BigQuery ML の新機能: 時系列と非時系列データの教師なし異常検出
Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
異常検出に関して多くの組織が直面する主要な課題の一つは、異常が何であるかを定義する方法を知ることが難しいという点です。不審なネットワーク侵入、製造欠陥、保険金詐欺をどのように定義して未然に防げるでしょうか。既知の異常でラベル付けされたデータがある場合、BigQuery ML ですでにサポートされているさまざまな教師あり機械学習モデルタイプから選択できます。しかし、どのような異常が起こるかを予想できず、ラベル付けされたデータもない場合にはどうすればよいでしょうか。教師あり学習を利用する一般的な予測の手法とは違って、ラベル付けされたデータがない場合でも、組織が異常を検出できるようにする必要があります。
本日発表するのは、BigQuery ML の新しい異常検出機能の公開プレビューです。この機能を使えば、教師なし機械学習を利用してラベル付けされたデータがなくても異常を検出できます。トレーニング データが時系列かどうかに応じ、新しい ML.DETECT_ANOMALIES 機能(ドキュメント)と次のタイプのモデルを使用して、トレーニング データと新しい入力データの異常を検出できます。
ML.DETECT_ANOMALIES を使った異常検出の仕組み
非時系列データ内の異常検出には以下のモデルを使用できます。
k 平均法クラスタリング モデル: k 平均法モデルで ML.DETECT_ANOMALIES を使用すると、各入力データポイントの最も近いクラスタまでの正規化距離の値に基づいて異常が特定されます。その距離が、ユーザーが規定した汚染値によって決められたしきい値を超えた場合に、そのデータポイントは異常とみなされます。
オートエンコーダ モデル: オートエンコーダ モデルで ML.DETECT_ANOMALIES を使用すると、各データポイントの再構成誤差に基づいて異常が特定されます。誤差は、汚染値によって決められたしきい値を超えたときに異常とみなされます。
時系列データ内の異常検出には以下のモデルを使用できます。
ARIMA_PLUS 時系列モデル: ARIMA_PLUS モデルで ML.DETECT_ANOMALIES を使用すると、そのタイムスタンプの信頼区間に基づいて異常が特定されます。タイムスタンプのデータポイントが予測区間以外で発生する見込みが、ユーザーが規定した見込みしきい値を超えた場合に、そのデータポイントは異常とみなされます。
上述の各シナリオにおける BigQuery ML の異常検出のコード例を以下に示します。
k 平均法クラスタリング モデルを使用した異常検出
トレーニング データと新しい入力データ内の異常を検出する ML.DETECT_ANOMALIES を実行することで、k 平均法クラスタリング モデルを使用した異常検出ができるようになりました。まず、k 平均法クラスタリング モデルを作成します。
