理: BigQuery からデータを移動することなく ML ワークフローを管理し、セキュリティやガバナンスの問題を解消できます。データストア内でワークフローを管理できるため、ML の開発と導入における大きな障壁が取り除かれます。
インフラストラクチャ管理のオーバーヘッド削減: BigQuery は、Google のコンピューティングとストレージの大規模なインフラストラクチャを利用しています。ML を効果的に実行するために、巨大なクラスタや HPC インフラストラクチャを管理する必要はありません。
スキルセットの障壁除去: BigQuery ML は SQL ベースです。これにより、回帰、分類、レコメンデーション システム、ディープ ラーニング、時系列、異常検出など、多くのモデルタイプを SQL で直接利用できます。
モデルのデプロイと ML ワークフローの運用化: Vertex AI Model Registry により、BigQuery ML モデルを Vertex AI REST エンドポイントに簡単にデプロイして、オンライン予測やバッチ予測を行うことができます。さらに、Vertex AI Pipelines によって ML ワークフローが自動化されるので、データの取り込みからモデルのデプロイまでを、ML システムをモニタリングし、状況を把握しながら確実に行うことができます。
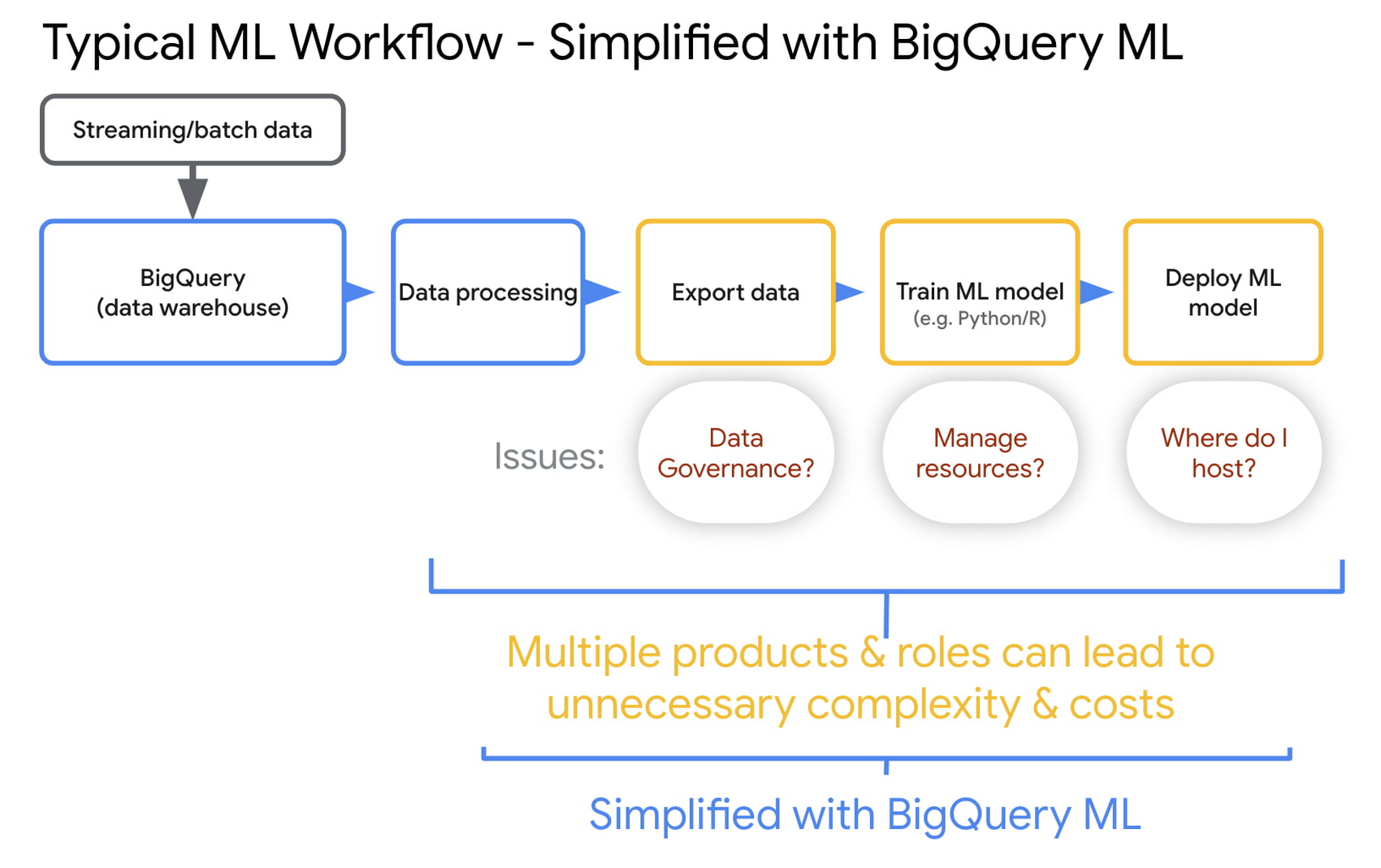
BigQuery ML の使用を開始する際の 3 つのステップ
ステップ 1: データを BigQuery に取り込む。Pub/Sub 経由で、BigQuery のユーティリティやパートナー ソリューションを使ってリアルタイムまたはバッチでデータを自動的に取り込みます。また、BigQuery では、オブジェクト ストレージに存在する Parquet / Hudi などのオープンソース形式のデータに、BigLake を使用してアクセスできます。詳しくは、BigQuery へのデータの読み込みの概要をご覧ください。
ステップ 2: モデルをトレーニングする。BigQuery で単純な SQL クエリ(モデル作成)を実行してモデルをトレーニングし、データセットを指定します。BigQuery はコンピューティングとストレージに高いスケーラビリティを備えており、1,000 行のデータセットにも数十億行のデータセットにも対応できます。詳しくは、BigQuery ML でのモデルのトレーニングをご覧ください。
ステップ 3: 予測を開始する。単純な SQL クエリを使用して、新しいデータに対して予測を実行します。BigQuery ML は、需要予測、異常検出、顧客の新規セグメント予測など、さまざまなユースケースをサポートしています。サポートされているモデルの一覧をご確認ください。予測の実行、異常検出、需要予測についての詳細をご覧ください。

