データと AI の統合により BigQuery に非構造化データ分析を提供する
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
3 分の 1 以上の組織が、データ分析と機械学習は、今後 3 年から 5 年の間にビジネスの進め方を大きく変える可能性があると信じています。しかし、データドリブンな組織はわずか 26% にすぎません。このギャップの最大の理由の一つは、今日生成されるデータの大部分が、画像、文書、動画などの非構造化データであることです。非構造化データは、全データの約 80% を占めると言われており、これまで、これらのデータは組織によって活用されないままとなっています。
Google のデータクラウドの目標の一つは、お客様があらゆる種類と形式のデータから価値を実現できるようにすることです。今年初めには、Google はデータレイクとウェアハウスを単一の管理フレームワークで統合し、BigQuery を使用して非構造化データの分析、検索、セキュリティ、ガバナンス、共有を可能にする BigLake を発表しました。
Next ‘22 において、Google は、Google Cloud Storage に保存された非構造化データの構造化レコード インターフェースを提供する、BigQuery の新しいテーブルタイプであるオブジェクト テーブルのプレビューを発表しました。これにより、画像、音声、ドキュメントなどのファイルタイプに対して、SQL などの既存のフレームワークや BigQuery 自体のネイティブなリモート関数を使って、直接的に分析や機械学習を実行できます。オブジェクト テーブルは、構造化されたデータを保護、共有、管理するためのベスト プラクティスを非構造化データにも拡張するもので、新しいツールの学習やデプロイは必要はありません。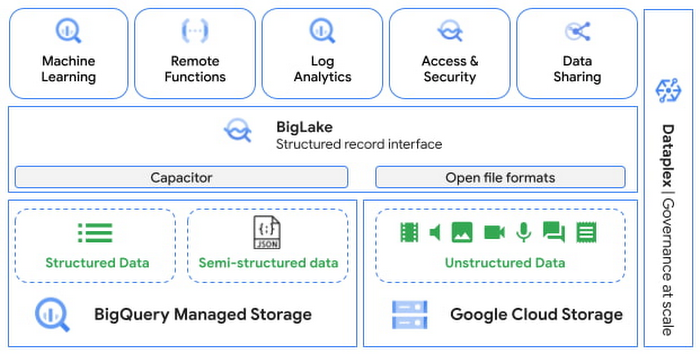
BigQuery ML を用いた非構造化データの直接処理
オブジェクト テーブルには、一意のリソース識別子(URI)、コンテンツ タイプ、サイズなどのメタデータが含まれており、他の BigQuery テーブルと同じようにクエリで確認できます。また、BigQuery ML で非構造化データに対して機械学習モデルによる推論を導き出すことができます。プレビューの一環として、オープンソースの TensorFlow Hub の画像モデルや、独自のカスタムモデルをインポートして画像にアノテーションを付けることができます。近々、音声、動画、テキストなどさまざまなフォーマットに対応し、事前学習済みのモデルですぐに解析できるようにする予定です。この動画で詳細を確認し、デモをご覧ください。BigQuery で非構造化データをネイティブに分析することで、企業は以下のことができます。
モデル要件に合わせた画像サイズの調整などの前処理が自動化されるため、手作業を排除できる。
シンプルで使い慣れた SQL インターフェースを活用し、短時間で分析情報を得ることができる。
既存の BigQuery スロットを利用するため、新たなコンピューティング フォームのプロビジョニングが不要になり、費用を削減できる。
Adswerve は、データを身近なものにするというミッションを掲げる、Google マーケティング、Google アナリティクス、Google Cloud の主要パートナーです。Twiddy & Co. は、Adswerve のクライアントで、ノースカロライナ州の民泊サービスを提供する会社です。Twiddy と Adswerve は、構造化データと非構造化データを組み合わせることで、BigQuery ML を使用して賃貸物件の画像を分析し、クリック率を予測し、写真編集に関するデータドリブンな意思決定を可能にしました。
「Twiddy は、高度な画像解析により、変化し続ける民泊プロバイダの中で競争力を維持する能力を持ち、社内の SQL スキルを使って、この作業を行うことができるようになりました。」- Adswerve、テクノロジー エバンジェリスト Pat Grady 氏
リモート機能による非構造化データの処理