トレーニング済みの k 平均法クラスタリング モデルを使用して ML.DETECT_ANOMALIES を実行し、トレーニング データまたは新しい入力データ内の異常を検出できます。
トレーニング データ内の異常を検出するには、トレーニング中に使用したのと同じデータで ML.DETECT_ANOMALIES を使用します。
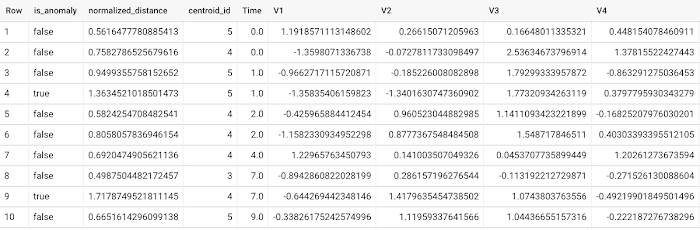
新しいデータ内の異常を検出するには、ML.DETECT_ANOMALIES を使用して、新しいデータを入力として渡します。

k 平均法クラスタリング モデルでの異常検出の仕組み
各入力データポイントの一番近いクラスタまでの正規化距離の値に基づいて異常が特定されます。その値が汚染値によって定められたしきい値を超えた場合は、異常とみなされます。具体的にはどのような仕組みなのでしょうか。入力として k 平均法モデルとデータを使用して、ML.DETECT_ANOMALIES はまず、各入力データポイントからモデル内のすべてのクラスタ セントロイドまでの絶対距離を計算します。続いて、各距離がそれぞれのクラスタ半径(このクラスタ内のすべてのポイントからセントロイドまでの絶対距離の標準偏差として定義される)によって正規化されます。上のスクリーンショットのように、ML.DETECT_ANOMALIES は各データポイントに対して normalized_distance(正規化距離)を基準に一番近い centroid_id(セントロイド ID)を返します。ユーザーが規定した汚染値によって、データポイントが異常であるか否かを判断するしきい値が決められます。たとえば、汚染値 0.1 とは、トレーニング データの正規化距離のうち降順で上から 10% がカットオフしきい値として使用されるという意味です。データポイントの正規化距離がそのしきい値を超えた場合に、異常とみなされます。適正な汚染の設定はユーザーまたは企業の要件によって大きく異なります。
k 平均法クラスタリングを使用した異常検出について詳しくは、こちらのドキュメントをご参照ください。
オートエンコーダ モデルを使用した異常検出
トレーニング データと新しい入力データ内の異常を検出する ML.DETECT_ANOMALIES を実行することで、オートエンコーダ モデルを使用した異常検出ができるようになりました。
まず、オートエンコーダ モデルを作成します。
トレーニング データ内の異常を検出するには、トレーニング中に使用したのと同じデータで ML.DETECT_ANOMALIES を使用します。
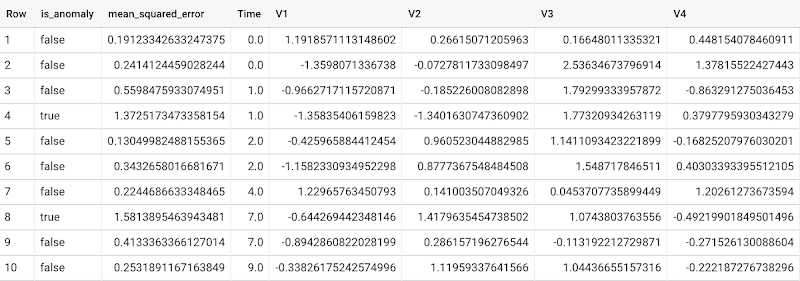
新しいデータ内の異常を検出するには、ML.DETECT_ANOMALIES を使用して、新しいデータを入力として渡します。

オートエンコーダ モデルでの異常検出の仕組み