BigQuery ML の新機能で効果を高める
Google Cloud は Next ‘22 で、迅速かつ容易に ML を大規模に運用化するために役立つ、BigQuery ML のいくつかの革新的な機能を発表しました。早期アクセスを利用して、これらの新機能を確認するには、こちらのお問い合わせフォームを送信してください。
1. MLOps とパイプラインによってスケーリングする
組織全体で多くのモデルをトレーニングしている場合、モデルの管理、結果の比較、再現性のあるトレーニング プロセスの作成は非常に難しい課題です。新機能により、Vertex AI の MLOps 機能を使って BigQuery ML モデルの運用化とスケーリングを簡単に行えるようになります。
BigQuery ML モデルを含むすべてのモデルのデプロイを管理、統制するための一元的な場所を提供する Vertex AI Model Registry が一般提供となりました。Vertex AI Model Registry は、バージョン管理や ML メタデータのトラッキング、モデルの評価と検証、デプロイ、モデルのレポート作成に使用できます。詳しくはこちらをご覧ください。
ML の大規模な運用化をさらに支援するもう一つの機能が Vertex AI Pipelines です。これは、各 ML タスク(モデルのトレーニング、モデルの評価、エンドポイントへのデプロイなど)を手動で別々にトリガーするのではなく、単一のパイプラインとして実行できるように ML タスクをオーケストレーションするサーバーレス ツールです。Google Cloud では 20 以上の BigQuery ML コンポーネントを導入して、BigQuery ML オペレーションのオーケストレーションを簡素化しています。これにより、開発者や ML エンジニアは、BigQuery ML ジョブを呼び出すための独自のカスタム コンポーネントを作成する必要がなくなります。さらに、SQL よりもコードの実行を好むデータ サイエンティストの方は、BigQuery ML でこれらの演算子を使用してトレーニングや予測を行えるようになりました。
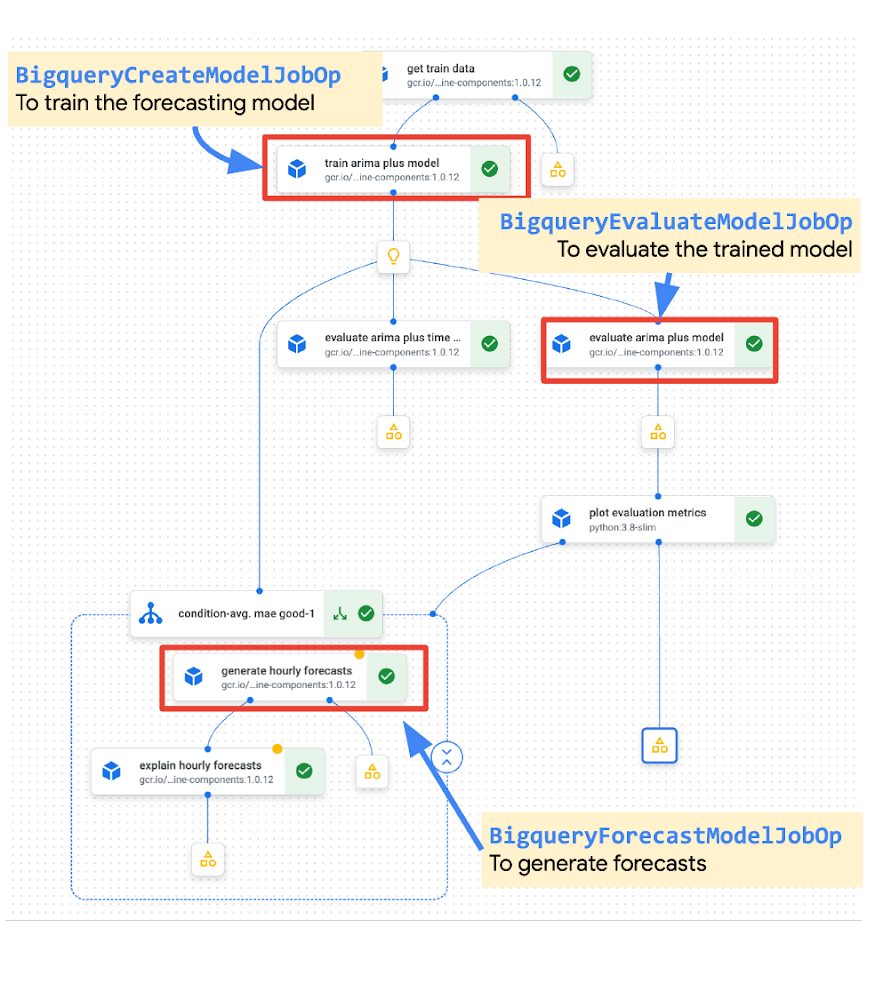
2. 非構造化データから分析情報を引き出す
Google Cloud は先日、BigQuery の新しいテーブルタイプであるオブジェクト テーブルのプレビュー版を発表しました。オブジェクト テーブルでは、画像、音声、ドキュメントなどのファイル形式を含む非構造化データに対して直接分析を実行できます。BigQuery ML で、同じ基本フレームワークを使って非構造化データからその価値を引き出せるようになりました。画像データに対して SQL を実行し、BigQuery ML を使用して機械学習モデルから結果を予測できます。たとえば、最新の TensorFlow ビジョンモデル(ImageNet や ResNet 50 など)または独自のモデルのどちらかをインポートし、オブジェクトの検出、写真のアノテーション付け、画像からのテキストの抽出を行うことができます。
