BigQuery ML で需要予測モデルを構築する方法

Google Cloud Japan Team
※この投稿は米国時間 2021 年 1 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
小売業者は、ほどよく在庫を維持しようといつも頭を悩ませています。在庫が多すぎても少なすぎても良くないためです。何百万種もの製品があるとされる中で、データ サイエンスとエンジニアリングの担当チームが数百万件の予測を作成するのも一仕事ですが、継続的なモデル トレーニングと予測を処理するためのインフラストラクチャを調達、管理することは、特に大企業にとっては、すぐに手に負えない作業となり得ます。
BigQuery ML では、SQL を使用して、機械学習モデルのトレーニングとデプロイを行えます。フルマネージド型のスケーラブルな BigQuery のインフラストラクチャを使用することで、複雑さを軽減しながら本運用までの時間を短縮できるため、より多くの時間を予測に費やして、業務を改善できます。
そこで、以下のアルコール飲料のような、何千種類から何百万種類にも及ぶ製品の需要予測モデルを BigQuery ML で大規模に構築する方法を説明します。
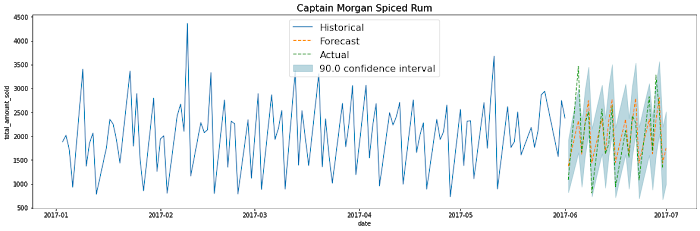
このブログ記事では、BigQuery ML を使用して複数の製品の需要を予測する時系列モデルの構築方法を紹介します。アイオワ州の酒類販売データを使用し、過去 18 か月分の取引データを使って、次の 30 日の需要を予測してみます。
次の方法を学習します。
BigQuery ML を使用して需要予測モデルを作成するために必要な正しい形式にデータを事前加工する方法
BigQuery ML で ARIMA ベースの時系列モデルをトレーニングする方法
モデルを評価する方法
今後 n 日間における各製品の将来的な需要を予測する方法
出された予測に対しどのような対応を取るか
ダッシュボードを作成し、データポータルを使用して、予測された需要を可視化する方法
クエリのスケジュールを設定して、定期的にモデルを自動で再トレーニングする方法
データ: アイオワ州の酒類販売
BigQuery で一般公開されているアイオワ州酒類販売データは、「アイオワ州のクラス「E」酒類ライセンシーの酒類購入情報を、2012 年 1 月 1 日から現在までの商品別、購入日別に収録したデータセット」(アイオワ州の公式資料より)です。
生データセットは、以下の形式になっています。
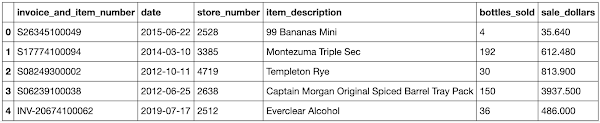
特定の日に同じ商品に対し複数の注文が出される場合があるため、以下を行う必要があります。
日付および商品ごとに、合計販売済み商品数を計算する
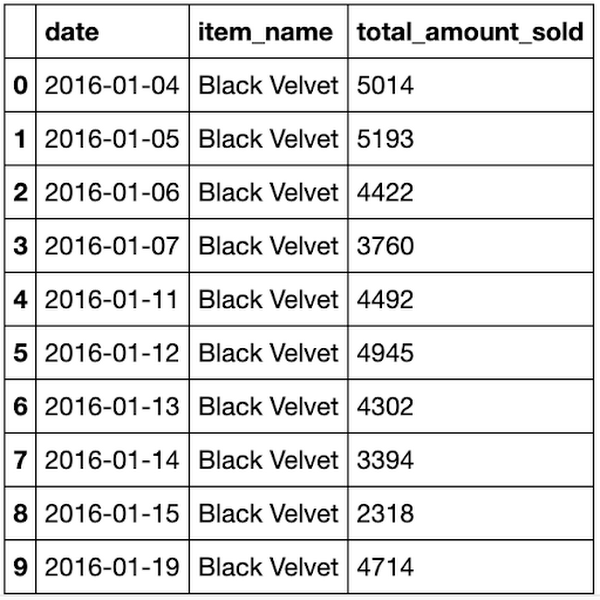