各入力データポイントの再構成誤差の値に基づいて異常が特定されます。その値が汚染値によって定められたしきい値を超えた場合は、異常とみなされます。具体的にはどのような仕組みなのでしょうか。入力としてオートエンコーダ モデルとデータを使用して、ML.DETECT_ANOMALIES はまず、各データポイントの元の値と再構成された値の間の mean_squared_error(平均 2 乗誤差)を計算します。ユーザーが規定した汚染値によって、データポイントが異常であるか否かを判断するしきい値が決められます。たとえば、汚染値 0.1 とは、トレーニング データの誤差のうち降順で上から 10% がカットオフしきい値として使用されるという意味です。適正な汚染の設定はユーザーまたは企業の要件によって大きく異なります。
オートエンコーダ モデルを使用した異常検出について詳しくは、こちらのドキュメントをご覧ください。
ARIMA_PLUS 時系列モデルを使用した異常検出
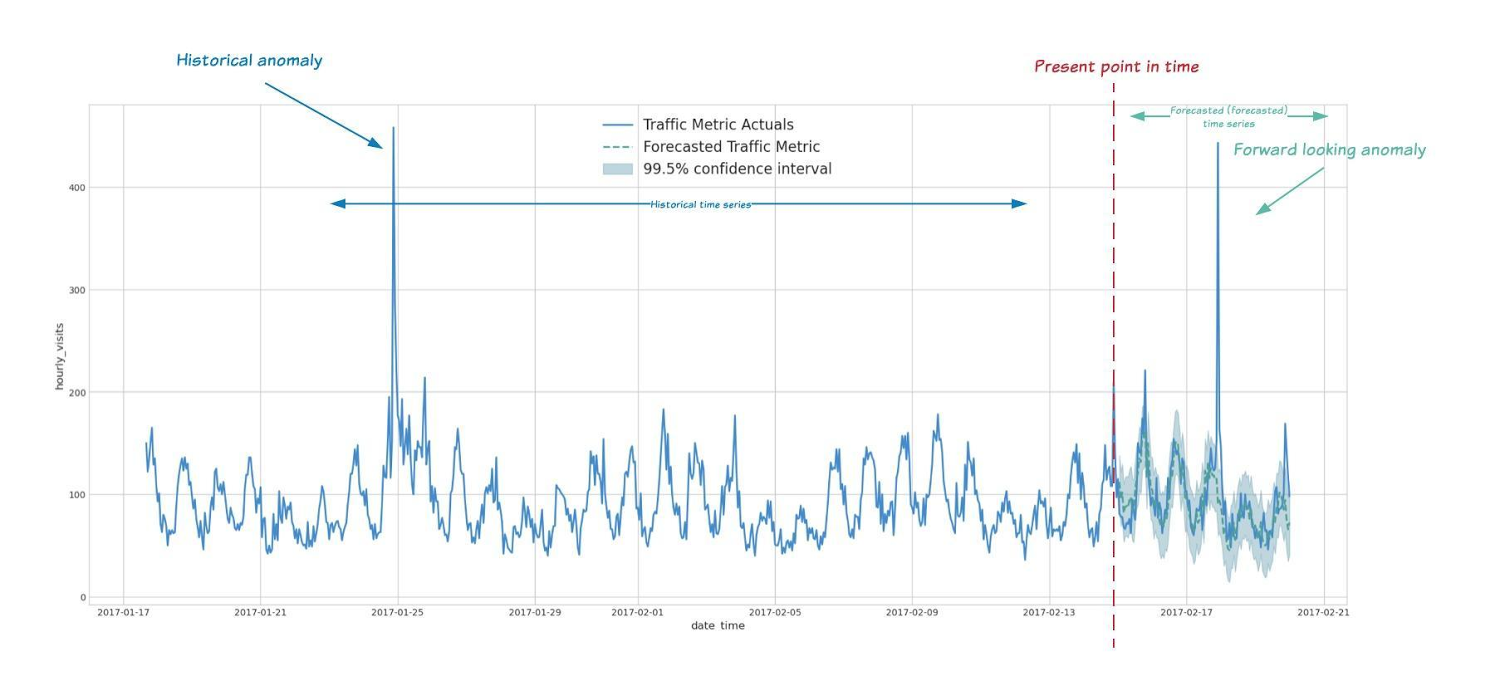
ML.DETECT_ANOMALIES を使うことで、ARIMA_PLUS 時系列モデルによる(過去の)トレーニング データと新しい入力データ内の異常検出ができるようになりました。時系列データを使用した異常検出の例を次に示します。
過去のデータの異常検出:
予測とモデリングを目的とするデータのクリーンアップ。たとえば、過去の時系列を ML モデルのトレーニング用に前処理する場合など。
小売の需要の時系列が大量にあり(数百の店舗や郵便番号にまたがる数千の商品)、異常な販売パターンを示した店舗と商品カテゴリを迅速に特定し、原因を詳細に分析したい。
先を見越した異常検出:
消費者行動と価格設定の異常をできるだけ早く検出。たとえば、特定のプロダクト ページへのトラフィックが予期せず急増した場合は、価格設定プロセスにエラーが生じて異常に安い価格になっている可能性があります。
小売の需要の時系列が大量にあり(数百の店舗や郵便番号にまたがる数千の商品)、異常な販売パターンを示した店舗と商品カテゴリを予測に基づいて特定し、不測の急増や急減に迅速に対応したい。
ARIMA_PLUS を使って異常を検出するには、まず ARIMA_PLUS 時系列モデルを作成します。
トレーニング データ内の異常を検出するには、上述の取得したモデルで ML.DETECT_ANOMALIES を使用します。
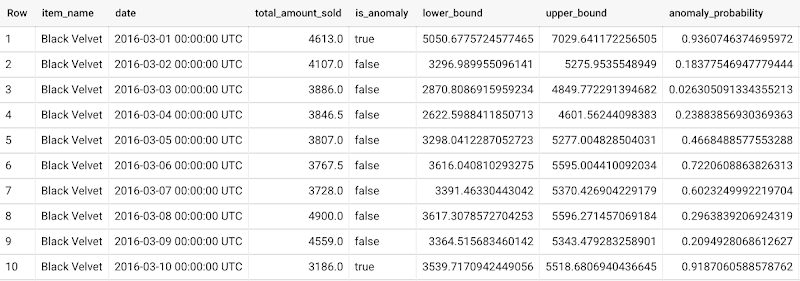
新しいデータ内の異常を検出するには、ML.DETECT_ANOMALIES を使用して、新しいデータを入力として渡します。
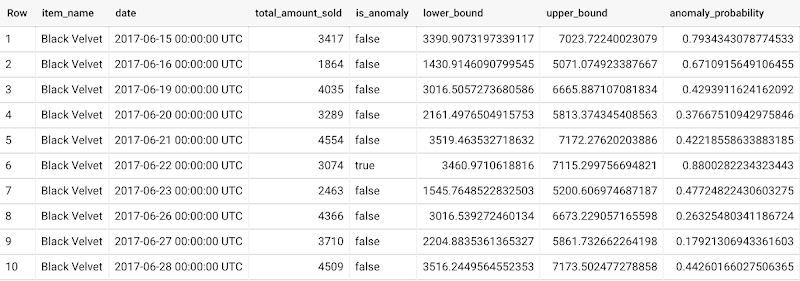
ARIMA_PLUS 時系列モデルを使用した異常検出について詳しくは、こちらのドキュメントをご覧ください。
BigQuery ML チーム、特に Abhinav Khushraj、Abhishek Kashyap、Amir Hormati、Jerry Ye、Xi Cheng、Skander Hannachi、Steve Walker、Stephanie Wang に感謝します。
-デベロッパー アドボケイト Polong Lin
- BigQuery ML ソフトウェア エンジニア Jiashang Liu