現在、お客様は BigQuery でサポートされていない言語やライブラリの構造化データを処理するために、リモート関数(UDF)を使用しています。この機能を拡張して、オブジェクト テーブルを使った非構造化データの処理も行っています。
オブジェクト テーブルは、Cloud Functions または Cloud Run 上で動作するリモート UDF がオブジェクト テーブルのコンテンツを処理できるように、署名付き URL を提供します。特に、Vision AI、Speech-to-Text、Document AI などの Google の事前学習済み AI モデル、Apache Tika などのオープンソース ライブラリ、またはパフォーマンス SLA が重要な独自のカスタムモデルのデプロイを実行する際に便利な機能です。
以下は、リモート UDF として動作するオープンソース ライブラリを使用して解析された PDF ファイルに対してオブジェクト テーブルを作成する場合の例です。非構造化データへの BigQuery のさらなる機能拡張
ビジネス インテリジェンス - 非構造化データを BigQuery ML で直接、または UDF で分析した結果を構造化データと組み合わせて、Looker Studio (無償)、Looker またはお好みの BI ソリューションを使って統合レポートを作成することが可能です。これにより、より包括的なビジネスの分析情報を得ることができます。たとえば、オンライン小売店では、不良品の画像と関連付けることで、返品率を分析できます。同様に、デジタル広告主は、広告のパフォーマンスと広告クリエイティブのさまざまな属性を関連付けることで、より多くの情報に基づいた意思決定を行うことができます。
BigQuery 検索インデックス - BigQuery の検索機能を利用して、検索ユースケースを強化するお客様が増えています。これらの機能は、非構造化データ分析にも拡張されています。BigQueryML で画像の推論を行う場合も、Doc AI でリモート UDF を使用してドキュメント抽出を行う場合も、その結果を検索インデックスにして、検索アクセス パターンに対応させることができるようになりました。
以下は PDF ファイルから解析されたデータに対する検索インデックスの例です。
セキュリティとガバナンス - Google は、BigQuery の行レベルのセキュリティ機能を拡張し、Google Cloud Storage のオブジェクトを安全に保護できるようにします。オブジェクト テーブルの特定の行を保護することで、エンドユーザーがテーブル内に存在している対応する URI の署名付き URL を取得する能力を制限できます。これは共有責任のセキュリティ モデルで、管理者はエンドユーザーが Google Cloud Storage に直接アクセスできないようにし、オブジェクト テーブルからの署名付き URL を唯一のアクセスのメカニズムとして使用する必要があります。
ここでは、PII 画像を保護するために、まずぼかしパイプラインで処理するポリシーの一例を紹介します。
まもなく Dataplex はオブジェクト テーブルをサポートし、BigQuery でオブジェクト テーブルを自動的に作成し、非構造化データを大規模に管理し、統制することができるようになる予定です。
データ共有 - Analytics Hub を使用することで、セキュリティとガバナンスを妥協することなく、パートナー、お客様、サプライヤーと非構造化データを共有できるようになりました。サブスクライバーは、共有されているオブジェクトテーブルの行を消費し、非構造化データ オブジェクトの署名付き URL を使用できます。
スタートガイド
このフォームを送信して、BigQuery で非構造化データの能力を引き出す、これらの新機能を試すことができます。これらの新機能の詳細については、このデモをご覧ください。
本投稿を執筆したエンジニアリング リーダーの Amir Hormati、Justin Levandoski、Yuri Volobuev に感謝します。

- Google Cloud プロダクト マネージャー、Gaurav Saxena
- Google Cloud ソフトウェア エンジニア、Thibaud Hottelier