クリーンアップしたトレーニング データ
クリーンアップしたトレーニング データでは、日付ごと、商品名ごとに当日の合計販売数が 1 行で表されます。このデータは、テーブルまたはビューとして保存できます。この例では、このデータは CREATE TABLE を使用して、bqmlforecast.training_data として保存されます。
BigQuery ML を使用して、時系列モデルをトレーニングする
時系列モデルのトレーニングは、単純な作業です。
BigQuery ML での時系列モデル作成方法
BigQuery ML で時系列モデルをトレーニングする場合、複数のモデルまたはコンポーネントがモデル作成パイプラインで使用されます。ARIMA は、コア アルゴリズムの 1 つです。その他のコンポーネントも、下記のおおまかに示した実行順に使用されます。
事前加工: 入力時系列に対する自動クリーニング調整。欠損値、タイムスタンプの重複、異常値の急増などを調整します。また、時系列履歴の急激なレベル変更にも対応します。
休日効果: BigQuery ML で時系列モデルを作成する場合は、休日効果を加味することもできます。デフォルトでは、休日効果のモデリングは無効になっています。ただし、このデータは米国のデータであり、最小限の 1 年分の日次データしかないため、任意の HOLIDAY_REGION を指定することもできます。休日効果を有効にすると、休日中に見られる異常な増大と減少が異常として処理されなくなります。休日基準地域の全一覧については、HOLIDAY_REGIONドキュメントをご覧ください。
LOESS 回帰に基づく季節変動と長期変動の分解(STL)アルゴリズムによる季節変動と長期変動の分解。2 重指数平滑(ETS)アルゴリズムを使用した季節性の推定。
ARIMA モデルと auto.ARIMA アルゴリズムを使用したトレンド モデリングによるハイパーパラメータの自動調整。auto.ARIMA では、p、d、q、ブレなど、多くの候補モデルが並行してトレーニング、評価されます。赤池情報量規準(AIC)が最も低いモデルが最適なモデルになります。
BigQuery ML での複数製品の並行予測
時系列モデルをトレーニングして単一の製品の需要を予測することも、複数の製品の需要を同時に予測することもできます(予測する製品が何千点、何百万点もある場合には非常に便利です)。複数の製品の需要を同時に予測する場合は、複数のパイプラインが並行して実行されます。
この例では、1 つのモデル作成文で複数の製品のモデルをトレーニングしているため、TIME_SERIES_ID_COL というパラメータを item_name として指定する必要があります。なお、1 点の商品の需要のみを予測する場合は、TIME_SERIES_ID_COL を指定する必要はありません。詳細は、BigQuery ML 時系列モデル作成のドキュメントをご覧ください。
