Built with BigQuery: Faraday による BigQuery ML を活用した米国消費者ブランドの予測
Google Cloud Japan Team
※この投稿は米国時間 2022 年 9 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
2022 年は、デジタルネイティブな企業も従来型の企業も、データのウェアハウジング、保護、ガバナンスについて理解を深める年となりました。しかし、安全に活用されれば素晴らしい効果を生むことは約束されているものの、機械学習および人工知能と機械学習(AI / ML)の倫理的応用については未知の部分が残されています。Google Cloud Platform(GCP)のユーザーは、BigQuery やサーバーレスのゼロ ETL 環境など、業界をリードする技術へアクセスはできても、何から始めればいいのか模索を続けている状態です。
Google Cloud はお客様に多くのデータ分析および AI / ML 用の組み込みオプションを提供していますが、それぞれのユースケースの目的に合わせてカスタマイズしたソリューションは、技術パートナーを通じてお届けしています。
Faraday は、あらゆる規模のブランドが、予測のパワーを活用してより効果的に顧客を惹きつけることができるよう支援する、Google の技術パートナーです。2012 年以来、Faraday は、あらゆる企業が自身の消費者データの中から見い出すために利用できるシグナルのパターンを標準化してきました。企業はそのシグナルをもとに、さまざまな実行パートナーとともに活性化を図ることができます。
Faraday の成功の鍵となったのは、GCP のデータクラウドの、目玉の一つともいえる BigQuery の活用方法です。BigQuery はサーバーレスのデータ ウェアハウスで、分析および機械学習ワークロードの両方にデータローカル コンピューティングを提供しています。BigQuery の大きな特徴の一つは、すべての機能において、ビジネス ロジックを宣言するために SQL を使用することです。この設計は非常に大きな意味を持つと言えます。SQL を記述と、実質的に無制限のリソースにおいて、BigQuery がそれを同時に読み込むのです。これは、いわゆるデータ エンジニアが、ML への深い専門知識がなくても、機械学習を活用できるというはっきりとした道すじを示しています。
Faraday は BigQuery を使って、実質無制限の顧客データを取り込み、Google の最高水準の Google のツールを利用してそのデータを保護、管理します。さらに、データを標準スキーマに変換し、消費者予測に関連するさまざまな特徴を計算し、BigQuery ML を使ってデータローカルの機械学習モデリングと予測を実行します。BigQuery ML を使用すると、BigQuery で標準 SQL クエリを使用して、機械学習モデルを作成し実行できます。BigQuery ML は、SQL 実務担当者が既存の SQL ツールやスキルを使ってモデルを構築することを可能にし、機械学習をより多くの人が利用できるようにします。BigQuery ML ではデータを移動する必要がないため、開発スピードを向上させることができます。
以下に、Faraday のこうした一連の作業の例と、Built in BigQuery の比較優位性を紹介します。
BigQuery ML での実例
ユースケース 1: パーソナライズによるコンバージョンの増加
クライアントは、メール、メールハッシュ、住所など、あらゆる形で Faraday に既知の ID を提供します。顧客は、ブランド固有の一連のペルソナにセグメント化されます。その後、それらのペルソナに対するアウトリーチのパーソナライズを行うことで、コンバージョンを向上させることができます。これは Faraday の、米国の 2 億 6,000 万人の成人を対象とした、すぐに利用できるデータベースによって実現され、ユーザー属性、心理学的属性、財産、ライフイベントなどのデータを網羅した 600 以上の機能を有しています。
