Built with BigQuery: BigQuery ML enables Faraday to make predictions for any US consumer brand
Dr. Ali Arsanjani
Director, Applied AI Engineering, Google
Seamus Abshere
Co-founder and CTO, Faraday
In 2022, digital natives and traditional enterprises find themselves with a better understanding of data warehousing, protection, and governance. But machine learning and the ethical application of artificial intelligence and machine learning (AI/ML) remain open questions, promising to drive better results if only their power can be safely harnessed. Customers on the Google Cloud Platform (GCP) have access to industry-leading technology for example, with BigQuery, with access to in a serverless, zero-ETL environment - but it's still hard to know how to start.
While Google Cloud provides customers with a multitude of built-in options for Data Analytics and AI/ML, Google relies on technology partners to provide customized solutions to meet fit-for-purpose customer use-cases.
Faraday is a Google technology partner focused on helping brands of all sizes engage customers more effectively with the practical power of prediction. Since 2012, Faraday has been standardizing a set of patterns that any business can follow to look for signal in its consumer data - and activate on that signal with a wide variety of execution partners.
Crucial to Faraday's success is how it uses Google BigQuery, one of the crown jewels of GCP's data cloud. BigQuery is a serverless data warehouse that provides data-local compute for both analytic and machine learning workloads. One of BigQuery's core abstractions is the use of SQL to declare business logic across all of its functions. This is a design choice with wide implications: if you can write SQL, then BigQuery will take care of parallelizing it across virtually unlimited resources. This presents a very clear path from a Data Engineer persona to the use of machine learning without the need for deep expertise in ML.
On BigQuery, Faraday can ingest virtually unlimited amounts of client data, protect and govern it with best-in-breed Google tools, transform it into a standard schema, calculate a wide variety of features that are relevant to consumer predictions, and run data-local machine learning modeling and prediction using BigQuery ML. BigQuery ML lets you create and execute machine learning models in BigQuery using standard SQL queries. BigQuery ML democratizes machine learning by letting SQL practitioners build models using existing SQL tools and skills. BigQuery ML increases development speed by eliminating the need to move data.
Below, Faraday gives some examples of this work and also the comparative advantage from being Built on BigQuery.
Real examples of BigQuery ML
Use case 1: increase conversion with personalization
Clients who provide known identity to Faraday in any form - email, email hash, or physical address - can have their customers segmented into a brand-specific set of personas. Then they can personalize outreach to these personas to increase conversion. This is facilitated by Faraday's "batteries included" database of 260 million US adults, with more than 600 features covering demographic, psychographic, property, and life event data.
Once the client requests a "persona set" in the Faraday API or application, Faraday joins any available client "first party data" (provided by the client) with the national dataset ("third party data") and declares the following BigQuery ML statement:

What's unique about BigQuery ML is that Faraday is able to do all data prep in SQL, and from that point on, Google is in charge of data movement, scaling and computation. The resulting cluster model can be used to predictively segment the entire US population, so that the client can personalize outreach in any channel.
Use case 2: lead scoring
As long as the client is able to provide a form of known identity for their customers, leads, or prospects, Faraday can construct a rich training dataset from first and third party data. This dataset can be used to predict the likelihood of leads becoming customers, of customers becoming great (high-spending) customers, or of customers churning or otherwise becoming inactive.
Once the client requests an "outcome" in the Faraday API or application, Faraday again joins any first and third party data, computes relevant machine learning features including time-based differentials, and declares the following BigQuery ML statement:
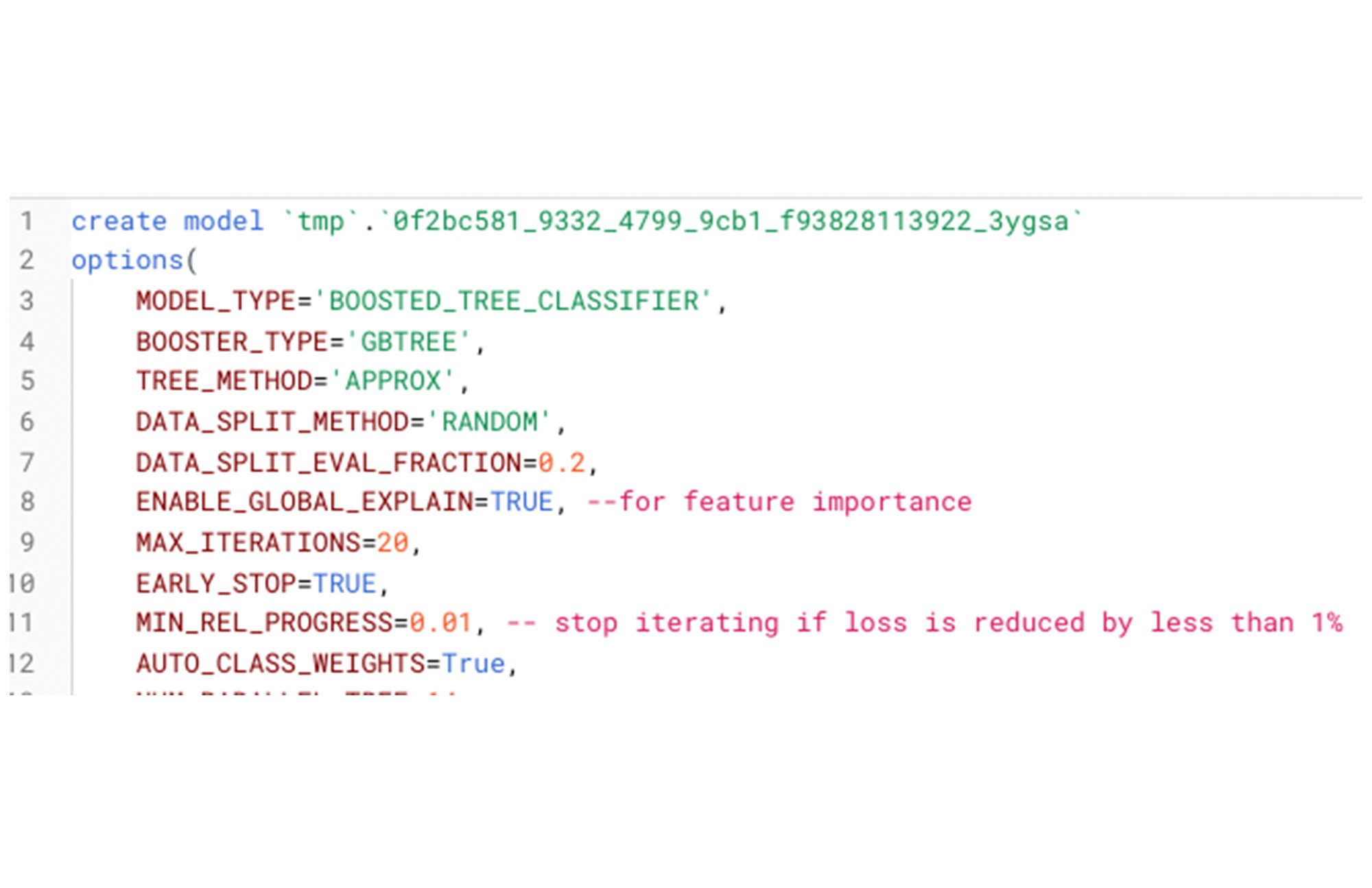