Google Cloud のユーザーである Adswerve(Google マーケティング、Google アナリティクス、Google Cloud の主要パートナー)とそのクライアント、Twiddy & Co(米国ノースカロライナ州の民泊会社)は、BigQuery ML を使用して構造化データと非構造化データを組み合わせることで、賃貸物件の画像の分析、クリック率の予測、写真編集に関するデータドリブンな意思決定を可能にしました(詳細およびデモ)。この作業では、最終的な予測結果の 57% が画像に起因しています。
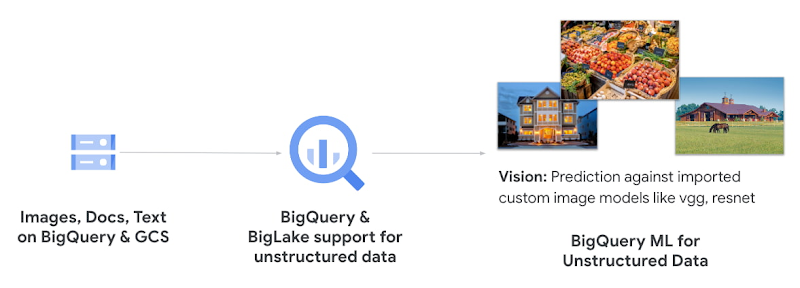
3. 推論エンジン
BigQuery ML は、既存のモデルを利用したり、次のような独自のモデルを持ち込んで拡張したりするなど、さまざまな方法で動作する推論エンジンとして機能します。
BigQuery ML のトレーニング済みモデル
さまざまな形式のインポート済みモデル
リモートモデル(まもなく利用可能になります)
BigQuery ML では、いくつかのモデルをすぐに使用できます。しかし、他のプラットフォームですでにトレーニング済みのモデルで推論したいというユーザーも存在します。そこで、TensorFlow 以外のモデルを BigQuery ML にインポートできる新機能を、TFLite と XGBoost から導入する予定です。
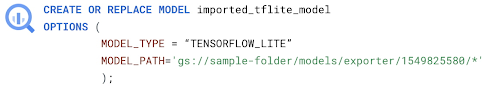
また、モデルが大きすぎてインポートできない場合(現在の制限事項はこちら)や、すでにエンドポイントにデプロイされていて、そのモデルを BigQuery に取り込めない場合、BigQuery ML でリモートモデル(Vertex AI 以外でトレーニングしたリソース、または Vertex AI を使ってトレーニングし、エクスポートしたリソース)に対して推論を行えるようになりました。Vertex AI や Cloud Functions にモデルをデプロイし、BigQuery ML を使用して予測を行うことができます。

4. より速く、より強力な特徴量エンジニアリング
特徴量の前処理は機械学習モデルの開発において最も重要なステップの一つで、特徴量の作成とデータのクリーニングで構成されます。特徴量の作成は「特徴量エンジニアリング」とも呼ばれます。言い換えれば、特徴量エンジニアリングとは、モデルをトレーニングして優れたモデルになるように、取り込んだデータを表現することです。BQML はトレーニング時に、特徴量データの種類に応じて自動的に特徴量の前処理を行います。この処理は、欠損値の補完と特徴量の変換で構成されます。