クライアントが Faraday の API かアプリケーションに「ペルソナセット」をリクエストすると、Faraday は(クライアントが提供する)利用可能なクライアントの「自社データ」と国のデータセット(「第三者データ」)を結合し、次の BigQuery ML ステートメントを宣言します。

BigQuery ML が他と異なるのは、Faraday がすべてのデータ準備を SQL で行い、そこから先は Google がデータの移動、スケーリング、コンピューティングを担当する点です。その結果得られたクラスタモデルは、米国内の全人口を予測的にセグメント化します。これにより、クライアントはあらゆるチャネルでアウトリーチをパーソナライズできるようになります。
ユースケース 2: リード スコアリング
クライアントが顧客、見込み顧客、潜在顧客の既知の ID を提供しさえすれば、Faraday は、自社と第三者のデータから豊富なトレーニング データセットを構築できます。このデータセットを使って、見込み顧客が顧客になる可能性、顧客が高額消費をする優良顧客になる可能性、顧客が他社に乗り換えるなどで非アクティブになる可能性を予測することができます。
クライアントが Faraday API やアプリケーションで「結果」をリクエストすると、Faraday は再び自社データと第三者データを結合し、時間ベースの差分を含む関連する機械学習機能をコンピューティングし、以下の BigQuery ML ステートメントを宣言します。

注意すべき点がいくつかあります。第一に、このユースケースとその前のパーソナライズに関するユースケースでは、Faraday は BigQuery ML を使って他の最適化を適用しています。しかし、これは通常のデータ サイエンスの実践を単純に表現し、さまざまな形式の回帰を使用して特徴選択を強化したものです。いずれの場合も SQL は簡単です。あるいは Python、Spark、Airflow などの技術で表現されたデータ パイプラインよりも使いやすいかもしれません。
第二に、Faraday はクライアントにデータ サイエンティストとしての役割を求めてはいません。BigQuery ML のブースト ツリーモデルの説明可能性を活用し、クライアントへの出力は特徴の重要性と可能なバイアスに関する広範なレポートでなされますが、クライアントからの最初の入力は、彼らがもっと見てみたいと思う集団を選択するだけでよいのです。たとえば、「高額消費顧客」とは何かを定義できれば、Faraday にそうした顧客をより多く予測するように依頼するだけで済みます。
ユースケース 3: 費用予測と LTV
クライアントが、来年または 36 か月以内に、特定の顧客や顧客セグメント(ペルソナ)が、自社にどんな支出をしそうかを知りたいとします。Faraday の API やアプリケーションで「予測」をリクエストすれば、Faraday は前述のデータ結合と特徴量生成を行ったうえで、以下の BigQuery ML ステートメントを宣言します。
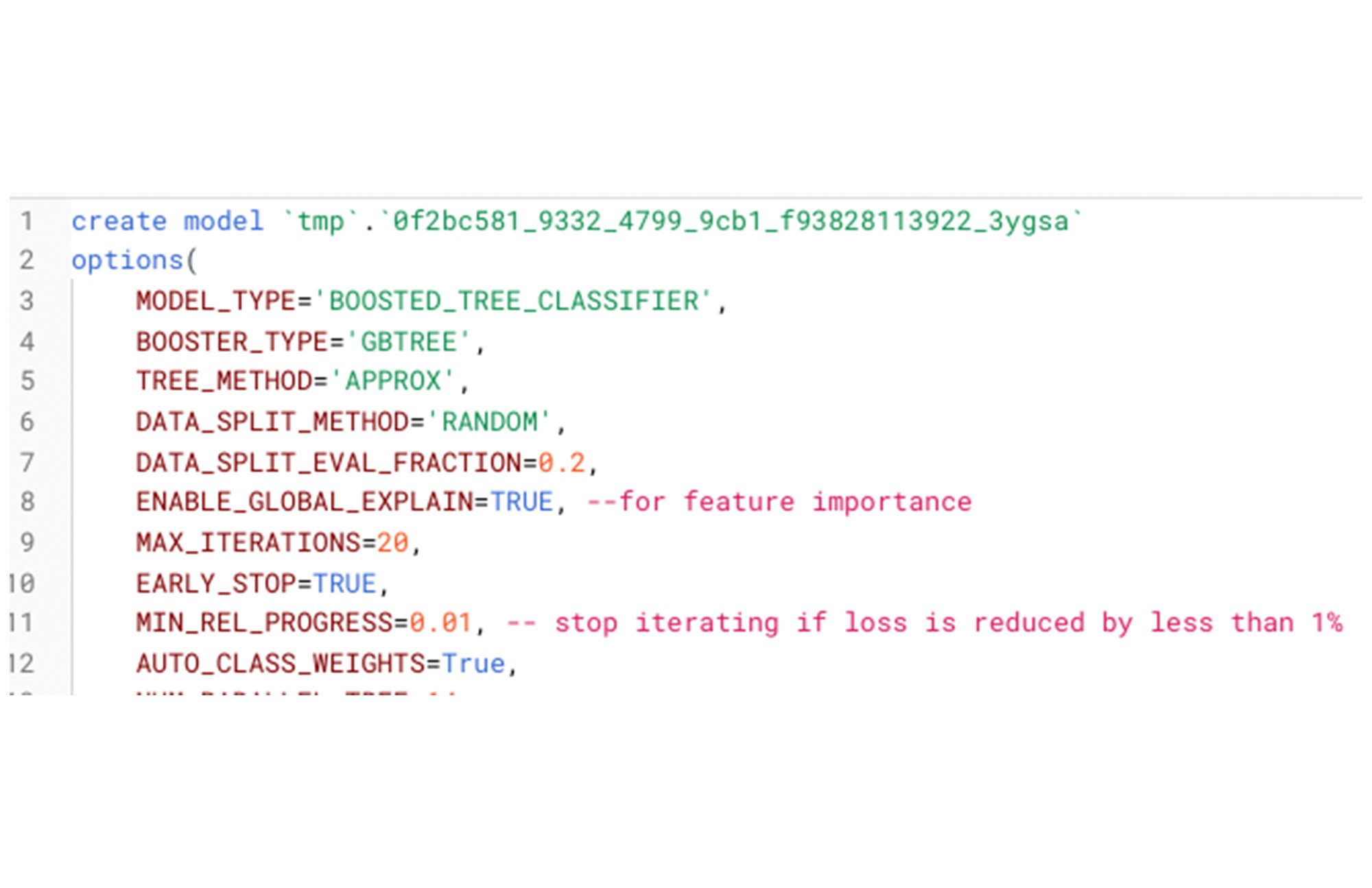
現在、Faraday では消費予測や LTV(ローン トゥ バリュー レシオ)を回帰モデルとして実装していますが、BigQuery は活発に開発が行われているため、将来的にはさらに優れたオプションが利用できるようになるかもしれません。そうすれば、Faraday のクライアントに、Faraday が提供したシグナルが改善されたと思ってもらえるでしょう。
GCP が予測製品を構築するのに最適なデータクラウドである理由
2022 年の上半期、Faraday は 1 兆以上の米国の消費者向けビジネスの予測を行ってきました。これは、GCP が予測製品の構築に最適なデータクラウドであることを示す次の要素によって可能になりました。
要素 1: ゼロ ETL