時系列モデルの評価
ML.EVALUATE 関数(ドキュメント)を使用すると、作成されたすべてのモデルの評価指標を確認できます。

ご覧のとおり、この例では、item_name の各商品に 1 つずつ、合計 5 つのモデルがトレーニングされました。最初の 4 列(non_seasonal_{p,d,q}、has_drift)は、ARIMA モデルの定義です。その後の 3 つの指標(log_likelihood、AIC、variance)は、ARIMA モデルの適合プロセスに関連するものです。適合プロセスでは、時系列ごとに auto.ARIMA アルゴリズムが使用され、最適な ARIMA モデルが決定されます。これらの指標のうち、AIC が一般的に最も使用される指標で、時系列モデルがデータにどれだけ適合するかを評価しながら、複雑すぎるモデルに低評価を下します。目安として、AIC のスコアが低いほど良いとされます。最後に、5 つの商品それぞれについて検出された seasonal_periods が偶然にも WEEKLY で一致しました。
モデルを使用して予測を行う
以降の、ホライズンに設定された n 個の値を予測する ML.FORECAST(構文ドキュメント)を使用して、予測を行います。また、予測値が予測区間内に収まる割合である confidence_level を変更することもできます。
下のコードは予測ホライズン「30」を示していますが、これはトレーニング データが日次データであったため、次の 30 日間の予測を行うことを意味しています。
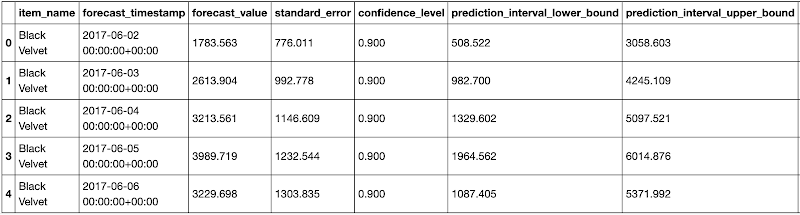
ホライズンが 30 に設定されたため、結果には 30 個の予測値 *(商品数)に等しい数の行が含まれています。
各予測値には、confidence_level が与えられた場合の prediction_interval の上限と下限も表示されます。
SQL スクリプトでは、ホライズンと confidence_level の入力をパラメータ化できるよう、DECLARE と EXECUTE IMMEDIATE を使用しています。これらの HORIZON 変数および CONFIDENCE_LEVEL 変数を使用すると、後で値をより簡単に調整できるため、コードの可読性と保守性を向上させることができます。この構文の動作については、Standard SQL のスクリプトに関するドキュメントをご覧ください。
予測のプロット
お気に入りのデータ可視化ツールの使用や、以下に示すように、GitHub に掲載の matplotlib とデータポータル用のこちらのテンプレート コードの使用ができます。
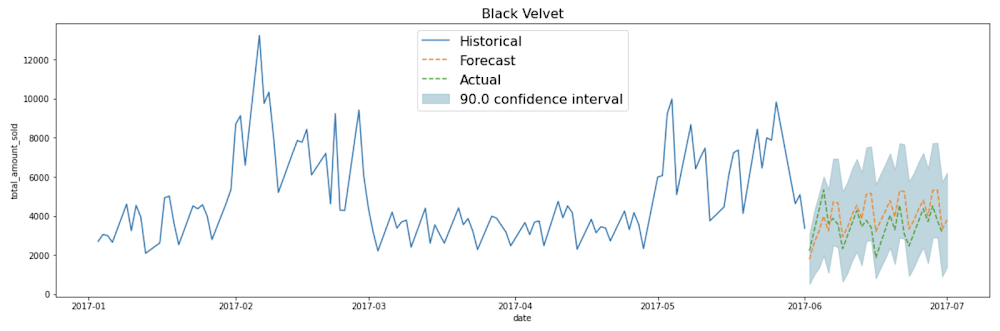
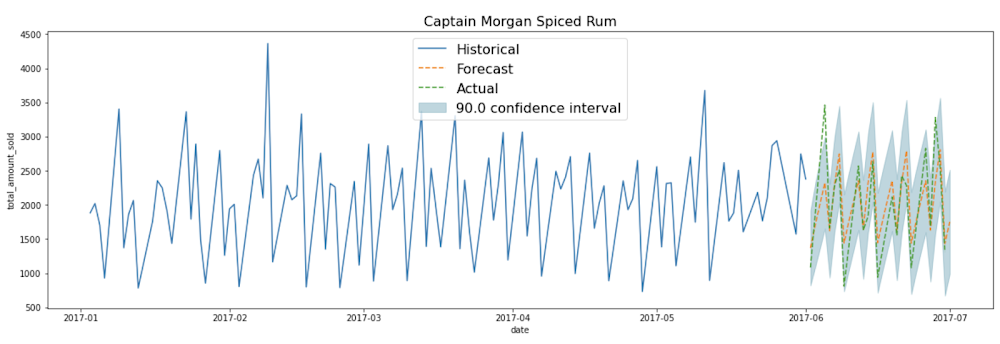