これらに加え、BQML のトレーニングと推論のために、すべての数値特徴量が倍精度数に、すべてのカテゴリ特徴量が文字列にキャストされます。Google Cloud では、新しい数値関数(MAX_ABS_SCALER、IMPUTER、ROBUST_SCALER、NORMALIZER など)とカテゴリ関数(ONE_HOT_ENCODER、LABEL_ENCODER など)を導入して、特徴量エンジニアリングを次世代のレベルに引き上げる予定です。
BigQuery ML がサポートする 2 つのタイプの特徴量の前処理は次のとおりです。
自動前処理。BigQuery ML はトレーニング中に自動前処理を行います。詳しくは、特徴量の自動前処理をご覧ください。
手動前処理。BigQuery ML では、手動前処理関数で TRANSFORM 句を使用してカスタム前処理を定義できます。これらの関数は、TRANSFORM 句の外でも使用できます。
さらに、Vertex AI Model Registry による登録または手動で BigQuery ML モデルをエクスポートする際には、TRANSFORM 句も一緒にエクスポートされます。これにより、Vertex へのオンライン モデルのデプロイが非常にシンプルになります。
5. 多変量時系列予測
BigQuery の多くのお客様は、ネイティブにサポートされている ARIMA PLUS モデルを使用して、将来の需要を予測し、ビジネス運営を計画しています。これまで、お客様は予測を行う際に、単一の入力変数しか使用できませんでした。たとえば、アイスクリームの売上を予測する場合、過去の売上を基にした目標指標に天候などの外部共変量を合わせて予測することはできませんでした。今回のリリースにより、ARIMA_PLUS_XREG(外部リグレッサー(天候、場所など)を付加した ARIMA_PLUS)を使った多変量時系列予測により、複数の変数を考慮した、より正確な予測を行えるようになりました。

ご利用方法
こちらのフォームを送信すると、BigQuery ML を使用してデータから AI への移行を加速させるために役立つ、これらの新機能をお試しいただけます。こちらの動画で、ご紹介した機能の詳細と、構造化データと非構造化データの ML によってマーケティング分析がどのように変化するかを示すデモをご覧ください。
謝辞: Amir Hormati、Polong Lin、Candice Chen、Mingge Deng、Yan Sun とともにこのブログ投稿の作成に取り組めたことは光栄でした。また、サポート、協力、情報提供してくださった Manoj Gunti、Shana Matthews、Neama Dadkhahnikoo にも謝辞を送ります。
- Google、プロダクト管理 Abhinav Khushraj
- Google、プロダクト管理 Firat Tekiner



