What's new with ML infrastructure for Dataflow
Efesa Origbo
Product Manager, Google
Danny McCormick
Software Engineer, Google Cloud
The world of artificial intelligence is moving at lightning speed. At Google Cloud, we’re committed to providing best-in-class infrastructure to power your AI and ML workloads. Dataflow is a critical component of Google Cloud’s AI stack that lets you create batch and streaming pipelines that support a variety of analytics and AI use cases. We’re excited to share a wave of recent features and capabilities that give you more choice, greater obtainability, and improved efficiency when it comes to running your batch and streaming ML workloads.
More choice: Performance-optimized hardware
We understand that all ML workloads are not created equal. That's why we're expanding our hardware offerings to give you the flexibility to choose the best accelerators for your specific needs.
-
New GPUs: We’re constantly adding the latest and greatest GPUs to our lineup, and we recently announced support for NVIDIA H100 GPUs (A3 High and A3 Mega VMs with enhanced networking capabilities). This means you can take advantage of cutting-edge hardware to accelerate your AI inference workloads. Leading businesses are leveraging GPUs in Dataflow to power innovative customer experiences — from threat intelligence platform provider Flashpoint powering document translation, to media provider Spotify enabling at-scale podcast previews.
-
TPUs: For large-scale ML tasks, Tensor Processing Units (TPUs) offer a powerful and cost-effective solution. We recently announced support for TPU V5E, V5P and V6E, which enable state-of-the-art ML builders to efficiently run high-volume, low-latency machine learning inference workloads at scale, directly within their Dataflow jobs.
Greater accelerator obtainability
Getting access to the hardware you need, when you need it, is crucial for keeping your ML projects on track. We've introduced new ways to consume accelerators that make it easier than ever to get the resources you need.
-
GPU/TPU reservations: You can now reserve GPUs and TPUs for your Dataflow jobs, so that you'll have the resources you need when you need them. This is important for critical workloads that can't afford to wait for resources to become available.
-
Flex-start GPU provisioning: For batch jobs with flexible start times, securing GPUs can be a manual and uncertain process due to high industry-wide demand. Our new flex-start provisioning model enabled by Dynamic Workload Scheduler (DWS) effectively addresses this issue: Instead of a job failing when accelerator resources are unavailable, Dataflow now queues your job and automatically starts it as soon as the required GPUs become available. This eliminates the need for repeated manual resubmissions, mitigating stockout risk and accelerating developer productivity.
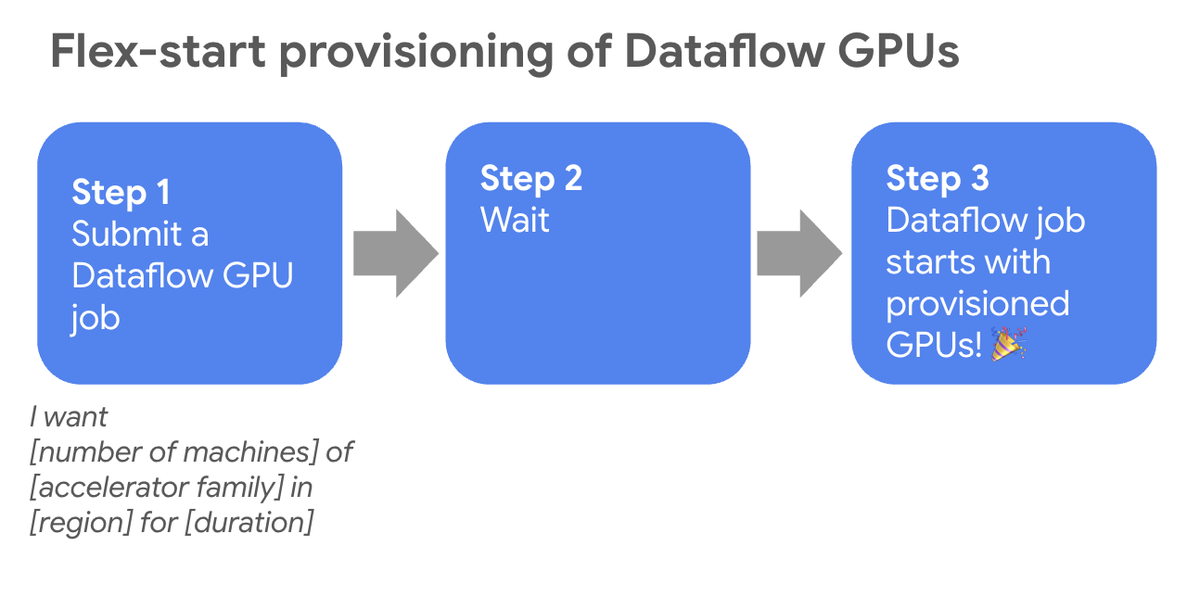
Improved efficiency for AI workloads
We're always looking for ways to help you run your AI workloads more efficiently. Recently announced features like right fitting and ML-aware streaming are designed to help you get the most out of your investments in AI.