BigQuery ML モデルを構築することで、同時に Vertex AI モデルも作成していることをご存じでしたか?おそらく多くの方はご存じないでしょうし、知らなくてもほぼ問題はありません。Google の業界最高水準のデータクラウド アーキテクチャでは、クライアント(および Faraday)はデータ移動、RAM 割り当て、ディスクの拡張、シャーディングを行いません。SQL でお望みのことを宣言するだけで、Google がそれを叶えます。
要素 2: サーバーレスでデータローカルなコンピューティング
「データの局所性」は単なる流行語ではありません。Faraday は、BigQuery と手を携えた 2018 年から、逆転の発想として、データにコンピューティングをもたらすことで、以前の機械学習ソリューションと比較して予測能力を 2 桁もスケールアップさせることができたのです。以前は、Faraday が非常に複雑なデータコピーと再試行ロジックを構築しなければなりませんでした。しかし、現在は再試行ロジックは削除され、スロット予約の増加(または SQL の見直し)によるスケーリングの問題の解決がなされています。
要素 3: モデルの多様性と活発な開発
何かをモデル化したい場合、BigQuery ML にはすでに適切なモデルタイプがあるはずです。もしなかったとしても、Google は継続的な投資を行い、BigQuery 上に構築されたデータ パイプラインの価値を時間とともに増加させていきます。これにより、一部のタスクの達成のために、SQL 以外の言語やフレームワークを学習する必要がある場合に生じる認知的不協和も解消されていくでしょう。
まとめ
デジタルネイティブな企業も従来型の企業も同様に、顧客や潜在顧客に関する予測から利益を得ることができます。Faraday は、課題に対するレディーメイドのソリューションを提供します。このソリューションはすぐに利用することが可能で、データ サイエンスを推し進めるクライアントの意欲を後押ししてベンチマークテストを行えるようにします。Google BigQuery のスケーリング、利便性、積極的な投資により、GCP は Faraday が製品を構築するために最適なデータクラウドとなりました。また、クライアントが自身のアーキテクチャのために GCP を検討する際の説得力のある理由となっています。
ISV にとっての Built with BigQuery のメリット
Google は、Google Data Cloud Summit の一環として、4 月にリリースした Built with BigQuery を通じて、SoundCommerce のようなテクノロジー企業が、Google のデータクラウド上に革新的なアプリケーションを構築できるよう、テクノロジーへのシンプルなアクセス、役立つ専任のエンジニアリング サポート、共同市場開拓プログラムなどを提供しています。参加企業には以下のメリットがあります。
Google が資金提供した事前構成済みのサンドボックスを使って、すぐに構築に着手できます。
ISV センター オブ エクセレンスの専任エキスパートから、重要なユースケース、アーキテクチャ パターン、ベスト プラクティスについてのインサイトを得て、プロダクトの設計とアーキテクチャを加速できます。
共同マーケティング プログラムを利用して、認知度の向上、需要の創出、導入の拡大を図り、より大きな成功を実現できます。
BigQuery は、Google Cloud のオープンかつ安全でサステナブルなプラットフォームに統合された、パワフルでスケーラビリティの高いデータ ウェアハウスのメリットを ISV に提供します。Google が提供する巨大なパートナー エコシステムと、マルチクラウド、オープンソース ツール、API のサポートを利用すれば、テクノロジー企業は、データ ロックインを回避するために必要な移植性と拡張性を得ることができます。
Built with BigQuery の詳細については、こちらをクリックしてご確認ください。
- Cloud パートナー エンジニアリング担当ディレクター Ali Arsanjani 博士
- Faraday、共同創設者 / CTO Seamus Abshere 氏