There are a couple points to note. First, in this use case and the previous (personalization), Faraday applies other optimizations using BigQuery ML - but they are a simple expression of normal data science practice to enhance feature selection using different forms of regression. In all cases, the SQL is straightforward - and perhaps more accessible than data pipelines expressed in Python, Spark, Airflow or other technologies.
Second, Faraday is not asking the client to act as a data scientist. Thanks to the explainability of BigQuery ML boosted tree models, the output to the client is an extensive report on feature importances and possible biases, but the initial input from the client is to simply select a population they would like to see more of. For example, if they can define what a "high spending customer" is, they can simply ask Faraday to predict more of those.
Use case 3: spend forecasting and LTV
Say a client wants to know what particular customers or customer segments (personas) will spend with them in the next year or 36 months. By requesting a "forecast" in the Faraday API or application, Faraday will perform the aforementioned data joining and feature generation and then declare the following BigQuery ML statement:

Currently, Faraday implements spend forecasting and LTV (Life Time Value) as a regression model, but even better options may become available in the future as BigQuery is under active development. Faraday clients would see this as an improvement in the signal that Faraday provided to them.
Why GCP is the best data cloud for building predictive products
In the first half of 2022, Faraday ran more than 1 trillion predictions for US consumer businesses. This was only possible due to a number of factors that make GCP the best data cloud for building predictive products.
Factor 1: Zero ETL
Did you know that when you build a BigQuery ML model, you are actually creating a Vertex AI model? Probably not - and it doesn't matter in most cases. Google's industry leading data cloud architecture means that the client (and Faraday) is not responsible for data movement, RAM allocation, disk expansion, or sharding. You simply declare what you want in SQL, and Google ensures that it happens.
Factor 2: Serverless, data-local compute
"Data locality" is not just a buzzword - ever since Faraday came to BigQuery in 2018, bringing the compute to the data instead of the other way around has enabled Faraday to scale its predictive capability by two orders of magnitude compared to its previous machine learning solution. Previously, Faraday had to build highly complex data copying and retry logic; now, the retry logic has been deleted and scaling problems are solved by increasing slot reservations (or rethinking SQL).
Factor 3: Model diversity and active development
If you want to model something, there is probably an appropriate model type already available in BigQuery ML. But if there's not, Google's continuing investment means that data pipelines built on BigQuery will grow in value over time - without the cognitive dissonance that arises from needing to learn languages and frameworks outside of SQL just to accomplish a particular task.
Conclusion
Digital natives and traditional enterprises alike will benefit from predictions made about their customers and potential customers. Faraday can provide a ready-made solution to this problem, both to enable immediate activation and to inspire and benchmark clients on their own data science journey. Google BigQuery's scale, convenience, and active investment make GCP the best data cloud for Faraday to build its product - and provide a compelling reason for clients to consider it for their own architecture.
The Built with BigQuery advantage for ISVs
Through Built with BigQuery, launched in April as part of Google Data Cloud Summit, Google is helping tech companies like Faraday build innovative applications on Google’s data cloud with simplified access to technology, helpful and dedicated engineering support, and joint go-to-market programs. Participating companies can:
Get started fast with a Google-funded, pre-configured sandbox.
Accelerate product design and architecture through access to designated experts from the ISV Center of Excellence who can provide insight into key use cases, architectural patterns, and best practices.
Amplify success with joint marketing programs to drive awareness, generate demand, and increase adoption.
BigQuery gives ISVs the advantage of a powerful, highly scalable data warehouse that’s integrated with Google Cloud’s open, secure, sustainable platform. And with a huge partner ecosystem and support for multi-cloud, open source tools and APIs, Google provides technology companies the portability and extensibility they need to avoid data lock-in.
Click here to learn more about Built with BigQuery.