定期的にモデルを自動で再トレーニングする方法
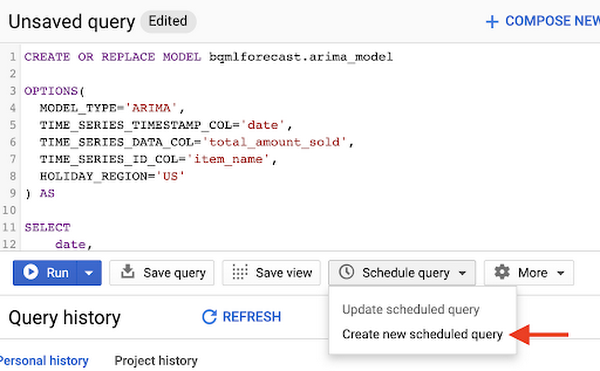
多くの小売業者と同様、最新のデータに基づいて新たに時系列予測を作成する必要がある場合、スケジュール設定されたクエリを使用して、CREATE MODEL クエリ、ML.EVALUATE クエリ、または ML.FORECAST クエリを含む SQL クエリを自動的に再実行できます。
1. BigQuery UI で、新しくスケジュール設定されたクエリを作成する
先に「スケジュール設定されたクエリを有効化」してから、最初のクエリを作成することをおすすめします。
2. 要求事項(例: Weekly を繰り返す)を入力し、[Schedule] をクリックする
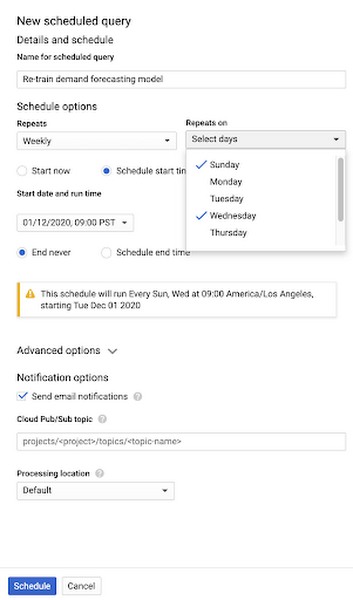
3. スケジュール設定された BigQuery クエリのページで、スケジュール設定したクエリを監視する

BigQuery ML での時系列の使用に関する追加アドバイス
ARIMA モデル係数を確認する
各 ARIMA モデルの正確な係数を知りたい場合は、ML.ARIMA_COEFFICIENTS(ドキュメント)を使用して確認できます。
各モデルの ar_coefficients は、ARIMA モデルの自己回帰(AR)部分のモデル係数を表します。同様に、ma_coefficients は、移動平均(MA)部分のモデル係数を表します。どちらも配列で、長さはそれぞれ non_seasonal_p と non_seasonal_q です。intercept_or_drift は ARIMA モデルの定数項です。
まとめ
お疲れさまでした。BigQuery ML を使用して時系列モデルをトレーニングし、モデルを評価して、本番環境で結果を使用する方法を学びました。
GitHub のコード
GitHub の以下の Jupyter ノートブックに全体コードが掲載されています。
BigQuery ML で小売業販売データを基に必要在庫をトレーニング、評価、予測する方法について、2 月 4 日のライブ チュートリアルで説明します。予測モデルを最新状態に保てるようモデルの定期的な再トレーニングのスケジュールを設定する方法についても、デモを行います。チャットで Google Cloud の専門家に質問して回答を得るチャンスもあります。
詳細情報
Google Cloud のデベロッパー アドボケイトの Polong Lin です。@polonglin をフォローいただくか、Linkedin(linkedin.com/in/polonglin)でご連絡ください。
ご提案やご意見がございましたら、コメントでお寄せください。
レビュー担当の Abhishek Kashyap と Karl Weinmeister に感謝します。

-デベロッパー アドボケイト Polong Lin