-
ML-aware streaming: We’ve made our streaming engine ML-aware, which means it can now make smarter decisions about how to execute your streaming ML pipelines. For example, horizontal autoscaling in Dataflow usually relies on a variety of input signals that include backlog size and CPU utilization. As accelerators become a critical part of the compute infrastructure for processing ML workloads, they need to be factored into autoscaling decisions. We recently launched GPU-based autoscaling, which enables the Dataflow service to use GPU-related signals such as degree of parallelism as a key input to its horizontal autoscaling algorithm, and deliver increased efficiency to streaming ML jobs.
-
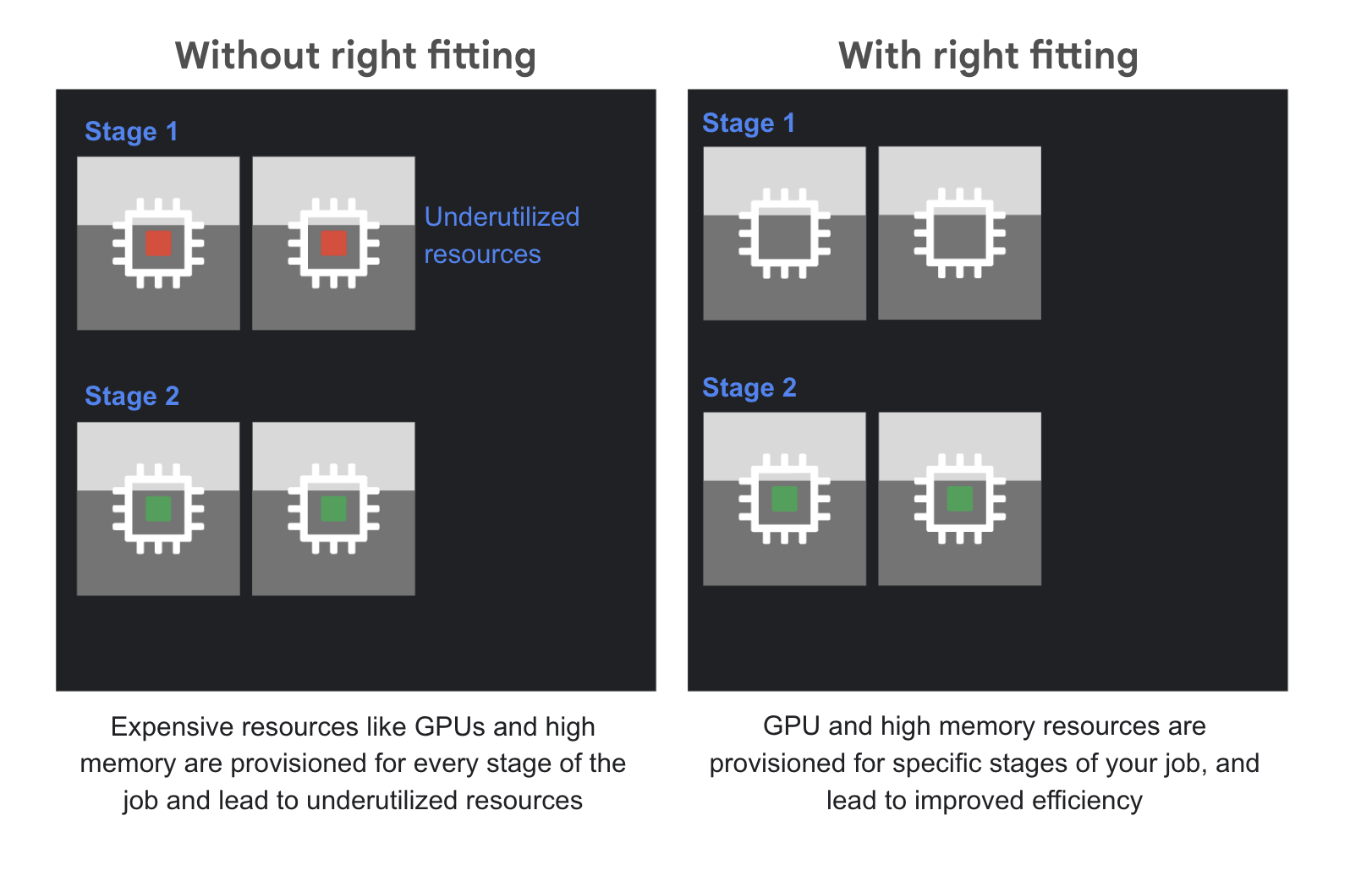
Right fitting: Dataflow pipelines often have different resource needs at different stages. Previously, you had to choose a single machine type that would be powerful enough for the most demanding stage, leading to inefficiency and wasted cost during the less resource-intensive stages of the job. Right fitting solves this "one-size-fits-all" problem by allowing you to use heterogeneous resource pools. This means that compute-intensive stages of a job can run on specialized hardware with high memory or GPUs, while other stages run on generic, cost-effective workers. This leads to significantly increased efficiency and optimized costs.
We’re incredibly excited about Dataflow’s ML capabilities and the possibilities they unlock for our customers. Get started with Dataflow today and use these features to solve your hardest ML challenges.

